Elasticsearch安裝、原理學習總結
- 2020 年 9 月 22 日
- 筆記
ElasticSearch
ElasticSearch概念
Elasticsearch是Elastic Stack核心的分散式搜索和分析引擎。
什麼是Elastic Stack
Elastic Stack,就是ElasticSearch + LogStash + Kibana
Logstash用於收集,聚合和豐富數據並將其存儲在Elasticsearch中。
Kibana提供了一套可視化介面,可以互動式的瀏覽數據,以及管理和監視堆棧。
ElasticSearch是一個分散式,高性能、高可用、可伸縮的搜索和分析系統。
Elasticsearch是用Java語言開發的,並作為Apache許可條款下的開放源碼發布,是一種流行的企業級搜索引擎。Elasticsearch主要用於雲計算中,能夠達到實時搜索,穩定,可靠,快速,並且安裝使用方便。官方客戶端在Java、.NET(C#)、PHP、Python、Apache Groovy、Ruby和許多其他語言中都是可用的。
Elasticsearch的使用場景
網上商場,搜索商品.
配合logStash和kibana進行日誌分析
為什麼要使用Elasticsearch
假設用關係型資料庫做搜索,當用戶在搜索框輸入「一名程式設計師」時,資料庫通常只能把這四個字去進行全部匹配。可是在文本中,可能會出現「他是一名合格的程式設計師」,這時候就沒有結果了,但是ES就可以實現檢索,而且速度極快。
Elasticsearch基本概念
Elasticsearch和關係型資料庫概念對應關係(方便理解ES的架構)
|
關係型資料庫 |
Elasticsearch |
|
資料庫 |
索引 |
|
數據表 |
類型 |
|
行 |
文檔 |
|
列 |
欄位 |
近實時(NRT)
ES是一個近實時的搜索引擎(平台),代表著從添加數據到能被搜索到只有很少的延遲。(大約是1s)
文檔
Elasticsearch是面向文檔的。可以把文檔理解為關係型資料庫中的一條記錄,文檔會被序列化成json格式,保存在Elasticsearch中。同樣json對象由欄位組成,每一個欄位都有自己的類型(字元串,數值,布爾,二進位,日期範圍類型)。當我們創建文檔時,如果不指定類型,Elasticsearch會幫我們自動匹配類型。每個文檔都一個ID(_id),你可以自己指定,也可以讓Elasticsearch自動生成。json格式,支援數組/嵌套,在一個索引裡面,你可以存儲任意多的文檔。
具體欄位類型和屬性的對應關係請參考官網:
//www.elastic.co/guide/en/elasticsearch/reference/6.0/mapping-types.html
索引
索引是具有某種相似特性的文檔集合。例如,您可以擁有客戶數據的索引、產品目錄的索引以及訂單數據的索引。索引的名稱必須全部是小寫字母。在單個集群中,您可以定義任意多個索引。
類型
一個索引可以有多個類型。例如一個索引下可以有文章類型,也可以有用戶類型,也可以有評論類型。

從6.0開始,type已經被逐漸廢棄。在7.0之前,一個index可以設置多個types。7.0開始一個索引只能創建一個type(默認是_doc,索引創建以後會自動創建)
節點
節點是一個Elasticsearch實例,本質上就是一個java進程。
節點的類型主要分為如下幾種:
master eligible節點
每個節點啟動後,默認就是master eligible節點,可以通過node.master: false 禁止,
master eligible可以參加選舉成為master節點,當第一個節點啟動後,它會將自己選為master節點。
data節點
可以保存數據的節點。負責保存分片數據。
Coordinating(協調)節點
負責接收客戶端請求,當請求發送到某個節點的時候,這個節點就成為了協調節點,將請求發送到合適的節點,最終把結果彙集到一起,返回給客戶端。每個節點默認都起到了協調節點的職責。
分片和分片副本
一個索引可能會存儲大量數據,這些數據可能超過單個節點的硬體限制。例如,十億個文檔的單個索引佔用了1TB的磁碟空間,可能不適合單個節點的磁碟,或者可能太慢而無法單獨滿足來自單個節點的搜索請求。
為了解決此問題,Elasticsearch提供了將索引細分為多個碎片的功能。創建索引時,只需定義所需的分片數量即可。每個分片本身就是一個功能齊全且獨立的「索引」,可以託管在群集中的任何節點上。
分片很重要,它可能分布在多個節點上。
在隨時可能發生故障的網路環境中,分片副本非常有用,為了防止某節點因某種原因離線。導致數據查詢不到,Elasticsearch允許將索引分片的一個或多個副本製作為所謂的副本分片(簡稱副本)。如果分片/節點發生故障,分片副本可提供高可用性(相當於一個主從)。
重要的是要注意:副本碎片永遠不會與從其複製原始碎片的節點分配在同一節點上。
例如:node1和node2的集群,如果分片1在node1節點,那麼分片1的副本就不可能分布在node1節點,因為如果這樣設計的話就沒意義了,如果node1掛了,那麼分片1 和它的副本都不可用了。
創建索引後,可以隨時動態更改副本數,但不能更改分片數,因為如果修改了分片數的話會導致分片上的數據錯亂。
Elasticsearch寫數據原理

寫請求發送到集群節點,比如發送到了node1,這個節點內部會去根據ID計算hash,計算這個ID到底屬於哪個主分片(ID通過hash以後對主分片的數量取余),比如這個時候計算出來屬於主分片2,這個時候node1節點會把請求轉發到node2節點的主分片2,進行寫入數據,當主分片2寫入數據成功以後,會把請求並行轉發到對應的兩個副本R2-1和R2-2,寫入成功以後返回到主分片,然後返回到node1,最後由node1返回到客戶端,報告寫入成功,如果寫入副本的時候失敗了,會把寫入失敗的分片移除(防止讀取數據的時候從這個分片中讀不到數據或者讀到臟數據)。
以上寫入都是寫入到記憶體中,寫入之前會先轉換為段(這就是近實時中說到的,有1S的延遲時間),同時伴隨有一個日誌文件的寫入,當寫入到記憶體以後過五分鐘以後,通過定時任務,才把數據寫到磁碟上,日誌文件的存在是為了解決定時任務5分鐘期間記憶體出現問題導致讀取不到記憶體數據的問題,如果記憶體出現問題,直接讀取日誌文件,寫到磁碟。
官網參考:
//www.elastic.co/guide/en/elasticsearch/reference/6.0/docs-replication.html
Elasticsearch讀數據原理
Elasticsearch查詢分為兩個階段: Query(查)和 Fetch(取),假設我們進行分頁查詢從 from到 from + size 的文檔資訊,下面是查詢流程:
from:代表前面忽略多少數據,size:代表查詢數據的條數
Query 階段
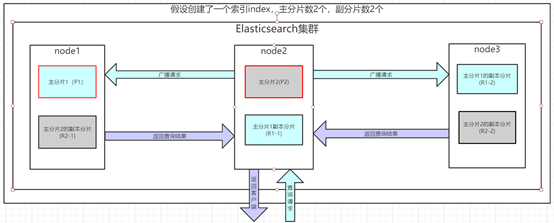
1、客戶端發送一個search請求到node2上,node節點此時就是協調節點。
2、接著node2以協調節點的身份廣播這個search請求到索引裡面每一個主分片或者副分片上(不為主副),每個分片執行查詢並進行排序,返回from+size個排序後的文檔 ID給協調節點node2。
3、然後node2負責將所有分片查詢返回的數據給合併到一個全局的排序的列表。
Fetch 階段
1、協調節點node2從全局排序列表中,選取 from 到 from + size 個文檔的 ID,並發送一個批量的查詢請求到相關的分片上(即發送批量文檔ID,根據ID查詢文檔)。
2、協調節點node2將查詢到的結果集返回到客戶端上。
官網參考:
//www.elastic.co/guide/en/elasticsearch/reference/6.0/docs-replication.html
倒排索引
倒排索引就是為什麼ES查詢如此快的原因
官網地址:
//www.elastic.co/guide/en/elasticsearch/guide/current/inverted-index.html
原理自行參考:通過分詞到記憶體中找ID,再通過ID到磁碟上查找數據
//blog.csdn.net/jiaojiao521765146514/article/details/83750548
//www.cnblogs.com/dreamroute/p/8484457.html
Elasticsearch安裝(linux)
下載安裝包
下載elasticsearch安裝包,版本7.9.1(目前最新版本)
下載地址://www.elastic.co/cn/downloads/elasticsearch
安裝elasticsearch
特別注意:
elasticsearch和kibana的安裝路徑不能有空格,要不然kibana啟動會報如下錯誤
把安裝包上傳到伺服器的安裝目錄並解壓
注意:
elasticsearch是不允許使用root用戶啟動的
在6.xx之前,可以通過root用戶啟動。但是後來發現黑客可以通過elasticsearch獲取root用戶密碼,所以為了安全性,在6版本之後就不能通過root啟動elasticsearch
新建操作用戶
|
groupadd elasticsearch useradd elasticsearch -g elasticsearch cd /usr/local/src/elasticsearch chown -R elasticsearch: elasticsearch elasticsearch-7.9.1 |
修改JVM參數
如果機器記憶體足夠的話也可以默認,默認1G
|
vi config/jvm.options |
修改如下內容:
|
-Xms512m -Xmx512m |
修改ES相關配置
|
vi config/elasticsearch.yml |
修改如下內容:
|
#集群名稱, 默認名稱為elasticsearch cluster.name=zhongan-elasticsearch #節點名稱 node.name=node-1 #允許訪問的IP network.host: 0.0.0.0 #管理管埠 http.port: 9200 #允許成為主節點的節點名稱 cluster.initial_master_nodes: [“node-1”] #數據保存路徑 path.data: /usr/local/src/elasticsearch/elasticsearch-7.9.1/data #日誌路徑 path.logs: /usr/local/src/elasticsearch/elasticsearch-7.9.1/logs |
修改sysctl.conf
|
vi /etc/sysctl.conf |
寫入如下內容:
|
vm.max_map_count=655360 #使配置生效 sysctl -p |
註:如果不修改,啟動會報如下錯誤:
vm最大虛擬記憶體,max_map_count[65530]太低,至少增加到[262144]
|
max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144] |
修改limits.conf
|
vi /etc/security/limits.conf |
寫入如下內容:
|
* soft nofile 65536 * hard nofile 131072 * soft nproc 2048 * hard nproc 4096 |
* 所有用戶
nofile – 打開文件的最大數目
noproc – 進程的最大數目
soft 指的是當前系統生效的設置值
hard 表明系統中所能設定的最大值
註:如果不修改,啟動會報如下錯誤:
最大文件描述符[4096]對於elasticsearch進程可能太低,至少增加到[65536]
|
descriptors [4096] for elasticsearch process likely too low, increase to at least [65536] |
修改90-nproc.conf
|
vi /etc/security/limits.d/90-nproc.conf |
寫入如下內容:
|
* soft nproc 4096 |
註:如果不修改,啟動會報如下錯誤:
用戶的最大執行緒數[2048]過低,增加到至少[4096]
|
max number of threads [2048] for user [tongtech] is too low, increase to at least [4096] |
啟動
|
cd /usr/local/src/elasticsearch/elasticsearch-7.9.1/bin #以後台方式運行 ./elasticsearch -d |
出現如下日誌表示啟動成功

防火牆設置
需要把ES相關埠添加白名單
|
#開啟9200埠 firewall-cmd –zone=public –add-port=9200/tcp –permanent #開啟9300埠 firewall-cmd –zone=public –add-port=9300/tcp –permanent #重啟防火牆 systemctl restart firewalld |
驗證
瀏覽器訪問://ip:9200/

Elasticsearch重啟
|
ps -ef | grep elastic kill -9 PID |
Kibana安裝(linux)
下載安裝包
下載kibana安裝包,版本7.9.1(需要和ES版本一致)
下載地址://www.elastic.co/cn/downloads/kibana

安裝Kibana
把安裝包上傳到伺服器的安裝目錄並解壓
修改配置文件
|
vi /usr/local/src/elasticsearch/kibana-7.9.1-linux-x86_64/config/kibana.yml |
修改如下配置
|
#管理端埠 server.port: 5601 #允許訪問的IP server.host: “0.0.0.0” #管理端語言,默認未英文,修改為中文 i18n.locale: “zh-CN” #ES地址 elasticsearch.hosts: [“//localhost:9200”] |
啟動kibana
|
cd /usr/local/src/elasticsearch/kibana-7.9.1-linux-x86_64/bin nohup ./kibana –allow-root & |
防火牆設置
把kibana埠設置為白名單
|
#開啟5601埠 firewall-cmd –zone=public –add-port=5601/tcp –permanent #重啟防火牆 systemctl restart firewalld |
訪問kibana
瀏覽器訪問://ip:5601/
出現如下介面表示啟動成功

Kibana重啟
|
netstat -apn|grep 5601 kill -9 PID |
Elasticsearch用戶設置
完成Elasticsearch和kibana的安裝以後發現管理端可以直接訪問數據,這樣是不安全的,下面就是Elasticsearch用戶相關介紹
用戶新增
Elasticsearch內部已經內置了一些用戶,只需要設置這些用戶的密碼,並修改配置文件即可。
修改配置文件
修改elasticsearch.yml文件加入如下配置,啟用節點上的Elasticsearch安全功能
|
xpack.security.enabled: true xpack.license.self_generated.type: basic xpack.security.transport.ssl.enabled: true |
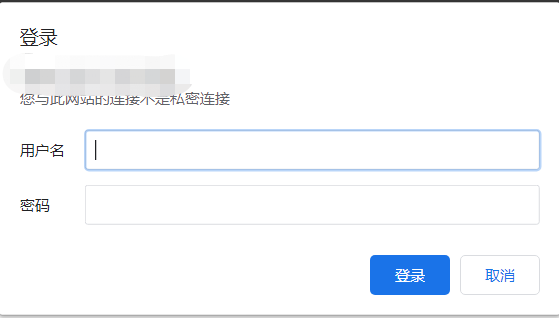
重啟ES,訪問ES,這個時候需要用戶名密碼訪問,如下截圖:
設置用戶密碼
ES bin目錄執行命令,依次設置用戶密碼
|
./elasticsearch-setup-passwords interactive |
用戶登錄

Kibana配置
這個時候訪問kibana發現也需要登錄
需要修改kibana的配置文件:kibana.yml
加入以下配置:
|
#ES的登錄用戶名 elasticsearch.username: “elastic” # ES的登錄用戶名密碼,需要對應 elasticsearch.password: “123456” |
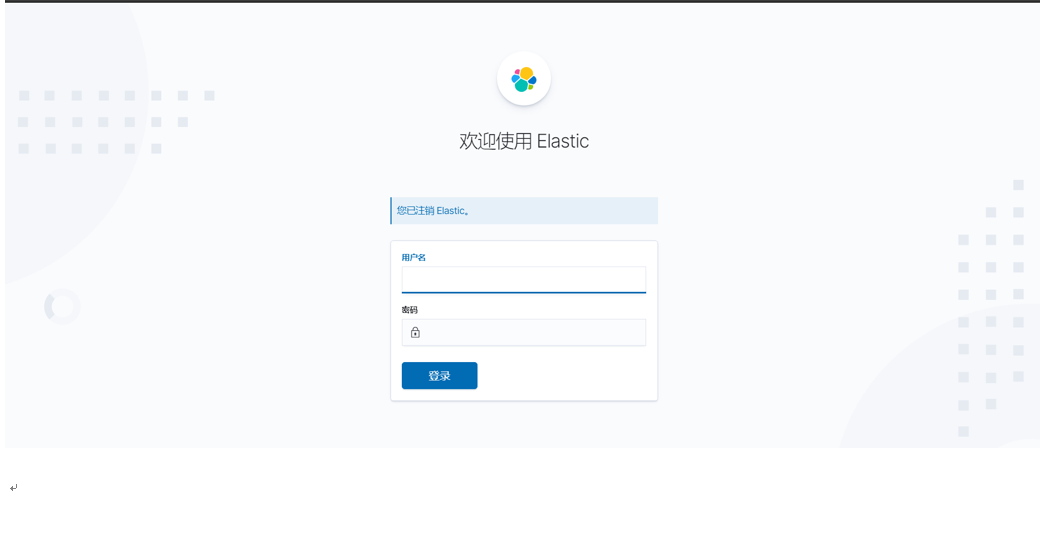
重啟kibana,訪問kibana
分詞器安裝
Elasticsearch內部已經內置了一些分詞器,無需進一步配置即可在任何索引中使用
官網地址:
//www.elastic.co/guide/en/elasticsearch/reference/current/analysis-analyzers.html
|
Standard |
默認分詞器 按詞分類 小寫處理 |
|
Simple |
非字母文本劃分為多個詞 小寫處理 |
|
Stop |
小寫處理 停用詞過濾(the,a, is) |
|
Whitespace |
按空格切分 |
|
Keyword |
不分詞,當成一整個term輸出 |
|
Patter |
通過正則表達式進行分詞 默認是 \W+(非字母進行分隔) |
|
Language |
提供了 30 多種常見語言的分詞器 |
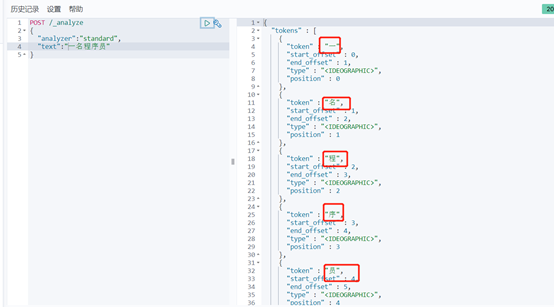
Standard分詞器簡單操作:
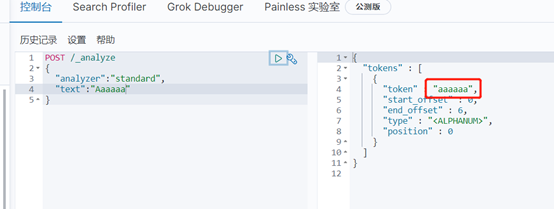
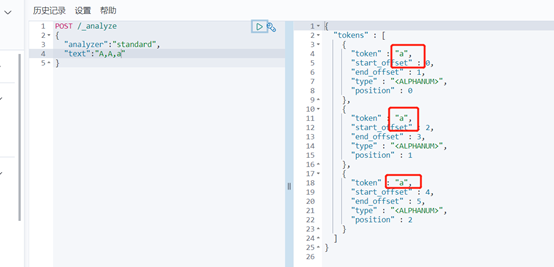
其他分詞器自行嘗試後看效果。。。
一般使用ES內置分詞器即可,但是內置分詞器對中文的分詞效果較差,一段中文經過內置分詞器分詞以後會變為一個一個的漢字,所以需要用分詞器插件,對中文分詞時可以實現在詞語之間分詞。
常用中文分詞器,IK、jieba、THULAC等,推薦使用IK分詞器。
IK分詞器
下載ik分詞器安裝包,版本7.9.1(需要和ES的版本對應)
下載地址://github.com/medcl/elasticsearch-analysis-ik/releases

安裝
安裝包解壓,在ES的plugins目錄下創建一個ik文件夾,把解壓後的內容放到該文件夾即可。
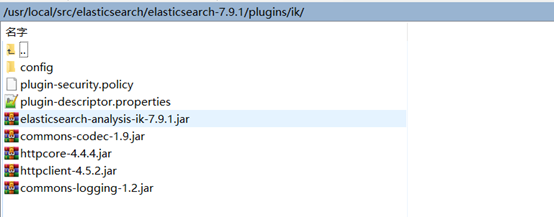
驗證
重啟ES,執行如下命令:
|
POST /_analyze { “analyzer”: “ik_max_word”, “text”: “一名程式設計師” } |

ElasticSearch基本API
索引操作
創建索引
官網地址:
//www.elastic.co/guide/en/elasticsearch/reference/current/indices-create-index.html
|
PUT /test { “settings”: { “number_of_shards”: “2”, //分片數 “number_of_replicas”: “0”, //副本數 “write.wait_for_active_shards”: 1 //操作之前必須處於活動狀態的分片分片數 } } |
修改索引
|
PUT test/_settings { “number_of_replicas” : “2”//修改索引的副本數位2 } |
刪除索引
|
DELETE /test |
文檔操作
插入數據
|
//指定id POST /test/_doc/1 { “id”:1001, “name”:”張三”, “age”:20, “sex”:”男” } |
|
//不指定id es幫我們自動生成 POST /test/_doc { “id”:1002, “name”:”三哥”, “age”:20, “sex”:”男” } |
更新數據
在Elasticsearch中,文檔數據是不能修改的,但是可以通過覆蓋的方式進行更新
|
POST /test/_doc/1 { “id”:1001, “name”:”張三四五”, “age”:20, “sex”:”男” } |
局部更新
其實Elasticsearch內部對局部更新的實際執行和全量替換方式是幾乎一樣的,其步驟如下
1、內部先獲取到對應的文檔;
2、將傳遞過來的field更新到文檔的json中(這一步實質上也是一樣的);
3、將老的文檔標記為deleted(到一定時候才會物理刪除);
4、將修改後的新的文檔創建出來
|
POST /test/_update/1 { “doc”:{ “age”:46 } } |
刪除數據
|
DELETE /test/_doc/1 |
根據ID搜索數據
|
GET /test/_doc/h5a3n3QBhTn7IjwCRtEV #去掉元數據查詢 GET /test/_source/h5a3n3QBhTn7IjwCRtEV #去掉元數據並且返回指定欄位 GET /test/_source/h5a3n3QBhTn7IjwCRtEV?_source=id,name |
根據屬性查詢
|
GET /test/_search?q=age:20 //查詢age為20的 |
返回節點說明
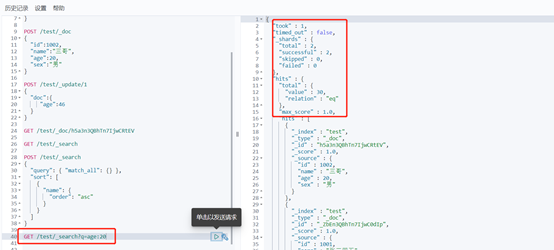
took Elasticsearch運行查詢需要多長時間(以毫秒為單位)
timed_out 搜索請求是否超時
_shards 搜索了多少碎片,並對多少碎片成功、失敗或跳過進行了細分。
max_score 找到最相關的文檔的得分
搜索全部數據
|
GET /test/_search //默認最多返回10條數據 GET /test/_search?size=1000 //指定查詢的條數 |
高級檢索
查詢年齡等於23的
|
POST /test/_search { “query” : { “match” : { “age” : 20 } } } |
查詢地址是南京市或者上海市的數據
|
GET /test/_search { “query”: { “match”: { “address”: “南京市 上海市” } } } |
查詢地址是(南京市 上海市)的數據
|
GET /test/_search { “query”: { “match_phrase”: { “address”: “南京市 上海市” } } } |
注意:
match 中如果加空格,那麼會被認為兩個單詞,包含任意一個單詞將被查詢到。
match_parase 將忽略空格,將該字元認為一個整體,會在索引中匹配包含這個整體的文檔。
查詢年齡大於20 並且性別是男的
|
POST /test/_search { “query”: { “bool”: { “filter”: { “range”: { “age”: { “gt”: 20 } } }, “must”: { “match”: { “sex”: “男” } } } } } |
聚合
|
avg :平均值 max:最大值 min:最小值 sum:求和 |
查詢前100條數據的年齡平均值
|
POST /test/_search { “aggs”: { “test”: { “avg”: { “field”: “age” } } }, “size”: 100 } |
分頁查詢
from跳過開頭的結果數;size查詢的結果數,默認為10
|
GET /test/_search?from=1&size=10 |
淺分頁
淺分頁,它的原理很簡單,就是查詢前20條數據,然後截斷前10條,只返回10-20的數據。這樣其實白白浪費了前10條的查詢
|
GET /test/_search { “sort”: [ { “age”: { “order”: “desc” } } ], “query”: { “match”: { “name”: “張三” } }, “size”: 10, “from”: 0 } |
scroll 深分頁
scroll 深分頁,使用scroll,每次只能獲取一頁的內容,然後會返回一個scroll_id。根據返回的這個scroll_id可以不斷地獲取下一頁的內容,因為查一次獲取下一頁,所以scroll並不適用於有跳頁的情景
scroll=5m表示設置scroll_id保留5分鐘可用。
使用scroll必須要將from設置為0。
size決定後面每次調用_search搜索返回的數量
|
GET /test/_search?scroll=5m { “size”: 10, “from”: 0, “sort”: [ { “_id”: { “order”: “desc” } } ] } 會返回一個: “_scroll_id” : “FGluY2x1ZGVfY29udGV4dF91dWlkDnF1ZXJ5VGhlbkZldGNoAhRzWmJzbjNRQmhUbjdJandDbWRjMgAAAAAAABHZFlRKaUV2aGRMVEM2LXM1enN6c0dLb0EUc3Bic24zUUJoVG43SWp3Q21kYzIAAAAAAAAR2hZUSmlFdmhkTFRDNi1zNXpzenNHS29B” 以後調用: GET _search/scroll { “scroll_id”: “FGluY2x1ZGVfY29udGV4dF91dWlkDnF1ZXJ5VGhlbkZldGNoAhRzWmJzbjNRQmhUbjdJandDbWRjMgAAAAAAABHZFlRKaUV2aGRMVEM2LXM1enN6c0dLb0EUc3Bic24zUUJoVG43SWp3Q21kYzIAAAAAAAAR2hZUSmlFdmhkTFRDNi1zNXpzenNHS29B”, “scroll”: “5m” } 刪除scroll_id DELETE _search/scroll/ FGluY2x1ZGVfY29udGV4dF91dWlkDnF1ZXJ5VGhlbkZldGNoAhRzWmJzbjNRQmhUbjdJandDbWRjMgAAAAAAABHZFlRKaUV2aGRMVEM2LXM1enN6c0dLb0EUc3Bic24zUUJoVG43SWp3Q21kYzIAAAAAAAAR2hZUSmlFdmhkTFRDNi1zNXpzenNHS29B
刪除所有scroll_id DELETE _search/scroll/_all |
結構化查詢
term查詢
term 主要用於精確匹配哪些值,比如數字,日期,布爾值等
|
POST /test/_search { “query” : { “term” : { “age” : 20 } } } |
terms查詢
terms 跟 term 有點類似,但 terms 允許指定多個匹配條件。 如果某個欄位指定了多個值,那麼文檔需要一起去做匹配:
|
POST /test/_search { “query” : { “terms” : { “age” : [30,46] } } } |
range查詢
range 過濾允許我們按照指定範圍查找一批數據:
|
gt 大於 gte 大於等於 lt 小於 lte 小於等於 |
|
POST /test/_search { “query”: { “range”: { “age”: { “gte”: 25, “lte”: 50 } } } } |
exists查詢
exists 查詢可以用於查找文檔中是否包含指定欄位或沒有某個欄位,類似於SQL語句中的 IS_NULL 條件,包含這個欄位就返回這條數據
|
POST /test/_search { “query”: { “exists”: { “field”: “address” } } } |
match查詢
match 查詢是一個標準查詢,不管你需要全文本查詢還是精確查詢基本上都要用到它。如果你使用 match 查詢一個全文本欄位,它會在真正查詢之前先用分詞器去分析一下查詢字元;如果用 match 下指定了一個確切值,在遇到數字,日期,布爾值的字元串時,它將為你搜索你給定的值,不再分詞:
|
POST /test/_search { “query” : { “match” : { “name” : “三個” } } } |
bool查詢
bool 查詢可以用來合併多個條件查詢結果的布爾邏輯,它包含一下操作符:
|
must 多個查詢條件的完全匹配,相當於 and 。 must_not 多個查詢條件的相反匹配,相當於 not 。 should 至少有一個查詢條件匹配, 相當於 or 。 |
這些參數可以分別繼承一個查詢條件或者一個查詢條件的數組:
|
POST /test/_search { “query”: { “bool”: { “must”: { “term”: { “sex”: “男” } }, “must_not”: { “term”: { “age”: “29” } }, “should”: [ { “term”: { “sex”: “男” } }, { “term”: { “id”: 1003 } } ] } } } |
Elasticsearch整合Springboot
版本對應關係
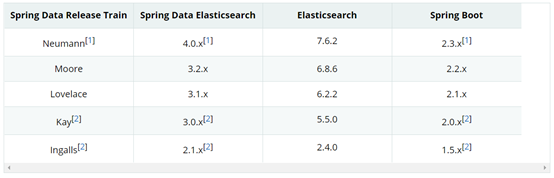
由於Elasticsearch版本為7.9.1,所以Springboot版本必須至少為2.3.x,此處採用目前官網最新版本:2.3.4.RELEASE
導入依賴
|
<parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>2.3.4.RELEASE</version> <relativePath/> </parent>
<!–elasticsearch包–> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-elasticsearch</artifactId> </dependency>
<!–單元測試–> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> <exclusions> <exclusion> <groupId>org.junit.vintage</groupId> <artifactId>junit-vintage-engine</artifactId> </exclusion> </exclusions> </dependency> |
配置類
配置類裡面配置了連接ES的連接資訊,相當於配置了一個數據源
|
import org.elasticsearch.client.RestHighLevelClient; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.data.elasticsearch.client.ClientConfiguration; import org.springframework.data.elasticsearch.client.RestClients; import org.springframework.data.elasticsearch.config.AbstractElasticsearchConfiguration;
@Configuration public class RestClientConfig extends AbstractElasticsearchConfiguration {
@Override @Bean public RestHighLevelClient elasticsearchClient() { final ClientConfiguration clientConfiguration = ClientConfiguration.builder().connectedTo(“10.0.2.102:9200”) .withBasicAuth(“elastic”, “123456”).build(); return RestClients.create(clientConfiguration).rest(); } } |
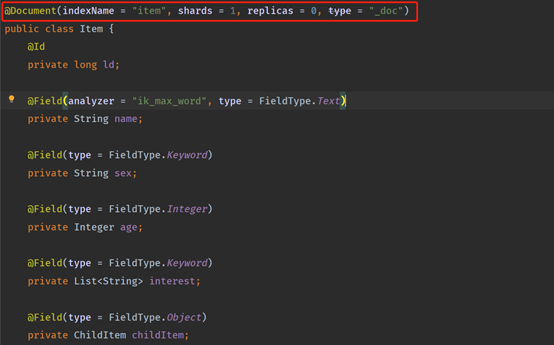
創建實體類
實體類上加上Document註解,指定索引名稱和主分片副分片數量,type可以不用指定了,默認一個索引只有一個類型,屬性加上對應的註解,具體屬性和欄位對應關係文檔章節已經說明,請自行參考。
analyzer = “ik_max_word”是指定IK分詞器,說明name欄位分詞的時候需要根據IK分詞器去分詞,不採用ES內置的分詞器,也可以用ES內置的分詞器。
測試
注入elasticsearchRestTemplate
|
@Autowired private ElasticsearchRestTemplate elasticsearchRestTemplate; |
索引創建
|
/** * 創建索引 */ @Test public void createIndex() throws Exception { IndexOperations indexOperations = elasticsearchRestTemplate.indexOps(Item.class); boolean exists = indexOperations.exists(); System.out.println(“索引是否已經存在:”+exists); } |
數據新增
|
/** * 測試新增數據 */ @Test void save() { SimpleDateFormat simpleDateFormat = new SimpleDateFormat(“yyyy-MM-dd HH:mm:ss”); String str = simpleDateFormat.format(new Date()); Goods goods = new Goods(1093l, “”, “測試數據” + str, 37400, 20, 100, “//m.360buyimg.com/mobilecms/s720x720_jfs/t1/10441/9/5525/162976/5c177debEaf815b43/3aa7d4dc182cc4d9.jpg!q70.jpg.webp”, “//m.360buyimg.com/mobilecms/s720x720_jfs/t1/10441/9/5525/162976/5c177debEaf815b43/3aa7d4dc182cc4d9.jpg!q70.jpg.webp”, 10, str, str, “10000243333000”, 558, “測試”, “”, “”, 1, 1, 1, 5L); /*方法1*/ Goods save = elasticsearchRestTemplate.save(goods); System.out.println(save.toString());
/*方法2*/ // IndexQuery indexQuery = new IndexQueryBuilder() // .withId(goods.getId()+””) // .withObject(goods) // .build(); // String documentId = elasticsearchRestTemplate.index(indexQuery,IndexCoordinates.of(“goods”)); // System.out.println(documentId); } |
數據查詢詳情
|
/** * 測試通過ID查詢 */ @Test void searchById() { Goods goods = elasticsearchRestTemplate.get(“1092”, Goods.class, IndexCoordinates.of(“goods”)); System.out.println(goods.toString()); } |
注意:
查詢的時候如果是根據ID查詢,那麼這個ID指的是文檔id(_id),而且查詢返回的實體裡面的id也是文檔id(分頁查詢返回結果中的實體id也是文檔id),所以最好讓文檔id和業務數據的id保持一致,如果不一致,請注意實體id和ES文檔id類型兼容,因為ES默認生成的文檔id是字元串,如果業務id為long類型的話查詢會報錯。
數據修改
|
/** * 測試修改數據 */ @Test void update() { Map<String, Object> map = new HashMap<>(); map.put(“name”, “測試數據修改”); UpdateQuery updateQuery = UpdateQuery.builder(“1093”).withDocument(Document.from(map)).build(); UpdateResponse updateResponse = elasticsearchRestTemplate.update(updateQuery, IndexCoordinates.of(“goods”)); System.out.println(updateResponse.getResult()); } |
分頁查詢
|
/** * 分頁查詢 */ @Test void getByMatch() { MatchQueryBuilder matchQueryBuilder = QueryBuilders.matchQuery(“name”, “測試”); NativeSearchQueryBuilder nativeSearchQueryBuilder = new NativeSearchQueryBuilder(); //id排序 FieldSortBuilder sortBuilder = SortBuilders.fieldSort(“id”).order(SortOrder.ASC); //分頁 Pageable pageable = PageRequest.of(0, 10); nativeSearchQueryBuilder.withFilter(matchQueryBuilder).withSort(sortBuilder).withPageable(pageable); NativeSearchQuery nativeSearchQuery = nativeSearchQueryBuilder.build(); SearchHits<Goods> goods = elasticsearchRestTemplate .search(nativeSearchQuery, Goods.class, IndexCoordinates.of(“goods”)); goods.getSearchHits().forEach(info -> { Goods good = info.getContent(); System.out.println(good.toString()); }); } |


