在VS2019使用MASM編寫彙編程式
- 2020 年 9 月 22 日
- 筆記
具體的配置步驟可以參考:
彙編環境搭建 Windows10 VS2019 MASM32
本文主要是入門向的教程,VS2019中要調用C語言函數需要加上
includelib ucrt.lib
includelib legacy_stdio_definitions.lib
輸出
配置好了環境之後,讓我們開始第一個彙編程式吧
.686
.MODEL flat, c
.stack 100h
includelib ucrt.lib
includelib legacy_stdio_definitions.lib
;Function prototypes
printf PROTO arg1:PTR byte
.data
hello byte "hello world !",0Ah, 0 ;聲明變數
.code
main proc
invoke printf, ADDR hello ;調用printf函數列印變數
ret ;相當於return 0
main endp
end main
.686是指明使用的指令集,向下兼容,.model flat,c中的flat表示程式使用保護模式,c表示可以和c/c++進行連接。.stack以十六進位的形式聲明堆棧大小,這幾句先照抄就好。
如果要調用C函數記得把上面說的兩個lib加上,printf proto這句話是指明printf函數的原型,它的參數是一個指向字元串的指針。
.data與.code就如同他們的英文名字一樣直接明了,數據段和程式碼段。
在彙編中要想使用printf,需要使用INVOKE指令。ADDR你可以理解成給參數賦值,ADDR表明了輸出字元串的記憶體地址。特別注意:該指令會破壞eax,ecx,edx暫存器的值
hello byte "hello world !",0Ah, 0,你可能比較疑惑0Ah是幹啥的,它其實就是\n,最後面跟著個0表示字元串到此結束(你肯定在C語言里學到過)。hello是變數名,你可以換成你喜歡的名字。不過彙編裡面變數名是不區分大小寫的
endp表示過程(procduce)的結束,end表示程式的結束.
ret等同於return 0
整個程式如果用C來寫相當於
#include<stdio.h>
int main()
{
printf("hello world !");
return 0;
}
輸入
學會了輸出自然也得把輸入學會,請看下面的程式碼:
.686
.MODEL flat, c
.stack 100h
includelib ucrt.lib
includelib legacy_stdio_definitions.lib
printf PROTO arg1:PTR byte, printlist:vararg
scanf PROTO arg2:ptr byte, inputlist:vararg
.data
in1fmt byte "%d",0
msg1fmt byte 0Ah,"%s%d",0Ah,0
msg1 byte "the number is ",0
number sdword ?
.code
main proc
invoke scanf, ADDR in1fmt, ADDR number ;scanf必須都加addr,類似於&
invoke printf, ADDR msg1fmt, ADDR msg1, number
ret
main endp
end main
看著有點恐怖?對照C語言程式看一下吧
#include<stdio.h>
int main()
{
int number;
scanf("%d",&number);
printf("\n%s%d\n","the number is ",number);
return 0;
}
這段程式大體跟之前的差不多,只不過多了幾張新面孔。
.686
.model flat, c
.stack 100h
includelib ucrt.lib
includelib legacy_stdio_definitions.lib
printf proto arg1:ptr byte, printlist:vararg
scanf proto arg2:ptr byte, inputlist:vararg
.data
in1fmt byte "%d",0
msg1fmt byte "%s%d",0Ah,0
msg1 byte "x: ",0
msg2 byte "y: ",0
x sdword ?
y sdword ?
.code
main proc
invoke scanf,ADDR in1fmt, ADDR x
invoke printf,ADDR msg1fmt, ADDR msg1, x
mov eax,x
mov y,eax
invoke printf,ADDR msg1fmt, ADDR msg2, y
ret
main endp
end main
#include<stdio.h>
int main()
{
int x,y;
scanf("%d",&x);
printf("x: %d",x );
y=x;
printf("y: %d",y);
return 0;
}
對比上面兩段程式碼你發現了什麼嗎?在C語言裡面,把x賦值給y只需要一句話,但在彙編裡面卻不能這樣做。因為數據不能直接從一個記憶體單元到另外一個記憶體單元去,只能是通過暫存器完成相關操作。RAM中的數據先要被裝載到CPU中,再由CPU將其存到目的記憶體單元中。
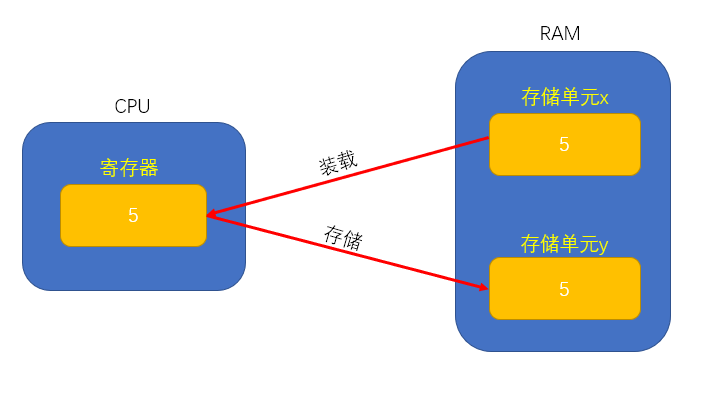
如果是字元怎麼辦?方法跟是一樣的,只不過這裡只需要使用eax的低8位al即可。
.data
char1 byte ?
char2 byte ?
.code
mov char1,'A'
mov al,char1
mov char2,al
字元串怎麼辦?其實這玩意就是個數組,讓我們來看看如何操作數組吧
循環與數組
它們倆可是好兄弟
.data
numary sdword 2,3,4
zeroary sdword 3 dup(0)
empary sdword 3 dup(?)
要想遍曆數組,循環結構是必不可少的。
for(int i=0;i<3;i++)
{
printf("%d\n",numary[i]);
sum += numary[i];
}
printf("%d\n",sum);
這段C語言程式碼用彙編來寫是這樣的
.686
.model flat, c
includelib ucrt.lib
includelib legacy_stdio_definitions.lib
printf proto arg1:ptr byte, printlist:vararg
.data
msg1fmt byte "%d",0ah,0 ;還記得吧?0ah表示換行
numary sdword 2,5,7
sum sdword ?
.code
main proc
mov sum,0
mov ecx,3
mov ebx,0
.repeat
push eax
push ecx
push edx
invoke printf,addr msg1fmt, numary[ebx]
pop edx
pop ecx
pop eax
mov eax,numary[ebx]
add sum,eax
add ebx,4 ;因為是雙字,4個位元組
.untilcxz
invoke printf,addr msg1fmt, sum
ret
main endp
end main
.repeat-.untilcxz該指令對做的事情就是每次循環都把ecx的值減一,直到它為0。這裡有一個特別坑的地方:只能有126位元組的指令包含在.repeat-.untilcxz循環體內,多了會報錯。
另外還有注意的是,千萬不要讓ecx值為0進入.repeat-.untilcxz循環體,因為執行到.untilcxz語句時,ecx的值會先減1再與0比較是否相等。這就出大麻煩了,ecx的值現在為負數,雖然不會死循環,但程式要循環40億次才能停下來。(一直減到-2147483648,下一次減一得到的結果才是一個正數2137483647)
鑒於上訴情況,還是用.while來寫循環結構比較好
;前置檢測循環while(i<=3)
mov i,1
.while (i<=3)
inc i ;i+=1
.endw ;循環體結束
;後置檢測循環do while
mov i,1
.repeat
inc
.untile (i>3)
棧的作用
上面那個列印數組的程式中為什麼還用到了push指令?*因為invoke指令會破壞eax,ecx,edx暫存器的值,程式還需要ecx控制循環,所以在調用invoke指令之前需要利用棧將被破壞的ecx賦回原來的值,保證循環正確運行。
當然你也不需要一股腦push這麼多,上面的例子其實只需要push ecx就可以了,這樣別人看你程式碼時也能更清楚你都做了些什麼。
要想偷懶的話可以使用pushad和popad來保存和恢復暫存器(eax,ecx,edx)中的值。
使用堆棧與xchg指令來實現數據交換
交換兩數在高級語言之中一般這樣寫:
temp=num1
num1=num2
num2=temp
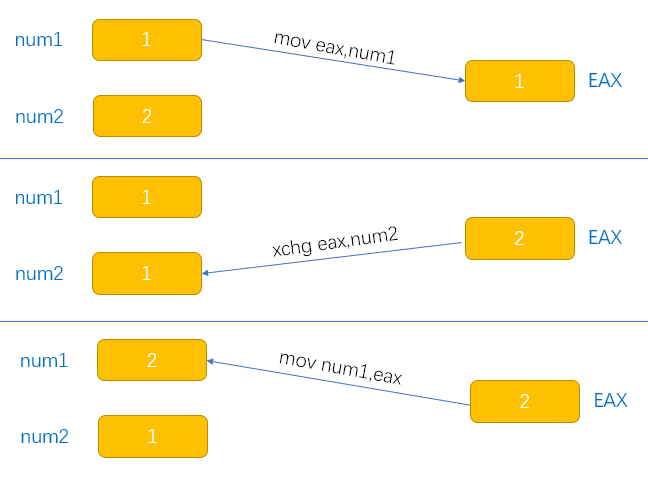
對應到咱們彙編,簡短點寫法是:
mov eax,num1
mov edx,num2
mov num1,edx
mov num2,eax
不過這裡用到了兩個暫存器,還有沒有別的比較好的辦法呢?
當然是有的,可不就是咱們的標題嘛
push num1;將num1壓棧
push num2;將num2壓棧
pop num1;將出棧的元素(num2)賦值給num1
pop num2;將出棧的元素(num1)賦值給num2
;利用echg指令
mov eax,num1
xchg eax,num2
mov num1,eax
搞這麼麻煩,直接xchg num1,num2不就好了嗎?
如果你這麼想就大錯特錯了!因為:數據不能直接從一個記憶體單元到另外一個記憶體單元去,我們必須藉助暫存器的幫助。
上訴三種方法中mov指令是最快的,但需要用到兩個暫存器;堆棧是最慢的,但無需使用暫存器;使用xchg指令算是一種折中的方法。
字元串
前面鋪墊了那麼多,終於到字元串了。
它也是數組
先來個樸實無華的hello world
.686
.model flat, c
includelib ucrt.lib
includelib legacy_stdio_definitions.lib
printf proto arg1:ptr byte, printlist:vararg
.data
msg1fmt byte "%s",0Ah,0
string1 byte "Hello World!",0
string2 byte 12 dup(?),0
.code
main proc
mov ecx,12
mov ebx,0
.repeat
mov al,string1[ebx]
mov string2[ebx],al
inc ebx
.untilcxz
invoke printf,addr msg1fmt,addr string2
ret
main endp
end main
使用暫存器esi和edi進行索引
.686
.model flat, c
includelib ucrt.lib
includelib legacy_stdio_definitions.lib
printf proto arg1:ptr byte, printlist:vararg
.data
msg1fmt byte "%s",0Ah,0
string1 byte "Hello World!",0
string2 byte 12 dup(?),0
.code
main proc
mov ecx,12
lea esi,string1 ;將string1的地址裝載到esi
lea edi,string2 ;將string2的地址裝載到edi
.repeat
mov al,[esi] ;將esi所指向的地址中的內容放入al
mov [edi],al ;將al中的內容放入edi所指向的地址
inc esi ;將esi中的內容加1
inc edi ;將esi中的內容加1
.untilcxz
invoke printf,addr msg1fmt,addr string2
ret
main endp
end main

當循環體中指令第一次執行時,esi和edi分別指向String1和String2的首地址。第二次執行時,esi和edi以及分別遞增加1,esi所指00000101地址處的e會被複制到edi所指的0000010D地址中去。之後ecx減1,esi,edi遞增,指向下一個位元組處。
movsb指令可以幫助我們簡化程式,它可用於完成單位元組字元串的移動工作:首先將esi所指的位元組內容複製到edi所指向的地址,接著將ecx的值減1,同時對esi和edi指向遞增或遞減操作。
雖然它是單位元組移動指令,但與循環結構配合能夠發揮出強大的作用。之前的程式碼我們可以改寫成
.686
.model flat, c
includelib ucrt.lib
includelib legacy_stdio_definitions.lib
printf proto arg1:ptr byte, printlist:vararg
.data
msg1fmt byte "%s",0Ah,0
string1 byte "Hello World!",0
string2 byte 12 dup(?),0
.code
main proc
mov ecx,12
mov esi,offset string1+0 ;將string1地址的值加0放入esi中
mov edi,offset string2+0 ;將string2地址的值加0放入edi中
cld ;方向標誌值清零
.repeat
movsb
.untilcxz
invoke printf,addr msg1fmt,addr string2
ret
main endp
end main
如果想要將esi和edi中的值都遞減,那麼需要將cld指令換成std指令。
字元串數組
如何複製一個字元串數組?可以將其看成一個大字元串,這樣使用兩個循環:一個用於控制字元串數組,另一個用於處理字元串中的每一個數組,即可複製該字元串數組。
.686
.model flat, c
includelib ucrt.lib
includelib legacy_stdio_definitions.lib
printf proto arg1:ptr byte, printlist:vararg
.data
msg1fmt byte "%s",0Ah,0
names1 byte "Abby","Fred","John","Kent","Mary"
names2 byte 20 dup(?)
.code
main proc
mov ecx,5
lea esi,names1
lea edi,names2
cld
.repeat
push ecx ;保存暫存器ecx的值
mov ecx,4
rep movsb ;重複執行movsb直到ecx為0
pop ecx ;恢復暫存器ecx的值
.untilcxz
invoke printf,addr msg1fmt,addr names2
ret
main endp
end main
| 前綴 | 意義 |
|---|---|
| rep | 重複操作 |
| repe | 如果相等,則重複操作 |
| repne | 如果不相等,則重複操作 |
前綴rep指令會對暫存器ecx的值進行遞減直到它為0,所以程式中使用了堆棧來保護用於控制循環的ecx的值。
過程
過程又被稱為子程式,函數。
call指令可以用於調用過程:
call pname
之前程式里的main就是一個過程,過程的具體格式如下
pname proc
;過程體
ret
pname endp
雖然過程的調用與返回要比直接在主程式中編寫程式碼效率低,但因為相關的程式碼只需要寫一次,所以節省了記憶體空間。
編寫過程時,最好對eax,ecx,edx進行保存恢復工作,這樣能方便需要用到這些暫存器的程式調用該過程。
宏
宏的聲明需要放在.code之後main過程之前
mname macro
;宏體
endm
宏的調用不需要call指令,你可以就把它當成一條指令來使用。
使用堆棧與xchg指令來實現數據交換這一標題下提到的程式可以用宏改寫為
.code
swap macro p1:REQ,p2:REQ ;; :REG表示參數是必須的
mov ebx,p1 ;;使用雙分號進行注釋,這段注釋不會在後續的宏擴展中出現
xchg ebx,p2
mov p1,ebx
endm
main proc
swap eax,ebx
main endp
end main
判斷與條件彙編
在彙編中,if語句與C語言中的沒太大區別
.if (判斷條件)
.else (判斷條件)
.endif
也支援嵌套if,只要記得用完if之後要在後面有個.endif對應即可
那條件彙編又是什麼東西呢,它與if這類的選擇結構有什麼區別?
.if語句用於控制程式執行流從哪一條路徑執行下去,條件彙編告訴程式是否將一條指令或一段程式碼包含到程式中去。
addacc macro parm
ifb <parm> ;ifb if blank
inc eax ;如果缺少參數就把eax的值加1
else
add eax,parm;相當於eax+=parm
endif
endm
如果調用宏addacc時缺少了參數,eax默認為1,否則將參數與eax的值相加。
| 彙編指令 | 含義 |
|---|---|
| if | 如果(可以使用EQ,NE,LT,GT,OR…) |
| ifb | 如果為空 |
| ifnb | 如果不為空 |
| ifidn | 如果相同 |
| ifidni | 不區分大小寫時,如果相同 |
| ifdif | 如果不同 |
| ifdifi | 不區分大小寫時,如果不相同 |

