數據分析與數據挖掘 – 03智慧對話
一 數據分析與自然語言處理
我們在處理很多數據分析任務時,不可避免地涉及到與文本內容相關的知識,這是屬於文本挖掘(text mining)的內容,顯然是NLP技術的範疇,基於這樣的考慮我們先來對自然語言處理有一個基本的認識。
二 自然語言處理
如果一台電腦能夠欺騙人類,讓人相信它是人類,那麼該電腦就應當被認為是智慧的。(阿蘭.圖靈)
機器能像我們人類一樣理解文本嗎?這是大家對人工智慧最初的幻想。如今,它已成為人工智慧的核心領域——自然語言處理(簡稱:NLP)。自然語言處理是一門融語言學、電腦科學、人工智慧於一體的科學,人們把自然語言處理認為是人工智慧的皇冠,它解決的是「讓機器可以理解自然語言」——這一到目前為止都還只是人類獨有的特權,因此,自然語言理解(NLU)被譽為人工智慧皇冠上的明珠。
自然語言處理涉及到眾多的技術,它包括但不限於以下幾個領域:
- 機器翻譯(MT):實現一種語言到另一種語言的自動翻譯
- 自動文摘(Automatic Abstracting):將文檔的主要內容和含義自動歸納,提煉,形成摘要
- 資訊檢索(Information Retrieval): 從海量文檔中找到符合用戶需要的相關文檔
- 文檔分類(Document Classification): 對大量文檔按照一定的分類標準實現自動歸類
- 問答系統(Question-answering system): 對用戶提出的問題理解,並自動作出應答
- 語音識別(Automatic Speech Recognition): 將用戶語音資訊識別成文本資訊
- 語音合成(Text-to-speech):將文本資訊合成人類的語音
以上簡單列舉了幾個NLP相關的技術,接下來,我們希望能夠在短時間內,對於NLP有一個基本的了解和簡單的實踐,我會帶領大家寫一個問答系統,也就是智慧聊天機器人。
三 聊天機器人的發展
聊天機器人是我們日常生活中非常常見的一個人工智慧的應用,從這一章開始,我們將通過技術的學習,一步一步開發出一款自己的聊天機器人。其實,早在1965年,Joseph Weizenbaum 在ACM上發表了題為《ELIZA,一個研究人機自然語言交流的電腦程式》的文章。文章描述了這個叫作Eliza的程式如何使人與電腦在一定程度上進行自然語言對話成為可能。Eliza通過關鍵詞匹配規則對輸入進行分解,而後根據分解規則所對應的重組規則來生成回復。從那之後,聊天機器人經歷了飛速的發展,像微軟小冰,蘋果siri,小愛同學,天魔精靈等等都是現代聊天機器人的具體應用。
四 聊天機器人的分類
我們一般把聊天機器人分為三類:
- 任務型機器人
- 知識型機器人
- 閑聊形機器人
對於聊天機器人的歸類,我們從字面意思就能看的出來。任務型機器人就是能夠在某個領域或者某個特定的場景下來幫助我們完成某些人物,比如小愛同學可以操作家裡面的空調,siri可以幫助我們上鬧鐘等等。知識型機器人就是能夠幫助我們處理某個特定領域的知識,比如天貓的自動客服,Sophia能夠回答各種問題。聊天機器人就是能夠和我們隨機聊天的機器人。在我印象中,iphone4s剛誕生的時候,siri就上線了這個功能,曾經無數痴漢都肆虐式地調戲過siri老阿姨Susan Bennett,我們一起來看一下,阿姨年輕時那美麗的容顏。

不過當對siri原聲進行採集的時候是這樣的

感謝Susan的付出,才有當時的siri和我們寢室內的歡樂(我我我,一不小心暴露了年齡)
五 聊天機器人的原理
目前搭建聊天機器人主要要四種方法:
- 基於模版匹配的方法
- 基於檢索模型的方法
- 基於意圖識別的方法
- 端到端生成式方法
基於模版匹配的方法其核心就是要定義一條一條的規則,不需要AI技術就可以實現,上面提到的最早的聊天機器人Eliza就是其中的經典案例。這個過程雖然簡單,但是需要設計大量的規則,而且要確保規則之間沒有衝突(很難),可擴展性差、重複工作很多,很難處理語句的多樣化表達等等。
基於檢索模型的方法可以有效避免上述的缺點,首先仍是獲取輸入的文本資訊,然後進入檢索模型階段,最後輸出回答的結果。這一章,我們主要基於檢索模型來構建聊天機器人。
後面的兩種意圖識別和端到端的方法需要隨著NLP相關知識的學習深入才能有更多的實踐。
六 中文分詞
1 分詞基本知識
基於檢索模型的方法做聊天機器人,主要分為以下幾步:中文分詞,分本的表示,相似度計算,返回結果這四個步驟。分詞就是把詞分開,在英文中,I love you,這三個片語成的一句話原本就是用空格分開的,而中文裡面的一句話,比如「我愛北京天安門」,應該怎麼樣用空格分開呢?
為了能夠 讓程式來幫我們自動完成這個工作,Python語言中提供了多個分詞庫,比如jieba,SnowNLP,thulac,pynlpir,nltk,pyltp等等,其中最具有代表性的還是百度的jieba分詞,github地址是//github.com/fxsjy/jieba,有興趣的同學可以深入了解以下。中文分詞的意思就是有人根據經驗把很多詞梳理了出來,然後對一個句子進行檢索,知道了哪些字能夠組成一個詞,使用它之後,就會自動的幫助我們把句子拆分成不同的詞。
jieba分詞示例程式碼如下所示
import jieba
text = '我愛北京天安門'
result = jieba.cut(text) # 分詞的結果是一個生成器對象
for i in result:
print(i)
2 分詞模式
jieba分詞庫提供了三種分詞模式,分別是精準模式,全模式和搜索引擎模式。
- 精準模式:將句子精確的切開,適合文本分析。通過參數cut_all確定分詞模型,如果為False,則為精準模式。如果不寫參數,默認就是精準模式。
- 全模式:把句子中所有的可以成詞的詞語都掃描出來,速度非常快。但是不能解決歧義問題。當cut_all參數的值等於True的時候,就是全模式。
- 搜索引擎模式:在精準模式的基礎上,對長詞再次切分,適用於搜索引擎分詞。使用jieba.cut_for_search()方法來實現搜索引擎模式。
下面我們通過一個實例來看一下他們的效果分別是怎麼樣的,程式碼如下:
import jieba
text = '今天天氣很熱,我出去轉了一圈出了一身汗,還是待在家裡吹空調吧'
result1 = jieba.cut(text, cut_all=False) # 精準模式
result2 = jieba.cut(text, cut_all=True) # 全模式
result3 = jieba.cut_for_search(text) # 搜索引擎模式
print(list(result1))
print(list(result2))
print(list(result3))
從結果上,我們看到在文本分析場景下,使用精準模式是比較適合的,其他兩種模式對於詞的切分上都太過於細緻了。
七 文本表示
1 詞向量基本介紹
在自然語言處理中,文本表示非常重要,只有把文本表示成數字的樣子,我們才能夠進一步進行處理。這種用數字代替文本的表示方法就是詞向量。顧名思義,它就是用一個向量的形式來表示一個詞。
2 詞向量表示的原理
假想我現在有一個由一些單片語成的文本的詞典,詞典的內容是:我 愛 北京 天安門,現在有三個詞,分別是:我,北京和愛,現在我們要通過向量的方式根據詞典來表達出這三個詞,表示方法如下圖所示:
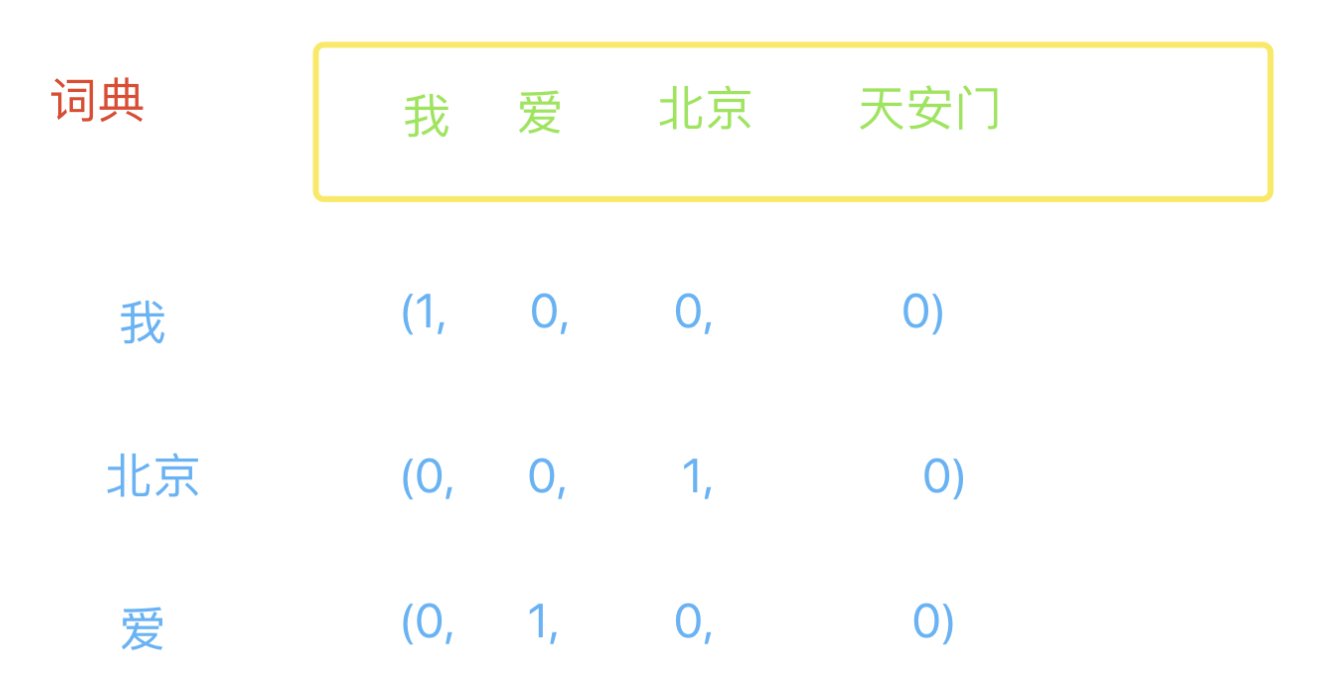
使用這種方式,假如詞典,有10億個詞,每一個詞的表示都是一個10億維的數組,其中一維是1,其他全是0。顯然,是用這種方式會把一個詞表示的特別複雜,實際應用場景肯定不是這樣的,我先使用這種方式來便於理解。
3 詞向量表示小練習
現在有一個詞典和兩個詞,基於剛才介紹的詞向量表示方法寫一個程式來表示這兩個詞。
text_list = ['我', '愛', '北京', '天安門']
w1 = '我'
w2 = '天安門'
def get_vector(word):
vector = []
for i in text_list:
if word == i:
vector.append(1)
else:
vector.append(0)
return vector
print(get_vector(w1))
print(get_vector(w2))
4 用向量的方式去表達一個句子
表示句子與詞向量的表示方式類似,只需要我們判斷在詞向量中是否出現了這個句子的每一個詞,出現標記為1,沒有出現標記為0。表示句子的程式程式碼如下:
import jieba
text_list = ['我', '愛', '北京', '天安門']
w1 = '我愛你'
w2 = '我在天安門'
w3 = '我的家在北京'
def get_vector(word):
word_list = list(jieba.cut(word))
print(word_list)
vector = []
for i in text_list:
if i in word_list:
vector.append(1)
else:
vector.append(0)
return vector
print(get_vector(w1)) # 其中w1會受分詞結果的影響非常嚴重,此處做簡要說明
print(get_vector(w2))
print(get_vector(w3))
5 詞向量自動表示庫gensim
詞向量的表示Python給我們提供了一個庫gensim,它的使用方式如下程式碼所示:
import jieba
from gensim.models import word2vec
# 假設有文件 a.txt ,文件內容為:我愛北京天安門
f1 = open('a.txt')
# 用來存儲分詞之後的結果
f2 = open('b.txt', 'a')
# 假設文件內有多行文本
lines = f1.readlines()
for line in lines:
# 替換tab,換行,空格
line.replace('/t', '').replace('/n', '').replace(' ', '')
segment = jieba.cut(line)
# 以空格拼接並寫入
f2.write(' '.join(segment))
f1.close()
f2.close()
# 載入語料
sentences = word2vec.Text8Corpus('b.txt')
# 訓練模型
model = word2vec.Word2Vec(sentences, min_count=1) # 語料庫太少,必須設置min_count參數為1
# 保存模型
model.save('word2vec.model')
# 表示詞向量
print(model.wv['我'])
print(model.wv['天安門'])
print(model.wv['我', '天安門'])
# print(model.wv['上海']) # 詞向量必須在語料庫中存在才可以表示,不存在會報錯
八 計算文本相似度
1 歐式距離
文本相似度,主要是計算不同文本之間的距離,他計算方式就像是計算直角三角形的斜邊的長度,那麼現在我們計算a和b兩點之間的距離的計算方法就是:

這種距離的計算方式叫做歐式距離,把它擴展到n維空間下的計算方式就是:

2 曼哈頓距離
曼哈頓距離是與歐式距離比較相近的距離計算,也叫做曼哈頓街區距離,他的計算距離很簡單,就是計算兩點在軸上的相對距離總和,如下圖藍色虛線所示:
曼哈頓距離公式:d(a,b)= |x1 – x2| + |y1 – y2|
在n維空間下:d(a,b)= |x1 – x2|+|y1 – y2|+ … |xn – yn|
在早期的電腦圖形學中,使用曼哈頓距離可以大大提高運算速度,而且誤差很小,現在常把曼哈頓距離應用於與圖形相關的複雜的計算中以此來提高效率,這裡我們做一個簡單的引導就不再一一展開。
3 餘弦相似度
餘弦相似度是計算文本相似度應用的非常多的一個計算公式,它的本質是計算兩點所構成向量夾角的餘弦值,如下圖所示:
從圖中我們可以看:θ = θ1 – θ2,θ的值越小,則餘弦值越接近於1,進而說明兩個點之間越相似。餘弦相似度的計算也有其特定的公式,他的推導過程如下所示:

公式的推導過程比較簡單,有數學恐懼症的同學可以先跳過這一部分。
4 使用gensim計算文本相似度
計算文本相似度只需要一行程式碼,但是有一個小細節,我們計算的詞必須要出現在語料庫中,由於文本數據少之又少,我們計算的結果會和實際有所偏差,但這並不影響我們的理解,示例程式碼如下:
# 1 獲取兩個文本之間的相似度
sim1 = model.wv.similarity('我', '天安門')
# sim2 = model.wv.similarity('我們', '天安門') # 報錯:"word '我們' not in vocabulary"
print(sim1)
# 2 找到與給定文本最想的文本,並排序
sim_text = model.wv.most_similar('我')
print(sim_text)
# 3 比較兩個詞條的相似性
sim3 = model.wv.n_similarity(['我', '天安門'], ['愛', '北京'])
print(sim3)
九 聊天機器人實踐
首先我這裡會有以壓縮文件,裡面包含兩個txt文件,其中fenci.txt裡邊存儲了一段文字,你需要把這些文字用分詞庫,把他們分成不同的詞語,作為我們的語料庫。
chapter3_1.zip
content_file.txt文件中存儲了一些標題和回帖的內容,這些內容是來源於網上的一些帖子內容。我們把title看做是相關的聊天主題,而reply看做是回答的答案。
你需要根據這些語料來製作一個能夠自動回復用戶的聊天機器人,具體程式碼如下:
import json
import random
import jieba
from gensim.models import word2vec
"""
1、用戶輸入一段文本
2、對用戶輸入的文本進行分詞
3、把用戶輸入的結果與content_file.txt文件中的title欄位,一一的進行相似度運算
4、獲取到最大的相似度。
5、由於reply中的內容是一個列表,所以隨機產生一個答案進行回復。
"""
f1 = open('fenci.txt')
f2 = open('result.txt', 'a')
lines = f1.readlines()
for line in lines:
line.replace('\t', '').replace('\n', '').replace(' ', '')
segment = jieba.cut(line)
f2.write(' '.join(segment))
f1.close()
f2.close()
sentences = word2vec.Text8Corpus('result.txt')
model = word2vec.Word2Vec(sentences, min_count=1)
model.save('chat-bot.model')
word2vec.Word2Vec.load('chat-bot.model')
# 3 比較兩個詞條的相似性
sim3 = model.wv.n_similarity(['我們', '最近'], ['因為', '不好'])
print(sim3)
while True:
text = input("請輸入>>:").strip()
if text in ['拜拜', 88, 8, 'bye', '再見']:
print("有緣再見")
break
# 1 分詞
words = jieba.cut(text)
user_word_list = []
for word in words:
user_word_list.append(word)
# 2 載入回復文件
content_file = open('content_file.txt')
json_content_file = json.load(content_file)
max_sim_result = 0
max_sim_response = []
max_sim_title = ''
for line in json_content_file:
content_cut_word = jieba.cut(line['title'])
content_list = []
for w in content_cut_word:
content_list.append(w)
try:
sim_result_value = model.wv.n_similarity(user_word_list, content_list)
except:
continue
# 3 檢查最大相似度的匹配
if sim_result_value > max_sim_result:
max_sim_result = sim_result_value
max_sim_response = line['reply']
max_sim_title = line['title']
print(max_sim_result)
print(max_sim_title)
if max_sim_response:
print(max_sim_response[random.randint(0, len(max_sim_response) - 1)])
else:
print('對不起,請說人話')
我的部落格即將搬運同步至騰訊雲+社區,邀請大家一同入駐://cloud.tencent.com/developer/support-plan。