tensorflow學習筆記——多執行緒輸入數據處理框架
- 2019 年 10 月 3 日
- 筆記
之前我們學習使用TensorFlow對影像數據進行預處理的方法。雖然使用這些影像數據預處理的方法可以減少無關因素對影像識別模型效果的影響,但這些複雜的預處理過程也會減慢整個訓練過程。為了避免影像預處理成為神經網路模型訓練效率的瓶頸,TensorFlow提供了一套多執行緒處理輸入數據的框架。
下面總結了一個經典的輸入數據處理的流程:

下面我們首先學習TensorFlow中隊列的概念。在TensorFlow中,隊列不僅是一種數據結構,它更提供了多執行緒機制。隊列也是TensorFlow多執行緒輸入數據處理框架的基礎。然後再學習上面的流程。最後這個流程將處理好的單個訓練數據整理成訓練數據 batch,這些batch就可以作為神經網路的輸入。
準備知識:多執行緒的簡單介紹
在傳統作業系統中,每個進程有一個地址空間,而且默認就有一個控制執行緒。執行緒顧名思義,就是一條流水線工作的過程(流水線的工作需要電源,電源就相當於CPU),而一條流水線必須屬於一個車間,一個車間就是一個進程,車間負責把資源整合到一起,是一個資源單位,而一個車間內至少有一條流水線。所以,進程只是用來把資源集中到一起(進程只是一個資源單位,或者說資源集合),而執行緒才是CPU上的執行單位。
多執行緒(即多個控制執行緒)的概念就是:在一個進程中存在多個執行緒,多個執行緒共享該進程的地址空間,相當於一個車間內有多條流水線,都共用一個車間的資源。比如成都地鐵和西安地鐵是不同的進程,而成都地鐵3號線是一個執行緒,成都地鐵所有的執行緒共享成都所有的資源,比如成都所有的乘客可以被所有線拉。
開啟多執行緒的方式:
import time import random from threading import Thread def study(name): print("%s is learning" % name) time.sleep(random.randint(1, 3)) print("%s is playing " % name) if __name__ == '__main__': t = Thread(target=study, args=('james', )) t.start() print("主執行緒開始運行") ''' 結果展示: james is learning 主執行緒開始運行 james is playing '''
t.start() 將開啟進程的訊號發給作業系統後,作業系統要申請記憶體空間,讓好拷貝父進程地址空間到子進程,開銷遠大於執行緒。
1,隊列與多執行緒
在TensorFlow中,隊列和變數類似,都是計算圖上有狀態的節點。其他的計算節點可以修改他們的狀態。對於變數,可以通過賦值操作修改變數的取值。對於隊列,修改隊列狀態的操作主要有Enqueue,EnqueueMany和Dequeue。下面程式展示了如何使用這些函數來操作一個隊列。
#_*_coding:utf-8_*_ import tensorflow as tf # 創建一個先進先出的隊列,指定隊列中最多可以保存兩個元素,並指定類型為整數 q = tf.FIFOQueue(2, 'int32') # 使用enqueue_many 函數來初始化隊列中的元素。 # 和變數初始化類似,在使用隊列之前需要明確的調用這個初始化過程 init = q.enqueue_many(([0, 10], )) # 使用Dequeue 函數將隊列中的第一個元素出隊列。這個元素的值將被存在變數x中 x = q.dequeue() # 將得到的值加1 y = x + 1 # 將加 1 後的值在重新加入隊列 q_inc = q.enqueue([y]) with tf.Session() as sess: # 運行初始化隊列的操作 init.run() for _ in range(6): #運行q_inc 將執行數據出隊列,出隊的元素 +1 ,重新加入隊列的整個過程 v, _ = sess.run([x, q_inc]) # 列印出隊元素的取值 print('%s'%v) ''' 隊列開始有[0, 10] 兩個元素,第一個出隊的為0, 加1之後為[10, 1] 第二次出隊的為10, 加1之後入隊的為11, 得到的隊列為[1, 11] 以此類推,最後得到的輸出為: 0 10 1 11 2 '''
TensorFlow中提供了FIFOQueue 和 RandomShuffleQueue 兩種隊列。在上面的程式中,已經展示了如何使用FIFOQueue,它的實現的一個先進先出隊列。 RandomShuffleQueue 會將隊列中的元素打亂,每次出隊操作得到的是從當前隊列所有元素中隨機選擇的一個。在訓練審計網路時希望每次使用的訓練數據盡量隨機。 RandomShuffleQueue 就提供了這樣的功能。
在TensorFlow中,隊列不僅僅是一種數據結構,還是非同步計算張量取值的一個重要機制。比如多個執行緒可以同時向一個隊列中寫元素,或者同時讀取一個隊列中的元素。在後面我們會學習TensorFlow是如何利用隊列來實現多執行緒輸入數據處理的。
TensorFlow提供了 tf.Coordinator 和 tf.QueueRunner 兩個類來完成多執行緒協同的功能。tf.Coordinator 主要用於協同多個執行緒一起停止,並提供了 should_stop, request_stop 和 join 三個函數。在啟動執行緒之前,需要先聲明一個 tf.Coordinator 類,並將這個類傳入每一個創建的執行緒中。啟動的執行緒需要一直查詢 tf.Coordinator 類中提供的 should_stop 函數,當這個函數的返回值為 True時,則當前執行緒也需要退出。每一個啟動的執行緒都可以通過調用 request_stop 函數來通知其他執行緒退出。當某一個執行緒調用 request_stop 函數之後, should_stop 函數的返回值將被設置為 TRUE,這樣其他的執行緒就可以同時終止了。下面程式展示了如何使用 tf.Coordinator。
#_*_coding:utf-8_*_ import tensorflow as tf import numpy as np import threading import time # 執行緒中運行的程式,這個程式每隔1秒判斷是否停止並列印自己的ID def MyLoop(coord, worker_id): # 使用 tf.Coordinator 類提供的協同工具判斷當前是否需要停止 while not coord.should_stop(): # 隨機停止所有的執行緒 if np.random.rand() < 0.1: print("Stopping from id: %dn" % worker_id) # 調用 coord.request_stop() 函數來通知其他執行緒停止 coord.request_stop() else: # 列印當前執行緒的 ID print("Working on id: %dn" % worker_id) # 暫停1 s time.sleep(1) # 聲明一個 tf.train.Coordinator 類來協同多個執行緒 coord = tf.train.Coordinator() # 聲明創建 5 個執行緒 threads = [ threading.Thread(target=MyLoop, args=(coord, i, )) for i in range(5) ] # 啟動所有的執行緒 for t in threads: t.start() # 等待所有執行緒退出 coord.join(threads) ''' Working on id: 0 Working on id: 1 Working on id: 2 Working on id: 3 Working on id: 4 Working on id: 0 Working on id: 1 Working on id: 3 Working on id: 2 Working on id: 4 Working on id: 0 Working on id: 2 Working on id: 1 Working on id: 3 Working on id: 4 Working on id: 2 Working on id: 1 Working on id: 0 Working on id: 3 Working on id: 4 Working on id: 3 Working on id: 0 Working on id: 1 Working on id: 2 Working on id: 4 Working on id: 1 Stopping from id: 0 '''
當所有執行緒啟動之後,每個執行緒會列印各自的ID,於是前面4行列印出了他們的ID。然後在暫停1秒之後,所有的執行緒又開始第二遍列印ID。在這個時候有一個執行緒推出的條件達到,於是調用了coord.request_stop 函數來停止所有其他的執行緒。然而在列印Stoping_from_id:4之後,可以看到有執行緒仍然在輸出。這是因為這些執行緒已經執行完 coord.should_stop 的判斷,於是仍然會繼續輸出自己的ID。但在下一輪判斷是否需要停止時將推出執行緒。於是在列印一次ID之後就不會再有輸出了。
tf.QueueRunner 主要用於啟動多個執行緒來操作同一個隊列,啟動的這些執行緒可以通過上面介紹的 tf.Coordinator 類來統一管理,下面程式碼展示了如何使用 tf.QueueRunner 和 tf.Coordinator 來管理多執行緒隊列操作。
#_*_coding:utf-8_*_ import tensorflow as tf # 聲明一個先進先出的隊列,隊列中最多100個元素,類型為實數 queue = tf.FIFOQueue(100, 'float') # 定義隊列的入隊操作 enqueue_op = queue.enqueue([tf.random_normal([1])]) # 使用 tf.train.QueueRunner 來創建多個執行緒運行隊列的入隊操作 # tf.train.QueueRunner 的第一個參數給出了被操作的隊列 # [enqueue_op] * 5 表示了需要啟動5個執行緒,每個執行緒運行的是equeue_op操作 qr = tf.train.QueueRunner(queue, [enqueue_op]*5) # 將定義過的 QueueRunner 加入 TensorFlow計算圖上指定的集合 # tf.train.add_queue_runner 函數沒有指定集合 # 則加入默認集合 tf.GraphKeys.QUEUE_RUNNERS # 下面的函數就是講剛剛定義的qr加入默認的tf.GraphKeys.QUEUE_RUNNERS集合 tf.train.add_queue_runner(qr) # 定義出隊操作 out_tensor = queue.dequeue() with tf.Session() as sess: # 使用 tf.train.coordinator 來協同啟動的執行緒 coord = tf.train.Coordinator() # 使用tf.train.QueueRunner時,需要明確調用 tf.train.start_queue_runnsers來啟動所有執行緒 # 否則因為沒有執行緒運行入隊操作,當調用出隊操作時,程式會一直等待入隊操作被運行。 # tf.train.start_queue_runners 函數會默認啟動 tf.GraphKeys.QUEUE_RUNNERS集合 # 所說的 tf.train.add_queue_runner 函數和 tf.train.start_queue_runners 函數會指定同一個集合 threads = tf.train.start_queue_runners(sess=sess, coord=coord) # 獲取隊列中的取值 for _ in range(3): print(sess.run(out_tensor)[0]) # s使用 tf.train.Coordinator 來停止所有的執行緒 coord.request_stop() coord.join(threads) ''' -0.88587755 -0.6659831 -2.9722364 '''
輸入文件隊列
下面將學習如何使用TensorFlow中的隊列管理輸入文件列表。這裡假設所有的輸入數據都已經整理成了TFRecord 格式。雖然一個 TFRecord 文件中可以存儲多個訓練樣例,但是當訓練數據量較大時,可以將數據分成多個 TFRecord 文件來提高處理效率。 TensorFlow 提供了 tf.train.match_filenames_once 函數來獲取符合一個正則表達式的所有文件,得到的文件列表可以通過 tf.train.string_input_producer 函數進行有效的管理。
tf.train.string_input_producer 函數會使用初始化時提供的文件列表創建一個輸入隊列,輸入對壘中原始的元素為文件列表中的所有文件。如上面的程式碼所示,創建好的輸入隊列可以作為文件讀取函數的參數。每次調用文件讀取函數時,該函數會先判斷當前是否已有打開的文件可讀,如果沒有或者打開的文件以及讀完,這個函數會從輸入隊列中出隊一個文件並從這個文件中讀取數據。
通過設置 shuffle 參數,tf.train.string_input_producer 函數支援隨機打亂文件列表中文件出隊的順序。當 shuffle 參數為 TRUE時,文件在加入隊列之前會被打亂順序,所以出隊的順序也是隨機的。隨機打亂文件順序以及加入輸入隊列的過程會泡在一個單獨的執行緒上,這樣不會影響獲取文件的速度。tf.train.string_input_producer 函數生成的輸入隊列可以同時被多個文件讀取執行緒操作,而且輸入隊列會將隊列中的文件均勻的分給不同的執行緒,不出現有些文件被處理過多次而有些文件還沒有被處理過的情況。
當一個輸入隊列中的所有文件都被處理完後,它會將初始化時提供的文件列表中的文件全部重新加入隊列。tf.train.string_input_producer 函數可以設置 num_epochs 參數來限制載入初始文件列表的最大輪數。當所有文件都已經被使用了設定的輪數後,如果繼續嘗試讀取新的文件,輸入隊列會報 OutOfRange 的錯誤。在測試神經網路模型時,因為所有測試數據只需要使用一次,所以可以將 num_epochs 參數設置為1,這樣在計算完一輪之後程式將自動停止。在展示 tf.train.match_filenames_once 和 tf.train.string_input_producer 函數的使用方法之前,我們可以先給出一個簡單的程式來生成數據。
#_*_coding:utf-8_*_ import tensorflow as tf # 創建TFReocrd文件的幫助函數 def _int64_feature(value): return tf.train.Feature(int64_list=tf.train.Int64List(value=[value])) # 模擬海量數據情況下降數據寫入不同的文件,num_shards 定義了總共寫入多少文件 # instances_per_shard 定義了每個文件中有多少個數據 num_shards = 2 instances_per_shard = 2 for i in range(num_shards): # 將數據分為多個文件時,可以將不同文件以類似0000n-of-0000m 的後綴區分 # 其中m表示了數據總共被存在了多少個文件中,n表示當前文件的編號 # 式樣的方式既方便了通過正則表達式獲取文件列表,又在文件名中加入了更多的資訊 filename = ('data.tfrecords-%.5d-of-%.5d' % (i, num_shards)) writer = tf.python_io.TFRecordWriter(filename) # 將數據封裝成Example結構並寫入 TFRecord 文件 for j in range(instances_per_shard): # Example 結構僅包含當前樣例屬於第幾個文件以及時當前文件的第幾個樣本 example = tf.train.Example(features=tf.train.Features( feature={ 'i': _int64_feature(i), 'j': _int64_feature(j) } )) writer.write(example.SerializeToString()) writer.close()
程式運行之後,在指定的目錄下生產兩個文件,每一個文件中存儲了兩個樣例,在生成了樣例數據之後,下面程式碼展示了 tf.train.match_filenames_once 函數 和 tf.train.string_input_producer 函數的使用方法:
#_*_coding:utf-8_*_ import tensorflow as tf # 使用tf.train.match_filenames_once 函數獲取文件列表 files = tf.train.match_filenames_once('path/data.tfrecords-*') # print(files) # 輸入隊列中的文件列表為 tf.train.match_filenames_once 函數獲取的文件列表 # 這裡將 shuffle參數設置為FALSE來避免隨機打亂讀文件的順序 # 但是一般在解決真實問題,會將shuffle參數設置為TRUE filename_queue = tf.train.string_input_producer(files, shuffle=False) # print(filename_queue) # 讀取並解析一個樣本 reader = tf.TFRecordReader() _, serialized_example = reader.read(filename_queue) features = tf.parse_single_example( serialized_example, features={ 'i': tf.FixedLenFeature([], tf.int64), 'j': tf.FixedLenFeature([], tf.int64), } ) with tf.Session() as sess: # 雖然在本段程式中沒有聲明任何變數 # 但在使用 tf.train.match_filenames_once 函數時需要初始化一些變數 # init = tf.global_variables_initializer() # init = tf.initialize_all_variables() init = tf.local_variables_initializer() sess.run(init) # sess.run(files) # sess.run([tf.global_variables_initializer(), tf.local_variables_initializer()]) print(sess.run(files)) # 聲明 tf.train.Coordinator 類來協同不同執行緒,並啟動執行緒 coord = tf.train.Coordinator() threads = tf.train.start_queue_runners(sess=sess, coord=coord) # 多次執行獲取數據的操作 for i in range(6): print(sess.run([features['i'], features['j']])) coord.request_stop() coord.join(threads)
列印結果如下:
[b'path\data.tfrecords-00000-of-00002' b'path\data.tfrecords-00001-of-00002'] [0, 0] [0, 1] [1, 0] [1, 1] [0, 0] [0, 1]
在不打亂文件列表的情況下,會依次獨處樣例數據中的每一個樣例。而且當所有樣例都被讀完之後,程式會自動從頭開始。如果限制 num_epochs=1,那麼程式會報錯。
組合訓練數據(batching)
在上面,我們已經學習了如何從文件列表中讀取單個樣例,將這些單個樣例通過預處理方法進行處理,就可以得到提高給神經網路輸入層的訓練數據了。在之前學習過,將多個輸入樣例組織成一個batch可以提高模型訓練的效率。所以在得到單個樣例的預處理結果之後,還需要將他們組織成batch,然後再提供給審計網路的輸入層。TensorFlow提供了 tf.train.batch 和 tf.train.shuffle_batch 函數來將單個的樣例組織成 batch 的形式輸出。這兩個函數都會生成一個隊列,隊列的入隊操作時生成單個樣例的方法,而每次出隊得到的時一個batch的樣例。他們唯一的區別自安於是否會將數據順序打亂。下面程式碼展示了這兩個函數的使用方法。
下面程式碼展示了 tf.train.batch函數的用法:
#_*_coding:utf-8_*_ import tensorflow as tf # 讀取解析得到樣例,這裡假設Example結構中 i表示一個樣例的特徵向量 # 比如一張影像的像素矩陣,而j表示該樣例對應的標籤 # 使用tf.train.match_filenames_once 函數獲取文件列表 files = tf.train.match_filenames_once('path/data.tfrecords-*') # 輸入隊列中的文件列表為 tf.train.match_filenames_once 函數獲取的文件列表 # 這裡將 shuffle參數設置為FALSE來避免隨機打亂讀文件的順序 # 但是一般在解決真實問題,會將shuffle參數設置為TRUE filename_queue = tf.train.string_input_producer(files, shuffle=False) # print(filename_queue) # 讀取並解析一個樣本 reader = tf.TFRecordReader() _, serialized_example = reader.read(filename_queue) features = tf.parse_single_example( serialized_example, features={ 'i': tf.FixedLenFeature([], tf.int64), 'j': tf.FixedLenFeature([], tf.int64), } ) example, label = features['i'], features['j'] # 一個 batch 中樣例的個數 batch_size = 2 # 組合樣例的隊列中最多可以存儲的樣例個數。這個隊列如果太大, # 那麼需要佔用很多記憶體資源,如果太小,那麼出隊操作可能會因為 # 沒有數據而被阻礙(block),從而導致訓練效率降低,一般來說 # 這個隊列的大小會和每一個batch的大小相關,下面程式碼給出了設置 # 隊列大小的一種方式。 capacity = 1000 + 3 * batch_size # 使用 tf.train.batch 函數來組合樣例。[example, label] 參數給 # 出了需要組合的元素,一般 example 和 label分別代表訓練樣本和這個樣本 # 對應的正確標籤。batch_size 參數給出了每個batch中樣例的個數。 # capacity 給出了隊列的最大容量。當隊列長度等於容量時,TensorFlow將暫停 # 入隊操作,而只是等待元素出隊。當元素個數小於容量時,TensorFlow將自動重新啟動入隊操作 example_batch, label_batch = tf.train.batch( [example, label], batch_size=batch_size, capacity=capacity ) with tf.Session() as sess: tf.global_variables_initializer().run() tf.local_variables_initializer().run() coord = tf.train.Coordinator() threads = tf.train.start_queue_runners(sess=sess, coord=coord) # 獲取並列印組合之後的樣例,在真實問題中,這個輸出一般會作為神經網路的輸入 for i in range(3): cur_example_batch, cur_label_batch = sess.run( [example_batch, label_batch] ) print(cur_example_batch, cur_label_batch) coord.request_stop() coord.join(threads) ''' 運行上面的程式會得到下面的輸出: [0 0] [0 1] [1 1] [0 1] [0 0] [0 1] 從這個輸出可以看到 tf.train.batch函數可以將單個的數據組織成3個一組的batch 在 example, lable 中讀取的數據依次為: example:0 label:0 example:0 label:1 example:1 label:1 example:0 label:1 example:0 label:0 example:0 label:1 這是因為 tf.train.batch 函數不會隨機打亂順序,所以在組合之後得到的數據 組成了上面給出的輸出。 '''
下面程式碼展示了 tf.train.shuffle_batch 函數的使用方法:
import tensorflow as tf #_*_coding:utf-8_*_ import tensorflow as tf # 讀取解析得到樣例,這裡假設Example結構中 i表示一個樣例的特徵向量 # 比如一張影像的像素矩陣,而j表示該樣例對應的標籤 # 使用tf.train.match_filenames_once 函數獲取文件列表 files = tf.train.match_filenames_once('path/data.tfrecords-*') # 輸入隊列中的文件列表為 tf.train.match_filenames_once 函數獲取的文件列表 # 這裡將 shuffle參數設置為FALSE來避免隨機打亂讀文件的順序 # 但是一般在解決真實問題,會將shuffle參數設置為TRUE filename_queue = tf.train.string_input_producer(files, shuffle=False) # print(filename_queue) # 讀取並解析一個樣本 reader = tf.TFRecordReader() _, serialized_example = reader.read(filename_queue) features = tf.parse_single_example( serialized_example, features={ 'i': tf.FixedLenFeature([], tf.int64), 'j': tf.FixedLenFeature([], tf.int64), } ) example, label = features['i'], features['j'] # 一個 batch 中樣例的個數 batch_size = 2 # 組合樣例的隊列中最多可以存儲的樣例個數。這個隊列如果太大, # 那麼需要佔用很多記憶體資源,如果太小,那麼出隊操作可能會因為 # 沒有數據而被阻礙(block),從而導致訓練效率降低,一般來說 # 這個隊列的大小會和每一個batch的大小相關,下面程式碼給出了設置 # 隊列大小的一種方式。 capacity = 1000 + 3 * batch_size # 使用 tf.train.shuffle_batch 函數來組合樣例。[example, label] 參數給 # 出了需要組合的元素,一般 example 和 label分別代表訓練樣本和這個樣本 # 對應的正確標籤。batch_size 參數給出了每個batch中樣例的個數。 # capacity 給出了隊列的最大容量。min_after_dequeue參數是 # tf.train.shuffle_batch 特有的。min_after_dequeue參數限制了出隊時 # 隊列中元素的最小個數,當隊列中元素太小時,隨機打亂樣例的順序作用就不大了 # 所以 tf.train.shuffle_batch 函數提供了限制出隊時的最小元素的個數來保證 # 隨機打亂順序的作用。當出隊函數被調用但是隊列中元素不夠時,出隊操作將等待更多 # 的元素入隊才會完成。如果min_after_dequeue參數被設定,capacity也應該來調整 example_batch, label_batch = tf.train.shuffle_batch( [example, label], batch_size=batch_size, capacity=capacity, min_after_dequeue=30 ) with tf.Session() as sess: tf.global_variables_initializer().run() tf.local_variables_initializer().run() coord = tf.train.Coordinator() threads = tf.train.start_queue_runners(sess=sess, coord=coord) # 獲取並列印組合之後的樣例,在真實問題中,這個輸出一般會作為神經網路的輸入 for i in range(3): cur_example_batch, cur_label_batch = sess.run( [example_batch, label_batch] ) print(cur_example_batch, cur_label_batch) coord.request_stop() coord.join(threads) ''' 運行上面的程式會得到下面的輸出: [0 1] [0 0] [1 0] [0 0] [1 0] [0 1] 從這個輸出可以看到 tf.train.shuffle_batch函數已經將樣例順序打亂了 '''
tf.train.batch 函數 和 tf.train.shuffle_batch 函數除了將單個訓練數據整理成輸入 batch,也提供了並行化處理輸入數據的方法。tf.train.batch 函數 和 tf.train.shuffle_batch 函數並行化的方式一樣,所以我們執行應用更多的 tf.train.shuffle_batch 函數為例。通過設置tf.train.shuffle_batch 函數中的 num_threads參數,可以指定多個執行緒同時執行入隊操作。tf.train.shuffle_batch 函數的入隊操作就是數據讀取以及預處理的過程。當 num_threads 參數大於1時,多個執行緒會同時讀取一個文件中的不同樣例並進行預處理。如果需要多個執行緒處理不同文件中的樣例時,可以使用tf.train.shuffle_batch_join 函數。此函數會從輸入文件隊列中獲取不同的文件分配給不同的執行緒。一般來說,輸入文件隊列時通過 tf.train.string_input_producer 函數生成的。這個函數會分均分配文件以保證不同文件中的數據會被盡量平均地使用。
tf.train.shuffle_batch 函數 和 tf.train.shuffle_batch_join 函數都可以完成多執行緒並行的方式來進行數據預處理,但是他們各有優劣。對於tf.train.shuffle_batch 函數,不同執行緒會讀取同一個文件。如果一個文件中的樣例比較相似(比如都屬於同一個類別),那麼神經網路的訓練效果有可能會受到影響。所以在使用 tf.train.shuffle_batch 函數時,需要盡量將同一個TFRecord 文件中的樣例隨機打亂。而是用 tf.train.shuffle_batch_join 函數時,不同執行緒會讀取不同文件。如果讀取數據的執行緒數比總文件數還大,那麼多個執行緒可能會讀取同一個文件中相近部分的數據。而卻多個執行緒讀取多個文件可能導致過多的硬碟定址,從而使得讀取的效率降低。不同的並行化方式各有所長。具體採用哪一種方法需要根據具體情況來確定。
輸入數據處理框架
前面已經學習了開始給出的流程圖中的所有步驟,下面將這些步驟串成一個完成的TensorFlow來處理輸入數據,下面程式碼給出了這個步驟:
#_*_coding:utf-8_*_ import tensorflow as tf # 創建文件隊列,並通過文件列表創建輸入文件隊列 # 需要統一所有原始數據的格式並將他們存儲到TFRecord文件中 # 下面給出的文件列表應該包含所有提供訓練數據的TFRecord文件 files = tf.train.match_filenames_once('path/output.tfrecords') filename_queue = tf.train.string_input_producer([files]) # 解析TFRecord文件中的數據,這裡假設image中存儲的時影像的原始數據 # label為該樣例所對應的標籤。height,width 和 channels 給出了圖片的維度 reader = tf.TFRecordReader() _, serialized_example = reader.read(filename_queue) # 用FixedLenFeature 將讀入的Example解析成 tensor features = tf.parse_single_example( serialized_example, features={ 'image_raw': tf.FixedLenFeature([], tf.string), 'pixels': tf.FixedLenFeature([], tf.int64), 'label': tf.FixedLenFeature([], tf.int64) } ) # 從原始影像數據解析出像素矩陣,並根據影像尺寸還原影像 decoded_images = tf.decode_raw(features['image_raw'], tf.uint8) labels = tf.cast(features['label'], tf.int32) pixels = tf.cast(features['pixels'], tf.int32) retyped_images = tf.cast(decoded_images, tf.float32) images = tf.reshape(retyped_images, [784]) # 將處理後的影像和標籤數據通過 tf.train.shuffle_batch 整理成 # 神經網路訓練訓練時需要的batch # 將文件以100個為一組打包 min_after_dequeue = 10000 batch_size = 100 capacity = min_after_dequeue + 3 * batch_size image_batch, label_batch = tf.train.shuffle_batch([images, labels], batch_size=batch_size, capacity=capacity, min_after_dequeue=min_after_dequeue) # 訓練模型 計算審計網路的前向傳播結果 def inference(input_tensor, weights1, biases1, weights2, biases2): # 引入激活函數讓每一層去線性化 tf.nn.relu() layer1 = tf.nn.relu(tf.matmul(input_tensor, weights1) + biases1) return tf.matmul(layer1, weights2) + biases2 # 模型相關的參數 INPUT_NODE = 784 OUTPUT_NODE = 10 LAYER1_NODE = 500 REGULARAZTION_RATE = 0.0001 TREINING_STEPS = 5000 # 生成隱藏層的參數 weights1 = tf.Variable(tf.truncated_normal([INPUT_NODE, LAYER1_NODE], stddev=0.1)) biases1 = tf.Variable(tf.constant(0.1, shape=[LAYER1_NODE])) # 生成輸出層的參數 weights2 = tf.Variable(tf.truncated_normal([LAYER1_NODE, OUTPUT_NODE], stddev=0.1)) biases2 = tf.Variable(tf.constant(0.1, shape=[OUTPUT_NODE])) y = inference(image_batch, weights1, biases1, weights2, biases2) # 計算交叉熵及其平均值(對於分類問題,通常將交叉熵與softmax回歸一起使用 cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=label_batch) cross_entropy_mean = tf.reduce_mean(cross_entropy) # 損失函數的計算 regularizer = tf.contrib.layers.l2_regularizer(REGULARAZTION_RATE) # 計算模型的正則化損失,一般只計算神經網路邊上的權重的正則化損失,而不是用偏置項 regularization = regularizer(weights1) + regularizer(weights2) # 總損失等於交叉熵損失和正則化損失的和 loss = cross_entropy_mean + regularization # 優化損失函數 # 一般優化器的目的是優化權重W和偏差 biases,最小化損失函數的結果 train_step = tf.train.GradientDescentOptimizer(0.01).minimize(loss) # 初始化會話,並開始訓練過程 with tf.Session() as sess: # 由於使用了Coordinator,必須對local 和 global 變數進行初始化 sess.run(tf.local_variables_initializer()) sess.run(tf.global_variables_initializer()) coord = tf.train.Coordinator() threads = tf.train.start_queue_runners(sess=sess, coord=coord) # 循環的訓練神經網路 for i in range(TREINING_STEPS): if i %1000 == 0: print("After %d training step(s), loss is %g " % (i, sess.run(loss))) sess.run(train_step) coord.request_stop() coord.join(threads)
下面程式碼是生成TFRecord文件的(數據是MNIST數據)程式碼:
#_*_coding:utf-8_*_ import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data import numpy as np # 生成整數型的屬性 def _int64_feature(value): return tf.train.Feature(int64_list=tf.train.Int64List(value=[value])) # 生成字元串型的屬性 def _bytes_feature(value): return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value])) mnist = input_data.read_data_sets( 'data', dtype=tf.uint8, one_hot=True ) images = mnist.train.images # 訓練數據所對應的正確答案,可以作為一個屬性保存在TFRecord中 labels = mnist.train.labels # 訓練數據的影像解析度,這可以作為Example中的一個屬性 pixels = images.shape[1] num_examples = mnist.train.num_examples # 輸出TFRecord 文件的地址 filename = 'path/output.tfrecords' # 創建一個writer來寫TFRecord 文件 writer = tf.python_io.TFRecordWriter(filename) for index in range(num_examples): # 將影像矩陣轉化為一個字元串 image_raw = images[index].tostring() # 將一個樣例轉化為 Example Protocol Buffer,並將所有的資訊寫入這個數據結構 example = tf.train.Example( features=tf.train.Features( feature={ 'pixels': _int64_feature(pixels), 'labels': _int64_feature(np.argmax(labels[index])), 'image_raw': _bytes_feature(image_raw) } )) # 將一個Example寫入 TFRecord文件 writer.write(example.SerializeToString()) writer.close()
上面程式碼給出了從輸入數據處理的整個流程。(但是程式可能會報錯,我們這裡主要學習思路)。從下圖中可以看出,輸入數據處理的第一步是為獲取存儲訓練數據的文件列表。下圖的文件列表為{A, B, C}.通過 tf.train.string_input_producer 函數可以選擇性地將文件列表中文件的順序打亂,並加入輸入隊列。因為是否打亂文件的順序是可選的,所以在圖中是虛線的。tf.train.string_input_producer 函數會生成並維護一個輸入文件隊列,不同執行緒中的文件讀取函數可以共享這個輸入文件隊列。在讀取樣例數據之後,需要將影像進行預處理。影像預處理的過程也會通過tf.train.shuffle_batch 提供的機制並行地跑在多個執行緒中。輸入數據處理流程的最後通過 tf.train.shuffle_batch 函數將處理好的單個樣例整理成 batch 提供給神經網路的輸入層。通過這種方式,可以有效地提高數據預處理的效率,避免數據預處理成為神經網路模型性能過程中的性能瓶頸。
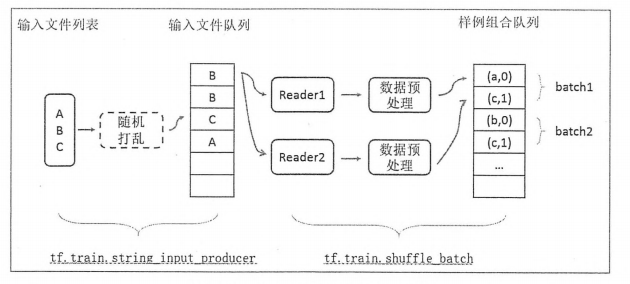
TensorFlow 數據讀取機制主要是兩種方法:
- (1)使用文件隊列方法,如使用 slice_input_producer 和 string_input_producer;這種方法既可以將數據轉存為 TFRecord數據格式,也可以直接讀取文件圖片數據,當然轉存為 TFRecord 數據格式進行讀取會更高效點。而這兩者之間的區別就是前者是輸入 tensor_list ,因此可以將多個list組合成一個 tensorlist 作為輸入;而後者只能是一個 string_tensor了。
- (2)使用TensorFlow 1.4版本後出現的 tf.data.DataSet 的數據讀取機制(pipeline機制),這是TensorFlow強烈推薦的方式,是一種更高效的讀取方式。使用 tf.data.Dataset 模組的pipeline機制,可以實現 CPU 多執行緒處理輸入的數據,如讀取圖片和圖片的一些預處理,這樣 GPU就可以專註於訓練過程,而CPU去準備數據。
舉例如下:
image_dir ='path/to/image_dir/*.jpg' image_list = glob.glob(image_dir) label_list=... image_list = tf.convert_to_tensor(image_list, dtype=tf.string) # 可以將image_list,label_list多個list組合成一個tensor_list image_que, label_que = tf.train.slice_input_producer([image_list,label_list], num_epochs=1) # 只能時string_tensor,所以不能組合多個list image = tf.train.string_input_producer(image_list, num_epochs=1)
tf.train.slice_input_produce() 函數的用法
這個函數的作用就是從輸入的 tensor_list 按要求抽取一個 tensor 放入文件名隊列,下面學習各個參數:
tf.slice_input_producer(tensor_list, num_epochs=None, shuffle=True, seed=None,capacity=32, shared_name=None, name=None)
說明:
- tensor_list 這個就是輸入,格式為tensor的列表;一般為[data, label],即由特徵和標籤組成的數據集
- num_epochs 這個是你抽取batch的次數,如果沒有給定值,那麼將會抽取無數次batch(這會導致你訓練過程停不下來),如果給定值,那麼在到達次數之後就會報OutOfRange的錯誤
- shuffle 是否隨機打亂,如果為False,batch是按順序抽取;如果為True,batch是隨機抽取
- seed 隨機種子
- capcity 隊列容量的大小,為整數
- name 名稱
舉個例子:我們的數據data的 shape是(4000,10),label的shape是(4000, 2),運行下面這行程式碼:
input_queue = tf.train.slice_input_producer([data, label], num_epochs=1, shuffle=True, capacity=32 )
結果肯定是返回值包含兩組數據的 list,每個list的shape和輸入的data和label的shape對應。
batch_size 的設置與影響
1,batch_size 的含義
batch_size 可以理解為批處理參數,它的極限值為訓練集樣本總數,當數據量比較小時,可以將batch_size 值設置為全數據集(Full batch cearning)。實際上,在深度學習中所涉及到的數據都是比較多的,一般都採用小批量數據處理原則。
2,關於小批量訓練網路的優缺點
小批量訓練網路的優點:
- 相對海量的的數據集和記憶體容量,小批量處理需要更少的記憶體就可以訓練網路。
- 通常小批量訓練網路速度更快,例如我們將一個大樣本分成11小樣本(每個樣本100個數據),採用小批量訓練網路時,每次傳播後更新權重,就傳播了11批,在每批次後我們均更新了網路的(權重)參數;如果在傳播過程中使用了一個大樣本,我們只會對訓練網路的權重參數進行1次更新。
- 全數據集確定的方向能夠更好地代表樣本總體,從而能夠更準確地朝著極值所在的方向;但是不同權值的梯度值差別較大,因此選取一個全局的學習率很困難。
小批量訓練網路的缺點:
- 批次越小,梯度的估值就越不準確,在下圖中,我們可以看到,與完整批次漸變(藍色)方向相比,小批量漸變(綠色)的方向波動更大。
- 極端特例batch_size = 1,也成為在線學習(online learning);線性神經元在均方誤差代價函數的錯誤面是一個拋物面,橫截面是橢圓,對於多層神經元、非線性網路,在局部依然近似是拋物面,使用online learning,每次修正方向以各自樣本的梯度方向修正,這就造成了波動較大,難以達到收斂效果。
3,為什麼需要 batch_size 的參數
Batch 的選擇,首先決定的時下降的方向。如果數據集比較小,完全可以採用全數據集(Full Batch Learning)的形式,這樣做有如下好處:
- 全數據集確定的方向能夠更好的代表樣本總體,從而更準確地朝著極值所在的方向
- 由於不同權值的梯度差別較大,因此選取一個全局的學習率很困難
Full Batch Learning 可以使用 Rprop 只基於梯度符號並且針對性單獨更新各權值。但是對於非常大的數據集,上述兩個好處變成了兩個壞處:
- 隨著數據集的海量增加和記憶體限制,一次載入所有數據不現實
- 以Rprop的方式迭代,會由於各個 batch之間的取樣差異性,各次梯度修正值相互抵消,無法修正。這才有了後來的RMSprop的妥協方案。
4,選擇適中的 batch_size
可不可以選擇一個適中的Batch_size 值呢?當然可以,就是批梯度下降法(Mini-batches Learning)。因為如果數據集足夠充分,那麼用一半(甚至少得多)的數據訓練算出來的梯度與用全部數據訓練出來的梯度是幾乎一樣的。
在合理的範圍內,增大Batch_size 有什麼好處?
- 記憶體利用率提高了,大矩陣乘法的並行化效率提高
- 跑完一次epoch(全數據集)所需要的迭代次數減少,對於相同數據量的處理速度進一步加快。
- 在一定範圍內,一般來說Batch_Size 越大,其確定的下降方向越准,引起訓練震蕩越小。
盲目增大Batch_size 有什麼壞處?
記憶體利用率提高了,但是記憶體容量可能撐不住了
跑完一次epoch(全數據集)所需要的迭代次數減少,要想達到相同的精度,其所花費的時間大大的增加了,從而對參數的修正也就顯得更加緩慢。
Batch_size 增大到一定程度,其確定的下降方向已經基本不再變化。
5,調節Batch_Size 對訓練效果影響到底如何?
這裡有一個LeNet 在MNIST 數據集上的效果。MNIST 是一個手寫體標準庫。
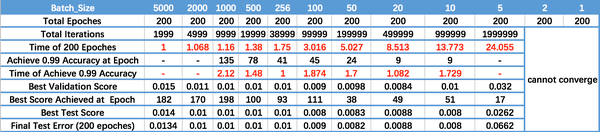
運行結果如上圖所示,其中絕對時間做了標準化處理。運行結果與上文分析相印證:
- Batch_Size 太小,演算法在200 epochs 內不收斂。
- 隨著Batch_Size 增大,處理相同數據量的速度越快。
- 隨著Batch_Size 增大,達到相同精度所需要的epoch 數量越來越多
- 由於上述兩種因素的矛盾,Batch_Size 增大到某個時候,達到時間上的最優
- 由於最終收斂精度會陷入不同的局部極值,因此Batch_Size 增大到某些時候,達到最終收斂精度上的最優
此文是自己的學習筆記總結,學習於《TensorFlow深度學習框架》,俗話說,好記性不如爛筆頭,寫寫總是好的,所以若侵權,請聯繫我,謝謝。
