Android開發高手課NOTE
- 2019 年 11 月 1 日
- 筆記
最近學習了極客時間的《Android開發高手課》很有收穫,記錄總結一下。
歡迎學習老師的專欄:Android開發高手課
記憶體優化
卡頓的原因
頻繁 GC 造成卡頓、物理記憶體不足時系統會觸發 low memory killer 機制,系統負載過高是造成卡頓的倆個原因。
除了頻繁 GC 造成卡頓之外,物理記憶體不足時系統會觸發 low memory killer 機制,系統負載過高是造成卡頓的另外一個原因。「用時分配,及時釋放」
Android 3.0~Android 7.0 將 Bitmap 對象和像素數據統一放到 Java 堆中,這樣就算我們不調用 recycle,Bitmap 記憶體也會隨著對象一起被回收。不過 Bitmap 是記憶體消耗的大戶,把它的記憶體放到 Java 堆中似乎不是那麼美妙。即使是最新的華為 Mate 20,最大的 Java 堆限制也才到 512MB,可能我的物理記憶體還有 5GB,但是應用還是會因為 Java 堆記憶體不足導致 OOM。Bitmap 放到 Java 堆的另外一個問題會引起大量的 GC,對系統記憶體也沒有完全利用起來。
將 Bitmap 記憶體放到 Native 中,也可以做到和對象一起快速釋放,同時 GC 的時候也能考慮這些記憶體防止被濫用。NativeAllocationRegistry 可以一次滿足你這三個要求,Android 8.0 正是使用這個輔助回收 Native 記憶體的機制,來實現像素數據放到 Native 記憶體中。Android 8.0 還新增了硬體點陣圖 Hardware Bitmap,它可以減少圖片記憶體並提升繪製效率。
// 步驟一:申請一張空的 Native Bitmap Bitmap nativeBitmap = nativeCreateBitmap(dstWidth, dstHeight, nativeConfig, 22); // 步驟二:申請一張普通的 Java Bitmap Bitmap srcBitmap = BitmapFactory.decodeResource(res, id); // 步驟三:使用 Java Bitmap 將內容繪製到 Native Bitmap 中 mNativeCanvas.setBitmap(nativeBitmap); mNativeCanvas.drawBitmap(srcBitmap, mSrcRect, mDstRect, mPaint); // 步驟四:釋放 Java Bitmap 記憶體 srcBitmap.recycle(); srcBitmap = null; sampling模式和instrumentation模式的區別
兩者的區別:
- 在sampling模式中,profiler以固定的間隔對運行中的程式進行取樣,根據取樣結果統計出程式中各個部分的開銷。
- 在instrumentation模式中,profiler對運行中的程式所執行的每一個指令都進行記錄,最後根據這份記錄生成程式中各個部分的開銷。
在實際使用中:
- sampling模式速度快,記錄產生的數據量小,但是統計結果並不十分精確,適合於對程式全局性能進行初步的分析,找出程式瓶頸大致的「區間」。
- instrumentation模式能精確記錄程式各個部分的開銷,但是速度慢,記錄產生的數據量大,適合於對程式局部進行精細分析,精確定位瓶頸位置。
捕獲堆轉儲
使用:點擊 Dump Java heap
堆轉儲顯示在您捕獲堆轉儲時您的應用中哪些對象正在使用記憶體。 特別是在長時間的用戶會話後,堆轉儲會顯示您認為不應再位於記憶體中卻仍在記憶體中的對象,從而幫助識別記憶體泄漏。 在捕獲堆轉儲後,您可以查看以下資訊:
- 您的應用已分配哪些類型的對象,以及每個類型分配多少。、
- 每個對象正在使用多少記憶體。
- 在程式碼中的何處仍在引用每個對象。
- 對象所分配到的調用堆棧(目前,如果您在記錄分配時捕獲堆轉儲,則只有在 Android 7.1 及更低版本中,堆轉儲才能使用調用堆棧)
在您的堆轉儲中,請注意由下列任意情況引起的記憶體泄漏:
- 長時間引用 Activity、Context、View、Drawable 和其他對象,可能會保持對 Activity 或 Context 容器的引用。
- 可以保持 Activity 實例的非靜態內部類,如 Runnable。
- 對象保持時間超出所需時間的快取。

分析記憶體的技巧
使用 Memory Profiler 時,您應對應用程式碼施加壓力並嘗試強制記憶體泄漏。 在應用中引發記憶體泄漏的一種方式是,先讓其運行一段時間,然後再檢查堆。 泄漏在堆中可能逐漸匯聚到分配頂部。 不過,泄漏越小,您越需要運行更長時間的應用才能看到泄漏。
您還可以通過以下方式之一觸發記憶體泄漏:
- 將設備從縱向旋轉為橫向,然後在不同的 Activity 狀態下反覆操作多次。 旋轉設備經常會導致應用泄漏 Activity、Context 或 View 對象,因為系統會重新創建 Activity,而如果您的應用在其他地方保持對這些對象之一的引用,系統將無法對其進行垃圾回收。
- 處於不同的 Activity 狀態時,在您的應用與另一個應用之間切換(導航到主螢幕,然後返回到您的應用)。
ANR
- 我的經驗是,先看看主執行緒的堆棧,是否是因為鎖等待導致。接著看看 ANR 日誌中 iowait、CPU、GC、system server 等資訊,進一步確定是 I/O 問題,或是 CPU 競爭問題,還是由於大量 GC 導致卡死.從 Logcat 中我們可以看到當時系統的一些行為跟手機的狀態,例如出現 ANR 時,會有「am_anr」;App 被殺時,會有「am_kill」。
- 查找共性,機型、系統、ROM、廠商、ABI,這些採集到的系統資訊都可以作為維度聚合,在文中我提到 Hprof 文件裁剪和重複圖片監控,這是很多應用目前都沒有做的,而這兩個功能也是微信的 APM 框架 Matrix 中記憶體監控的一部分。Matrix 是我一年多前在微信負責的最後一個項目,也付出了不少心血,最近聽說終於準備開源了。那今天我們就先來練練手,嘗試使用 HAHA 庫快速判斷記憶體中是否存在重複的圖片,並且將這些重複圖片的 PNG、堆棧等資訊輸出
SharedPreferences的問題
- 跨進程不安全。SharedPreferences 在跨進程頻繁讀寫有可能導致數據全部丟失。根據線上統計,SP 大約會有萬分之一的損壞率。
- 載入緩慢。SharedPreferences 文件的載入使用了非同步執行緒,而且載入執行緒並沒有設置執行緒優先順序,如果這個時候主執行緒讀取數據就需要等待文件載入執行緒的結束。
這就導致出現主執行緒等待低優先順序執行緒鎖的問題,比如一個 100KB 的 SP 文件讀取等待時間大約需要 50~100ms,我建議提前用非同步執行緒預載入啟動過程用到的 SP 文件。 - 全量寫入。無論是調用 commit() 還是 apply(),即使我們只改動其中的一個條目,都會把整個內容全部寫到文件。而且即使我們多次寫入同一個文件,SP 也沒有將多次修改合併為一次,這也是性能差的重要原因之一。
- 卡頓。由於提供了非同步落盤的 apply 機制,在崩潰或者其他一些異常情況可能會導致數據丟失。所以當應用收到系統廣播,或者被調用 onPause 等一些時機,系統會強制把所有的 SharedPreferences 對象數據落地到磁碟。如果沒有落地完成,這時候主執行緒會被一直阻塞。
使用mmkv

mmap將一個文件或者其它對象映射進記憶體。(linux上的東西)
常規文件操作需要從磁碟到頁快取再到用戶主存的兩次數據拷貝。(從磁碟拷貝到頁快取中,由於頁快取處在內核空間,不能被用戶進程直接定址,所以還需要將頁快取中數據頁再次拷貝到記憶體對應的用戶空間中)
而mmap操控文件,只需要從磁碟到用戶主存的一次數據拷貝過程。說白了,mmap的關鍵點是實現了用戶空間和內核空間的數據直接交互而省去了空間不同數據不通的繁瑣過程。因此mmap效率更高。
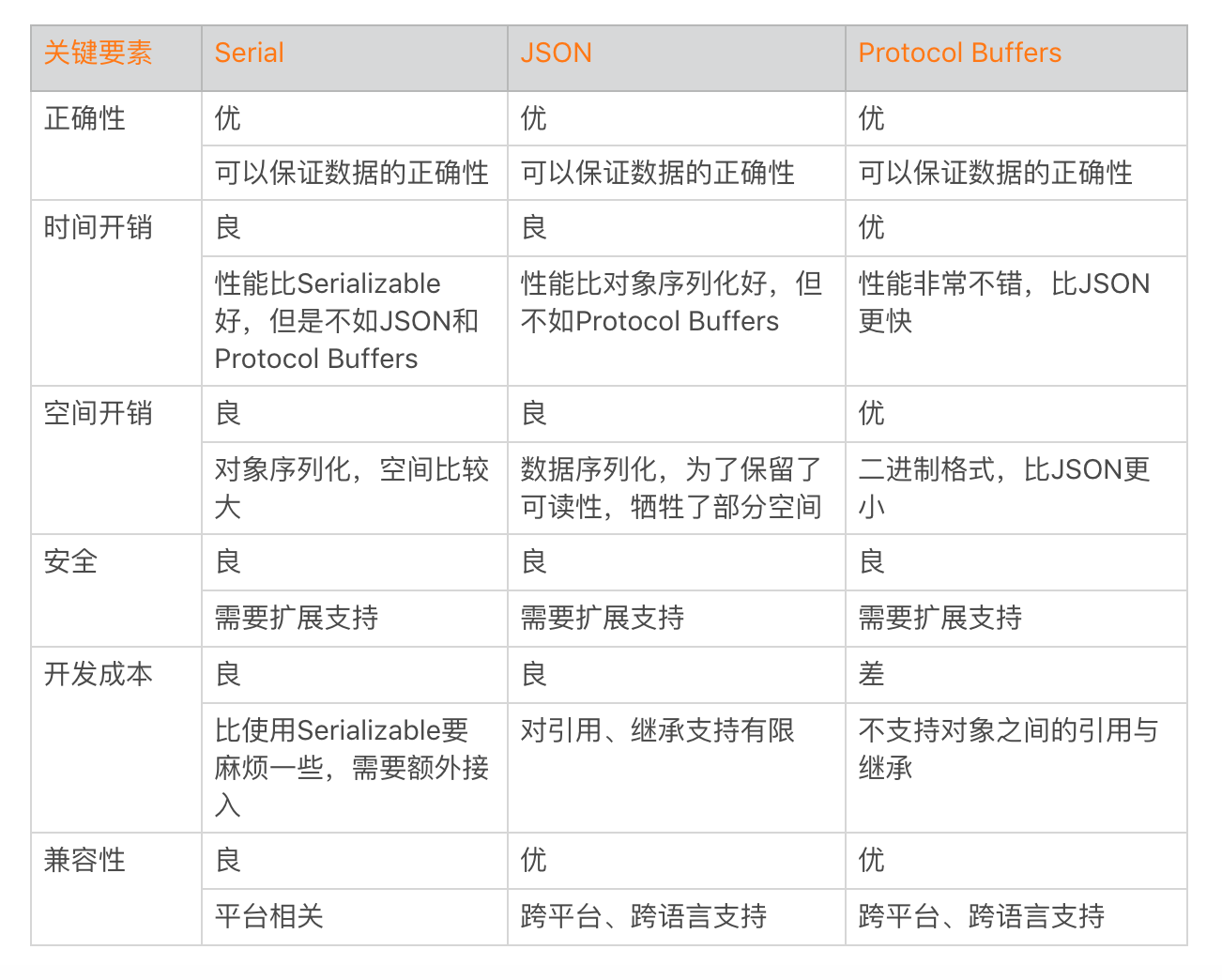
Serializable
- 整個序列化過程使用了大量的反射和臨時變數,而且在序列化對象的時候,不僅會序列化當前對象本身,還需要遞歸序列化對象引用的其他對象。
- 整個過程計算非常複雜,而且因為存在大量反射和 GC 的影響,序列化的性能會比較差。另外一方面因為序列化文件需要包含的資訊非常多,導致它的大小比 Class 文件本身還要大很多,這樣又會導致 I/O 讀寫上的性能問題
- Parcel 序列化和 Java 的 Serializable 序列化差別還是比較大的,Parcelable 只會在記憶體中進行序列化操作,並不會將數據存儲到磁碟里。通過取巧的方法可以實現 Parcelable 的永久存儲,但是它也存在兩個問題。
Serial的優點
- 相比起傳統的反射序列化方案更加高效(沒有使用反射)
- 性能相比傳統方案提升了3倍 (序列化的速度提升了5倍,反序列化提升了2.5倍)
- 序列化生成的數據量(byte[])大約是之前的1/5
- 開發者對於序列化過程的控制較強,可定義哪些object、field需要被序列化
- 有很強的debug能力,可以調試序列化的過程(詳見:調試)
數據的序列化
Serial 性能看起來還不錯,但是對象的序列化要記錄的資訊還是比較多,在操作比較頻繁的時候,對應用的影響還是不少的,這個時候我們可以選擇使用數據的序列化。
json:原生、gosn、fastjson(數據量大了的時候最快)
文件遍歷在 API level 26 之後建議使用FileVisitor,替代 ListFiles,整體的性能會好很多。
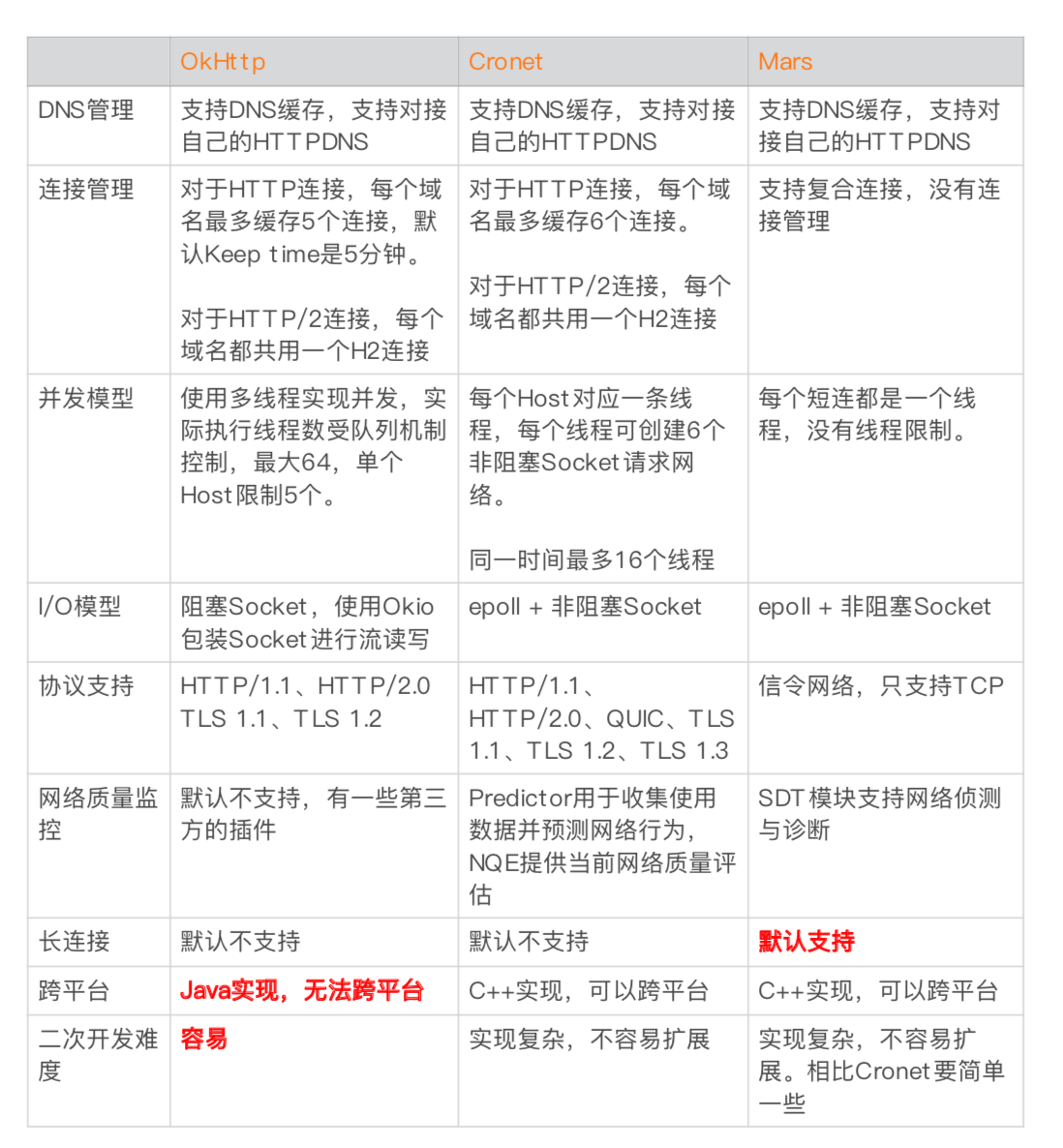
Mars的好處就是跨平台、長鏈接,看情況
網路數據壓縮

電量
-
Android 是基於 Linux 內核,而 Linux 大部分使用在伺服器中,它對功耗並沒有做非常嚴格苛刻的優化。特別是中國會有各種各樣的「保活黑科技」,大量的應用在後台活動簡直就是「電量黑洞」。
-
耗電量這塊, 因為要維持推送的實時到達, 只能追求黑科技, 要不然人家就會問,為啥蘋果可以收到推送,android就不行~ 但是保活就會加大耗電
-
耗電優化的第一個方向是優化應用的後台耗電。因為用戶最容易感知這個,我明明沒有怎麼打開,為什麼耗這麼多?在後台不要做這些:長時間獲取 WakeLock(及時釋放)、WiFi 和藍牙的掃描、GPS、video、audio
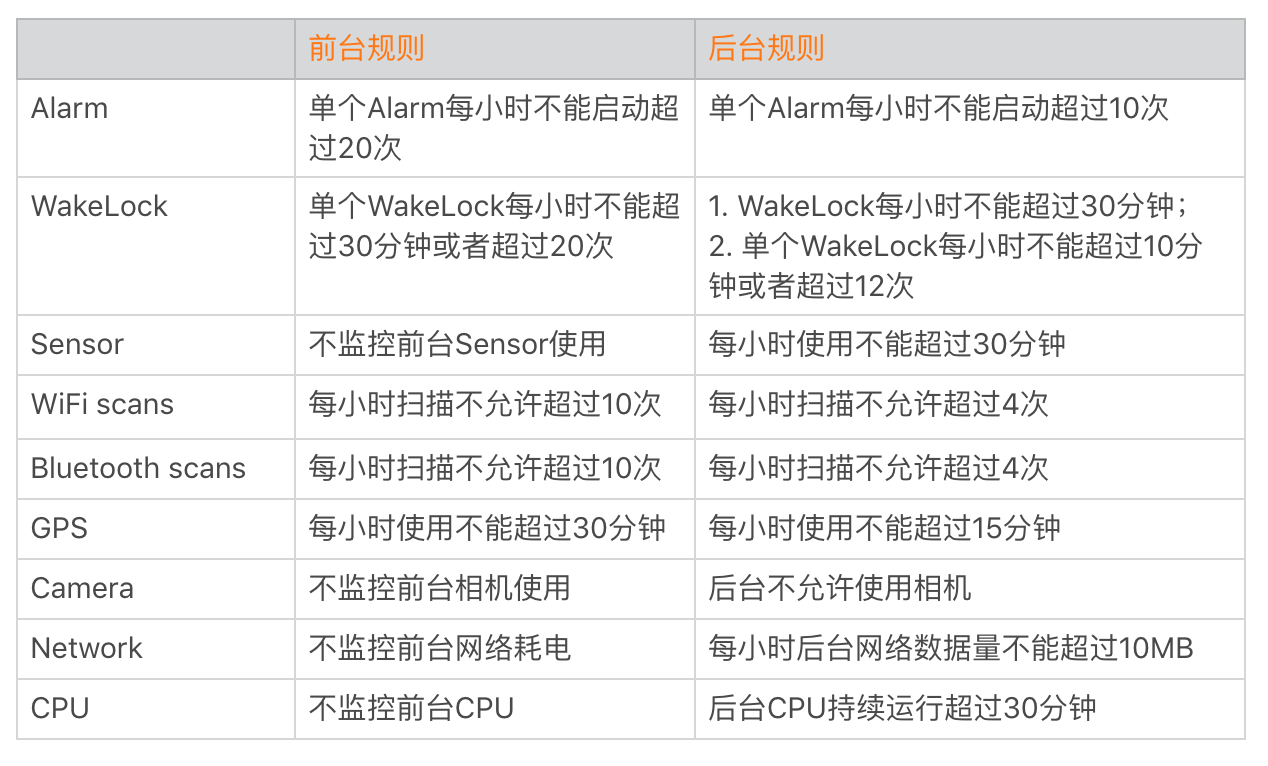
WakeLock 用來阻止 CPU、螢幕甚至是鍵盤的休眠。類似 Alarm、JobService 也會申請 WakeLock 來完成後台 CPU 操作.
Alarm 用來做一些定時的重複任務
通過 Hook,我們可以在申請資源的時候將堆棧資訊保存起來。當我們觸發某個規則上報問題的時候,可以將收集到的堆棧資訊、電池是否充電、CPU 資訊、應用前後台時間等輔助資訊也一起帶上。
UI優化

autosize是頭條方案,通過反射修改系統的density值
對於硬體繪製,我們通過調用 OpenGL ES 介面利用 GPU 完成繪製。opengl是一個跨平台的圖形 API,它為 2D/3D 圖形處理硬體指定了標準軟體介面。而 OpenGL ES 是 OpenGL 的子集,專為嵌入式設備設計。
使用 XML 進行 UI 編寫可以說是十分方便,可以在 Android Studio 中實時預覽到介面。如果我們要對一個介面進行極致優化,就可以使用程式碼進行編寫介面。
xml缺點
讀取xml很耗時
遞歸解析xml較耗時
反射生成對象的耗時是new的3倍以上
x2c:在編譯的時候,通過註解的方式,將xml轉換成Java程式碼

利用卡頓優化中的traceview或者systrace定位是最高效的
measure/layout 優化
- 減少布局的嵌套(viewstub、merge、include)
- 盡量不使用 RelativeLayout 或者基於 weighted LinearLayout,它們 layout 的開銷非常巨大。這裡我推薦使用 ConstraintLayout (約束布局,只有一個層級)替代 RelativeLayout 或者 weighted LinearLayout。
- 減少多餘的background
- PrecomputedText(研究下),非同步的textview。
Litho (研究下)如我前面提到的 PrecomputedText 一樣,把 measure 和 layout 都放到了後台執行緒,只留下了必須要在主執行緒完成的 draw,這大大降低了 UI 執行緒的負載。
如果你沒有計劃完全遷移到 Litho,我建議可以優先使用 Litho 中的 RecyclerCollectionComponent 和 Sections 來優化自己的 RecyelerView 的性能。
減少apk體積
- Android Studio 3.0 推出了新 Dex 編譯器 D8 與新混淆工具 R8,目前 D8 已經正式 Release,大約可以減少 3% 的 Dex 體積。但是計劃用於取代 ProGuard 的依然處於實驗室階段,期待它在未來能有更好的表現。
- MultiDex.install(this);分多個dex包
- 使用andresguard,路徑變成了r/d/a,還有Android 編譯過程中,下面這些格式的文件會指定不壓縮;在 AndResGuard 中,我們支援針對 resources.arsc、PNG、JPG 以及 GIF 等文件的強制壓縮。
- 移出無用的資源
android { ... buildTypes { release { shrinkResources true minifyEnabled true } } }加快編譯速度
- 你可以把編譯簡單理解為,將高級語言轉化為機器或者虛擬機所能識別的低級語言的過程。對於 Android 來說,這個過程就是把 Java 或者 Kotlin 轉變為 Android 虛擬機運行的Dalvik 位元組碼
- 關閉 JITandroid:vmSafeMode=「true」,關閉虛擬機的 JIT 優化
- r8/d8
- 使用tinker,可以回退
線上問題排查
- 日誌打點怕打太多也怕太少,擔心出現問題沒有足夠豐富的資訊去定位分析問題。應該打多少日誌,如何去打日誌並沒有一個非常嚴格的準則,這需要整個團隊在長期實踐中慢慢去摸索。在最開始的時候,可能大家都不重視也不願意去增加關鍵程式碼的日誌,但是當我們通過日誌平台解決了一些疑難問題以後,團隊內部的成功案例越來越多的時候,這種習慣也就慢慢建立起來了。
- 使用Mars的xlog,Java實現寫日誌,GC頻繁,而C實現並不會出現這種情況,因為它不會佔用Java的堆記憶體。
- 倆種方式上報日誌:push上報,主動上報(在用戶出現奔潰,回饋問題時主動上報日誌(可以重啟了上報))
- 正因為反覆「痛過」,才會有了微信的用戶日誌和點擊流平台,才會有美團的 Logan 和 Homles(看看) 統一日誌系統。所謂團隊的「提質增效」,就是尋找團隊中這些痛點,思考如何去改進。無論是流程的自動化,還是開發新的工具、新的平台,都是朝著這個目標前進。
h5優化
分為前端優化和本地優化
前端優化

本地:
- webview預創建。提前創建和初始化 WebView,以及實現 WebView 的復用,這塊大約可以節省 100~200 毫秒。
- 快取。提前把網頁需要的資源請求下來。
React Native 和 Weex 性能差。 JS 是解釋性的動態語言,它的執行效率相比 AOT 編譯後的 Java,性能依然會在幾倍以上的差距。
音影片
對於我們來說,最常見的影片格式就是MP4格式,這是一個通用的容器格式。所謂容器格式,就意味內部要有對應的數據流用來承載內容。而且既然是一個影片,那必然有音軌和視軌,而音軌、視軌本身也有對應的格式。常見的音軌、視軌格式包括:
視軌:其中,目前大部分 Android 手機都支援 H.264 格式的直接硬體編碼和解碼;對於 H.265 來說,Android 5.0 以上的機器就支援直接硬體解碼了,但是對於硬體編碼,目前只有一部分高端晶片可以支援,例如高通的 8xx 系列、華為的 98x 系列。對於視軌編碼來說,解析度越大性能消耗也就越大,編碼所需的時間就越長。
音軌:AAC
同一個壓縮格式下,碼率越高品質也就越好。
我們分別從攝影機 / 錄音設備採集數據,將數據送入編碼器,分別編碼出視軌 / 音軌之後,再送入合成器(MediaRemuxer 或者類似 mp4v2、FFmpeg 之類的處理庫),最終輸出 MP4 文件。
對於目前的影片類 App 來說,還有各種各樣的濾鏡和美顏效果,實際上都可以基於 OpenGL 來實現。
播放的影片可能是作為影片編輯的一部分,在剪輯時需要實時預覽影片特效。我們可以簡單配置播放影片的 View 為一個 GLSurfaceView,有了 OpenGL 的環境,我們就可以在這上實現各種特效、濾鏡的效果了。而對於影片編輯常見的快進、倒放之類的播放配置,MediaPlayer 也有直接的介面可以設置。
MediaPlayer無法精準的seek
關於學習
- 年輕人千萬不要碰的東西之一,便是能獲得短期快感的軟體。它們會在不知不覺中偷走你的時間,消磨你的意志力,摧毀你向上的勇氣。
- 需要看產出,而是不是工作時長
- 每天我們應該需要有一段時間真正的靜下心來工作,而且每過一段時間也要重新審視一下自己的工作,有哪些地方做的不夠好?有沒有什麼事情是自己或者團隊的人正在反覆而低效在做的,是否可以優化。
- 人的精力是有限的,每天可能也就有2個多小時能高效的產出,一定要把握好這個時間,留給最重要的事情。每天早上通勤的路上或者到公司的前10分鐘可以好好規劃一下當天要做的事情。
- 所謂的「T」無非就是橫向和縱向兩個維度。縱向解決的是深度問題,橫向解決的是廣度問題。
- 如果你在大廠,就應該從客戶端到後端,儘可能全面深入研究你參與的模組,多想想如何把你所做的模組優化到極致,並且在巨大的用戶量面前依然能夠穩定運行。如果你在初創團隊,在業餘時間也要堅持學習,持續探索自己的技術深度。這樣在將來,無論是初創團隊內部的晉陞,還是跳到大廠,這樣努力的經驗都可以成為未來無數次面試、加薪的一大亮點。
- 我建議你應該至少先在一個技術領域付出大量的精力,深入鑽研透徹,然後再去思考廣度的問題。這是因為經驗豐富的程式設計師學新的東西都非常快,因為現在已經不那麼容易出現太多全新的技術,所謂的新技術其實都是舊技術的重新組合和微創新。
- 現在好像有個觀點說「Android 開發沒人要」,大家都想轉去做大前端開發,是不是真的是這樣呢?事實上,無論我們使用哪一種跨平台方案,它們最終都要運行在 Android 平台上。崩潰、記憶體、卡頓、耗電這些問題依然存在,而且可能會更加複雜。而且從 H5 極致體驗優化的例子來看,很多優化是需要深入研究平台特性和系統底層機制,我們在「高品質開發」中學到的底層和系統相關的知識依然很重要。
- 這一系列涉及的內容就非常複雜,但每一項單拆出來去看,一層層的去學習和補充,就會感覺容易很多。這一點其實在業務開發上也有體現,我們剛接手一個複雜的業務,程式碼龐大,注釋和文檔都很少,但在一段時間後你還是會對整個業務有或多或少的認識,在接到新的業務的時候也沒有覺得難到無從下手,頂多是覺得複雜。底層的系統、框架也是如此,這是一個由點到面的過程。
- 在平時零散的時間裡我們看到一篇技術文章,並不是閱讀收藏後就結束了,這樣你可能會在很短的時間裡就忘掉了文章的內容。他將閱讀一篇文章分成以下幾個步驟:提取這篇文章要解決的問題;然後概括一下涉及的技術點;提取重點內容,比如問題發生的緣由、有哪幾種解決方法。總體來說,這個方法是為了在短時間內提取出重點內容,然後記錄下來後面再進行複習。所以我們都需要多記錄、多複習,可以培養使用一些工具來幫助自己養成習慣
- 唯有學習,不可辜負
- 確認嚴重程度。解決崩潰也要看性價比,我們優先解決 Top 崩潰或者對業務有重大影響,例如啟動、支付過程的崩潰。我曾經有一次辛苦了幾天解決了一個大的崩潰,但下個版本產品就把整個功能都刪除了,這令我很崩潰


