istio 常見的 10 個異常
總結使用 istio 常見的10個異常:
-
Service 埠命名約束
-
流控規則下發順序問題
-
請求中斷分析
-
sidecar 和 user container 啟動順序
-
Ingress Gateway 和 Service 埠聯動
-
VirtualService 作用域
-
VirtualService 不支援 host fragment
-
全鏈路跟蹤並非完全透明接入
-
mTLS 導致連接中斷
-
用戶服務監聽地址限制
1. Service 埠命名約束
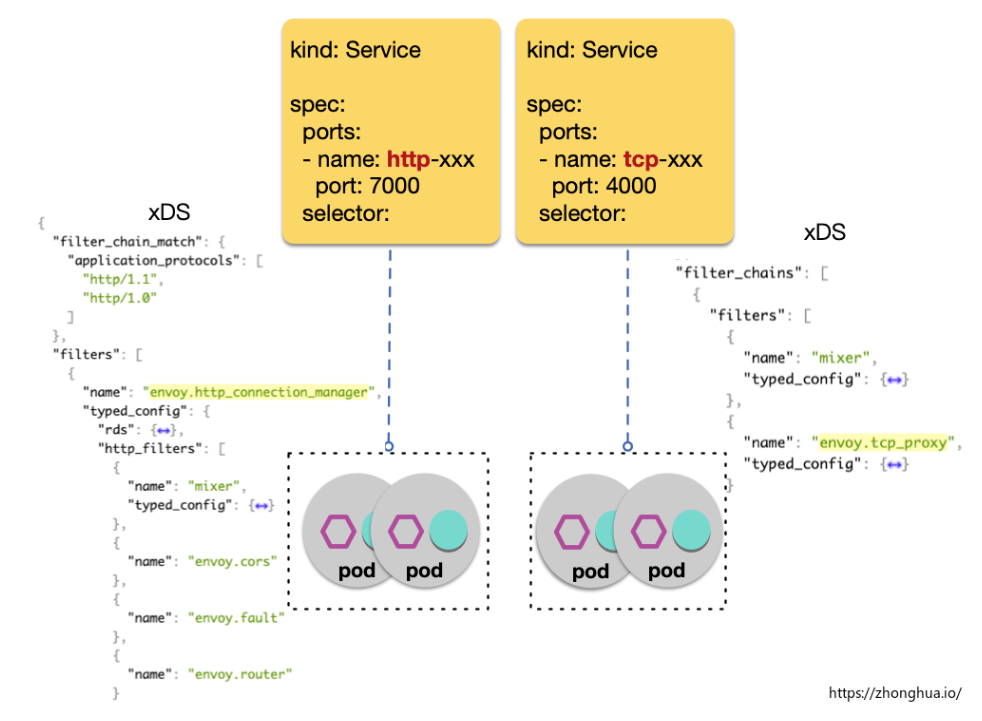
istio 支援多平台,不過 Istio 和 k8s 的兼容性是最優的,不管是設計理念,核心團隊還是社區, 都有一脈相承的意思。但 istio 和 k8s 的適配並非完全沒有衝突, 一個典型問題就是 istio 需要 k8s service 按照協議進行埠命名(port naming)。
埠命名不滿足約束而導致的流量異常,是使用 mesh 過程中最常見的問題,其現象是協議相關的流控規則不生效,這通常可以通過檢查該 port LDS 中 filter 的類型來定位。
原因
k8s 的網路對應用層是無感知的,k8s 的主要流量轉發邏輯發生在 node 上,由 iptables/ipvs 來實現,這些規則並不關心應用層里是什麼協議。
istio 的核心能力是對 7層流量進行管控,但前提條件是 istio 必須知道每個受管控的服務是什麼協議,istio 會根據埠協議的不同,下發不同的流控功能(envoy filter),而 k8s 資源定義里並不包括七層協議資訊,所以 istio 需要用戶顯式提供。
istio 的解決方案:Protocol sniffing
協議嗅探概要:
- 檢測 TLS
CLIENT_HELLO提取 SNI、ALPN、NPN 等資訊 - 基於常見協議的已知典型結構,嘗試檢測應用層 plaintext 內容 a. 基於HTTP2 spec: Connection Preface,,判斷是否為 HTTP/2 b. 基於 HTTP header 結構,判斷是否是 HTTP/1.x
- 過程中會設置超時控制和檢測包大小限制, 默認按照協議 TCP 處理
最佳實踐
Protocol sniffing 減少了新手使用 istio 所需的配置,但是可能會帶來不確定的行為。不確定的行為在生產環境中是應該盡量避免的。
一些嗅探失效的例子:
- 客戶端和服務端使用著某類非標準的七層協議,客戶端和服務端都可以正確解析,但是不能確保 istio 自動嗅探邏輯認可這類非標準協議。比如對於 http 協議,標準的換行分隔是用 CRLF (
0x0d 0x0a), 但是大部分 http 類庫會使用並認可 LF (0x0a)作為分隔。 - 某些自定義私有協議,數據流的起始格式和 http 報文格式類似,但是後續數據流是自定義格式:未開啟嗅探時:數據流按照 L4 TCP 進行路由,符合用戶期望 如果開啟嗅探:數據流最開始會被認定為 L7 http 協議,但是後續數據不符合 http 格式,流量將被中斷
建議生產環境不使用協議嗅探, 接入 mesh 的 service 應該按照約定使用協議前綴進行命名。
2. 流控規則下發順序問題
異常描述
在批量更新流量規則的過程中,偶爾會出現流量異常(503),envoy 日誌中 RESPONSE_FLAGS 包含「NR」標誌(No route configured),持續時間不長,會自動恢復。
原因分析
當用戶使用 kubectl apply -f multiple-virtualservice-destinationrule.yaml時,這些對象的傳播和生效先後順序是不保證的,所謂最終一致性,比如 VirtualService 中引用了某一個 DestinationRule 定義的子版本,但是這個 DestinationRule 資源的傳播和生效可能在時間上落後於 該 VirtualService 資源。

最佳實踐:make before break
將更新過程從批量單步拆分為多步驟,確保整個過程中不會引用不存在的 subset:
當新增 DestinationRule subset 時,應該先 apply DestinationRule subset,等待 subset 生效後,再 apply 引用了該 subset 的 VirtualService。
當刪除 DestinationRule subset 時,應該先 刪除 VirtualService 中對 該 subset 的引用,等待 VirtualService 的修改生效後,在執行刪除 DestinationRule subset。
3. 請求中斷分析
請求異常,到底是 istio 流控規則導致,還是業務應用的返回,流量斷點出現在哪個具體的 pod?
這是使用 mesh 最常見的困境,在微服務中引入 envoy 作為代理後,當流量訪問和預期行為不符時,用戶很難快速確定問題是出在哪個環節。客戶端收到的異常響應,諸如 403、404、503 或者連接中斷等,可能是鏈路中任一 sidecar 執行流量管控的結果, 但也有可能是來自某個服務的合理邏輯響應。
envoy 流量模型
Envoy 接受請求流量叫做 Downstream,Envoy 發出請求流量叫做Upstream。在處理Downstream 和 Upstream 過程中, 分別會涉及2個流量端點,即請求的發起端和接收端:
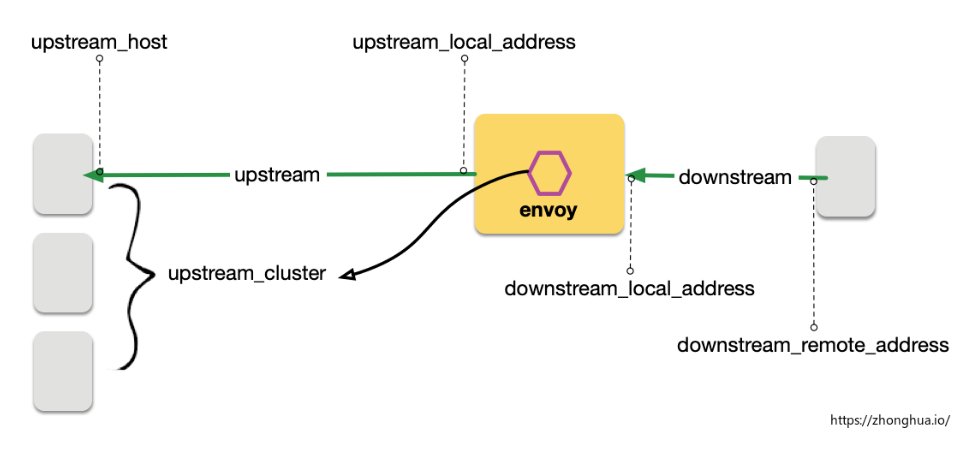
在這個過程中, envoy 會根據用戶規則,計算出符合條件的轉發目的主機集合,這個集合叫做 UPSTREAM_CLUSTER, 並根據負載均衡規則,從這個集合中選擇一個 host 作為流量轉發的接收端點,這個 host 就是 UPSTREAM_HOST。
以上就是 envoy 請求處理的 流量五元組資訊, 這是 envoy 日誌里最重要的部分,通過這個五元組我們可以準確的觀測流量「從哪裡來」和「到哪裡去」。
- UPSTREAM_CLUSTER
- DOWNSTREAM_REMOTE_ADDRESS
- DOWNSTREAM_LOCAL_ADDRESS
- UPSTREAM_LOCAL_ADDRESS
- UPSTREAM_HOST
日誌分析示例
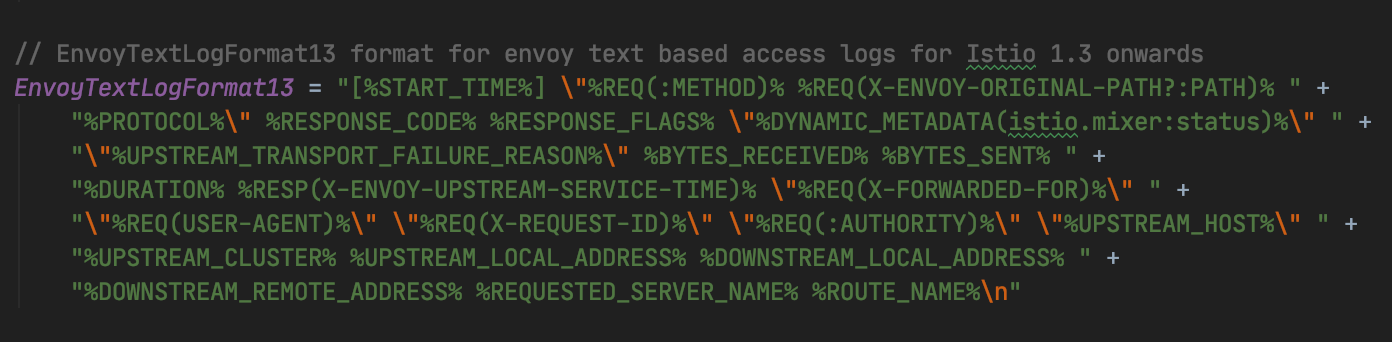
通過日誌重點觀測 2 個資訊:
- 斷點是在哪裡 ?
- 原因是什麼?
示例一:一次正常的 client-server 請求
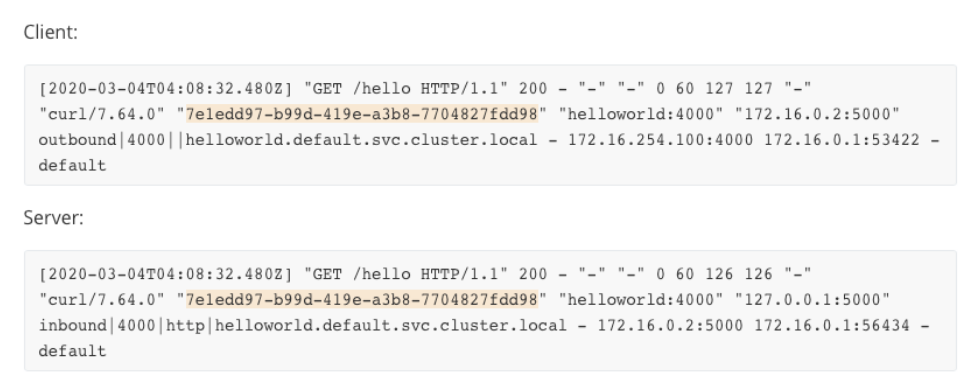
可以看到 2 端日誌包含相同的 request ID,因此可以將流量分析串聯起來。
示例二:no healthy upstream, 比如目標 deployment 健康副本數為 0

日誌中 flag「UH」表示 upstream cluster 中沒有健康的 host。
示例三:No route configured , 比如 DestinationRule 缺乏對應的 subset

日誌中 flag「NR」表示找不到路由。
示例四,Upstream connection failure,比如服務未正常監聽埠。

日誌中 flag「UF」表示 Upstream 連接失敗,據此可以判斷出流量斷點位置。
4. sidecar 和 user container 啟動順序
異常描述
Sidecar 模式在kubernetes 世界很流行,但對目前的 k8s (V1.17)來說,並沒有 sidecar 的概念,sidecar 容器的角色是用戶主觀賦予的。
對 Istio 用戶來說,一個常見的困擾是:sidecar 和用戶容器的啟動順序:
sidecar(envoy) 和用戶容器的啟動順序是不確定的,如果用戶容器先啟動了,envoy 還未完成啟動,這時候用戶容器往外發送請求,請求仍然會被攔截,發往未啟動的 envoy,請求異常。
在 Pod 終止階段,也會有類似的異常,根源仍然是 sidecar 和普通容器的生命周期的不確定性。
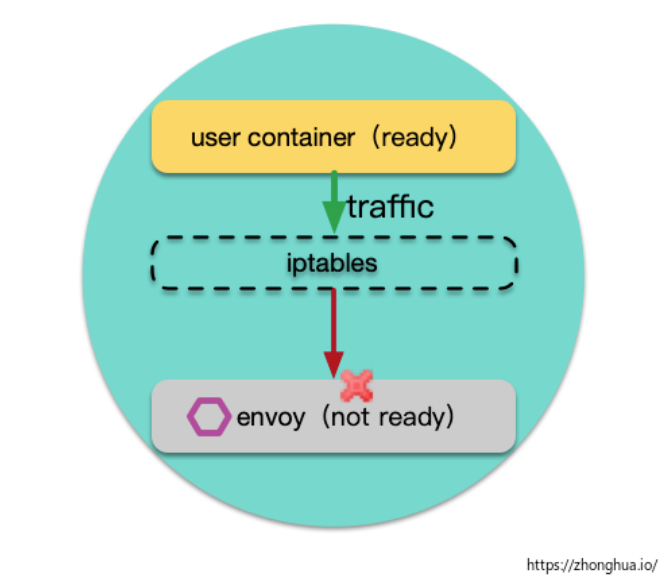
解決方案
目前常規的規避方案主要是有這樣幾種:
- 業務容器延遲幾秒啟動, 或者失敗重試
- 啟動腳本中主動探測 envoy 是否ready,如
127.0.0.1:15020/ healthz/ready
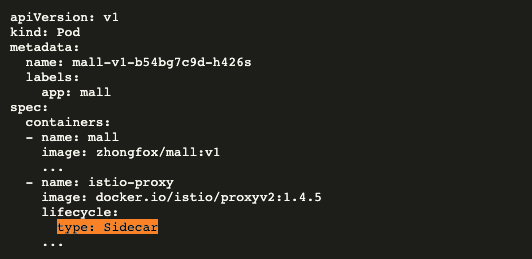
無論哪種方案都顯得很蹩腳,為了徹底解決上述痛點,從 kubernets 1.18版本開始,k8s 內置的 Sidecar 功能將確保 sidecar 在正常業務流程開始之前就啟動並運行,即通過更改pod的啟動生命周期,在init容器完成後啟動sidecar容器,在sidecar容器就緒後啟動業務容器,從啟動流程上保證順序性。而 Pod 終止階段,只有當所有普通容器都已到達終止狀態, 才會向sidecar 容器發送 SIGTERM 訊號。
5. Ingress Gateway 和 Service 埠聯動
Ingress Gateway 規則不生效的一個常見原因是:Gateway 的監聽埠在對應的 k8s Service 上沒有開啟,首先我們需要理解 Istio Ingress Gateway 和 k8s Service 的關係:
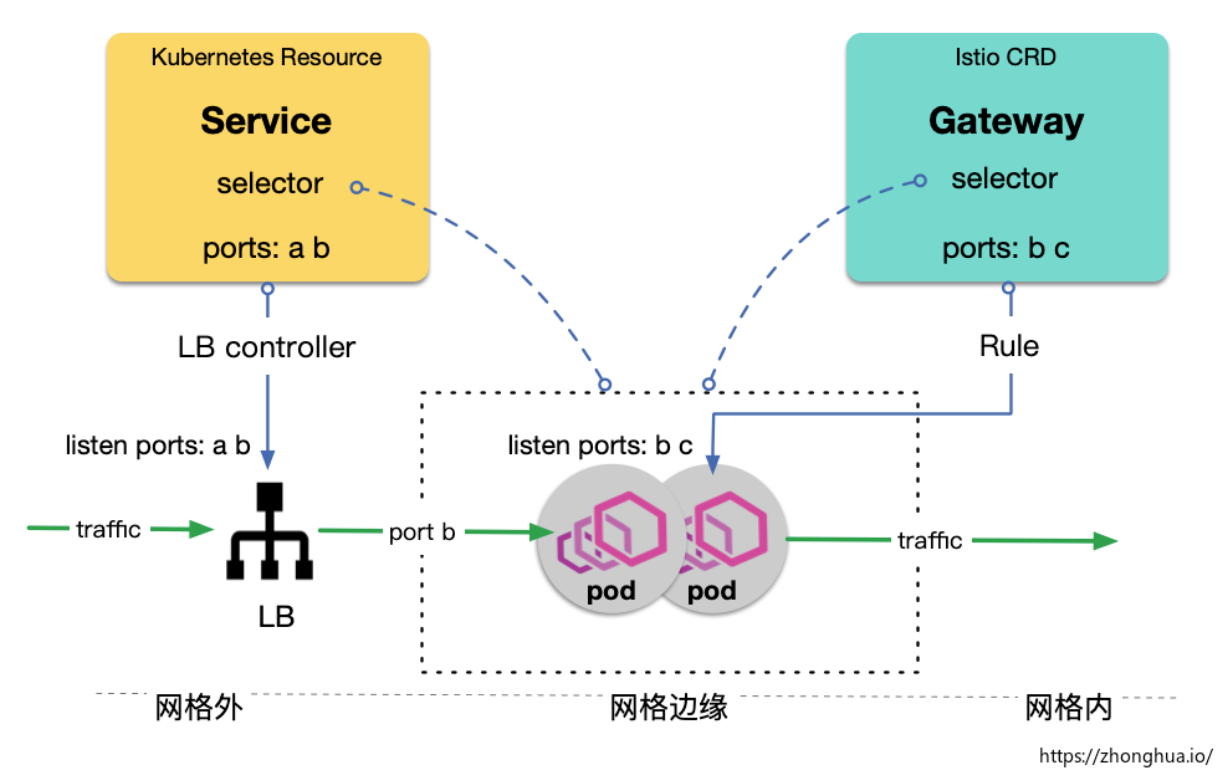
上圖中,雖然 gateway 定義期望管控埠 b 和 c,但是它對應的 service (通過騰訊雲CLB)只開啟了埠 a 和 b,因此最終從 LB 埠 b 進來的流量才能被 istio gateway 管控。
- Istio Gateway 和 k8s Service 沒有直接的關聯,二者都是通過 selector 去綁定 pod,實現間接關聯
- Istio CRD Gateway 只實現了將用戶流控規則下發到網格邊緣節點,流量仍需要通過 LB 控制才能進入網格
- 騰訊雲 tke mesh 實現了 Gateway-Service 定義中的 Port 動態聯動,讓用戶聚焦在網格內的配置。
6. VirtualService 作用域
VirtualService 包含了大部分 outbound 端的流量規則,它既可以應用到網格內部數據面代理中, 也可以應用到網格邊緣的代理中。
VirtualService 的屬性gateways用於指定 VirtualService 的生效範圍:
- 如果
VirtualService.gateways為空,則 istio 為其賦默認值mesh, 代表生效範圍為網格內部 - 如果希望 VirtualService 應用到具體邊緣網關上,則需要顯示為其賦值:
gateway-name1,gateway-name2... - 如果希望 VirtualService 同時應用到網格內部和邊緣網關上,則需要顯示地把
mesh值加入VirtualService.gateways, 如mesh,gateway-name1,gateway-name2...一個常見的問題是以上的第三種情況,VirtualService 最開始作用於網關內部,後續要將其規則擴展到邊緣網關上,用戶往往只會添加具體 gateway name,而遺漏mesh:

Istio 自動給VirtualService.gateways設置默認值, 本意是為了簡化用戶的配置,但是往往會導致用戶應用不當,一個 feature 一不小心會被用成了 bug。
7. VirtualService 不支援 host fragment
異常案例
對某一 host 新增、修改 VirtualService,發現規則始終無法生效,排查發現存在其他 VirtualService 也對該 host 應用了其他規則,規則內容可能不衝突,但還是可能出現其中一些規則無法生效的情況。
背景
- VirtualService 里的規則,按照 host 進行聚合
- 隨著業務的增長,VirtualService 的內容會快速增長,一個 host 的流控規則,可能會由不同的團隊分布維護。如安全規則和業務規則分開,不同業務按照子 path 分開
目前 istio 對 cross-resource VirtualService 的支援情況:
- 在網格邊緣(gateway),同一個 host 的流控規則,支援分布到多個 VirtualService 對象中,istio 自動聚合,但依賴定義順序以及用戶自行避免衝突。
- 在網格內部(for sidecar),同一個 host 的流控規則,不支援分布到多個 VirtualService 對象中,如果同一個 host 存在多個 VirtualService,只有第一個 VirtualService 生效,且沒有衝突檢測。
VirtualService 不能很好支援 host 規則分片,使得團隊的維護職責不能很好的解耦,配置人員需要知悉目標 host 的所有流控規則,才有信心去修改 VirtualService。
Istio 解決方案:Virtual Service chaining(plan in 1.6)
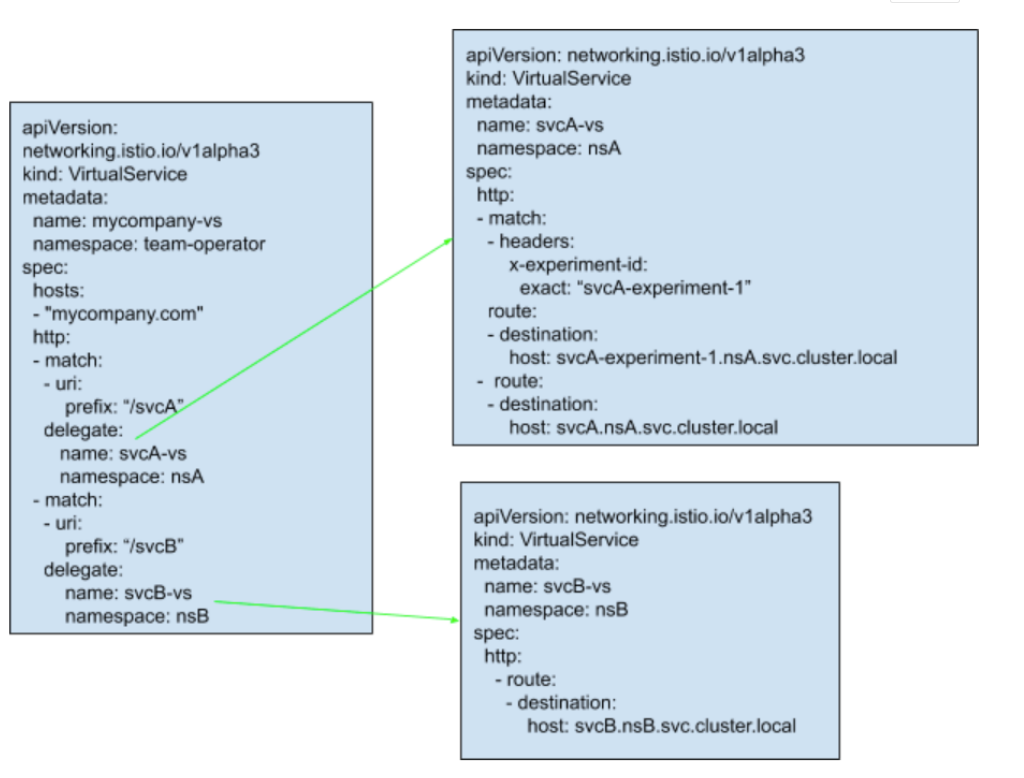
Istio 計劃在 1.6 中支援 Virtual Service 代理鏈:
- Virtual Service 支援分片定義 + 代理鏈
- 支援團隊對同一 host 的 Virtual Service 進行靈活分片,比如按照 SecOps/Netops/Business 特性分離,各團隊維護各種獨立的 Virtual Service
8. 全鏈路跟蹤並非完全透明接入
異常案例
微服務接入後 service mesh 後,鏈路跟蹤數據沒有形成串聯。
原因
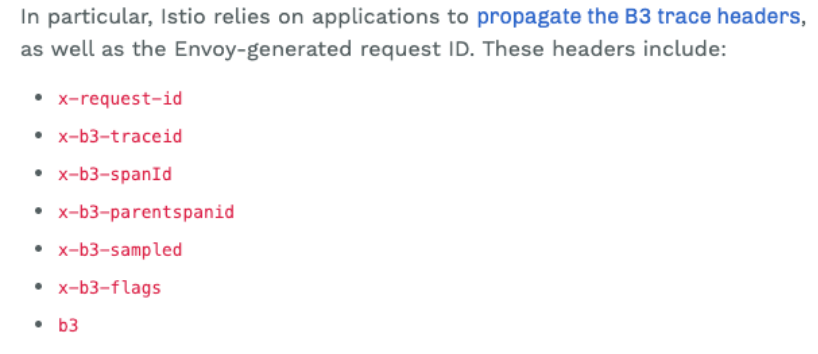
service mesh 遙測系統中,對調用鏈跟蹤的實現,並非完全的零入侵,需要用戶業務作出少量的修改才能支援,具體地,在用戶發出(http/grpc) RPC 時, 需要主動將上游請求中存在的 B3 trace headers寫入下游 RPC 請求頭中,這些 headers 包括:
有部分用戶難以理解:既然 inbound 流量和 outbound 流量已經完全被攔截到 envoy,envoy 可以實現完全的流量管控和修改,為什麼還需要應用顯示第傳遞 headers?
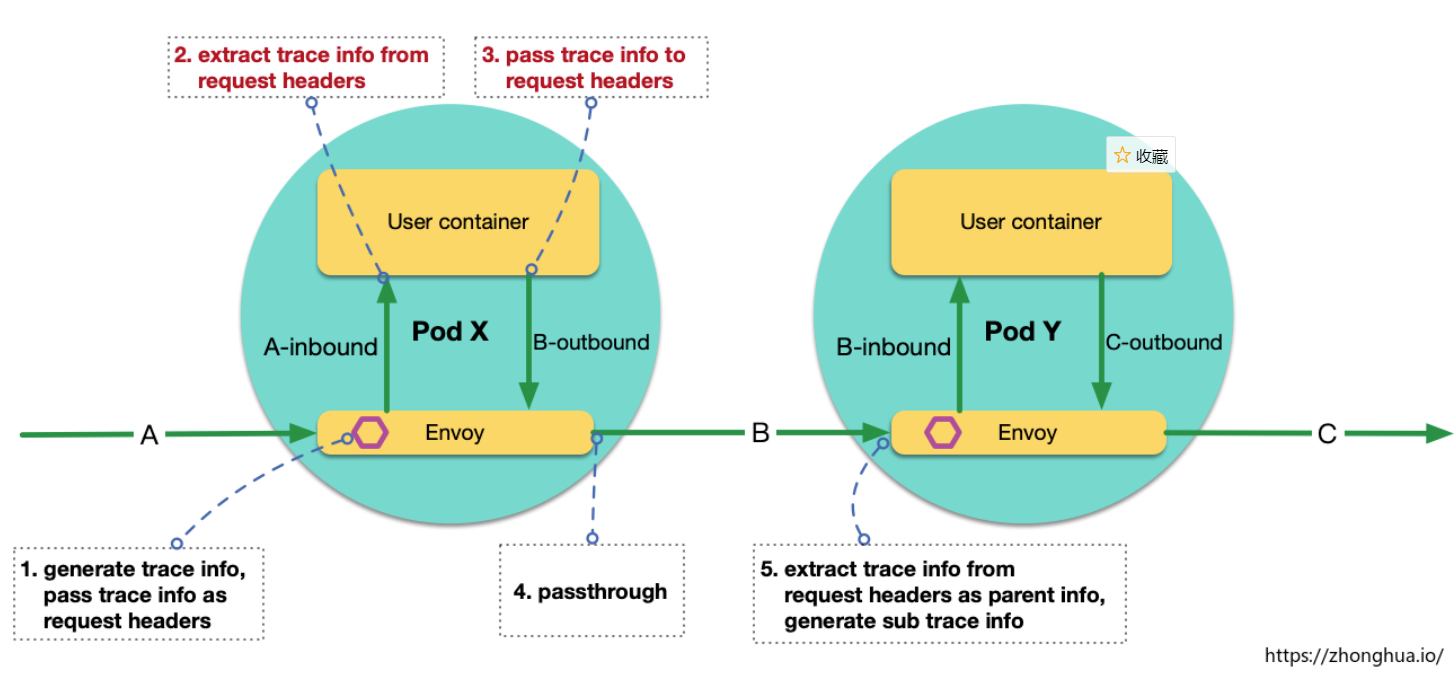
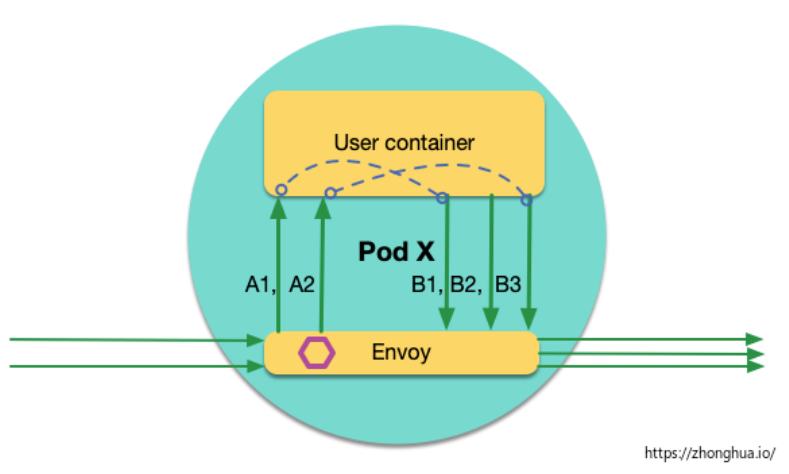
對於 envoy 來說,inbound 請求和 outbound 請求完全是獨立的,envoy 無法感知請求之間的關聯。實際上這些請求到底有無上下級關聯,完全由應用自己決定。舉一個特殊的業務場景,如果 Pod X 接收到 請求 A,觸發的業務邏輯是:每隔 10 秒 發送一個請求到 Pod Y,如 B1,B2,B3,那麼這些扇出的請求 Bx(x=1,2,3…),和請求 A 是什麼關係?業務可能有不同的決策:認為 A 是 Bx 的父請求,或者認為 Bx 是獨立的頂層請求。
9. mTLS 導致連接中斷
在開啟 istio mTLS 的用戶場景中,訪問出現 connection termination 是一個高頻的異常:
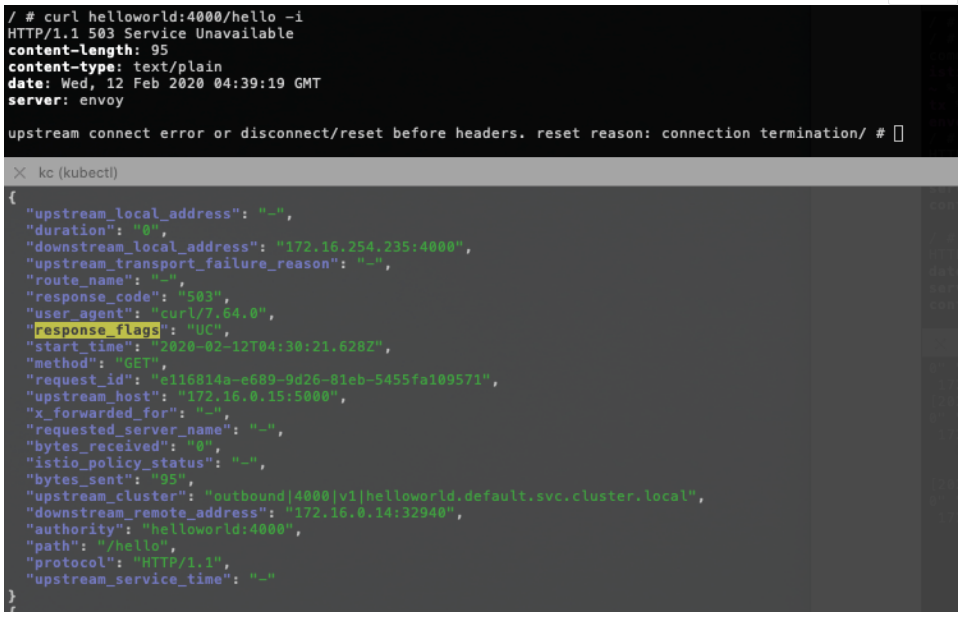
這個異常的原因和 DestinationRule 中的 mTLS 配置有關,是 istio 中一個不健壯的介面設計。
- 當通過 MeshPolicy 開啟全局 mTLS, 如果網格中沒有定義其他的 DestinationRule,mTLS 正常運行
- 如果後續網格中新增了 DestinationRule,而 DestinationRule 中可以覆蓋子版本的 mTLS 值(默認是不開啟!), 用戶在使用 DestinationRule 時,往往很少去關注 mTLS 屬性(留空)。最終導致增 DestinationRule 後 mTLS 變成了不開啟,導致
connection termination - 為了修復以上問題,用戶不得不在所有 DestinationRule 中增加 mTLS 屬性並設置為開啟

這種 istio mtls 用戶介面極度不友好,雖然 mtls 默認做到了全局透明, 業務感知不到 mtls 的存在, 但是一旦業務定義了 DestinationRule,就必須要知道當前 mtls 是否開啟,並作出調整。試想 mtls 配置交由安全團隊負責,而業務團隊負責各自的 DestinationRule,團隊間的耦合會非常嚴重。
10. 用戶服務監聽地址限制
異常描述
如果用戶容器中業務進程監聽的地址是具體ip (pod ip),而不是0.0.0.0, 該用戶容器無法正常接入 istio,流量路由失敗。這是又一個挑戰 Istio 最大透明化(Maximize Transparency)設計目標 的場景。
原因分析
Istio-proxy 中的一段 iptables:

其中,ISTIO_IN_REDIRECT 是 virtualInbound, 埠 15006;ISTIO_REDIRECT 是 virtualOutbound,埠 15001。
關鍵點是規則二:如果 destination 不是127.0.0.1/32, 轉給15006 (virtualInbound, envoy監聽),這裡導致了對 pod ip 的流量始終會回到 envoy。
對該規則的解釋:
# Redirect app calls back to itself via Envoy when using the service VIP or endpoint # address, e.g. appN => Envoy (client) => Envoy (server) => appN.
該規則是希望在這裡起作用: 假設當前Pod a屬於service A, Pod 中用戶容器通過服務名訪問服務A, envoy中負載均衡邏輯將這次訪問轉發到了當前的pod ip, istio 希望這種場景服務端仍然有流量管控能力. 如圖示:
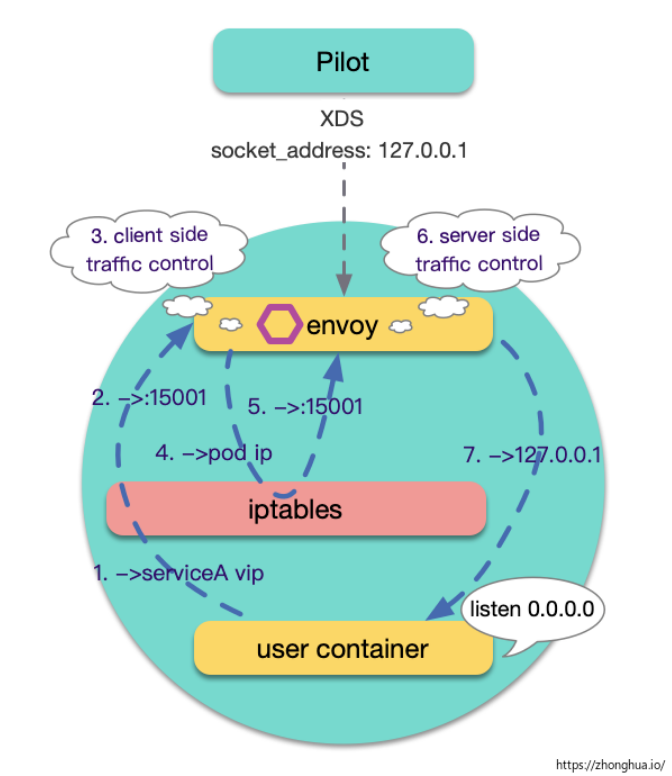
改造建議
建議應用在接入 istio 之前, 調整服務監聽地址,使用 0.0.0.0 而不是具體 IP。如果業務方認為改造難度大,可以參考之前分享的一個解決方案:服務監聽pod ip 在istio中路由異常分析
【騰訊雲原生】雲說新品、雲研新術、雲遊新活、雲賞資訊,掃碼關注同名公眾號,及時獲取更多乾貨!!


