AI小白必讀:深度學習、遷移學習、強化學習別再傻傻分不清
摘要:諸多關於人工智慧的流行辭彙縈繞在我們耳邊,比如深度學習 (Deep Learning)、強化學習 (Reinforcement Learning)、遷移學習 (Transfer Learning),不少人對這些高頻辭彙的含義及其背後的關係感到困惑,今天就為大家理清它們之間的關係和區別。
一. 深度學習:
深度學習的成功和發展,得益於算力的顯著提升和大數據,數字化後產生大量的數據,可通過大量的數據訓練來發現數據的規律,從而實現基於監督學習的數據預測。
基於神經網路的深度學習主要應用於影像、文本、語音等領域。
2016年的 NIPS 會議上,吳恩達給出了一個未來AI方向的技術發展圖:

監督學習(Supervised learning)是目前商用場景最多,成熟度最高的AI技術,而下一個商用的AI技術將會是遷移學習(Transfer Learning),這也是 Andrew 預測未來五年最有可能走向商用的AI技術。
二. 遷移學習:
遷移學習:用相關的、類似數據來訓練,通過遷移學習來實現模型本身的泛化能力,是如何將學習到知識從一個場景遷移到另一個場景。
拿影像識別來說,從白天到晚上,從冬天到夏天,從識別中國人到 識別外國人……
借用一張示意圖(From:A Survey on Transfer Learning)來進行說明:
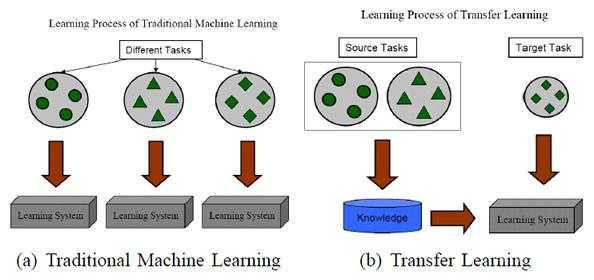
遷移學習的價值體現在:
1.一些場景的數據根本無法採集,這時遷移學習就很有價值;
2.復用現有知識域數據,已有的大量工作不至於完全丟棄;
3.不需要再去花費巨大代價去重新採集和標定龐大的新數據集;
4.對於快速出現的新領域,能夠快速遷移和應用,體現時效性優勢;
關於遷移學習演算法的實踐總結:
1. 通過原有數據和少量新領域數據混淆訓練;
2. 將原訓練模型進行分割,保留基礎模型(數據)部分作為新領域的遷移基礎;
3. 通過三維模擬來得到新的場景影像(OpenAI的Universe平台藉助賽車遊戲來訓練);
4. 藉助對抗網路 GAN 進行遷移學習 的方法;
三. 強化學習:
強化學習:全稱是 Deep Reinforcement Learning(DRL),讓機器有了自我學習、自我思考的能力。
目前強化學習主要用在遊戲 AI 領域,最出名的應該算AlphaGo的圍棋大戰。強化學習是個複雜的命題,Deepmind 大神 David Silver 將其理解為這樣一種交叉學科:

實際上,強化學習是一種探索式的學習方法,通過不斷 「試錯」 來得到改進,不同於監督學習的地方是 強化學習本身沒有 Label,每一步的 Action 之後它無法得到明確的回饋(在這一點上,監督學習每一步都能進行 Label 比對,得到 True or False)。
強化學習是通過以下幾個元素來進行組合描述的:
對象(Agent)
也就是我們的智慧主題,比如 AlphaGo。
環境(Environment)
Agent 所處的場景-比如下圍棋的棋盤,以及其所對應的狀態(State)-比如當前所對應的棋局。
Agent 需要從 Environment 感知來獲取回饋(當前局勢對我是否更有利)。
動作 (Actions)
在每個State下,可以採取什麼行動,針對每一個 Action 分析其影響。
獎勵 (Rewards)
執行 Action 之後,得到的獎勵或懲罰,Reward 是通過對 環境的觀察得到。


