【大數據】深入源碼解析Map Reduce的架構
這幾天學習了MapReduce,我參照資料,自己又畫了兩張MapReduce的架構圖。
這裡我根據架構圖以及對應的源碼,來解釋一次分散式MapReduce的計算到底是怎麼工作的。
話不多說,開始!
首先,結合我畫的架構圖來進行解釋。
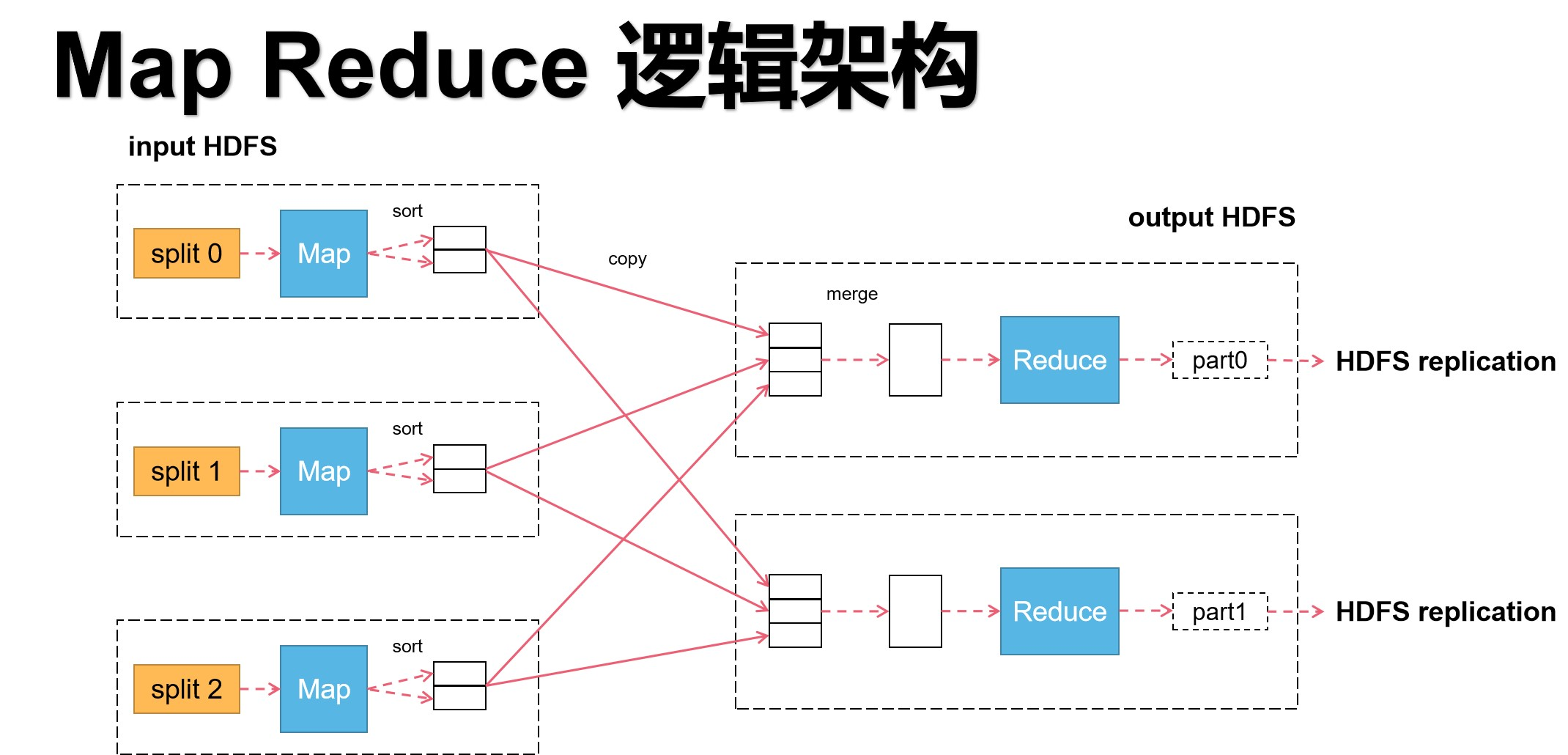
上圖是MapReduce的基本運行邏輯。把圖從中間切分,左邊為Map任務,右邊為Reduce任務。Map的輸出是Reduce的輸入。因此Map執行完畢Reduce才能執行,兩者的執行順序是一個線性關係,即輸入輸出的關係為:HDFS->Map->Reduce->HDFS。
在Map階段,多個Map可並行執行,Map數量越多,執行速度越快。
在Reduce階段,也可設置多個Reduce,但Reduce設置的大小依賴Map計算後的分組數量決定。換言之,在不破壞原語(「相同」的key為一組,調用一次reduce方法,方法內迭代這一組數據的計算)的情況下,Reduce程式數量由大數據研發人員確定。
這裡舉個例子:假設,有兩台機器,有5個不同組的Map結果,Reduce的程式數量有以下A、B兩種情況。 A:一台機器中啟動3個進程每個進程為一個Reduce程式,一台機器中啟動2個進程,每個進程是一個Reduce程式 B:兩台機器各啟動一個進程,每個進程是一個Reduce程式 請問哪種情況效率更高? 在機器為單核的情況下,採用B進程,因為若採用A方案,會涉及到進程切換以及爭搶資源的損耗,反而不如直接用單進程跑划算。 在機器為多核的情況下,採用A進程,因為當核的數量夠的情況下,每個進程可獨立運轉,就允許並行計算,效率就會提升。
所以說,Reduce數量的配置也是可以考驗一個大數據研發人員水平的。
左邊的每一個虛框中,都有split,意思是切片。根據圖,可以得出,一個切片對應一個Map程式。切片通俗來講,就是一個Map程式處理目標文件多大的數據,它採用的是窗口機制,可大可小,這是由大數據研發人員根據實際業務需求來進行確定的。在默認情況下是文件的一個塊的大小。同時,切片會將數據輸入格式化,變成多條記錄流向map程式。換言之,以一條記錄為單位調用一次map程式。在map任務執行完畢後,會輸出key,value的映射對。
舉個例子。假設,要處理一個文件中男性和女性的人數。
原文件內容有5行,內容如下:
張靚穎
羅志祥
蔡徐坤
那英
劉歡
那麼,經過map之後,每一行對應map的k,v輸出為:
女:1
男:1
男:1
女:1
男:1
在map輸出成(k,v)之後,每個map會將輸出的數據根據組進行排序,相同的key排成一組,等待Reduce程式進行拉取對應組的數據。
這裡,需要注意,map的輸出可以沒有排序,但是有排序和沒有排序會造成整個框架的效率的天壤之別。
因為根據MR原語,相同的key為一組,進行Reduce計算
若沒有排序,Reduce每一次拉取都需要遍歷各個map節點的輸出的全部數據,時間成本大大增加!
在大數據的背景下,不做排序幾乎就要了整個分散式計算框架的命!
再看Reduce階段,首先根據MR原語,Reduce要通過http協議請求拉取屬於自己組的map輸出結果。(這是一次網路IO操作,這裡也是可以進行優化的地方,後續在講。)
對於每一個Reduce而言,拷貝完之後生成的是一個內部有序外部無序的輸入數據,之後進行歸併排序,將同組文件放一起,就生成了可用於計算的數據序列。在將數據處理好之後,開始執行Reduce的方法,最終生成結果文件,傳入HDFS中保存。
一個小總結,總結一下MR中的一些對應關係
1、Block和Split的對應關係
- 1:1
- N:1
- 1:N
2、Split和Map的對應關係
- 1:1
3、Map和Reduce的對應關係
- N:1
- N:N
- 1:1
- 1:N
4、Group(key)和Reduce的對應關係
- 1:1
- N:1
- N:N
5、Reduce和Output的對應關係
- 1:1
再給個例子鞏固一下

這裡給出我畫的更細緻的架構圖。

上面幾段是一個很粗略的MR架構過程的分析,接下來細講,這裡結合源碼。
首先,補充一個內容。
在map的輸出階段,輸出了(k,v)之後,馬上會調用一個演算法,計算該輸出屬於哪個Reduce任務,所以實際上,map的輸出為(k,v,p),p代表屬於哪個Reduce任務,Reduce直接根據p的資訊進行拉取操作。另外,map產生的中間的數據結果的存儲在對應執行的主機的磁碟中存儲,不經過HDFS。
開始細講,這裡分三個部分講,分別是Client階段、Map階段、Reduce階段。
- Client階段
在客戶端開始運行後,主要功能是創建了一個job實例,並通過各種配置把這次的任務個性化,最後提交job給集群做計算
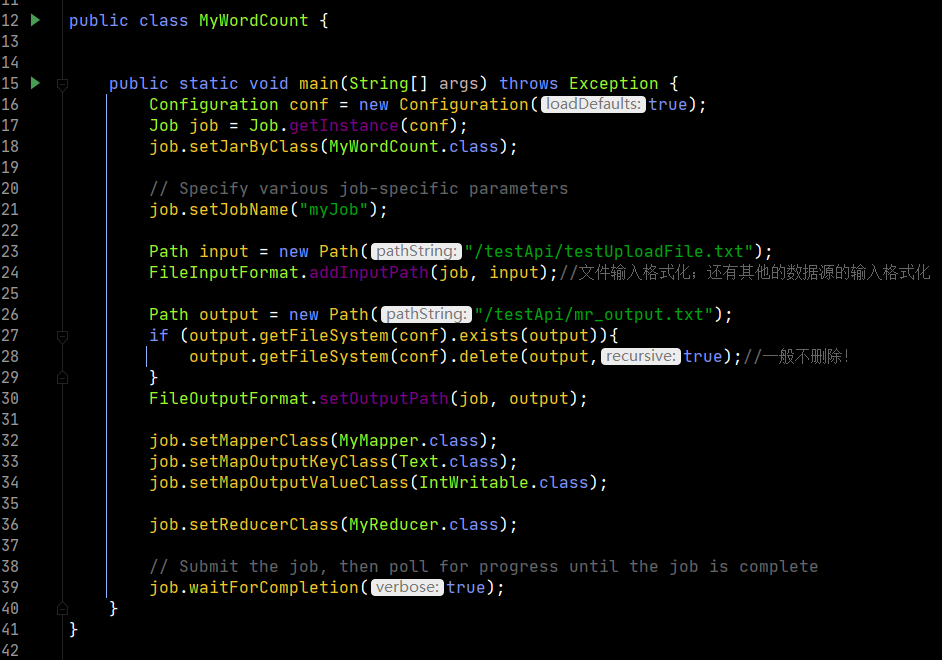
上圖是客戶端的程式碼
第16行和17行創建了配置對象以及根據配置對象創建job對象,然後指定要執行的方法類,設置此次任務的job名稱。
第23行至36行對數據的輸入輸出進行格式化,為後續的計算做準備。
最後第39行,執行提交方法。

1590行,這個submit是真正提交的函數,之後要看。
下面首先根據傳入的變數進行判斷,如果為true則執行monitorAndPrintJob方法,即監控並列印job執行過程。最後該函數返回的是一個執行狀態。
我們來看submit函數的實現。

第1569行會判斷是否執行新的API,這是因為第一版的hadoop和第二版的hadoop在計算上有變化,第一版叫做mapread,第二個版本才叫做mapreduce,因此為了兼容兩個版本,直接新寫一個函數。
第1570行是connect函數是調度層的事情,對集群進行連接,是對yarn的通訊調度過程,這裡不展開討論。
第1576行返回一個JobSubmitter的對象方法,方法中包含全部job的運行邏輯,這裡是一句關鍵程式碼。官方給的注釋也寫得明明白白,客戶端一共要干5件事情,分別是檢查輸入輸出、為job計算切片資訊、設置賬戶資訊、拷貝job的jar文件和配置到各個mapreduce計算節點上、監控job作業。
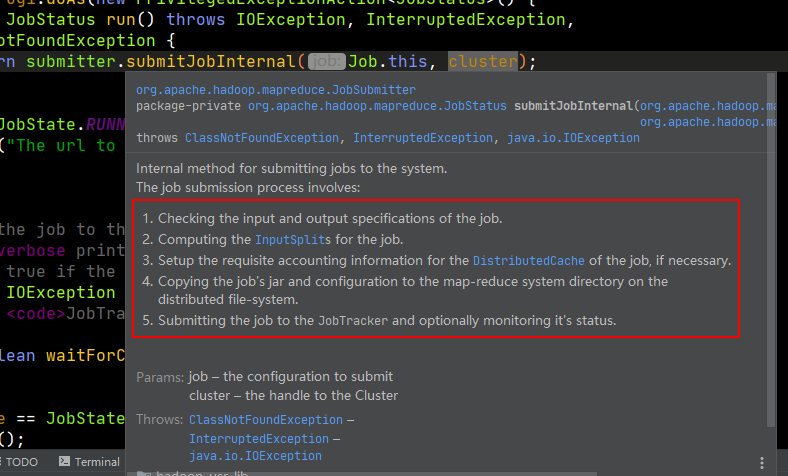
我們來看submitJobInternal

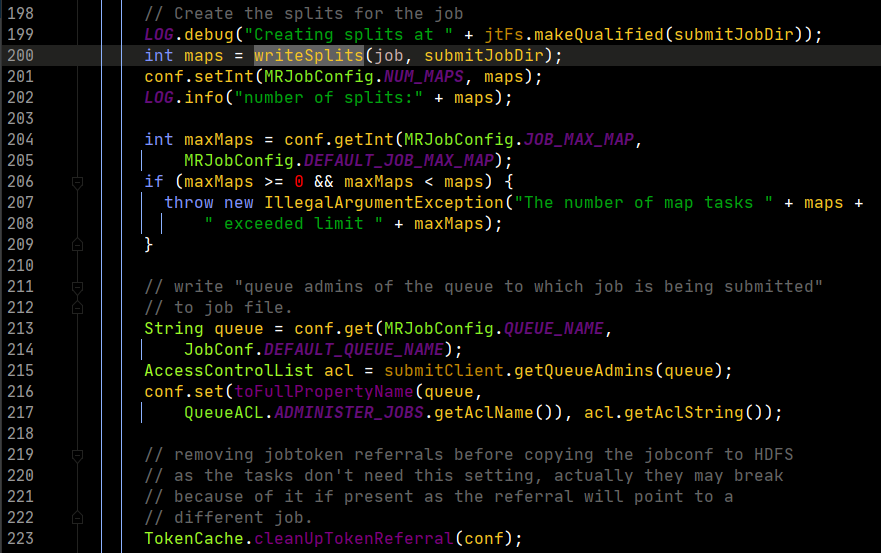
由於方法中內容太多,摘主要的進行分析。
看第200行,有一個writeSplits方法,這個方法就是要書寫切片資訊,這是一個關鍵方法,我們打開看看。
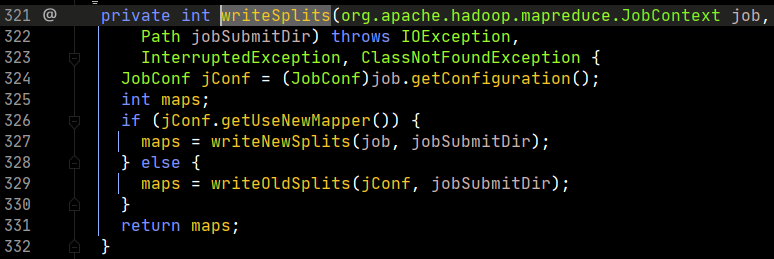
這個函數中根據判斷會調用不同的計算方法,判斷依據就是是否使用新的API。我們打開writeNewSplits方法。

這裡第306行,拿出job對象的配置資訊實例化一個新的配置對象;然後看307、308行,要產生一個InputFormat的對象。產生這個對象的原理利用Java的反射機制。框架運行的個性化就是靠動態的反射機制來實現的,這種方法在框架源碼中會大量出現。
我們來看看getInputFormatClass()這個類的實現。

第175行,意思是通過配置對象中是否存在INPUT_FORMAT_CLASS_ATTR的配置來獲取資訊,如果沒有設置則讀取第二個參數的資訊進行返回。
跳回至writeNewSplits方法中,繼續講解。
根據閱讀源碼,我們應該知道框架默認應該返迴文本的輸入格式化類,即TextInputFormat
我們看310行getSplits()的實現。


可以看到,第399行和第400行有兩個變數,需要注意這兩個變數的值是如何計算出來的。首先,minSize是通過getFormatMinSplitSize(), getMinSplitSize()兩個方法的返回值的最大值得出來。分別進入兩個方法中,看其返回值。


一個返回1,另一個通過先獲取用戶配置,若無則返回1。
因此,在框架默認情況下,minSize為1。
再看maxSize

這裡,通過配置對象取用戶的配置資訊,若沒有則返回Java的Long變數的最大長度
因此,在框架默認情況下,maxSize為一個非常大的數,具體就是Long變數的最大值。
繼續返回getSplits函數查看。
第403行起,函數開始進行切片的生成,首先創建一個切片的序列對象。
第404行,FileStatus是HDFS的對象,因此這裡的含義是生成一個包含全部要計算文件的的列表(元資訊)。
第408行,開始進行for循環,迭代每一個文件進行切片的處理。因此,通過閱讀源碼,我們知道,切片不可能會跨文件,因為每個文件都是單獨處理的。
第412行,獲得文件在HDFS上的路徑。
第413行,獲得文件的大小。
第414行,判斷文件是否為空,不為空進行計算,為空則創建一個長度為空的切片資訊,用於對該空文件進行佔位。
第419行,通過配置對象的返回的配置資訊調用得到一個分散式文件系統對象。
第420行,取出文件所有的塊。
第422行,首先判斷文件是否允許切片,因為在HDFS文件中,有些文件被壓縮或其他格式,切片之後也是亂碼,無法讀取,因此切片不適用,只能拿到全部的塊組裝成一個文件後進行操作。
第423行,若允許切片,則首先得到每一個塊的大小。
第424行,切片的大小通過computeSplitSize函數決定,看其實現如下

我們分析框架默認的情況。當默認情況下, 首先maxSize是Long的最大值,非常大,blockSize肯定小於maxSize,因此兩者取最小,則為blockSize,然後minSize為1,取最大值的情況下,返回blockSize的大小。所以,通過源碼分析,框架默認切片大小等於文件塊的大小。這裡,可以繼續深入一下,當我們需要切片比塊小的情況下,改大值,當需要切片比塊大的情況下,改小值。
第426行,定義一個變數,值為一個文件的長度,後面的執行會用到。
第428行,length-byteRemaining為偏移量,第一次循環值為0,第二次循環,由於第449行的存在,其值為一個切片的大小,以此類推。這樣得到了一個塊的索引。這裡需要注意以下,切片的偏移量,一定是大於等於一個塊的起始偏移量,小於等於一個塊的結束的偏移量,用人話說就是切片的偏移量要包含在塊的偏移量之內。getBlockIndex函數有實現,這裡不看了。這裡其實還可以更深入,考慮切片大於和小於一個塊的情況,不過這裡暫時略過。
第429行,根據計算好的偏移量資訊和塊資訊創建切片並添加至splits這個切片序列對象中。我們看一下這個makeSplit函數的參數,前4個參數是一個切片最核心的資訊。

file,是該切片屬於哪個文件;start是切片的起始偏移量;length是切片的大小;hosts是塊的位置資訊,其實就是實現了將塊的位置資訊賦值給了切片。
#舉個例子
有一個切片,資訊分別可以是
1,0,4,[1,2,6]
1,代表文件標識
0,代表起始偏移量
4,代表切片大小
[1,2,6],代表這個切片對應的塊的副本的位置
到這裡,基本上源碼分析就差不多結束,從開始到這裡,都是客戶端要做的事情,做完之後將配置、jar以及切片資訊上傳至ResorceManager,然後進行後續調度,這裡按住不表。
- Map階段
我們先來看MapTask中的run方法。

第318行,從配置資訊中取reduce任務的數量並判斷是否為0,即沒有reduce階段,則定義整個過程不調用reduce階段。如果有,則進入下面的設置。
第323、324行,設置在存在reduce任務的情況下,除了有map階段外,還有sort階段。
然後跳轉至347行,進入runNewMapper。
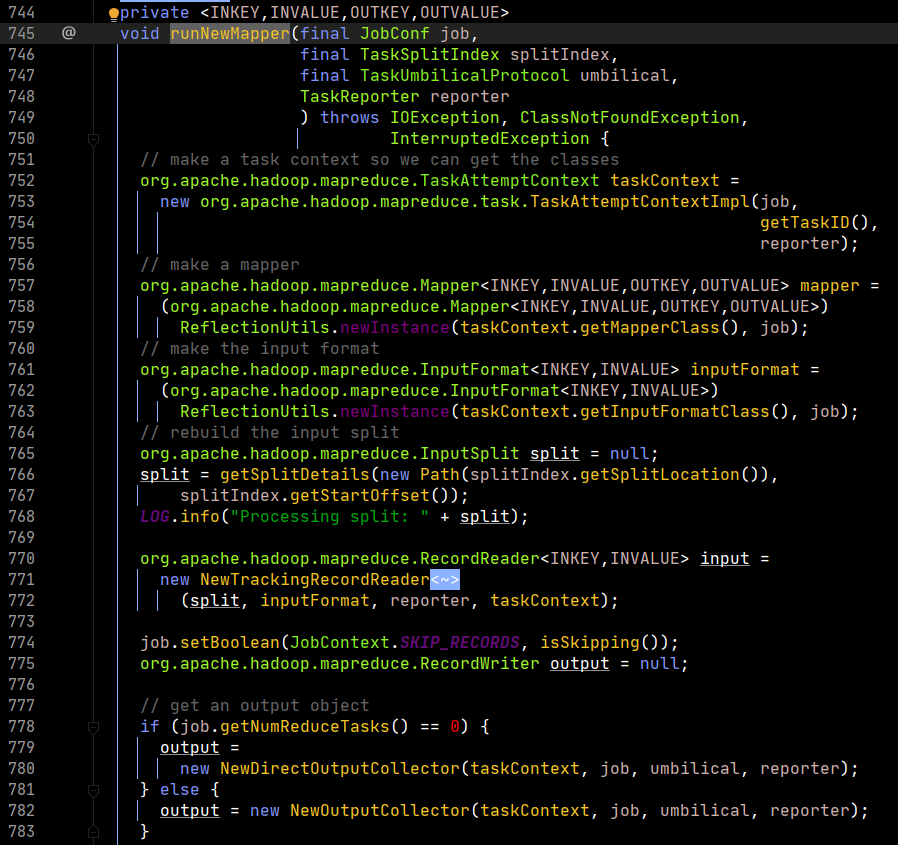

第752行,初始化任務上下文,裡面包含了job對象。
第757行,通過反射,實例化一個map對象。這裡根據研發人員在配置資訊中指定的mapper類來進行。
第761行,通過反射,實例化一個輸入格式化對象。這裡根據研發人員在配置資訊中指定的輸入格式化類來返回,默認返回Text的輸入格式化類。
第766行,生成一個切片對象。
第771行,創建一個輸入格式化記錄讀取器對象,該對象默認返回一個行記錄讀取器,即LineRecordReader。這個類中有三個方法,經常被使用,即nextKeyValue、getCurrentKey、getCutrrentValue。
我們可以看一下實現。
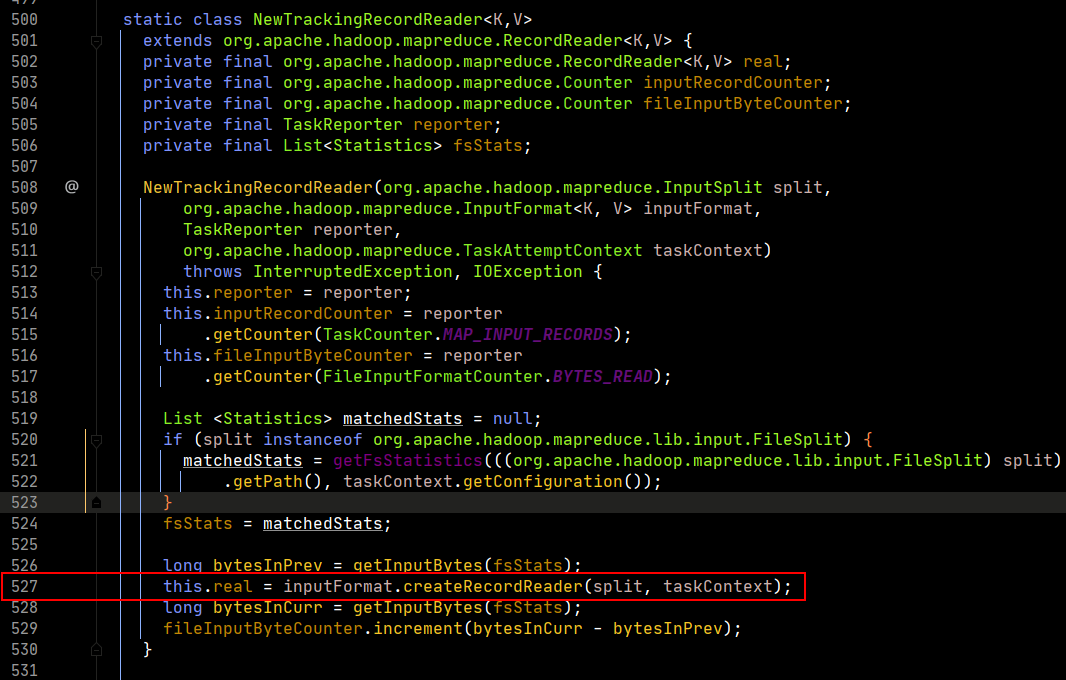
在第527行,記錄讀取器real被輸入格式化對象創建記錄讀取器,這裡我們再打開createRecordReader方法,看最終返回。
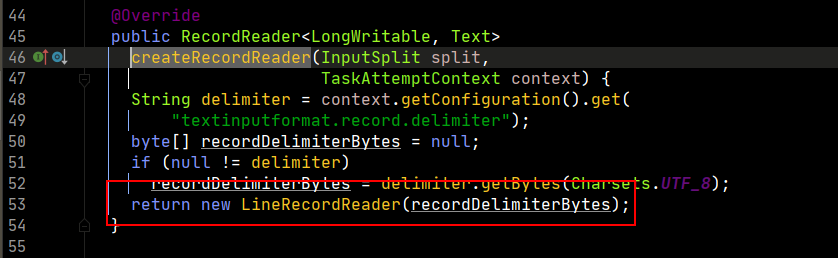
所以,最終幹活的是LineRecordReader對象。
返回來,繼續看。
第786、787行,創建了map的上下文對象,這裡傳入的input,在框架默認情況下就是LineRecordReader。
第798行,首先進行輸入初始化。因此map程式必須是輸入初始化變為序列後,才執行map程式。

這裡能夠發現,真正的初始化是real的初始化,而real就是LineRecordReader,我們繼續看這個初始化函數的實現。


第81行,獲得行數
第82行,獲得切片的起始偏移量
第83行,獲得切片結束的偏移量
第84行,從切片中獲得對應的文件路徑資訊
第87行,獲得HDFS的對象
第92行,獲得對程式的輸入流
第121行,定位到對應的起始的偏移量。這樣每個map讀取的文件都是自己對應的文件,和其他map就不會衝突。
第122行,獲得的IncompressedSplitLineReader對象就是真正可以進行讀取文件內容的對象。
第129行,判斷是否是讀取第一行數據,不是則進入方法,是則跳過。目的是維護數據的完整性!因為HDFS文件切塊時,可能會把連起來的一句話切到不同的塊中,因此map在計算時,會默認開始讀取第二行。而第一行的數據通過上一個切片的末尾進行補全後計算。這裡比較重要!
第130行,in.readLine()返回讀到了多少個位元組,然後加上start就獲得了新的偏移量
第132行,將start資訊賦值給pos。
回到之前的RunNewMapper的方法。
第799行,執行mapper的run方法

第143行,首先設置上下文對象,context包含了map任務的輸入和輸出資訊。
第146行,將map對象中添加key和value的值,然後執行map方法進行計算。
不過這裡需要注意一下,while循環判斷中的nextKeyValue主要功能就是對key和value做了一次賦值操作,具體可以對源碼再次打開查看,這裡不詳細展開了。
回到runNewMapper方法。
第800行,設置map階段結束。
第801行,開始設置排序階段。
第803-806,對輸入輸出置空。
這裡就是map中最核心的程式碼,就幹了兩件事情,計算+排序。
接下來,看一下map的輸出階段。
第777-783行,構造了一個output實例,打開NewOutputCollector對象。

第711行,創建了一個分區的數量,也就是reduce的任務數量。
第712-723行,如果分區數量等於1,返回分區號0;若大於1,則查看用戶是否設置,不設置默認返回hashPartitioner,這種方式會破壞數據原有的序列特徵。
由於我們mapper類輸出使用write進行輸出,這裡看一下write的實現,就會發現上面的partition是有用的。

我們看到,map輸出就會輸出k,v,p三個維度的值。
回到之前的方法,看一下collector的構造。
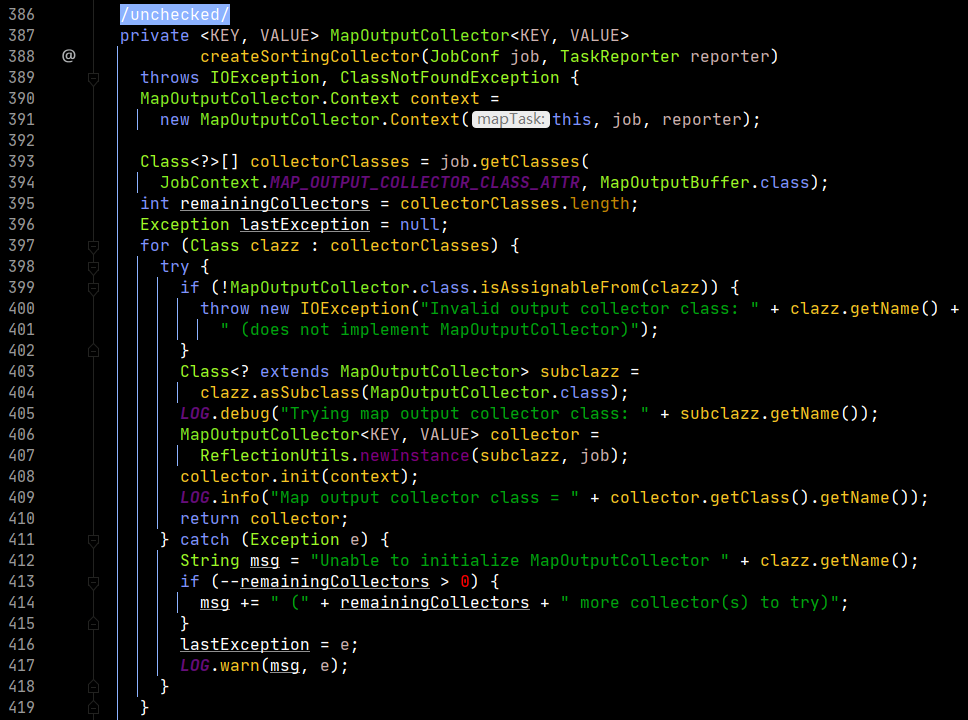
這個collector最後定位到了第393-394行,框架默認為MapOutputBuffer類,這裡就聯繫到了緩衝區。
第408行,對collector進行了初始化,起始就是對MapOutputBuffer進行了初始化,我們看其實現。



我們注意第980-981行,定義了一個spillper的值,定義了一個異寫的百分比,80%。這裡需要解釋一下,80%是可以變化的,也是大數據開發中調優的一個點。當然,這個80%就是說當map輸出大小到達緩衝區的80%之後,這80%的數據被鎖定,進行本地磁碟的寫入,同時,將map輸出向20%的容量中繼續寫。這裡就會壓縮了寫入磁碟的時間,因為有部分時間時同時進行本地磁碟的寫入和緩衝區的寫入工作。
然後注意到,第994-996行在緩衝區的數據的排序默認使用了快速排序演算法。同時需要知道的是,在向磁碟寫入的過程之前,框架就會在緩衝區內將80%的數據進行快速排序,變成一個有序的數據。
由於排序一定用到了比較,因此這裡就需要一個比較器。第1018行就定義了一個比較器,看一下其實現。

當用戶有配置比較器時,返回用戶配置的;沒有配置時,默認返回Map的key自身的介面的比較器。因為Map在數據序列化過程中也是需要比較器的。
回到之前的函數,第1044-1045行,設置了一個combiner。目的是壓縮數據,將重複的數據進行壓縮,編程一個更小的數據,這裡就是一個優化的點。這樣做的好處就是減少了之後輸出到磁碟的時間以及Reduce的I/O時間。這裡的Combiner的原理類似於Reduce。Combiner的執行是在快排之後,寫入磁碟之前進行。或者在向Reduce傳輸之前進行。
這裡解釋一下什麼時記憶體緩衝區。

這是一個記憶體緩衝區,前面的kv對進行寫入,後面的索引從尾部開始往回寫。到達80%的情況後,鎖定80%的內容進行後續的異寫,在20%的空間繼續寫。為了能夠循環往複的進行操作,將上述的緩衝區換成下面的環形,這樣當到達80%的情況後,將剩餘的部分中間切開,然後kv對從切開的部分往一個方向寫,索引資訊從切開的部分往另一個方向寫,只要保證在20%沒有被佔滿的情況下,80%的寫入數據完畢就可以實現無限的循環往複。
這裡,源碼的閱讀基本結束,一個map的任務基本介紹完畢。
- Reduce階段
首先看一下官方怎麼介紹這個階段。
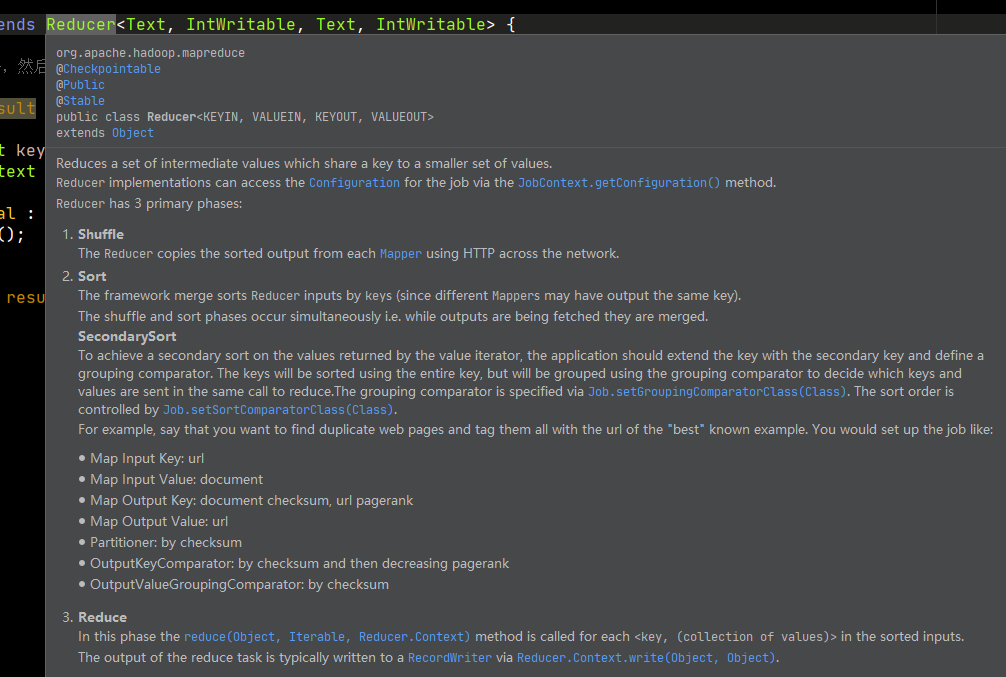
有三個階段,洗牌、排序、Reduce。我們看Reduce源碼,重點要知道如何實現Reduce的運行邏輯,還要知道如何規避記憶體溢出。
好了,我們繼續,堅持就是勝利!
我們首先看ReduceTask.class中的run方法。

從第325-327,可知,過程添加了拷貝、排序和Reduce三個階段。

第377行,返回了一個迭代器,而迭代器時通過調用的時NodeManager中的插件拉取數據之後返回。因此,可以知道這個迭代器可以獲得這個Reduce方法應該處理的所有數據。
第387行,定義了一個排序比較器,這個比較器是給排序用的,具體來說就是分組的比較器。這裡的實現中,首先判斷用戶是否設置了組比較器,如果設置,則使用用戶定義的,沒有則判斷用戶是否設置了key比較器,如果沒有則使用默認的key比較器。
之後,看runNewReducer的實現。
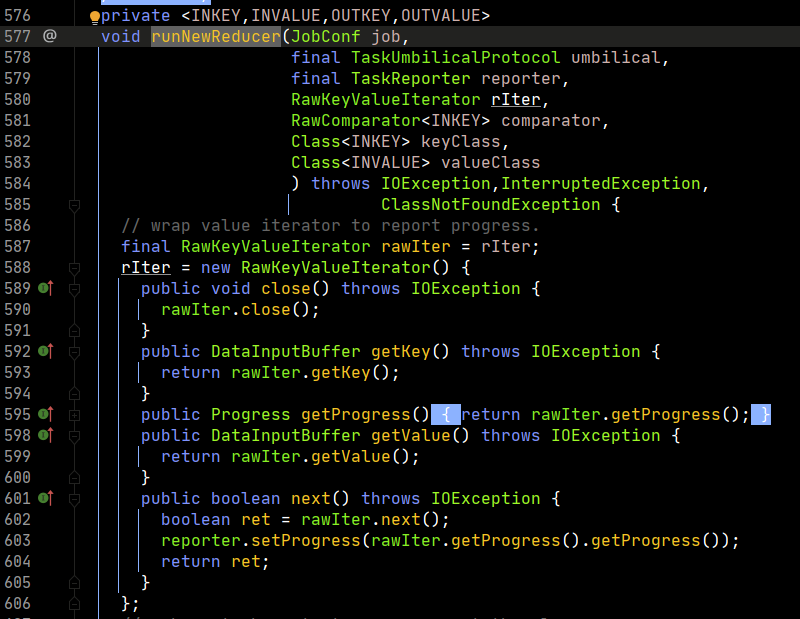
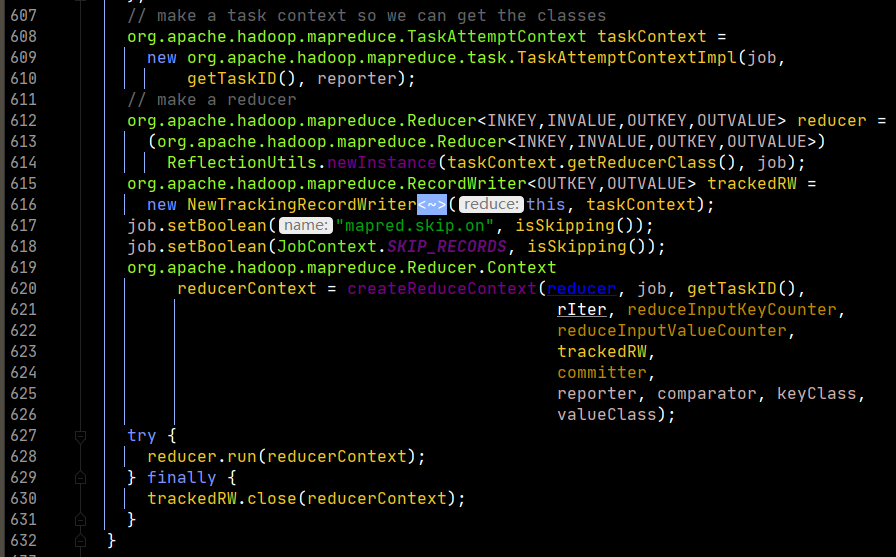
我們重點看一下run方法的實現。
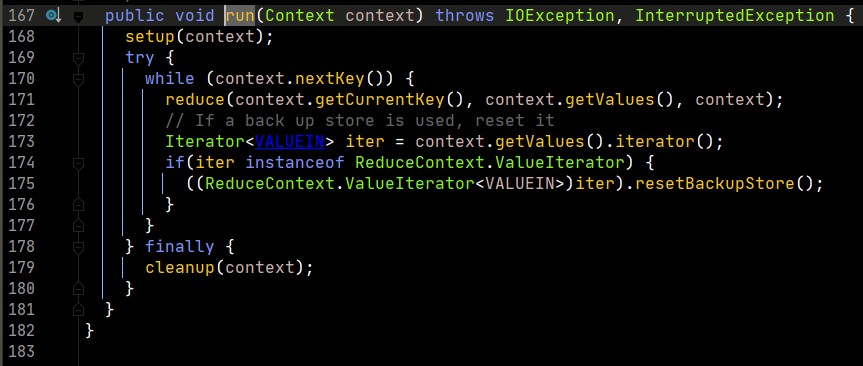
在run中,重點對context.nextKey()的實現進行分析,這裡是最重要的部分,也是避免記憶體溢出的關鍵思想。

再看一下nextKeyValue的實現。
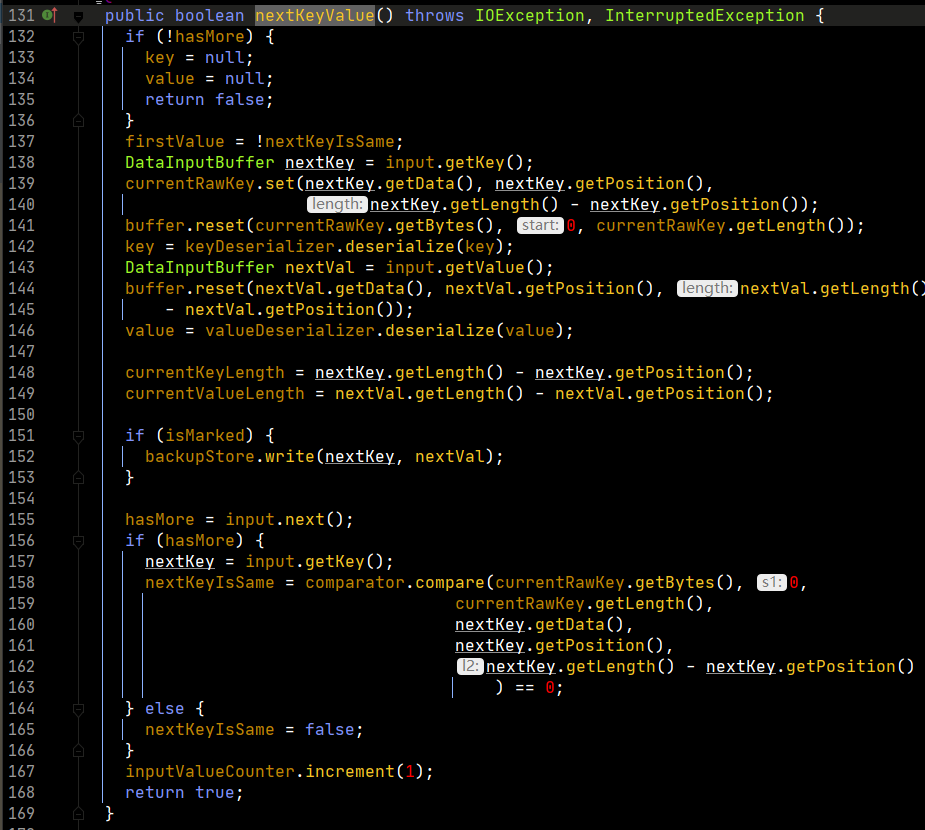
上述程式碼用人話來說nextKeyValue的功能,就是對k和v進行賦值操作。由於map輸出的是把k和v變為序列化,存為位元組數組,這裡反序列化就是將位元組數組再變為真正的k和v,也就是對key和value的賦值操作。
然後,從第156行開始,進行比較。首先,取得下一個key,然後通過分組比較器,比較當前的key和下一個key是否相等,相等是true,不等就是false。
我們再追蹤一下,run方法中,context.getValues到底返回的是什麼。

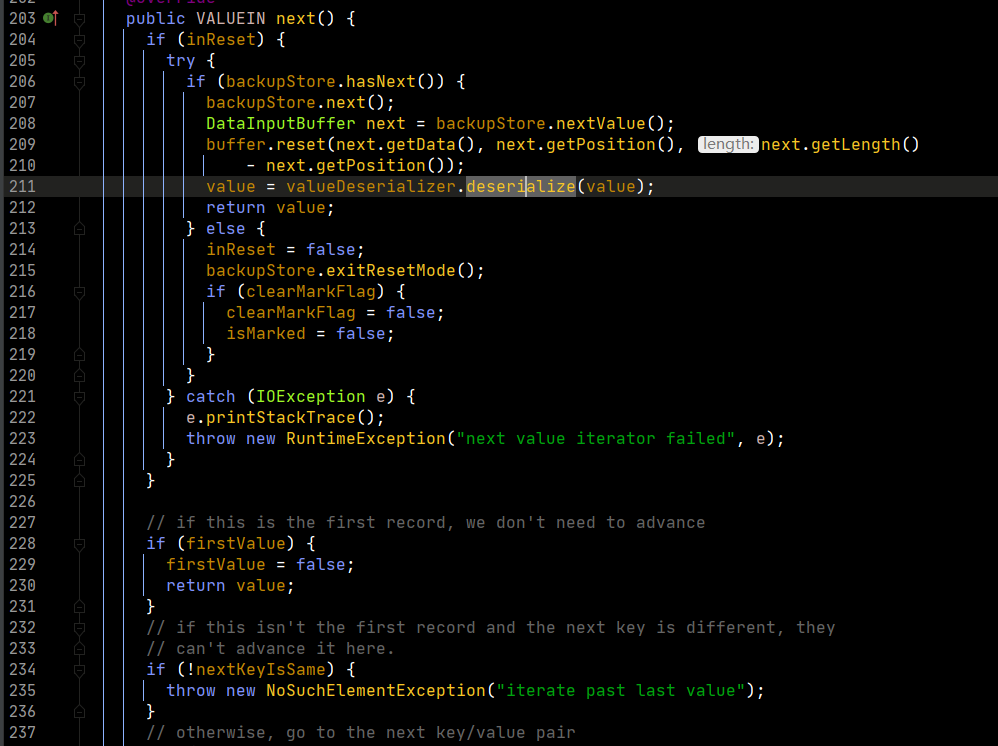

我們可以追蹤到,最終value返回的迭代器是上圖中的迭代器。這裡需要注意的是第199行的nextKeyIsSame。這個判斷是根據key來判斷下一條的數據是否是同一組的數據。同時在next函數中,會調用nextKeyValue,這個函數就會更新nextKeyIsSame的值,從而hasNext使用的naxtKeyIsSame就更新了。
啰嗦了這麼多,其實核心思想就是,在循環取值的過程中,reduce會預先判斷下一個key與當前key是否一致,一致則取值,不一致,退出while循環。這樣做的好處就是保證了MR原語,即相同的key為一組,調用reduce方法做計算。
也應該知道,一次while循環,只會把相同的key的值拿出來。
因此,我們也就清楚了避免記憶體溢出的解決方案了。就是以一條記錄為單位,判斷下一條記錄是否和當前是一組,是則計算,不是則退出,等待下一次的循環。這樣做就避免了直接把相同的key的值全部放在記憶體中,由於數據量可能會很大,超過記憶體限制,就會產生移除問題,而這樣的話,只需要記憶體有兩條數據的大小就可以完成MR原語的要求。
至此,Reduce階段的分析結束。
最後,我想說,這是一個非常粗淺的源碼分析,其實這個框架很大,能夠設置的東西很多,過程中僅僅是摘了比較核心的部分進行了分析,要熟練掌握MR,需要多多分析源碼原理,然後寫出最適合的業務程式碼,最終讓自己的技術能力得到提高!



