數據結構與演算法:查找演算法
查找演算法
查找( Search)是指從一批記錄中找出滿足指定條件的某一記錄的過程,查找又稱為檢索。查找演算法廣泛應用於各類應用程式中。因此,一個有效的查找演算法往往可以大大提高程式的執行效率。在實際應用中,數據的類型千變萬化,每條數據項往往包含多個數據域。但是,在執行查找操作時,往往只是指定一個或幾個域的值,這些作為查找條件的域稱為關鍵字(Key),關鍵字分為兩類。
在實際應用中,針對不同的情況往往可以選擇不同的查找演算法。對於無順序的數據,只有逐個比較數據,才能找到需要的內容,這種方法稱為順序查找。對於有順序的數據,也可以採用順序查找法逐個比較,但也可以採取其他更快速的方法找到所需數據。另外,對於一些特殊的數據結構,例如鏈表、樹結構和圖結構等,也都有相對應的合適的查找演算法。
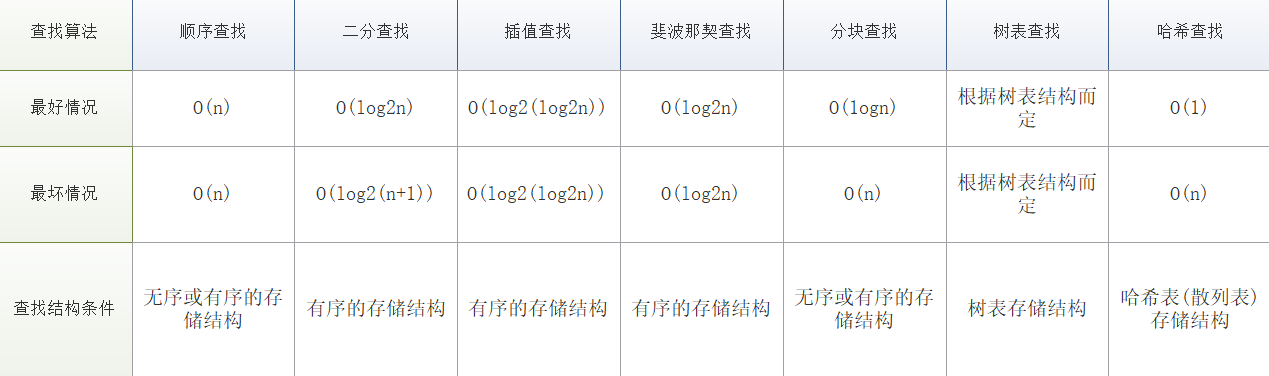
常見七大查找演算法:
-
順序查找 2. 二分查找 3. 插值查找 4. 斐波那契查找 5. 分塊查找
-
哈希查找(涉及哈希表結構) 7. 樹表查找(涉及樹表結構)
1. 順序查找
線性查找又稱順序查找,是一種最簡單的查找方法,它的基本思想是從第一個記錄開始,逐個比較記錄的關鍵字,直到和給定的K值相等,則查找成功;若比較結果與文件中n個記錄的關鍵字都不等,則查找失敗。
程式碼實現
/** * 順序查找 * @param array 查找的數組 * @param value 查找的值 * @return 數組內有和查找值匹配的值則返回數組內匹配值的下標,反之則返回-1 */ public static int orderSearch(int[] array, int value){ //遍曆數組中的所有數據,當有能和value匹配的數據時,返回該數據的數組下標 for (int i=0; i<array.length; i++){ if (array[i] == value){ return i; } } //當數組中沒有能和value匹配的數據時,返回-1 return -1; }
2. 二分查找
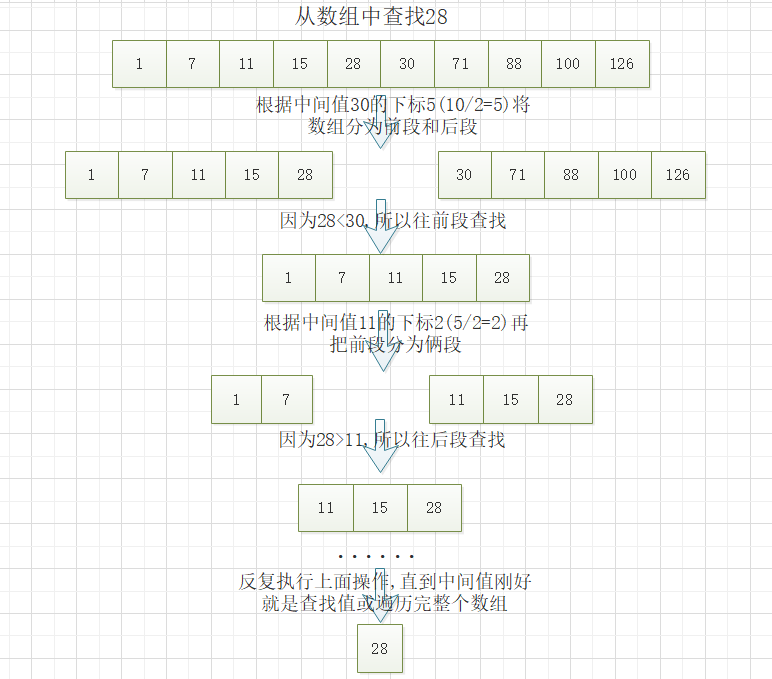
二分查找也稱折半查找(Binary Search),它是一種效率較高的查找方法。但是,折半查找要求線性表必須採用順序存儲結構,而且表中元素按關鍵字有序排列。
二分查找的操作就像它的名字一樣,根據中間值將一個存儲結構一分為二,分為前段和後段,因為規定了儲存結構必須按關鍵字有序排序,所以只需將傳入的查找值與中間值進行比較,根據比較結果再判斷是往前段查找還是往後段查找,反覆執行前面的操作,直到查找到傳入的值或查找完整個儲存結構。
/** * 二分查找(查找的數組必須是有序數組) * @param array 查找的數組 * @param left 中間值的左標(該次遞歸操作數組段的最左端下標) * @param right 中間值的右標(該次遞歸操作數組段的最右端下標) * @param findValue 查找的值 * @return 數組內有和查找值匹配的值則返回數組內匹配值的下標,反之則返回-1 */ public static int binarySearch(int[] array, int left, int right, int findValue){ if (left > right){//判斷是否已經查找到盡頭 return -1; } int mid = (left + right)/2;//取中間值下標 if (findValue > array[mid]){//如果findValue>array[mid] 則從中間值向右遞歸 return binarySearch(array, findValue, mid+1, right); }else if (findValue < array[mid]){//如果findValue<array[mid] 則從中間值向左遞歸 return binarySearch(array, findValue, left, mid); }else {//findValue==array[mid]時,則匹配成功,返回mid下標 return mid; } }
插值查找,有序表的一種查找方式。插值查找是根據查找關鍵字與查找表中最大最小記錄關鍵字比較後的查找方法。插值查找基於二分查找,將查找點的選擇改進為自適應選擇,提高查找效率。插值類似於平常查英文字典的方法,在查一個以字母C開頭的英文單詞時,決不會用二分查找,從字典的中間一頁開始,因為知道它的大概位置是在字典的較前面的部分,因此可以從前面的某處查起,這就是插值查找的基本思想。
插值查找除要求查找表是順序存儲的有序表外,還要求數據元素的關鍵字在查找表中均勻分布,這樣,就可以按比例插值。

mid:查找數組段內的中間值
key:查找的值
low:查找數組段內最小值的下標,即查找數組段內最左下標left
high:查找數組段內最大值的下標,即查找數組段內最右下標right
程式碼實現
/** * 插值查找(查找的數組必須是有序數組) * @param array 查找的數組 * @param left 查找段的最小值索引下標,即查找段內最左下標 * @param right 查找段的最大值索引下標,即查找段內最右下標 * @param findValue 查找的值 * @return 數組內有和查找值匹配的值則返回數組內匹配值的下標,反之則返回-1 */ public static int insertSearch(int array[], int left, int right, int findValue){ //當左標left大於右標right時,即查找已經遍歷到數組的盡頭,則返回-1 //當查找值findValue小於數組內最小值或大於數組內最大值時,即數組內沒有能匹配的值,則返回-1 if (left>right || findValue<array[0] || findValue>array[array.length-1]){ return -1; } //使用插值公式求出中間值位置下標 int mid = left + (right-left) * (findValue-array[left]) / (array[right]-array[left]); if (findValue < array[mid]){//當查找值小於中間中間值時,向左遞歸查找 return insertSearch(array, left, mid-1, findValue); }else if (findValue > array[mid]){//當查找值大於中間值時,向右遞歸查找 return insertSearch(array, mid+1, right, findValue); }else {//當查找值等於中間值時,則返回中間值下標 return mid; } }
斐波那契查找就是在二分查找的基礎上根據斐波那契數列進行分割的。在斐波那契數列找一個等於略大於查找表中元素個數的數f[n],將原查找表擴展為長度為f[n],完成後進行斐波那契分割,即f[n]個元素分割為前半部分f[n-1]個元素,後半部分f[n-2]個元素,找出要查找的元素在那一部分並遞歸,直到找到。
黃金分割:在介紹斐波那契查找演算法之前,先了解根它緊密相連的一個概念——黃金分割。黃金比例又稱黃金分割,是指事物各部分間一定的數學比例關係,即將整體一分為二,較大部分與較小部分之比等於整體與較大部分之比,其比值約為1:0.618或1.618:1。0.618被公認為最具有審美意義的比例數字,這個數值的作用不僅僅體現在諸如繪畫、雕塑、音樂、建築等藝術領域,而且在管理、工程設計等方面也有著不可忽視的作用。因此被稱為黃金分割。斐波那契數列:1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89…….(從第三個數開始,後邊每一個數都是前兩個數的和)。然後我們會發現,隨著斐波那契數列的遞增,前後兩個數的比值會越來越接近0.618,利用這個特性,我們就可以將黃金比例運用到查找技術中。
程式碼實現
/** * 斐波那契查找(查找數組必須是有序數組) * @param array 查找的數組 * @param findValue 查找的值 * @return 數組內有和查找值匹配的值則返回數組內匹配值的下標,反之則返回-1 */ public static int fibonacciSearch(int array[], int findValue){ int low = 0;//查找段的最小值索引下標,即查找段內最左下標 int high = array.length-1;//查找段的最大值索引下標,即查找段內最右下標 int mid = 0;//儲存中間值的下標 int k = 0;//斐波那契數組的下標索引 int fib[] = fib();//斐波那契數列數組 /* 獲取和查找數組最接近且大於查找數組最右下標的斐波那契數組的值,以作為新數組的長度 因為斐波那契的值fib[k]對應的是數組的長度,而右標high對應的是數組下標, 所以比較時,fib[k]的值需要-1 */ while (high > fib[k]-1){ k++; } //將查找的數組複製到新的數組,長度為前面求出的斐波那契數組值fib[k] int temp[] = Arrays.copyOf(array, fib[k]); /* 因為fib[k]不一定等於查找數組的長度,所以在最右下標high右邊, 即超出查找數組的部分,把它們的值都設為最右下標的值temp[high] */ for (int i=high+1; i<temp.length-1; i++){ temp[i] = temp[high]; } /* 在斐波那契查找中是按照斐波那契數列的黃金分割點來劃分查找數組的, 而在斐波那契數列中 fib[k] = fib[k-1]+fib[k-2], 所以可以把查找數組分成倆部分fib[k-1]和fib[k-2],因此 黃金分割點,即中間值的下標mid = low+fib[k-1]-1, 向左遞歸部分 = fib[k-1],向右遞歸部 = fib[k-2] */ while (low <= high){//判斷是否查找到盡頭 /* low:隨著向右遞歸而發生變化,使得中間值可以跟著適應 fib[k-1]-1:因為斐波那契數列數組中的值對應的是數組長度,所以需-1 */ mid = low + fib[k-1] -1; if (findValue < temp[mid]){//查找值小於中間值,向左遞歸 high = mid-1;//重新設置查找數組右標,設置新的查找段 k -=1; //因為是向左遞歸,對應的是fib[k-1],所以斐波那契數組的下標k要-1 }else if (findValue > temp[mid]){//查找值大于于中間值,向右遞歸 low = mid+1;//重新設置查找數組的左標,設置新的查找段 k -=2;//因為是向右遞歸,對應的是fib[k-2],所以斐波那契數組的下標k要-2 }else {//當查找值等於中間值時,即匹配成功 /* 因為臨時數組temp的長度可能超過原先的查找數組,而超出部分的值都等於右標位置的值, 所以當匹配成功值的下標大於右標時,要返回右標high,反之則之間返回中間值下標mid即可 */ if (mid <= high){ return mid; }else { return high; } } } //數組內無匹配成功的值,則返回-1 return -1; } //獲取斐波那契數列 public static int[] fib(){ int fib[] = new int[20]; fib[0] = 1; fib[1] = 1; for (int i=2; i<fib.length; i++){ fib[i] = fib[i-1] + fib[i-2]; } return fib; }
分塊查找是二分查找和順序查找的一種改進方法,二分查找雖然具有很好的性能,但其前提條件時線性表順序存儲而且按照關鍵碼排序,這一前提條件在結點樹很大且表元素動態變化時是難以滿足的。而順序查找可以解決表元素動態變化的要求,但查找效率很低。如果既要保持對線性表的查找具有較快的速度,又要能夠滿足表元素動態變化的要求,則可採用分塊查找的方法。
分塊查找的速度雖然不如折半查找演算法,但比順序查找演算法快得多,同時又不需要對全部節點進行排序。當節點很多且塊數很大時,對索引表可以採用折半查找,這樣能夠進一步提高查找的速度。
分塊查找由於只要求索引表是有序的,對塊內節點沒有排序要求,因此特別適合於節點動態變化的情況。當增加或減少節以及節點的關鍵碼改變時,只需將該節點調整到所在的塊即可。在空間複雜性上,分塊查找的主要代價是增加了一個輔助數組。
分塊查找操作:分塊,即把一個存儲結構分成多塊,每一塊都有一個關鍵字——該塊數據池中的最大值,和一個塊在原始存儲結構中的起始位置。將分後的各塊組合成一個索引表,儲存各塊的最大值和起始位置。通過查找值和塊中的最大值進行比較,從而縮短需要查找的原始儲存結構長度。

程式碼實現
public class BlockSearch { public static void main(String[] args) { int[] array = new int[50]; for (int i=0; i<array.length; i++){ array[i] = (int)(Math.random() * 100); } System.out.println(Arrays.toString(array)); List<Block> blockTable = createBlockTable(array); System.out.println(blockSearch(array, 10, blockTable)); } /** * 將數組分成多塊,並創建塊索引表儲存各塊的最大值和起始位置 * @param array 查找的數組 * @return 返回塊索引表 */ public static List<Block> createBlockTable(int[] array){ int nums = 10;//每塊儲存的數據數量 int start = 0;//塊的起始位置,初始為0 int maxValue = 0;//塊中的最大值 List<Block> blockTable = new ArrayList<>();//塊索引表 while (start < array.length){//判斷起始起始位置是否大於查找數組的長度 maxValue = array[start];//假定塊中的最大值為起始位置的值 //判斷剩餘的數組長度是否小於每塊儲存的初始數據量, //如果大於則的塊的長度為初始數據量,如果大於則最後一塊的長度就是剩餘的數組長度 int maxLength = (start+nums) < array.length ? (start+nums) : array.length; //遍歷塊中的元素,選出塊中的最大值 for (int i=start; i<maxLength; i++){ if (maxValue < array[i]){ maxValue = array[i]; } } //將塊中的最大值和起始位置添加進塊索引表 //注意:塊中的數據與塊的索引對於查找數組來說是有序的,即是按照查找數組的原始順序來排序的 blockTable.add(new Block(start, maxValue)); //移動到下一塊的起始位置 start += nums; } return blockTable; } /** * 分塊查找 * @param array 查找數組 * @param findValue 查找的值 * @param blockTable 塊索引表 * @return 數組內有和查找值匹配的值則返回數組內匹配值的下標,反之則返回-1 */ public static int blockSearch(int[] array, int findValue, List<Block> blockTable){ int blockIndex = 0;//塊索引表中塊的索引,按順序遍歷,初始值為0 //判斷查找值是否大於塊中的最大值,如果大於則移動到下一塊 while (blockIndex < blockTable.size() && findValue > blockTable.get(blockIndex).maxValue){ blockIndex++; } //當塊的索引大於塊索引表的大小時,即說明查找值大於查找數組中的最大值,數組中沒有查找值 if (blockIndex > blockTable.size()-1){ return -1; } //從塊的起始位置開始在查找數組中進行查找,這時查找長度比順序查找的長度縮短了start+1 for (int i=blockTable.get(blockIndex).start; i<array.length; i++){ //當從數組中匹配到查找值時,返回該匹配值在數組中的下標 if (array[i] == findValue){ return i; } } //當查找數組中無與查找值匹配的值時,返回-1 return -1; } } //塊 class Block{ int start;//起始位置 int maxValue;//塊中的最大值 public Block(int start, int maxValue) { this.start = start; this.maxValue = maxValue; } }


