乾貨 Elasticsearch 知識點整理二
- 2019 年 11 月 8 日
- 筆記
目錄
## mapping
root object
mapping json中包含了諸如properties,matadata(_id,_source,_type),settings(analyzer)已經其他的settings
PUT my_index { "mappings": { "my_index": { "properties": { "my_field1": { "type": "integer" }, "my_field2": { "type": "float" }, "my_field2": { "type": "scaled_float", "scaling_factor": 100 } } } } }mate-field 元數據欄位
_all
當我們往ES中插入一條document時,它裡面包含了多個fireld, 此時,ES會自動的將多個field的值,串聯成一個字元串,作為_all屬性,同時會建立索引,當用戶再次檢索卻沒有指定查詢的欄位 時,就會在這個_all中進行匹配
_field_names
按照指定的field進行檢索,所有含有指定field並且field不為空的document全部會被檢索出來
示例:
# Example documents PUT my_index/_doc/1 { "title": "This is a document" } PUT my_index/_doc/2?refresh=true { "title": "This is another document", "body": "This document has a body" } GET my_index/_search { "query": { "terms": { "_field_names": [ "title" ] } } }禁用:
PUT tweets { "mappings": { "_doc": { "_field_names": { "enabled": false } } } }_id
document的唯一標識資訊
_index
標識當前的doc存在於哪個index中,並且ES支援跨域index進行檢索,詳情見官網 點擊進入官網
_routing
路由導航需要的參數,這是它的計算公式shard_num = hash(_routing) % num_primary_shards
可以像下面這樣訂製路由規則
PUT my_index/_doc/1?routing=user1&refresh=true { "title": "This is a document" } GET my_index/_doc/1?routing=user1_source
這個元數據中定義的欄位,就是將要返回給用戶的doc的中欄位,比如說一個type = user類型的doc中存在100個欄位,但是前端並不是真的需要這100個欄位,於是我們使用_source去除一些欄位,注意和filter是不一樣的,filter不會影響相關性得分
禁用
PUT tweets { "mappings": { "_doc": { "_source": { "enabled": false } } } }_type
這個欄位標識doc的類型,是一個邏輯上的劃分, field中的value在頂層的lucene建立索引的時候,全部使用的opaque bytes類型,不區分類型的lucene是沒有type概念的, 在document中,實際上將type作為一個document的field,什麼field呢? _type
ES會通過_type進行type的過濾和篩選,一個index中是存放的多個type實際上是存放在一起的,因此一個index下,不可能存在多個重名的type
_uid
在ES6.0中被棄用
mapping-parameters
首先一點,在ES5中允許創建多個index,這在ES6中繼續被沿用,但是在ES7將被廢棄,甚至在ES8中將被徹底刪除
其次:在一開始我們將Elastic的index必做Mysql中的database, 將type比作table,其實這種比喻是錯誤的,因為在Mysql中不同表之間的列在物理上是沒有關係的,各自佔有自己的空間,但是在ES中不是這樣,可能type=Student中的name和type=Teacher中的name在存儲在完全相同的欄位中,換句話說,type是在邏輯上的劃分,而不是在物理上的劃分
copy_to
這個copy_to實際上是在允許我們自定義一個_all欄位, 程式設計師可以將多個欄位的值複製到一個欄位中,然後再次檢索時目標欄位就使用我們通過copy_to創建出來的_all新欄位中
它解決了一個什麼問題呢? 假設我們檢索的field的value="John Smith",但是doc中存放名字的field卻有兩個,分別是firstName和lastName中,就意味著cross field檢索,這樣一來再經過TF-IDF演算法一算,可能結果就不是我們預期的樣子,因此使用copy_to 做這件事
示例:
PUT my_index { "mappings": { "_doc": { "properties": { "first_name": { "type": "text", "copy_to": "full_name" }, "last_name": { "type": "text", "copy_to": "full_name" }, "full_name": { "type": "text" } } } } } PUT my_index/_doc/1 { "first_name": "John", "last_name": "Smith" } GET my_index/_search { "query": { "match": { "full_name": { "query": "John Smith", "operator": "and" } } } }動態mapping(dynamic mapping)
ES使用_type來描述doc欄位的類型,原來我們直接往ES中存儲數據,並沒有指定欄位的類型,原因是ES存在類型推斷,默認的mapping中定義了每個field對應的數據類型以及如何進行分詞
null --> no field add true flase --> boolean 123 --> long 123.123 --> double 1999-11-11 --> date "hello world" --> string Object --> object訂製dynamic mapping 策略
- ture: 語法陌生欄位就進行dynamic mapping
- false: 遇到陌生欄位就忽略
- strict: 遇到默認欄位就報錯
示例
PUT /my_index/ { "mappings":{ "dynamic":"strict" } }- 禁用ES的日期探測
PUT my_index { "mappings": { "_doc": { "date_detection": false } } } PUT my_index/_doc/1 { "create": "2015/09/02" }- 訂製日期發現規則
PUT my_index { "mappings": { "_doc": { "dynamic_date_formats": ["MM/dd/yyyy"] } } } PUT my_index/_doc/1 { "create_date": "09/25/2015" }- 訂製數字類型的探測規則
PUT my_index { "mappings": { "_doc": { "numeric_detection": true } } } PUT my_index/_doc/1 { "my_float": "1.0", "my_integer": "1" }核心的數據類型
各種類型的使用及範圍參見官網,點擊進入
數字類型
long, integer, short, byte, double, float, half_float, scaled_float示例:
PUT my_index { "mappings": { "_doc": { "properties": { "number_of_bytes": { "type": "integer" }, "time_in_seconds": { "type": "float" }, "price": { "type": "scaled_float", "scaling_factor": 100 } } } } }日期類型
date示例:
PUT my_index { "mappings": { "_doc": { "properties": { "date": { "type": "date" } } } } } PUT my_index/_doc/1 { "date": "2015-01-01" } boolean類型
string類型的字元串可以被ES解釋成boolean
boolean示例:
PUT my_index { "mappings": { "_doc": { "properties": { "is_published": { "type": "boolean" } } } } }二進位類型
binary示例
PUT my_index { "mappings": { "_doc": { "properties": { "name": { "type": "text" }, "blob": { "type": "binary" } } } } } PUT my_index/_doc/1 { "name": "Some binary blob", "blob": "U29tZSBiaW5hcnkgYmxvYg==" }範圍
integer_range, float_range, long_range, double_range, date_range示例
PUT range_index { "settings": { "number_of_shards": 2 }, "mappings": { "_doc": { "properties": { "expected_attendees": { "type": "integer_range" }, "time_frame": { "type": "date_range", "format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis" } } } } } PUT range_index/_doc/1?refresh { "expected_attendees" : { "gte" : 10, "lte" : 20 }, "time_frame" : { "gte" : "2015-10-31 12:00:00", "lte" : "2015-11-01" } }複雜數據類型
對象類型,嵌套對象類型示例:
PUT my_index/_doc/1 { "region": "US", "manager": { "age": 30, "name": { "first": "John", "last": "Smith" } } }在ES內部這些值被轉換成這種樣式
{ "region": "US", "manager.age": 30, "manager.name.first": "John", "manager.name.last": "Smith" }Geo-type
ES支援地理上的定位點
PUT my_index { "mappings": { "_doc": { "properties": { "location": { "type": "geo_point" } } } } } PUT my_index/_doc/1 { "text": "Geo-point as an object", "location": { "lat": 41.12, "lon": -71.34 } } PUT my_index/_doc/4 { "text": "Geo-point as an array", "location": [ -71.34, 41.12 ] } Arrays 和 Multi-field
更多內容參見官網**,點擊進入
查看某個index下的某個type的mapping
GET /index/_mapping/type訂製type field
可以給現存的type添加field,但是不能修改,否則就會報錯
PUT twitter { "mappings": { "user": { "properties": { "name": { "type": "text" , # 會被全部檢索 "analyzer":"english" # 指定當前field使用 english分詞器 }, "user_name": { "type": "keyword" }, "email": { "type": "keyword" } } }, "tweet": { "properties": { "content": { "type": "text" }, "user_name": { "type": "keyword" }, "tweeted_at": { "type": "date" }, "tweeted_at": { "type": "date" "index": "not_analyzeed" # 設置為當前field tweeted_at不能被分詞 } } } } }mapping複雜數據類型再底層的存儲格式
Object類型
{ "address":{ "province":"shandong", "city":"dezhou" }, "name":"zhangsan", "age":"12" }轉換
{ "name" : [zhangsan], "name" : [12], "address.province" : [shandong], "address.city" : [dezhou] }Object數組類型
{ "address":[ {"age":"12","name":"張三"}, {"age":"12","name":"張三"}, {"age":"12","name":"張三"} ] }轉換
{ "address.age" : [12,12,12], "address.name" : [張三,張三,張三] }精確匹配與全文檢索
精確匹配稱為 : exact value
搜索時,輸入的value必須和目標完全一致才算作命中
"query": { "match_phrase": { "address": "mill lane" } }, # 短語檢索 address完全匹配 milllane才算命中,返回 全文檢索 full text
全文檢索時存在各種優化處理如下:
- 縮寫: cn == china
- 格式轉換 liked == like == likes
- 大小寫 Tom == tom
- 同義詞 like == love
示例
GET /_search { "query": { "match" : { "message" : "this is a test" } } }倒排索引 & 正排索引
倒排索引 inverted index
倒排索引指向所有document分詞的field
假設我們存在這樣兩句話
doc1 : hello world you and me doc2 : hi world how are you建立倒排索引就是這樣
| – | doc1 | doc2 |
|---|---|---|
| hello | * | – |
| world | * | * |
| you | * | * |
| and | * | – |
| me | * | – |
| hi | – | * |
| how | – | * |
| are | – | * |
這時,我們拿著hello world you 來檢索,經過分詞後去上面索引中檢索,doc12都會被檢索出,但是doc1命中了更多的詞,因此doc1得分會更高
正排索引 doc value
doc value實際上指向所有不分詞的document的field
ES中,進行搜索動作時需要藉助倒排索引,但是在排序,聚合,過濾時,需要藉助正排索引,所謂正排索引就是其doc value在建立正排索引時一遍建立正排索引一遍建立倒排索引, doc value會被保存在磁碟上,如果記憶體充足也會將其保存在記憶體中
正排索引大概長這樣
| document | name | age |
|---|---|---|
| doc1 | 張三 | 12 |
| doc2 | 李四 | 34 |
正排索引也會寫入磁碟文件 中,然後os cache會對其進行快取,以提成訪問doc value的速度,當OS Cache中記憶體大小不夠存放整個正排索引時,doc value中的值會被寫入到磁碟中
關於性能方面的問題: ES官方建議,大量使用OS
Cache來進行快取和提升性能,不建議使用jvm記憶體來進行快取數據,那樣會導致一定的gc開銷,甚至可能導致oom問題,所以官方的建議是,給JVM更小的記憶體,給OS Cache更大的記憶體, 假如我們的機器64g,只需要給JVM 16g即可
doc value存儲壓縮 — column壓縮
為了減少doc value佔用記憶體空間的大小,採用column對其進行壓縮, 比如我們存在三個doc, 如下
doc 1: 550 doc 2: 550 doc 3: 500合併相同值,doc1,doc2的值相同都是550,保存一個550標識即可
- 所有值都相同的話,直接保留單位
- 少於256的值,使用table encoding的模式進行壓縮
- 大於256的值,檢查他們是否有公約數,有的話就除以最大公約數,並保留最大公約數
如: doc1: 24 doc2 :36 除以最大公約數 6 doc1: 4 doc2 : 6 保存下最大公約數6- 沒有最大公約數就使用 offset結合壓縮方式
禁用doc value
假設,我們不使用聚合等操作,為了節省空間,在創建mappings時,可以選擇禁用doc value
PUT /index { "mappings":{ "my_type":{ "properties":{ "my_field":{ "type":"text", "doc_values":false # 禁用doc value } } } } }相關性評分與 TF-IDF演算法
relevance score 相關度評分演算法, 直白說就是算出一個索引中的文本和搜索文本之間的相似程度
Elasticsearch使用的是 TF-IDF演算法 (term-frequency / inverser document frequency)
- term-frequency: 表示當前搜索的文本中的詞條在field文本中出現了多少次,出現的次數越多越相關
- inverse document frequency : 表示搜索文本中的各個詞條在整個index中所有的document中出現的次數,出現的次數越多越不相關
- field-length: field長度越長,越不相關
向量空間模式
ES會根據用戶輸入的詞條在所有document中的評分情況計算出一個空間向量模型 vector model, 他是空間向量中的一個點
然後會針對所有的doc都計算出一個vector model出來, 將這個
如果存在多個term,那麼就是一個多維空間向量之間的運算,但是我們假設是二維的,就像下面這張圖

一目了然,Doc2和目標詞條之間的弧度小,於是認為他們最相似,它的得分也就越高
分詞器
什麼是分詞器?
我們使用分詞將將一段話拆分成一個一個的單詞,甚至進一步對分出來的單詞進行詞性的轉換,師太的轉換,單複數的轉換的操作, 為什麼使用分詞器? 就是為了提高檢索時的召回率,讓更多的doc被檢索到
分詞器的組成
character filter:
在一段文本在分詞前先進行預處理,比如過濾html標籤, 將特殊符號轉換成123..這種阿拉伯數字等特殊符號的轉換
tokenizer
進行分詞,拆解句子,記錄詞條的位置(在當前doc中占第幾個位置term position)及順序
token filter
進行同義詞的轉換,去除同義詞,單複數的轉換等等
ES內置的分詞器
- standard analyzer(默認)
- simple analyzer
- whitespace
- language analyzer(特定語言的分詞器,English)
知識補充
- ES隱藏了複雜分散式機制,如分片,副本,負載均衡
- 增加或者減少節點時,ES會自動的進行rebalance,使數據平均分散在不同的節點中
- master節點: master節點用來管理集群中的元數據,默認會在集群中選出一個節點當成master節點,而且master節點並不會承載全部請求,所以不存在單點瓶頸
- 元數據: 創建或者刪除索引,增加或者刪除節點
- 擴容方案: 更推薦橫向擴容,這也符合ES分片的特定,購置大量的便宜的機器讓他們成為replica shard加入集群中
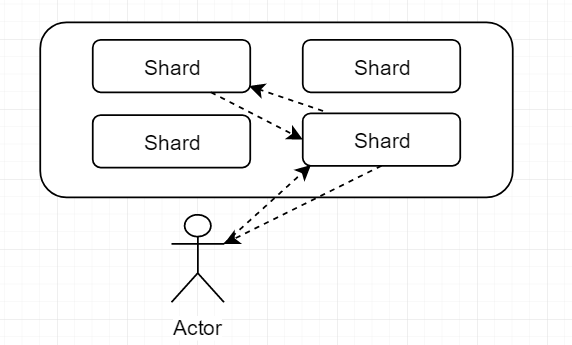
每一個分片地位相同,都能接受請求,處理請求,噹噹用戶的一個請求發送到某一個shard中後,這個shard會自動就請求路由到真正存儲數據的shard上去,但是最終總是由接受請求的節點響應請求
圖解: master的選舉,容錯,以及數據的恢復
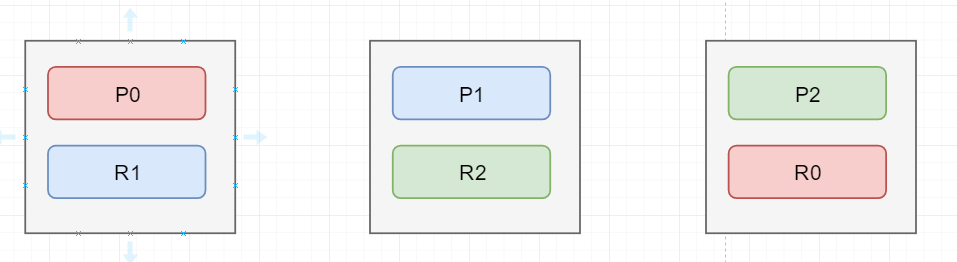
如上圖為初始狀態圖
假如,圖上的第一個節點是master節點,並且它掛掉,在掛掉的一瞬間,整個cluster的status=red,表示存在數據丟失了集群不可用
下面要做的第一步就是完成master的選舉,自動在剩下的節點中選出一個節點當成master節點, 第二步選出master節點後,這個新的master節點會將Po在第三個節點中存在一個replica shard提升為primary shard,此時cluster 的 status = yellow,表示集群中的數據是可以被訪問的但是存在部分replica shard不可用,第三步,重新啟動因為故障宕機的node,並且將右邊兩個節點中的數據拷貝到第一個節點中,進行數據的恢復
並發衝突問題
ES的實現
ES內部的多執行緒非同步並發修改時,是通過_version版本號進行並發控制的,每次創建一個document,它的_version內部版本號都是1,以後對這個doc的修改,刪除都會使這個版本號增1
ES的內部需在Primary shard 和 replica shard之間同步數據,這就意味著多個修改請求其實是亂序的不一定按照先後順序執行
相關語法:
PUT /index/type/2?version=1{ "name":"XXX" }上面的命令中URL中的存在?version=1,此時,如果存在其他客戶端將id=2的這條記錄修改過,導致id=2的版本號不等於1了,那麼這條PUT語句將會失敗並有相應的錯誤提示
基於external的版本號控制,ES提供了一個Futrue,也就是說用戶可以使用自己維護的版本號進行並發訪問控制,比如:
PUT /index/type/2?version=1&version_type=external假設當前ES中的版本號是1, 那麼只有當用戶提供的版本號大於1時,PUT才會成功
路由原理
- 什麼是數據路由?
一個index被分成了多個shard,文檔被隨機的存在某一個分片上,客戶端一個請求打向index中的一個分片,但是請求的doc可能不存在於這個分片上,接受請求的shard會將請求路由到真正存儲數據的shard上,這個過程叫做數據路由
其中接受到客戶端請求的節點稱為coordinate node,協調節點,比如現在是客戶端往服務端修改一條消息,接受A接受到請求了,那麼A就是 coordnate node協調節點,數據存儲在B primary shard 上,那麼協調節點就會將請求路由到B primary shard中,B處理完成後再向 B replica shard同步數據,數據同步完成後,B primary shard響應 coordinate node, 最後協調節點響應客戶端結果
- 路由演算法,揭開primary_shard數量不可變的面紗
shard = hash(routing) % number_of_primary_shards其實這個公式並不複雜,可以將上面的routing當成doc的id,無論是用戶執行的還是自動生成的,反正肯定是唯一,既然是唯一的經過每次hash得到的結果也是一樣的, 這樣一個唯一的數對主分片的數進行取餘數,得到的結果就會在0-最大分片數之間
可以手動指定routing value的值,比如PUT /index/type/id?routing=user_id ,在保證這類doc一定被路由到指定的shard上,而且後續進行應用級負載均衡時會批量提升讀取的性能
寫一致性及原理
我們在發送任何一個增刪改查時,都可以帶上一個 consistency 參數,指明我們想要的寫一致性是什麼,如下
PUT /index/type/id?consistency=quorum有哪些可選參數呢?
- one: 當我們進行寫操作時,只要存在一個primary_shard=active 就能寫入成功
- all: cluster中全部shard都為active時,可以寫入成功
- quorum: 意味:法定的,也是ES的默認值, 要求大部分的replica_shard存活時系統才可用
quorum數量的計算公式: int((primary+number_of_replicas)/2)+1, 算一算,假如我們的集群中存在三個node,replica=1,那麼cluster中就存在3+3*1=6個shard
int((3+1)/2)+1 = 3
結果顯示,我們只有當quorum=3,即replica_shard=3時,集群才是可用的,但是當我們的單機部署時,由於ES不允許同一個server的primary_shard和replica_shard共存,也就是說我們的replica數目為0,為什麼ES依然可以用呢? 這是ES提供了一種特殊的處理場景,即當number_of_replicas>1時才會生效
quorum不全時,集群進入wait()狀態, 默認1分鐘,,在等待期間,期望活躍的shard的數量可以增加,到最後都沒有滿足這個數量的話就會timeout
我們在寫入時也可以使用timeout參數, 比如: PUT /index/type/id?timeout=30通過自己設置超時時間來縮短超時時間
運行流程
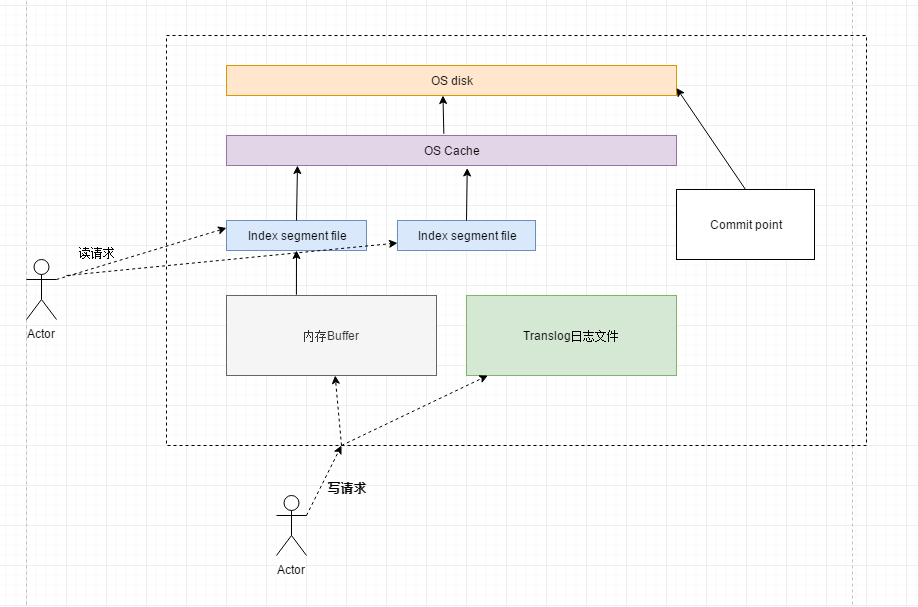
ES的底層運行流程探秘:
用戶的寫請求將doc寫入記憶體緩衝區,寫的動作被記錄在translog日誌文件中,每隔一秒中記憶體中的數據就會被刷新到index segment file中,index segment file中的數據隨機被刷新到os cache中,然後index segement file處理打開狀態,對外提供檢索服務,ES會重複這個過程,每次重複這個過程時,都會先清空記憶體buffer,處理打開狀態的 index segment file可以對外提供檢索
直到translog日誌文件體積太大了,就會進一步觸發flush操作,這個flush操作會將buffer中全部數據刷新進新的segment file中,將index segment file刷新進os cache, 寫一個commit point 到磁碟上,標註有哪些index segment,並將OS cache中的數據刷新到OS Disk中,完成數據的持久化
上面的flush動作,默認每隔30分鐘執行一次,或者當translog文件體積過大時也會自動flush
數據恢復時,是基於translog文件和commit point兩者判斷,究竟哪些數據在日誌中存在記錄,卻沒有被持久化到OSDisk中,重新執行日誌中的邏輯,等待下一次的flush完成持久化
merge segment file
看上面的圖中,為了實現近實時的搜索,每1秒鐘就會產生一個segment文件,文件數目會特別多,而恰巧對外提供搜索的就是這些segment文件,因此ES會在後台進行segement 文件的合併,在合併的時候,被標記deleted的docment會會被徹底的物理刪除
每次merge的操作流程
- 選擇大小相似的segment文件,merge成一個大的segement文件
- 將新的segment文件flush到磁碟上去
- 寫一個新的commit point,包括了新的segement,然後排除那些就的segment
- 將新的segment打開提供搜索
- 將舊的segement刪除