軟體性能測試分析與調優實踐之路-性能分析調優思想與調優技術總結
- 2020 年 9 月 13 日
- 筆記
- 性能測試, 性能診斷, 性能調優, 跟我學性能測試分析和性能診斷調優
本文主要闡述軟體性能測試中的一些調優思想和技術,節選自作者新書《軟體性能測試分析與調優實踐之路》部分章節歸納。
一、 性能分析與調優思想
1、性能分析調優模型
性能測試除了為獲取性能指標外,更多是為了發現性能瓶頸和性能問題,然後對性能問題和瓶頸進行分析和調優,在當今互聯網高速發展的時代,性能調優的模型可以歸納總結如下圖所示。
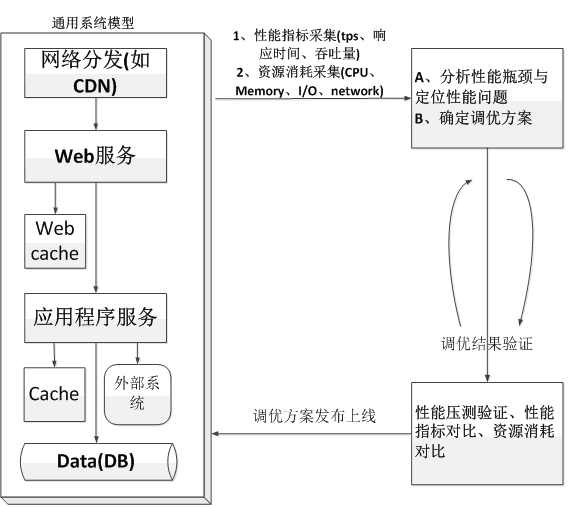
系統模型中相關的組件描述如下表所示
|
組件 |
描述 |
|
網路分發 |
網路分發是高速發展的互聯網時代常用的降低網路擁塞,快速響應用戶請求的一種技術手段,最常用的網路分發就是CDN(Content Delivery Network,即內容分發網路),依靠部署在世界各地的邊緣伺服器,通過中心平台的負載均衡、源伺服器內容分發、調度等功能模組,使世界各地用戶就近獲取所需內容,而不用每次都到中心平台的源伺服器獲取響應結果,比如南京的用戶直接訪問部署在南京的邊緣伺服器,而不需要訪問部署在遙遠的北方的北京的伺服器 |
|
Web伺服器 |
Web伺服器用於部署Web服務,Web伺服器的作用就是負責請求的響應和分發以及靜態資源的處理 |
|
Web服務 |
Web服務指運行在Web伺服器上的服務程式,最常見的Web服務就是Nginx和Apache |
|
Web Cache |
Web Cache指Web層的快取,一般都是臨時快取HTML、CSS、影像等靜態資源文件 |
|
應用伺服器 |
應用伺服器用於部署應用程式,如Tomcat、WildFly、普通的Java應用程式(如jar包服務),IIS等 |
|
應用程式服務 |
應用程式服務指運行在應用伺服器上的程式,比如Java應用,C/C++應用、Python應用,一般用於處理用戶的動態請求 |
|
應用快取 |
應用快取指應用程式層的快取服務,常用的應用快取技術有Redis、Memcached等,這些技術手段也是動態擴展的高並發分散式應用架構中經常使用的技術手段 |
|
資料庫(DB) |
用於數據的存儲,可以包括關係型資料庫以及NoSql資料庫(非關係型資料庫),常見的關係型資料庫有Mysql、Oracle、Sqlserver、DB2等,常見的NoSql資料庫有Hbase、MongoDB、ElasticSearch等 |
|
外部系統 |
指當前系統依賴於其他的外部系統,需要從其他的外部系統中通過二次請求獲取數據,外部系統有時候可能會存在很多個 |
上圖中的系統模型是一個互聯網中常見的用戶請求的分層轉發和處理的過程,在性能調優時就是不斷採集系統中的性能指標以及系統模型中各層的資源消耗,從中發現性能瓶頸和性能問題,然後對瓶頸和問題進行分析診斷來確定性能調優方案,最後通過性能壓測進行驗證調優方案是否有效,如果無效繼續重複這個過程進行性能分析,直到調優方案有效,瓶頸和問題得到解決。這個過程一般是非常漫長,因為很多時候性能調優方案往往不是一次就能有效或者一次就能解決所有的瓶頸和問題,或者解決了當前的瓶頸和問題,但是繼續性能壓測又可能會出現新的瓶頸和問題。
轉載請註明出處:來源於部落格園,作者:張永清,//www.cnblogs.com/laoqing/p/13660768.html
2、性能分析與調優思想
2.1、分層分析
分層分析指的就是按照系統模型以及系統架構分層按照調用鏈進行監控分析和問題排查,如下圖所示。
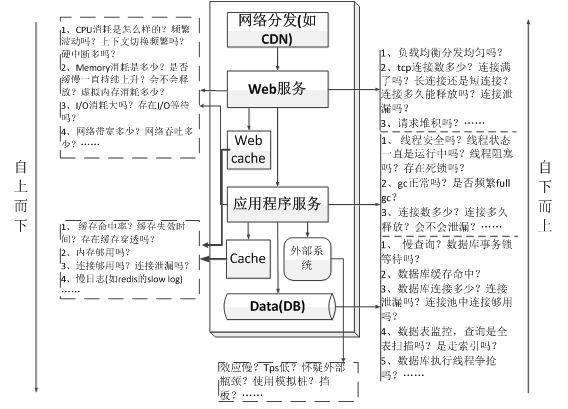
- 分層排查一般需要對系統的應用架構層次以及部署架構非常的熟悉,需要熟悉請求的處理鏈過程。
- 分層排查一般需要對每一層建立checklist,然後按照每層的checklist逐一進行分析。
- 分層排排查效率較低,但是往往能發現更多的性能問題。
- 分層排查可以自上而下也可以自下而上。
2.2、科學論證
科學論證一般包括發現問題、問題假設、預測、試驗論證、分析這5個步驟,如下圖所示。

- 發現問題:指通過性能採集和監控,發現了性能瓶頸或者性能問題,比如並發用戶數增大後TPS並不增加、每台應用伺服器的CPU消耗相差特別大等。
- 問題假設:指根據自己的經驗判斷,假設是某個因素導致了出現瓶頸和問題。
- 預測:指根據問題假設,預測可能出現的一些現象或者特徵。
- 試驗論證:根據預測,去檢查預期可能出現的現象或者特徵
- 分析:根據獲取到的實際現象或者特徵進行分析,判斷假設是否正確,如果不正確,就重新按照這個流程進行分析論證。
科學論證法進行性能分析與調優的示例如下圖所示。

2.3、問題追溯與歸納總結
(1)、問題追溯分析指的是根據問題去追溯最近系統或者環境發生的變化,一般適用於生產已上線系統的版本發布或者環境變動導致的性能問題,問題追溯的步驟一般如下圖所示,問題追溯分析是通過在追溯和描述中去逐步排查可能導致問題的原因。

(2)、歸納總結指的根據經驗的總結,在出現某種性能瓶頸或者性能問題時根據以往總結的原因進行逐一排查。
二、 性能調優技術
1、快取調優
互聯網高速發展的這個時代,快取使用已經成為了很多大型系統或者電商網站使用的一個關鍵技術,合理的設計快取直接關係到了一個系統或者網站的並發訪問能力和用戶體驗。網站按照存放地點的不同可以分為用戶端快取和服務端快取,如下圖所示。

快取調優的關鍵點說明如下:
- 如何讓快取的命中率更高?
- 如何注意防止快取穿透?
- 如何控制好快取的失效時間?
- 如何做好快取的監控分析?比如slow log分析、連接數監控、記憶體使用監控。
- 如何防止快取雪崩?快取雪崩指的是伺服器在出現斷電等極端異常情況後,快取中的數據全部丟失,導致大量的請求全部需要從資料庫中直接獲取數據從而資料庫壓力過大造成資料庫崩潰,防止快取雪崩需要注意:
(1) 要處理好快取數據全部丟失後,如何能快速把數據重新載入到快取中。
(2) 快取數據的分散式冗餘備份,當出現數據丟失時,可以迅速切換使用備份數據。
2、同步轉非同步推送
同步:指的是系統收到一個請求後,在該請求沒有處理完成時,就一直不返迴響應結果,直到處理完成了才返迴響應結果,如下圖所示。
轉載請註明出處:來源於部落格園,作者:張永清,//www.cnblogs.com/laoqing/p/13660768.html

非同步:與同步相比,非同步指的是系統收到一個請求後,只立即返回請求調用方請求接收成功,在請求處理完成後,再非同步推送處理結果給調用方,或者請求調用方在間隔一定時間再重新來獲取請求結果。如下圖所示。
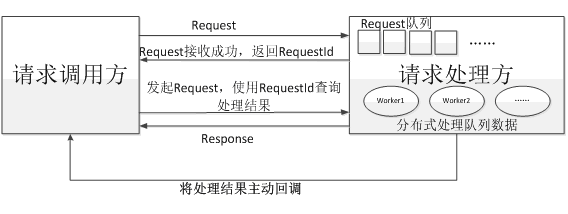
轉載請註明出處:來源於部落格園,作者:張永清,//www.cnblogs.com/laoqing/p/13660768.html
同步轉非同步主要是解決同步請求時的阻塞等待,一直處於阻塞等待的請求,往往會造成連接不能快速釋放,從而導致高並發處理時,連接數不夠用,通過隊列非同步接收請求後,請求處理方再進行分散式的並行處理,從而達到處理能力擴展,並且網路連接也可以快速釋放。
3、拆分
拆分指的是將系統中的複雜的業務調用拆分為多個簡單的調用,如下圖所示,一般遵循的原則如下:
- 對於高並發的業務請求調用都單獨拆分為單個的子系統應用。
- 對於並發訪問量接近的業務,可以按照產品業務進行拆分,相同的產品業務都歸類到一個新的子系統中。
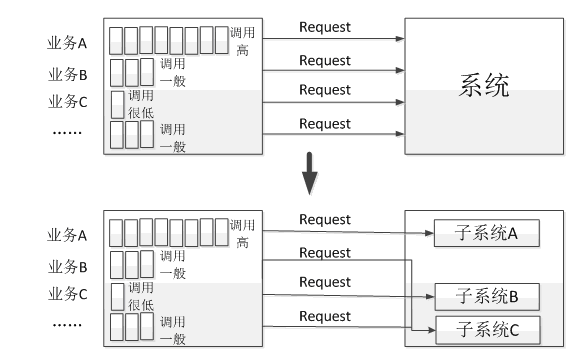
系統拆分帶來的好處就是高並發的業務不會對低並發業務的性能造成影響,而且系統在硬體擴展時,也可以有針對性的進行擴展,避免資源的浪費。
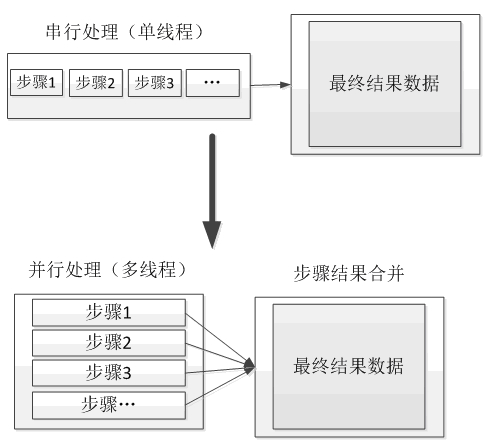
4、任務分解與並行計算
任務分解與並行計算指的是將一個任務拆分為多個子任務,然後將多個子任務並行進行計算處理,最後只需要再將並行計算的結果合併在一起返回即可。目的是通過並行計算的方式來增加處理性能,如圖所示。

轉載請註明出處:來源於部落格園,作者:張永清,//www.cnblogs.com/laoqing/p/13660768.html
另外對於包含多個處理步驟的串列任務,也可以盡量按照如下圖所示的方式轉換為並行計算處理。
5、索引與分庫分表
索引指應用程式在查詢時,盡量走資料庫索引查詢,資料庫表在創建時也盡量對查詢條件的欄位建立合適的索引,這裡強調一定是合適的索引,如果索引建立不合適,不僅對查詢效率沒有任何的幫助,反而會使資料庫表在插入數據時變的更慢,因為一旦建立了索引後,數據在插入時,索引也會自動更新,這樣就加大資料庫的插入時的資源消耗。比如資料庫表中有一個欄位為「status」,而「status」的取值只有0、1、2 三個值,這時候如果對「status」建立索引,對查詢效率就沒有任何幫助,因為「status」欄位的值只有1、2、3這三個值,建立索引後根據「status」去檢索時,需要掃描的數據還是非常的大,因為「status」欄位的取值範圍太少,過濾出來的數據量還是非常的龐大。
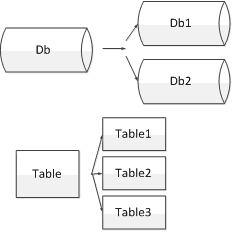
正確的使用索引可以很好的提高查詢效率,但是如果一個表的數據量非常的龐大,比如達到了億萬級別了,此時索引查詢很慢了,並且新數據插入時也很慢,此時就需要對數據進行分表或者分庫了,分庫一般指的是一個資料庫的存儲已經很大了,查詢和插入時I/O消耗非常大,此時就需要將資料庫拆分成2個庫來減輕讀寫時I/O的壓力,如下圖所示。
轉載請註明出處:來源於部落格園,作者:張永清,//www.cnblogs.com/laoqing/p/13660768.html
常見的分庫分表方式如下:
- 按照冷熱數據分離的方式:一般將使用頻率非常高的數據稱之為熱數據,查詢頻率較低或者幾乎不被查詢的數據稱之為冷數據,冷熱數據分離後,熱數據單獨存儲,這樣數據量就會下降下來了,查詢的性能自然也就提升了,而且還可以更方便的單獨針對熱數據做I/O的性能調優了。
- 按照時間維度的方式:比如可以按照實時數據和歷史數據分庫分表,也可以按照年份、月份等事件區間進行分庫分表,目的是儘可能的減少庫表中的數據量。
- 按照一定的演算法計算的方式:此種方式一般適用於數據都是熱數據的情況,比如數據無法做冷熱分離,所有的數據都經常被查詢,而且數據量又非常的大。此時就可以根據數據中的某個欄位做演算法計算(注意的是這個欄位一般是數據查詢時的檢索條件欄位),使得數據能均勻的落到不同的分表中去,查詢時再根據查詢條件欄位做演算法計算就可以快速的定位到是需要到哪個表中去進行查詢。
數據分庫分表後,帶來的另一個好處就是,如果單次查詢時,需要查詢多個分表,那麼此時就可以通過多執行緒並行的方式去查詢每個分表,最後對每個分表的查詢結果做一次合併即可,這樣也可以使得查詢的效率更高。
關於軟體性能分析調優,可以加微訊號yq597365581或者微訊號hqh345932,進入專業的性能分析調優群進行交流溝通。

備註:作者的原創文章,轉載須註明出處。原創文章歸作者所有,歡迎轉載,但是保留版權。對於轉載了部落客的原創文章,不標註出處的,作者將依法追究版權,請尊重作者的成果。
本文作者:張永清 文章選自 作者2020年初即將出版的《軟體性能測試、分析與調優實踐之路》一書。文章鏈接://www.cnblogs.com/laoqing/p/13660768.html

個人介紹:從事功能測試、自動化測試、性能測試、Java軟體開發、大數據開發、架構師等工作十多年,在自動化測試設計、性能測試設計、性能診斷、性能調優、分散式架構設計等方面積累了多年經驗,參與過的系統涉及公安、互聯網、移動互聯網、大數據、人工智慧等領域。先後任職於江蘇飛搏軟體、蘇寧大數據研發中心、蘇寧研究院、蘇寧人工智慧研發中心、紫金普惠研發中心等公司,歷任測試經理、技術經理、部門經理、高級架構師等職位,重點關注大數據、影像處理、高性能分散式架構設計等領域,著有《robot framework 自動化測試框架核心指南》、《軟體性能測試、分析與調優實踐之路》,apache dolphinscheduler 貢獻者。