《k8s權威指南》讀書筆記
抽空讀完了《k8s權威指南》一書,對k8s的總算有了較為系統的認知。
好記憶不如多寫字,以下是讀書筆記
第一章 k8s入門
k8s是什麼: 一個開源的容器集群管理平台,可提供容器集群的自動部署,擴縮容,維護等功能。分為管理節點Master和工作節點Node
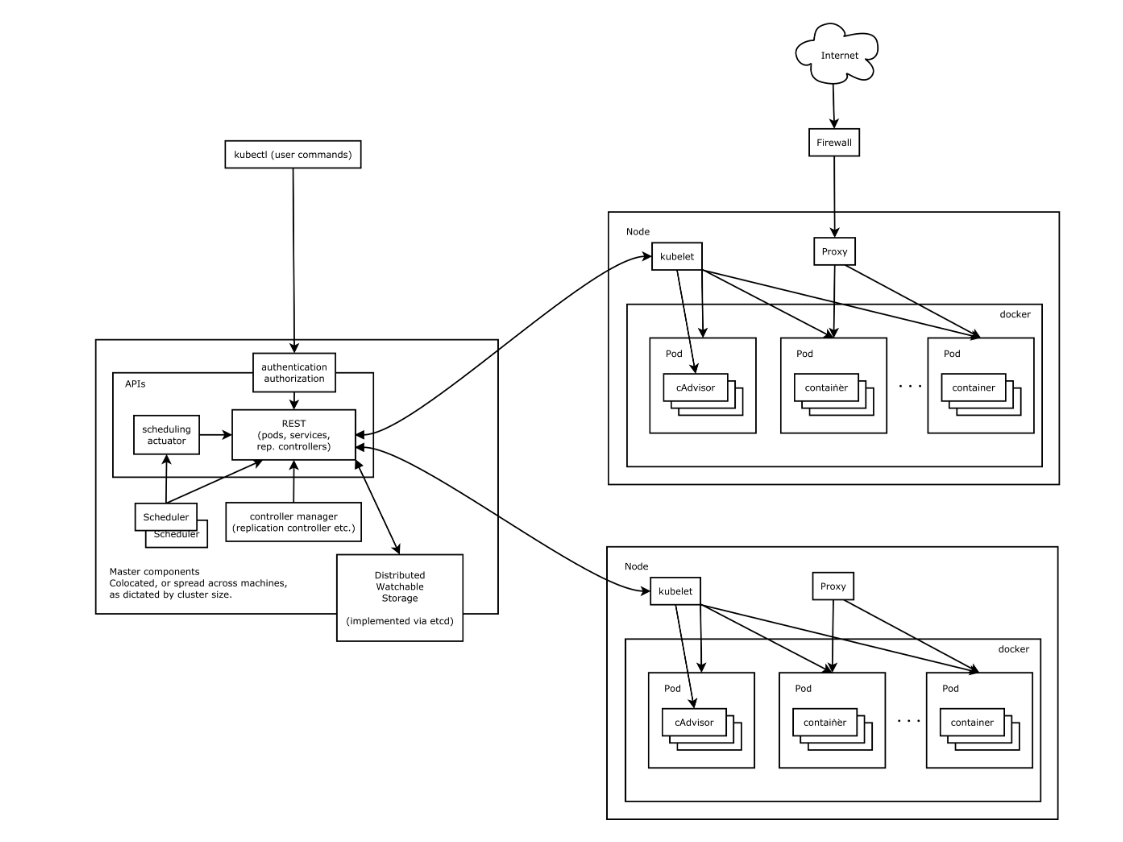
核心組件:
- etcd保存了整個集群的狀態;
- apiserver提供了資源操作的唯一入口,並提供認證、授權、訪問控制、API註冊和發現等機制;
- controller manager負責維護集群的狀態,比如故障檢測、自動擴展、滾動更新等;
- scheduler負責資源的調度,按照預定的調度策略將Pod調度到相應的機器上;
- kubelet負責維護容器的生命周期,同時也負責Volume(CVI)和網路(CNI)的管理;
- Container runtime負責鏡像管理以及Pod和容器的真正運行(CRI);
- kube-proxy負責為Service提供cluster內部的服務發現和負載均衡;
分層架構:
- 核心層:k8s最核心的功能,對外提供API構建高層應用,對內可提供插件式的應用執行環境。
- 應用層:部署和路由
- 管理層:策略管理,自動化管理,以及系統度量。
- 介面層:kubectl命令行工具。
- 生態系統:外部:日誌、監控、配置管理、CI、CD等 內部:CRI、CNI、CVI、鏡像倉庫、Cloud Provider、集群自身的配置和管理等。
第二章 實踐指南
2.1 基本配置
apiVersion : v1 用來標識版本
kind : Pod/Service 類型可選Pod Service等
metadata: name: nameSpace:
2.4 Pod
- pod中的容器要求啟動命令必須以前台命令作為啟動命令【避免k8s 監控到pod運行結束 銷毀,根據配置的RC副本數量重新啟動,從而進入死循環】
- pod 可以由一個或者多個容器組合而成。
- pod中的多個容器只需要localhost就可以相互訪問。
2.4.3 靜態pod
靜態pod 是由kubelet進行管理創建的只存在於特定Node上的Pod,kubelet無法對其進行靜態檢查,且一般只存在於kubelet所在的節點上。
且無法通過API server進行管理,也不會和ReplicationController Deployment產生關聯。
創建方式: yml文件【配置文件】或者http請求
如何刪除: 無法通過API server進行管理,所以Master無法對靜態pod進行刪除【狀態更新為pending】。刪除只能通過所在的node節點刪除配置文件
2.4.4 容器共享volume
在同一個pod內的容器可以共享pod級別的volume
2.4.5 pod配置管理
pod可以通過k8s提供的集群化配置管理方案 configMap來實現配置資訊和程式分離。
創建方式: yaml文件
2.4.6 生命周期和重啟策略
生命周期 在系統內被定義為各種狀態。可以分為 Pending Running Succeeded Failed Unknow
- Pending : API Server 已經創建好Pod,但是Pod內還有一個或者多個容器的鏡像沒創建,包括正在下載的鏡像。
- Running : Pod內所有的容器已經創建成功,至少有一個容器處於運行,正在啟動或者重啟狀態。
- Succeeded : Pod內的所有容器均成功執行退出,且不會再重新啟動。
- Failed : 所有容器都已退出,至少有一個容器為退出失敗狀態。
- Unknow: 無法獲取到Pod的狀態。
重啟策略 應用於Pod內的所有容器,並由Pod所在node節點上的kubelet進行狀態判斷和重啟。當容器異常退出或者健康檢查狀態失敗的時候,kubelet會根據所設置的重啟策略重新啟動該container
- always : 當容器失效時,有kubelet自動重啟改容器。
- OnFailure : 容器運氣終止且狀態碼不為0的時候。
- Never :無論狀態如何都不重啟該容器。
重啟的間隔時間以設定的間隔時間的2n來計算,且在成功重啟的10分鐘後重置該時間。
不同的控制器對Pod的重啟策略的要求是不一樣的:
- RC和DaemonSet: 這2類控制器要求所管理的Pod 必須設置為Always,才能保障整個k8s周期內,提供服務的副本數量是滿足要求的。
- Job: 這類控制器可根據需求靈活設定OnFailure 或者Never
- Kubelet: 由kubelet管理的一般是靜態Pod,kubelet不會對其進行健康檢查,Pod失效就回進行重啟。和設置的重啟策略沒有關聯。
2.4.7 健康檢查
pod的健康檢查可使用2類探針: LivenessProbe 和ReadinessProbe
- LivenessProbe :用來判斷容器是否存活【running狀態】若容器不處於running狀態,則會有kubelet對容器根據設定的重啟策略進行操作。若容器內不存在LivenessProbe探針,kubelet會認為容器的狀態是succeed
- ReadinessProbe :用來判斷容器是否是ready狀態【這個狀態下可以正常接收請求 處理任務】若ReadinessProbe 探針檢查失敗,EndPoint controller 會從service的endPoint中刪除包含該容器所在Pod的endPoint不讓該容器對外提供服務。
LivenessProbe 探針的實現方法
- ExecAction 在容器內執行命令若返回狀態碼為0 表示容器正常。
- TcpSocketAction 成功建立Tcp連接表示狀態正常。
- HttpGetAction 對容器路徑內調用httpGet方法若返回的狀態碼在200-400之間表示容器狀態正常。
2.4.8 Pod的調度方式
1 RC Deployment
全自動調度,用戶配置好應用容器的副本數量後RC會自動調度+持續監控始終讓副本數量為此在規定的個數當中。
調度演算法 系統內置的調度演算法/NodeSelector/NodeAffinity
- 內置調度演算法: 對外無感知,無法預知會調度到那個節點上,系統內完成的。
- NodeSelector 定向調度:在Pod上如果設置了NodeSelector屬性 Scheduler會將該節點調度到和NodeSelector屬性一致的帶有Label的特定Node上去。【NodeSelector和Node Label精確匹配】
- NodeAffinity 親和性調度: 在NodeSelector的基礎上做了一些改進,可以設置在Node不滿足當前調度條件時候,是否移除之前調度的Pod,以及在符合要求的Node節點中那些Node會被優先調度。
2 DaementSet
和RC類似,不同之處在於DaementSet控制每一台Node上只允許一個Pod副本實例,適用於需要單個Node運行一個實例的應用:
- 分散式文件存儲相關 在每台Node上運行一個應用實例如GlusterFS Ceph
- 日誌採集程式 logStach
- 每台Node上運行一個健康程式,來讀當前Node的健康狀態進行採集。
3 Job 批處理任務調度
批處理模型
- Job Template Expansion : 一個待處理的工作項就對應一個Job,效率較低。
- Queue with Per Pod Work Item : 使用隊列存儲工作項,一個Job作為消費者消費隊列中的工作項,同時啟動和隊列中work Item數量對應的Pod實例。
- Queue with Variable Pod Work Item : 同per Pod 模式,不同之處在於Job數量是可變的。
這裡在項目中的具體應用待更新,現在項目所用的k8s 調度模型【後續會單獨寫篇文章更新】
2.4.9 Pod的擴縮容
手動更新 kubectl scale命令更新RC的副本實例數量
自動更新 使用HAP控制器,基於在controller-manager設置好的周期,周期性的對Pod的cup佔用率進行監控,自動的調節RC或者Deployment中副本實例進行調整來達到設定的CPU佔用率。
2.5 service
service可以為一組具有相同功能的容器提供一個統一的入口地址,並將請求負載進行分發到後端各個容器應用上。
2.5.2 service的基本使用
直接使用RC創建多個副本和創建SVC提供服務的異同
直接創建RC

- 先定義RC yaml文件,如上所示
- 執行創建命令
kubectl create -f name.yaml - 查看提供服務的Pod地址
kubectl get pods -l app=webapp -o yaml | grep podIP
因為RC配置的副本實例數量為2 所以可得2個可用的Pod EndPoint 分別為172.17.172.3:80 172.17.172.4:80 無論任何一個Pod出現問題,kubelet 會根據重啟策略對Pod進行重新啟動,再次查詢PodIP會發現PodIP發生變化
使用SVC
因為Pod的不可靠,重新啟動被k8s調度到其他Node上會導致實例的endpoint不一樣。且在分散式部署的情況下,多個容器對外提供服務,還需要在Pod前自己動手解決負載均衡的問題,這些問題都可通過SVC解決。
創建方式 : kubectl expose命令/配置文件
kubectl expose命令
- 創建SVC
kubectl expose rc webapp此時埠號會根據之前RC設置的containerPort 來進行設置 - 查看SVC
kubectl get SVC
配置文件方式啟動
定義的關鍵在於 selector 和ports


負載分發策略 RoundRobin/SessionAffinity/自定義實現
- RoundRobin : 輪詢策略
- SessionAffinity : 基於客戶端IP的回話保持策略,相同IP的會話,會落在後端相同的IP上面。
- 自定義實現: 不給SVC設置clusterIP 通過label selector拿到所有的實例地址,根據實際情況來選用。
2.5.3 集群外部訪問SVC或者Pod
思路是把SVC或者pod的虛擬埠映射到宿主機的埠,使得客戶端應用可以通過宿主機埠訪問容器應用。
將容器應用的埠號映射到主機
1 容器級別 設置hostPort = prodNum yaml中的配置表為hostPort: 8081,指的是綁定到的宿主機埠。HostPort和containerPort可以不相等
2 Pod級別 設置hostNetWork = true 這時候設置的所有的containerPort 都會直接映射到宿主機相同的埠上。默認且必須是HostPort = containerPort,若顯示的指定HostPort和containerPort不相等則無效。
將SVC埠號映射到主機
關鍵配置為 kind = service type = NodePort nodePort = xxxxx,同時在物理機上對防火牆做對應的設置即可。
2.5.4 搭建DNS
可以直接完成服務名稱到ClusterIP的解析。由以下部分組成
- 1 etcd DNS資訊存儲
- 2 kube2sky 將k8sMaster中的 service註冊到etcd
- 3 skyDNS 提供DNS解析
- 4 healthz 提供對skyDNS的健康檢查
第三章 原理分析
3.1 API Server
主要提供了各類資源對象【SVC Pod RC】等的增刪查改以及Watch等Http Rest介面,是各個模組之間的數據交互和通訊的樞紐。
Kubernetes API Server : 提供API介面來完成各種資源對象的創建和管理,本身也是一個SVC 名稱為Kubernetes
Kubernetes Proxy API :負責把收到的請求轉到對應Node上的kubelet守護進程的埠上,kubelet負責相應,來查詢Node上的實時資訊 包括node pod SVC等 多用於集群外想實時獲取Node內的資訊用於狀態查詢以及管理。 【kubelet也會定時和etcd 同步自身的狀態,和直接查詢etcd存在一定的差異,這裡強調實時】
集群模組之間的通訊: 都需要通過API Server 來完成模組之間的通訊,最終會將資源對象狀態同步到etcd,各個集群模組根據通過API Server在etcd定時同步資訊,來對所管理的資源進行相應處理。
3.2 Controller Manager
集群內部的管理中心,負責集群內部的Node Pod Endpoint Namespace 服務帳號(ServiceAccount)資源定額(ResourceQuota)等的管理。出現故障時候會嘗試自動修復,達到預期工作狀態。
3.2.1 Replication Controller
一般我們把資源對象 Replication Controller 簡寫為RC 是為了區別於Controller Manager 中的Replication Controller【副本控制器】,副本控制器是通過管理資源對象RC來達到動態調控Pod的
副本控制器Replication Controller的作用:
- 【重新調度】確保當前集群中存在N個pod實例,N是在RC中定義的Pod實例數量
- 【彈性擴容】通過調整RC中配置的副本實例個數在實現動態擴縮容。
- 【滾動升級】通過調整RC中Pod模板的鏡像版本來實現滾動升級。
3.2.2 Node Controller
Node節點在啟動時候,會同kubelet 主動向API Server彙報節點資訊,API Server將節點資訊存儲在etcd中,Node Controller通過API Server獲取到Node的相關資訊對Node節點進行管理和監控。
節點狀態包括:就緒 未就緒 未知三種狀態
3.2.3 ResourceQuota Controller
資源配額管理,確保指定資源對象在任一時刻不會超量佔用系統物理資源。支援以下維度的系統資源配額管理
- 容器級別可以CPU和Memory進行限制
- Pod級別可以對一個Pod內的所有容器進行限制。
- Namespace級別,可以對多租戶進行限制,包括Pod數量,Replication Controller數量,SVC數量 ResourceQuota 數量等。
3.2.4 Namespace Controller
用戶通過API server 設置的Namespace會保存在etcd中,Namespace Controller會定時的獲取namespace狀態,根據所得狀態對不同的namespace進行相應的刪除,釋放namespace下對應的物理資源。
3.2.5 SVC Controller& Endpoint Controller
Endpoints 表示一個svc對應的所有的pod的訪問地址,Endpoint Controller是負責維護和生成所有endpoint對象的控制器。
每個Node對應的kube-proxy獲取到svc對應的Endpoints來實現svc的負載均衡。
3.3 Scheduler
Scheduler 主要是接受controller Manager創建的pod為Pod選定目標Node,調度到合適的Node後,由Node中的kubelet負責接下來的管理運維。
過程中涉及三個對象 待調度的Pod列表,空閑的Node列表,調度演算法和策略。
也就是根據調度演算法和策略為待調度的每個Pod從空閑的Node中選擇合適的。 隨後kubelet通過API Server監聽到Pod的調度事件,獲取對應的Pod清單,下載Image鏡像,並啟動容器。
3.3.1 默認的調度流程如下:1&2
1【預選調度】遍歷所有的Node節點,選出合適的Node
2優選策略確定最優節點
3.4 Kubelet
每個Node節點中都會啟動一個Kubelet,該進程用於處理Master節點下發到本節點的任務,管理Pod以及Pod中的容器,每個Kubelet都會向API Server註冊自身資訊,定期和Master節點彙報Node節點資源使用情況。
容器健康檢查
使用2類探針LivenessProbe 和ReadinessProbe
資源監控
使用cAdvisor
總結:kubelet 作為連接K8s Master節點機和Node機器的橋樑,管理運行在Node機器上的Pod和容器,同時從cAdvisor中獲取容器使用統計資訊,然後通過API Server上報資源使用資訊。
3.5 Kube-Proxy
SVC是對一組提供相同服務Pod的抽象,會根據訪問策略來訪問這一組Pod。在每一個Node節點上都存在一個Kube-proxy,可以在任意Node上發起對SVC的訪問請求。
SVC的ClusterIp和NodePort等概念是kube-proxy服務通過IPtables的NAT轉換實現重定向到本地埠,再均衡到後端的Pod
3.6 集群安全機制
待補充
3.7 網路原理
k8s+docker 網路原理常常涉及到以下問題
- 1 k8s的網路模型是什麼?
- 2 Docker的網路基礎是什麼?
- 3 Docker的網路模型和局限?
- 4 k8s的網路組件之間是如何通訊的?
- 5 外部如何訪問k8s集群?
- 6 有那些開源組件支援k8s網路模型?
1 k8s的網路模型
IP-per-Pod:每個Pod都有自己獨立的IP,無論是否處於同一個Node節點,Pod直接都可以通過IP相互訪問。同時Pod內的容器共享一個網路堆棧【=網路命名空間 包括IP地址,網路設備,配置等】按照這個網路模型抽象出來的一個Pod對應一個IP也叫IP-per-Pod
Pod內部應用程式看到的自己的IP+port和pod外部的應用程式看到的IP+port是一致的,他們都是Pod實際分配的ip地址,從docker0上分配的。這樣可以不用NAT來進行轉換,設計的原則是為了兼容以前的應用 。
K8S對網路的要求:
- 所有容器在不通過NAT的方式下和其他容器進行通訊
- 所有節點在不使用NAT的方式下和容器相互通訊
- 容器的地址和外部看到的地址是同一個地址
2 Docker的網路基礎是什麼?
- Docker使用網路命名空間來達到不同容器之間的網路隔離【不同的網路命名空間內的 IP地址 網路設備 配置等是相互隔離不可見的】
- Docker 使用Veth設備對來達到2個不同的網路命名空間的相互訪問。【Veth設備對可以直接將2個不同的網路命名空間連接起來,其中一端稱為另一端的peer 從a端發送數據時候會直接觸發b端的接受操作,從而達到不同容器之間相互訪問的目的】
由於網路命名空間以及Veth設備對是建立在同一個linux內核的基礎上。所以Docker的跨主機通訊處理的不夠友好。
3 Docker的網路模型和局限?
- host模式 使用
--net= host指定 - container模式 使用
--net = container: Id_or_NAME指定 - none模式 使用
--net= none指定 - bridge模式 使用
--net = bridge指定
bridge模式 : 也是docker默認的網路模型,在這個模型下Docker第一次啟動會創建一個新的網橋 大名鼎鼎的docker0,每個容器獨享一個網路命名空間,且每一個容器具有一個Veth設備對,一端連接容器設備eth0一端連接網橋,docker0。如下圖:
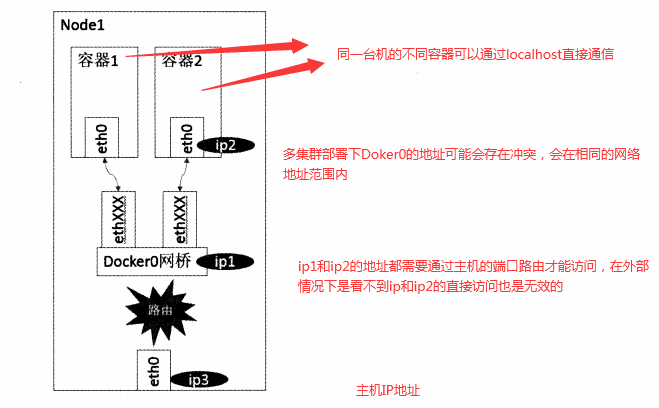
4 k8s的網路組件之間是如何通訊的?
- 容器到容器之間的通訊
- Pod到Pod之間的通訊
- Pod到Service之間的通訊
- 集群外與內部組件之間的通訊
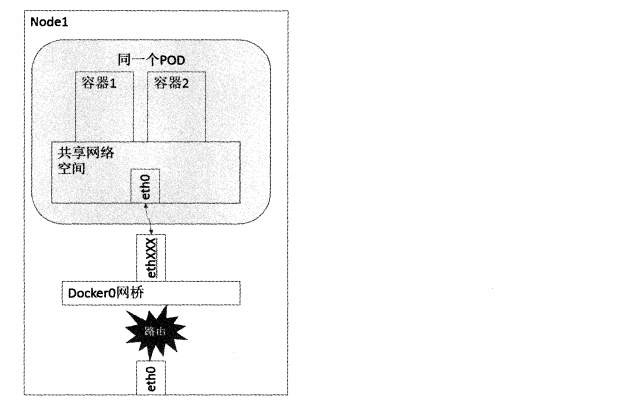
容器到容器之間的通訊
同一個Pod內的容器共享同一個網路命名空間,可以直接使用Localhost進行通訊,不同Pod之間容器的通訊可以理解為Pod到Pod OR Pod到SVC之間的通訊
Pod到Pod之間的通訊
可以分為同一個Node內Pod之間的通訊&不同Node內Pod之間的通訊
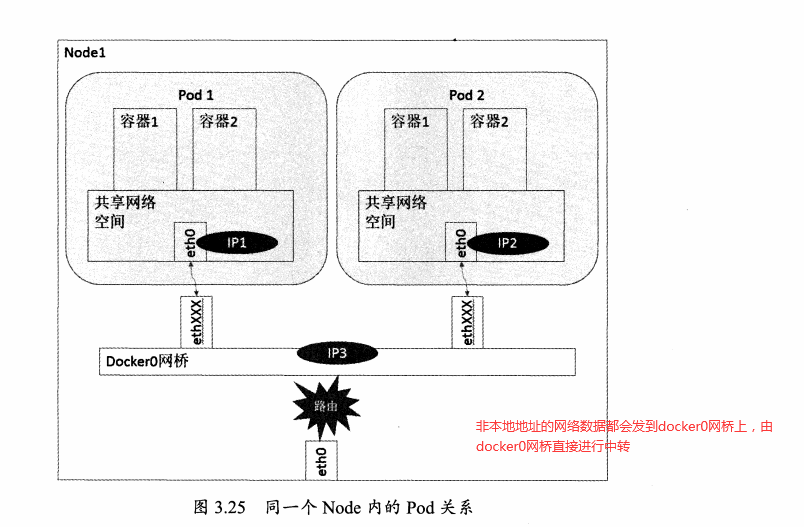
同Node內Pod
同一Node中Pod的默認路由都是docker0的地址,由於它們關聯在同一個docker0網橋上,地址網段相同,可以直接進行通訊。
不同Node的Pod
docker0網段和宿主機的網卡是2個不同的IP段,Pod地址和docker0處於同一網段。所以為了使不同Node之間的Pod可以通訊,需要將PodIP和所在Node的IP進行關聯且保證唯一性。
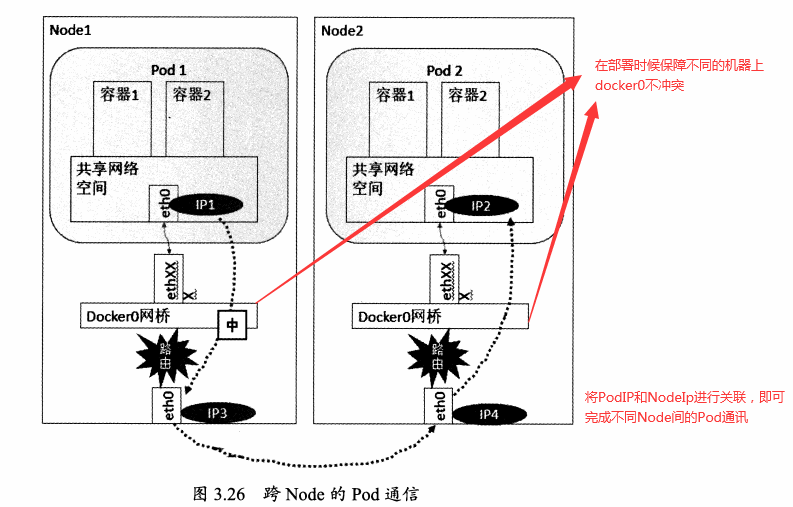
Pod到Service之間的通訊
SVC是對一組Pod服務的抽象,相當於一組服務的負載均衡。且對外暴露統一的clusterIP,所以Pod到SVC之間的通訊可以理解為Pod到Pod之間的通訊
集群外與內部組件之間的通訊
集群外和內部組件之間通訊,將Pod OR SVC埠綁定到物理機埠即可。

