Redis高可用——副本機制
為實現Redis服務的高可用,Redis官方為我們提供了副本機制(或稱主從複製)和哨兵機制。副本機制使得當Master伺服器宕機後,我們可以將其中一台Slave切換為新的Master伺服器。哨兵機制則實現了自動發現Master伺服器宕機,並自動進行主從切換。本文主要介紹副本機制(Replication),包括副本機制的概念、用法及其底層實現。下一篇文章我們再介紹哨兵機制。
從技術實現角度來看,Redis通過主從複製的方式來實現副本機制,所以下面介紹技術實現時,我們採用「主從複製」這個詞。
概念
高可用的作用是為了解決伺服器宕機帶來的服務不可用問題。對於Redis快取伺服器而言,解決方法就是在多台電腦上存儲快取數據,即:副本機制。當客戶端往快取伺服器(通常稱為Master伺服器)寫數據時,其他快取伺服器(通常稱為Slave伺服器)自動同步,如下圖所示:
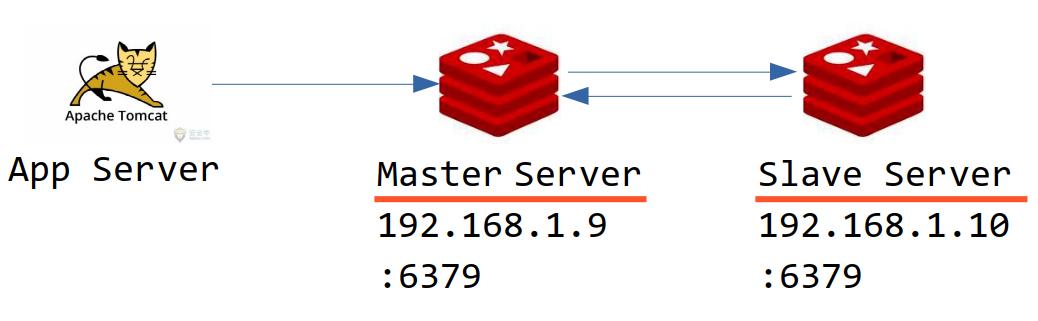
上圖是最簡單的主從集群結構,只有一個Master節點和一個Slave節點。複雜一點的話,我們也可以配置多個Slave節點。
配置
Redis的主從複製集群配置非常簡單,Master節點只需要改兩個地方的配置,Slave節點只需要改一個配置項即可。這裡,我們以上圖的最簡單的主從結構為例,具體修改如下:
Master節點的配置文件改動
修改之前:
bind 127.0.0.1
protected-mode yes
修改之後:
# bind 127.0.0.1
protected-mode no
即:去掉保護模式,並且將綁定的IP地址注釋掉。
- Slave節點的配置文件改動
添加一行:
# replicaof <masterip> <masterport>
replicaof 192.168.1.9 6379
即:此Slave伺服器待同步的Master伺服器的IP地址為192.168.1.9,埠號為6379(見上圖)。接下來我們來學習一下,Redis底層是如何實現主從複製的。
同步方式
具體講解程式碼實現之前,先來了解一下兩種主從同步方式。
-
完全同步(Full Sync):所有快取數據同步到
Slave機器。如下圖所示,Master機器從rdb文件(Redis的持久化文件)中讀取位元組流發送到Slave機器,知道發完為止。Slave機器根據發送過來的數據執行命令。
-
部分同步(Partial Sync):客戶端每發送一條Redis命令到Master,Master執行這條命令後,會轉發到Slave機器。如下圖所示,Slave接收到命令後,和Master一樣,會執行一遍命令流程,從而達到同步命令。這種方式每次都是同步命令,所以稱為部分同步,也可以理解為增量式的同步。


起點
上一篇文章我們介紹了事件機制,我們已經看到,系統啟動時,會註冊一個時間事件,其回調函數為serverCron,這個函數默認每秒執行10次。這個函數中會調用——replicationCron()函數——這就是主從複製的起點了:
int serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData) {
run_with_period(1000) replicationCron();
}
從這裡開始,主從同步的會依次經歷主從握手、完全同步以及部分同步三個階段,下面我們分三個部分具體闡述。
主從握手
我們知道TCP傳輸數據前會執行三次握手來建立連接,Redis的主從伺服器之間也會執行一段握手操作,目的是執行基本的驗證邏輯,並配置必要的同步參數。這個握手過程涉及的數據傳遞如下圖所示(程式碼具體實現參見replication.c的syncWithMaster()函數):

上圖左側所示為握手過程中Slave伺服器狀態變化,右側為握手過程的消息傳輸。可以看到,主從複製的過程是由Slave發起的,涉及五個來回,十條消息,可分以下三個階段:
-
PING-PONG階段:這一階段類似於打電話開頭 -
密碼認證階段:
Slave發送密碼到master進行認證。如果沒有配置master密碼的話,則會跳過這一步。可能有人會問,認證階段有什麼意義?如果“master伺服器配置了訪問需要密碼,而Slave伺服器因為沒有配置master`的密碼而跳過認證階段,則會導致後續命令會執行失敗——返回沒有驗證錯誤,具體如下:int processCommand(client *c) { if (server.requirepass && !c->authenticated && c->cmd->proc != authCommand) { flagTransaction(c); addReply(c,shared.noautherr); return C_OK; } } -
參數配置階段:最後三條以
replconf開頭的命令,用於告訴master伺服器主從同步相關的參數——IP地址、埠以及支援的服務。
經過以上握手步驟之後,Slave伺服器進入主從複製階段。Slave伺服器首先嘗試進行部分同步,即發送psync命令到Master伺服器,如上圖紅線所示。如果Master伺服器不支援或認為不滿足部分同步的條件,則告訴Slave伺服器需要執行完全同步。所以,接下來我們也是先闡述部分同步,再闡述完全同步。
部分同步
剛才已經說了,部分同步下,Master伺服器在執行命令的同時,會將命令廣播到Slave伺服器,如下所示:
void readQueryFromClient(aeEventLoop *el, int fd, void *privdata, int mask) {
processInputBufferAndReplicate(c);
}
void processInputBufferAndReplicate(client *c) {
if (!(c->flags & CLIENT_MASTER)) {
processInputBuffer(c);
} else {
size_t prev_offset = c->reploff;
processInputBuffer(c);
size_t applied = c->reploff - prev_offset;
if (applied) {
replicationFeedSlavesFromMasterStream(server.slaves,
c->pending_querybuf, applied);
sdsrange(c->pending_querybuf,applied,-1);
}
}
}
void replicationFeedSlavesFromMasterStream(list *slaves, char *buf, size_t buflen) {
listNode *ln;
listIter li;
if (server.repl_backlog) feedReplicationBacklog(buf,buflen);
listRewind(slaves,&li);
while((ln = listNext(&li))) {
client *slave = ln->value;
/* Don't feed slaves that are still waiting for BGSAVE to start */
if (slave->replstate == SLAVE_STATE_WAIT_BGSAVE_START) continue;
addReplyString(slave,buf,buflen);
}
}
readQueryFromClient()這個函數我們應該很熟悉了,上一篇文章中我們知道,這就是和客戶端建立連接後,在客戶端socket上註冊的回調函數。此函數會調用processInputBufferAndReplicate,進而調用replicationFeedSlavesFromMasterStream,這就是向Slave伺服器推送命令位元組流的函數了。通過程式碼可以看到,該函數會遍歷所有的Slave伺服器,並逐個向Slave伺服器發送命令位元組流。
那麼,接下來的疑問便是server.slaves數組是怎麼得到的?這就是上一節最後說到的psync命令要做的事了,psync命令的處理函數syncCommand有如下邏輯:
/* SYNC and PSYNC command implemenation. */
void syncCommand(client *c) {
if (!strcasecmp(c->argv[0]->ptr,"psync")) {
if (masterTryPartialResynchronization(c) == C_OK) {
server.stat_sync_partial_ok++;
return; /* No full resync needed, return. */
}
}
}
int masterTryPartialResynchronization(client *c) {
c->flags |= CLIENT_SLAVE;
c->replstate = SLAVE_STATE_ONLINE;
c->repl_ack_time = server.unixtime;
c->repl_put_online_on_ack = 0;
listAddNodeTail(server.slaves,c);
}
上述兩個函數均是截取我們關心的部分,應該不用做過多解釋了。
完全同步
執行完全同步判斷條件
有了部分同步就能實現主從同步了嗎?顯然不能,部分同步之前,Master伺服器上執行的命令需要同步到Slave伺服器,這就是完全同步發揮作用的地方了。講解完全同步的實現之前,我們來看看Redis是怎麼判斷是否需要完全同步的?下面是判斷是否需要完全同步所需的三組狀態數據:
replid和reploff:第一個參數replid是Master伺服器的id,第二個參數reploff為當前Slave伺服器複製的偏移量。Slave伺服器發起部分同步時,一般會帶上這兩個參數,即:psync replid reploff。replid2和second_replid_offset: 這兩個變數用於主從切換的情形。主從切換的時候,Slave伺服器會變成Master伺服器,這兩個變數分別用於該Slave伺服器同步的Master伺服器的id和同步的偏移量。repl_backlog、repl_back_off和repl_backlog_histlen:Master伺服器的後台緩衝區、後台緩衝區偏移及長度。
下面程式碼就是Master伺服器判斷是否需要完全同步的邏輯:
int masterTryPartialResynchronization(client *c) {
if (getLongLongFromObjectOrReply(c,c->argv[2],&psync_offset,NULL) !=
C_OK) goto need_full_resync;
if (strcasecmp(master_replid, server.replid) &&
(strcasecmp(master_replid, server.replid2) ||
psync_offset > server.second_replid_offset))
{
goto need_full_resync;
}
if (!server.repl_backlog ||
psync_offset < server.repl_backlog_off ||
psync_offset > (server.repl_backlog_off + server.repl_backlog_histlen))
{
goto need_full_resync;
}
}
- 第一個判斷表示無法解析
psync命令的參數reploff時,需要進行完全同步。原因:如果沒有這個參數,我們就無法知道此前Slave伺服器同步的是不是本Master伺服器同步的; - 第二個判斷,分為兩個子判斷:
Slave伺服器發送過來的replid和當前Master伺服器的replid不一致,並且Slave伺服器發送過來的replid和當前Master伺服器的replid2不一致,需要進行完全同步;Slave伺服器發送過來的replid和當前Master伺服器的replid不一致,並且Slave伺服器請求的同步速度快於Master伺服器;
- 第三個判斷表示
Master伺服器是否有後台日誌緩衝區,如果沒有,則需要進行完全同步;如果有,則繼續判斷待同步的偏移是否在後台日誌緩衝區的範圍內,如果不在後台日誌緩衝區的範圍內,則需要進行完全同步。換句話說,只有Master伺服器有後台日誌緩衝區,並且Slave伺服器發過來的同步偏移量在後台日誌緩衝區記錄的範圍之內,才能進行部分同步。
完全同步程式碼實現
完全同步的實現是比較簡單,下面來看看Master伺服器和Slave伺服器所需要執行的邏輯。
Master伺服器端:載入並讀取RDB文件,寫入Slave客戶端的套接字,具體實現邏輯如下(提取主要部分):
void sendBulkToSlave(aeEventLoop *el, int fd, void *privdata, int mask) {
if (slave->replpreamble) {
nwritten = write(fd,slave->replpreamble,sdslen(slave->replpreamble));
}
buflen = read(slave->repldbfd,buf,PROTO_IOBUF_LEN);
nwritten = write(fd,buf,buflen);
slave->repldboff += nwritten;
if (slave->repldboff == slave->repldbsize) {
close(slave->repldbfd);
slave->repldbfd = -1;
aeDeleteFileEvent(server.el,slave->fd,AE_WRITABLE);
putSlaveOnline(slave);
}
}
上面程式碼最後一段邏輯表明:完全同步完成後,Slave伺服器成為部分同步的客戶端被加入到Master伺服器的server.slaves中。結合前面對部分同步的分析,此後Slave就開始了部分同步的過程,通過增量式來實現主從同步。
Slave伺服器端:讀取來自伺服器發過來的RDB位元組流,保存到本地的RDB文件。位元組流讀取完畢後,清空Slave伺服器上的所有數據,然後重新載入RDB文件,從而實現主從完全同步。具體實現邏輯如下(提取主要部分):
void readSyncBulkPayload(aeEventLoop *el, int fd, void *privdata, int mask) {
if (server.repl_transfer_size == -1) {
syncReadLine(fd,buf,1024,server.repl_syncio_timeout*1000);
server.repl_transfer_size = strtol(buf+1,NULL,10);
serverLog(LL_NOTICE,
"MASTER <-> REPLICA sync: receiving %lld bytes from master",
(long long) server.repl_transfer_size);
return;
}
left = server.repl_transfer_size - server.repl_transfer_read;
readlen = (left < (signed)sizeof(buf)) ? left : (signed)sizeof(buf);
nread = read(fd,buf,readlen);
write(server.repl_transfer_fd,buf,nread);
/* Check if the transfer is now complete */
if (server.repl_transfer_read == server.repl_transfer_size)
eof_reached = 1;
if (eof_reached) {
rename(server.repl_transfer_tmpfile,server.rdb_filename);
emptyDb(
-1,
server.repl_slave_lazy_flush ? EMPTYDB_ASYNC : EMPTYDB_NO_FLAGS,
replicationEmptyDbCallback);
rdbLoad(server.rdb_filename,&rsi);
}
}
需要指出的是,Slave伺服器讀取到RDB位元組流後,先寫入一個臨時文件中server.repl_transfer_tmpfile中,等同步完成後,將臨時文件重命名為正式的RDB文件server.rdb_filename。


