ZooKeeper 入門指引
定義
Apache ZooKeeper is an effort to develop and maintain an open-source server which enables highly reliable distributed coordination.
ZooKeeper是一個開源的,高可靠性的分散式系統協調器。它公開了一些常用的服務,如命名,配置管理,同步和組服務,你可以用它來共識、組管理、領導人選舉和出席協議,甚至可以根據自己的需求來構建它.
特點
1.簡單
zookeeper實現分散式協調的功能是通過一個共享的層級空間,類似於標準的文件系統,它有所謂的znodes組成,即類似文件系統中的文件和目錄。但是跟文件系統不同的是,它不是用來存儲的,他的數據保存在記憶體中,這樣可以達到高吞吐低延遲的目標。在CAP理論中,zookeeper保證了CP即一致性和分區容錯性,
2.可靠
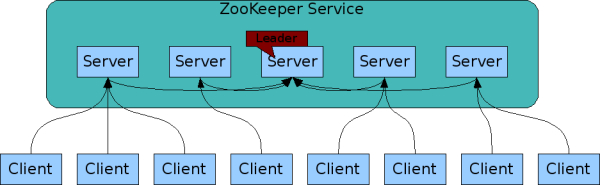
zk通過一組集群來保證高度的可靠,如下圖zookeeper集群當中broker相互都知道對方的存在,它們的數據狀態都維護在記憶體,同時在磁碟會有失誤日誌和數據快照,只要大部分server有效就能保證zk有效。
3.順序一致性
zk為每個更新添加一個反映所有ZooKeeper事務順序的數字。後續操作可以使用該順序來實現更高級別的抽象,例如同步原語
4.快
它在「以讀為主」的工作負載中尤其快。ZooKeeper應用程式運行在數千台機器上,在讀操作比寫操作更常見的情況下,它的性能最好,其比率大約為10:1。
5.類似文件系統的模型架構
zk提供的命名空間非常類似於標準文件系統的名稱空間。名稱是由斜杠(/)分隔的路徑元素序列。zk命名空間中的每個節點都由路徑標識。
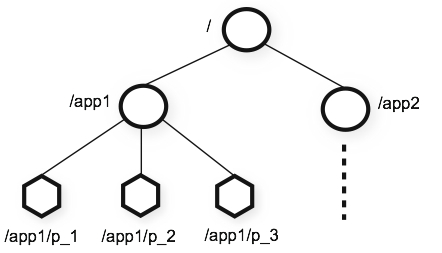
6.永久節點和臨時節點
znode維護一個stat結構,其中包括數據更改、ACL更改和時間戳的版本號,以允許快取驗證和協調更新。每次znode的數據更改時,版本號都會增加。例如,每當客戶機檢索數據時,它也會收到數據的版本。存儲在命名空間中每個znode的數據是以原子方式讀寫的。Reads獲取與znode關聯的所有數據位元組,write替換所有數據。每個節點都有一個訪問控制列表(ACL),它限制了誰可以做什麼。
臨時節點:只要創建znode的會話處於活動狀態,這些znode就存在。會話結束時,znode被刪除。
7.事件監聽
ZooKeeper允許用戶在指定節點上註冊一些 Watcher,並且在一些特定事件觸發的時候,ZooKeeper服務端會將事件通知到感興趣的客戶端上去。該機制是 ZooKeeper 實現分散式協調服務的重要特性
8.簡單的API
- create : 創建節點
- delete : 刪除節點
- exists : 判斷節點是否存在
- get data : 讀取節點數據
- set data : 寫節點數據
- get children : 獲取子節點
- sync : 等待數據傳播
下載安裝
下載地址: //zookeeper.apache.org/releases.html#download 解壓到合適目錄,測試版本3.5.5
將conf下樣例配置文件zoo_sample.cfg複製一份重來命名為zoo.cfg,配置下數據目錄和日誌目錄,接下來啟動測試
服務端啟動:zkServer.cmd
客戶端啟動:zkCli.cmd
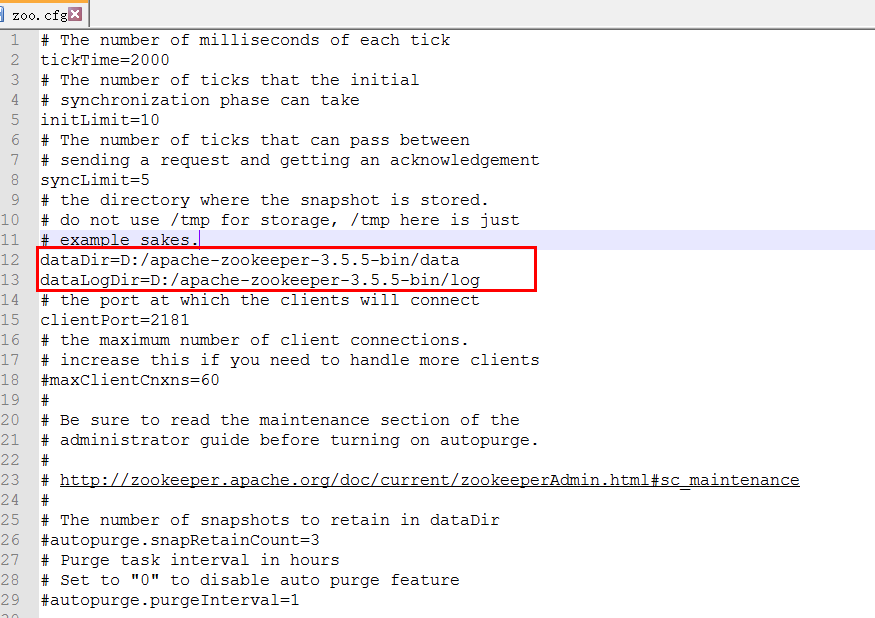

啟動服務端時似乎埠被佔用,所以再加個配置項
admin.serverPort=8888
同時看到myid值為空,window下測試時也沒有生成myid文件,默認會去dataDir配置的目錄找這個文件,可自己創建一個myid文件並在文件里寫入一個序號標識該伺服器,注意文件名為myid而不是myid.txt
服務端啟動後可以看到有個java.exe 偵聽埠2181

啟動客戶端


集群模式
zk的安裝模式可以分為3種,分別為:單機模式,集群模式和偽集群模式。上面演示的即為單機模式;通過多台集群提供服務即為集群模式;一台電腦還可以進行偽集群模式,即在一台物理電腦上運行多個zk實例。
集群模式是通過配置文件的配置項來設置,主要涉及的配置項如下:
initLimit=10
syncLimit=5
server.1=192.168.191.1:2888:3888
server.2=192.168.191.2:2888:3888
-
initlimit:用來配置zk接受客戶端(指zk集群中連接都leader的follower伺服器)初始化連接時最長能忍受多少個心跳時間間隔數。當已經超過10個心跳時間(即tickTime)長度後zk伺服器還沒有收到客戶端返回的資訊,那麼表明這個客戶端連接失敗。總時間長度為10*2000=20s
-
synclimit:標識leader和follower之間發送消息,請求和應答時間長度,最長不能超過多少個ticktime的時間長度,總時間程度為:5*2000=10s
-
server.A=B:C:D:其中 A 是一個數字,表示這個是第幾號伺服器;B 是這個伺服器的 ip 地址;C 表示的是這個伺服器與集群中的 Leader 伺服器交換資訊的埠;D 表示的是萬一集群中的 Leader 伺服器掛了,需要一個埠來重新進行選舉,選出一個新的 Leader,而這個埠就是用來執行選舉時伺服器相互通訊的埠,通俗一點講就是C埠用於集群內部通訊,D埠用於leader選舉。如果是偽集群的配置方式,由於 B 都是一樣,所以不同的 Zookeeper 實例通訊埠號不能一樣,所以要給它們分配不同的埠號。
集群模式下還需要修改一個文件myid,這個文件在dataDir目錄下,這個文件裡面就有一個數據就是 A 的值,Zookeeper 啟動時會讀取這個文件,拿到裡面的數據與 zoo.cfg 裡面的配置資訊比較從而判斷到底是哪個 server。
對於集群模式,至少需要三台伺服器,強烈建議使用奇數個伺服器。如果您只有兩台伺服器,那麼您將處於這樣一種情況:如果其中一台伺服器發生故障,則沒有足夠的電腦組成多數仲裁。兩台伺服器天生就比一台伺服器不穩定,因為有兩個單點故障
接下來我們做一個為集群模式的測試,配置出3個zk實例
-
配置文件修改,zoo.cfg文件配置出3份
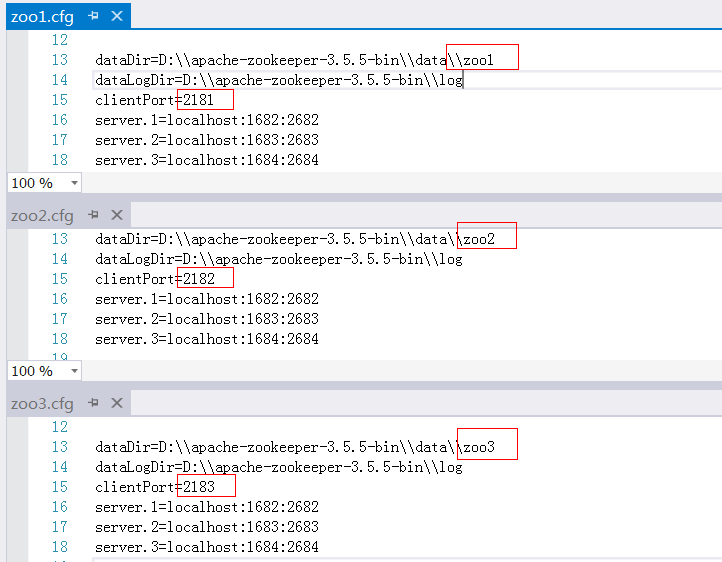
響應的在各自的datadir下創建自己的myid文件,注意無後綴名,內容為1,2,3 分別用來表示第幾號伺服器 -
服務端啟動配置文件,同樣複製3份

-
啟動服務
當啟動第1個cmd文件zkServer1.cmd時,會報如下錯誤,啟動第2個cmd文件zkServer2.cmd就正常了,依次啟動zkserver1.cmd,zkserver2.cmd,zkserver3.cmd,報錯資訊是zookeeper的Leader選舉演算法的異常資訊,當節點沒有啟動完畢的時候,Leader無法正常進行工作,這種錯誤資訊是可以忽略的,等其他節點啟動之後就正常了。

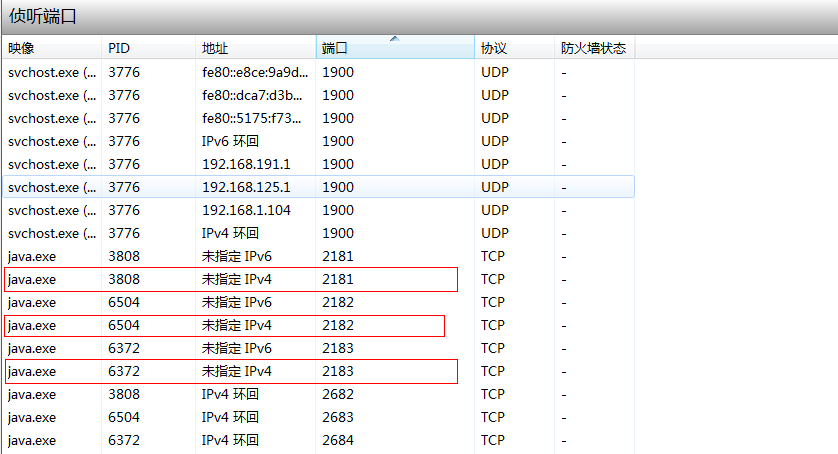
3個埠已全部啟動




參考鏈接 //zookeeper.apache.org/doc/r3.6.2/zookeeperOver.html


