Apache Hudi和Presto的前世今生
- 2020 年 9 月 22 日
- 筆記
一篇由Apache Hudi PMC Bhavani Sudha Saktheeswaran和AWS Presto團隊工程師Brandon Scheller分享Apache Hudi和Presto集成的一篇文章。
1. 概述
Apache Hudi 是一個快速迭代的數據湖存儲系統,可以幫助企業構建和管理PB級數據湖,Hudi通過引入upserts、deletes和增量查詢等原語將流式能力帶入了批處理。這些特性使得統一服務層可提供更快、更新鮮的數據。Hudi表可存儲在Hadoop兼容的分散式文件系統或者雲上對象存儲中,並且很好的集成了 Presto, Apache Hive, Apache Spark 和Apache Impala。Hudi開創了一種新的模型(數據組織形式),該模型將文件寫入到一個更受管理的存儲層,該存儲層可以與主流查詢引擎進行互操作,同時在項目演變方面有了一些有趣的經驗。
本部落格討論Presto和Hudi集成的演變,同時討論Presto-Hudi查詢即將到來的文件Listing和查詢計劃優化。
2. Apache Hudi
Apache Hudi(簡稱Hudi)提供在DFS上存儲超大規模數據集,同時使得流式處理如果批處理一樣,該實現主要是通過如下兩個原語實現。
- Update/Delete記錄: Hudi支援更新/刪除記錄,使用文件/記錄級別索引,同時對寫操作提供事務保證。查詢可獲取最新提交的快照來產生結果。
- Change Streams: Hudi也支援增量獲取表中所有更新/插入/刪除的記錄,從指定時間點開始進行增量查詢。
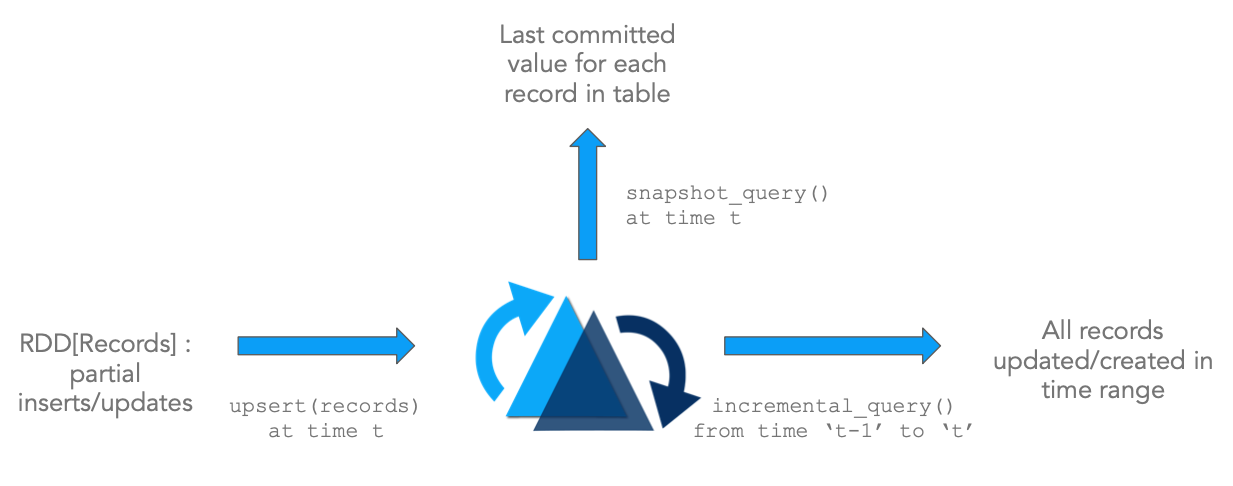
上圖說明了Hudi的原語,配合這些原語可以直接在DFS抽象之上解鎖流/增量處理功能。這和直接從Kafka Topic消費事件,然後使用狀態存儲來增量計算臨時結果類似,該架構有很多優點。
- 提升效率: 攝取數據經常需要處理更新(例如CDC),刪除(法律隱私條例)以及強制主鍵約束來確保數據品質。然而由於缺乏標準工具,數據工程師往往需要使用批處理作業來重新處理整天的事件或者每次運行時重新載入上游所有數據,這會導致浪費大量的資源。由於Hudi支援記錄級別更新,只需要重新處理表中更新/刪除的記錄,大大提升了處理效率,而無需重寫表的所有分區或事件。
- 更快的ETL/派生管道: 還有一種普遍情況,即一旦從外部源攝取數據,就使用Apache Spark/Apache Hive或任何其他數據處理框架構建派生的數據管道,以便為各種用例(如數據倉庫、機器學習功能提取,甚至僅僅是分析)構建派生數據管道。通常該過程再次依賴於以程式碼或SQL表示的批處理作業,批量處理所有輸入數據並重新計算所有輸出結果。通過使用增量查詢(而不是常規快照查詢)查詢一個或多個輸入表,從而只處理來自上游表的增量更改,然後對目標派生表執行upsert或delete操作,可以顯著加快這種數據管道的速度,如第一個圖所示。
- 更新鮮的數據訪問: 通常我們會添加更多的資源(例如記憶體)來提高性能指標(例如查詢延遲)。Hudi從根本上改變了數據集的傳統管理方式,這可能是大數據時代出現以來的第一次。增量地進行批處理可以使得管道運行時間少得多。相比以前的數據湖,現在數據可更快地被查詢。
- 統一存儲: 基於以上三個優點,在現有數據湖上進行更快、更輕的處理意味著不需要僅為了獲得接近實時數據的訪問而使用專門存儲或數據集市。
2.1 Hudi表和查詢類型
2.1.1 表類型
Hudi支援如下兩種類型表
Copy On Write (COW): 使用列式存儲格式(如parquet)存儲數據,在寫入時同步更新版本/重寫數據。
Merge On Read (MOR): 使用列式存儲格式(如parquet)+ 行存(如Avro)存儲數據。更新被增量寫入delta文件,後續會進行同步/非同步壓縮產生新的列式文件版本。
下表總結了兩種表類型的trade-off。
| Trade-off | CopyOnWrite | MergeOnRead |
|---|---|---|
| 數據延遲 | 更高 | 更低 |
| 更新開銷 (I/O) | 高(重寫整個parquet文件) | 更低 (寫入增量日誌文件) |
| Parquet文件大小 | 更小(高update (I/0) 開銷) | 更大 (低updaet開銷) |
| 寫放大 | 更低 (決定與Compaction策略) |
2.1.2 查詢類型
Hudi支援如下查詢類型
快照查詢: 查詢給定commit/compaction的表的最新快照。對於Merge-On-Read表,通過合併基礎文件和增量文件來提供近實時數據(分鐘級);對於Copy-On-Write表,對現有Parquet表提供了一個可插拔替換,同時提供了upsert/delete和其他特性。
增量查詢: 查詢給定commit/compaction之後新寫入的數據,可為增量管道提供變更流。
讀優化查詢: 查詢給定commit/compaction的表的最新快照。只提供最新版本的基礎/列式數據文件,並可保證與非Hudi表相同的列式查詢性能。
下表總結了不同查詢類型之間的trade-off。
| Trade-off | 快照 | 讀優化 |
|---|---|---|
| 數據延遲 | 更低 | 更高 |
| 查詢延遲 | COW: 與parquet表相同。MOR: 更高 (合併基礎/列式文件和行存增量文件) | 與COW快照查詢有相同列式查詢性能 |
下面動畫簡單演示了插入/更新如何存儲在COW和MOR表中的步驟,以及沿著時間軸的查詢結果。其中X軸表示每個查詢類型的時間軸和查詢結果。
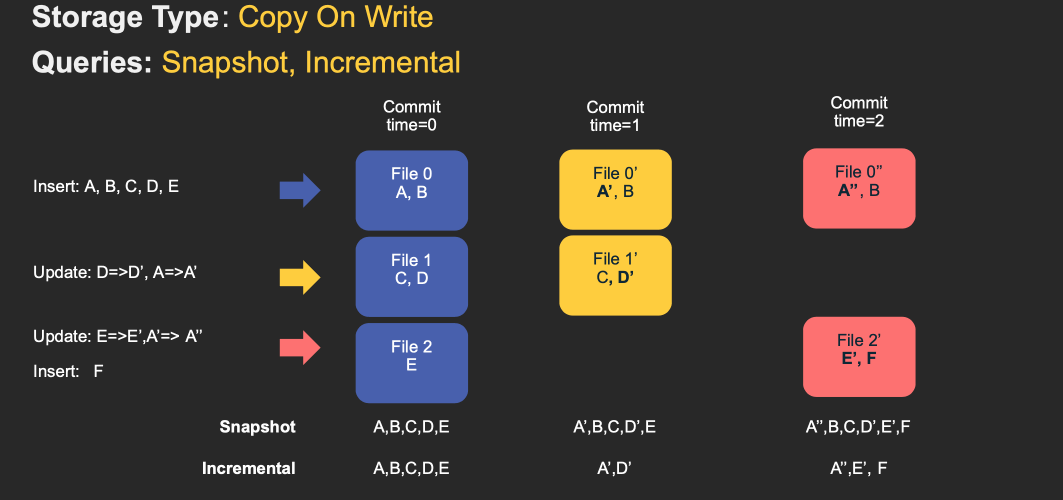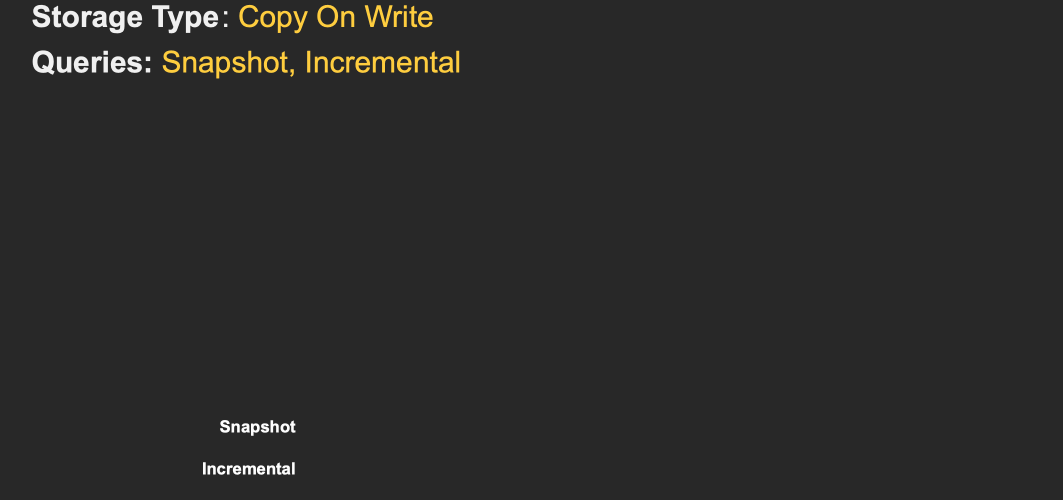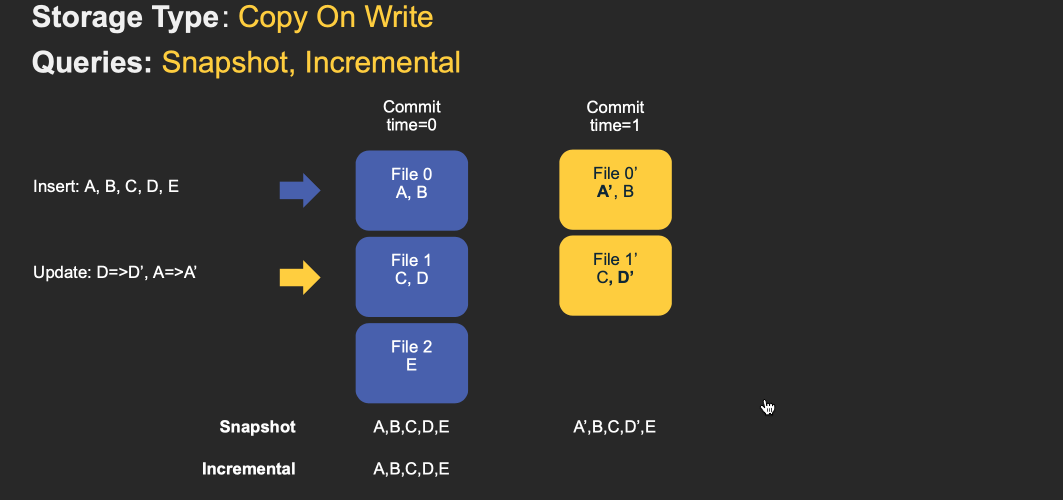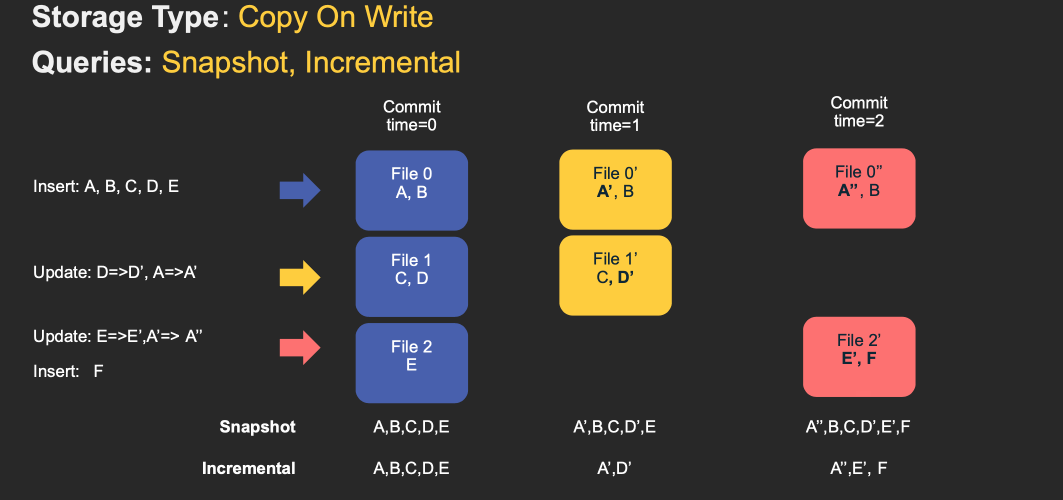
注意,作為寫操作的一部分,表的commit被完全合併到表中。對於更新,包含該記錄的文件將使用所有已更改記錄的新值重新寫入。對於插入,優先會將記錄寫入到每個分區路徑中最小文件,直到它達到配置的最大大小。其他剩餘的記錄都將寫入新的文件id組中,會保證再次滿足大小要求。

MOR和COW在攝取數據方面經歷了相同步驟。更新將寫入屬於最新文件版本的最新日誌(delta)文件,而不進行合併。對於插入,Hudi支援2種模式:
- 寫入log文件 – 當Hudi表可索引日誌文件(例如HBase索引和即將到來的記錄級別索引)。
- 寫入parquet文件 – 當Hudi表不能索引日誌文件(例如布隆索引)。
增量日誌文件後面通過時間軸中的壓縮(compaction)操作與基礎parquet文件合併。這種表類型是最通用、高度高級的,為寫入提供很大靈活性(指定不同的壓縮策略、處理突發性寫入流量等)和查詢提供靈活性(例如權衡數據新鮮度和查詢性能)。
3. Presto
3.1 早期Presto集成方案
Hudi設計於2016年中後期。那時我們就著手與Hadoop生態系統中的查詢引擎集成。為了在Presto中實現這一點,正如社區建議的那樣,我們引入了一個自定義註解@UseFileSplitsFromInputFormat。任何註冊的Hive表(如果有此註解)都將通過調用相應的inputformat的getSplits()方法(而不是Presto Hive原生切片載入邏輯)來獲取切片。通過Presto查詢的Hudi表,只需簡單調用HoodieParquetInputFormat.getSplits(). 集成非常簡單只,需將相應的Hudi jar包放到<presto_install>/plugin/hive-hadoop2/目錄下。它支援查詢COW Hudi表,並讀取MOR Hudi表的優化查詢(只從壓縮的基本parquet文件中獲取數據)。在Uber,這種簡單的集成已經支援每天超過100000次的Presto查詢,這些查詢來自使用Hudi管理的HDFS中的100PB的數據(原始數據和模型表)。
3.2 移除InputFormat.getSplits()
調用inputformat.getSplits()是個簡單的集成,但是可能會導致對NameNode的大量RPC調用,以前的集成方法有幾個缺點。
- 從Hudi返回的InputSplits不夠。Presto需要知道每個InputSplit返回的文件狀態和塊位置。因此,對於每次切片乘以載入的分區數,這將增加2個額外的NameNode RPC調用。有時,NameNode承受很大的壓力,會觀察到背壓。
- 此外對於Presto Split計算中載入的每個分區(每個
loadPartition()調用),HoodieParquetInputFormat.getSplits()將被調用。這導致了冗餘的Hudi表元數據Listing,其實可以被屬於從查詢掃描的表的所有分區復用。
我們開始重新思考Presto-Hudi的整合方案。在Uber,我們通過在Hudi上添加一個編譯時依賴項來改變這個實現,並在BackgroundHiveSplitLoader構造函數中實例化HoodieTableMetadata一次。然後我們利用Hudi Api過濾分區文件,而不是調用HoodieParquetInputFormat.getSplits(),這大大減少了該路徑中NameNode調用次數。
為了推廣這種方法並使其可用於Presto-Hudi社區,我們在Presto的DirectoryLister介面中添加了一個新的API,它將接受PathFilter對象。對於Hudi表,我們提供了這個PathFilter對象HoodieROTablePathFilter,它將負責過濾為查詢Hudi表而預先列出的文件,並獲得與Uber內部解決方案相同的結果。
這一變化是從0.233版本的Presto開始提供,依賴Hudi版本為0.5.1-incubating。由於Hudi現在是一個編譯時依賴項,因此不再需要在plugin目錄中提供Hudi jar文件。
3.3 Presto支援查詢Hudi MOR表
我們看到社區有越來越多人對使用Presto支援Hudi MOR表的快照查詢感興趣。之前Presto只支援查詢Hudi表讀優化查詢(純列式數據)。隨著該PR //github.com/prestodb/presto/pull/14795被合入,現在Presto(0.240及後面版本)已經支援查詢MOR表的快照查詢,這將通過在讀取時合併基本文件(parquet數據)和日誌文件(avro數據)使更新鮮的數據可用於查詢。
在Hive中,這可以通過引入一個單獨的InputFormat類來實現,該類提供了處理切片的方法,並引入了一個新的RecordReader類,該類可以掃描切片以獲取記錄。對於使用Hive查詢MOR Hudi表,在Hudi中已經有類似類可用:
InputFormat–org.apache.hudi.hadoop.realtime.HoodieParquetRealtimeInputFormatInputSplit–org.apache.hudi.hadoop.realtime.HoodieRealtimeFileSplitRecordReader–org.apache.hudi.hadoop.realtime.HoodieRealtimeRecordReader在Presto中支援這一點需要理解Presto如何從Hive表中獲取記錄,並在該層中進行必要的修改。因為Presto使用其原生的ParquetPageSource而不是InputFormat的記錄讀取器,Presto將只顯示基本Parquet文件,而不顯示來自Hudi日誌文件的實時更新,後者是avro數據(本質上與普通的讀優化Hudi查詢相同)。
為了讓Hudi實時查詢正常工作,我們確定並進行了以下必要更改:
-
向可序列化HiveSplit添加額外的元數據欄位以存儲Hudi切片資訊。Presto-Hive將其拆分轉換為可序列化的HiveSplit以進行傳遞。因為它需要標準的切片,所以它將丟失從FileSplit擴展的複雜切片中包含的任何額外資訊的上下文。我們的第一個想法是簡單地添加整個切片作為
HiveSplit的一個額外的欄位。但這並不起作用,因為複雜的切片不可序列化,而且還會複製基本切片數據。相反我們添加了一個
CustomSplitConverter介面。它接受一個自定義切片並返回一個易於序列化的String->String Map,其中包含來自自定義切片的額外數據。為了實現這點,我們還將此Map作為一個附加欄位添加到Presto的HiveSplit中。我們創建了HudiRealtimeSplitConverter來實現用於Hudi實時查詢的CustomSplitConverter介面。 -
從HiveSplit的額外元數據重新創建Hudi切片。現在我們已經掌握了HiveSplit中包含的自定義切片的完整資訊,我們需要在讀取切片之前識別並重新創建
HoodieRealtimeFileSplit。CustomSplitConverter介面還有另一個方法,它接受普通的FileSplit和額外的split資訊映射,並返回實際複雜的FileSplit,在本例中是HudiRealtimeFileSplit。 -
使用
HoodieParquetRealtimeInputFormat中的HoodieRealtimeRecordReader讀取重新創建的HoodieRealtimeFileSplit。Presto需要使用新的記錄讀取器來正確處理HudiRealtimeFileSplit中的額外資訊。為此,我們引入了與第一個注釋類似的另一個註解@UseRecordReaderFromInputFormat。這指示Presto使用Hive記錄游標(使用InputFormat的記錄讀取器)而不是PageSource。Hive記錄游標可以理解重新創建的自定義切片,並基於自定義切片設置其他資訊/配置。
有了這些變更,Presto用戶便可查詢Hudi MOR表中更新鮮的數據了。
4. 下一步計劃
下面是一些很有意思的工作(RFCs),可能也需要在Presto中支援。
RFC-12: Bootstrapping Hudi tables efficiently
ApacheHudi維護每個記錄的元數據,使我們能夠提供記錄級別的更新、唯一的鍵語義和類似資料庫的更改流。然而這意味著,要利用Hudi的upsert和增量處理能力,用戶需要重寫整個數據集,使其成為Hudi表。這個RFC提供了一種機制來高效地遷移他們的數據集,而不需要重寫整個數據集,同時還提供了Hudi的全部功能。
這將通過在新的引導Hudi表中引用外部數據文件(來自源表)的機制來實現。由於數據可能駐留在外部位置(引導數據)或Hudi表的basepath(最近的數據)下,FileSplits將需要在這些位置上存儲更多的元數據。這項工作還將利用並建立在我們當前添加的Presto MOR查詢支援之上。
增量查詢允許我們從源Hudi表中提取變更日誌。時間點查詢允許在時間T1和T2之間獲取Hudi表的狀態。這些已經在Hive和Spark中得到支援。我們也在考慮在Presto中支援這個特性。
在Hive中,通過在JobConf中設置一些配置來支援增量查詢,例如-query mode設置為INCREMENTAL、啟動提交時間和要使用的最大提交數。在Spark中有一個特定的實現來支援增量查詢—IncrementalRelation。為了在Presto中支援這一點,我們需要一種識別增量查詢的方法。如果Presto不向hadoop Configuration對象傳遞會話配置,那麼最初的想法是在metastore中將同一個表註冊為增量表。然後使用查詢謂詞獲取其他詳細資訊,如開始提交時間、最大提交時間等。
Hudi write client和Hudi查詢需要對文件系統執行listStatus操作以獲得文件系統的當前視圖。在Uber,HDFS基礎設施為Listing做了大量優化,但對於包含數千個分區的大型數據集以及每個分區在雲/對象存儲上有數千個文件的大型數據集來說,這可能是一個昂貴的操作。上面的RFC工作旨在消除Listing操作,提供更好的查詢性能和更快的查找,只需將Hudi的時間軸元數據逐漸壓縮到表狀態的快照中。
該方案旨在解決:
- 存儲和維護最新文件的元數據
- 維護表中所有列的統計資訊,以幫助在掃描之前有效地修剪文件,這可以在引擎的查詢規劃階段使用。
為此,Presto也需要一些變更。我們正在積極探索在查詢規劃階段利用這些元數據的方法。這將是對Presto-Hudi集成的重要補充,並將進一步降低查詢延遲。
Upsert是Hudi表上一種流行的寫操作,它依賴於索引將傳入記錄標記為Upsert。HoodieIndex在分區或非分區數據集中提供記錄id到文件id的映射,實現有BloomFilters/Key ranges(用於臨時數據)和Apache HBase(用於隨機更新)支援。許多用戶發現Apache HBase(或任何類似的key-value-store-backed索引)很昂貴,並且增加了運維開銷。該工作試圖提出一種新的索引格式,用於記錄級別的索引,這是在Hudi中實現的。Hudi將存儲和維護記錄級索引(有HFile、RocksDB等可插拔存儲實現支援)。這將被writer(攝取)和reader(攝取/查詢)使用,並將顯著提高upsert性能,而不是基於join的方法,或者是用於支援隨機更新工作負載的布隆索引。這是查詢引擎在列出文件之前修剪文件時可以利用這些資訊的另一個領域。我們也在考慮一種在查詢時利用Presto中的元數據的方法。
5. 總結
像Presto這樣的查詢引擎是用戶了解Hudi優勢的入口。隨著不斷增長的社區和活躍的開發路線圖,Hudi中有許多有趣的工作,由於Hudi在上面的工作上投入了大量精力,因此只需要與Presto這樣的系統進行深度集成。為此,我們期待著與Presto社區合作。我們歡迎您的建議回饋,並鼓勵您作出貢獻 ,與我們聯繫。
英文鏈接://prestodb.io/blog/2020/08/04/prestodb-and-hudi


