數據分析與數據挖掘 – 07數據處理
一 pandas基本數據類型
1 Series類型
Pandas是數據處理中非常常用的一個庫,是數據分析師、AI的工程師們必用的一個庫,對這個庫是否能夠熟練的應用,直接關係到我們是否能夠把數據處理成我們想要的樣子。Pandas是基於NumPy構建的,讓以NumPy為中心的應用變得更加的簡單,它專註於數據處理,這個庫可以幫助數據分析、數據挖掘、演算法等工程師崗位的人員輕鬆快速的解決處理預處理的問題。比如說數據類型的轉換,缺失值的處理、描述性統計分析、數據匯總等等功能。
它不僅僅包含各種數據處理的方法,也包含了從多種數據源中讀取數據的方法,比如Excel、CSV等,這些我們後邊會講到,讓我們首先從Pandas的數據類型開始學起。
Pandas一共包含了兩種數據類型,分別是Series和DataFrame,我們先來學習一下Series類型。
Series類型就類似於一維數組對象,它是由一組數據以及一組與之相關的數據索引組成的,程式碼示例如下:
import pandas as pd
# 實例化一個Series對象,參數是一個數組。
obj = pd.Series([1, 2, 3, 4, 5, 6])
print(obj)
print(obj.index) # 獲取索引
print(obj.values) # 獲取值
在列印結果中一共呈現出兩列的內容:
0 1
1 2
2 3
3 4
4 5
5 6
dtype: int64
RangeIndex(start=0, stop=6, step=1)
[1 2 3 4 5 6]
第一列代表索引值,第二列代表對象本身的值,第7行是對這個對象裡邊的值進行的說明。
關於Series類型的索引,我們是可以自己去定義的,就像這樣:
# Series中的第一個參數指定對象的值,而index參數就是我們重新定義的索引。
obj = pd.Series(['a', 'b', 'c', 'd', 'e'], index=[1, 2, 3, 4, 5])
print(obj)
print(obj[1]) # 訪問到索引值為1的對象的值
聲明一個Series類型,也可以採用字典的格式:
data = {'a': 100000, 'b': 20000, 'c': 30000}
obj = pd.Series(data)
print(obj) # 字典的key就是Series對象中的索引值,字典中的value就是Series對象中的值
print(obj['a']) # 訪問到索引值為a的對象的值
2 DataFrame類型
DataFrame 是一個表格型的數據結構,它含有一組有序的列,每列可以是不同值的類型,數值、字元串、布爾值都可以。DataFrame 本身有行索引,也有列索引。這裡需要注意一下,它是擁有列索引的,這一點是我們之前沒有接觸過的。
DataFrame類型可以直接想像成是我們把數據放在了Excel表格里一樣,分具體的行和列,程式碼示例如下:
# 如果我們對96年,03年和09年選秀重新排名
data = {
'96年': ['科比', '艾弗森', '卡特'],
'03年': ['詹姆斯', '韋德', '安東尼'],
'09年': ['庫里', '哈登', '格里芬'],
}
frame_data = pd.DataFrame(data)
print(frame_data)
注意看返回內容:
96年 03年 09年
0 科比 詹姆斯 庫里
1 艾弗森 韋德 哈登
2 卡特 安東尼 格里芬
我們把0,1,2叫做行索引,把96年,03年和09年叫做列索引,我們可以使用如下程式碼直接訪問一列的值:
print(frame_data['96年']) # 直接訪問這一列的值
我們有一個根據日期自動生成索引的方法,首先我們先來生成一個日期的範圍,程式碼如下:
import pandas as pd
import numpy as np
# date_range與我們之前學習的range是類似的
# periods是在我們給定的日期上往後加幾天的意思
dates = pd.date_range('20190701', periods=6)
print(dates)
如果這個時候,我們單獨來查看dates的值的話,返回的結果就是:
DatetimeIndex(['2019-07-01', '2019-07-02', '2019-07-03', '2019-07-04',
'2019-07-05', '2019-07-06'],
dtype='datetime64[ns]', freq='D')
下面我們可以使用dates作為索引,然後聲明一個DataFrame對象,程式碼如下:
df = pd.DataFrame(np.random.rand(6, 4), index=dates, columns=list('ABCD'))
print(df)
在這行程式碼中第一個參數就是使用了NumPy進行一個6行4列的隨機數生成,index指定了它的行索引,而columns參數指定了列索引。那麼此時的df變數被列印出來的話,結果如下圖: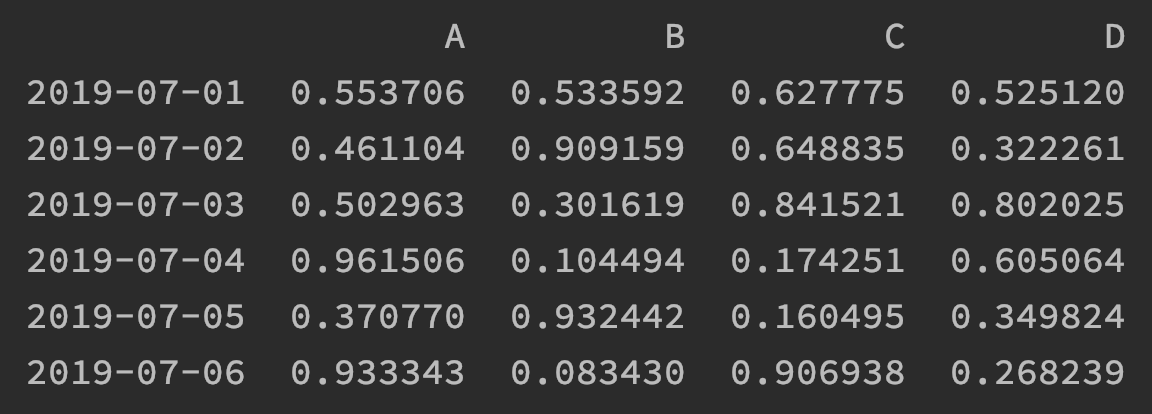
“現在我們可以專註的來練習一下如何具體的去訪問DataFrame里的數據。在剛剛我們學習過訪問一列的數據,現在我們來思考一下,如果我想按照行來訪問數據怎麼辦呢?如果我們想根據行和列來同時進行數據訪問,我們可以使用loc方法來完成這個操作,程式碼如下:
# 僅對行數據進行篩選
print(df['20201012':'20201015'])
# 訪問其中的一個值
print(df.loc["20201012", ['A']])
# 對多行和多列進行篩選
print(df.loc["20201012":'20201015', ['A', 'B']])
二 外部數據載入
1 csv
外部數據主要有四種:txt,Excel,csv和資料庫,文本文件我們只能用最基本的Python的方式來讀取,其他的接下來我們分別看一下。
如果你是非IT行業從業者的話,那麼CSV格式的文件你可能並不常用,我們可以把它理解成為一個文本文件,但其特殊性主要呈現在數據與數據之間的分割符號上,除了這個特點,另外一個就是其文件的後綴名稱了,是以.csv結尾的,文件如下:
雖然CSV格式的文件我們也可以使用Python中的文件讀取方法,但由於其擁有格式,所以我們需要按照其格式來取,方便我們後續對數據進行處理,把取出來後的數據變成某種數據類型,這樣操作起來就方便了,程式碼如下:
import pandas as pd
# data1.csv就是文件的路徑,這裡可以寫絕對路徑也可以寫相對路徑
data = pd.read_csv('data1.csv', header=None)
print(data)
print(type(data))
其中第一個參數是文件的路徑,這一個我們已經清楚了。參數header就是顯式的說明文件中沒有頭,自動幫我創建一個頭吧。如果不指定參數header那麼默認第一行數據就是頭,也就是列索引,程式碼運行結果如下:
0 1 2 3 4
0 a b c d e
1 1 2 3 4 5
2 6 7 8 9 10
如果你需要指定某一列來當作行索引,程式碼如下:
data = pd.read_csv('data1.csv', index_col='b')
print(data)
print(type(data))
以上結果需要你注意的是返回值的類型,全部都是DataFrame,也就是說後邊我們使用到的DataFrame的方法都適合來處理這些從文件中讀取出來的數據。
2 Excel
Excel的讀取與csv非常類似,這裡的參數sheet_name就是指定要讀取哪一張表的數據,如果不指定,默認就是第一張表,具體程式碼如下:
data = pd.read_excel("data.xls", sheet_name="申報表")
print(data)
print(type(data))
需要注意的是,讀取Excel文件你需要安裝一個xlrd模組才可以。
3 MySQL
讀取MySQL的方式也是一樣的,前提是先連接資料庫,具體程式碼如下:
import pandas as pd
import pymysql
conn = pymysql.connect(host='192.168.1.1',
port=3306,
user='admin',
passwd='123456',
db='school',
use_unicode=True,
charset="utf8")
sql = 'select * from class'
r = pd.read_sql(sql, con=conn)
print(r)
print(type(r))
三 日期的處理
日期格式的數據是我們在進行數據處理的時候經常遇到的一種格式,讓我來看一下在Excel中的日期類的數據我們該如何處理?
現有Excel數據如下圖所示: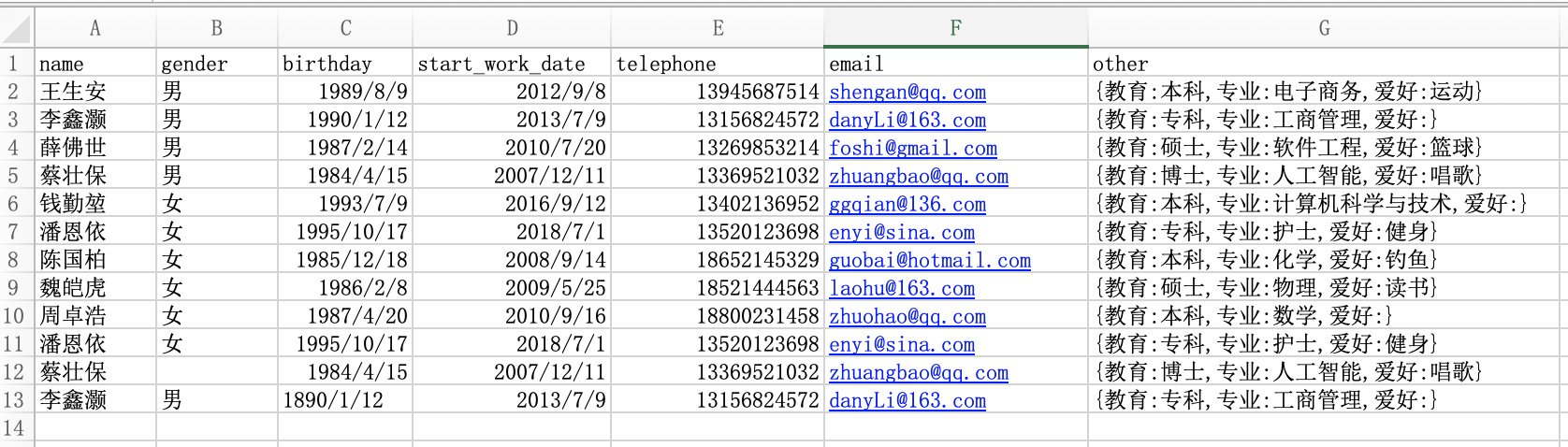
現在我們來思考幾個問題:
- 如何更改手機號欄位的數據類型
- 如何根據出生日期和開始工作日期兩個欄位更新年齡和工齡兩個欄位
- 如何將手機號的中間四位隱藏起來
- 如何根據郵箱資訊取出郵箱域名欄位
- 如何基於other欄位取出每個人的專業資訊
解決過程和程式碼如下:
import pandas as pd
import datetime
data = pd.read_excel('data2.xls')
print(data)
print(data.dtypes) # 查看各元素的數據類型
# 1 把手機號欄位改為object(字元串)類型
data.telephone = data.telephone.astype('str')
print(data.telephone.dtype)
# 2 計算年齡和工齡
now_year = datetime.datetime.now().year # 獲取現在的年份,也可使用 pd.datetime.today().year
print(now_year)
bir_year = data.birthday.dt.year
print(bir_year) # 獲取生日欄位的年份
data['age'] = now_year - bir_year # 添加一個age欄位
data['work_age'] = now_year - data.start_work_date.dt.year
print(data)
# 3 隱藏手機號中間四位
data.telephone = data.telephone.apply(func=lambda x: x.replace(x[3:7], '****'))
print(data.telephone)
# 4 取出郵箱域名
data['email_domain'] = data.email.apply(func=lambda x: x.split('@')[1])
print(data.email_domain)
# 5 取出專業(我們使用正則來完成,也可以有別的方法)
data['profession'] = data.other.str.findall('專業:(.*?),')
print(data.profession)
除了能夠添加欄位,我也可以刪除欄位,程式碼如下:
# axis=1是指定軸1,inplace=True是真正刪除
data.drop(['birthday', 'start_work_date'], axis=1, inplace=True)
print(data)
關於日期的處理方法需要多說一點,上邊我們已經獲取了年,我們還可以獲取其他的單位。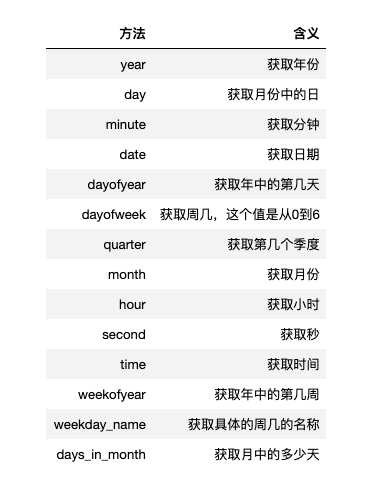
四 數據清洗的方法
1 處理重複數據
首先,我們把原有的數據集做一個簡單的修改,如下圖所示: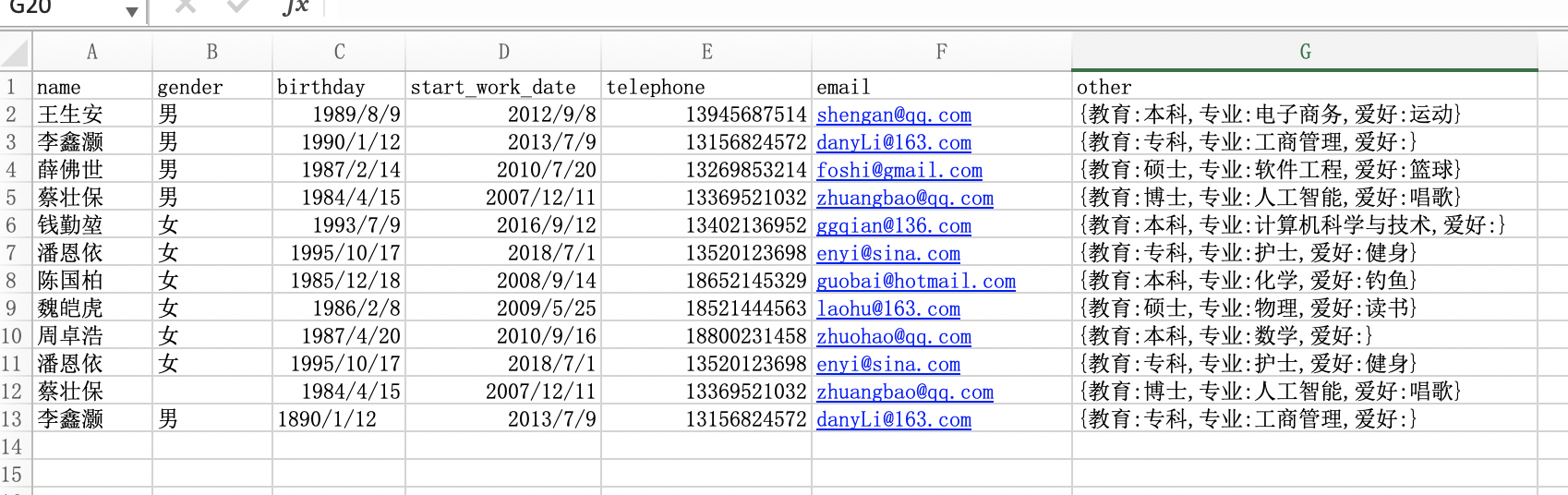
我們不需要去遍歷比對,pandas有專門的方法獲取到重複的數據,程式碼如下:
import pandas as pd
data = pd.read_excel('data.xlsx')
# 用duplicated()獲取重複數據
repetition = data.duplicated()
print(repetition)
以下是返回的結果:
0 False
1 False
2 False
3 False
4 False
5 False
6 False
7 False
8 False
9 True
10 False
11 False
dtype: bool
注意這裡返回結果中的行與Excel中的行不是對應的,根據返回結果我們可以看出,第9行是重複的,這裡的重複數據指的是每一個欄位都重複的數據。如果不重複,那麼結果返回的就是False,如果重複,那麼返回的就是True。對於重複數據,我們採用的處理方法一般就是刪除,這個可以使用drop_duplicates()方法。
data.drop_duplicates(inplace=True) # 必須要有這個參數才能真正刪除
print(data)
刪除之後,你會發現索引沒有變化,如需重置索引,我們使用reset_index這個方法。
# 如需重置索引,使用reset_index
data = data.reset_index(drop=True)
print(data)
2 處理缺失值
從原數據中我們可以看到,索引為10的數據,gender這一列的值為NaN,這就是代表著這個數據為空。我們可以通過isnull()方法來獲取到位空的數據。
nan = data.isnull()
print(nan)
對於缺失的數據,我們有很多的處理方法,常見的處理方法有刪除、和填充。如果是刪除掉的話,我們可以使用df.dropna()方法,這樣就把數據刪除掉了。這裡著重要講解的是填充數據的方法,填充有這樣幾種方法:
# 向前填充,指的是用缺失值的前一個值替換
data = data.fillna(method='ffill')
print(data)
# 向後填充,指的是用缺失值的後一個值替換
data = data.fillna(method='bfill')
print(data)
# 指定值來進行替換,如果沒有那麼默認為男,這裡也可以寫一些表達式
data = data.fillna(value='男')
print(data)
3 處理異常值
關於異常值,我們通常是結合著業務來進行觀察出來的。比如索引為11的數據,他的出生日期為1890/01/12,這明顯是異常值。當然Pandas也提供了一些方法,供我們去觀察一下是否有異常值,通常我們會通過查看資訊info屬性,查看描述方法describe(),或者是通過獲取標準差std等方式來觀察數據是否存在異常。在企業中進行數據處理時,對於異常的值,一定要和你的業務場景結合起來才有意義,就像上邊的出生日期一樣,放在現在肯定是異常的值了,但放在百年前,那就是正常的值。
4 透視表
接下來要講的知識點叫做透視表,相信你一定用過Excel來統計一些數據,那麼Pandas也提供了一個這樣的功能,它就是具有透視表功能的函數pivot_table(),我們先來看一下這個函數的一些參數。
- 參數data,指的是你的數據集。
- 參數values,指的是要用來觀察分析的數據值,就是Excel中的值欄位。
- 參數index,指的是要行索引的數據值,就是Excel中的行欄位。
- 參數columns,指的是列索引的數據值,就是Excel中的列欄位。
- 參數aggfunc,指的是數據的統計函數,默認為統計平均值,也可以指定為NumPy模組中的其他統計函數。
- 參數fill_value,指的是一個標量,用來填充缺失值。
- 參數margins,布爾值,是否需要顯示行或列的總計值,默認為False。
- 參數dropna,布爾值,是否刪除整列為缺失的欄位,默認為True。
- 參數margins_name,指定行或列的總計名稱,默認為All。
現在讓我們來試一下統計一下現有表中男人和女人分別的年齡和。首先我們計算出所有人的年齡。
data['age'] = pd.datetime.today().year - data.birthday.dt.year
print(data)
然後通過透視表功能計算男人和女人的年齡的總和。
import numpy as np
age_sum = pd.pivot_table(data=data, index='gender', values='age', aggfunc=np.sum)
print(age_sum)
練習:
這裡有一個小練習作為鞏固,練習內容已上傳到文件中,可以直接下載查看,如果遇到不太會的地方,首先搜索一下,嘗試自己能否獨立的解決掉。
chapter7-1.zip


