深入理解Kafka必知必會(上)
- 2019 年 11 月 7 日
- 筆記
Kafka的用途有哪些?使用場景如何?
-
消息系統: Kafka 和傳統的消息系統(也稱作消息中間件)都具備系統解耦、冗餘存儲、流量削峰、緩衝、非同步通訊、擴展性、可恢復性等功能。與此同時,Kafka 還提供了大多數消息系統難以實現的消息順序性保障及回溯消費的功能。
-
存儲系統: Kafka 把消息持久化到磁碟,相比於其他基於記憶體存儲的系統而言,有效地降低了數據丟失的風險。也正是得益於 Kafka 的消息持久化功能和多副本機制,我們可以把 Kafka 作為長期的數據存儲系統來使用,只需要把對應的數據保留策略設置為「永久」或啟用主題的日誌壓縮功能即可。
-
流式處理平台: Kafka 不僅為每個流行的流式處理框架提供了可靠的數據來源,還提供了一個完整的流式處理類庫,比如窗口、連接、變換和聚合等各類操作。
Kafka中的ISR、AR又代表什麼?ISR的伸縮又指什麼
分區中的所有副本統稱為 AR(Assigned Replicas)。所有與 leader 副本保持一定程度同步的副本(包括 leader 副本在內)組成ISR(In-Sync Replicas),ISR 集合是 AR 集合中的一個子集。
ISR的伸縮:
leader 副本負責維護和跟蹤 ISR 集合中所有 follower 副本的滯後狀態,當 follower 副本落後太多或失效時,leader 副本會把它從 ISR 集合中剔除。如果 OSR 集合中有 follower 副本「追上」了 leader 副本,那麼 leader 副本會把它從 OSR 集合轉移至 ISR 集合。默認情況下,當 leader 副本發生故障時,只有在 ISR 集合中的副本才有資格被選舉為新的 leader,而在 OSR 集合中的副本則沒有任何機會(不過這個原則也可以通過修改相應的參數配置來改變)。
replica.lag.time.max.ms : 這個參數的含義是 Follower 副本能夠落後 Leader 副本的最長時間間隔,當前默認值是 10 秒。
unclean.leader.election.enable:是否允許 Unclean 領導者選舉。開啟 Unclean 領導者選舉可能會造成數據丟失,但好處是,它使得分區 Leader 副本一直存在,不至於停止對外提供服務,因此提升了高可用性。
Kafka中的HW、LEO、LSO、LW等分別代表什麼?
HW 是 High Watermark 的縮寫,俗稱高水位,它標識了一個特定的消息偏移量(offset),消費者只能拉取到這個 offset 之前的消息。
LSO是LogStartOffset,一般情況下,日誌文件的起始偏移量 logStartOffset 等於第一個日誌分段的 baseOffset,但這並不是絕對的,logStartOffset 的值可以通過 DeleteRecordsRequest 請求(比如使用 KafkaAdminClient 的 deleteRecords()方法、使用 kafka-delete-records.sh 腳本、日誌的清理和截斷等操作進行修改。
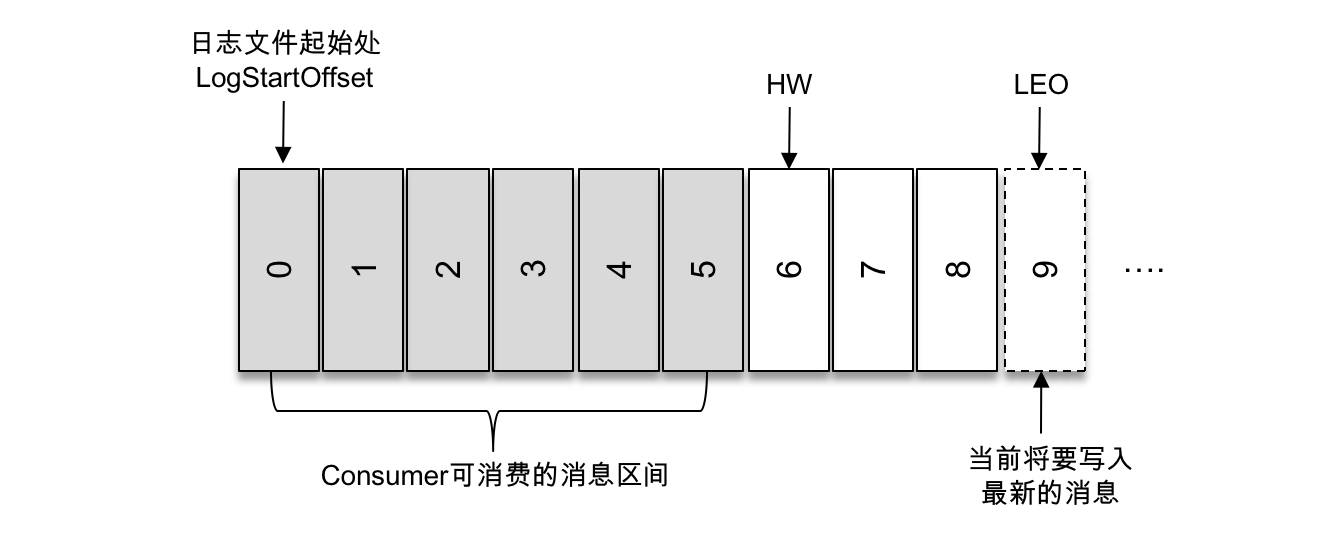
如上圖所示,它代表一個日誌文件,這個日誌文件中有9條消息,第一條消息的 offset(LogStartOffset)為0,最後一條消息的 offset 為8,offset 為9的消息用虛線框表示,代表下一條待寫入的消息。日誌文件的 HW 為6,表示消費者只能拉取到 offset 在0至5之間的消息,而 offset 為6的消息對消費者而言是不可見的。
LEO 是 Log End Offset 的縮寫,它標識當前日誌文件中下一條待寫入消息的 offset,上圖中 offset 為9的位置即為當前日誌文件的 LEO,LEO 的大小相當於當前日誌分區中最後一條消息的 offset 值加1。分區 ISR 集合中的每個副本都會維護自身的 LEO,而 ISR 集合中最小的 LEO 即為分區的 HW,對消費者而言只能消費 HW 之前的消息。
LW 是 Low Watermark 的縮寫,俗稱「低水位」,代表 AR 集合中最小的 logStartOffset 值。副本的拉取請求(FetchRequest,它有可能觸發新建日誌分段而舊的被清理,進而導致 logStartOffset 的增加)和刪除消息請求(DeleteRecordRequest)都有可能促使 LW 的增長。
Kafka中是怎麼體現消息順序性的?
可以通過分區策略體現消息順序性。
分區策略有輪詢策略、隨機策略、按消息鍵保序策略。
按消息鍵保序策略:一旦消息被定義了 Key,那麼你就可以保證同一個 Key 的所有消息都進入到相同的分區裡面,由於每個分區下的消息處理都是有順序的,故這個策略被稱為按消息鍵保序策略
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic); return Math.abs(key.hashCode()) % partitions.size();Kafka中的分區器、序列化器、攔截器是否了解?它們之間的處理順序是什麼?
- 序列化器:生產者需要用序列化器(Serializer)把對象轉換成位元組數組才能通過網路發送給 Kafka。而在對側,消費者需要用反序列化器(Deserializer)把從 Kafka 中收到的位元組數組轉換成相應的對象。
- 分區器:分區器的作用就是為消息分配分區。如果消息 ProducerRecord 中沒有指定 partition 欄位,那麼就需要依賴分區器,根據 key 這個欄位來計算 partition 的值。
- Kafka 一共有兩種攔截器:生產者攔截器和消費者攔截器。
- 生產者攔截器既可以用來在消息發送前做一些準備工作,比如按照某個規則過濾不符合要求的消息、修改消息的內容等,也可以用來在發送回調邏輯前做一些訂製化的需求,比如統計類工作。
- 消費者攔截器主要在消費到消息或在提交消費位移時進行一些訂製化的操作。
消息在通過 send() 方法發往 broker 的過程中,有可能需要經過攔截器(Interceptor)、序列化器(Serializer)和分區器(Partitioner)的一系列作用之後才能被真正地發往 broker。攔截器(下一章會詳細介紹)一般不是必需的,而序列化器是必需的。消息經過序列化之後就需要確定它發往的分區,如果消息 ProducerRecord 中指定了 partition 欄位,那麼就不需要分區器的作用,因為 partition 代表的就是所要發往的分區號。
處理順序 :攔截器->序列化器->分區器
KafkaProducer 在將消息序列化和計算分區之前會調用生產者攔截器的 onSend() 方法來對消息進行相應的訂製化操作。
然後生產者需要用序列化器(Serializer)把對象轉換成位元組數組才能通過網路發送給 Kafka。
最後可能會被發往分區器為消息分配分區。
Kafka生產者客戶端的整體結構是什麼樣子的?

整個生產者客戶端由兩個執行緒協調運行,這兩個執行緒分別為主執行緒和 Sender 執行緒(發送執行緒)。
在主執行緒中由 KafkaProducer 創建消息,然後通過可能的攔截器、序列化器和分區器的作用之後快取到消息累加器(RecordAccumulator,也稱為消息收集器)中。
Sender 執行緒負責從 RecordAccumulator 中獲取消息並將其發送到 Kafka 中。
RecordAccumulator 主要用來快取消息以便 Sender 執行緒可以批量發送,進而減少網路傳輸的資源消耗以提升性能。
Kafka生產者客戶端中使用了幾個執行緒來處理?分別是什麼?
整個生產者客戶端由兩個執行緒協調運行,這兩個執行緒分別為主執行緒和 Sender 執行緒(發送執行緒)。在主執行緒中由 KafkaProducer 創建消息,然後通過可能的攔截器、序列化器和分區器的作用之後快取到消息累加器(RecordAccumulator,也稱為消息收集器)中。Sender 執行緒負責從 RecordAccumulator 中獲取消息並將其發送到 Kafka 中。
Kafka的舊版Scala的消費者客戶端的設計有什麼缺陷?
老版本的 Consumer Group 把位移保存在 ZooKeeper 中。Apache ZooKeeper 是一個分散式的協調服務框架,Kafka 重度依賴它實現各種各樣的協調管理。將位移保存在 ZooKeeper 外部系統的做法,最顯而易見的好處就是減少了 Kafka Broker 端的狀態保存開銷。
ZooKeeper 這類元框架其實並不適合進行頻繁的寫更新,而 Consumer Group 的位移更新卻是一個非常頻繁的操作。這種大吞吐量的寫操作會極大地拖慢 ZooKeeper 集群的性能
「消費組中的消費者個數如果超過topic的分區,那麼就會有消費者消費不到數據」這句話是否正確?如果正確,那麼有沒有什麼hack的手段?
一般來說如果消費者過多,出現了消費者的個數大於分區個數的情況,就會有消費者分配不到任何分區。
開發者可以繼承AbstractPartitionAssignor實現自定義消費策略,從而實現同一消費組內的任意消費者都可以消費訂閱主題的所有分區:
public class BroadcastAssignor extends AbstractPartitionAssignor{ @Override public String name() { return "broadcast"; } private Map<String, List<String>> consumersPerTopic( Map<String, Subscription> consumerMetadata) { (具體實現請參考RandomAssignor中的consumersPerTopic()方法) } @Override public Map<String, List<TopicPartition>> assign( Map<String, Integer> partitionsPerTopic, Map<String, Subscription> subscriptions) { Map<String, List<String>> consumersPerTopic = consumersPerTopic(subscriptions); Map<String, List<TopicPartition>> assignment = new HashMap<>(); //Java8 subscriptions.keySet().forEach(memberId -> assignment.put(memberId, new ArrayList<>())); //針對每一個主題,為每一個訂閱的消費者分配所有的分區 consumersPerTopic.entrySet().forEach(topicEntry->{ String topic = topicEntry.getKey(); List<String> members = topicEntry.getValue(); Integer numPartitionsForTopic = partitionsPerTopic.get(topic); if (numPartitionsForTopic == null || members.isEmpty()) return; List<TopicPartition> partitions = AbstractPartitionAssignor .partitions(topic, numPartitionsForTopic); if (!partitions.isEmpty()) { members.forEach(memberId -> assignment.get(memberId).addAll(partitions)); } }); return assignment; } }注意組內廣播的這種實現方式會有一個嚴重的問題—默認的消費位移的提交會失效。
消費者提交消費位移時提交的是當前消費到的最新消息的offset還是offset+1?
在舊消費者客戶端中,消費位移是存儲在 ZooKeeper 中的。而在新消費者客戶端中,消費位移存儲在 Kafka 內部的主題__consumer_offsets 中。
當前消費者需要提交的消費位移是offset+1
有哪些情形會造成重複消費?
- Rebalance
一個consumer正在消費一個分區的一條消息,還沒有消費完,發生了rebalance(加入了一個consumer),從而導致這條消息沒有消費成功,rebalance後,另一個consumer又把這條消息消費一遍。 - 消費者端手動提交
如果先消費消息,再更新offset位置,導致消息重複消費。 - 消費者端自動提交
設置offset為自動提交,關閉kafka時,如果在close之前,調用 consumer.unsubscribe() 則有可能部分offset沒提交,下次重啟會重複消費。 - 生產者端
生產者因為業務問題導致的宕機,在重啟之後可能數據會重發
那些情景下會造成消息漏消費?
- 自動提交
設置offset為自動定時提交,當offset被自動定時提交時,數據還在記憶體中未處理,此時剛好把執行緒kill掉,那麼offset已經提交,但是數據未處理,導致這部分記憶體中的數據丟失。 - 生產者發送消息
發送消息設置的是fire-and-forget(發後即忘),它只管往 Kafka 中發送消息而並不關心消息是否正確到達。不過在某些時候(比如發生不可重試異常時)會造成消息的丟失。這種發送方式的性能最高,可靠性也最差。 - 消費者端
先提交位移,但是消息還沒消費完就宕機了,造成了消息沒有被消費。自動位移提交同理 - acks沒有設置為all
如果在broker還沒把消息同步到其他broker的時候宕機了,那麼消息將會丟失
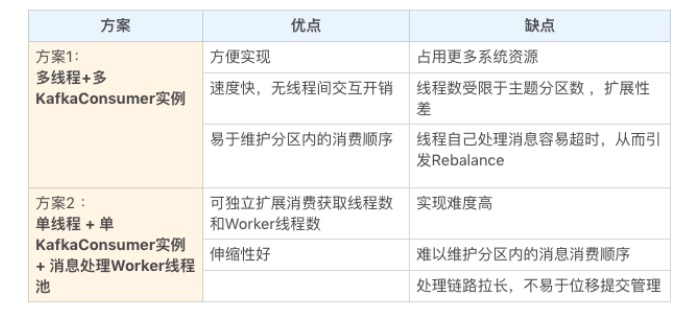
KafkaConsumer是非執行緒安全的,那麼怎麼樣實現多執行緒消費?
- 執行緒封閉,即為每個執行緒實例化一個 KafkaConsumer 對象
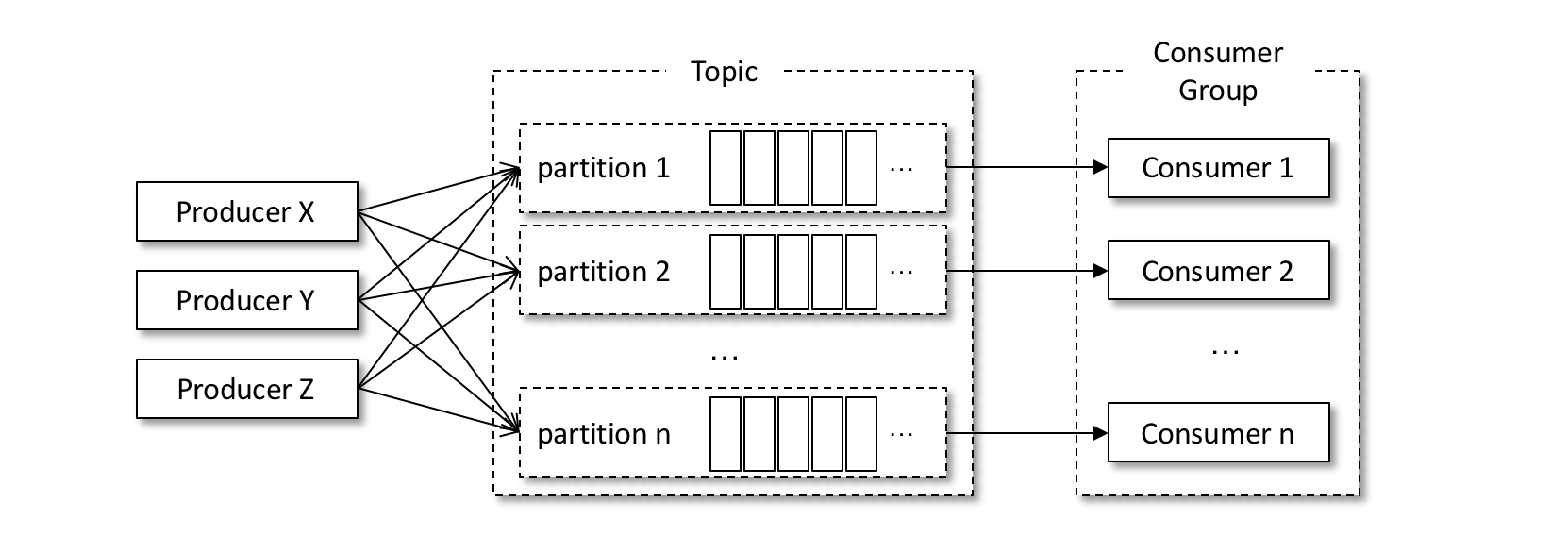
一個執行緒對應一個 KafkaConsumer 實例,我們可以稱之為消費執行緒。一個消費執行緒可以消費一個或多個分區中的消息,所有的消費執行緒都隸屬於同一個消費組。
- 消費者程式使用單或多執行緒獲取消息,同時創建多個消費執行緒執行消息處理邏輯。
獲取消息的執行緒可以是一個,也可以是多個,每個執行緒維護專屬的 KafkaConsumer 實例,處理消息則交由特定的執行緒池來做,從而實現消息獲取與消息處理的真正解耦。具體架構如下圖所示:
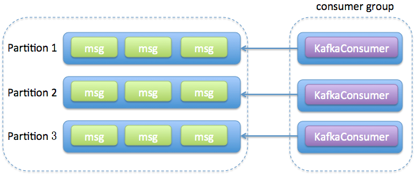
兩個方案對比:
簡述消費者與消費組之間的關係
- Consumer Group 下可以有一個或多個 Consumer 實例。這裡的實例可以是一個單獨的進程,也可以是同一進程下的執行緒。在實際場景中,使用進程更為常見一些。
- Group ID 是一個字元串,在一個 Kafka 集群中,它標識唯一的一個 Consumer Group。
- Consumer Group 下所有實例訂閱的主題的單個分區,只能分配給組內的某個 Consumer 實例消費。這個分區當然也可以被其他的 Group 消費。
當你使用kafka-topics.sh創建(刪除)了一個topic之後,Kafka背後會執行什麼邏輯?
在執行完腳本之後,Kafka 會在 log.dir 或 log.dirs 參數所配置的目錄下創建相應的主題分區,默認情況下這個目錄為/tmp/kafka-logs/。
在 ZooKeeper 的/brokers/topics/目錄下創建一個同名的實節點,該節點中記錄了該主題的分區副本分配方案。示例如下:
[zk: localhost:2181/kafka(CONNECTED) 2] get /brokers/topics/topic-create {"version":1,"partitions":{"2":[1,2],"1":[0,1],"3":[2,1],"0":[2,0]}}topic的分區數可不可以增加?如果可以怎麼增加?如果不可以,那又是為什麼?
可以增加,使用 kafka-topics 腳本,結合 –alter 參數來增加某個主題的分區數,命令如下:
bin/kafka-topics.sh --bootstrap-server broker_host:port --alter --topic <topic_name> --partitions <新分區數>當分區數增加時,就會觸發訂閱該主題的所有 Group 開啟 Rebalance。
首先,Rebalance 過程對 Consumer Group 消費過程有極大的影響。在 Rebalance 過程中,所有 Consumer 實例都會停止消費,等待 Rebalance 完成。這是 Rebalance 為人詬病的一個方面。
其次,目前 Rebalance 的設計是所有 Consumer 實例共同參與,全部重新分配所有分區。其實更高效的做法是盡量減少分配方案的變動。
最後,Rebalance 實在是太慢了。
topic的分區數可不可以減少?如果可以怎麼減少?如果不可以,那又是為什麼?
不支援,因為刪除的分區中的消息不好處理。如果直接存儲到現有分區的尾部,消息的時間戳就不會遞增,如此對於 Spark、Flink 這類需要消息時間戳(事件時間)的組件將會受到影響;如果分散插入現有的分區,那麼在消息量很大的時候,內部的數據複製會佔用很大的資源,而且在複製期間,此主題的可用性又如何得到保障?與此同時,順序性問題、事務性問題,以及分區和副本的狀態機切換問題都是不得不面對的。
創建topic時如何選擇合適的分區數?
在 Kafka 中,性能與分區數有著必然的關係,在設定分區數時一般也需要考慮性能的因素。對不同的硬體而言,其對應的性能也會不太一樣。
可以使用Kafka 本身提供的用於生產者性能測試的 kafka-producer- perf-test.sh 和用於消費者性能測試的 kafka-consumer-perf-test.sh來進行測試。
增加合適的分區數可以在一定程度上提升整體吞吐量,但超過對應的閾值之後吞吐量不升反降。如果應用對吞吐量有一定程度上的要求,則建議在投入生產環境之前對同款硬體資源做一個完備的吞吐量相關的測試,以找到合適的分區數閾值區間。
分區數的多少還會影響系統的可用性。如果分區數非常多,如果集群中的某個 broker 節點宕機,那麼就會有大量的分區需要同時進行 leader 角色切換,這個切換的過程會耗費一筆可觀的時間,並且在這個時間窗口內這些分區也會變得不可用。
分區數越多也會讓 Kafka 的正常啟動和關閉的耗時變得越長,與此同時,主題的分區數越多不僅會增加日誌清理的耗時,而且在被刪除時也會耗費更多的時間。