KUDU 學習筆記
Kudu
現存系統針對結構化數據存儲與查詢的一些痛點問題,結構化數據的存儲,通常包含如下兩種方式:
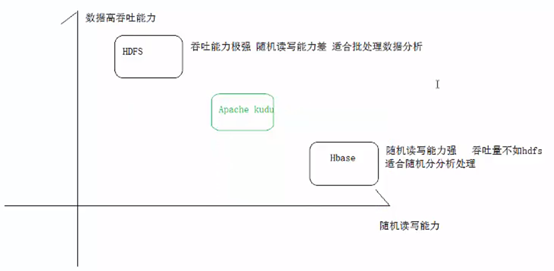
- 靜態數據通常以Parquet/Carbon/Avro形式直接存放在HDFS中,吞吐能力大,適合離線分析,隨機讀寫能力差,難以支援單條記錄級別的更新。
- 可變數據的存儲通常選擇面向列族的HBase或者Cassandra,高效隨機讀寫,吞吐能力小,不適合離線分析場景。
Kudu的設計是結合了Hbase的高效隨機讀寫和HDFS高吞吐能力一種折中處理,既能支援OLTP型實時讀寫能力又能支援OLAP型分析。另外一個初衷Kudu作為一個新的分散式存儲系統期望有效提升CPU的使用率,而低CPU使用率恰是HBase/Cassandra等系統的最大問題。
Kudu架構
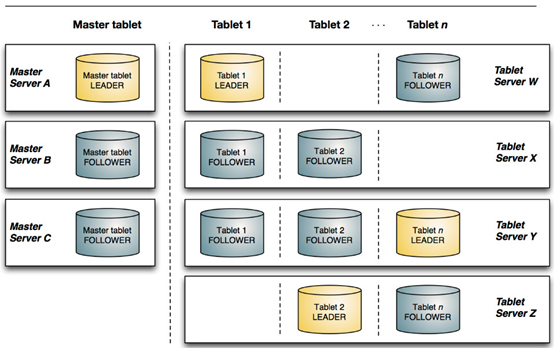
Kudu採用了Master-Slave主從架構,一個table表會按照主鍵進行hash/或者range(分區)劃分出多個小的tablet(相當於Hbase里的Region),每個小的tablet會對應多個副本(其中1個Leader tablet用於讀寫,其他的副本為Follower tablet用於只讀),這個小的tablet會分到各個Tablet Server 中,這些tablet相關資訊存儲在Master Server中(1個Leader多個Follower)。
Master Server
1用來存放一些表的Schema資訊,且負責處理建表等請求,管理元數據(元數據存儲在只有一個tablet的Catalog table中),即tablet與表的基本資訊。
2. 跟蹤管理集群中的所有的Tablet Server,並且在Tablet Server異常之後協調數據的重部署。
3. 存放Tablet到Tablet Server的部署資訊。
其中Catalog Table元數據表,用來存儲table(schema、locations、states)與tablet(現有的tablet列表,每個tablet及其副本所處Tablet Server,tablet當前狀態以及開始和結束鍵)的資訊。
Tablet Server
存儲tablet和為tablet向client提供服務。對於給定的tablet,一個Tablet Server充當leader,其他Tablet Server充當該tablet的follower副本。只有leader服務寫請求,leader與follower為每個服務提供讀請求。
Tablet與HBase中的Region大致相似,但存在如下一些明顯的區別點:
分區策略不一樣
Tablet包含兩種分區策略,一種是基於Hash Partition方式,在這種分區方式下用戶數據可較均勻的分布在各個Tablet中,但原來的數據排序特點已被打亂。另外一種是基於Range Partition(分區)方式,數據將按照用戶數據指定的有序的分區鍵的組合String的順序進行分區。而HBase中僅僅提供了一種按用戶數據RowKey的Range Partition方式。
多副本機制不一樣
一個Tablet可以被部署到了多個Tablet Server中,由自己系統管理,不依賴HDFS。在HBase最初的架構中,一個Region只能被部署在一個RegionServer中,它的數據多副本交由HDFS來保障。
數據文件存儲結構
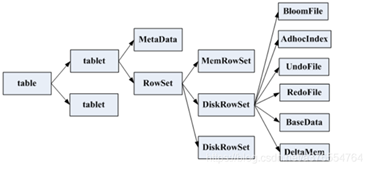
具體結構如下
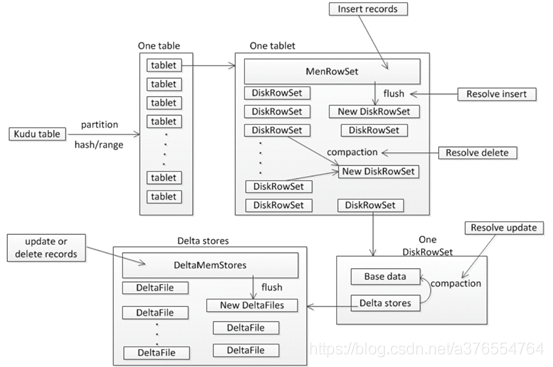
數據的讀寫更操作
不管數據的讀寫,還是更新操作,其大致都需要先查找我們要的數據的主鍵所對應的位置,比如下面的寫操作
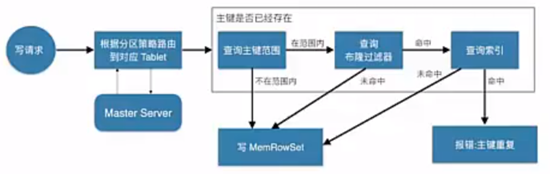
寫流程
Client首先連接Master,獲取元數據資訊。然後連接Tablet Server,查找MemRowSet與DeltMemStore中是否存在相同primary key,如果存在,則報錯;如果不存在,則將待插入的數據寫入WAL日誌,然後將數據寫入MemRowSet。

1、client向Master請求預寫表的元數據資訊
2、Master會進行一定的校驗,表是否存在,欄位是否存在等
3、如果Master校驗通過,則返回表的分區、tablet與其對應的Tablet Server給client;如果校驗失敗則報錯給client。
4、client根據Master返回的元數據資訊,將請求發送給tablet對應的Tablet Server.
5、Tablet Server首先會查詢記憶體中MemRowSet與DeltMemStore中是否存在與待插入數據主鍵相同的數據,如果存在則報錯。
6、Tablet Server會講寫請求預寫到WAL日誌,用來server宕機後的恢復操作
7、將數據寫入記憶體中的MemRowSet中,一旦MemRowSet的大小達到1G或120s後,MemRowSet會flush成一個或DiskRowSet,用來將數據持久化
8、返回client數據處理完畢
更新流程
Client首先向Master請求元數據,然後根據元數據提供的tablet資訊,連接Tablet Server,根據數據所處位置的不同,有不同的操作:在記憶體MemRowSet中的數據,會將更新資訊寫入數據所在行的mutation鏈表中;在磁碟中的數據,會將更新資訊寫入DeltMemStore中。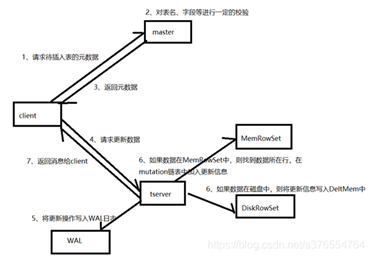
1、client向Master請求預更新表的元數據,首先Master會校驗表是否存在,欄位是否存在,如果校驗通過則會返回給client表的分區、tablet、tablet所在Tablet Server資訊
2、client向Tablet Server發起更新請求
3、將更新操作預寫如WAL日誌,用來在server宕機後的數據恢復
4、根據Tablet Server中待更新的數據所處位置的不同,有不同的處理方式:
如果數據在記憶體中,則從MemRowSet中找到數據所處的行,然後在改行的mutation鏈表中寫入更新資訊,在MemRowSet flush的時候,將更新合併到baseData中
如果數據在DiskRowSet中,則將更新資訊寫入DeltMemStore中,DeltMemStore達到一定大小後會flush成DeltFile。
5、更新完畢後返回消息給client。
讀流程
客戶端將要讀取的數據資訊發送給Master,Master對其進行一定的校驗,比如表是否存在,欄位是否存在。Master返回元數據資訊給client,然後client與Tablet Server建立連接,通過metaData找到數據所在的RowSet,首先載入記憶體裡面的數據(MemRowSet與DeltMemStore),然後載入磁碟裡面的數據,最後返回最終數據給client.
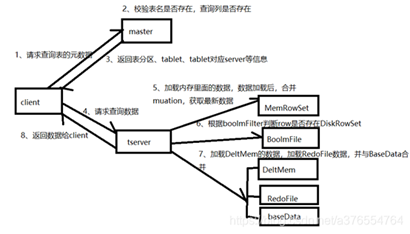
1、客戶端Master請求查詢表指定數據
2、Master對請求進行校驗,校驗表是否存在,schema中是否存在指定查詢的欄位,主鍵是否存在
3、Master通過查詢Catalog Table返回表,將tablet對應的Tablet Server資訊、Tablet Server狀態等元數據資訊返回給client
4、client與Tablet Server建立連接,通過metaData找到primary key對應的RowSet。
5、首先載入RowSet記憶體中MemRowSet與DeltMemStore中的數據
6、然後載入磁碟中的數據,也就是DiskRowSet中的BaseData與DeltFile中的數據
7、返回數據給Client
8、繼續4-7步驟,直到拿到所有數據返回給client
參考
//blog.csdn.net/nosqlnotes/article/details/79496002
//blog.csdn.net/a376554764/article/details/89445319