招聘網站爬蟲模板
招聘網站爬蟲模板
- 項目的創建
- 項目的設置
- 中間件的理解與使用
- selenium的基本使用
爬蟲項目的創建:
- scrapy startproject spiderName
- cd spiderName
- scrapy genspider name www.xxx.com
項目的設置:
settings的基礎設置:
-
USER_AGENT='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36' -
ROBOTSTXT_OBEY = False #關閉協議 LOG_LEVEL = 'ERROR' #日誌輸出最低等級 -
DOWNLOADER_MIDDLEWARES = { #開啟下載器中間件 # 'TZemployment.middlewares.TzemploymentDownloaderMiddleware': 543, 'TZemployment.middlewares.自定義中間件名字': 543, } -
ITEM_PIPELINES = { #開啟item 'TZemployment.pipelines.TzemploymentPipeline': 300, }
中間件的理解與使用:
雖然中間件網上的示意圖都爛大街了,我還是想貼一下;
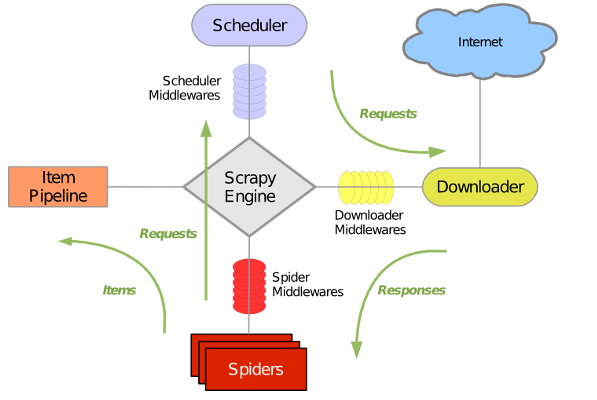
中間件分為下載器中間件與爬蟲中間件,我們常說的中間件為下載器中間件;
定義(官方解釋):
下載器中間件是位於引擎和下載器之間的特定掛鉤,它們在從引擎傳遞到下載器時處理請求,以及從下載器傳遞到引擎的響應。
如果需要執行以下操作之一,請使用Downloader中間件:
- 在將請求發送到下載器之前處理請求(即,在Scrapy將請求發送到網站之前);
- 在將接收到的響應傳遞給蜘蛛之前,先對其進行更改;
- 發送新的請求,而不是將收到的響應傳遞給蜘蛛;
- 將響應傳遞給蜘蛛,而無需獲取網頁;
- 默默地丟棄一些請求。
說人話就是:所有的請求與響應都會經過它,我們可以截取並修改成我們需要的形式或功能;
下載器中間件的好處:
- 可以集成Selenium、重試和處理請求異常等
- 我們就是用到了Selenium在中間件中對接scrapy;
selenium在中間件中的使用:
selenium的基本語法:
推薦該網站://www.testclass.net/selenium_python

通過selenium中的page_source獲取網頁源碼,發送至spider下的parse進行xpath解析。
# -*- coding: utf-8 -*-
from scrapy import signals
from scrapy.http import HtmlResponse
import time
#設置selenium的中間件
class SelemiumSpiderMiddleware(object):
#對發送的
def process_request(self,request,spider):
#通過spider調用spider下的driver屬性
spider.driver.get(request.url)
time.sleep(1)
page_text = spider.driver.page_source
return HtmlResponse(url=request.url,body=page_text,request=request,encoding='utf-8')
存儲部分:(pipelines模組)
該存儲功能如下,程式碼暫時不開放;
調用外部文件,自動建庫建表,對MySQL中的數據進行檢測是否重複;
主函數spider配置:
# -*- coding: utf-8 -*-
import scrapy
from selenium import webdriver
#from .. import items
from TZtalent.items import TztalentItem
#from 主項目名.items import items中的類
class TzcodeSpider(scrapy.Spider):
#泰州就業人才網
name = 'tzcode'
# allowed_domains = ['www.xxx.com']
#不需要動,改相應的配置資訊即可
#傳參
def __init__(self,table_name,keyword,webhook,*args,**kwargs):
super(TzcodeSpider, self).__init__(*args, **kwargs)
# path = r"C:\Users\Administrator\Desktop\phantomjs-1.9.2-windows\phantomjs.exe"
# self.driver = webdriver.PhantomJS(executable_path=path)
#防止selenium識別
options = webdriver.ChromeOptions()
options.add_experimental_option("excludeSwitches", ["enable-automation"])
options.add_experimental_option('useAutomationExtension', False)
self.driver = webdriver.Chrome(options=options)
self.driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""
})
# self.driver = webdriver.Chrome()
##靈活變動,有的網站統一是gb2312編碼,需要將URL進行轉換--urlencode編碼
#self.keyword = quote(keyword.encode("gb2312"))
self.keyword = keyword
self.webhook_url = webhook
self.table_name = table_name
self.start_urls =[f"-----------url------{self.keyword}"]
#解析selenium發過來的response數據
def parse(self, response):
# print(response.url)
#父標籤---所需要資訊標籤上的父標籤
div_list = response.xpath("父標籤xpath語法")
item = TzemploymentItem()
for div in div_list:
item['title'] = div.xpath("./匹配的title資訊xpath").extract_first()
#判斷title是否為空
if item['title'] == None:
break
item['company_name'] = div.xpath("./匹配的company_name資訊xpath").extract_first()
item['company_url'] = div.xpath("./匹配的company_url資訊xpath").extract_first()
item['site'] = div.xpath('./匹配的site資訊xpath').extract_first()
yield items
#
def __del__(self):
#退出驅動並關閉所有關聯的窗口
self.driver.quit()
傳參並啟動爬蟲:
#spider中url與xpath配置完成後,進行參數設置
from scrapy import cmdline
cmdline.execute("scrapy crawl tzcode -a table_name=表名 -a keyword=java -a webhook=".split())

