論文翻譯:2020_Acoustic Echo Cancellation Challenge Datasets And Testingframework
論文地址:ICASSP 2021聲學回聲消除挑戰:數據集和測試框架
程式碼地址://github.com/microsoft/DNS-Challenge
主頁://aec-challenge.azurewebsites.net/
摘要
ICASSP 2021年聲學回聲消除挑戰賽旨在促進聲學回聲消除(AEC)領域的研究,該領域是語音增強的重要組成部分,也是音頻通訊和會議系統中的首要問題。許多最近的AEC研究報告了在訓練和測試樣本(來自相同基礎分布的合成數據集)上的良好性能。然而,AEC的性能經常在真實錄音上顯著下降。此外,在現實環境中存在背景雜訊和混響的情況下,大多數傳統的客觀指標,如回聲回波損耗增強(ERLE)和語音品質感知評估(PESQ),與主觀語音品質測試沒有很好的相關性。在這個挑戰中,我們開源了兩個大數據集來訓練在單對話和雙對話場景下的AEC模型。這些數據集包括來自
- 2500多個真實的音頻設備
- 真實環境中的人類說話人的錄音
- 一個合成數據集
我們基於ITU-T P.808開源了一個在線主觀測試框架,以便研究人員快速測試他們的結果。這個挑戰的獲勝者將根據所有不同的單向談話和雙向談話的平均P.808平均意見分數(MOS)來選擇。
關鍵詞:聲學回聲消除、深度學習、單語、雙語、主觀測試
1 引言
隨著遠程工作的日益普及和需求,諸如Microsoft Teams、Skype、WebEx、Zoom等遠程會議系統的使用顯著增加。為了讓用戶體驗愉快和富有成效,必須有高品質的通話。在語音和影片通話中,回聲引起的通話品質下降是語音和影片通話品質較差的主要原因之一。雖然基於數字訊號處理(DSP)的聲學回聲消除(AEC)模型已被用於在通話過程中消除這些回聲,但對於物理聲學設計較差的設備或超出其設計目標和實驗室的測試環境的設備,其性能可能會降低。在全雙工通訊模式下,這個問題變得更具挑戰性,因為在沒有顯著失真或衰減的情況下,雙重通話場景的回聲很難抑制[1]。
隨著深度學習技術的出現,一些用於AEC的監督學習演算法與經典演算法相比表現出了更好的性能[2,3,4]。一些研究也表明,將經典和深度學習方法相結合,如使用自適應濾波器和遞歸神經網路(RNNs)[4,5]具有良好的性能,但僅適用於合成數據集。雖然這些方法對AEC模型的性能提供了一個很好的啟發式,但還沒有證據表明它們在真實數據集上(不同的噪音和混響環境)的性能。這使得該行業的研究人員很難選擇一個能夠在具有代表性的真實數據集上表現良好的模型。
大多數帶有評估的AEC論文使用的客觀測量有:回聲回波損耗增強(ERLE) [6]和語音品質感知評估(PESQ [7]。ERLE被定義為:
$$E R L E=10 \log _{10} \frac{\mathbb{E}\left[y^{2}(n)\right]}{\mathbb{E}\left[\hat{y}^{2}(n)\right]}$$
其中$y(n)$是麥克風訊號,$\hat{y}(n)$是增強語音。ERLE只有在沒有背景噪音的安靜房間里測量時才合適,並且只適用於單向談話場景(不是兩向談話)。在存在背景雜訊的情況下,PESQ也被證明與主觀語音品質沒有很高的相關性[8]。使用本挑戰中提供的數據集,我們表明ERLE和PESQ與主觀測試的相關性較低(表1)。為了在真實環境中使用帶有錄音的數據集,我們不能使用ERLE和PESQ。需要一個更可靠、更穩健的評估框架,讓研究界的每個人都能使用。
這個AEC挑戰旨在通過開放一個大型訓練數據集、測試集和主觀評估框架來刺激AEC領域的研究工作。我們為訓練AEC模型提供了兩個新的開源數據集。
- 第一個是使用大規模眾包工作捕獲的真實數據集。該數據集由從2500多種不同音頻設備和環境中收集的真實錄音組成。
- 第二個是合成數據集,增加了來自[9]的房間脈衝響應和背景雜訊。
最初的測試集將被發布,供研究人員在開發過程中使用,並在臨近結束時進行盲測,以決定最終的比賽獲勝者。我們相信這些數據集不僅是AECs的第一個開源數據集,而且是足夠大的數據集,可以促進深度學習,在電信產品的運輸中具有足夠的代表性。
在[9]深度雜訊抑制挑戰中,我們證明了一種眾包的主觀品質評價對語音增強挑戰是有效的。因此,我們將再次使用ITU-T P.808 [10] 人群源主觀品質評價對提交的AEC方法進行比較。在評價時,我們採用了基於dnn的AEC方法(第4節)作為參考。在線主觀評價框架將在第5節中討論。第6節介紹了挑戰規則和其他後勤工作。
2 訓練數據集
挑戰將包括兩個新的開源數據集,一個是真實的,一個是合成的。數據集可在//github.com/microsoft/AEC-Challenge獲得。
2.1 真實數據集
第一個數據集是通過大規模的眾包工作獲得的。此數據集由以下場景中的超過2500個不同的真實環境、音頻設備和人類說話人組成:
- 遠端單端通話,無回聲路徑改變
- 遠端單端通話,迴音路徑改變
- 近端單端通話,無回聲路徑改變
- 雙端通話,無回聲路徑改變
- 雙端通話,迴音路徑改變
- 用於RT60估計的掃描訊號(Sweep signal)
- 對於遠端單端通話情況,只有揚聲器訊號(遠端)向用戶播放而用戶保持沉默(無近端訊號)。
- 對於近端單端通話情況,沒有遠端訊號,並且提示用戶講話,捕捉近端訊號。
- 對於雙向通話情況,遠端和近端訊號均處於活動狀態,在該揚聲器中播放揚聲器訊號,並且用戶同時通話。
- 回聲路徑改變是通過指示用戶在設備周圍移動或讓自己移動設備來實現的。
每種情況都包括揚聲器,麥克風和環回(loopback)訊號。 圖1給出了近端單通話語音品質。使用Karjalainen等人[11]的方法估算了數據集的RT60分布,如圖2所示。RT60估計值可用於對數據集進行取樣以進行訓練。

圖1.以95%的置信區間對近端單個談話片段品質(P.808)進行了排序
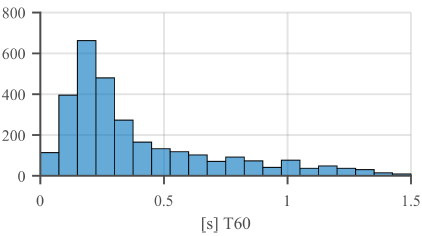
圖2 混響時間分布(T60)
我們使用亞馬遜機械土耳其公司作為眾包(crowdsourcing)平台,並編寫了一個訂製的HIT應用程式,其中包括一個自定義工具,評估人員下載並執行該工具以記錄上述六個場景。 數據集僅包含Microsoft Windows設備。
對於純凈的語音遠端訊號,我們使用來自愛丁堡數據集的語音片段[12]。 該語料庫由簡短的單個說話者語音片段(1到3秒)組成。 我們使用了基於長期短期記憶(LSTM)的性別檢測器來選擇相等數量的男性和女性說話者片段。 此外,我們將這些短片段中的3到5個組合在一起,以創建長度在9到15秒之間的片段。 每個剪輯均由一位性別發言人組成。 我們創建了一個由500個男性和500個女性剪輯組成的性別平衡的遠端訊號源。 記錄以設備支援的最大取樣率和32位浮點格式保存; 在發布的數據集中,我們使用自動增益控制將取樣降低到16KHz和16位,以最大程度地減少片段。
對於有雜訊的語音遠端訊號,我們使用來自DNS Challenge[9]的數據以及該數據集中的近端單段通話場景的片段。
對於近端語音,用戶會被提示閱讀TIMIT[13]句子列表中的句子。當用戶閱讀時,大約10秒的音頻被記錄下來。
2.2 合成數據集
第二個數據集提供了10,000個合成示例,分別表示單端通話,雙端通話,近端雜訊,遠端雜訊和各種非線性失真情況。 每個示例都包括遠端語音,回聲訊號,近端語音和近端麥克風訊號片段。 我們從LibriVox project1的[9]中獲得的純凈語音和帶噪語音數據集中使用12,000個案例(100小時的音頻)作為源剪輯來取樣遠端和近端訊號。 LibriVox項目是志願者閱讀的公共領域有聲讀物的集合[9]。使用在線主觀測試框架ITU-T P.808從LibriVox項目中選擇了高品質的錄音(4.3 MOS 5)。 通過將乾淨的語音與從Audioset [14],Freesound2和DEMAND [15]資料庫中取樣的雜訊片段混合在一起,以不同的信噪比水平創建嘈雜的語音數據集。
為了模擬遠端訊號,我們從1,627個說話人池中選擇一個隨機說話人,從說話人中隨機選擇一個片段,並從片段中取樣10秒的音頻。 對於近端訊號,我們隨機選擇另一個說話人並獲取3-7秒的音頻,然後將其零填充到10秒。 為了產生回聲,我們從一個大型內部資料庫中隨機選擇一個房間脈衝響應與遠端訊號進行卷積。在80%的情況下,通過非線性函數處理遠端訊號以模仿揚聲器失真。 該訊號與近端訊號以從-10 dB到10 dB均勻取樣的信噪比混合。 在50%的情況下,從嘈雜的數據集中獲取遠端和近端訊號。 前500個片段可用於驗證,因為它們有一個單獨的發言者和房間脈衝響應列表。可以在存儲庫中找到詳細的元數據資訊。
3 測試集
將包括兩個測試集,一個在挑戰開始時,一個接近結束的盲測試集。 兩者都包含大約800個錄音,並分為以下幾種情況:
- 近端和遠端的純凈語音(MOS> 4)
- 近端和遠端的嘈雜語音
4 基準線AEC方法
我們採用文獻[16]中的雜訊抑制模型來實現回聲消除的任務。 其中,具有門控循環單元的循環神經網路將麥克風訊號和遠端訊號的級聯對數功率頻譜特徵作為輸入,並輸出頻譜抑制掩碼(spectral suppression mask)。 STFT是根據幀長20 ms,幀移為10ms,320點離散傅里葉變換計算的。 我們使用兩個GRU層的堆棧,然後是具有S型激活功能的全連接層。 將估計的掩碼逐點乘以麥克風訊號的幅度譜圖,以抑制遠端訊號。 最後,為了重新合成增強的訊號,在麥克風訊號和估計的幅度譜圖的相位上使用了短時傅立葉逆變換。 我們在純凈頻譜圖和增強幅度頻譜圖之間使用均方誤差損失。 學習率為0.0003的Adam優化器用於訓練模型。
5 在線主觀評估框架 ITU-T P.808
AEC評估的主要標準是用於客觀評估(例如ERLE)的G.168 [6]和用於主觀評估的P.831 [17]。如前所述,ERLE和PESQ並不是評估實際數據AEC性能的可行指標。 P.831第7節中給出的主觀測試是可行的,儘管它假設測試環境安靜。例如,在P.831中,為了測量遠端的單端通話回聲性能,使用圖3中的設置進行錄音,並要求評估者對Sout處的回聲量進行評估。但是,任何背景雜訊都會使評估者混淆什麼是回聲泄露,什麼不是。我們的解決方案是實現一個三方通話的主觀評分,評分者是偵聽者(見圖4)。為了構造一個聽眾可以聽到的延遲回聲訊號,將遠端訊號(說話人訊號)與AEC輸出的600ms延遲輸出訊號相結合,以模擬較大的網路延遲。這使評估者可以聽到遠端語音和延遲的回聲泄漏(如果有),從而有助於評估者更好地區分回聲泄漏和雜訊。然後,我們使用P.808框架[10]通過以下來自P.831 [17]的評級調查獲得回聲MOS分數:您如何在此對話中判斷聲回聲的衰減
5、聽不清
4、可以察覺但不煩人
3、有點煩
2、煩人
1、非常煩人
挑戰中使用的音頻管道如圖5所示。在第一階段(AGC1),使用傳統的自動增益控制目標語音水平在- 24dbfs。 AGC1的輸出保存在測試集中。 下一階段是AEC,參與者將處理該AEC並將其上傳到challenge CMT站點。下一步是傳統的雜訊抑制器(DMOS <0.1改進),以減少靜態雜訊。 最後,運行第二個AGC以確保語音水平仍為-24 dBFS。
對於雙端通話場景,我們使用標準的P.808 ACR等級來評估AEC麥克風輸出的MOS得分,這是Sout上P.831估計的措施之一。
主觀測試框架可在//github.com/ microsoft/P.808獲得。

圖3所示。AEC測試步驟。S是發送,R是接收
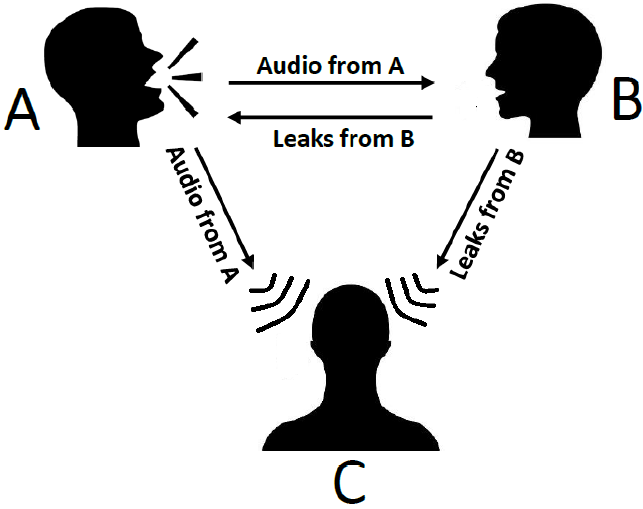
圖4.用於測量單個通話回聲的方法。 當說話人A講話時,B處的設備漏出回聲,而C正在收聽(並進行評級)
6、AEC挑戰規則和時間表
挑戰在於如何使用真實(而非模擬)測試集對實時演算法的性能進行基準測試。 參與者將在測試儀上評估其AEC,並將結果(音頻片段)提交以進行評估。 用於提交的每個AEC的要求是
- 在Intel Core i5四核機器上,,AEC必須用少於跨步時間$T_s$(以毫秒為單位)來處理大小為T(以毫秒為單位)的幀,處理器的頻率為2.4 GHz或同等的處理器。 例如,對於幀之間50%的重疊,$T_s=\frac{T}{2}$。 允許的總演算法等待時間包括幀大小T,跨步時間Ts和任何向前看都必須小於等於40ms。 例如:如果使用20ms的幀長和10ms的步長導致30ms的演算法延遲,則可以滿足延遲要求。 如果您使用的幀大小為32ms,跨度為16ms,導致演算法延遲為48ms,則您的方法無法滿足延遲要求,因為總演算法延遲超過40ms。 如果您的幀大小加上步長$T_1 = T + T_s$小於40毫秒,那麼您最多可以使用(40 T1)毫秒的未來資訊。
- AEC可以是深度模型,也可以是傳統的訊號處理演算法,也可以是兩者的混合。 除了上面描述的運行時間和演算法延遲外,對AEC沒有任何限制。
- 提交內容必須遵循//aec-challenge.azurewebsites.net上的說明。
- 將根據在第5節中所述的使用ITU-T P.808框架在盲測試集上評估的主觀回聲MOS來選出獲勝者。
- 盲測集將在2020年10月2日提供給參與者。參與者必須將通過他們開發的模型獲得的結果(音頻剪輯)發送給組織者。 我們將使用提交的剪輯進行ITU-T P.808主觀評估,並根據結果選出獲獎者。 禁止參與者使用盲測集重新訓練或調整其模型。 他們不應使用未提交給ICASSP 2021的其他AEC方法來提交結果。不遵守這些規則將導致取消參賽資格。
- 參與者應根據參數數量和推斷特定CPU(最好是時鐘頻率為2.4 GHz的Intel Core i5四核電腦)上的幀所需的時間,報告其模型的計算複雜性。 在提交的建議相差不到0.1 MOS的建議中,較低複雜度的模型將獲得較高的排名。
- 每個參賽團隊都必須提交ICASSP論文,以總結研究成果並提供所有細節以確保可重複性。 作者可以選擇在論文中報告其他客觀/主觀指標。
- 提交的論文將接受ICASSP 2021的標準同行評審過程。論文需要被會議接受才能使參加者有資格挑戰。
6.2 時間軸
2020年9月8日:數據集發布。
2020年10月2日:向參與者發布盲測集。
2020年10月9日:在盲測集上提交客觀和P.808主觀評估結果的截止日期。
2020年10月16日:主辦方將通知參賽者比賽結果。
2020年10月19日:ICASSP 2021年常規論文提交截止日期。
2021年1月22日:書面接收/拒絕通知
2021年1月25日:獲獎者通知及獲獎指示,包括領獎截止日期。
6.3 支援
參賽者可向aec [email protected]發送與挑戰有關的任何問題或需要就挑戰的任何方面進行澄清的電子郵件。
7 總結
這是第一個AEC挑戰,我們希望它既有趣又有教育意義,對於參與者和論文的讀者以及它幫助產生的想法。
8 參考文獻
[1] 「IEEE 1329 standard method for measuring transmission performance of handsfree telephone sets,」 1999.
[2] A. Fazel, M. El-Khamy, and J. Lee, 「Cad-aec: Context-aware deep acoustic echo cancellation,」 in ICASSP 2020 – 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2020, pp. 6919–6923.
[3] M. M. Halimeh and W. Kellermann, 「Efficient multichannel nonlinear acoustic echo cancellation based on a cooperative strategy,」 in ICASSP 2020 – 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2020, pp. 461–465.
[4] Lu Ma, Hua Huang, Pei Zhao, and Tengrong Su, 「Acoustic echo cancellation by combining adaptive digital filter and recurrent neural network,」 arXiv preprint arXiv:2005.09237, 2020.
[5] Hao Zhang, Ke Tan, and DeLiang Wang, 「Deep learning for joint acoustic echo and noise cancellation with nonlinear distortions.,」 in INTERSPEECH, 2019, pp. 4255–4259.
[6] 「ITU-T recommendation G.168: Digital network echo cancellers,」 Feb 2012.
[7] 「ITU-T recommendation P.862: Perceptual evaluation of speech quality (PESQ): An objective method for end-to-end speech quality assessment of narrow-band telephone networks and speech codecs,」 Feb 2001.
[8] A. R. Avila, H. Gamper, C. Reddy, R. Cutler, I. Tashev, and J. Gehrke, 「Non-intrusive speech quality assessment using neural networks,」 in ICASSP 2019 – 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2019, pp. 631–635.
[9] Chandan KA Reddy, Vishak Gopal, Ross Cutler, Ebrahim Beyrami, Roger Cheng, Harishchandra Dubey, Sergiy Matusevych, Robert Aichner, Ashkan Aazami, Sebastian Braun, et al., 「The interspeech 2020 deep noise suppression challenge: Datasets, subjective testing framework, and challenge results,」 arXiv preprint arXiv:2005.13981, 2020.
[10] Babak Naderi and Ross Cutler, 「An open source implementation of itu-t recommendation p. 808 with validation,」 arXiv preprint arXiv:2005.08138, 2020.
[11] Matti Karjalainen, Poju Antsalo, Aki M¨akivirta, Timo Peltonen, and Vesa V¨alim¨aki, 「Estimation of modal decay parameters from noisy response measurements,」 J. Audio Eng. Soc, vol. 50, no. 11, pp. 867, 2002.
[12] Cassia Valentini-Botinhao, Xin Wang, Shinji Takaki, and Junichi Yamagishi, 「Speech enhancement for a noise-robust textto- speech synthesis system using deep recurrent neural networks.,」 in Interspeech, 2016, pp. 352–356.
[13] J. S. Garofolo, L. F. Lamel, W. M. Fisher, J. G. Fiscus, D. S.
Pallett, and N. L. Dahlgren, 「DARPA TIMIT acoustic phonetic continuous speech corpus CDROM,」 1993.
[14] Jort F Gemmeke, Daniel PW Ellis, Dylan Freedman, Aren Jansen, Wade Lawrence, R Channing Moore, Manoj Plakal, and Marvin Ritter, 「Audio set: An ontology and human-labeled dataset for audio events,」 in 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2017, pp. 776–780.
[15] Joachim Thiemann, Nobutaka Ito, and Emmanuel Vincent, 「The diverse environments multi-channel acoustic noise database: A database of multichannel environmental noise recordings,」 The Journal of the Acoustical Society of America, vol. 133, no. 5, pp. 3591–3591, 2013.
[16] Yangyang Xia, Sebastian Braun, Chandan KA Reddy, Harishchandra Dubey, Ross Cutler, and Ivan Tashev, 「Weighted speech distortion losses for neural-network-based real-time speech enhancement,」 in ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020, pp. 871–875.
[17] 「ITU-T P.831 subjective performance evaluation of network echo cancellers ITU-T P-series recommendations,」 1998.


