你必須知道的容器監控 (3) Prometheus
- 2019 年 11 月 5 日
- 筆記
本篇已加入《.NET Core on K8S學習實踐系列文章索引》,可以點擊查看更多容器化技術相關係列文章。上一篇介紹了Google開發的容器監控工具cAdvisor,但是其提供的操作介面較為簡陋,且不支援監控多Host,實用性有待提高。因此,本篇會介紹一個流行的生產級監控工具,不,準確說來應該是一個監控方案,它就是Prometheus!
# 實驗環境:阿里雲ECS主機(兩台),CentOS 7.4
一、Prometheus簡介
1.1 關於Prometheus

Prometheus是由SoundCloud開發的開源監控系統的開源版本。2016年,由Google發起的雲原生基金會CNCF (Cloud Native Computing Foundation) 將其納入為其第二大開源項目(第一大開源項目是Kubernetes)。Prometheus提供了一整套的包括監控數據搜集、存儲、處理、可視化和告警的完整解決方案。
Prometheus官網地址:https://prometheus.io/
Prometheus GitHub:https://github.com/prometheus/prometheus/
1.2 Prometheus架構
Prometheus在其官方github上貼出的其架構圖如下:
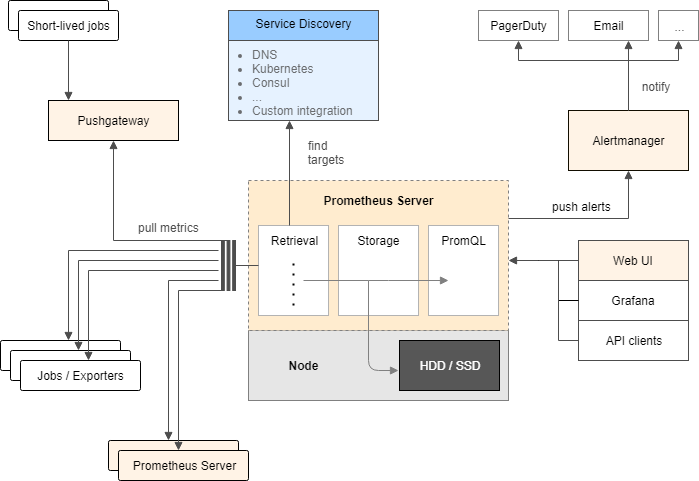
為了更容易理解這個架構,這裡我們採用園友Cloud Man(他也是本文參考資料《每天5分鐘玩轉Docker》作者)總結的下圖,它去掉了一些部分,只保留了最重要的組件,可以幫助我們避免注意力分散。
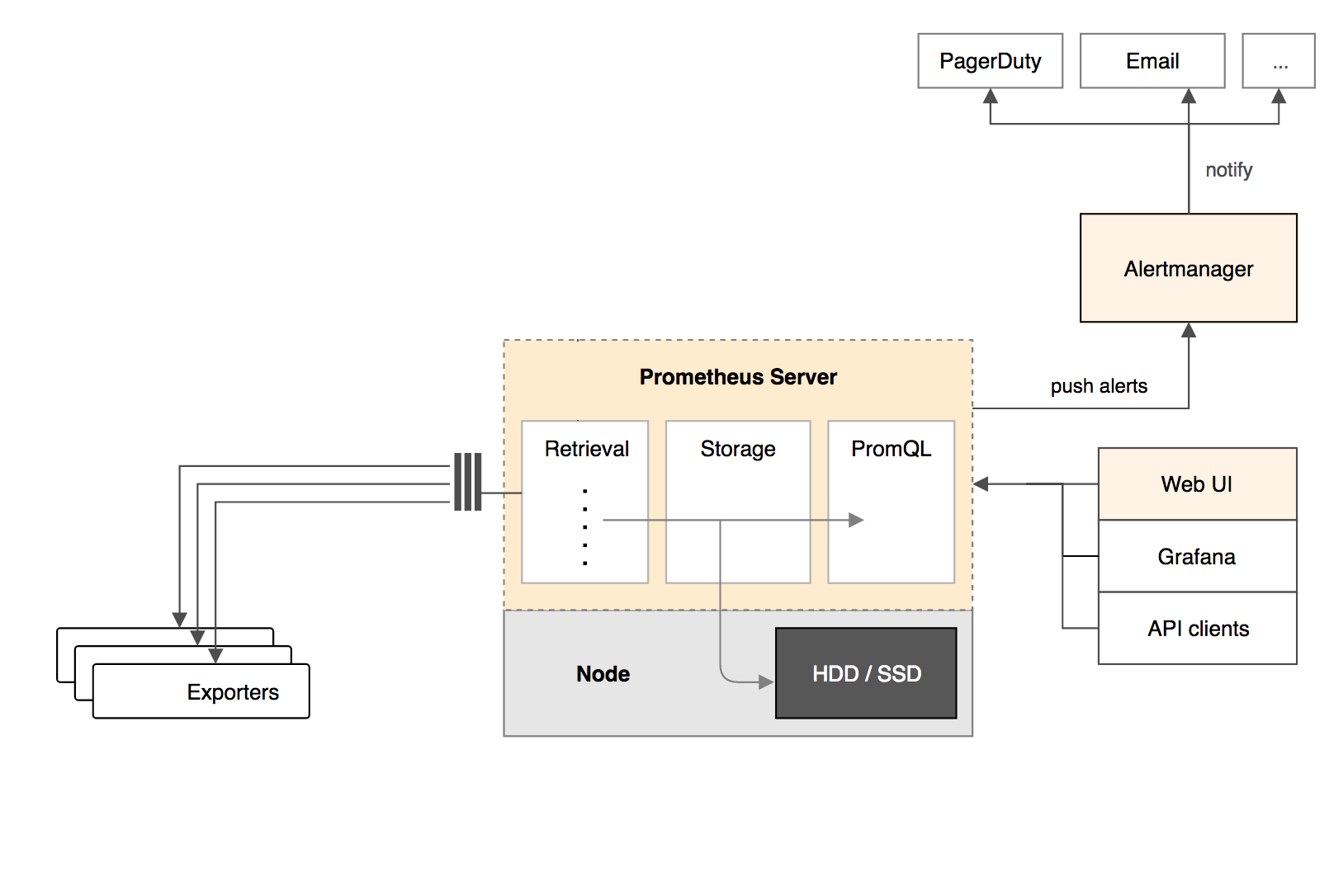
從上圖看來,我們著重需要關注以下幾個核心組件:
(1)Prometheus Server:負責從Exporter中拉取和存儲監控數據,並提供一套查詢語言(PromQL)供用戶使用。
(2)Exporter:負責收集目標對象(如Host或Container)的性能數據,並通過HTTP介面供Prometheus Server獲取。
(3)可視化組件 Grafana:獲取Prometheus Server提供的監控數據並通過Web UI的方式完美展現數據。
(4)AlertManager:負責根據告警規則和預定義的告警方式發出例如Email、Webhook之類的告警。
1.3 Prometheus數據模型
Prometheus 中存儲的數據為時間序列,是由 metric 的名字和一系列的標籤(鍵值對)唯一標識的,不同的標籤則代表不同的時間序列。
- metric 名字:該名字應該具有語義,一般用於表示 metric 的功能,例如:http_requests_total, 表示 http 請求的總數。其中,metric 名字由 ASCII 字元,數字,下劃線,以及冒號組成,且必須滿足正則表達式 [a-zA-Z_:][a-zA-Z0-9_:]*。
- 標籤:使同一個時間序列有了不同維度的識別。例如 http_requests_total{method=”Get”} 表示所有 http 請求中的 Get 請求。當 method=”post” 時,則為新的一個 metric。標籤中的鍵由 ASCII 字元,數字,以及下劃線組成,且必須滿足正則表達式 [a-zA-Z_:][a-zA-Z0-9_:]*。
- 樣本:實際的時間序列,每個序列包括一個 float64 的值和一個毫秒級的時間戳。
時間序列格式:
<metric name>{<label name>=<label value>, ...}
示例:
api_http_requests_total{method="POST", handler="/messages"}
之前有分享過另一個時序資料庫InfluxDB,它也是一個不錯的時序資料庫,經常用來作為監控數據的存儲。OK,關於Prometheus的簡介就到這兒,下面那我們開始動手將Prometheus初步用起來。
二、Prometheus實踐
2.1 實驗環境說明
此次實驗會搭建一個基於Prometheus的監控系統,用於監控兩台阿里雲ECS主機,監控目標為Host和容器兩個層次。
| 主機 | IP | 運行組件 |
| 阿里雲ECS1 | 47.102.140.100 | Prometheus Server、Grafana、Exporter(Node Exporter & cAdvisor) |
| 阿里雲ECS2 | 47.102.140.101 | Exporter(Node Exporter & cAdvisor) |
Note:Prometheus支援多種Exporter,這裡我們使用Node Exporter 和 cAdvisor。其中,Node Exporter用於收集Host相關數據,cAdvisor用於收集容器相關數據。Node Exporter 和 cAdvisor 會運行在所有實驗主機上。
2.2 運行Node Exporter
在兩台主機上執行以下命令運行Node Exporter:
docker run -d -p 9100:9100 -v "/proc:/host/proc" -v "/sys:/host/sys" -v "/:/rootfs" prom/node-exporter --path.procfs /host/proc --path.sysfs /host/sys --collector.filesystem.ignored-mount-points "^/(sys|proc|dev|host|etc)($|/)"
執行成功後,會創建一個Node Exporter的容器實例,訪問兩台主機的地址 http://[Your Host IPs]:9100/metrics,你可以看到如下圖所示的資訊:

如果能看到上圖,說明你的Node Exporter可以為Prometheus提供該Host的監控數據了。
2.3 運行cAdvisor
這部分我們在上一篇《容器監控(2)cAdvisor》中已經介紹過了,這裡我們繼續在這兩台主機中執行以下命令安裝運行cAdvisor(如果已經運行了,就不必再執行了):
docker run --volume=/:/rootfs:ro --volume=/var/run:/var/run:rw --volume=/sys:/sys:ro --volume=/var/lib/docker/:/var/lib/docker:ro --volume=/dev/disk/:/dev/disk:ro --publish=8080:8080 --detach=true --name=cadvisor google/cadvisor:latest
同樣,我們也可以通過訪問 http://[Your Host IPs]:8080/metrics 來查看cAdvisor提供的監控數據,如下圖所示:

如果能看到上圖,說明你的cAdvisor可以為Prometheus提供該Host的監控數據了。
2.4 運行Prometheus Server
這裡我們在主機A(表中的ECS1)上執行以下命令來運行Prometheus Server:
docker run -d -p 9090:9090 -v /edc/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml --name prometheus prom/prometheus
此外,這裡的prometheus.yml 是Prometheus Server的配置文件,需要事先編輯好並放到指定目錄下(這裡是/edc/prometheus/目錄下)讓docker可以讀取到,內容如下:
global: scrape_interval: 15s evaluation_interval: 15s external_labels: monitor: 'edc-lab-monitor' alerting: alertmanagers: - static_configs: - targets: # - alertmanager:9093 rule_files: # - "first.rules" # - "second.rules" scrape_configs: - job_name: 'prometheus' static_configs: - targets: ['47.102.140.100:9090'] - job_name: 'host' static_configs: - targets: ['47.102.140.100:9100','47.102.140.101:9100'] - job_name: 'container' static_configs: - targets: ['47.102.140.100:8080','47.102.140.101:8080']
這裡需要注意的配置是scrape_configs中的static_configs,裡面定義了Prometheus會從哪些Exporter中抓取監控數據,這裡指定了兩台雲主機的Node Exporter與cAdvisor。
執行成功後,Prometheus容器已經創建好了,訪問這台ECS1的地址:http://[ECS1 Host IP]:9090/metrics,如下圖所示:
然後,我們直接訪問http://[ECS1 Host IP]:9090,會進入Prometheus主頁:
單擊菜單Status => Targets,會看到所有監控的目標Exporters:
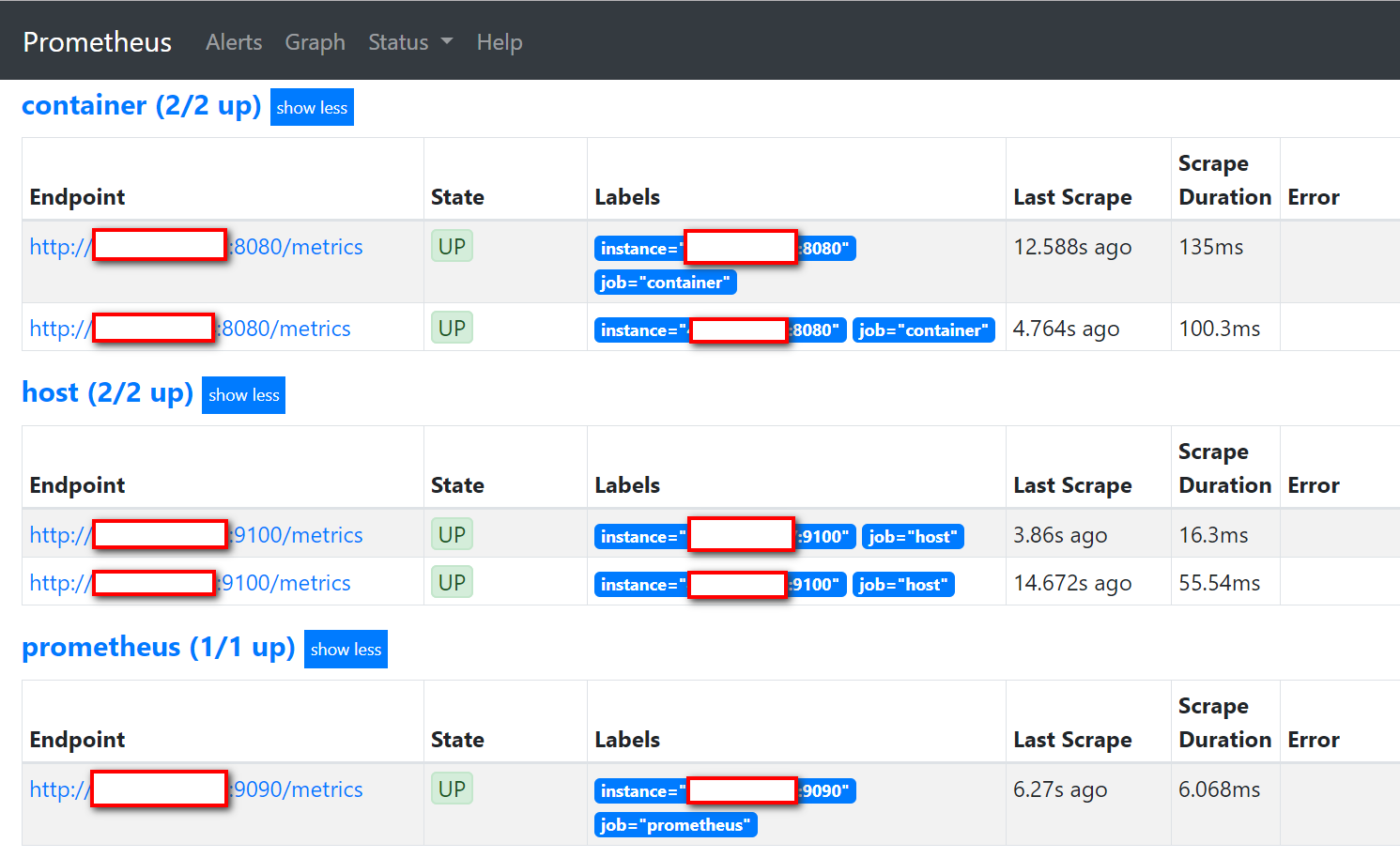
可以看到所有監控目標的狀態都是Up,表示Prometheus Server可以正常獲取監控數據。
2.5 運行Grafana
這裡我們繼續在主機A(ECS1)上執行以下命令運行Grafana:
docker run -d -i -p 3000:3000 -e "GF_SERVER_ROOT_URL=http://grafana.server.name" -e "GF_SECURITY_ADMIN_PASSWORD=secret" grafana/grafana
-e “GF_SECURITY_ADMIN_PASSWORD=secret” 則指定了Admin用戶的密碼為secret,這裡你也可以隨你的意願改為你可以記得住的。
執行成功後,我們可以通過訪問:http://[ECS1 Host IP]:3000 看到以下Grafana的登錄介面

下面幾個步驟用於初始化配置Grafana讓其可以展示監控數據儀錶盤Dashboard:
Step1.登陸之後進入主頁,選擇引導頁,從”add data source”開始,第一步選擇時序資料庫,這裡選擇Prometheus

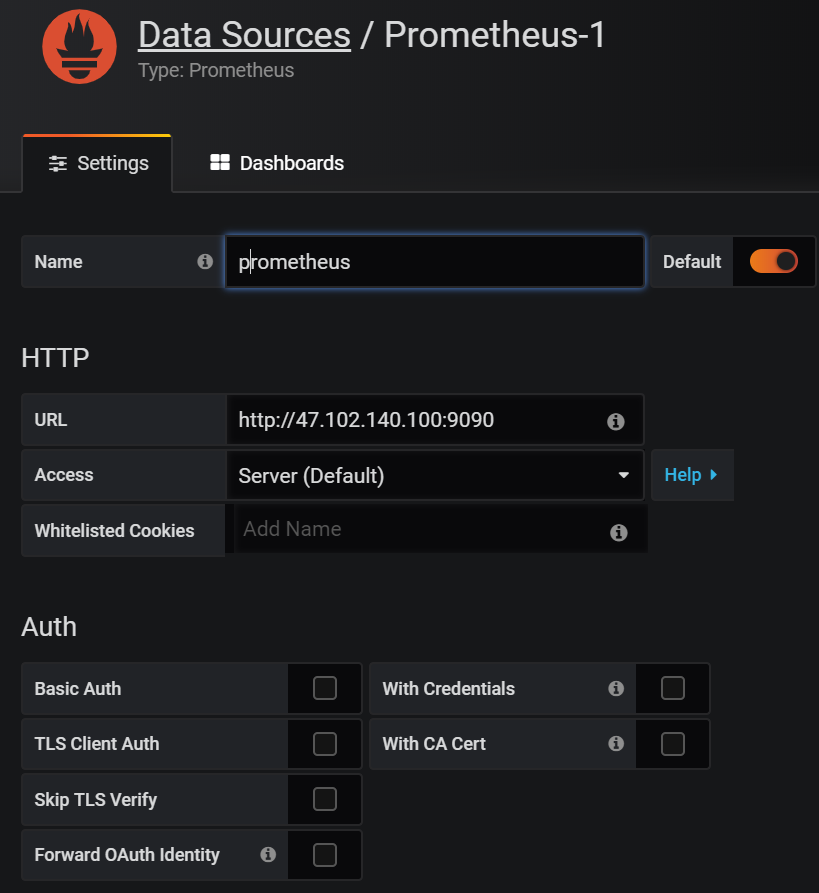
Step2.配置Prometheus Server地址及Name,完成後點擊“Save&Test”:
Step3.回到引導主頁,選擇Add Dashboard按鈕,進入Dashboard頁,選擇Import Dashboard,進入下圖:
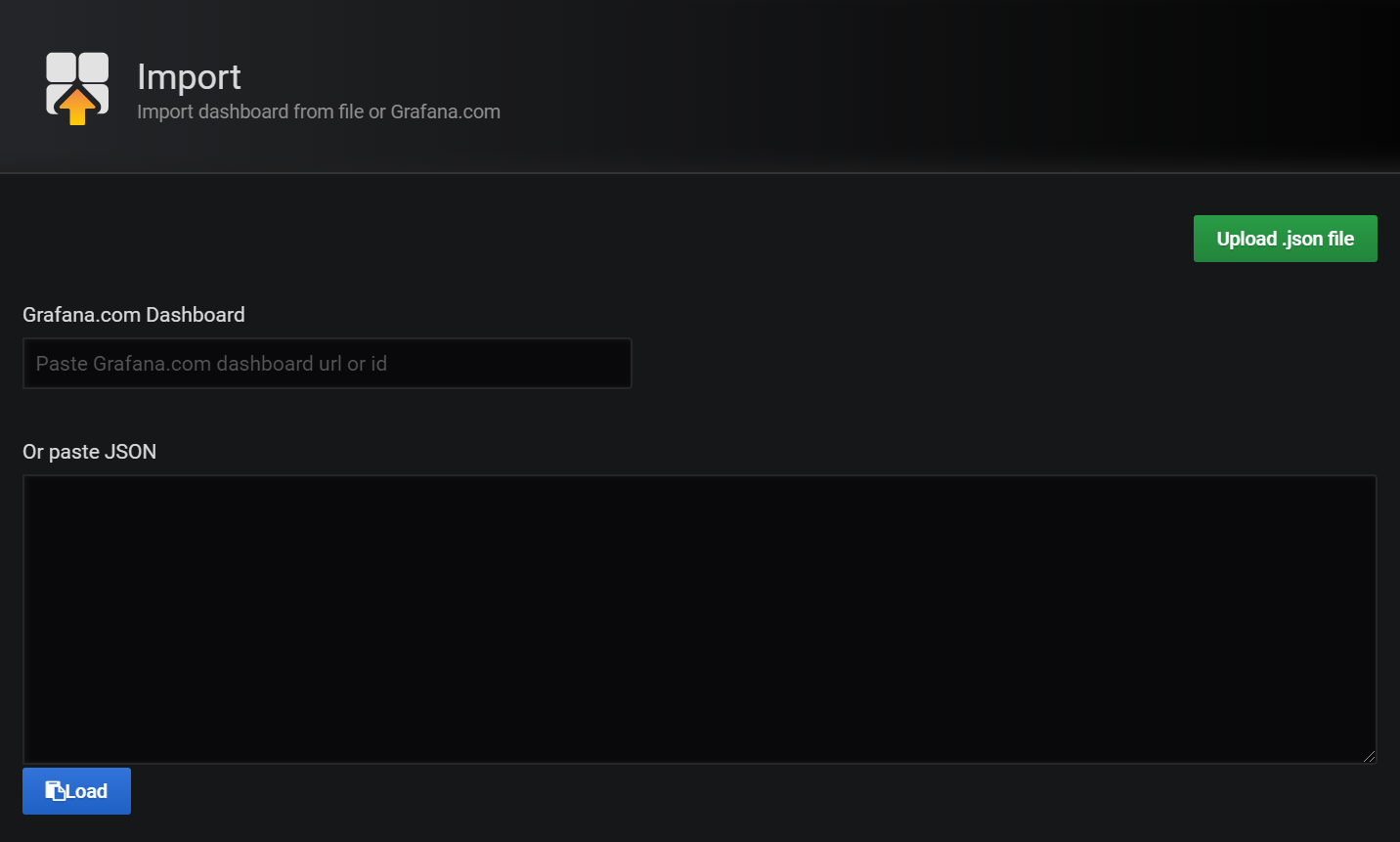
這裡選擇的Dashboard,你可以在grafana的dashboard官網的搜索你喜歡的關於Docker監控主題的各種Dashboard樣式。這裡我們要做的就是將其ID(這裡我選擇的一個Docker監控的dashboard ID是193,其餘的我不記得了)複製到圖中的文本框中(當然,你也可以下載json並粘貼進去)。
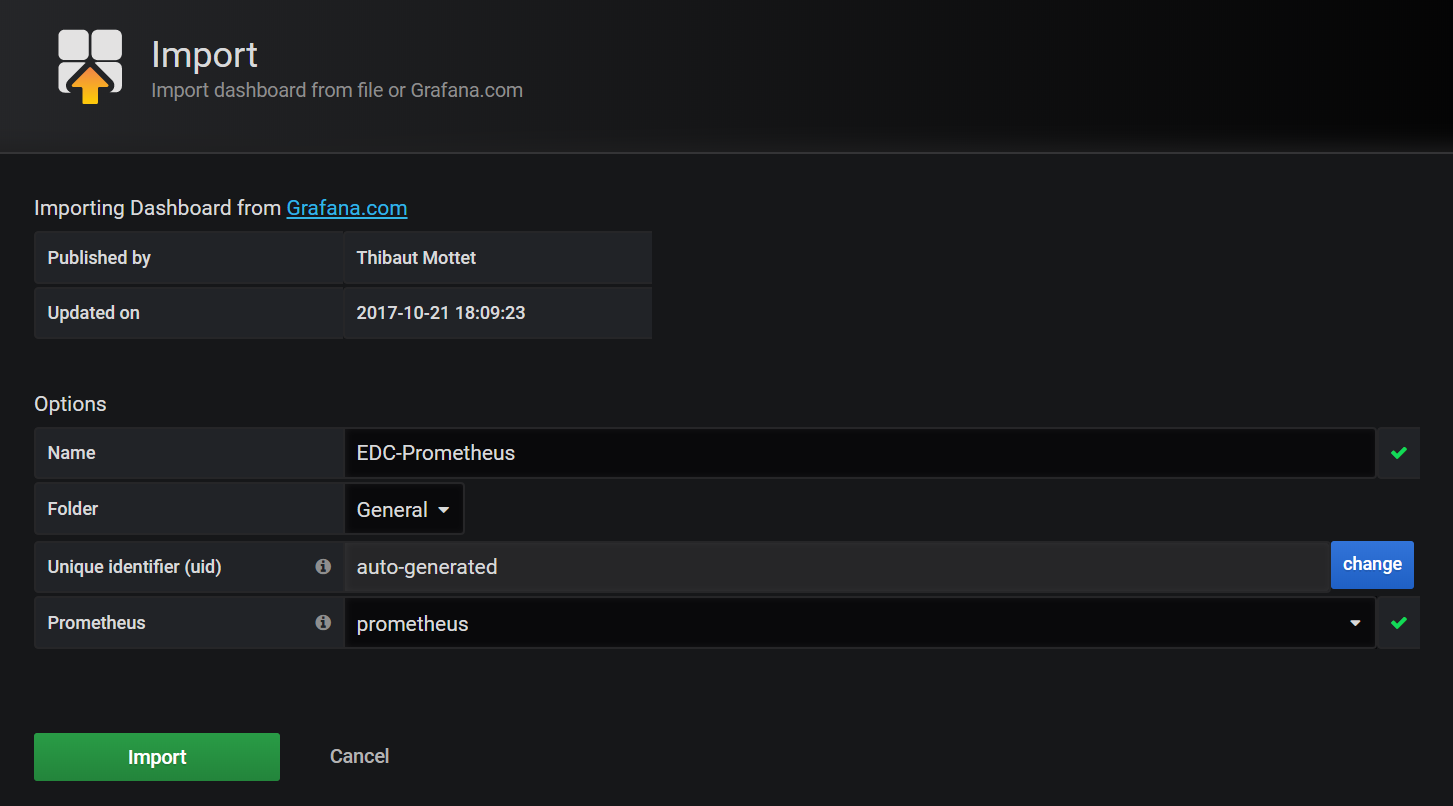
Step4.Grafana識別之後,就會顯示其詳情讓你確認。在確認頁選擇Prometheus的數據源,這裡選擇我們剛剛添加的數據源,然後點擊Import即可完成導入。
完成以上導入Dashboard步驟之後,這裡我的Dashboard列表有了三個Dashboard:
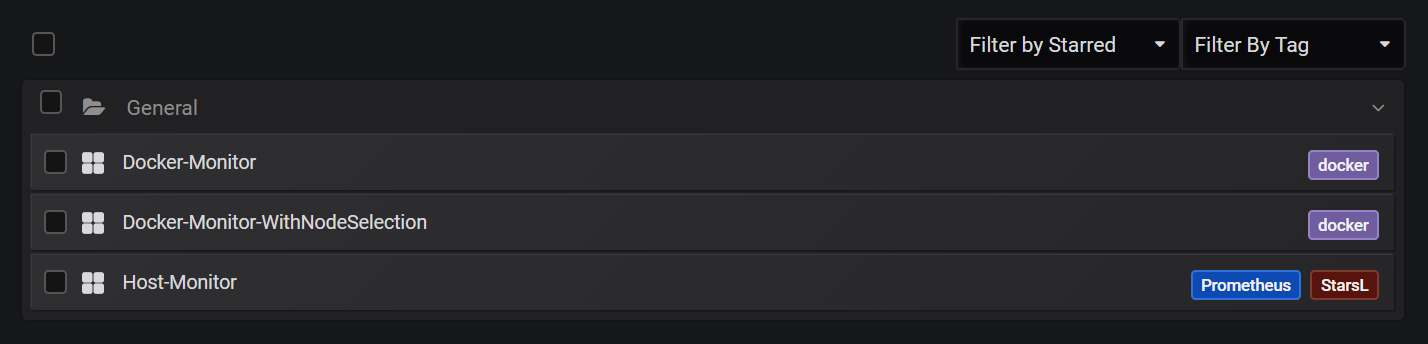
這裡我們主要關注第一個(Docker-Monitor)和第三個(Host-Monitor),先來看第一個Dashboard,它主要是為我們展示Docker層次的監控面板:
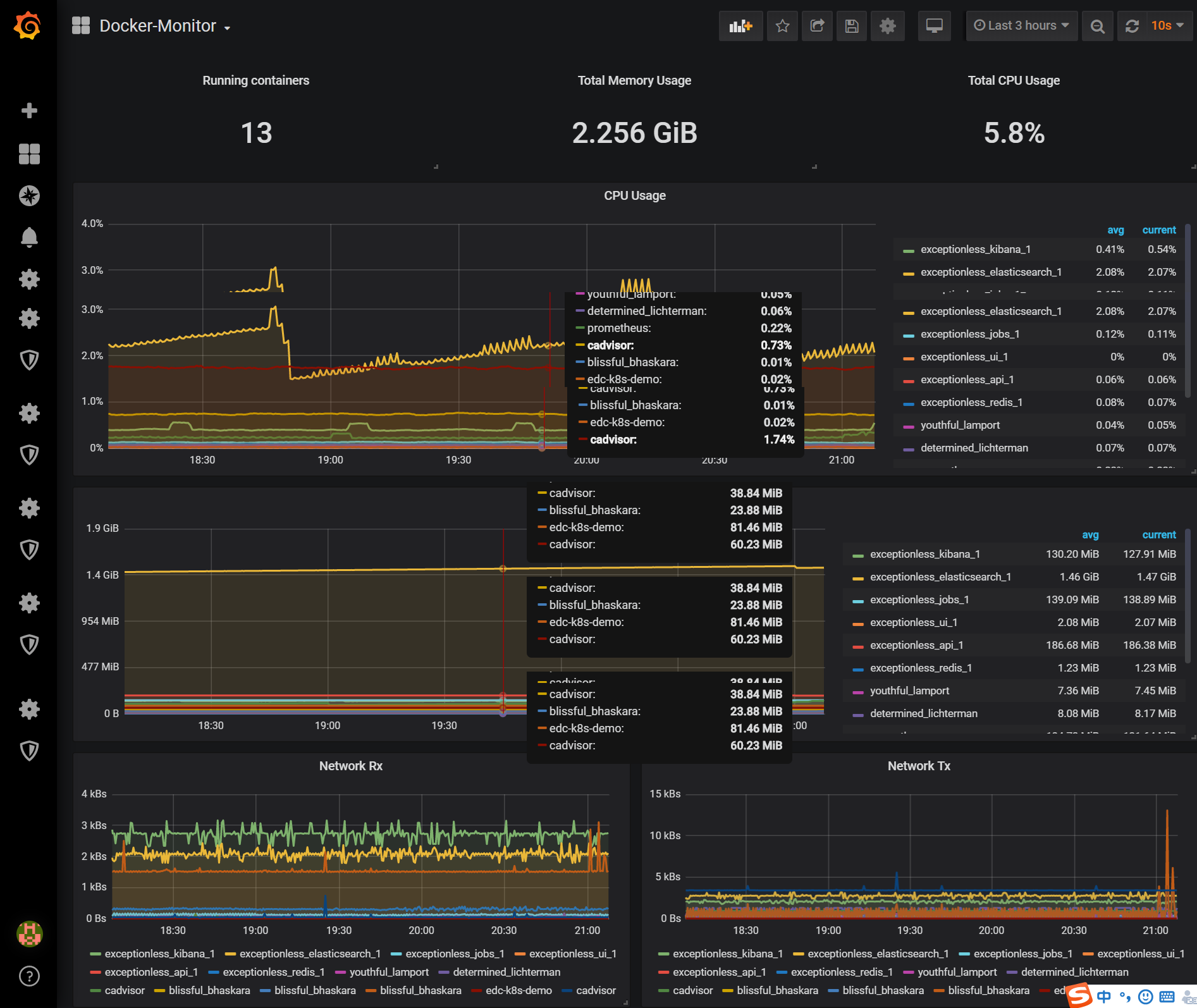
從上圖可以看到兩台Host中的所有容器監控數據一覽無遺。
第三個面板(Host-Monitor)的展示面板如下圖所示:
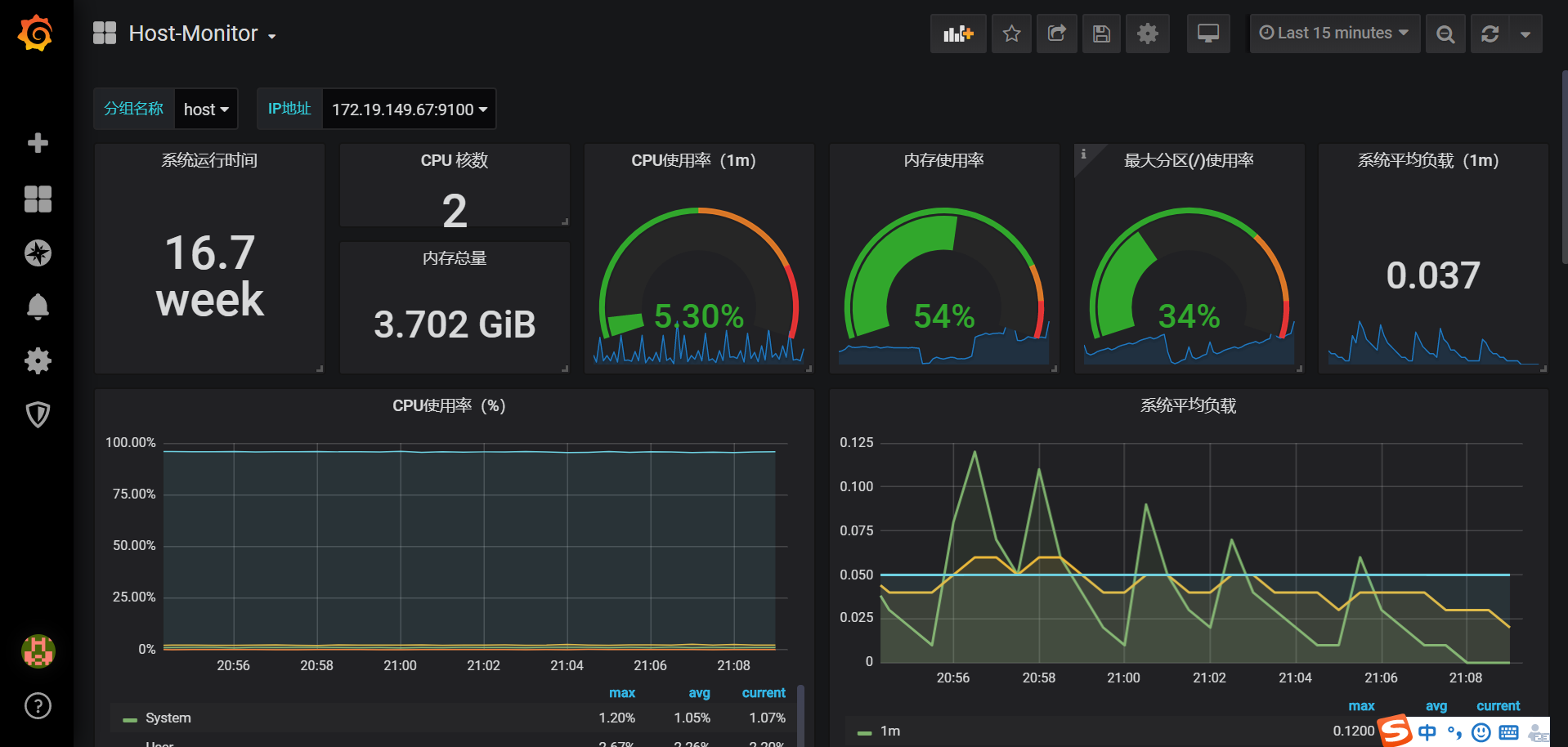
在上圖中,我們選擇的分組是Host,它主要是收集來自Node-Exporter中回饋的基於Host的監控數據,可以實時展示Host的關鍵指標。不過,它每次只能顯示單台Host的數據,我們可以通過切換Host IP下拉列表查看不同Host的性能數據。
此外,我們一般會將其投屏到工作區的電視上,所以我們可以點擊下面這個按鈕以投屏模式顯示在電視上,供整個團隊及時查看。

三、監控工具大比較
這裡我們仍然引用Cloud Man總結的一張表來看看:
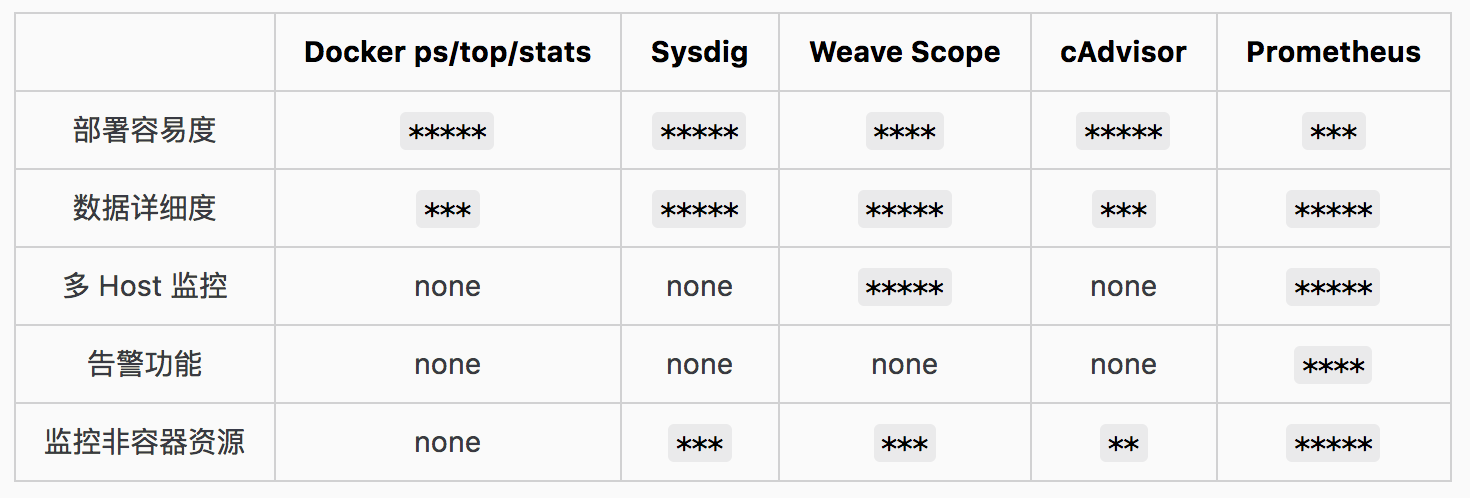
毫無疑問,Prometheus作為生產級的監控方案,對其他幾個工具形成了壓倒性的優勢。而事實上,Prometheus + Grafana + cAdvisor這一套方案也是大家廣泛採用的結構。
四、小結
本文首先簡單介紹了Prometheus及其架構,然後通過搭建基於Prometheus + cAdvisor + Grafana的監控系統,能夠實現對於多台雲主機的性能監控(包括Host和容器兩個層次的數據)。當然,Prometheus還有很多的配置和好玩的地方例如Alert Manager可以及時發送告警通知等,筆者也只是初步把玩,還有很多東西不知道。後面我會分享引入K8S後,結合Prometheus + cAdvisor + Grafana實現K8S集群的監控,敬請期待。
參考資料
Cloud Man,《每天5分鐘玩轉Docker容器技術》
三無程式設計師,《Prometheus》
虎糾衛,《監控神器-普羅米修斯Prometheus》
項思凱,《Prometheus介紹詳解》
rj-bai,《Prometheus+Grafana打造全方位監控系統》
GeekerLou,《雲原生監控系統Prometheus》
Cloud Man,《一文搞懂各種容器監控方案》
