NVIDIA影片合成有多「騷」,看看蒙娜麗莎你就知道了
- 2019 年 10 月 31 日
- 筆記
- 論文:https://nvlabs.github.io/few-shot-vid2vid/main.pdf
- 項目程式碼:https://nvlabs.github.io/few-shot-vid2vid/
先來看一下合成效果:

用不同示例影像合成的人體跳舞影片。

用NVIDIA 的方法合成的雕塑跳舞影片。

用不同示例影像合成的頭部特寫影片。

蒙娜麗莎頭部合成影片。

街景合成影片。
「影片到影片」合成(簡稱「vid2vid」)旨在將人體姿態或分割掩模等輸入的語義影片,轉換為逼真的輸出影片。雖然當前 vid2vid 合成技術已經取得了顯著進展,但依然存在以下兩種局限:其一,現有方法極其需要數據。訓練過程中需要大量目標人物或場景的影像;其二,學習到的模型泛化能力不足。姿態到人體(pose-to-human)的 vid2vid 模型只能合成訓練集中單個人的姿態,不能泛化到訓練集中沒有的其他人。
為了克服這兩種局限,NVIDIA 的研究者提出了一種 few-shot vid2vid 框架,該框架在測試時通過利用目標主體的少量示例影像,學習對以前未見主體或場景的影片進行合成。
藉助於一個利用注意力機制的新型網路權重生成模組,few-shot vid2vid 模型實現了在少樣本情況下的泛化能力。他們進行了大量的實驗驗證,並利用人體跳舞、頭部特寫和街景等大型影片數據集與強基準做了對比。
實驗結果表明,NVIDIA 提出的 few-shot vid2vid 框架能夠有效地解決現有方法存在的局限性。
如下圖 1(右)所示,few-shot vid2vid 框架通過兩個輸入來生成一個影片:

圖 1:NVIDIA few-shot vid2vid(右)與現有 vid2vid(左)框架的對比。現有的 vid2vid 方法不考慮泛化到未見過的域。經過訓練的模型只能用於合成與訓練集中影片相似的影片。NVIDIA 的模型則可以利用測試時提供的少量示例影像來合成新人體的影片。
除了和現有 vid2vid 方法一樣輸入語義影片外,few-shot vid2vid 還有第二個輸入,其中包括測試時可用的目標域的一些示例影像。值得注意的是,現有的 vid2vid 方法不存在第二個輸入。研究者提出的模型使用這幾個示例影像,並通過新穎的網路權重生成機制實現對影片合成機制的動態配置。具體來說,他們訓練一個模組來使用示例影像生成網路權重。此外,他們還精心設計了學習目標函數,以方便學習網路權重生成模組。
少樣本的影片到影片合成
影片到影片合成旨在學習一個映射函數,該函數可以將輸入語義影像的序列,即

,轉化為輸出影像的序列,即

。在這一過程中,以語義影像序列為條件的輸出影像分布和標註影像分布是近似的。換言之,影片到影片合成旨在實現

,其中 D 是分布散度測量,如 Jensen-Shannon 散度(簡稱「J-S 散度」)或 Wasserstein 散度。為了對條件分布進行建模,現有研究利用了簡化的馬爾可夫假設(Markov assumption),並通過以下方程得出序列生成模型:

換言之,它基於觀察到的 Τ+1 輸入語義影像

,還有Τ-1 生成的影像

生成輸出影像。
序列生成器 F 可以通過幾種方式進行建模,並且通常選擇使用由以下方程得出的 matting 函數:

下圖 2(a)是 vid2vid 架構和摳圖函數的可視圖,其中輸出影像 x_t tilde 是通過結合最後生成影像的光流變形版本,即

和合成的中間影像 h_t tilde 生成的。

圖 2:(a)現有 vid2vid 框架的架構;(b)NVIDIA 提出的 few-shot vid2vid 框架的架構。
軟遮擋映射 m˜_t 說明了在每個像素位置上如何組合兩個影像。簡單來說,如果某個像素能在此前生成的幀中被找到,會更有利於從變形影像中複製像素值。實際上是通過神經網路參數化的函數 M、W 和 H 生成的:
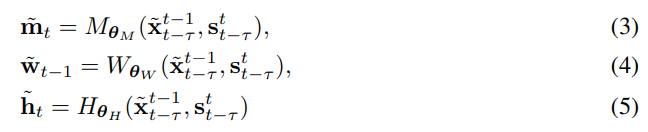
其中,θM、θW 和θH 是可學習的參數,訓練完成後它們會保持固定狀態。
Few-shot vid2vid
前面方程 1 得到的序列生成器希望將新穎的輸入轉化為語義影片,但現在有一個問題,這樣的模型是做不到 Few-shot 的,它並沒有學習到如何合成未知領域的影片。為了令生成器 F 適應未見過的數據,研究者使得 F 依賴於額外的輸入。
具體而言,研究者給 F 增加了兩個額外的輸入參數:即目標領域的 K 個樣本影像 {e_1, e_2, …, e_K},以及對應它們對應的語義影像 {s_e1 , s_e2 , …, s_eK }。這樣整個生成器就可以表示為如下方程式,它嵌入了少樣本學習的屬性:

基於注意力的聚合(K > 1)
除此之外,研究者還想讓 E 從任意數量的示例影像中提取出模式。由於不同的示例影像可能具有不同的外觀模式,而且它們與不同輸入影像之間的關聯程度也存在差異,研究者設計了一種注意力機制來聚合提取出的外觀模式 q_1……q_K。
為此,它們構建了一個新的包含若干完全卷積層的注意力網路 E_A。E_A 應用於示例影像的每個分割影像 s_e_k。這樣可以得到一個關鍵向量 a_k ∈ R^(C×N),其中,C 是通道的數量,N = H × W 是特徵圖的空間維度。
他們還將 E_A 應用於當前輸入語義影像 s_t,以提取其關鍵向量 a_t ∈ R^(C×N)。接下來,他們通過利用矩陣乘積計算了注意力權重α_k = (a_k) ^T ⊗ a_t。然後將注意力權重用於計算外觀表徵的加權平均值

,然後將其輸入到多層感知機 E_P 以生成網路權重(見下文中的圖 2(b))。這種聚合機制在不同示例影像包含目標的不同部分時很有幫助。例如,當示例影像分別包含目標人物的正面和背面時,該注意力圖可以在合成期間幫助捕捉相應的身體部位。
實驗結果
下圖 3 展示了在合成人物時使用不同示例的結果。可以看出,NVIDIA 提出的方法可以成功地將動作遷移至所有示例影像中。

圖 3:人體跳舞影片合成結果可視圖。
下圖 4 展示了NVIDIA 提出的方法與其他方法的對比。可以看出,其他方法要麼生成有瑕疵的影片,要麼無法將動作完全遷移至新影片。

圖 4:與其他人體動作合成結果的對比。
下圖 5 展示了用不同示例影像合成街景的效果。可以看出,即使使用相同的輸入分割圖,使用NVIDIA 的方法也能得到不同的結果。

圖 5:街景影片合成結果圖示。
下圖 6 展示了在合成人臉時使用不同示例影像的結果。NVIDIA 的方法可以在捕捉到輸入影片動作的同時完整保留示例人物特徵。

圖 6:人臉影片合成結果。


