mybatis 源碼分析(三)Executor 詳解
- 2019 年 10 月 3 日
- 筆記
本文將主要介紹 Executor 的整體結構和各子類的功能,並對比效率;
一、Executor 主體結構
1. 類結構
executor 的類結構如圖所示:
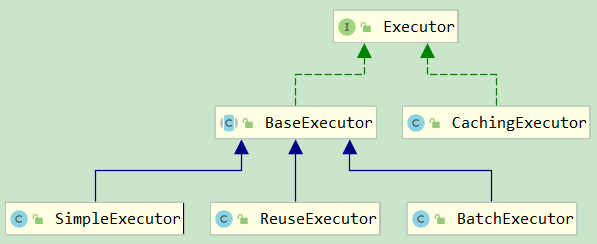

其各自的功能:
- BaseExecutor:基礎執行器,封裝了子類的公共方法,包括一級快取、延遲載入、回滾、關閉等功能;
- SimpleExecutor:簡單執行器,每執行一條 sql,都會打開一個 Statement,執行完成後關閉;
- ReuseExecutor:重用執行器,相較於 SimpleExecutor 多了 Statement 的快取功能,其內部維護一個
Map<String, Statement>,每次編譯完成的 Statement 都會進行快取,不會關閉; - BatchExecutor:批量執行器,基於 JDBC 的
addBatch、executeBatch功能,並且在當前 sql 和上一條 sql 完全一樣的時候,重用 Statement,在調用doFlushStatements的時候,將數據刷新到資料庫; - CachingExecutor:快取執行器,裝飾器模式,在開啟二級快取的時候。會在上面三種執行器的外麵包上 CachingExecutor;
2. Executor 的生命周期
初始化:
// DefaultSqlSessionFactory private SqlSession openSessionFromDataSource(ExecutorType execType, TransactionIsolationLevel level, boolean autoCommit) { Transaction tx = null; try { final Environment environment = configuration.getEnvironment(); final TransactionFactory transactionFactory = getTransactionFactoryFromEnvironment(environment); tx = transactionFactory.newTransaction(environment.getDataSource(), level, autoCommit); final Executor executor = configuration.newExecutor(tx, execType); return new DefaultSqlSession(configuration, executor, autoCommit); } catch (Exception e) { closeTransaction(tx); // may have fetched a connection so lets call close() throw ExceptionFactory.wrapException("Error opening session. Cause: " + e, e); } finally { ErrorContext.instance().reset(); } }關閉:
public void close() { try { executor.close(isCommitOrRollbackRequired(false)); dirty = false; } finally { ErrorContext.instance().reset(); } }所以 Executor 的生命周期和 SqlSession 是一樣的,之所以要明確的指出這一點是因為 Executor 中包含了快取的處理,並且因為 SqlSession 是執行緒不安全的,所以在使用 Executor 一級快取的時候,就很容易發生臟讀;後面還會通過具體示例演示;
3. query 方法
@Override public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException { BoundSql boundSql = ms.getBoundSql(parameter); //獲取綁定的sql CacheKey key = createCacheKey(ms, parameter, rowBounds, boundSql); // hash(mappedStementId + offset + limit + sql + queryParams + environment) return query(ms, parameter, rowBounds, resultHandler, key, boundSql); } @SuppressWarnings("unchecked") @Override public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException { ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId()); if (closed) { throw new ExecutorException("Executor was closed."); } // 查詢的時候一般不清楚快取,但是可以通過 xml配置或者註解強制清除,queryStack == 0 是為了防止遞歸調用 if (queryStack == 0 && ms.isFlushCacheRequired()) { clearLocalCache(); } List<E> list; try { queryStack++; // 首先查看一級快取 list = resultHandler == null ? (List<E>) localCache.getObject(key) : null; if (list != null) { handleLocallyCachedOutputParameters(ms, key, parameter, boundSql); } else { // 沒有查到的時候直接到資料庫查找 list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql); } } finally { queryStack--; } if (queryStack == 0) { // 延遲載入隊列 for (DeferredLoad deferredLoad : deferredLoads) { deferredLoad.load(); } deferredLoads.clear(); if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) { // 一級快取本身不能關閉,但是可以設置作用範圍 STATEMENT,每次都清除快取 clearLocalCache(); } } return list; } 4. update 方法
@Override public int update(MappedStatement ms, Object parameter) throws SQLException { ErrorContext.instance().resource(ms.getResource()).activity("executing an update").object(ms.getId()); if (closed) { throw new ExecutorException("Executor was closed."); } // update|insert|delete 方法首先會清除一級快取 clearLocalCache(); return doUpdate(ms, parameter); }5. 模版方法
protected abstract int doUpdate(MappedStatement ms, Object parameter) throws SQLException; protected abstract List<BatchResult> doFlushStatements(boolean isRollback) throws SQLException; //query-->queryFromDatabase-->doQuery protected abstract <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException;這裡就是一個典型的模版模式了,子類都會實現自己模版方法;
二、BaseExecutor 子類
1. SimpleExecutor
@Override public int doUpdate(MappedStatement ms, Object parameter) throws SQLException { Statement stmt = null; try { Configuration configuration = ms.getConfiguration(); StatementHandler handler = configuration.newStatementHandler(this, ms, parameter, RowBounds.DEFAULT, null, null); stmt = prepareStatement(handler, ms.getStatementLog()); return handler.update(stmt); } finally { closeStatement(stmt); } } @Override public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException { Statement stmt = null; try { Configuration configuration = ms.getConfiguration(); StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql); stmt = prepareStatement(handler, ms.getStatementLog()); return handler.<E>query(stmt, resultHandler); } finally { closeStatement(stmt); } }從上面的程式碼也可以看到 SimpleExecutor 非常的簡單,每次打開一個 Statement,使用完成以後關閉;
2. ReuseExecutor
private final Map<String, Statement> statementMap = new HashMap<String, Statement>(); // Statement 快取 private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException { Statement stmt; BoundSql boundSql = handler.getBoundSql(); // 獲取綁定的sql String sql = boundSql.getSql(); if (hasStatementFor(sql)) { // 如果快取中已經有了,直接得到Statement stmt = getStatement(sql); } else { // 如果快取沒有,就編譯一個然後加入快取 Connection connection = getConnection(statementLog); stmt = handler.prepare(connection); putStatement(sql, stmt); } handler.parameterize(stmt); return stmt; } ReuseExecutor 就比 SimpleExecutor 多了一個 Statement 的快取功能,其他的都是一樣的;
3. BatchExecutor
首先需要明確一點 BachExecutor 是基於 JDBC 的 addBatch、executeBatch 功能的執行器,所以 BachExecutor 只能用於更新(insert|delete|update),不能用於查詢(select),下面是一個 JDBC 的小 demo:
String url = "jdbc:mysql://localhost:3306/mybatis?serverTimezone=GMT"; String sql = "INSERT INTO user(username,password,address) VALUES (?,?,?)"; Class.forName("com.mysql.jdbc.Driver"); Connection conn = DriverManager.getConnection(url, "root", "root"); PreparedStatement stmt = conn.prepareStatement(sql); for (int i = 0; i < 4000; i++) { stmt.setString(1, "test" + i); stmt.setString(2, "123456"); stmt.setString(3, "test"); stmt.addBatch(); } stmt.executeBatch();下面從源碼來看一下 mybatis 是如何實現的:
private final List<Statement> statementList = new ArrayList<Statement>(); // 待處理的 Statement private final List<BatchResult> batchResultList = new ArrayList<BatchResult>(); // 對應的結果集 private String currentSql; // 上一次執行 sql private MappedStatement currentStatement; // 上次執行的 MappedStatement @Override public int doUpdate(MappedStatement ms, Object parameterObject) throws SQLException { final Configuration configuration = ms.getConfiguration(); final StatementHandler handler = configuration.newStatementHandler(this, ms, parameterObject, RowBounds.DEFAULT, null, null); final BoundSql boundSql = handler.getBoundSql(); final String sql = boundSql.getSql(); // 本次執行的 sql final Statement stmt; // 當本次執行的 sql 和 MappedStatement 與上次的相同時,直接復用上一次的 Statement if (sql.equals(currentSql) && ms.equals(currentStatement)) { int last = statementList.size() - 1; stmt = statementList.get(last); BatchResult batchResult = batchResultList.get(last); batchResult.addParameterObject(parameterObject); } else { // 不同時,新建 Statement,並加入快取 Connection connection = getConnection(ms.getStatementLog()); stmt = handler.prepare(connection); currentSql = sql; currentStatement = ms; statementList.add(stmt); batchResultList.add(new BatchResult(ms, sql, parameterObject)); } handler.parameterize(stmt); handler.batch(stmt); // 添加批處理任務 return BATCH_UPDATE_RETURN_VALUE; // 注意這裡返回的不再是更新的行數,而是一個常量 }BatchExecutor 的批處理添加過程相當於添加了一個沒有返回值的非同步任務,那麼在什麼時候執行非同步任務,將數據更新到資料庫呢,答案是處理 update 的任何操作,包括 select、commit、close等任何操作,具體執行的方法就是 doFlushStatements;此外需要注意的是 Batch 方式插入使用 useGeneratedKeys 獲取主鍵,在提交完任務之後,並不能馬上取到,因為此時 sql 語句還在快取中沒有真正執行,當執行完 Flush 之後,會通過回調的方式反射設置主鍵;
三、效率對比
幾種執行器效率對比
| batch | Reuser | simple | foreach | foreach100 | |
|---|---|---|---|---|---|
| 100 | 369 | 148 | 151 | 68 | 70 |
| 1000 | 485 | 735 | 911 | 679 | 148 |
| 10000 | 2745 | 4064 | 4666 | 38607 | 1002 |
| 50000 | 8838 | 17788 | 19907 | 796444 | 3703 |
從上面的結果對比可以看到:
- 整體而言 reuser 比 simple 多了快取功能,所以無論批處理的大小,其效率都要高一些;
- 此外在批處理量小的時候使用 foreach,效果還是可以的,但是當批量交大時,sql 編譯的時間就大大增加了,當 foreach 固定批大小 + reuser 時,每次的 Statement 就可以重用,從表中也可以看到效率也時最高的;
- batch 的優點則是所有的更新語句都能用;
- 所以在配置的時候建議默認使用 reuser,而使用 foreach 和 batch 需要根據具體場景分析,如果更新比較多的時候,可以在批量更新的時候單獨指定 ExecutorType.BATCH,如果批量插入很多的時候,可以固定批大小;

