揭開鏈表的真面目
鏈表是一種常見的數據結構,鏈表是由一連串的結點組成,這個節點就是鏈結點,每個鏈結點都由數據域和指針域兩部分組成。
使用鏈表結構可以克服數組結構需要預先知道數據大小的缺點,鏈表結構可以充分利用電腦記憶體空間,實現靈活的記憶體動態管理。但是鏈表失去了數組隨機讀取的優點,同時鏈表由於增加了結點的指針域,空間開銷比較大。
鏈表比較好的一種理解是:將鏈表看成一個火車,每個車廂之間都是相互連接的,只要找到火車頭,就可以找到具體的車身。鏈表也是,我們只關心它的頭。
一 單向鏈表
1.1 單向鏈表原理圖
單向鏈表的一個鏈結點包含數據域和下一個鏈結點的指針。頭結點也包含數據域和指針域,但是一般為了方便查找,頭節點不寫數據,最後一個結點的指針指向空。

1.2 實現單向鏈表的存儲等操作
創建一個鏈結點的實體類
public class Node {
// 數據域
public long data;
// 指針域
public Node next;
public Node(long value){
this.data = value;
}
}
1.2.1 插入一個節點
在頭節點後插入一個結點,第一步需要將新插入的結點指向頭結點指向的結點,第二部將頭結點指向新插入的結點。插入結點只需要改變一個引用,所以複雜度為O(1)。

public class LinkList {
private Node head;
/**
* 在頭節點之後插入一個節點
*/
public void insertFirst(long value){
Node node = new Node(value);
node.next = head;
head = node;
}
}
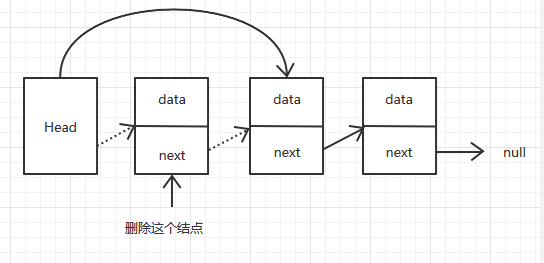
1.2.2 頭結點後刪除一個結點
在頭結點後刪除一個結點,就是讓頭結點指向這個結點的下一個結點。複雜度也是O(1)。
public Node deleteFirst(){
Node tmp = head;
head = tmp.next;
return tmp;
}
1.2.3 根據數據域查找結點
查找需要比對每個結點的數據,理論上查找一個結點平均需要N/2次,所以複雜度為O(N)。
public Node find(long value){
Node current = head;
while (current.data != value){
if(current.next == null){
return null;
}
current = current.next;
}
return current;
}
1.2.4 根據數據與刪除結點
查找需要比對每個結點的數據,理論上刪除一個結點平均需要N/2次,所以複雜度為O(N)。
public Node delete(int value){
Node current = head;
// 當前結點的前一個結點
Node pre = head;
while (current.data != value){
if(current.next == null){
return null;
}
pre = current;
current = current.next;
}
if(current == head){
head = head.next;
}else{
pre.next = current.next;
}
return current;
}
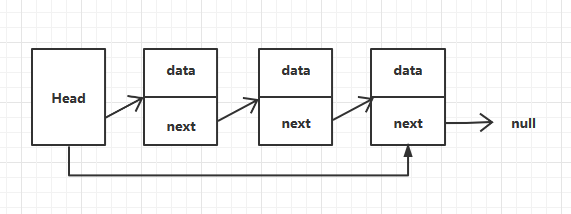
二 雙端鏈表
2.1 雙端鏈表原理圖
雙端鏈表是在單向鏈表的基礎上,頭結點增加了一個尾結點的引用。
2.2 實現雙端鏈表的存儲等操作
2.2.1 從頭部插入結點
如果鏈表為空,則設置尾結點就是新添加的結點。複雜度為O(1)。
public class FirstLastLinkList {
private Node first;
private Node last;
/**
* 在頭結點之後插入一個節點
*/
public void insertFirst(long value){
Node node = new Node(value);
if(first == null){
last = node;
}
node.next = first;
first = node;
}
}
2.2.2 從尾部插入結點
如果鏈表為空,則設置頭結點為新添加的結點,否則設置尾結點的後一個結點為新添加的結點。複雜度為O(1)。
public void insertLast(long value){
Node node = new Node(value);
if(first == null){
first = node;
}else{
last.next = node;
}
last = node;
}
2.2.3 從頭部進行刪除
判斷頭結點是否有下一個結點,如果沒有則設置尾結點為null,複雜度為O(1)。
public Node deleteFirst(){
Node tmp = first;
if(first.next == null){
last = null;
}
first = tmp.next;
return tmp;
}
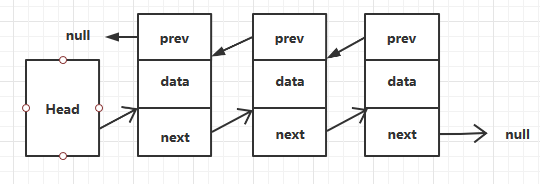
三 雙向鏈表
3.1 雙向鏈表原理圖
每個結點除了保存對後一個結點的引用外,還保存著對前一個結點的引用。
3.2 實現雙向鏈表的存儲等操作
鏈結點實體類
public class Node {
// 數據域
public long data;
// 後一個結點指針域
public Node1 next;
// 前一個結點指針域
public Node prev;
public Node(long value){
this.data = value;
}
}
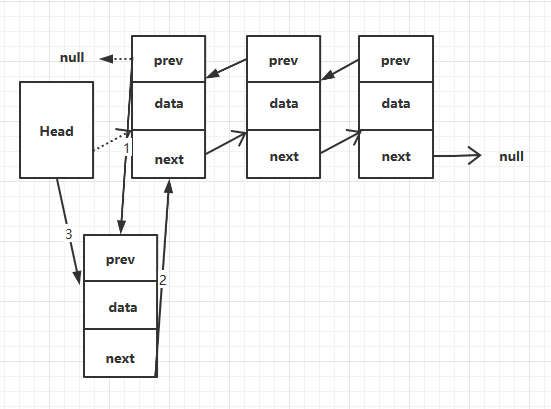
3.2.1 從頭部插入結點
如果鏈表為空,則設置尾結點為新添加的結點,如果不為空,還需要設置頭結點的前一個結點為新添加的結點。插入結點只需要改變兩個結點的引用,所以複雜度為O(1)。
public class DoubleLinkList {
private Node first;
private Node last;
/**
* 在頭結點之後插入一個節點
*/
public void insertFirst(long value){
Node node = new Node(value);
if(first == null){
last = node;
} else{
first.prev = node;
}
node.next = first;
first = node;
}
}
3.2.2 從尾部插入結點
如果鏈表為空,則設置頭結點為新添加的結點,否則設置尾結點的後一個結點為新添加的結點。同時設置新添加的結點的前一個結點為尾結點。插入結點只需要改變1個結點的引用,所以複雜度為O(1)。
public void insertLast(long value){
Node node = new Node(value);
if(first == null){
first = node;
}else{
last.next = node;
node.prev = last;
}
last = node;
}
3.2.3 從頭部刪除結點
判斷頭結點是否有下一個結點,如果沒有則設置尾結點為null,否則設置頭結點的下一個結點的prev為null。複雜度也為O(1)。
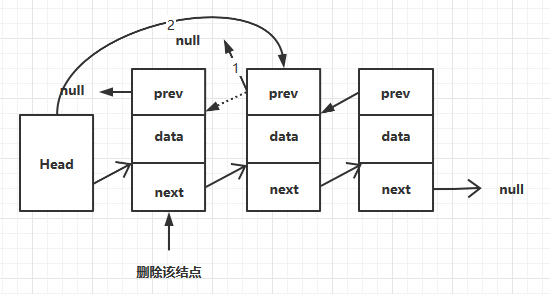
public Node deleteFirst(){
Node tmp = first;
if(first.next == null){
last = null;
}else{
first.next.prev = null;
}
first = tmp.next;
return tmp;
}
3.2.4 從尾部刪除結點
如果頭結點後沒有其他結點,則設置頭結點為null,否則設置尾結點的前一個結點的next為null,設置尾結點為前一個結點。複雜度為O(1)。
public Node deleteLast(){
Node tmp = last;
if(first.next == null){
first = null;
}else{
last.prev.next = null;
}
last = last.prev;
return last;
}
四 總結
鏈表包含一個頭結點和多個結點,頭結點包含一個引用,這個引用通常叫做first,它指向鏈表的第一個鏈結點。結點的next為null,則意味著這個結點時尾結點。與數組相比,鏈表更適合做插入、刪除操作,而查找操作的複雜度更高。還有一個優勢就是鏈表不需要初始化記憶體大小,不會造成記憶體溢出(數組中插入元素個數超過數組長度)或記憶體浪費(聲明的數組長度比實際放的元素長)。
點關注、不迷路
如果覺得文章不錯,歡迎關注、點贊、收藏,你們的支援是我創作的動力,感謝大家。
如果文章寫的有問題,請不要吝嗇,歡迎留言指出,我會及時核查修改。
如果你還想更加深入的了解我,可以微信搜索「Java旅途」進行關注。回復「1024」即可獲得學習影片及精美電子書。每天7:30準時推送技術文章,讓你的上班路不在孤獨,而且每月還有送書活動,助你提升硬實力!


