MySQL的B+Tree索引
- 2019 年 10 月 3 日
- 筆記
為什麼要使用索引?
最簡單的方式實現數據查詢:全表掃描,即將整張表的數據全部或者分批次載入進記憶體,由於存儲的最小單位是塊或者頁,它們是由多行數據組成,然後逐塊逐塊或者逐頁逐頁地查找,這樣查找的速度非常慢。優點:在數據量小比如只有幾十行數據的情況下很快。但數據量大時不適用。更通常情況下,我們應該避免全表掃描,我們可以通過索引來大幅提升查詢數據的速度。
什麼資訊能夠成為索引?
能把記錄限制在一定查找範圍內的欄位,比如鍵,唯一鍵,主鍵等


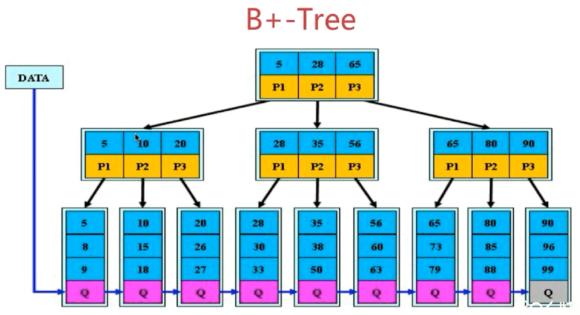

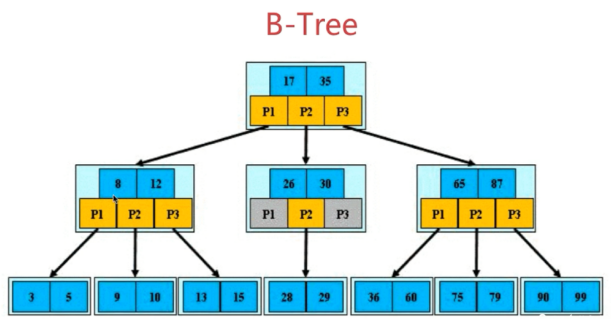
B+ Tree更適合用來做索引原因:
1.B+ 樹的磁碟讀寫代價更低。因為它的非葉子節點只存儲索引而不存儲具體數據,因此其內部節點相對B Tree 更小。如果把所有內部節點的關鍵字存放在同一盤塊中,這個盤塊能容納的關鍵字數量就更多,一次性讀入記憶體中的需要查找的關鍵字也越多,相對來說,I/O次數就降低了。
2.B+ 樹查詢效率更加穩定。其內部節點並不是最終指向文件內容的節點,而只是葉子節點中關鍵字的索引,所以任何關鍵字的查找必定有一條從根節點到葉子節點的路徑。所以關鍵字查詢的長度相同,導致每個數據的查找效率也幾乎是相同的穩定的,都是0log(n)
- B+ 樹更有利於對資料庫的掃描。B+ 樹只需要遍歷葉子節點就可以對全部關鍵字資訊的掃描,在做範圍查詢時效率很高。
如何優化索引?
1.哈希索引
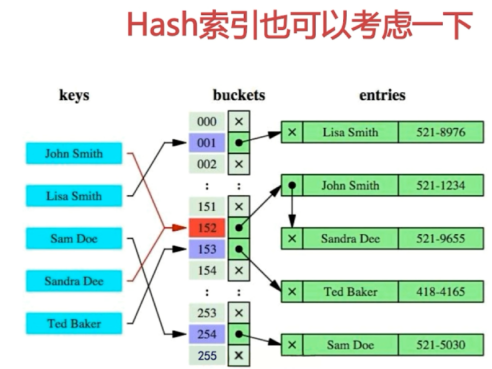
缺點:
①僅僅能滿足「=」,「IN",不能使用範圍查詢。哈希索引比較的是進行哈希運算之後的哈希值,所以它只能用於等值的過濾,不能用於基於範圍的查詢,因為經過哈希運算之後的哈希值不能保證和原來的鍵值一樣
②無法被用來避免數據的排序操作。由於哈希索引存儲的是經過哈希運算之後的值,而且哈希值不一定和原來的鍵值一樣,所以資料庫無法利用索引的數據來避免任何排序運算。
③不能利用部分索引鍵查詢。
④不能避免表掃描。哈希索引是將索引鍵通過哈希運算之後的哈希值和對應的行指針資訊存放在一個bucket當中,由於不同的索引建會出現相同的哈希值,所以即使取出滿足某個哈希鍵值的那些數據,也無法從哈希索引中直接完成查詢,還是要通過訪問bucket中的實際數據進行相應的比較。
⑤遇到大量Hash值相等的情況後性能並不一定就會比B樹索引高。極端情況下所有數據可能插入到一個桶中,如果正好要查詢最後一條數據,就變成線性的了。
2.BitMap
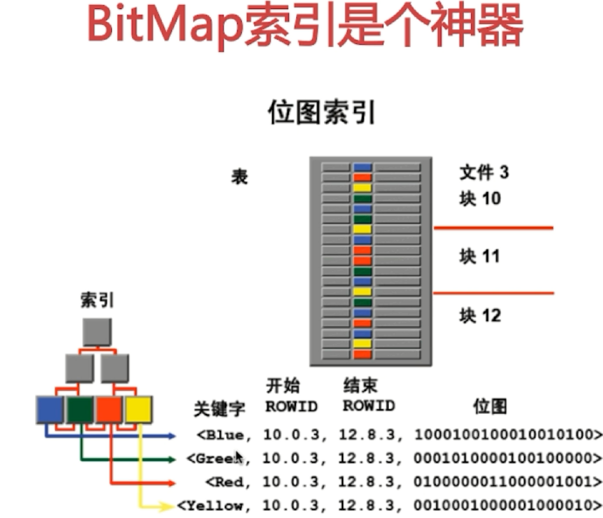
缺點:只適用於固定欄位的值,而且鎖的粒度非常大,不適用於並發場景,OLAP而不是OLTP
密集索引和稀疏索引的區別?



如何定位並優化慢查詢sql?
- 根據慢日誌定位慢查詢sql
- 使用explain等工具分析sql
- 修改sql或者盡量讓sql走索引

type關鍵欄位:如果出現了all欄位,則表示進行了全表掃描,效率非常低。
最左匹配原則
MySQL中的索引可以以一定順序引用多列,這種索引叫作聯合索引。如User表的name和city加聯合索引就是(name,city),而最左前綴原則指的是,如果查詢的時候查詢條件精確匹配索引的左邊連續一列或幾列,則此列就可以被用到。如果查詢條件為後面的一列或幾列,則無法用到此索引。如下:
select * from user where name=xx and city=xx ; //可以命中索引 select * from user where name=xx ; // 可以命中索引 select * from user where city=xx ; // 無法命中索引 
通常讓選擇性最強的索引列放在前面。
索引的選擇性是指:不重複的索引值和記錄總數的比值。最大值為 1,此時每個記錄都有唯一的索引與其對應。選擇性越高,每個記錄的區分度越高,查詢效率也越高。
最左匹配原則的成因?
mysql創建聯合索引的規則是首先對聯合索引最左邊的索引欄位的數據進行排序,然後在此基礎上在對第二個索引進行排序,類似於「order by 欄位1,order by 欄位2,…….」。第一個欄位絕對有序,第二個欄位就是無序的了。因此通常情況下,直接使用第二個欄位條件判斷是用不到索引的。
索引是建立的越多越好嗎?
- 數據量小的表不需要建立索引。建立索引會增加額外的索引開銷
- 數據變更需要維護索引,因此更多的索引意味著更多的成本
- 更多的索引意味著也需要更多的空間
索引的優點
- 大大減少了伺服器需要掃描的數據行數
- 可以讓伺服器避免進行排序和分組,以及避免創建臨時表(B+Tree索引本身就是有序的,可以用於ORDER BY和GROUP BY操作。臨時表主要是在排序和分組過程中創建,不需要排序和分組,也就不需要創建臨時表)
- 將隨機 I/O 變為順序 I/O(B+Tree 索引是有序的,會將相鄰的數據都存儲在一起)
索引的使用條件
- 對於非常小的表、大部分情況下簡單的全表掃描比建立索引更高效;
- 對於中到大型的表,索引就非常有效;
- 但是對於特大型的表,建立和維護索引的代價將會隨之增長。這種情況下,需要用到一種技術可以直接區分出需要查詢的一組數據,而不是一條記錄一條記錄地匹配,例如可以使用分區技術。
