如何無縫地將人工智慧擴展到分散式大數據
- 2020 年 9 月 19 日
- 筆記
- analytics zoo, bigdl, spark
作者:Jason Dai,最初發表於LinkedIn Pulse。
6 月初,在今年的虛擬 CVPR 2020 上,我在半天的 教程課中 介紹 了如何構建面向大數據的深度學習應用程式。這是一個非常獨特的體驗,在本文中,我想分享本教程的一些重點內容。
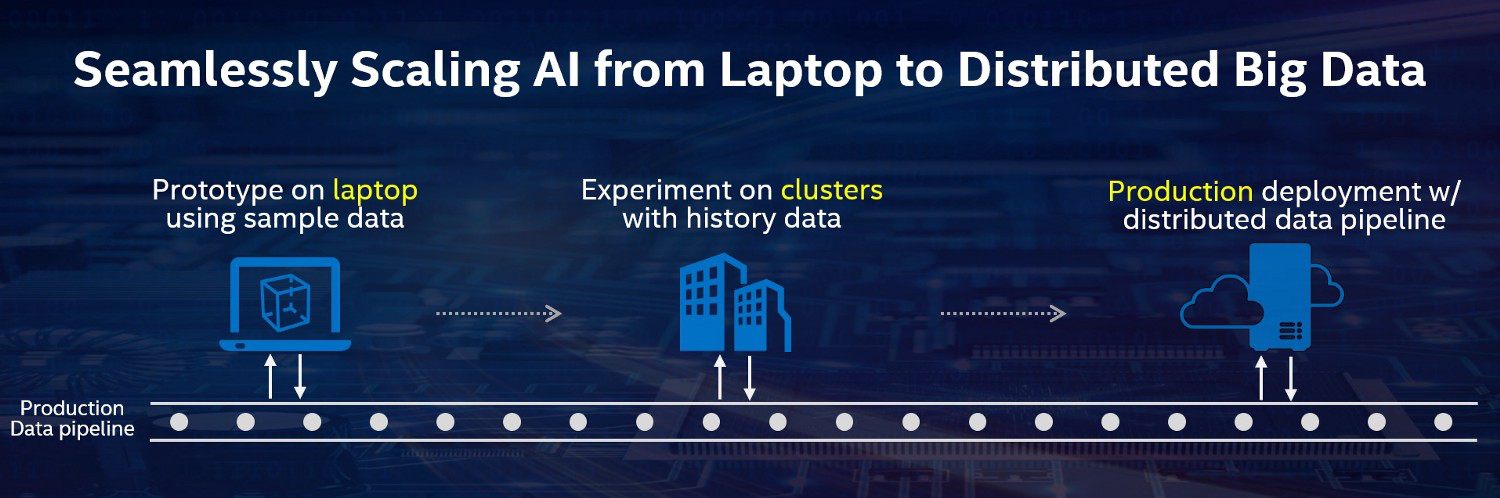
關鍵問題:大數據上的人工智慧
本教程的重點是AI 從實驗階段進入生產應用這個過程中出現的一個關鍵問題,即 如何無縫地將人工智慧擴展到分散式大數據 。如今,人工智慧研究人員和數據科學家要將人工智慧模型應用到存儲在分散式大數據集群中的生產數據集上,都需要經歷巨大的痛苦。
通常,傳統的方法是配置兩個獨立的集群,一個用於大數據處理,另一個用於深度學習(例如GPU 集群),中間部署「連接器」(或膠水程式碼)。遺憾的是,這種「連接器方法」不僅帶來了大量的開銷(例如,數據複製、額外的集群維護、碎片化的工作流等),而且還會因為跨異構組件而導致語義不匹配(下一節將對此進行詳細介紹)。
為了應對這些挑戰,我們開發了開源技術,直接在大數據平台上支援新的人工智慧演算法。如下圖所示,這包括 BigDL (面向 Apache Spark 的分散式深度學習框架)和 Analytics Zoo (Apache Spark/Flink&Ray 上的分散式 Tensorflow、Keras 和 PyTorch)。

一個啟發性的示例: JD.com
在深入講解 BigDL 和 Analytics Zoo 的技術細節之前,我在教程中分享了一個啟發性的示例。京東是中國最大的網購網站之一;他們在 HBase 中存儲了數以億計的商品圖片,並構建了一個端到端的對象特徵提取應用程式來處理這些圖片(用於影像相似性搜索、圖片去重等)。雖然對象檢測和特徵提取是標準的電腦視覺演算法,但如果擴展到生產環境中的數億張圖片,這將是一個相當複雜的數據分析流水線,如下面的幻燈片所示。
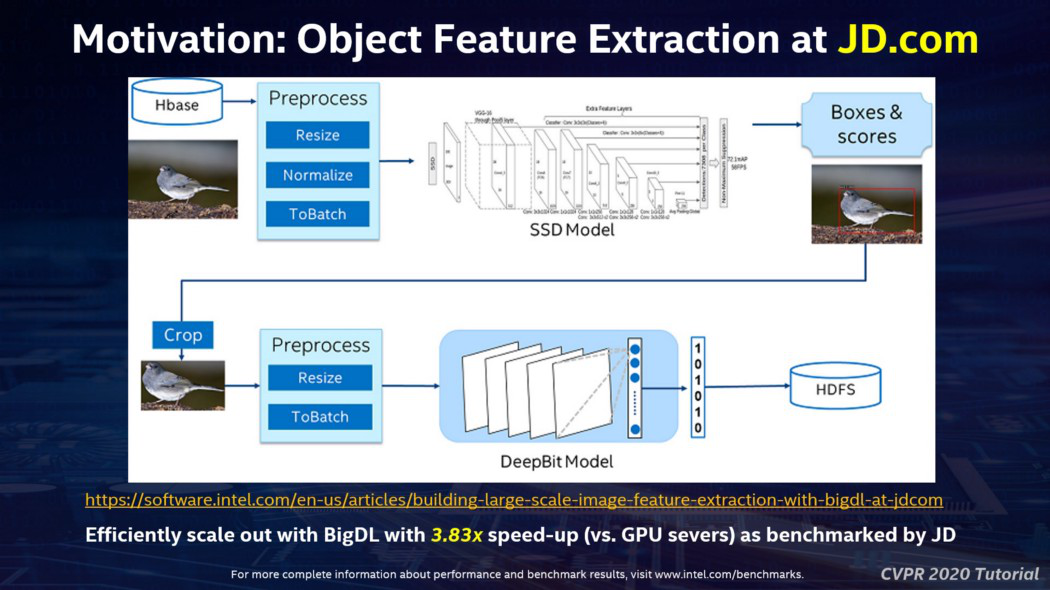
之前,京東的工程師在 5 節點的 GPU 集群上構建了解決方案,採用的是「連接器方法」:從 HBase 讀取數據,跨集群對數據進行分區和處理,然後在 Caffe 上運行深度學習模型。這個過程非常複雜且容易出錯(因為數據分區、負載平衡、容錯等都需要手動管理)。此外,「連接器」還出現了語義不匹配的情況(在這裡是 HBase+Caffe)——從 HBase 讀取數據大約需要花費一半的時間(因為任務並行性與系統中 GPU 卡的數量相關,與 HBase 交互讀取數據的速度太慢了)。
為了克服這些問題,京東的工程師使用 BigDL 實現了端到端的解決方案(包括數據載入、分區、預處理、DL 模型推斷等),作為一個統一的管道,以分散式方式運行在單個 Spark 集群上。這不僅極大地提高了開發效率,而且速度比 GPU 解決方案提高了大約 3.83 倍。要了解這個應用程式的更多細節,可以參考 [1] 和 [2] 。
關鍵技術:BigDL框架
在過去的幾年裡,我們一直在推動開源技術,力爭無縫地將人工智慧擴展到分散式大數據。2016 年,我們開源了 BigDL ,一個面向 Apache Spark 的分散式深度學習框架。它被實現為 Spark 上的一個標準庫,並提供了一個富有表現力的、「數據分析集成」深度學習編程模型。因此,用戶可以將新的深度學習應用程式作為標準的 Spark 程式構建,無需進行任何更改,就可以在現有的大數據集群上運行,如下面的幻燈片所示。

與機器學習社區的一般常識(細粒度的數據訪問和就地更新對於高效的分散式訓練至關重要)相反,BigDL 直接在 Spark 的函數式計算模型(具有寫時複製和粗粒度操作特性)上提供可擴展的分散式訓練。它使用 Spark 中現有的原語(比如 shuffle、broadcast、記憶體快取等)實現了一個高效的類 AllReduce 操作,與 Ring AllReduce 具有相似的性能特徵。詳情請參閱我們的 SoCC 2019 論文。
關鍵技術:Analytics Zoo平台
BigDL 提供了 Spark 原生框架讓用戶建立深度學習應用程式, Analytics Zoo 則試圖解決一個更普遍的問題:如何以分散式、可擴展的方式無縫地將任意人工智慧模型(可以使用 TensroFlow、PyTorch、PyTorch、Keras、Caffe 等等)應用到存儲在大數據集群上的生產數據。

如上面的幻燈片所示,Analytics Zoo 是在 DL 框架和分散式數據分析系統之上實現的一個更高層次的平台。特別是,它提供了一個「端到端 流水線 層」,可以無縫地將 TensorFlow、Keras、PyTorch、Spark 和 Ray 程式集成到一個集成 流水線 中,後者可以透明地擴展到大型(大數據或 K8s)集群,用於分散式訓練和推理。
作為一個具體的例子,下面的幻燈片展示了 Analytics Zoo 用戶如何在 Spark 程式中直接編寫 TensorFlow 或 PyToch 程式碼;這樣,程式就可以先使用 Spark 處理大數據(存儲在 Hive、HBase、Kafka、Parquet 中),然後將記憶體中的 Spark RDD 或 Dataframes 直接提供給 TensorFlow/PyToch 模型用於分散式訓練或推理。在底層,Analytics Zoo 會自動處理數據分區、模型複製、數據格式轉換、分散式參數同步等,這使得 TensorFlow/PyToch 模型可以無縫地應用於分散式大數據。

總結
在本教程中,我還分享了更多關於如何使用 Analytics Zoo 構建可擴展大數據 AI 流水線 的細節,包括高級功能(比如 RayOnSpark、用於時序數據的 AutoML 等)和 實際的應 用案例(比如 Mastercard、Azure、CERN、SK Telecom 等)。感興趣的讀者,可以查閱以下資料:
- 我的 CVPR 2020 教程網站 (//jason-dai.github.io/cvpr2020/)
- Analytics Zoo Github 網址 (//github.com/intel-analytics/analytics-zoo)
- Analytics Zoo 用例頁 (//analytics-zoo.github.io/master/#powered-by/)
參考
- 「Building Large-Scale Image Feature Extraction with BigDL at JD.com」, //software.intel.com/en-us/articles/building-large-scale-image-feature-extraction-with-bigdl-at-jdcom
- 「BigDL: A Distributed Deep Learning Framework for Big Data」, ACM Symposium of Cloud Computing conference (SoCC) 2019, //arxiv.org/abs/1804.05839

