(數據科學學習手札95)elyra——jupyter lab平台最強插件集
- 2020 年 9 月 19 日
- 筆記
- jupyter lab
本文示例文件已上傳至我的
Github倉庫//github.com/CNFeffery/DataScienceStudyNotes
1 簡介
jupyter lab是我最喜歡的編輯器,在過往的文章中也給大家介紹過很多相關資源和實用插件,但本文要給大家介紹的jupyter lab插件elyra,絕對是我使用過的最強大的jupyter lab插件沒有之一,因為它的核心功能就是幫助我們解決數據分析工作中非常重要的問題——搭建工作流。

2 利用elyra搭建工作流
在安裝elyra插件集之前,請確保你的jupyter lab版本在2.0及以上,並且已經安裝好了nodejs也就是所有jupyter lab拓展插件都需要的依賴。
不像常規的jupyter lab插件的安裝方法,我們執行下列命令即可安裝elyra下集成的多個插件:
pip install --upgrade elyra && jupyter lab build
安裝完之後,你的jupyter lab操作介面外觀會發生一些變化,我們先記住在安裝elyra之前我們的jupyter lab介面長啥樣(我使用的主題感興趣的朋友可以通過jupyter labextension install jupyterlab-tailwind-theme來安裝):
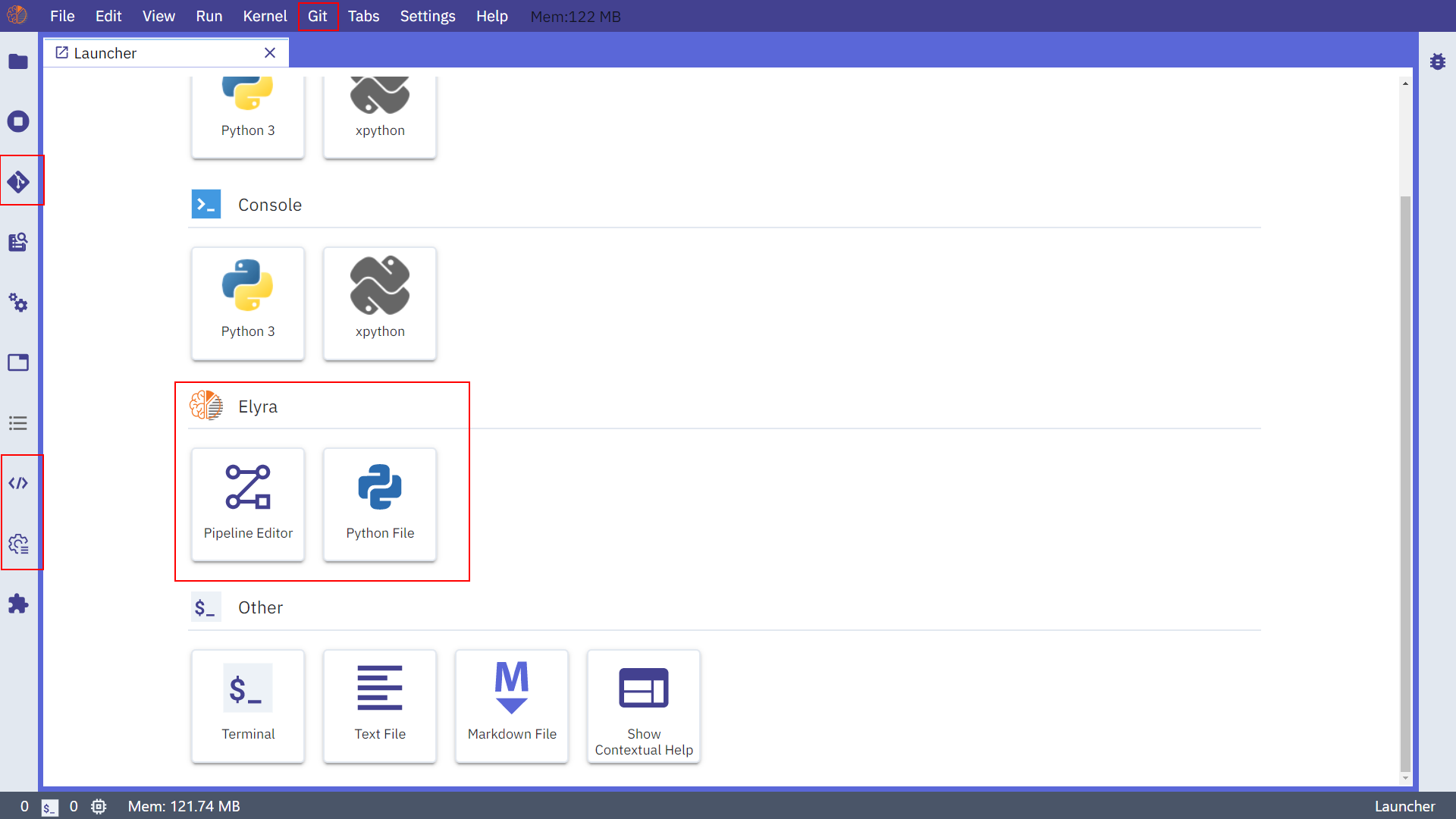
而在安裝完成重啟jupyter lab之後,除了左上角的jupyterlogo變化了之外,還新增了圖中我用紅框框選出來的地方:
接下來我們就來介紹如何利用elyra互動式地搭建工作流。
elyra賦予了我們通過交互的方式將若干個ipynb文件組織成工作流的能力,為了方便演示,這裡我們創建幾個帶有簡單流程程式碼的ipynb文件:




接著我們在Launcher頁面點擊Pipeline Editor打開用來互動式編輯notebook流水線的介面:

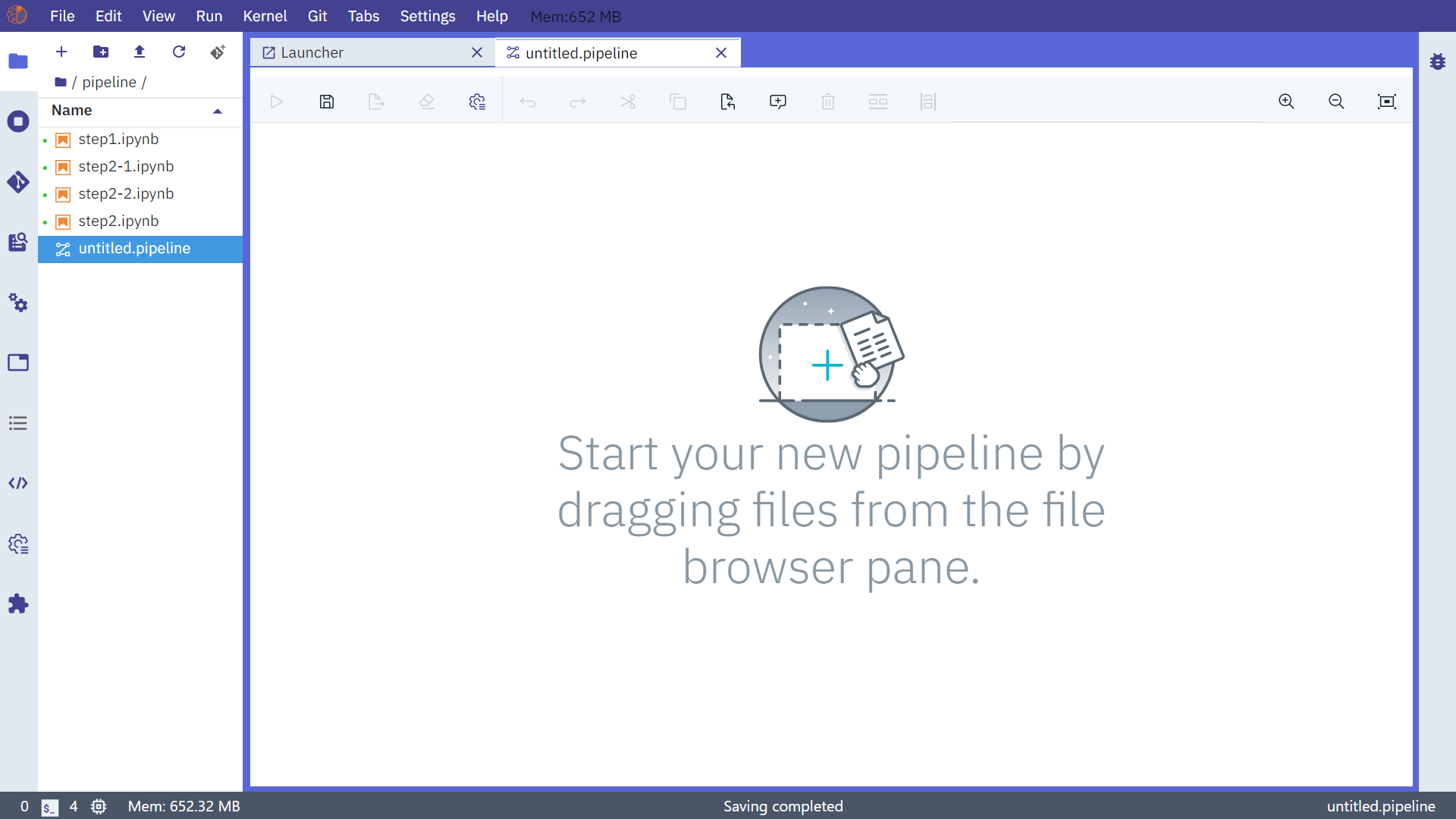
直接將側邊欄中對應的step1.ipynb文件拖拽進來:

點擊流水線介面中ipynb文件對應節點右側的三個圓點,可以打開更多功能選項:

因為我們是本地環境,所以這裡只需要在properties下必填參數Runtime Image中隨便選一個就行:

保存之後,就完成了本地環境下單個節點的必要參數設置,同樣的將其他ipynb文件拖拽進來,各自配置好必要參數再如圖13所示將各節點聯結起來:

這樣我們的流水線就搭建好了,是不是非常滴好玩~,接著點擊左上角的運行按鈕,輸入流水線名稱後即可開始運行我們的工作流:
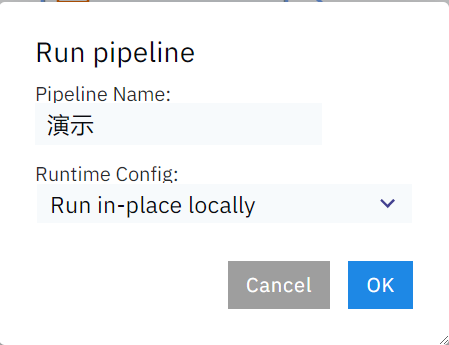
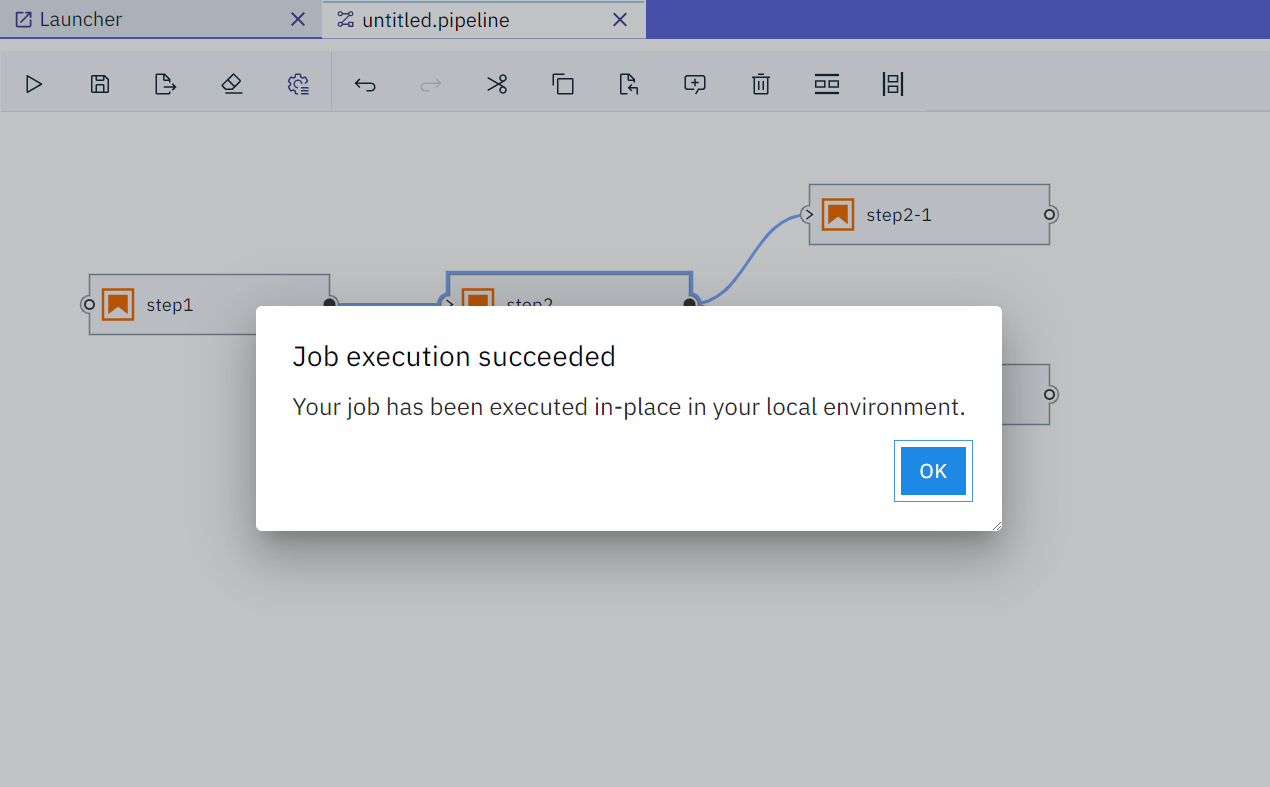
工作流執行成功之後也會有提示:
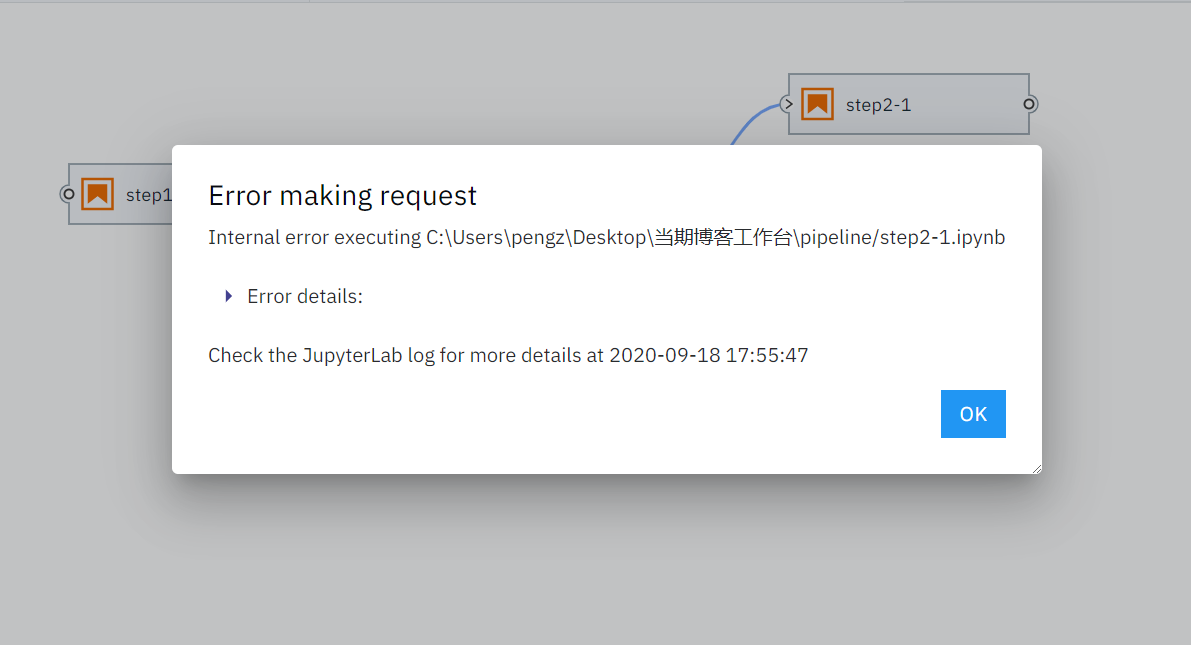
如果工作流執行到某個節點發生程式錯誤,也會有非常人性化的提示:
對應出錯的ipynb錯誤程式碼塊上方,elyra也會幫我們創建記錄錯誤資訊的markdown單元格:

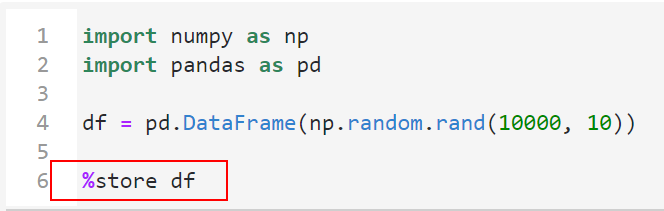
最好用的是,配合魔術命令%store,我們就可以跨notebook傳遞全局變數,而不需要再往外寫出先前節點的結果文件:
利用%store 變數名將某個變數轉化為跨kernel的全局變數:
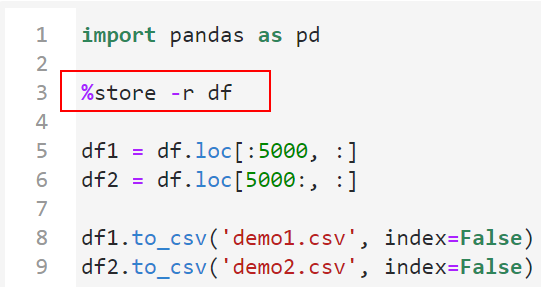
利用%store -r 變數名將跨kernel全局變數中的指定變數載入到當前kernel中:
而除了搭建工作流這個核心功能外,elyra還有很多其他的實用功能,感興趣的朋友可以前往官方文檔(//elyra.readthedocs.io/en/latest/)自行閱讀學習。

以上就是本文的全部內容,歡迎在評論區與我進行討論~


