Cassandra社區是怎麼測試4.0的
點擊查看活動錄像,獲取更多技術細節。
Cassandra社區是怎麼測試4.0的
Cassandra 4.0的目標就是成為史上最穩定的版本。為了達到這個目的,我們需要用很多方法和工具進行測試。我今天主要為大家介紹一下Cassandra 4.0的測試思路。不同的公司用不同的方法,希望我的介紹能給大家帶來一些啟發。
我先簡單介紹一下自己。我其實早在2006年就開始參與開源軟體的開發,一直致力於以開源的方式、以工程師驅動的方式來開發軟體。我在2010年至2013年曾領導過VMWare北京的研發團隊,所以我對中國的工程師很有感情,特別願意和大家溝通,向大家介紹我們最新的方法,希望為大家提供幫助和借鑒。
我在2014年加入了DataStax,並帶領我們的後端工程師團隊在Cassandra的基礎上整合了Apache Spark、Apache Solr和ThinkerPop等技術,開發出了一個多模式的大數據平台DSE (DataStax Enterprise),可以提供搜索和分析功能,並利用Graph搭建圖資料庫。
不過今天我的重點不在DSE,而是在於Cassandra的測試。
Cassandra資料庫準確性測試架構
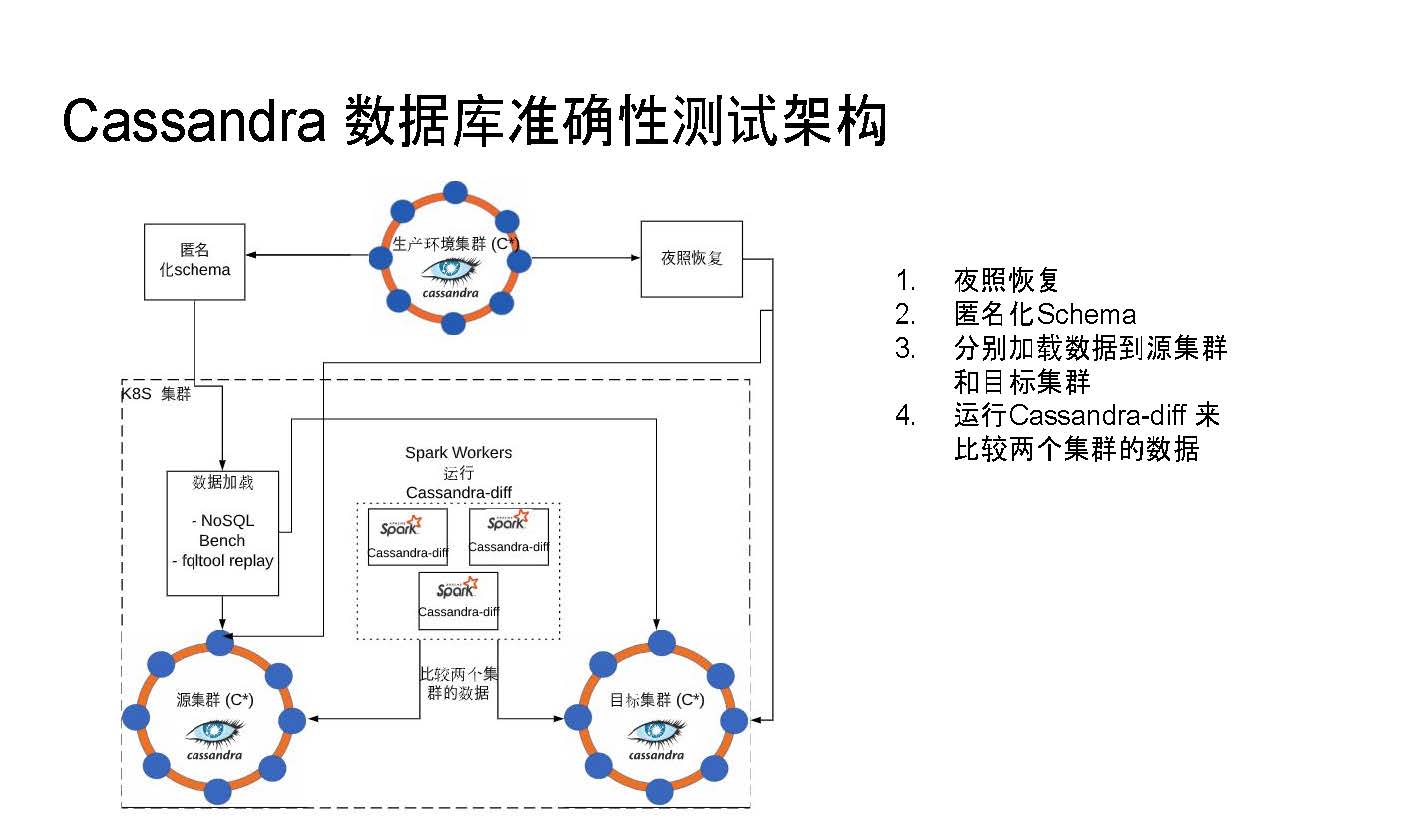
我今天介紹大致是圍繞PPT中的這張圖進行的。

對於資料庫來講,最最重要的就是準確性——你不希望你的數據在存儲的過程中被修改或丟失。所以,數據的準確性是4.0版本中最關注的地方。
簡單來講,在通常情況下,在測試時會有一個運行著Cassandra集群的生產環境。在這裡,我們的核心方式是利用開源的Cassandra-diff工具來測試源集群和目標集群裡面的數據。
首先,測試架構中包括了夜照恢復,這個功能能夠把想要測試的某個數據點在生產環境中恢復到測試環境中的源集群和目標集群。
第二,如果不希望別人知道schema的情況,我們有一個匿名化的工具幫助隱藏schema,這樣其他做測試的人就看不出來可能包含的敏感的資訊,比如客戶數據等。
第三步就是將不同的數據載入到源集群或目標集群。在載入過程中我們會使用到一些工具,主要包括NoSQLBench和fqltool。fqltool是一個full query log,會存儲所有通過CQL interface的query,之後可以再進行回放。在後面我會再具體介紹這兩種工具。
在Cassandra-diff運行中,有時數據量會非常大,這裡我們就用到了Spark。以Spark集群的形式,我們將Cassandra程式運行在Spark Workers上,然後再由Spark Workers運行Cassandra-diff來確保源集群和目標集群中的數據是準確的。
在實際應用時,夜照恢復可能是可選項,如果只是測試則完全不必要。匿名化Schema則取決於是否有生產環境,也不一定絕對需要。所以整個測試架構中的核心就是數據載入和Cassandra-diff。
整個測試環境可以運行在一般的伺服器環境之下,也可以運行在Kubernetes集群中。我們現在正在努力實現這些工具的自動化,將他們放到Kubernetes集群中,使得所有社區成員都可以使用。
接下來,我會就其中幾個重要的工具進行介紹。
匿名化schema

其實匿名化schema的概念非常簡單。在PPT中,源schema的keyspace的名字是cassandradiff,匿名化後變為ks_0,使得測試人員完全無法辨認原來的keyspace名字。除此之外,包括資料庫的名字、表的名字等等都被匿名化了。這樣一來,我們就可以放心地將數據導出並用來測試。

載入數據
NoSQLBench

載入數據主要用到兩種工具,其中一個是NoSQLBench。
NoSQLBench本來是一個用來做性能測試的工具,我們用它來載入數據的原因是它是決定性的(deterministic),即當開發人員配置好相關的配置文件,NoSQLBench能確保多次生成的數據是一致的,方便測試比較。另外一個使用NoSQLBench的原因是它可以基於匿名schema隨機生成數據。

在這裡,我們給出一個簡單的NoSQLBench的例子。
在PPT中,我們看到的是一個NoSQLBench配置文件。這裡面包括bindings,可以定義匿名化schema中不同欄位的屬性。
在下面的blocks中也分為不同的步驟(phase),比如這個例子中的第一步phase: schema是根據schema創建表;第二步phase: main主要是用來載入數據,在這其中我們可以定義需要插入的數據量。
點擊此處了解更多關於NoSQLBench的詳細資訊。
FQL – Replay Testing

第二種載入數據的方式是FQL(Full Query Log,所有查詢日誌)。
FQL是Cassandra 4.0中的新功能,它會記錄所有從CQL interface輸入的命令。通常情況下,FQL是用來做調試和性能測試的。而4.0中的另一個亮點功能審核日誌Audit log就是基於FQL開發的。FQL只會記錄成功的命令,不成功的命令不會被記錄。另外,FQL的運行對於集群性能的影響非常小,主要是因為FQL使用了非常簡單且性能很好的BinLog格式和高性能的Chronicle Queue。
點擊此處了解更多關於Audit Log的資訊。

在PPT中展示的是一些簡單的FQL命令。想要啟用FQL,有兩種方式。
一是使用nodetool enablefullquerylog。由於這些nodetool命令都是local的,所以你需要在local的每一個node上都啟用FQL,它才會記錄本地的CQL命令並支援回放。在nodetool enablefullquerylog後面定義的路徑存儲了所有被記錄的CQL命令。進到這個路徑地址,可以看到,不管記錄了多少命令,這裡都有兩個體積差不多的文件,你記錄更多就會有更多文件。這就是一個基於Chronicle Queue的存儲格式。
第二種啟用FQL的方式是在cassandra.yaml文件的full_query_logging_options中有相關的參數,可以用於配置路徑、存儲方式等等。我在這裡做一個最簡單的介紹。在測試中,所謂的「載入數據」其實就是一個回放。也就是說,在生產環境中啟動了FQL,記錄了所有CQL命令。如果這時出現問題,我們就需要查看一下問題出在哪裡。
在以前,出現問題時我們需要模擬用戶的使用過程,但是想要快速有效地複製之前的情況是一件很難的事情,因為每個運行環境和每個客戶的使用方法都有不同。而FQL相當於做了一個完整的記錄,當我們再遇到問題,就可以用replay功能來進行診斷和修復。在4.0版本中,我們就可以使用fqltool這一工具來操作FQL。當我們使用replay功能時,我們可以指定想要replay的資料庫或表,得到的結果會被存儲到指定的路徑、集群或者節點。
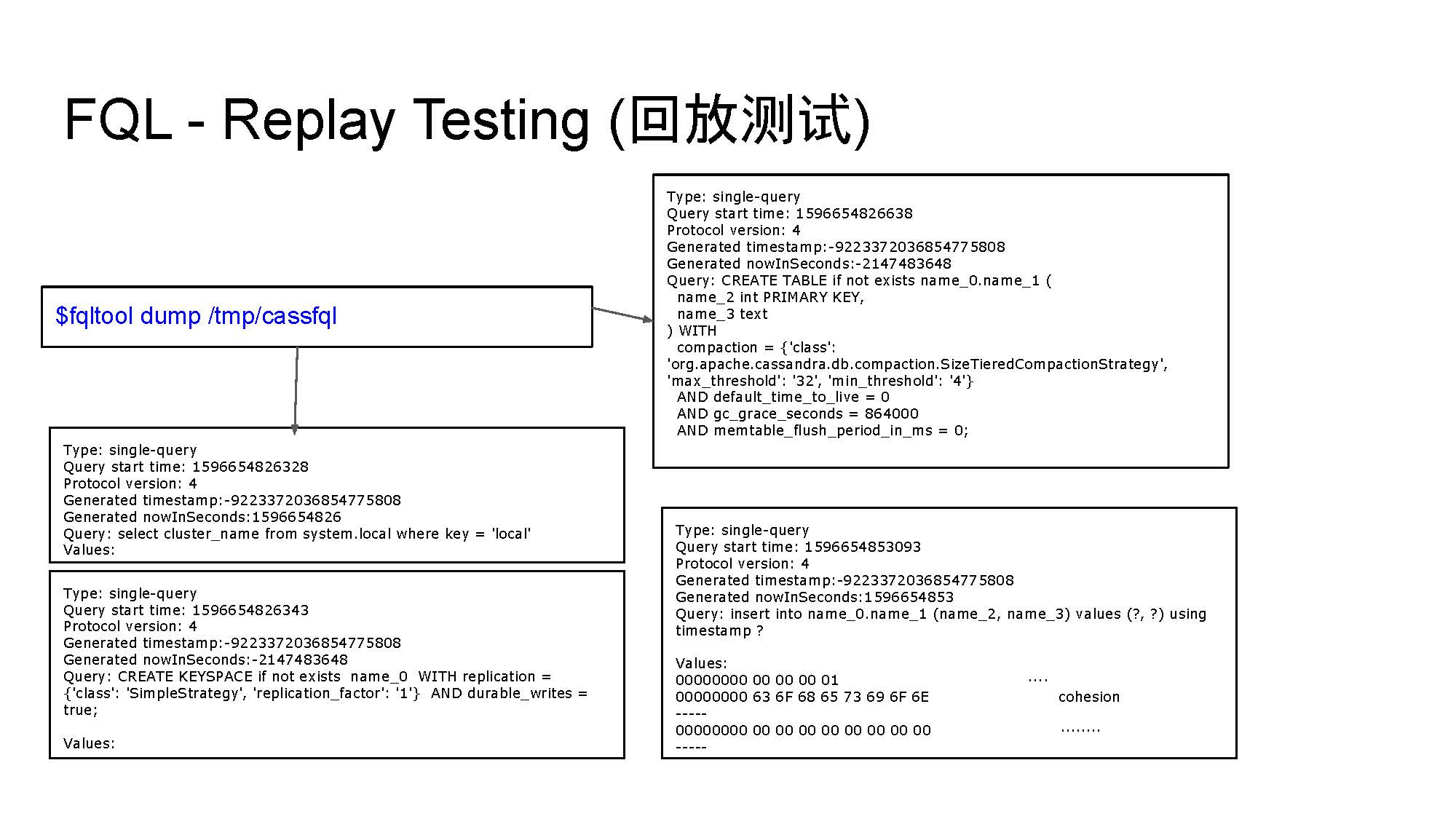
PPT中的例子就是在processing,回放存儲的命令。有時候因為目標節點上沒有所需的表,所以可能會出現錯誤。在PPT中我們還能看到有多少query以及完成了多少的query。
fqltool dump這個命令可以讓我們看到記錄的query,這裡面包括非常詳細的資訊,比如query開始的時間、使用的協議的版本、timestamp時間戳、執行花費的時間以及query本身是什麼。無論是SELECT、INSERT還是其它query,所有的命令都有詳細記錄。
Cassandra-diff

我們通過NoSQLBench或是FQL將數據載入到兩個不同集群裡面之後,有可能這兩個集群的Cassandra版本不同,也可能配置不同。在Cassandra的yaml文件中有很多配置,我們曾經做過調研,如果將yaml文件中不同的配置進行排列組合,大約能得到超過十億種組合。
而Cassandra-diff則可以幫助比較兩個版本或配置不同的集群所得到的結果是否相同。
使用Cassandra-diff的主要目的是確保資料庫的準確性,然後在資料庫不準確時查找出現的問題。具體實現方法是將整個集群的token切分,然後將不同的部分分配給不同的spark worker,進而比較每個token的數據。
Cassandra-diff是一個開源的程式,有興趣的朋友可以自行了解更多相關資訊。
這裡我們舉一個Cassandra-diff的例子。

正如前面提到的,Cassandra-diff是用Spark來submit。Spark是一個分散式的計算框架,能夠將程式放到多台機器上同時運行,從而節省性能。
在這個例子的命令行中,我們可以看到一個配置文件,它主要是給Cassandra-diff使用的。在這個文件中,我們可以定義keyspace是什麼、想要比較的table是什麼、splits是多少、buckets是多少等等與Spark相關的配置。後面的部分與集群相關,包括目標集群、源集群和metadata。
Metadata根據Cassandra運行的不同階段,可以把我們希望存的數據存到目標集群中,出現問題時可以在此尋找錯誤原因。
左邊下面的框里是運行時的情況,我們可以看到有很多token range,每一個token range中的數據都被取出來進行比較。比較後會給出狀態資訊,並回饋是否兩個集群中所有的partition都是一致的。如果一致就皆大歡喜,如果不一致可能就需要找到問題所在。
Property based testing (PBT)

在Cassandra 4.0中,我們採用了一個新的寫測試用例的方式。
在這之前,大家熟悉的是單元測試(unit test or example based test)——假設我們需要測試加法功能是否正確運行,我們可能以1+3為例進行測試,從結果是否為4判斷功能是否正確運行。
但是PBT與單元測試不同,PBT考慮的是問題本質的屬性,通過對屬性的深入理解提出到達解集的不同路徑,從而進行驗證。這個概念可能比較難理解,我們先講一下PBT的步驟,後面還會給出例子,幫助大家理解。
PBT將一個測試分為三步:
- 輸入策略:無需手寫一條條數據數據,只需訂製輸入策略,PBT框架會自動根據策略生成足夠大的、隨機的、包含所有情況的測試數據集
- 結果檢查:結果檢查是需要費心考慮的,因為無法預知測試集的輸入也就無法預先寫好測試集的輸出。所以PBT要求對邏輯需求有深入的理解,並精心構造不同的解題路徑來對結果進行驗證。
- 錯誤收斂:因為PBT會自動生成大量輸入參數,自然會產生眾多結果。為了使開發人員更方便地找到具有典型意義的異常數據,PBT框架會自動對錯誤集進行收斂,生成儘可能小的異常參數集合。
在這裡舉一個簡單的例子來幫助理解:加法的屬性。屬性一:比如我們需要求得a、b之和,無論是a+b還是b+a,其結果應該是相同的;屬性二:a+1+1與a+2應該得到相同的結果;屬性三:a+0和a應該是一樣的。
所以說,我們要的是像這樣的屬性而非具體的例子。
在資料庫的測試中來講,我們可以再舉一個例子:如果硬碟出現故障,就會發生數據損害。數據損害就是一個屬性,可以利用checksum來診斷數據損害。也就是說,數據受損後的checksum與受損前是不同的。
總的來說,PBT可以幫助我們更好、更多地發現問題,並且由於PBT產生的數據是隨機的,所以也能更廣泛地覆蓋測試的範圍。
結尾
以上就是今天我想和大家分享的Cassandra 4.0中使用到的測試方法,希望這些新的方法對大家有借鑒意義。
但是作為一個開源產品,要是想測試到所有情況,光靠少量程式設計師測試是很難達到的。因為雖然我們可以測試每一行程式,但是不能測試每個用戶的使用情景。這就是為什麼我們希望大家能夠參與到社區和項目當中。

PPT中列出了一些可以參與到社區和項目的方式和渠道,比如回答用戶的問題、參與測試、review程式碼、提交修補程式、參與開發新功能等等。這些會讓你對產品有更深入的了解,也會幫你在社區中建立自己的個人品牌。
Go fast, go alone; go far, go together. (單打獨鬥也許會走得更快,但團隊作戰才能走得更遠。)希望大家能夠積極為社區貢獻力量。
非常高興今天有機會和大家分享這些,謝謝大家。





