PCA(主成分分析)原理,步驟詳解以及應用
- 2019 年 10 月 3 日
- 筆記
主成分分析(PCA, Principal Component Analysis)
- 一個非監督的機器學習演算法
- 主要用於數據的降維處理
- 通過降維,可以發現更便於人類理解的特徵
- 其他應用:數據可視化,去噪等
主成分分析是儘可能地忠實再現原始重要資訊的數據降維方法
原理推導:
如圖,有一個二維的數據集,其特徵分布於特徵1和2兩個方向

現在希望對數據進行降維處理,將數據壓縮到一維,直觀的我們可以想到將特徵一或者特徵二捨棄一個,可以得到這樣的結果

——- : 捨棄特徵1之後
——- : 捨棄特徵2之後
可以看出,捨棄特徵2保留特徵1是一個較好的降維方案,此時點和點之間距離較大,擁有更高的可區分度
此時我們要想,肯定會有比這更好的方案,畢竟這太簡單了
我們想像一下,能夠找到這樣的一條斜線w,將數據降維到w上(映射到w上)之後,能最好的保留原來的分布特徵,且這些點分布在了一個軸上(斜線w)後點和點之間的距離也比之前的兩種方案更加的大,此時的區分度也更加明顯

思考:
- 如何找到讓這個樣本降維後間距最大的軸?
- 如何定義樣本間距?
在統計學中,有一個直接的指標可以表示樣本間的間距,那就是方差(Variance)
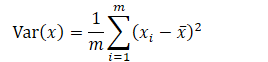
這樣回過頭來看思考1,問題就變成了:
找到一個軸,使得樣本空間的所有點映射到這個軸之後,方差最大
求解這個軸的過程
將樣例的均值歸為0(demean)
將全部樣本都減去樣本的均值,可以將樣本轉化為這種:

經過demean後,在各個維度均值均為0,我們可以推出:
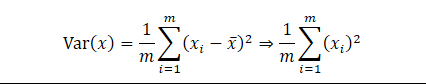
方便我們進行計算
我們想要求w軸的方向(w1,w2),使得 Var(Xproject) 最大,Xproject 是映射到w軸之後的X的坐標
![]()
因為我們已經進行了demean操作,均值為0,所以此時
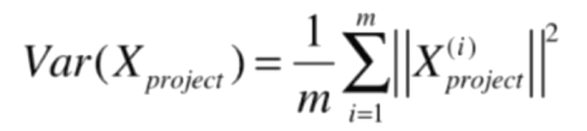
而 ||Xproject(i)||2 的實際長度就是下圖中藍色向量的長度
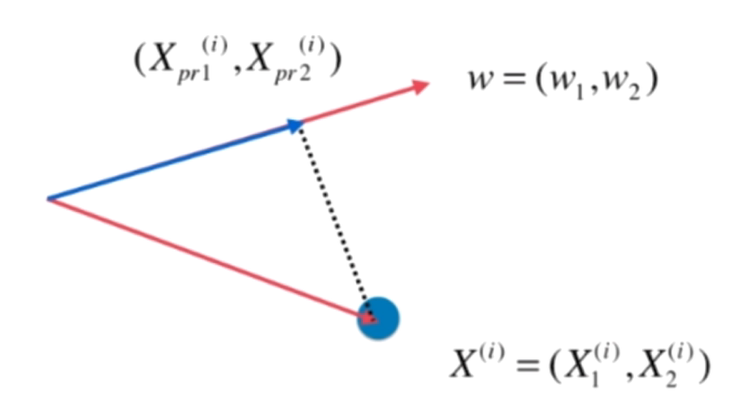
實際上,求把一個向量映射到另一個向量上的對應映射的長度,就是線性代數中點乘的操作
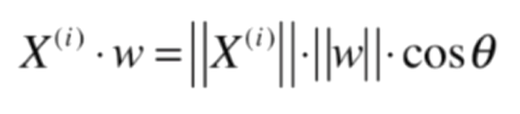
此時w是一個方向向量,||w|| = 1,所以可以化簡成:
![]()
且因為前面已經推知
![]()
通過替換,我們就得到了:
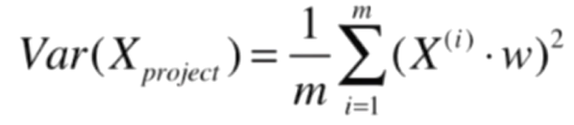
而我們的目標,就是求w,使得Var(Xproject) 最大
對公式進行拆分
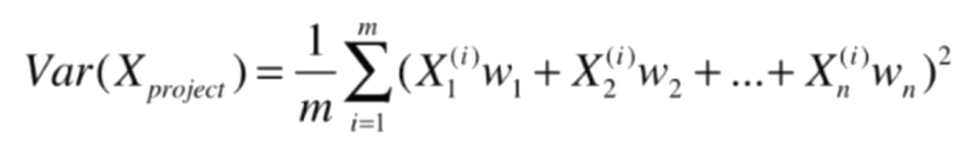
再化簡:
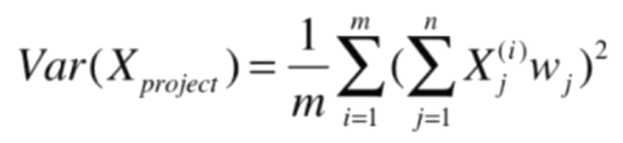
至此,我們的主成分分析法就化簡成了一個目標函數最優化問題,因為是求最大值,可以使用梯度上升法解決
使用梯度上升法求解PCA
目標: 求w,使得 ![]() 最大
最大
f(X)的梯度
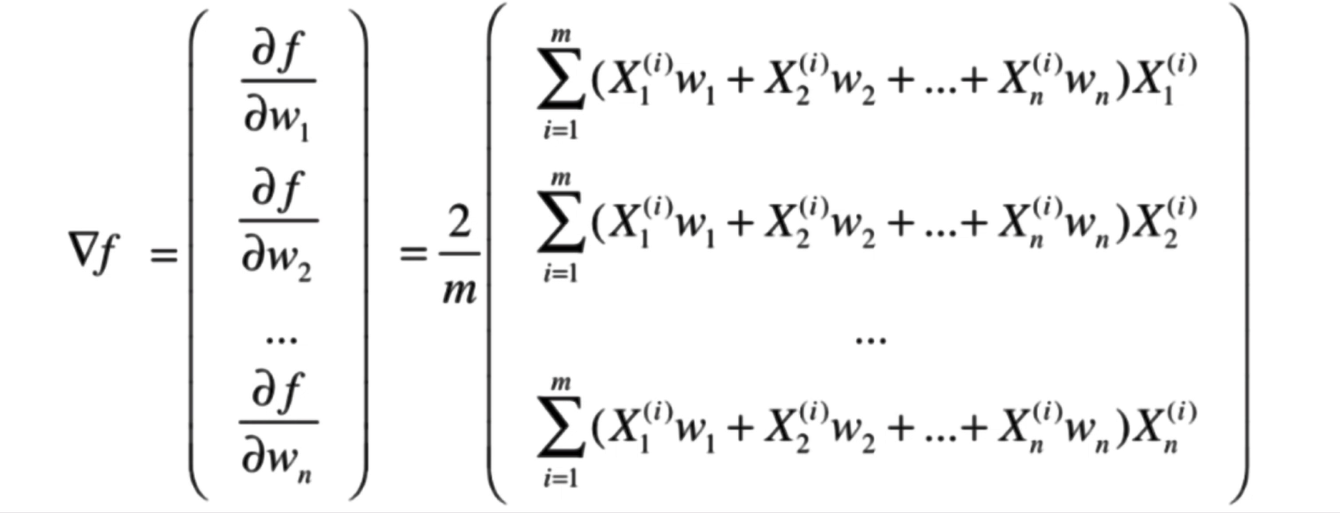
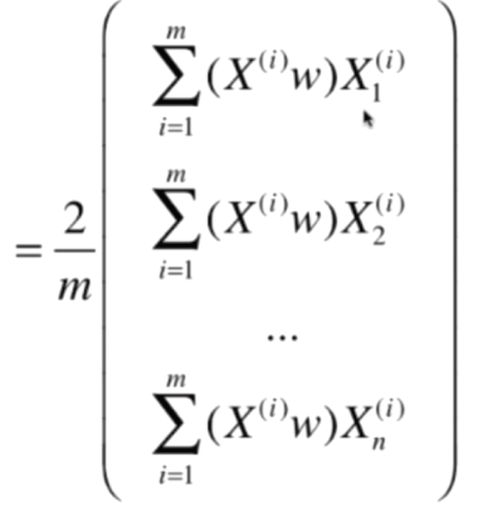
此時再觀察,可以將式子展開能夠得到這樣的結果:
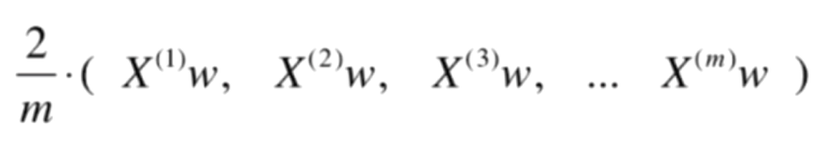
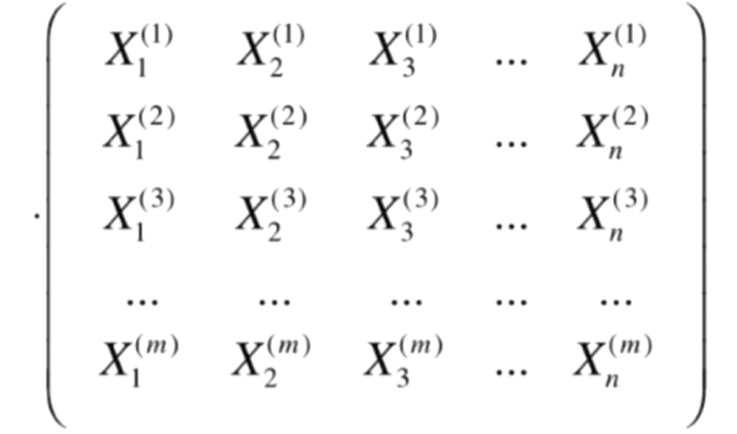
再化簡,可得:
原式 = ![]()
= ![]()
最後就得出結論:

那麼,求出第一個主成分之後,如何求出下一個主成分呢?
數據進行改變,將數據在第一主成分上的分量去掉,如圖
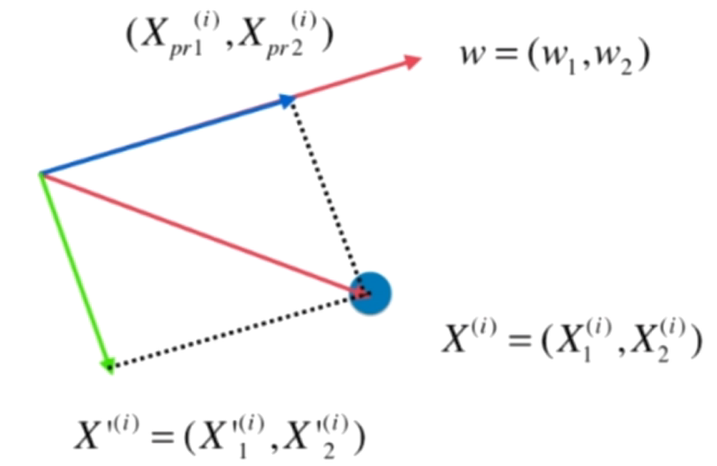
Xpr(i) 是第一主成分,原數據去掉第一主成分之後可以得到
![]()
再在 X’(i) 上求第一主成分即可求出原數據的第二主成分,以此類推..
程式碼實現
1 import numpy as np 2 import matplotlib.pyplot as plt 3 4 # 生成測試數據 5 X = np.empty((100, 2)) 6 X[:, 0] = np.random.uniform(0., 100., size=100) 7 X[:, 1] = 0.75 * X[:, 0]+ 3. + np.random.normal(0, 10., size=100) 8 9 # 均值歸零方法 10 def demean(X): 11 return X - np.mean(X, axis=0) 12 13 X_demean = demean(X) 14 15 # 梯度上升法 16 def f(w, X): 17 return np.sum((X.dot(w)**2)) / len(X) 18 def df(w, X): 19 return X.T.dot(X.dot(w)) * 2. / len(X) 20 21 # 將w轉化為單位向量,方便計算 22 def direction(w): 23 return w / np.linalg.norm(w) 24 25 #求第一主成分 26 def first_component(X, initial_w, eta, n_iters = 1e4, epsilon = 1e-8): 27 28 w = direction(initial_w) 29 cur_iter = 0 30 31 while cur_iter < n_iters: 32 gradient = df(w, X) 33 last_w = w 34 w = w + eta * gradient 35 w = direction(w) # 每次求一個單位方向 36 if abs(f(w, X) - f(last_w, X)) < epsilon: 37 break 38 39 cur_iter += 1 40 return w 41 42 initial_w = np.random.random(X.shape[1]) # 不能從零開始 43 44 eta = 0.01 45 46 def first_n_component(n, X, eta=0.01, n_iters = 1e4, espilon = 1e-8): 47 X_pca = X.copy() 48 X_pca = demean(X_pca) 49 res = [] 50 for i in range(n): 51 initial_w = np.random.random(X_pca.shape[1]) 52 w = first_component(X_pca, initial_w, eta) 53 res.append(w) 54 55 X_pca = X_pca - X_pca.dot(w).reshape(-1, 1) 56 X_pca = X_pca * w 57 return res 58 59 # 注意 不能使用StandardScaler標準化數據 這樣會打掉樣本間的方差 求不出想要的結果 60 61 res = first_n_component(2, X)
