從原理到應用落地,一文讀懂推薦系統中的深度學習技術
- 2019 年 11 月 1 日
- 筆記
作者丨gongyouliu、zandy 來源丨大數據與人工智慧(ID:ai-big-data)
2016年DeepMind開發的AlphaGo在圍棋對決中戰勝了韓國九段選手李世石,一時成為轟動全球的重大新聞,被全球多家媒體大肆報道。AlphaGo之所以取得這麼大的成功,這其中最重要的技術之一是深度學習技術。經過這幾年的發展,深度學習技術已經在影像分類、語音識別、自然語言處理等領域取得突破性進展,甚至在某些方面(如影像分類等)超越了人類專家的水平。深度學習技術驅動了第三次人工智慧浪潮的到來。
鑒於深度學習技術的巨大威力,它被學術界、產業界嘗試應用於各類業務及應用場景,包括電腦視覺、語音識別、自然語言處理、搜索、推薦、廣告等等。2016年YouTube發表論文將深度學習應用於影片推薦取得了非常好的效果,自此之後,深度學習技術在推薦系統上的應用遍地開花,各種論文、學術交流、產業應用層出不窮。國際著名的推薦系統會議RecSys從2016開始專門組織關於深度學習的會議,深度學習在推薦圈中越來越受到重視。
本文試圖對深度學習在推薦系統中的應用進行全面介紹,不光介紹具體的演算法原理,還會重點講解作者對深度學習技術的思考及深度學習應用於推薦系統的當前生態和狀況,我會更多地聚焦深度學習在工業界的應用。
具體來說,本文會從深度學習介紹、利用深度學習做推薦的一般方法和思路、工業界經典深度學習推薦演算法介紹、開源深度學習框架&推薦演算法介紹、深度學習推薦系統的優缺點、深度學習推薦系統工程實施建議、深度學習推薦系統的未來發展等7個部分分別介紹。
本文的目的是通過全面的介紹讓讀者更好地了解深度學習在推薦上的應用,並更多地冷靜思考,思考當前是否值得將深度學習引入到推薦業務中,以及怎麼引入、需要具備的條件、付出的成本等等,而不是追熱點跟風去做。
深度學習是一把雙刃劍,我們只有很好地理解深度學習、了解它當前的應用狀況,最終才能更好地用好深度學習這個強有力的武器,服務好推薦業務。希望本文可以為讀者提供一個了解深度學習在推薦系統中的應用的較全面的視角,成為你的一份學習深度學習推薦系統的參考指南。
一、深度學習介紹
深度學習其實就是神經網路模型,一般來說,隱含層數量大於等於2層就認為是深度學習(神經網路)模型。神經網路不是什麼新鮮概念,在好幾十年前就被提出來了,最早可追溯到1943年McCulloch與Pitts合作的一篇論文(參考文獻1),神經網路是模擬人的大腦中神經元與突觸之間進行資訊處理與交互的過程而提出的。
神經網路的一般結構如下圖,一般分為輸入層、隱含層和輸出層三層,其中隱含層可以有多層,各層中的圓形是對應的節點(模擬神經元的對應物),節點之間通過有向邊(模擬神經元之間的突觸)連接,所以神經網路也是一種有向圖模型。

圖1:深度學習網路(前饋神經網路)結構示意圖
假設前饋神經網路一共有k個隱含層,那麼我們可以用如下一組公式來說明數據沿著箭頭傳遞的計算過程,其中

是輸入,


是第i個隱含層各個節點對應的數值,
是從第i-1層到第i層的權重矩陣,

是偏移量,

是激活函數,

是最終的輸出,這裡
、
是需要學習的參數。


……

對於更加複雜的深度學習網路模型,公式會更加複雜,這裡不細說。深度學習一般應用於回歸、分類等監督學習問題,通過輸出層的損失函數,構建對應的最優化問題,深度學習藉助於反向傳播(參考文獻3)技術來進行迭代優化,將預測誤差從輸出層向輸入層(即反向)傳遞,依次更新各層的網路參數,通過結合某種參數更新的最優化演算法(一般是各種梯度下降演算法),實現參數的調整和更新,最終通過多倫迭代讓損失函數收斂到(局部)最小值,從而求出模型參數。梯度下降演算法的推導公式依賴於數學中求導的鏈式規則,這裡具體不做介紹,讀者可以參考相關文章及書本學習了解。
雖然神經網路很早被提出來了,但當時只是停留在學術研究領域,一直沒有得到大規模的產業應用。最早的神經網路叫做感知機(Perceptron),是單層的人工神經網路,只用於模擬簡單的線性可分函數,連最簡單的XOR異或都無能為力,這種致命的缺陷導致了神經網路發展的第一次低谷,科研院校紛紛減少對神經網路研究的經費支援。
單層感知機無法解決線性不可分的分類問題,後面人們提出了有名的多層感知機(MLP),但是限於當時沒有好的方法來訓練MLP,直到80年代左右,反向傳遞演算法被發現,被用於手寫字元識別並取得了成功,但是訓練速度非常慢,更複雜的問題根本無法解決。
90年代中期,由Vapnik等人發明的支援向量機(SVM)在各類問題上取得了非常好的效果,基本秒殺神經網路模型,這時神經網路技術陷入了第二次低谷,只有Hinton等很少學者一直堅持研究神經網路。
事情的轉機出現在2006年,Hinton提出了深度置信網路,通過預訓練及微調的技術讓深度神經網路的訓練時間及效果得到了極大提升。到了2012年,Hinton及他的學生提出的AlexNet網路(一種深度卷積神經網路)在ImageNet競賽(2010年開始,斯坦福的李飛飛教授組織的ImageNet項目,是一個用於視覺對象識別軟體研究的大型可視化資料庫,該競賽直接促進了以深度學習驅動的第三次AI浪潮的發展)中取得了第一名,成績比第二名高出許多,這之後深度學習技術獲得了空前的巨大成功。
經過近十來年的發展,有更多的神經網路模型被陸續發現,除了最古老的多層感知機(MLP)外,卷積神經網路(CNN)在影像識別取得極大的勝利,循環神經網路(RNN)在語音識別、自然語音處理中如魚得水,CNN和RNN是當前最成功的兩類神經網路模型,它們有非常多的變種。另外,像自編碼器(Autoencoder)、對抗網路(Adversarial Network,簡稱AN)等新的模型及神經網路架構不斷被提出。
對深度學習發展歷史感興趣的讀者可以閱讀參考文獻2,該文對深度學習發展歷史做了非常好的總結與整理。
二、利用深度學習做推薦的一般方法和思路
在上一節我們對深度學習的基本概念、原理、發展歷史做了簡單的介紹,同時也提到了MLP、CNN、RNN、Autoencoder、AN幾類比較出名並且常見的神經網路模型,這幾類模型都可以應用於推薦系統中。
本節我們來簡單講解一下可以從哪些角度將深度學習技術應用於推薦系統中。根據推薦系統的分類及深度學習模型的歸類,我們大致可以從如下三個角度來思考怎麼在推薦系統中整合深度學習技術。這些思考問題的角度可以幫助我們結合深度學習相關技術、推薦系統本身的特性以及公司具備的數據及業務特點選擇合適自身業務和技能的深度學習技術,將深度學習技術更好地落地到推薦業務中。
- 1、從推薦演算法中用到的深度學習技術角度來思考
常用的深度學習模型有MLP(多層感知機)、CNN(卷積神經網路)、RNN(循環神經網路)、Autoencoder(自編碼器)、AN(Adversarial Network,對抗網路)、RBM(受限玻爾茲曼機)、NADE(Neural Autoregressive Distribution Estimation)、AM(Attentional Model,注意力模型)、DRL(深度強化學習)等,這些模型都可以跟推薦系統結合起來,並且學術界和產業界都有相關的論文發表。
讀者可以參見參考文獻5,該文章是一篇非常全面實用的深度學習推薦系統綜述文章,在這篇文章中作者就是按照不同深度學習模型來整理當前深度學習應用於推薦系統的有代表性的文章和方法的。希望對深度學習推薦系統有全面了解和學習的讀者可以好好閱讀這篇文章,一定會有較大的收穫。
目前採用MLP網路來構建深度學習推薦演算法是最常見的一種範式(參考文獻7、8、13、19等),如果需要整合附加資訊(影像、文本、語音、影片等)會採用CNN、RNN模型來提取相關資訊。
- 2、從推薦系統的預測目標來思考
從推薦系統作為機器學習任務的目標來看,推薦系統是為用戶推薦用戶可能感興趣的標的物,一般可以分為預測評分、排序學習、分類等三類問題,下面分別介紹。
(1) 推薦作為評分預測問題
我們可以通過構建機器學習模型來預測用戶對未知標的物的評分,高的評分代表用戶對標的物更有興趣,最終根據評分高低來為用戶推薦標的物。這時推薦演算法就是一個回歸問題,經典的協同過濾演算法(如矩陣分解)、logistic回歸推薦演算法都是這類模型,以及基於經典協同過濾思路發展的深度學習演算法(見參考文獻19)也是這類模型。
由於在真實產品中用戶對標的物評分數據非常有限,因此隱式回饋是比用戶評分更容易獲得的數據類型,所以採用評分預測問題來構建深度學習推薦系統的案例及文章會比較少。深度學習需要大量的數據來訓練好的模型,因此也期望數據量足夠大,所以利用隱式回饋數據是更合適的。
(2) 推薦作為排序學習問題
可以將推薦問題看成排序學習(Learning to Ranking)問題,採用資訊抽提領域經典的一些排序學習演算法(point-wise、pair-wise、list-wise等)來進行建模,關於這方面利用深度學習做推薦的文章也有一些,比如參考文獻46是京東的一篇基於深度強化學習做list-wise排序推薦的文章。作者未來會單獨寫一篇關於排序學習相關的文章,這裡不細講解。
(3) 推薦作為分類問題
將推薦預測看成是分類問題是比較常見的一種形式,既可以看成二分類問題,也可以看成多分類問題。
對於隱式回饋,我們用0和1表示標的物是否被用戶操作過,那麼預測用戶對新標的物的偏好就可以看成一個二分類問題,通過輸出層的logistic激活函數來預測用戶對標的物的點擊概率。這種將推薦作為二分類問題,通過預測點擊概率的方式是最常用的一種推薦系統建模方式。下面會講到的wide & deep模型就是採用這樣的建模方式。
我們也可以將推薦預測問題看成一個多分類問題,每一個標的物就是一個類別,有多少個標的物就有多少類,一般標的物的數量是巨大的,所以這種思路就是一個海量標籤(label)分類問題。我們可以通過輸出層的softmax激活函數來預測用戶對每個類別的「分量概率」,預測用戶下一個要點擊的標的物就是分量概率最大的一個標的物。下面要講到的YouTube深度學習中的召回階段採用的就是這種建模方式。
- 3、根據推薦演算法的來歸類來思考
從推薦演算法最傳統的分類方式來看,推薦演算法分為基於內容的推薦、協同過濾推薦、混合推薦等三大類。
(1) 基於內容的推薦
基於內容的推薦,會用到用戶或者標的物的metadata資訊,基於該metadata資訊來為用戶做推薦,這些metadata資訊主要有文本、圖片、影片、音頻等,一般會用CNN或者RNN從metadata中提取資訊,並基於該資訊做推薦。參考文獻9就是這類推薦。
(2) 協同過濾推薦
協同過濾只依賴用戶的行為數據,不依賴metadata數據,因此可以在更多更廣泛的場景中使用,它也是最主流的推薦技術。絕大多數深度學習推薦系統都是基於協同過濾思路來推薦的,或者至少包含部分協同過濾的模組在其中,參考文獻19就是這類模型中的一個代表。
(3) 混合推薦
混合推薦就是混合使用多種模型進行推薦,可以混合使用基於內容的推薦和協同過濾推薦,或者混合多種內容推薦、混合多種協同過濾推薦等。參考文獻10就是一種混合的深度學習推薦演算法。下面要講到的wide & deep模型中wide部分可以整合metadata資訊,deep部分類似協同的思路,因此也可以認為是一種混合模型。
三、幾種用於推薦系統的嵌入方法的演算法原理介紹
深度學習在推薦系統中的應用最早可以追溯到2007年Hinton跟他的學生們發表的一篇將受限玻爾茲曼機應用於推薦系統的文章(參考文獻6),隨著深度學習在電腦視覺、語音識別與自然語音處理的成功,越來越多的研究者及工業界人士開始將深度學習應用於推薦業務中,最有代表性的是2016年Google發表的wide & deep模型和YouTube深度學習推薦模型(這兩個模型我們下面會重點講解),這之後深度學習在推薦上的應用如雨後春筍,使用各種深度學習演算法應用於各類產品形態上。
本節我們選擇幾個有代表性的工業級深度學習推薦系統,講解它們的演算法原理和核心亮點,讓大家更好地了解深度學習在推薦的應用方法,希望給大家提供一些可借鑒的的思路和方法。具體來說我們會重點講解如下4個主流深度學習推薦模型,在最後也會對其他重要的模型進行簡單介紹。
- 1、YouTube深度學習推薦系統
該模型發表於2016年(參考文獻7),應用於YouTube上的影片推薦。該篇文章按照工業級推薦系統的架構將整個推薦流程分為兩個階段:候選集生成(召回)和候選集排序(排序)(見下面圖2)。
構建YouTube影片推薦系統會面臨三大問題:規模大(YouTube有海量的用戶和影片),影片更新頻繁(每秒鐘都有數小時時長的影片上傳到YouTube平台,噪音(影片metadata不全、不規範,也無法很好度量用戶對影片的興趣),通過將推薦流程分解為這兩步,並且這兩部都採用深度學習模型來建模,很好地解決了這三大問題,最終獲得非常好的線上效果。

圖2:YouTube深度學習推薦系統架構
候選集生成階段根據用戶在YouTube上的行為為用戶生成幾百個候選影片,候選集影片期望盡量匹配用戶可能的興趣偏好。排序階段從更多的(特徵)維度為候選影片打分,根據打分高低排序,將用戶最有可能點擊的幾十個作為最終的推薦結果。劃分為兩階段的好處是可以更好地從海量影片庫中為用戶找到幾十個用戶可能感興趣的影片(通過兩階段逐步縮小查找範圍),同時可以很好地融合多種召回策略召回影片。下面我們分別來講解這兩個步驟的演算法。
- 候選集生成
通過將推薦問題看成一個多分類問題(類別的數量等於影片個數),基於用戶過去觀看記錄預測用戶下一個要觀看的影片的類別。利用深度學習(MLP)來進行建模,將用戶和影片嵌入同一個低維空間,通過softmax激活函數來預測用戶在時間點t觀看影片i的的概率。具體預測概率公式如下:

其中u、v分別是用戶和影片的嵌入向量。U是用戶集,C是上下文。該方法通過一個(深度學習)模型來一次性學習出用戶和影片的嵌入向量。
由於用戶在YouTube的顯示回饋較少,該模型採用隱式回饋數據,這樣可以用於模型訓練數據量會大很多,這剛好適合深度學習這種強依賴數據量的演算法系統。
為了更快地訓練深度學習多分類問題,該模型採用了負取樣機制(重要性加權的候選影片集抽樣)提升訓練速度。最終通過最小化交叉熵損失函數(cross-entropy loss)求得模型參數。通過負取樣可以將整個模型訓練加速上百倍。
候選集生成階段的深度學習模型結構如下圖。首先將用戶的行為記錄按照word2vec的思路嵌入到低維空間中(參考作者《嵌入方法在推薦系統中的應用》第四節2中的item2vec方法),將用戶的所有點擊過的影片的嵌入向量求平均(如element-wise average),獲得用戶播放行為的綜合嵌入表示(即下圖的watch vector)。
同樣的道理,可以將用戶的搜索詞做嵌入,獲得用戶綜合的搜素行為嵌入向量(即下圖的search vector)。同時跟用戶的其他非影片播放特徵(地理位置、性別等)拼接為最終灌入深度學習模型的輸入向量,再通過三層全連接的ReLU層,最終通過輸出層(輸出層的維度就是影片個數)的softmax激活函數獲得輸出,利用交叉熵損失函數來訓練模型最終求解最優的深度學習模型。

圖3:候選集生成階段深度學習模型結構
下面我們來講解一下候選集生成階段怎麼來篩選出候選集的,這一塊在論文中沒有講的很清楚(有可能論文作者覺得這個太簡單沒必要講,但是我還是花了很長時間才搞清楚的)。最上一層ReLU層是512維的,這一層可以認為是一個嵌入表示,表示的是用戶的嵌入向量。
那麼怎麼獲得影片的嵌入向量呢?是通過用戶嵌入向量經過softmax變換獲得512維的影片嵌入向量,這樣用戶和影片嵌入都確定了。最終可以通過用戶嵌入在所有影片嵌入向量空間中,按照內積度量找最相似的topN作為候選集。通過這裡的描述,我們可以將候選集生成階段看成是一個嵌入方法,是矩陣分解演算法的非線性(MLP神經網路)推廣。
候選集生成階段的亮點除了創造性地構建深度學習多分類問題、通過用戶、影片的嵌入獲取嵌入表示,通過KNN獲得候選集外,還有很多工程實踐上的哲學,這裡簡單列舉幾個:
(1) 每個用戶生成固定數量的訓練樣本,「公平」對待每一個用戶,而不是根據用戶觀看影片頻度的多少按照比例獲取訓練樣本(即觀看多的活躍用戶取更多的訓練樣本),這樣可以提升模型泛化能力,從而獲得更好的在線評估指標。
(2) 選擇輸入樣本和label時,是需要label觀看時間上在輸入樣本之後的,這是因為用戶觀看影片是有一定序關係的,比如一個系列影片,用戶看了第一季後,很可能看第二季。因此,模型預測用戶下一個要看的影片比預測隨機一個更好,能夠更好地提升在線評估指標,這就是要選擇label的時間在輸入樣本之後的原因。
(3) 模型將「example age」(等於
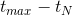
,這裡

是訓練集中用戶觀看影片的最大時間,

是某個樣本的label觀看時間)整合到深度學習模型的輸入特徵中,這個特徵可以很好地反應影片在上傳到YouTube之後播放流量的真實分布(一般是剛上線後流量有一個峰值,後面就迅速減少了),通過整合該特徵後預測影片的分布跟真實播放分布保持一致。
- 候選集排序
候選集排序階段(參見下面圖4)通過整合用戶更多維度的特徵,通過特徵拼接獲得最終的模型輸入向量,灌入三層的全連接MLP神經網路,通過一個加權的logistic回歸輸出層獲得對用戶點擊概率(即是我們前面介紹的當做二分類問題)的預測,同樣採用交叉熵作為損失函數。

圖4:候選集排序階段深度學習模型結構
YouTube希望優化的不是點擊率而是用戶的播放時長,這樣可以更好地滿足用戶需求,提升了時長也會獲得更好的廣告投放回報(時長增加了,投放廣告的可能性也相對增加),因此在候選集排序階段希望預測用戶下一個影片的播放時長。
所以才採用圖4的這種輸出層的加權logistic回歸激活函數和預測的指數函數(

),下面我們來說明為什麼這樣的形式剛好是優化了用戶的播放時長。
模型用加權logistic回歸來作為輸出層的激活函數,對於正樣本,權重是影片的觀看時間,對於負樣本權重為1。下面我們簡單說明一下為什麼用加權logistic回歸以及serving階段為什麼要用
來預測。
logistic函數公式如下,

通過變換,我們得到

左邊即是logistic回歸的odds(幾率),下面我們說明一下上述加權的logistic回歸為什麼預測的也是odds。對於正樣本i,由於用了

加權,odds可以計算為

上式中約等於號成立,是因為YouTube影片總量非常大,而正樣本是很少的,因此點擊率

很小,相對於1可以忽略不計。上式計算的結果正好是影片的期望播放時長。因此,通過加權logistic回歸來訓練模型,並通過
來預測,剛好預測的正是影片的期望觀看時長,預測的目標跟建模的期望保持一致,這是該模型非常巧妙的地方。
候選集排序階段為了讓排序更加精準,利用了非常多的特徵灌入模型(由於只需對候選集中的幾百個而不是全部影片排序,這時可以選用更多的特徵、相對複雜的模型),包括類別特徵和連續特徵,文章中講解了很多特徵處理的思想和策略,這裡不細介紹,讀者可以看論文深入了解。
YouTube的這篇推薦論文是非常經典的工業級深度學習推薦論文(我個人覺得是我看到的所有深度學習推薦系統論文中最好的一篇,沒有之一),裡面有很多工程上的權衡和處理技巧,值得我們深入學習。
這篇論文理解起來還是比較困難的,需要有很多工程上的經驗積累才能夠領悟其中的奧妙。因此,據我所知中國很少有團隊將這篇文章的方法應用於自己團隊的業務中的,而下一篇我們要講的wide & deep模型卻非常多,主要原因可能是對這篇文章的核心亮點把握還不夠,或者裡面用到的很多巧妙的工程設計哲學不適合自己公司的業務情況。
我們團隊在17年嘗試將該模型的候選集生成階段直接應用於推薦(沒有排序階段,我們也是影片行業,但是是長影片,因此影片量沒有YouTube那麼多,因此沒有採用兩階段的策略),並且取得了比矩陣效果轉化率提升近20%以上的效果。
- 2、Google的wide&deep深度學習推薦模型
參考文獻8是Google在2016年提出的一個深度學習模型,應用於Google Play應用商店上的APP推薦,該模型經過在線AB測試獲得了比較好的效果。這篇文章也是比較早將深度學習應用於工業界的文章,也是一篇非常有價值的文章,對整個深度學習推薦系統有比較大的積極促進作用。
基於該模型衍生出了很多其他模型(如參考文獻27中的DeepFM),並且很多都在工業界取得了很大的成功,在這一部分我們對該模型的思想進行簡單介紹,並介紹2個由該模型衍生出的比較有價值、有代表性的模型。
wide & deep模型分為wide和deep兩部分。wide部分是一個線性模型,學習特徵間的簡單交互,能夠「記憶」用戶的行為,為用戶推薦感興趣的內容,但是需要大量耗時費力的人工特徵工作。
deep部分是一個前饋深度神經網路模型,通過稀疏特徵的低維嵌入,可以學習到訓練樣本中不可見的特徵之間的複雜交叉組合,因此可以提升模型的泛化能力,並且也可以有效避免複雜的人工特徵工程。通過將這兩部分結合,聯合訓練,最終獲得記憶和泛化兩個優點。該模型的網路結構圖如下面圖5中間(左邊是對應的wide部分,右邊是deep部分)。

圖5:wide & deep 模型網路結構
wide部分是一般線性模型

,y是最終的預測值,這裡

是d個特徵,

是模型參數,b是bias。這裡的特徵
包含兩類特徵:
(1) 原始輸入特徵;
(2) 通過變換後(交叉積)的特徵;
這裡的用的主要變換是交叉積(cross-product),它定義如下:

上式中

是布爾型變數,如果第i個特徵

是第k個變換

的一部分,那麼
=1,否則為0。對於交叉積And(gender=female, language=en),只有當它的成分特徵都為1時,

,否則

。
deep部分是一個前饋神經網路模型,高維類別特徵通過先嵌入到低維空間(幾十上百維)轉化為稠密向量, 再灌入深度學習模型中。神經網路中每層通過計算公式

與上層進行數據交互。上式中

是層數,f是激活函數(該模型採用了ReLU),

、

是模型需要學習的參數。
最終wide和deep部分需要結合起來,通過將他們的的對數幾率加權平均,再餵給logistic損失函數進行聯合訓練。最終我們通過如下方式來預測用戶的興趣偏好(這裡也是將預測看成是二分類問題,預測用戶的點擊概率)。

這裡,

是最終的二元分類變數,

是sigmoid函數,

是前面提到的交叉積特徵,

和

分別是wide模型的權重和deep模型中對應於最後激活

的權重。
下圖是最終的wide & deep模型的整體結構,類別特徵是嵌入到32維空間的稠密向量,數值特徵歸一化到0-1之間(本文中歸一化採用了該變數的累積分布函數,再通過將累積分布函數分成若干個分位點,用

來作為該變數的歸一化值,這裡
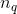
是分位點的個數),數值特徵和類別特徵拼接起來形成大約1200維的向量再灌入deep模型,而wide模型是APP安裝和APP評分(impression)兩類特徵通過交叉積變換形成模型需要的特徵。最後通過反向傳播演算法來訓練該模型(wide模型採用FTRL優化器,deep模型採用AdaGrad優化器),並上線到APP推薦業務中做AB測試。

圖6:wide & deep 模型的數據源於具體網路結構
上面簡單介紹完了wide & deep 模型,詳細的介紹請讀者閱讀參考文獻8進行了解。
藉助wide & deep模型這種將簡單模型跟深度學習模型聯合訓練,最終獲得淺層模型的記憶特性及深度模型的泛化特性兩大優點,有很多研究者進行了很多不同維度的嘗試和探索。其中deepFM(參考文獻27)就是將分解機與深度學習進行結合,部分解決了wide & deep模型中wide部分還是需要做很多人工特徵工程的問題,並取得了非常好的效果,被中國很多公司應用於推薦系統排序及廣告點擊預估中。
參考文獻13中,阿里提出了一種BST(Behavior Sequence Transformer)模型(見下圖),通過引入Transformer技術(參見參考文獻44、45),將用戶的行為序列關係整合到模型中,能夠捕獲用戶訪問的順序訊號,該模型跟wide & deep最大的不同是將用戶行為序列嵌入低維空間並通過一個Transformer層捕獲用戶行為序列特徵後再跟其他特徵(包括用戶維度的、物品維度的、上下文的、交叉的4類特徵)拼接灌入MLP網路訓練。該模型在淘寶真實推薦排序業務場景中得到了比wide & deep模型更好的效果,感興趣的讀者可以閱讀原文。

圖7:BST推薦模型網路結構
- 3、阿里基於興趣樹(TDM)的深度學習推薦演算法
參考文獻16中阿里的演算法工程師們提出了一類基於興趣樹(Tree-based Deep Model)的深度學習推薦模型,通過利用從粗到精的方式從上到下檢索興趣樹的節點為用戶生成推薦候選集,該方法可以從海量商品中快速(檢索時間正比於商品數量的對數,因此是一類高效的演算法)檢索出topN用戶最感興趣的商品,因此該演算法非常適合淘寶推薦中從海量商品中進行召回。下面我們對該演算法的基本原理做簡單介紹,演算法一共分為如下3個主要步驟。
(1) 構建興趣樹
構建樹模型分為兩種情況,首先是初始化樹模型,有了樹模型會經過下面的步驟(2)的深度學習模型學習樹中葉子節點的嵌入表示,有了嵌入表示後再重新優化新的樹模型,下面我們分別講解初始化樹模型和獲得了葉子節點的嵌入表示後重新構建新的樹模型。
初始化樹模型的思路是希望將相似的物品放到樹中相近的地方(參見下面圖8)。由於開始沒有足夠多的資訊,這時可以利用物品的類別資訊,同一類別中的物品一般會比不同類別的物品更相似。假設一共有k個類別,我們將這k個類別隨機排序,排序後為C_1、C_2、…… 、C_k,每一類中的物品隨機排序,如果一個物品屬於多個類別,那麼將它分配到所屬的任何類別中,確保每個商品分配的唯一性。
那麼通過這樣處理,就變為下圖中的最上面一層這樣的排列。這時可以找到這一個物品隊列的中點(下圖最最上一層的紅豎線),從中間將隊列均勻地分為兩個隊列(見下圖第二層的節點),這兩個隊列再分別從中間分為兩個隊列,遞歸進行下去,直到每個隊列只包含一個物品為止,這樣就構建出了一棵(平衡)二叉樹,得到了初始化的興趣樹模型。

圖8:初始化樹模型
如果有了興趣樹葉子節點的嵌入向量表示,我們可以基於該向量表示利用聚類演算法構建一棵新的興趣樹,具體流程如下:利用kmeans將所有商品的嵌入向量聚類為2類,並對這兩類做適當調整使得最終構建的興趣樹更加平衡(這兩類中的商品差不多一樣多),並對每一類再採用kmeans聚類並適當調整保持分的兩類包含的商品差不多一樣多,這個過程一直進行下去,直到每類只包含一個商品,這個分類過程就構建出了一棵平衡的二叉樹。由於是採用嵌入向量進行的kmeans聚類,被分在同一類的嵌入向量相似(歐幾里得距離小),因此,構建的興趣樹滿足相似的節點放在相近的地方。
(2) 學習興趣樹葉子節點的嵌入表示
在講興趣樹模型訓練之前,先說下該興趣樹的需要滿足的特性。該篇文章中的興趣樹是一種類似最大堆(為了方便最終求出topN推薦候選集)的樹。對於樹中第j層的每個非葉子節點,滿足如下公式:


是用戶u對商品n感興趣的概率,

是層j的歸一化項,保證該層所有節點的概率加起來等於1。上式的意思是某個非葉子節點的興趣概率等於它的子節點中興趣概率的最大值除以歸一化項。
為了訓練樹模型,我們需要確定樹中每個節點是否是正樣本節點和負樣本節點,下面說明怎麼確定它們。如果用戶喜歡某個葉子節點(即喜歡該葉子節點對應的商品,即用戶對該商品有隱式回饋),那麼該葉子節點從下到上沿著樹結構的所有父節點都是正樣本節點。
因此,該用戶所有喜歡的葉子節點及對應的父節點都是正樣本節點。對於某一層除去所有的正樣本節點,從剩下的節點中隨機選取節點作為負樣本節點,這個過程即是負取樣。讀者可以參考下面圖6中右下角中的正樣本節點和負樣本節點,更好地理解剛剛的文字介紹。
記

、

分別為用戶u的正、負樣本集。該模型的似然函數為

這裡

是用戶u對物品n的喜好label(=0或者=1),

是
=1或
=0對應的概率。對所有用戶u和商品n,我們可以獲得對應的模型損失函數,具體如下

有了上面的背景解釋,興趣樹中葉子節點(即所有商品集)的嵌入表示可以通過下面圖9的深度學習模型來學習(損失函數就是上面的損失函數)。用戶的歷史行為按照時間順序被劃分為不同的時間窗口,每個窗口中的商品嵌入最終通過加權平均(權重從Activation Unit獲得,見下圖右上角的Activation Unit模型)獲得該窗口的最終嵌入表示。所有窗口的嵌入向量外加候選節點(即正樣本和負取樣的樣本)的嵌入向量通過拼接,作為最上層神經網路模型的輸入。
最上層的神經網路是3層全連接的帶PReLU激活函數的網路結構,輸出層是2分類的softmax激活函數,輸出值代表的是用戶對候選節點的喜好概率。每個葉子節點擁有一樣的嵌入向量,所有嵌入向量是隨機初始化的。

圖9:TDM演算法深度學習模型
這裡說一下,上述興趣樹結構和這裡的深度學習模型是可以交替聯合訓練的。先構造初始化樹,再訓練深度學習模型直到收斂,從而獲得所有節點(即商品)的嵌入表示,基於該嵌入表示又可以獲得新的興趣樹,這時又可以開始訓練新的深度神經網路模型了,這個過程可以一直進行下去獲得更佳的效果。
(3) 從樹中檢索出topN最喜歡的商品
通過上面介紹的(1)、(2)兩步求得最終的興趣樹後,我們可以非常容易的檢索出topN用戶最喜歡的商品作為推薦候選集,具體流程如下:
採用自頂向下的方式檢索(這裡我們拿下面的圖10來說明,並且假設我們取top2候選集,對於更多候選集過程是一樣的)。從根節點1出發,從level2中取兩個興趣度最大的節點(從(2)中介紹可以知道,每個節點是有一個概率值來代表用戶對它的喜好度的),這裡是2、4兩個節點(用紅色標記了,下面也是一樣)。
再分別對2、4兩個節點找他們興趣度最大的兩個子節點,2的子節點是6、7,而4的子節點是11、12,從6、7、11、12這4個level3層的節點中選擇兩個興趣度最大的,這裡是6,11。再選擇6、11的兩個興趣度最大的子節點,分別是14、15和20、21,最後從14、15、20、21這四個level4層的節點中選擇2個興趣度最大的節點(假設是14、21)作為給用戶的最終候選推薦,所以最終top2的候選集是14、21。
在實際生成候選集推薦之前,可以事先對每個節點關聯一個N個元素的最大堆(即該節點興趣度最大的N個節點),將所有非葉子節點的最大堆採用Key-Value的數據結構存起來。在實際檢索時,每個非葉子節點直接從關聯的最大堆中獲取興趣度最大的N個子節點。因此,整個搜索過程是非常高效的。

圖10:從興趣樹中檢索出topN用戶最喜歡的商品
阿里這篇文章的思路還是非常值得學習的,通過樹模型檢索,可以大大減少檢索時間,避免了從海量商品庫中全量檢索的低效率情況,因此,該模型非常適合有海量標的物的產品的推薦候選集生成過程。感興趣的讀者可以好好閱讀該論文。
- 4、Google的NFC(神經網路協同過濾)深度學習推薦演算法
參考文獻19中提出了一種神經網路協同過濾模型(見下面圖11),通過將用戶行為矩陣中用戶和標的物向量做嵌入,灌入多層的MLP神經網路模型中,輸出層通過恆等激活函數輸出預測結果來預測用戶真實的評分,採用平方損失函數來訓練模型,因此這種方法就是第二節2中的預測評分問題。如果是隱式回饋,輸出層激活函數改為logistic函數,採用交叉熵損失函數,這時就是二分類問題。

圖11:NCF(Neural collaborative filtering)框架
矩陣分解演算法可以看成上面模型的特例,矩陣分解可以用公式

來表示,這裡
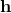
是所有分量為1的向量

是恆等函數,

代表的是向量對應位置的元素相乘(element-wise product),該公式可以將
看成權重,
看成激活函數,那麼矩陣分解演算法就可以看成只有輸入和輸出層(沒有隱含層)的神經網路模型,即是上面圖11中NCF模型的特例。
另外通過將矩陣分解和MLP的輸出向量拼接作為上面提到的NCF模型的輸入,可以得到下面表現力更強的神經矩陣分解模型。這裡不詳細講解,讀者可以閱讀原文了解更多細節。

圖12:神經矩陣分解模型(Neural matrix factorization model)
前面我們介紹了4篇利用深度學習進行推薦的工業級推薦系統解決方案,希望通過這幾個案例大家可以更好地了解深度學習在推薦系統中的應用方法與技巧。深度學習在工業界的應用最近幾年非常活躍,有很多這方面的論文發表,值得大家了解、學習和借鑒。由於時間及篇幅關係,還有很多好的文章和方法來不及整理,這裡簡單提一下,希望有興趣的讀者可以線下自行學習。
參考文獻18中,Facebook提供了一種DLRM的深度學習推薦模型,通過將嵌入技術、矩陣分解、分解機、MLP等技術整合起來,取各模型之長,能夠對稀疏特徵、稠密特徵進行建模,學習特徵之間的非線性關係,獲得更好的推薦預測效果。
參考文獻20是騰訊的微信團隊提出了一個基於注意力機制的look-alike深度學習模型RALM,是對廣告行業中傳統的look-alik模型的深度學習改造,通過用戶表示學習和look-alike學習捕獲種子用戶的局部和全局資訊,同時學慣用戶群和目標用戶的相似度表示,更好地挖掘長尾內容的受眾,並應用到了微信「看一看」中的精選推薦中。通過線上AB測試,點擊率、推薦結果多樣性等方面都有較大提升。
在參考文獻48中,Pinterest公司提出了一種圖卷積神經網路(Graph Convolutional Network)模型PinSage,結合高效的隨機遊走和圖卷積生成圖中節點的嵌入表示,該演算法有效地整合了圖結構和節點的特徵資訊。演算法部署到Pinterest網站上,通過AB測試獲得了非常好的推薦效果。該應用場景是深度圖嵌入技術在工業界規模最大的一個應用案例。
參考文獻17中網易考拉團隊提出了一個基於RNN的session-based實時推薦系統,參考文獻15中阿里提出了一個利用多個向量來表示一個用戶多重興趣的深度學習模型。另外,參考文獻11、12、14中阿里提出的DIN、SIEN、DSIN等用於CTR預估的深度學習模型也非常值得大家學習了解。
四、開源深度學習框架&推薦演算法介紹
深度學習技術要想很好地應用於推薦系統,需要我們開發出合適的深度學習推薦模型,並能夠很好地進行訓練、推斷,因此需要一個好的構建深度學習模型的計算平台。幸好,目前有很多開源的平台及工具可供大家選擇,讓深度學習的落地相對容易,不再只是大公司才使用得上的高端技術。本節我們就對業界比較主流的幾類深度學習平台進行介紹,給大家提供一些選擇的參考。同時,也會介紹該平台中已經實現的相關深度學習推薦演算法,這些演算法可以直接拿來用,或者作為我們學習深度學習推薦系統的材料。
- 1.Tensorflow(Keras)
Tensorflow是Google開源的深度學習平台,也是業界最流行的深度學習計算平台,有最為完善的開發者社區及周邊組件,被大量公司採用,並且幾乎所有的雲計算公司都支援Tensorflow雲端訓練。
Tensorflow整合了Keras,而Keras是一個高級的神經網路API,用python編寫,能夠運行在Tensorflow、CNTK或Theano之上,它的初衷是是實現快速實驗,能夠以最快的速度從想法到落地,因此可以快速實現神經網路原型,它的交互方式友好、模組化封裝得很好,很適合初學人員。
目前在Tensorflow上可以直接基於Keras API構建深度學習模型,這讓原本編程介面較低級的Tensorflow(相對沒有那麼好用)更加易用。
Tensorflow實現了NCF (Neural Collaborative Filtering)深度學習推薦演算法,讀者可以了解具體介紹及實現細節。
https://github.com/tensorflow/models/tree/master/official/recommendation
另外,Tensorflow在1.x中也有wide and deep推薦模型的實現,不過未包含在2.0版本中,讀者可以參考:
https://github.com/tensorflow/models/tree/master/official/r1/wide_deep
tensorrec也是一個基於Tensorflow的推薦庫,讀者可以參考:
https://github.com/jfkirk/tensorrec
基於Tensorflow的一個排序學習庫(見參考文獻47),可以基於該庫構建推薦候選集排序模型:
https://github.com/tensorflow/ranking/
- 2.PyTorch(Caffe)
PyTorch是Facebook開源的深度學習計算平台,目前是成長最快的深度學習平台之一,增長迅速,業界口碑很好,在學術界廣為使用,大有趕超Tensorflow的勢頭。它最大的優勢是對基於GPU的訓練加速支援得很好,有一套完善的自動求梯度的高效演算法,支援動態圖計算,有良好的編程API介面,非常容易實現快速的原型迭代。PyTorch整合了業界大名鼎鼎的電腦視覺深度學習庫Caffe,可以方便地復用基於Caffe的CV相關模型及資源。最近PyTorch發布了1.3版本,支援在移動端部署訓練好的深度神經網路模型。
利用PyTorch良好的編程介面及高效的網路搭建,可以非常容易構建各類深度學習推薦演算法。spotlight就是一個基於PyTorch的開源推薦演算法庫,提供基於分解模型和序列模型的推薦演算法實現,開源工程參見https://github.com/maciejkula/spotlight。
另外,參考文獻18中,Facebook提供了一種DLRM的深度學習推薦模型,通過將嵌入技術、矩陣分解、分解機、MLP等技術整合起來,能夠對類別特徵、數值特徵進行建模,學習特徵之間的隱含關係。該演算法已經開源,讀者可以參考https://github.com/facebookresearch/dlrm,該演算法分別利用PyTorch和Caffe2來實現了,這也算是Facebook官方提供的一個基於PyTorch平台的深度學習推薦演算法。
- 3.MxNet
MxNet也是一個非常流行的深度學習框架,是亞馬遜AWS上官方支援的深度學習框架。它是一個輕量級的、靈活便捷的分散式深度學習框架。支援Python、 R、Julia、Scala、 Go、 Javascript等各類程式語言介面。它允許你混合符號和命令式編程,以最大限度地提高效率和生產力。MxNet的核心是一個動態依賴調度程式,它可以動態地自動並行符號和命令操作,而構建在動態依賴調度程式之上的一個圖形優化層使符號執行速度更快,記憶體使用效率更高。MxNet具有隨身性和輕量級的優點,可以有效地擴展到多個gpu和多台機器。
MxNet也提供了推薦系統相關的程式碼實現,主要有矩陣分解推薦演算法和DSSM(Deep Structured Semantic Model)深度學習推薦演算法兩類推薦演算法。讀者可以了解更多細節:
https://github.com/apache/incubator-mxnet/tree/master/example/recommenders
- 4.DeepLearning4j
DeepLearning4j(簡稱dl4j)是基於Java生態系統的深度學習框架,構建在Spark等大數據平台之上,可以無縫跟Spark等平台對接。基於Spark平台構建的技術體系可以非常容易跟dl4j應用整合。dl4j對深度學習模型進行了很好的封裝,可以方便地通過類似搭積木的方式輕鬆構建深度學習模型,構建的深度學習模型直接可以在Spark平台上運行。
不過官方沒有提供推薦系統相關的參考實現案例,目前dl4j處在1.0版本預發布階段。如果你的機器學習平台基於Hadoop/Spark生態體系,dl4j是一個不錯的嘗試方案,作者曾經使用過dl4j構建深度學習模型,確實是非常高效的,但是訓練過程可能會佔用很多系統資源(當時是直接跑在CPU之上),有可能會影響現在的其他機器學習任務,最好的方式是採用更好的資源隔離策略或者使用獨立的集群供dl4j使用,並使用GPU進行計算。
- 5.百度的PaddlePaddle
PaddlePaddle(飛槳)是百度開源的深度學習框架,也是中國做的最好的深度學習框架,整個框架體系做的比較完善。官方介紹飛槳同時支援動態圖和靜態圖,兼顧靈活性和高性能,源於實際業務淬鍊,提供應用效果領先的官方模型,源於產業實踐,輸出業界領先的超大規模並行深度學習平台能力。提供包括AutoDL、深度強化學習、語音、NLP、CV等各個方面的能力和模型庫。
在深度學習推薦演算法方面,飛槳提供了超過5類深度學習推薦演算法模型,包括Feed流推薦、DeepFM、sesssion-based推薦、RNN相關推薦、卷積神經網路推薦等,是很好的深度學習推薦系統學習材料,想詳細了解的讀者可以參考:
https://github.com/PaddlePaddle/models/tree/develop/PaddleRec
- 6.騰訊的Angel
Angel是騰訊跟北京大學聯合開發的基於參數伺服器模型的分散式機器學習平台,可以跟Spark無縫對接,主要聚焦於圖模型及推薦模型。最近(今年8月份)Angel發布了3.0版本,提供了更多新的特性,包括自動特徵工程、Spark on Angel中集成了特徵工程,可以無縫對接自動調參、整合了PyTorch(PyTorch on Angel),增強了Angel在深度學習方面的能力、自動超參調節、Angel Serving、支援Kubernetes運行等很多非常有實際工業使用價值的功能點。
在深度學習推薦系統方面,Angel支援包括DeepFM、Wide & Deep、DNN、NFM、PNN、DCN、AFM等多種深度學習推薦演算法。
https://github.com/Angel-ML/angel
由於Angel可以跟Spark無縫對接,是比較適合基於Spark平台構建的技術棧的,我們公司目前也在嘗試使用Angel進行部分推薦演算法的研究與業務落地。不過,Angel中很多深度學習模型(比如wide & deep)還是實現的很粗陋,使用範圍有一定限制,沒有怎麼經過大規模實際數據的驗證,文檔也非常不完整,使用過程中可能會有很多坑。
- 7.微軟開源的推薦演算法庫recommenders
微軟雲計算團隊和人工智慧開發團隊在今年2月份開源了一個推薦演算法庫,基於微軟的大型企業級客戶項目經驗及最新的學術研究成果,將搭建工業級推薦系統的業務流程和適用操作技巧總結提煉開源出來,對構建工業級推薦系統的5大流程:數據準備、模型構建、模型離線評估、模型選擇與調優、模型上線,進行整理與提煉,方便學習者熟悉關鍵點與技巧,幫我我們更好地學習推薦系統。並提供多種有價值的適合工業級應用的推薦演算法,包括xDeepFM、DKN、NCF、RBM、Wide and Deep等深度學習推薦演算法。因此,是一份難得的學習推薦系統工程實踐及工業級推薦演算法的學習材料,這些演算法基於Python開發,不依賴其他深度學習平台,直接可以在伺服器上運行(部分演算法依賴GPU、部分演算法依賴PySpark),細節讀者可以參考:
https://github.com/microsoft/recommenders
前面介紹了7個深度學習相關的平台及該平台包含的推薦演算法,可供讀者參考。另外,CNTK(微軟開源的)、Theano、gensim(我們公司在用,還不錯)等也是比較有名的深度學習平台,阿里也開源了x-deeplearning深度學習平台。
如果讀者是從零開始學習深度學習推薦演算法,建議可以從Tensorflow或者PyTorch開始入手,他們是生態最完善、最出名的深度學習平台。
如果讀者公司基於Hadoop/Spark平台來開發推薦演算法,可以研究一下Angel及DeepLearning4j,不過請慎重用於真實業務場景,畢竟它們生態不完善,文檔相對較少,由於用的人少,出了問題,搜索相關問題解決方案也比較困難。
五、深度學習技術應用於推薦系統的優缺點及挑戰
前面幾節對深度學習推薦系統相關知識進行了全面介紹,大家知道了深度學習應用於推薦系統的巨大價值,本節我們來梳理總結一下深度學習應用於推薦系統的優缺點及挑戰,讓大家對深度學習推薦系統的價值有一個更加全面、客觀、公正的了解。
- 優點
深度學習技術最近幾年的大火,在電腦視覺和語音識別中的巨大成功,真正體現出了深度學習的巨大價值。深度學習應用於推薦系統的優勢主要體現在如下幾個方面。
(1) 更加精準的推薦
深度學習模型具備非常強的表達能力,已經證明MLP深度學習網路可以擬合任意複雜的函數到任意精度(見參考文獻4)。因此,利用深度學習技術來構建推薦演算法模型,可以學習特徵之間深層的交互關係,可以達到比傳統矩陣分解、分解機等模型更精準的推薦效果。第三節中的部分工業級深度學習推薦系統案例已經很好驗證了這一點。
(2) 可以減少人工特徵工程的投入
傳統機器學習模型(比如logistic回歸等),需要花費大量的人力工作用於構建特徵、篩選特徵,最終才能構建一個效果較好的推薦模型。而深度學習模型只需要將原始數據通過簡單的向量化灌入模型,通過模型自動學習特徵,最終獲得具備良好表達能力的神經網路,因此,通過深度學習構建推薦演算法可以大大節省人工特徵工程的投入成本。
(3) 可以方便整合附加資訊(side information)
深度學習模型的可拓展性很強,可以非常方便地在模型中整合附加資訊(利用附加資訊的嵌入,或者利用CNN、RNN等網路結構從附加資訊中提取特徵),這在第三節中部分模型中已經有詳細介紹。有更多的數據整合進深度學習模型,可以讓模型獲得更多的資訊,最終預測結果會更加精確。
- 缺點與挑戰
深度學習應用於推薦系統,除了上面的優勢外,還存在一些問題,這些問題限制了深度學習在推薦系統中的大規模應用。具體表現在如下幾個方面:
(1) 需要大量的樣本數據來訓練可用的深度學習模型
深度學習是一類需要大量樣本數據的機器學習演算法。模型的層數多,表達能力強,決定了需要學習的參數多,因此需要大量的數據才可以訓練出一個能真正解決問題、精度達到一定要求的演算法。所以,對於用戶規模小的產品或者剛剛開發不久還沒有很多用戶的產品,深度學習演算法是不合適的。
(2) 需要大量的硬體資源進行訓練
深度學習演算法需要依賴大量數據進行訓練,因此也是一類計算敏感型技術,要想訓練一個深度學習模型,需要足夠的硬體資源(一般是GPU伺服器)來計算,否則資源不足會導致訓練時間過長,無法真正應用,甚至無法進行訓練。一般GPU是比較貴的,所以對企業的資金提出了更高的要求。
(3) 對技術要求相對較高,人才比較緊缺
由於深度學習是最近幾年才流行起來的技術,深度學習相關技術相比傳統機器學習演算法,會更加複雜,對相關演算法人員要求更高。目前這方面的人才明顯非常緊缺。因此,團隊在落地深度學習演算法應用於推薦中,是否有相應的人才可以實踐、解決深度學習相關問題也是面臨的重要挑戰。
(4) 跟團隊現有的軟體架構適配,工程實現有一定難度
經過前面介紹,考慮應用深度學習技術的公司或者團隊,一定會負責著有足夠用戶規模的產品線,並且有足夠硬體、人力資源來應付,這樣的團隊一般是較成熟的團隊。經過幾年發展,團隊中肯定有各類演算法組件,特別是大數據相關技術與平台。在引進深度學習過程中,怎麼將深度學習相關技術組件跟團隊現有的架構和組件有機整合起來(深度學習平台可能需要大數據平台提供用於建模的數據分析處理、特徵工程等),也是團隊面臨的重要問題。一般需要團隊開發相關工具或者組件,打通現有的技術架構和深度學習技術架構之間的壁壘,讓兩者高效地融合起來,一起更好地服務於推薦業務。
(5) 深度學習模型可解釋性不強
深度學習模型基本是一個黑盒模型,通過數據灌入,學習輸入與輸出之間的內在聯繫,具體輸入是怎麼決定輸出的,我們一無所知,導致我們很難解釋清楚深度學習推薦系統為什麼給用戶推薦這個。給用戶提供有價值的推薦解釋,往往是很重要的,能夠加深用戶對產品的理解和信賴,提升用戶體驗。現在部分基於注意力機制的深度學習模型,具備一定的可解釋性,這塊也是未來一個值得研究和探索的方向。
(6) 調參過程冗長複雜
深度學習模型包含大量的參數及超參,訓練深度學習是一個複雜的過程,需要選擇隨機梯度下降演算法,並且在訓練過程中需要跟進觀察參數的變化情況,對模型的訓練過程進行跟蹤,並實時調整。調參是需要大量的實踐經驗積累的。
幸好,目前像Tensorflow等提供了可視化的工具(TensorBoard)方便模型訓練人員進行跟蹤。更好的消息是,有很多學術和工程研究在嘗試怎麼讓調參的過程盡量自動化,目前很多學者及大公司也在大力發展自動超參調節(AutoML)相關技術,讓參數調節更加簡單容易。
參考文獻41中,Google的研究者們提出了NIS技術(Neural Input Search),可以自動學習大規模深度推薦模型中每個類別特徵最優化的詞典大小以及嵌入向量維度大小。目的就是為了在節省性能的同時儘可能地最大化深度模型的效果。並且,他們發現傳統的Single-size Embedding方式(所有特徵值共享同樣的嵌入向量維度)其實並不能夠讓模型充分學習訓練數據。因此與之對應地,提出了Multi-size Embedding方式讓不同的特徵值可以擁有不同的嵌入向量維度。
在實際訓練中,他們使用強化學習來尋找每個特徵值最優化的詞典大小和嵌入向量維度。通過在兩大大規模推薦問題(檢索、排序)上的實驗驗證,NIS技術能夠自動學習到更優化的特徵詞典大小和嵌入維度並且帶來在Recall@1以及AUC等指標上的顯著提升。
六、深度學習推薦系統工程實施建議
前面對深度學習應用於推薦系統的相關演算法、優缺點等進行了比較全面的介紹。從第三節的案例介紹,我們知道深度學習使用得好是可以為推薦業務帶來巨大價值的,那麼是否一定需要在我們自己的推薦業務中引入深度學習演算法呢?如果考慮引入,該怎麼更好地跟現有的平台及業務對接呢? 需要注意哪些點呢?這些問題是我們在本節需要重點探討的問題。
- 深度學習的效果真的有那麼好嗎?
從第二節的案例介紹,確實給了我們很大的信心,相信引入深度學習技術一定會大大提升推薦業務的點擊率,從而提升用戶體驗,為公司創造業務價值。但是深度學習要做好,還是非常有難度的,甚至可以說,設計好的深度學習演算法是一門藝術而不僅僅是技術。參考文獻43對當前深度學習的效果進行了質疑,很多深度學習效果可能還不如常規演算法來得好(其中第三節4中的NCF模型也被該作者diss了)。因此,我們在是否選擇深度學習技術時一定要慎重,要有效果可能不一定如意的心裡準備和預期。
- 團隊是否合適引入深度學習推薦技術
我們除了要顧慮深度學習帶來的推薦效果外,我們還需要關注自己團隊是否合適引入深度學習技術。總體來說,我們必須要考慮如下幾個問題:
(1) 產品所在階段及產品定位
如果是新開發的產品或者產品定位只服務於非常有限的用戶群體,這樣的產品或者階段肯定是不適合深度學習技術的,因為深度學習需要大量的訓練數據來保證模型可訓練及模型的精度。
(2) 是否有相關技術人員
深度學習是一類新的發展中的技術,技術要求比一般機器學習應用要高,這方面的人才相對稀缺,團隊目前是否有相關人才,是否有學習能力強、短期可以試用深度學習技術的人才,以及是否可以招聘到(給到足夠高的工資)這方面的人才都是需要考慮的不穩定因素。
(3) 深度學習相關硬體資源
深度學習對硬體要求較高,團隊是否有現成的硬體支撐深度學習平台搭建,是否可以有足夠的資金支援購買深度學習相關硬體,能否承受購買代來的短期成本投入,都是團隊面臨的問題。
(4) 其他的沉默成本
深度學習推薦系統的模型訓練周期長,需要調整很多超參數,因此選擇合適的模型周期長,需要跟現有的技術架構打通,需要對可能出現的任何問題排查等等。這些可能都是沉默成本,我們必須要有心理預期。
- 怎麼打通深度技術相關技術棧與團隊現有技術棧之間的脈絡
如果通過2的思考,你覺得有必要在你們團隊引入深度學習推薦技術,那怎麼將深度學習相關技術棧跟團隊現有技術棧打通呢?
想必大部分團隊會技術Hadoop/Spark技術構建大數據與演算法平台,那麼怎麼將深度學習技術跟Hadoop生態打通就是擺在你面前急需解決的問題。
如果你嘗試選擇Angel、DeepLearning4j,就不存在這些問題,因為他們天生就是支援在Spark平台上運行的,只不過這兩個項目還不夠成熟,穩定性有待提高,在團隊中嘗試使用肯定會遇到很多坑,出了問題也沒有很好的資源進行排查解決,主要得靠自己。
如果你選擇Tensorflow、PyTorch等主流深度學習平台,因為它們都是基於Python體系的,將Hadoop生態與它們打通就是非常有必要的。一般會用Spark做數據處理、特徵構建、推斷等工作,利用Tensorflow、PyTorch訓練深度學習模型。那麼將兩者打通的可行方案有如下兩個:
(1) 將Tensorflow、PyTorch訓練好的模型上傳到Spark平台,開發基於Java的模型解析工具,讓Spark可以解析Tensorflow、PyTorch構建的深度學習模型,並最終進行預測;
(2) Tensorflow、PyTorch訓練好深度學習模型後,直接用Tensorflow Servering(PyTorch沒有官方提供的Servering,但是可以利用Flask等python web框架自己搭建)部署好深度學習模型,在Spark側做推斷時,通過調用Servering的介面來為每個用戶做推薦。
- 從經典成熟的模型、從跟公司業務接近的模型開始嘗試
如果我們考慮引入深度學習模型,我們可以考慮前面提到的一些經典的、在大公司海量數據場景下經過AB測試驗證過有巨大商業價值的模型開始嘗試,最好選擇跟本公司業務類似的模型,比如你們公司是做影片的,那麼選擇YouTube的深度學習模型可能是一個好的選擇。通過引入這些成熟模型並結合本公司的業務場景及數據情況進行裁剪調優,會更容易產生商業價值,可能付出的代價會更小,整個引入過程也會更加可控。
前面講完了引入深度學習需要考慮的工程問題,希望可以幫助讀者更好地做決策。深度學習不是銀彈,所以在考慮深度學習技術時,一定要慎重,不要被業界利好的消息所蒙蔽,我相信即使像Google這類有技術、有人才、有資源的公司,在將深度學習引入併產生商業價值的過程中,肯定是掉了很多坑的,他們論文發出來肯定是介紹美好的一面,走了多少彎路,付出了多少代價我們就不得而知了。
對於小團隊,作者強烈建議可以先用簡單的推薦模型(如矩陣分解、基於內容的推薦等)將推薦業務跑起來,將產品中需要用到推薦的所有業務場景都做完,將整個推薦流程做得更加易用、模組化,讓推薦迭代更加方便容易,同時對AB測試、推薦指標體系、推薦監控等體系要先做好。如果這些都做的比較完善了,並且有剩餘的人力資源,是可以投入一定的人力去研究、實踐深度學習技術的。否則,還是建議不要嘗試了。
七、深度學習推薦系統的未來發展
從2016年AlphaGo戰勝李世石開始,深度學習驅動了第三次人工智慧浪潮的到來。幾年時間內,深度學習風靡全球,幾乎所有的科技公司都希望將深度學習引入到真實業務場景中,期望藉助深度學習產生巨大的商業價值。深度學習的引入確實讓電腦視覺、語音識別、自然語言處理等領域有非常大的突破,在很多方面甚至超越了人類專家的水平,在推薦系統中的價值也逐漸凸顯出來。
我相信深度學習相關技術未來會給推薦系統帶來巨大的改變和革新,現在只是前奏。在本節作者就基於自己最近幾年的所知、所學、所思,對深度學習在推薦系統中的未來發展做一些預測,希望可以給讀者提供一些新的視角,更好地預見深度學習未來巨大價值的爆發,提前做好準備。具體來說,我會從如下5個維度來講解。
- 1. 演算法模型維度
目前的深度學習應用於推薦還只是包含2-3層隱含層的較淺層的深度學習模型,跟CNN等動輒上百層的模型還不在一個量級,目前應用於推薦的深度學習模型為什麼沒有朝深層發展,還需要有更多這方面的研究與實踐。
另外,目前應用於推薦的深度學習模型五花八門,基本是參考照搬在其他領域非常成功的模型,還沒有一個為推薦系統量身訂製的非常適合推薦業務的網路結構出現(比如電腦視覺中的CNN網路結構,語音識別中的RNN網路結構),我相信在這一方向上不久的將來一定會有突破,應該會出現一個適合推薦系統的獨有網路架構,給推薦系統帶來深遠影響。
未來的產品形態一定是朝著實時化方向發展,通過資訊流推薦的方式更好地滿足用戶的需求變化。這要求我們可以非常方便地將用戶的實時興趣整合到模型中,如果我們能夠對已有的深度學習推薦模型進行增量優化調整,反應用戶興趣變化,就可以更好更快地服務於用戶。可以進行增量學習的深度學習模型應該是未來一個有商業價值的研究課題。同時,隨身攜帶的智慧產品(手機、智慧手錶、智慧眼鏡等)會越來越多,如果我們要在這些跟隨身體運動的智慧產品上做推薦的話,一定需要結合當前的場景實時感知用戶的位置、狀態等的變化做到實時調整、動態變化。而強化學習是解決這類跟外界環境實時交互的一種有效機器學習範式,或許結合深度強化學習技術,這方面可以提供用戶體驗非常好的推薦解決方案,這也是未來一個非常火的領域,目前也有少量這方面的應用案例。
任何一種模型都不是萬能的,因此深度學習模型怎麼跟傳統的機器學習模型更好地融合來提供更好的推薦服務,也是非常值得研究的一個方向。
- 2. 工程維度
當前深度學習做分散式訓練還比較困難,也沒有很好地跟大數據平台打通,基本都是大公司花很多工程人員自己提供深度學習分散式解決方案及跟已有大數據平台對接。雖有很多將深度學習跟大數據結合的開源項目(比如雅虎的CaffeOnSpark,intel的bigDL、以及前面講的DeepLearning4j、Angel等),但是還不夠成熟,社區不夠壯大,遇到問題也可能會比較麻煩,不易解決。 。
要想讓深度學習在工業界產生巨大價值,深度學習技術需要做到高效、便捷、可拓展,怎麼跟現有的大數據平台更好地打通,做到無縫對接,對深度學習在推薦上更好地應用非常重要。亦或是深度學習平台通過自身發展具備處理大數據的能力。不管是哪種方式,做到跟大數據處理能力打通是必要的。
大數據和AI是無法割裂開來的,因此未來一定會有成熟的開源方案出現,可以方便整合大數據與深度學習相關的能力點,讓數據的處理、分析、建模更加流暢便捷。
- 3. 應用場景維度
目前深度學習的應用場景還比較單一,基本是對同一類場景的標的物的推薦(比如影片、電商商品),未來的產品(APP)一定會提供整體的大而全的解決方案(比如現在的微信、美團就是綜合服務平台),那麼怎麼在這些差異非常大的多場景中為用戶統一推薦各類產品與服務就是一個非常大的挑戰,深度學習是否可以在這類場景中發揮巨大價值,還需要更多的研究與實踐。在跨場景下結合知識圖譜與遷移學習,或許可以幫助深度學習演算法取得更大的成功。
隨著5G及物聯網的發展,不久的將來,像家庭、車載等新場景會變得越來越重要,這類場景用戶的交互方式會產生變化,我們可能更多地是從語音獲取用戶的回饋資訊,在這類場景中,將語音等資訊整合到深度學習模型中,做基於語音交互的推薦解決方案一定是一個比較有前景的方向。另外,VR/AR的發展,也可能促進視覺交互(如手勢交互)的成熟,通過神經網路處理視覺資訊,從而構建有效的推薦模型也是未來的一個重要方向。深度學習已經在電腦視覺、語音識別、自然語言處理中獲得了極大的成功,我相信在這些以語音、語言、視覺交互為主的新型產品中,深度學習必有用武之地。
- 4. 數據維度
目前的深度學習推薦模型還主要是使用單一的數據源(用戶行為數據、用戶標的物metadata數據)來構建深度學習模型。未來隨著5G技術的發展、各類感測器的普及,我們會更容易收集到多源的數據,怎麼充分有效地利用這些異構資訊網路(Heterogeneous Information Network,簡寫為HIN)的數據,構建一個融合多類別數據的深度學習推薦模型,是一個必須面對的有意思的並且極有挑戰的研究方向。在前面講的在新的未開發的應用場景中一定也會產生非常多種類的新數據類型(比如嗅覺的數據)需要深度學習來處理。
隨著安全意識的崛起及相關法律的規範化,未來對數據的收集形式及數量也可能會有變化和限制,深度學習這種強烈依賴數據的演算法是否能夠適應這種未來數據更加謹慎規範化的時代的發展,也是面臨的問題。怎麼在有限數據下、在保證用戶隱私情況下,應用深度學習技術也是值得研究的課題。
當前深度學習技術一般適合回歸、預測等監督學習任務,需要依賴大量的標註數據進行訓練,這限制了深度學習的應用場景,怎麼改造、進化深度學習模型,讓它可以處理少量標註數據,也是一個有前景、有需求的方向。強化學習、半監督學習在處理無監督學習上有天然優勢,或許深度學習跟這些技術的結合是一個好的方向。
- 5. 產品呈現與交互維度
目前的深度學習模型基本是一個黑盒模型,我們只有通過部署到線上經過AB測試觀察指標變化,進而評價模型的效果好壞,無法給出為什麼這樣推薦的原因。而給用戶一個明顯的、用戶可以理解和接受的推薦原因是大大有益於用戶信任建立的。好的推薦解釋可以提升用戶的產品體驗,這方面肯定是未來的一個研究熱點。
好的推薦產品除了推薦精準的物品外,給用戶的視覺呈現方式、視覺效果、交互方式等都對用戶是否願意使用、是否認同推薦都非常重要。未來的深度學習推薦技術可能會結合用戶的點擊率、用戶對標的物的視覺感受度(可以通過視覺感測器獲取)、甚至心情(可以通過視覺或者聲音識別出)、用戶的使用流暢度(可以通過用戶的操作,如觸屏點擊獲得)等多維度的目標進行建模,更好地提升推薦產品的用戶體驗。
總結
本文對深度學習技術、深度學習應用於推薦系統的一般方法和思路、幾個重要的工業級深度學習推薦系統、開源深度學習平台及推薦演算法、深度學習推薦演算法的優缺點與挑戰、深度學習推薦系統工程落地建議以及深度學習推薦系統的未來發展等幾個方面進行了比較全面的介紹。
本文更多地是從工業實踐的角度來講解深度學習推薦系統,特別是第三節中講解的幾個核心深度學習推薦演算法、第五節的優缺點與挑戰和第六節的工程實施建議,值得大家好好學習,希望可以給大家提供深度學習在推薦業務落地上的參考與借鑒。
深度學習在推薦系統中的應用是最近幾年的事情,雖然成功案例頗多,但是還不算完善,遠沒有達到成熟的地步。也沒有形成完善的理論體系,更多地是借鑒深度學習在影像、語音識別等領域的成功經驗,將模型稍作修改遷移過來,目前並未找到一種專為推薦系統量身訂製的深度學習模型,這方面未來還有很大的發展空間。
推薦系統作為機器學習中一個相對完善的子領域,它在實際業務中有重大商業價值,越來越個性化也是用戶發展的需要和社會發展趨勢。我相信,對極致用戶體驗的追求,對商業價值的挖掘,這兩個原因一定會推動學術界、產業界的專家在深度學習推薦系統上進行更多的的探索與實踐,未來深度學習相關技術一定會在推薦系統中產生更大的價值!讓我們拭目以待!
參考文獻
- [1943] A Logical Calculus of Ideas Immanent in Nervous Activity
- [2017] On the Origin of Deep Learning
- [1986] Learning Representations by Back-Propagating
- [1989] Multilayer feedforward networks are universal approximators
- [深度學習-綜述文章 2019] Deep Learning based Recommender System- A Survey and New Perspectives
- [2007] Restricted Boltzmann Machines for Collaborative Filtering
- [YouTube 2016] Deep Neural Networks for YouTube Recommendations
- [Google 2016] Wide & Deep Learning for Recommender Systems
- Deep content-based musicrecommendation
- Improving Content-based and Hybrid Music Recommendation using Deep Learning
- [2017 阿里] Deep Interest Network for Click-Through Rate Prediction
- [2018 阿里] Deep Interest Evolution Network for Click-Through Rate Prediction
- [2019 阿里] Behavior Sequence Transformer for E-commerce Recommendation in Alibaba
- [2019 阿里] Deep Session Interest Network for Click-Through Rate Prediction
- [2019 阿里] Multi-Interest Network with Dynamic Routing for Recommendation at Tmall
- [2018 阿里] Learning Tree-based Deep Model for Recommender Systems
- [網易] Personal Recommendation Using Deep Recurrent Neural Networks in NetEase
- [2019 facebook] Deep Learning Recommendation Model for Personalization and Recommendation Systems
- [2017 Google] Neural Collaborative Filtering
- [2019 騰訊] Real-time Attention Based Look-alike Model for Recommender System
- [2018 Airbnb] Applying Deep Learning To Airbnb Search
- A Multi-View Deep Learning Approach for Cross Domain User Modeling in Recommendation Systems
- [2015] Collaborative Deep Learning for Recommender Systems
- [2015] Deep Collaborative Filtering via Marginalized Denoising Auto-encoder
- [2016] A Neural Autoregressive Approach to Collaborative Filtering
- [2016] Deep Learning over Multi-field Categorical Data – A Case Study on User Response Prediction
- [2017 華為諾亞實驗室] DeepFM- A Factorization-Machine based Neural Network for CTR Prediction
- [2017 攜程] A Hybrid Collaborative Filtering Model with Deep Structure for Recommender Systems
- [2018] DKN- Deep Knowledge-Aware Network for News Recommendation
- DeepPlaylist- Using Recurrent Neural Networks to Predict Song Similarity
- The application of Deep Learning in Collaborative Filtering
- [2016] Improved Recurrent Neural Networks for Session-based Recommendations
- [2016] Session-based Recommendations with Recurrent Neural Networks
- [2017] Contextual Sequence Modeling for Recommendation with Recurrent Neural Networks
- [2017] Improving Session Recommendation with Recurrent Neural Networks by Exploiting Dwell Time
- [2017] Inter-Session Modeling for Session-Based Recommendation
- [2017] Personalizing Session-based Recommendations with Hierarchical Recurrent Neural Networks
- [2017] Recurrent Latent Variable Networks for Session-BasedRecommendation
- [2017] Recurrent Neural Networks with Top-k Gains for Session-based Recommendations
- Collaborative Memory Network for Recommendation Systems
- [2019 Google] Neural Input Search for Large Scale Recommendation Models
- [2018 Google] Efficient Neural Architecture Search via Parameters Sharing
- [2019] Are We Really Making Much Progress? A Worrying Analysis of Recent Neural Recommendation Approaches
- [2017] Attention is all you need
- [2018] Bert: Pre-training of deep bidirectional transformers for language understanding
- [2018 京東] Deep Reinforcement Learning for List-wise Recommendations
- [2019] TF-Ranking- Scalable TensorFlow Library for Learning-to-Rank
- [2018 Pinterest] Graph Convolutional Neural Networks for Web-Scale Recommender Systems
(*本文為 AI科技大本營投稿文章,請聯繫作者)

