Elasticsearch數據遷移與集群容災
- 2019 年 10 月 29 日
- 筆記
本文討論如何跨集群遷移ES數據以及如何實現ES的同城跨機房容災和異地容災。
跨集群數據遷移
在ES的生產實踐中,往往會遇到以下問題:
- 一個運行了較長時間的ES集群,因為物理設備老化,需要把數據遷移到一個使用新機器搭建的ES集群中
- 業務計划上雲,要把自建的ES集群數據遷移到雲廠商的ES集群中
根據業務需求,存在以下場景:
- 遷移過程中,舊的集群可以暫時停止服務或者暫停寫入,數據全部遷移到新的集群中後,業務切換到新的集群進行讀取和寫入
- 遷移過程中,舊集群不能停止寫入,業務不能停服
如果是第一種場景,數據遷移過程中可以停止寫入,可以採用諸如elasticsearch-dump、logstash、reindex、snapshot等方式進行數據遷移。實際上這幾種工具大體上可以分為兩類:
- scroll query + bulk: 批量讀取舊集群的數據然後再批量寫入新集群,elasticsearch-dump、logstash、reindex都是採用這種方式
- snapshot: 直接把舊集群的底層的文件進行備份,在新的集群中恢復出來,相比較scroll query + bulk的方式,snapshot的方式遷移速度最快。
如果是第二種場景,數據遷移過程中舊集群不能停止寫入,需要根據實際的業務場景解決數據一致性的問題:
- 如果業務不是直接寫ES, 而是把數據寫入到了中間件,比如業務->kafka->logstash->es的架構,此時可以直接採用雙寫的策略,舊集群不停止讀寫,新的集群也直接寫入,然後遷移舊集群的數據到新集群中去,等數據追平之後,新的集群再提供讀服務;
- 如果業務是直接寫ES, 並且會進行刪除doc操作;此時可以使用ES官方在6.5版本之後的CCR(跨集群複製)功能,把舊集群作為Leader, 新集群作為Follower, 舊集群不停止讀寫,新集群從舊集群中follow新寫入的數據;另一方面使用第三方工具把存量的舊集群中的數據遷移到新集群中,存量數據遷移完畢後,業務再切換到新的集群進行讀寫。
數據遷移時可以停止舊集群的寫入
下面介紹一下在舊集群可以停止寫入的情況下進行數據遷移的幾種工具的用法。
elasticsearch-dump
elasticsearch-dump是一款開源的ES數據遷移工具,github地址: https://github.com/taskrabbit/elasticsearch-dump
1 安裝elasticsearch-dump
elasticsearch-dump使用node.js開發,可使用npm包管理工具直接安裝:
npm install elasticdump -g
2 主要參數說明
--input: 源地址,可為ES集群URL、文件或stdin,可指定索引,格式為:{protocol}://{host}:{port}/{index} --input-index: 源ES集群中的索引 --output: 目標地址,可為ES集群地址URL、文件或stdout,可指定索引,格式為:{protocol}://{host}:{port}/{index} --output-index: 目標ES集群的索引 --type: 遷移類型,默認為data,表明只遷移數據,可選settings, analyzer, data, mapping, alias
3 遷移單個索引
以下操作通過elasticdump命令將集群172.16.0.39中的companydatabase索引遷移至集群172.16.0.20。注意第一條命令先將索引的settings先遷移,如果直接遷移mapping或者data將失去原有集群中索引的配置資訊如分片數量和副本數量等,當然也可以直接在目標集群中將索引創建完畢後再同步mapping與data
elasticdump --input=http://x.x.x.1:9200/companydatabase --output=http://x.x.x.2:9200/companydatabase --type=settings elasticdump --input=http://x.x.x.1:9200/companydatabase --output=http://x.x.x.2:9200/companydatabase --type=mapping elasticdump --input=http://x.x.x.1:9200/companydatabase --output=http://x.x.x.2:9200/companydatabase --type=data
4 遷移所有索引:以下操作通過elasticdump命令將將集群x.x.x.1中的所有索引遷移至集群x.x.x.2。 注意此操作並不能遷移索引的配置如分片數量和副本數量,必須對每個索引單獨進行配置的遷移,或者直接在目標集群中將索引創建完畢後再遷移數據
elasticdump --input=http://x.x.x.1:9200 --output=http://x.x.x.2:9200
logstash
logstash支援從一個ES集群中讀取數據然後寫入到另一個ES集群,因此可以使用logstash進行數據遷移,具體的配置文件如下:
input { elasticsearch { hosts => ["http://x.x.x.1:9200"] index => "*" docinfo => true } } output { elasticsearch { hosts => ["http://x.x.x.2:9200"] index => "%{[@metadata][_index]}" } }
上述配置文件將源ES集群的所有索引同步到目標集群中,當然可以設置只同步指定的索引,logstash的更多功能可查閱logstash官方文檔 logstash 官方文檔.
reindex
reindex是Elasticsearch提供的一個api介面,可以把數據從一個集群遷移到另外一個集群。
1 配置reindex.remote.whitelist參數
需要在目標ES集群中配置該參數,指明能夠reindex的遠程集群的白名單
2 調用reindex api
以下操作表示從源ES集群中查詢名為test1的索引,查詢條件為title欄位為elasticsearch,將結果寫入當前集群的test2索引
POST _reindex { "source": { "remote": { "host": "http://x.x.x.1:9200" }, "index": "test1", "query": { "match": { "title": "elasticsearch" } } }, "dest": { "index": "test2" } }
snapshot
snapshot api是Elasticsearch用於對數據進行備份和恢復的一組api介面,可以通過snapshot api進行跨集群的數據遷移,原理就是從源ES集群創建數據快照,然後在目標ES集群中進行恢復。需要注意ES的版本問題:
- 目標ES集群的主版本號(如5.6.4中的5為主版本號)要大於等於源ES集群的主版本號;
- 1.x版本的集群創建的快照不能在5.x版本中恢復;
1 源ES集群中創建repository
創建快照前必須先創建repository倉庫,一個repository倉庫可以包含多份快照文件,repository主要有一下幾種類型
fs: 共享文件系統,將快照文件存放於文件系統中 url: 指定文件系統的URL路徑,支援協議:http,https,ftp,file,jar s3: AWS S3對象存儲,快照存放於S3中,以插件形式支援(repository-s3) hdfs: 快照存放於hdfs中,以插件形式支援(repository-hdfs) cos: 快照存放於騰訊雲COS對象存儲中,以插件形式支援(repository-cos)
以repository-cos為例,創建倉庫:
PUT _snapshot/my_cos_backup { "type": "cos", "settings": { "app_id": "xxxxxxx", "access_key_id": "xxxxxx", "access_key_secret": "xxxxxxx", "bucket": "xxxxxx", "region": "ap-guangzhou", "compress": true, "chunk_size": "500mb", "base_path": "/" } }
2 源ES集群中創建snapshot
調用snapshot api在創建好的倉庫中創建快照
curl -XPUT http://x.x.x.1:9200/_snapshot/my_backup/snapshot_1?wait_for_completion=true
創建快照可以指定索引,也可以指定快照中包含哪些內容,具體的api介面參數可以查閱官方文檔官方文檔
3 目標ES集群中創建repository
目標ES集群中創建倉庫和在源ES集群中創建倉庫類似,用戶可在騰訊雲上創建COS對象bucket, 將倉庫建在COS的某個bucket下。
4 移動源ES集群snapshot至目標ES集群的倉庫
把源ES集群創建好的snapshot上傳至目標ES集群創建好的倉庫中
5 從快照恢復
curl -XPUT http://x.x.x.2:9200/_snapshot/my_backup/snapshot_1/_restore
6 查看快照恢復狀態
curl http://x.x.x.2:9200/_snapshot/_status
數據遷移時不能停止舊集群的寫入
如果舊集群不能停止寫入,此時進行在線數據遷移,需要保證新舊集群的數據一致性。目前看來,除了官方提供的CCR功能,沒有成熟的可以嚴格保證數據一致性的在線數據遷移方法。此時可以從業務場景出發,根據業務寫入數據的特點選擇合適的數據遷移方案。
一般來說,業務寫入數據的特點有以下幾種:
- add only, 只追加新數據,比如日誌、APM場景中,數據基本都是時序數據,只會追加,沒有更新、刪除數據的操作
- add & update, 數據有追加也有更新,但是沒有刪除數據的操作
- add & update & delete, 數據有追加,也有更新和刪除,搜索場景比較常見
下面來具體分析不同的寫入數據的特點下,該如何選擇合適的數據遷移方式。
add only
在日誌或者APM的場景中,數據都是時序數據,一般索引也都是按天創建的,當天的數據只會寫入當前的索引中。此時,可以先把存量的不再寫入的索引數據一次性同步到新集群中,然後使用logstash或者其它工具增量同步當天的索引,待數據追平後,把業務對ES的訪問切換到新集群中。
具體的實現方案為:
- 全量遷移冷索引 因為冷的索引不再寫入,可以採用elasticdump、logstash、reindex進行遷移;如果數據量比較大的情況下,可以採用snapshot方式進行遷移。
- 增量遷移熱索引
add only的數據寫入方式,可以按照數據寫入的順序(根據_doc進行排序,如果有時間戳欄位也可以根據時間戳排序)批量從舊集群中拉取數據,然後再批量寫入新集群中;可以通過寫程式,使用用scroll api 或者search_after參數批量拉取增量數據,再使用bulk api批量寫入。
使用scroll拉取增量數據:
POST {my_index}/_search?scroll=1m { "size":"100", "query": { "range": { "timestamp": { "gte": "now-1m", "lt": "now/m" } } } } POST _search/scroll { "scroll": "1m", "scroll_id": "DnF1ZXJ5VGhlbkZldGNoBQAAAAAAHCbaFndPR3J4bDJtVDh1bnNRaW5yYWZBWncAAAAAABwm2RZ3T0dyeGwybVQ4dW5zUWlucmFmQVp3AAAAAAAcJtwWd09HcnhsMm1UOHVuc1FpbnJhZkFadwAAAAAAHCbbFndPR3J4bDJtVDh1bnNRaW5yYWZBWncAAAAAABwm3RZ3T0dyeGwybVQ4dW5zUWlucmFmQVp3" }
上述操作可以每分鐘執行一次,拉起前一分鐘新產生的數據,所以數據在舊集群和新集群的同步延遲為一分鐘。
使用search_after批量拉取增量數據:
POST {my_index}/_search { "size":100, "query": { "match_all": {} }, "search_after": [ 1569556667000 ], "sort": "timestamp" }
上述操作可以根據需要自定義事件間隔執行,每次執行時修改search_after參數的值,獲取指定值之後的多條數據;search_after實際上相當於一個游標,每執行一次向前推進,從而獲取到最新的數據。
使用scroll和search_after的區別是:
- scroll相當於對數據做了一份快照,快照會保存在記憶體中,會比較消耗資源;search_after是無狀態的,並不會過多的消耗記憶體資源。
- scroll可以分批次執行,search_after獲取到的結果只能一次拉取完,所以需要合理控制search_after參數的值以及size的大小,以免出現一次拉取過多的數據導致記憶體暴漲。
- scroll執行過程中並不能獲取到更新後的數據(對add only的場景並無影響),search_after每次拉取到的數據都是最新的。
另外,如果不想通過寫程式遷移舊集群的增量數據到新集群的話,可以使用logstash結合scroll進行增量數據的遷移,可參考的配置文件如下:
input { elasticsearch { hosts => "x.x.x.1:9200" index => "my_index" query => '{"query":{"range":{"timestamp":{"gte":"now-1m","lt":"now/m"}}}}' size => 100 scroll => "1m" docinfo => true schedule => "*/1 * * * *" #定時任務,每分鐘執行一次 } } output { elasticsearch { hosts => "x.x.x.2:9200" index => "%{[@metadata][_index]}" document_type => "%{[@metadata][_type]}" document_id => "%{[@metadata][_id]}" } }
使用過程中可以根據實際業務的需求調整定時任務參數schedule以及scroll相關的參數。
add & update
業務場景如果是寫入ES時既有追加,又有存量數據的更新,此時比較重要的是怎麼解決update操作的數據同步問題。對於新增的數據,可以採用上述介紹的增量遷移熱索引的方式同步到新集群中。對於更新的數據,此時如果索引有類似於updateTime的欄位用於標記數據更新的時間,則可以通過寫程式或者logstash,使用scroll api根據updateTime欄位批量拉取更新的增量數據,然後再寫入到新的集群中。
可參考的logstash配置文件如下:
input { elasticsearch { hosts => "x.x.x.1:9200" index => "my_index" query => '{"query":{"range":{"updateTime":{"gte":"now-1m","lt":"now/m"}}}}' size => 100 scroll => "1m" docinfo => true schedule => "*/1 * * * *" #定時任務,每分鐘執行一次 } } output { elasticsearch { hosts => "x.x.x.2:9200" index => "%{[@metadata][_index]}" document_type => "%{[@metadata][_type]}" document_id => "%{[@metadata][_id]}" } }
實際應用各種,同步新增(add)的數據和更新(update)的數據可以同時進行。但是如果索引中沒有類似updateTime之類的欄位可以標識出哪些數據是更新過的,目前看來並沒有較好的同步方式,可以採用CCR來保證舊集群和新集群的數據一致性。
add & update & delete
如果業務寫入ES時既有新增(add)數據,又有更新(update)和刪除(delete)數據,可以採用6.5之後商業版X-pack插件中的CCR功能進行數據遷移。但是使用CCR有一些限制,必須要注意:
- 舊集群和新集群的版本必須都在6.5及以上才能使用
- Leader Index必須開啟index.soft_deletes.enabled, 否則不能使用CCR, 該參數的意義是打開後Leader Index中的所有操作都會被暫存下來,Follower Index 可以通過pull這些操作然後進行重放,從而達到數據同步的目的;另外index.soft_deletes.enabled也只能在6.5之後的版本使用,並且只能在創建索引時開啟,如果沒有開啟的話可以通過reindex到新的索引解決。
具體的使用方式如下:
1 在新集群中配置舊集群的地址,注意必須為transport埠
PUT /_cluster/settings { "persistent" : { "cluster" : { "remote" : { "leader" : { "seeds" : [ "x.x.x.1:9300" ] } } } } }
2 創建Leader Index
PUT my_leader_indx { "settings":{ "index.soft_deletes.enabled": true } }
3 創建Follower Index
PUT my_follower_index/_ccr/follow?wait_for_active_shards=1 { "remote_cluster" : "leader", "leader_index" : "my_leader_indx" }
4 查看Follower Index統計資訊
GET my_follower_index/_ccr/stats
使用中間件進行雙寫
如果業務是通過中間件如kafka把數據寫入到ES, 則可以使用如下圖中的方式,使用logstash消費kafka的數據到新集群中,在舊集群和新集群數據完全追平之後,可以切換到新集群進行業務的查詢,之後再對舊的集群下線處理。
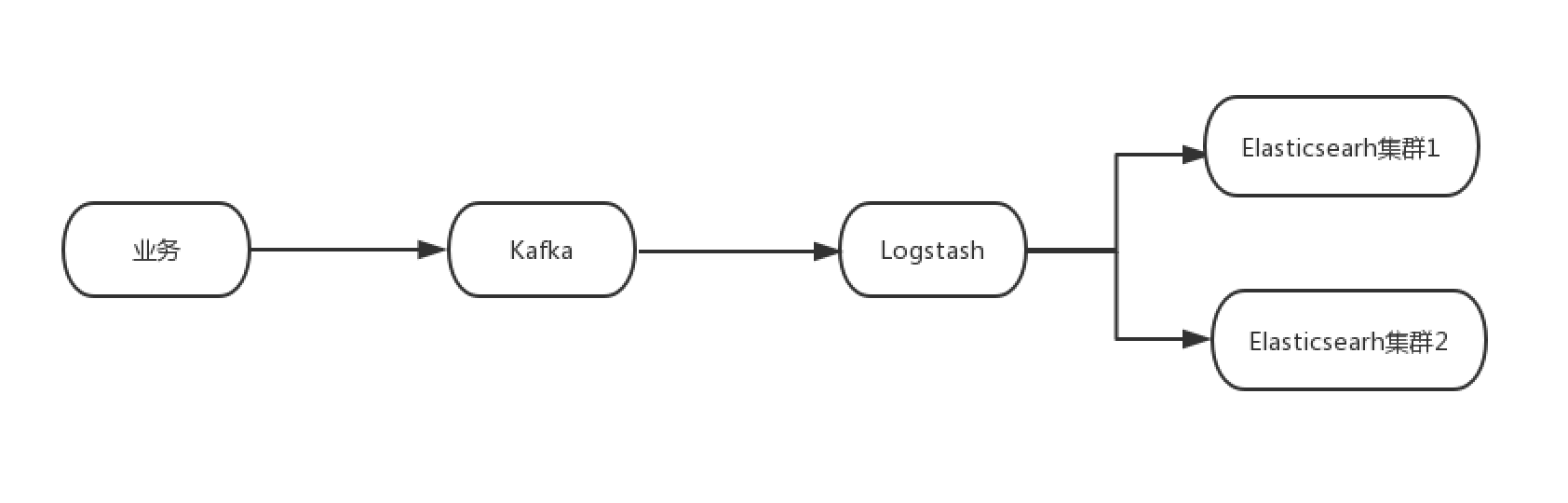
使用中間件進行同步雙寫的優點是:
- 寫入過程中丟失數據風險較低
- 可以保證新舊集群的數據一致性
當然,雙寫也可以使用其他的方式解決,比如自建proxy,業務寫入時向proxy寫入,proxy把請求轉發到一個或者多個集群中,但是這種方式存在以下問題:
- proxy的性能會影響數據寫入的性能
- proxy故障可能會丟失數據,需要有一套完善的機制保證proxy的可用性
Elasticsearch跨機房容災
隨著業務規模的增長,業務側對使用的ES集群的數據可靠性、集群穩定性等方面的要求越來越高,所以要比較好的集群容災方案支援業務側的需求。
同城跨機房容災:主備集群
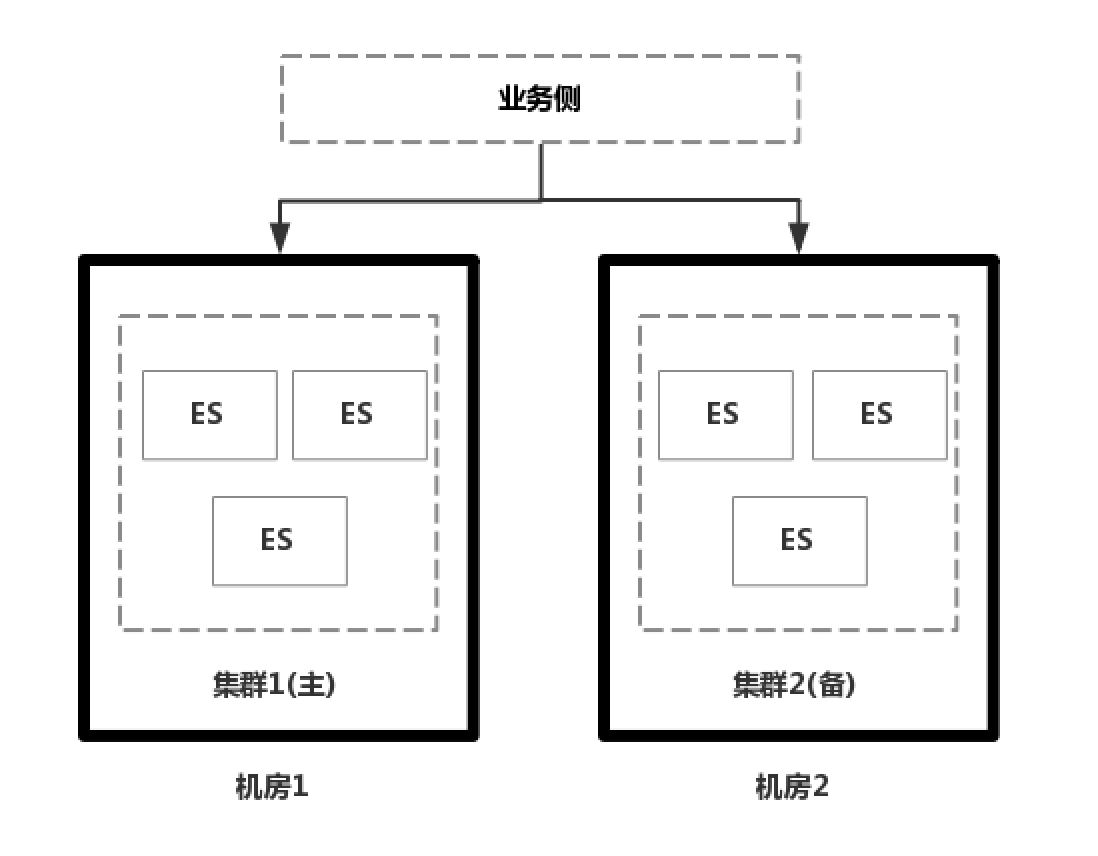
如果是公司在自建IDC機房內,通過物理機自己搭建的ES集群,在解決跨機房容災的時候,往往會在兩個機房 部署兩個ES集群,一主一備,然後解決解決數據同步的問題;數據同步一般有兩種方式,一種方式雙寫,由業務側實現雙寫保證數據一致性,但是雙寫對業務側是一個挑戰,需要保證數據在兩個集群都寫成功才能算成功。另外一種方式是非同步複製,業務側只寫主集群,後台再把數據同步到備集群中去,但是比較難以保證數據一致性。第三種方式是通過專線打通兩個機房,實現跨機房部署,但是成本較高。
同城跨機房容災:跨機房部署集群
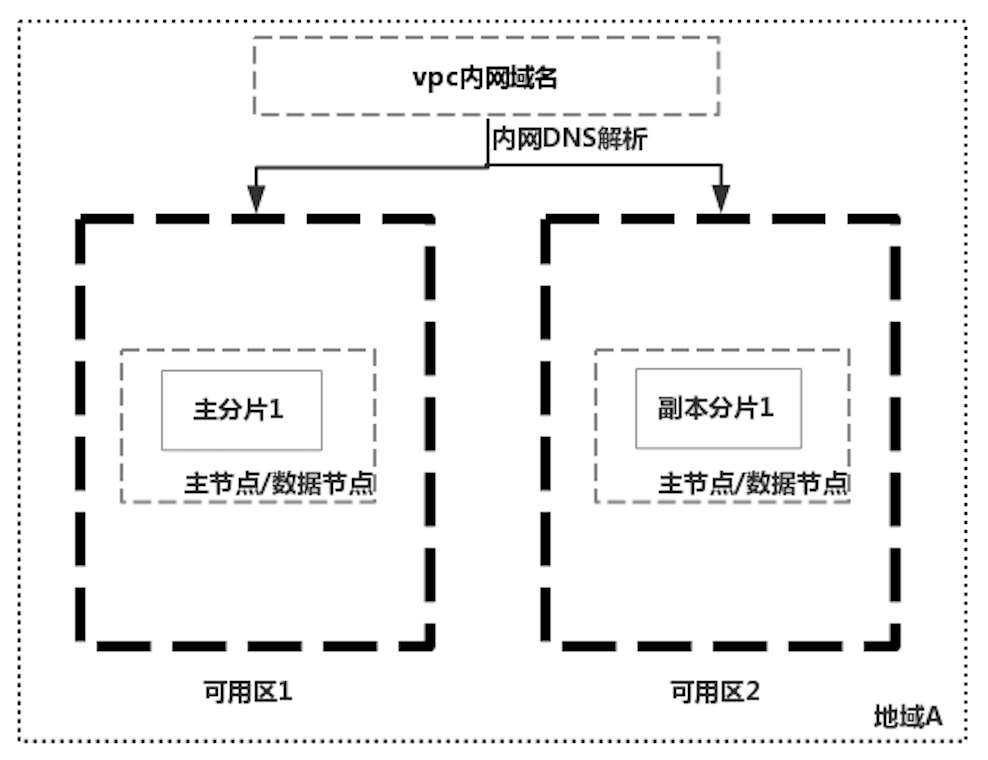
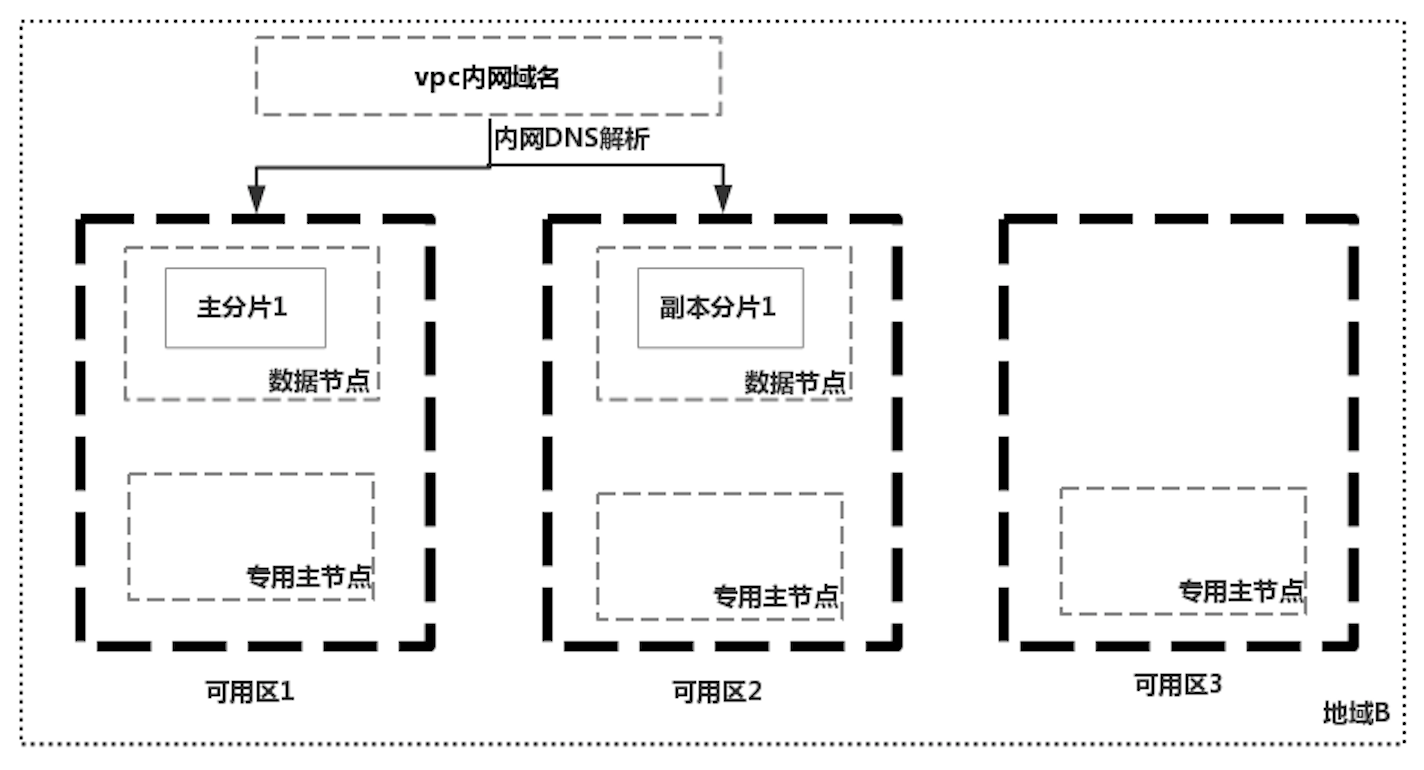
因為數據同步的複雜性,雲廠商在實現ES集群跨機房容災的時候,往往都是通過只部署一個集群解決,利用ES自身的能力同步數據。國外某雲廠商實現跨機房部署ES集群的特點1是不強制使用專用主節點,如上圖中的一個集群,只有兩個節點,既作為數據節點也作為候選主節點;主分片和副本分片分布在兩個可用區中,因為有副本分片的存在,可用區1掛掉之後集群仍然可用,但是如果兩個可用區之間網路中斷時,會出現腦裂的問題。如下圖中使用三個專用主節點,就不會存在腦裂的問題了。
但是如果一個地域沒有三個可用區怎麼辦呢,那就只能在其中一個可用區中放置兩個專用主節點了,如中國某雲廠商的解決方案:
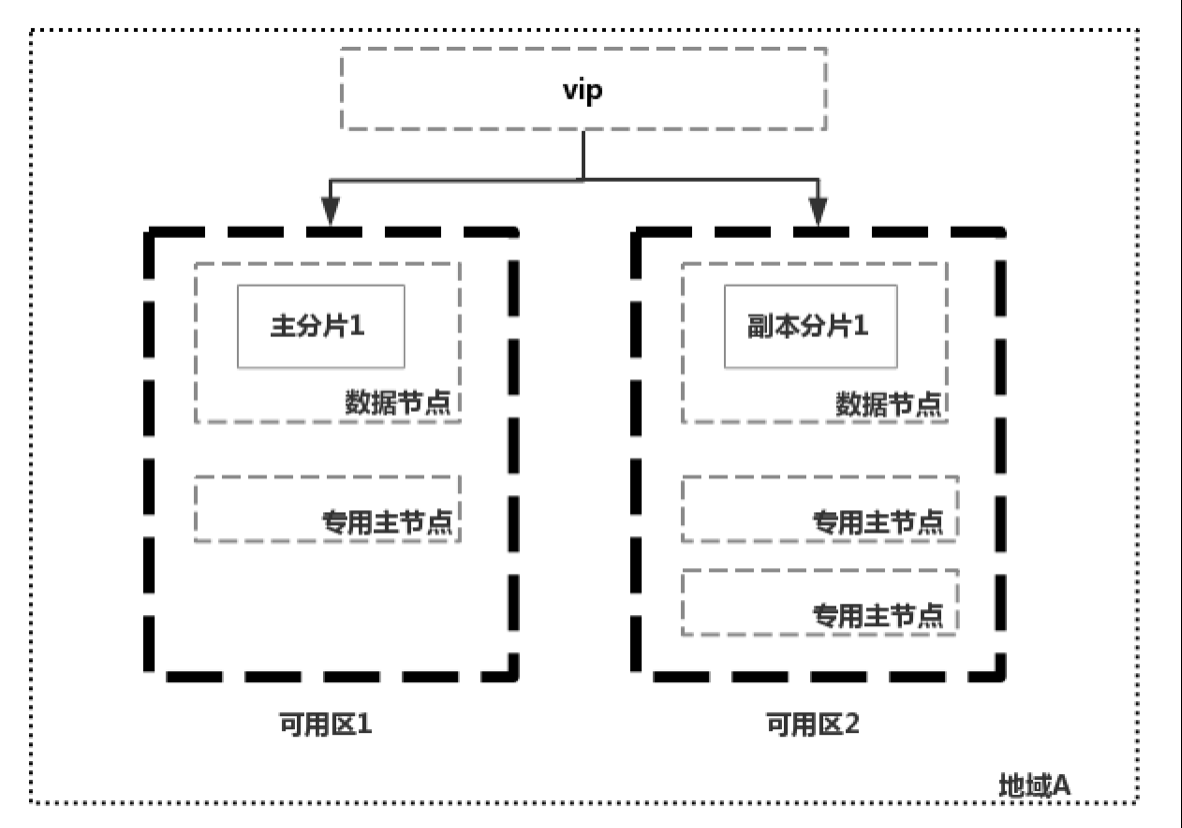
中國某雲廠商的做法是不管當前地域有幾個可用區,只要用戶只選擇在兩個可用區創建集群,那集群的節點必然只分布在兩個可用區中。但是這樣會引發集群無法選主的問題。比如上圖中的集群,如果可用區2掛掉,就只剩一個主節點了,不能滿足quorum法定票數, 無法選主了,這時候集群就不可用了。針對可能發生的腦裂和無法選主這兩個問題,國外某雲廠商和中國某雲廠商的解決辦法是進行故障恢復,重建節點。
但是重建節點的過程還是存在問題的,如上圖中,集群本身的quorum應該為2,可用區1掛掉後,集群中只剩一個專用主節點,需要把quorum參數(discovery.zen.minimum_master_nodes)調整為1後集群才能夠正常進行選主,等掛掉的兩個專用主節點恢復之後,需要再把quorum參數(discovery.zen.minimum_master_nodes)調整為2,以避免腦裂的發生。
當然還是有可以把無法選主和腦裂這兩個可能發生的問題規避掉的解決方案,如下圖中中國某雲廠商的解決思路:
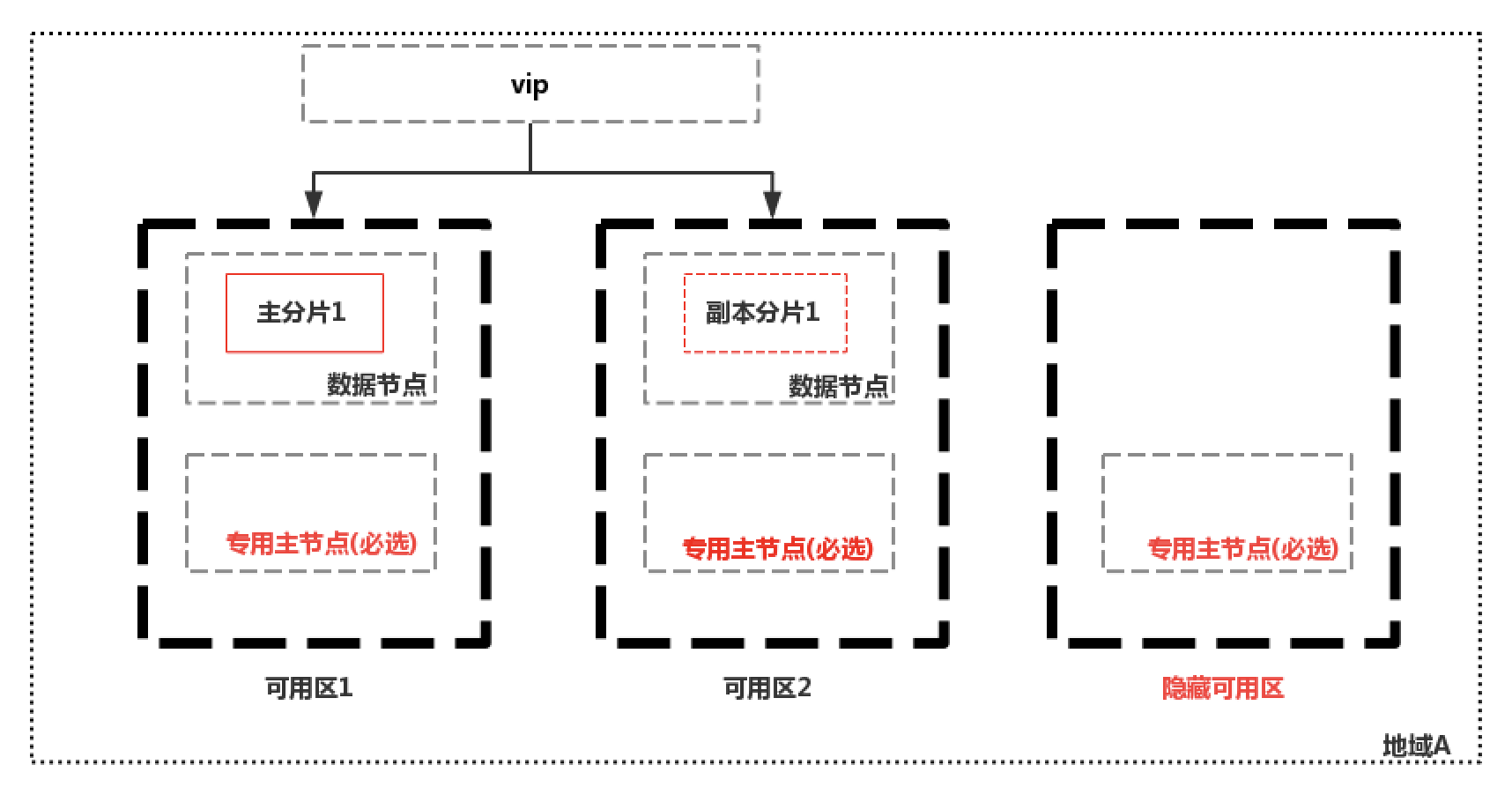
創建雙可用區集群時,必須選擇3個或者5個專用主節點,後台會在一個隱藏的可用區中只部署專用主節點;方案的優點1是如果一個可用區掛掉,集群仍然能夠正常選主,避免了因為不滿足quorum法定票數而無法選主的情況;2是因為必須要選擇三個或5個專用主節點,也避免了腦裂。
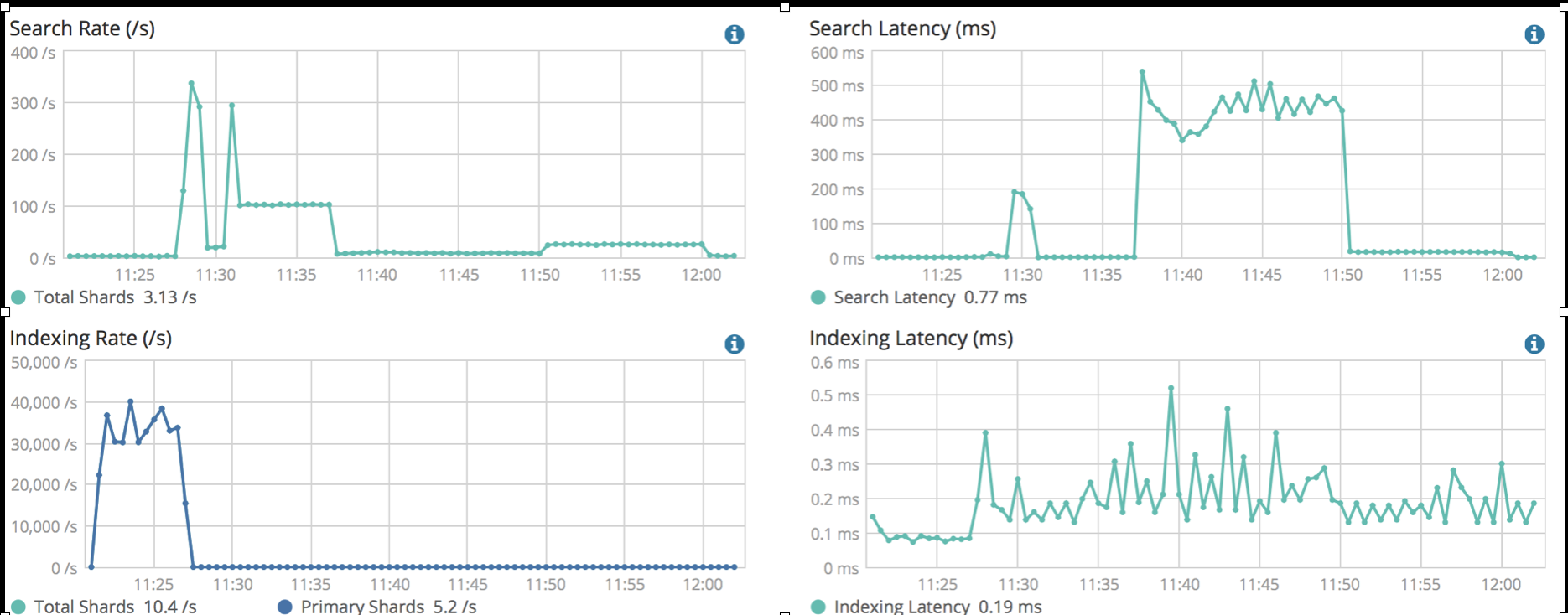
想比較一主一備兩個集群進行跨機房容災的方式,雲廠商通過跨機房部署集群把原本比較複雜的主備數據同步問題解決了,但是,比較讓人擔心的是,機房或者可用區之間的網路延遲是否會造成集群性能下降。這裡針對騰訊雲的雙可用區集群,使用標準的benchmark工具對兩個同規格的單可用區和雙可用區集群進行了壓測,壓測結果如下圖所示:
- 多可用區集群:
- 單可用區集群:
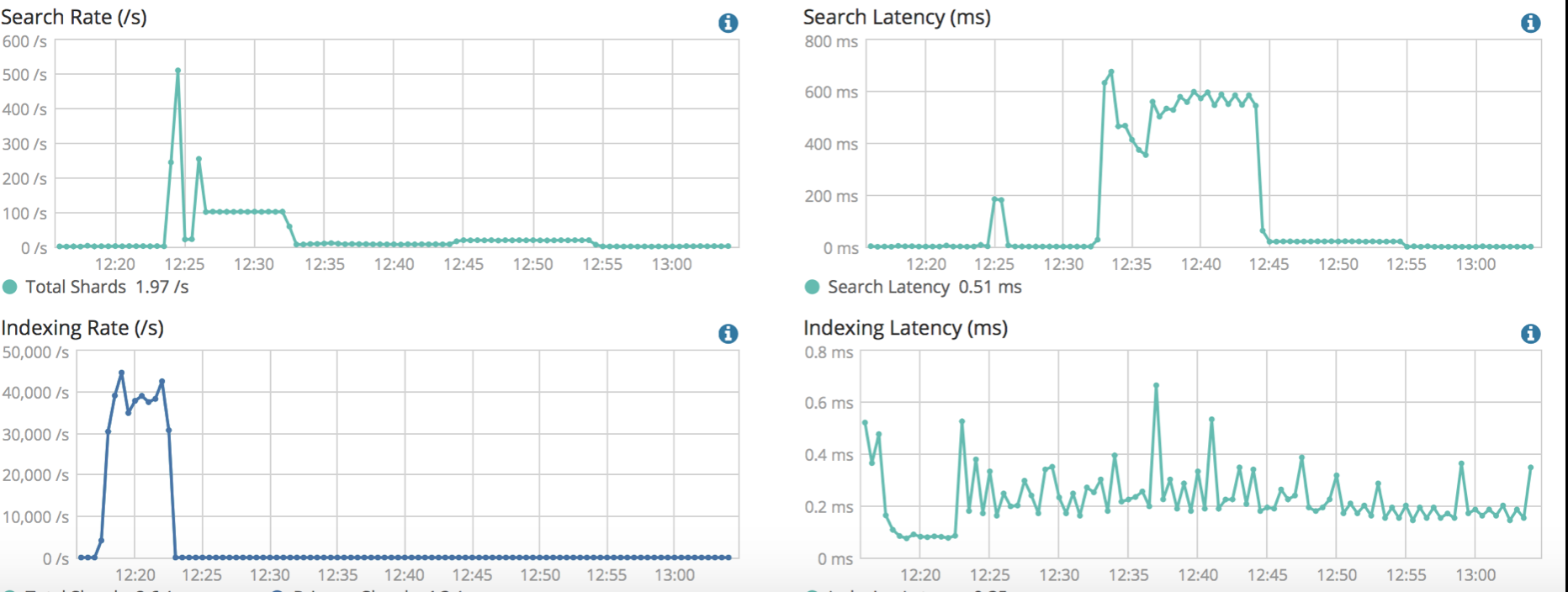
從壓測結果的查詢延時和寫入延時指標來看,兩種類型的集群並沒有明顯的差異,這主要得益與雲上底層網路基礎設施的完善,可用區之間的網路延遲很低。
異地容災:主備集群
類似於同城跨機房容災,異地容災一般的解決思路是在異地兩個機房部署一主一備兩個集群。業務寫入時只寫主集群,再非同步地把數據同步到備集群中,但是實現起來會比較複雜,因為要解決主備集群數據一致性的問題,並且跨地域的話,網路延遲會比較高;還有就是,當主集群掛掉之後,這時候切換到備集群,可能兩邊數據還沒有追平,出現不一致,導致業務受損。當然,可以藉助於kafka等中間件實現雙寫,但是數據鏈路增加了,寫入延遲也增加了,並且kafka出現問題,故障可能就是災難性的了。
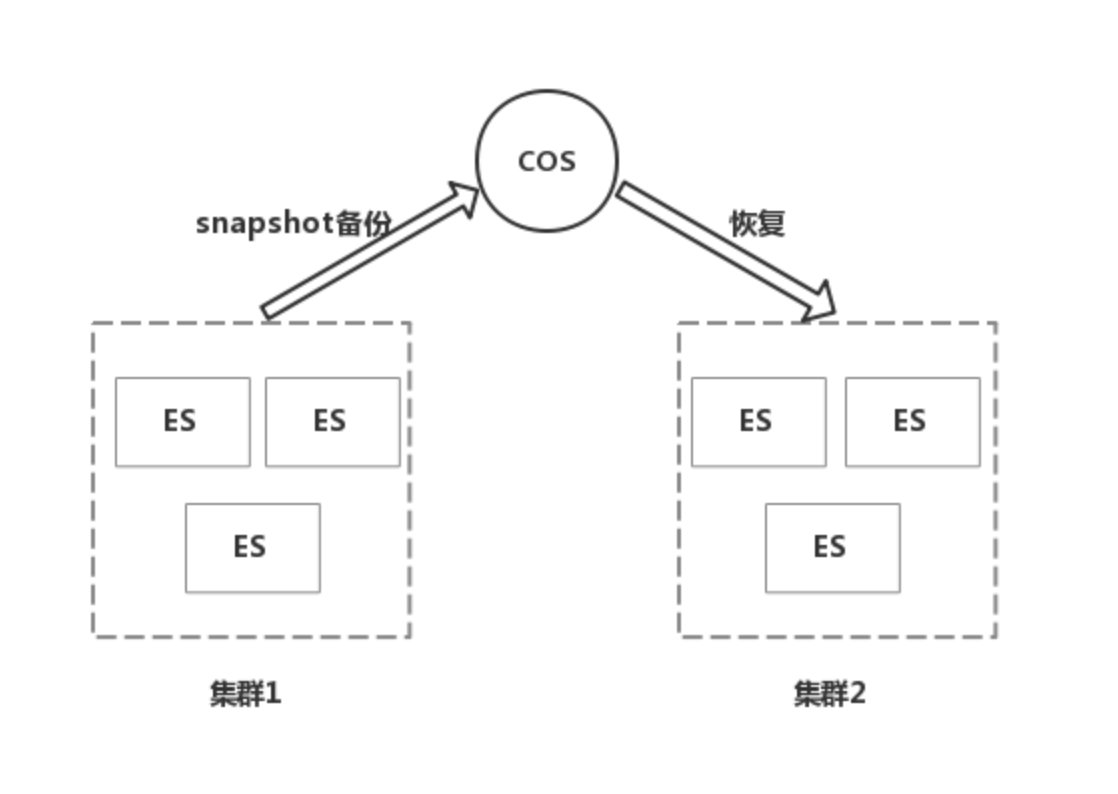
一種比較常見的非同步複製方法是,使用snapshot備份功能,定期比如每個小時在主集群中執行一次備份,然後在備集群中進行恢復,但是主備集群會有一個小時的數據延遲。以騰訊云為例,騰訊雲的ES集群支援把數據備份到對象存儲COS中,因為可以用來實現主備集群的數據同步,具體的操作步驟可以參考https://cloud.tencent.com/document/product/845/19549。
在6.5版本官方推出了CCR功能之後,集群間數據同步的難題就迎刃而解了。可以利用CCR來實現ES集群的異地容災:
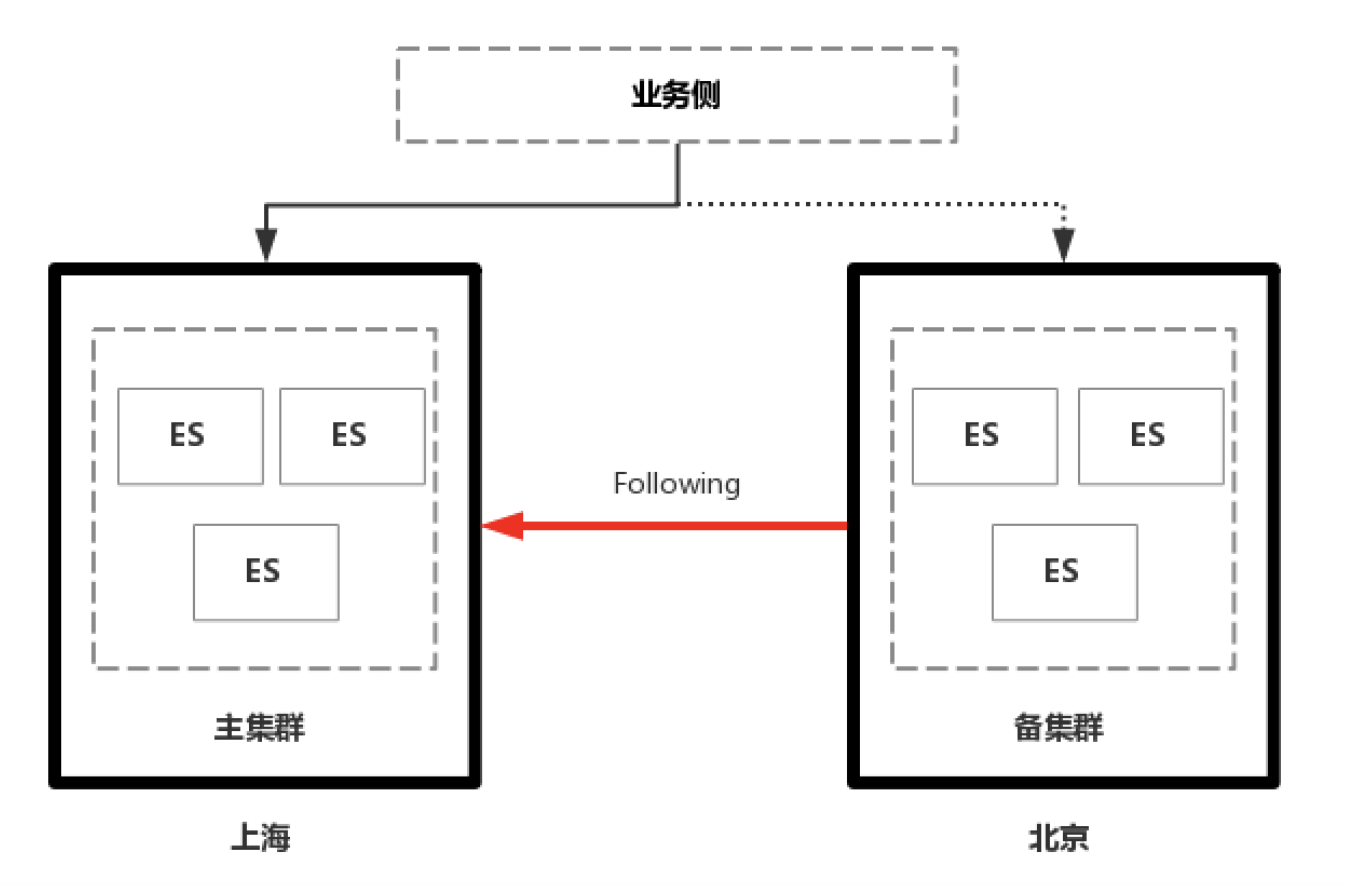
CCR是類似於數據訂閱的方式,主集群為Leader, 備集群為Follower, 備集群以pull的方式從主集群拉取數據和寫請求;在定義好Follwer Index時,Follwer Index會進行初始化,從Leader中以snapshot的方式把底層的segment文件全量同步過來,初始化完成之後,再拉取寫請求,拉取完寫請求後,Follwer側進行重放,完成數據的同步。CCR的優點當然是因為可以同步UPDATE/DELETE操作,數據一致性問題解決了,同步延時也減小了。
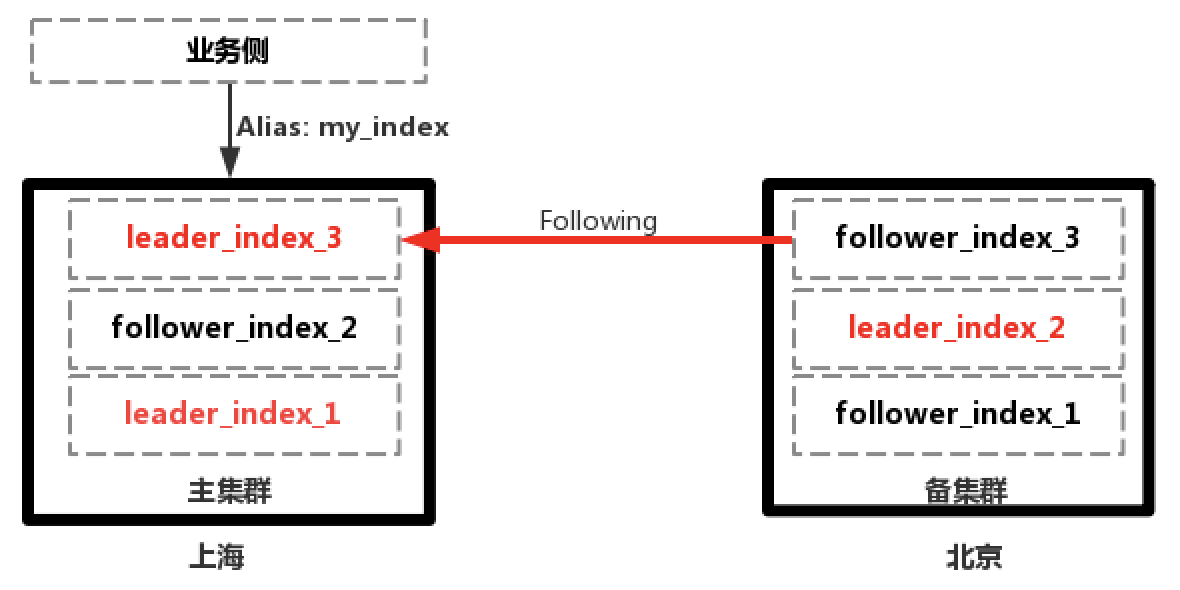
另外,基於CCR可以和前面提到的跨機房容災的集群結合,實現兩地多中心的ES集群。在上海地域,部署有多可用區集群實現跨機房的高可用,同時在北京地域部署備集群作為Follwer利用CCR同步數據,從而在集群可用性上又向前走了一步,既實現了同城跨機房容災,又實現了跨地域容災。
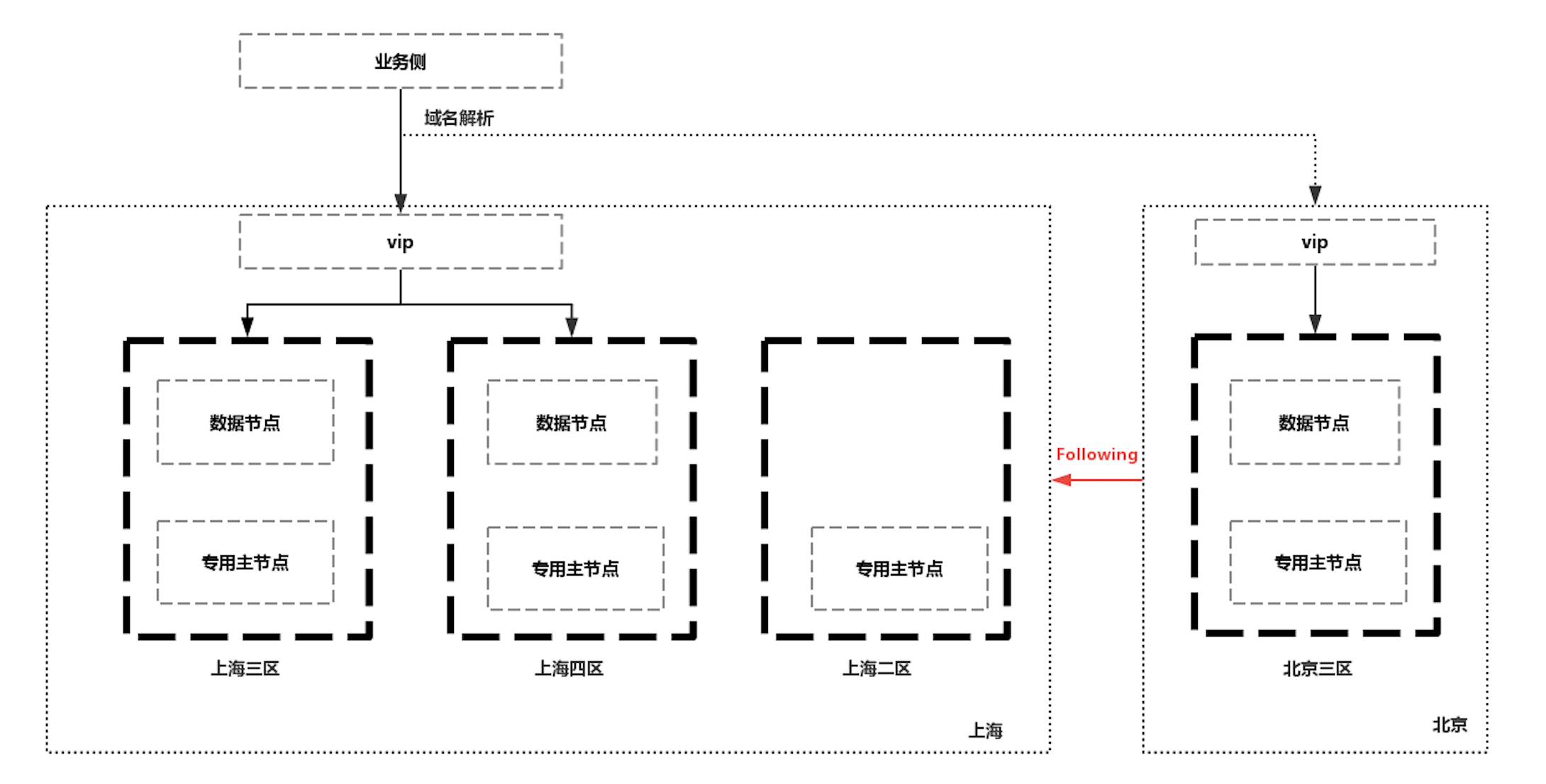
但是在出現故障時需要把集群的訪問從上海切換到北京時,會有一些限制,因為CCR中的Follwer Index是只讀的,不能寫入,需要切換為正常的索引才能進行寫入,過程也是不可逆的。不過在業務側進行規避,比如寫入時使用新的正常的索引,業務使用別名進行查詢,當上海地域恢復時,再反向的把數據同步回去。
POST /<follower_index>/_ccr/pause_follow POST /<follower_index>/_close POST /<follower_index>/_ccr/unfollow POST /<follower_index>/_open
現在問題就是保證上海地域集群數據的完整性,在上海地域恢復後,可以在上海地域新建一個Follower Index,以北京地域正在進行寫的索引為Leader同步數據,待數據完全追平後,再切換到上海地域進行讀寫,注意切換到需要新建Leader索引寫入數據。
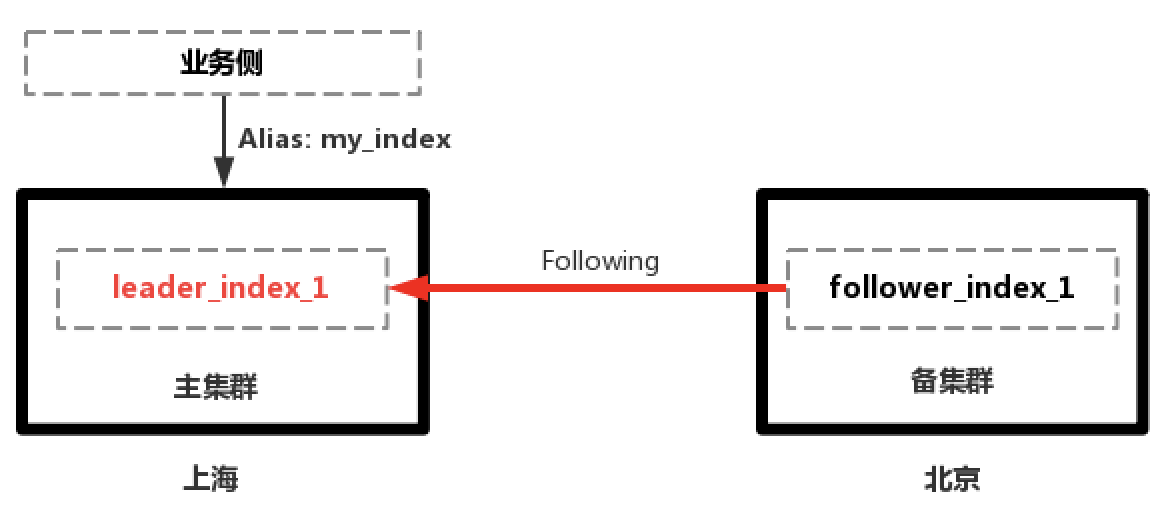
數據同步過程如下所示:
1.上海主集群正常提供服務,北京備集群從主集群Follow數據
2.上海主集群故障,業務切換到北京備集群進行讀寫,上海主集群恢復後從北京集群Follow數據
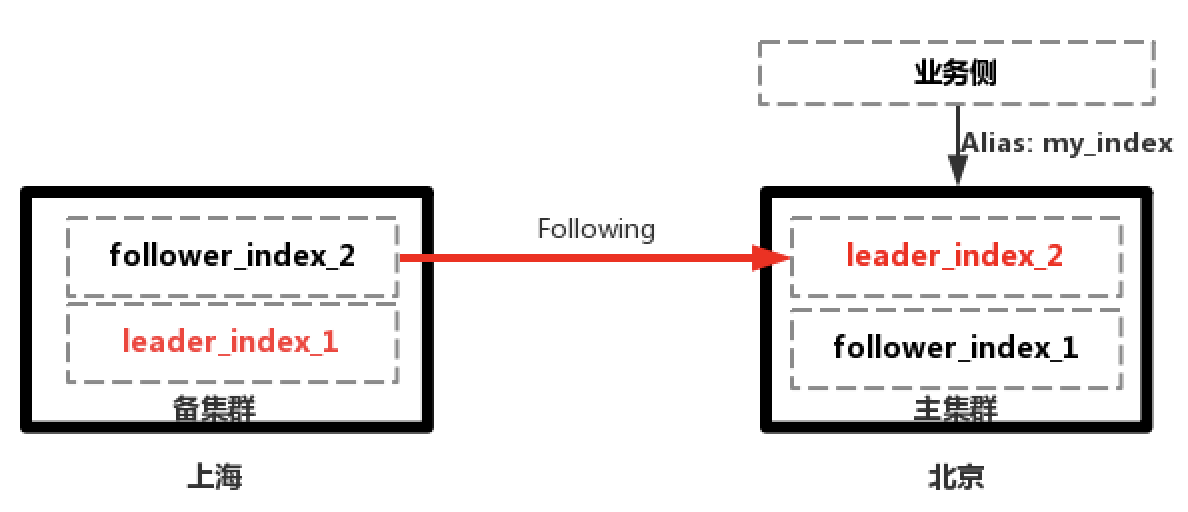
3.主備集群數據追平後,業務切換到上海集群進行讀寫