Redis入門–進階詳解
- 2020 年 8 月 26 日
- 筆記
Redis
NoSql入門和概述
入門概述
互聯網時代背景下大機遇,為什麼用nosql
1.單機MySQL的美好年代
- 在90年代,一個網站的訪問量一般都不大,用單個資料庫完全可以輕鬆應付,在那個時候,更多的都是靜態網頁,動態交互類型的網站不多

- 上述架構下,我們來看看數據存儲的瓶頸是什麼?
- 數據量的總大小 一個機器放不下時
- 數據的索引(B+ Tree)一個機器的記憶體放不下時
- 訪問量(讀寫混合)一個實例不能承受

2.Memcached(快取)+MySQL+垂直拆分
- 後來,隨著訪問量的上升,幾乎大部分使用MySQL架構的網站在資料庫上都開始出現了性能問題,web程式不再僅僅專註在功能上,同時也在追求性能。程式設計師們開始大量的使用快取技術來緩解資料庫的壓力,優化資料庫的結構和索引。開始比較流行的是通過文件快取來緩解資料庫壓力,但是當訪問量繼續增大的時候,多台web機器通過文件快取不能共享,大量的小文件快取也帶了了比較高的IO壓力。在這個時候,Memcached就自然的成為一個非常時尚的技術產品
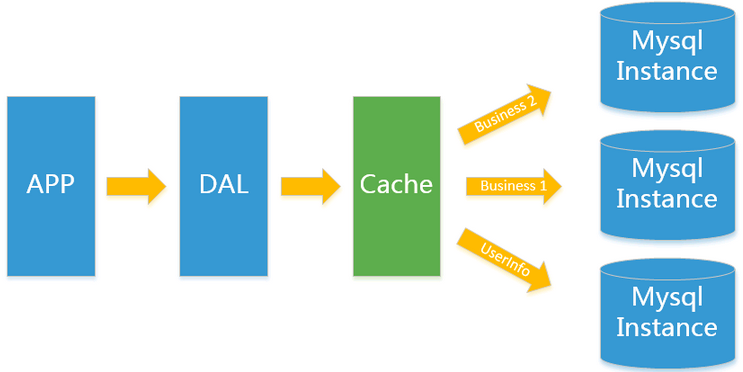
- Memcached作為一個獨立的分散式的快取伺服器,為多個web伺服器提供了一個共享的高性能快取服務,在Memcached伺服器上,又發展了根據hash演算法來進行多台Memcached快取服務的擴展,然後又出現了一致性hash來解決增加或減少快取伺服器導致重新hash帶來的大量快取失效的弊端

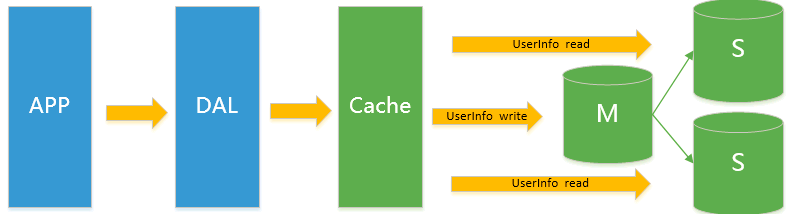
3.MySQL主從讀寫分離
- 由於資料庫的寫入壓力增加,Memcached只能緩解資料庫的讀取壓力。讀寫集中在一個資料庫上讓資料庫不堪重負,大部分網站開始使用主從複製技術來達到讀寫分離,以提高讀寫性能和讀庫的可擴展性。Mysql的master-slave模式成為這個時候的網站標配了

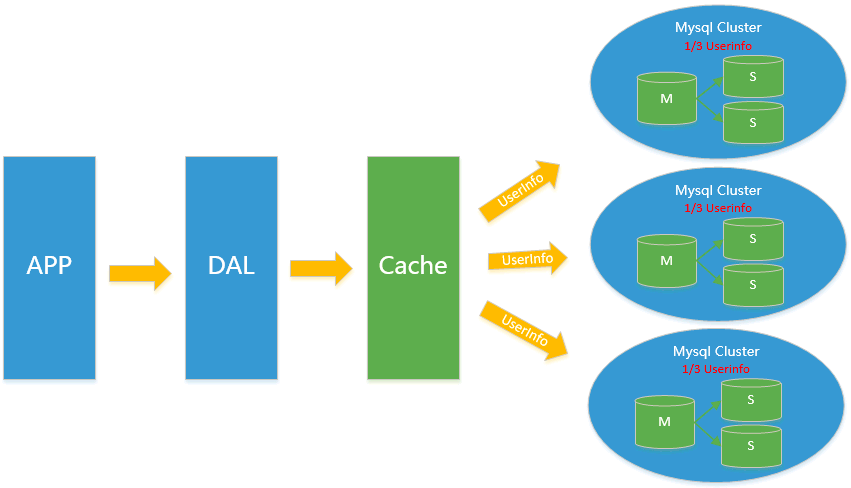
4.分表分庫+水平拆分+mysql集群
-
在Memcached的高速快取,MySQL的主從複製,讀寫分離的基礎之上,這時MySQL主庫的寫壓力開始出現瓶頸,而數據量的持續猛增,由於MyISAM使用表鎖,在高並發下會出現嚴重的鎖問題,大量的高並發MySQL應用開始使用InnoDB引擎代替MyISAM
-
同時,開始流行使用分表分庫來緩解寫壓力和數據增長的擴展問題。這個時候,分表分庫成了一個熱門技術,是面試的熱門問題也是業界討論的熱門技術問題。也就在這個時候,MySQL推出了還不太穩定的表分區,這也給技術實力一般的公司帶來了希望。雖然MySQL推出了MySQL Cluster集群,但性能也不能很好滿足互聯網的要求,只是在高可靠性上提供了非常大的保證
-

5.MySQL的擴展性瓶頸
- MySQL資料庫也經常存儲一些大文本欄位,導致資料庫表非常的大,在做資料庫恢復的時候就導致非常的慢,不容易快速恢復資料庫。比如1000萬4KB大小的文本就接近40GB的大小,如果能把這些數據從MySQL省去,MySQL將變得非常的小。關係資料庫很強大,但是它並不能很好的應付所有的應用場景。MySQL的擴展性差(需要複雜的技術來實現),大數據下IO壓力大,表結構更改困難,正是當前使用MySQL的開發人員面臨的問題
6.今天系統是什麼樣子
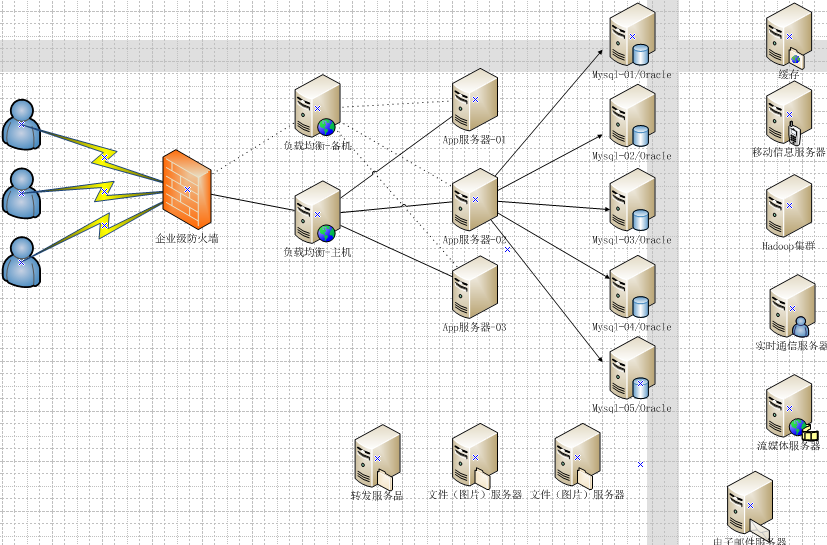
7.為什麼要用NoSQL
- 今天我們可以通過第三方平台(如:Google,Facebook等)可以很容易的訪問和抓取數據。用戶的個人資訊,社交網路,地理位置,用戶生成的數據和用戶操作日誌已經成倍的增加。我們如果要對這些用戶數據進行挖掘,那SQL資料庫已經不適合這些應用了, NoSQL資料庫的發展也卻能很好的處理這些大的數據
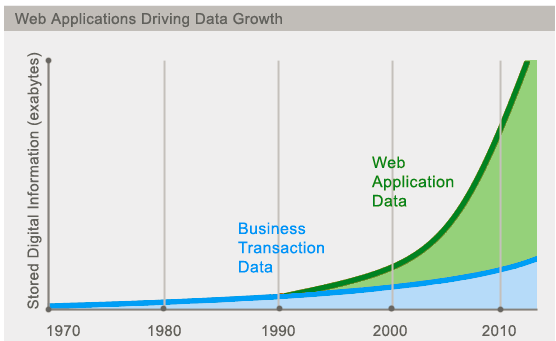

是什麼
-
NoSQL(NoSQL = Not Only SQL ),意即「不僅僅是SQL」
-
泛指非關係型的資料庫。隨著互聯網web2.0網站的興起,傳統的關係資料庫在應付web2.0網站,特別是超大規模和高並發的SNS類型的web2.0純動態網站已經顯得力不從心,暴露了很多難以克服的問題,而非關係型的資料庫則由於其本身的特點得到了非常迅速的發展。NoSQL資料庫的產生就是為了解決大規模數據集合多重數據種類帶來的挑戰,尤其是大數據應用難題,包括超大規模數據的存儲
-
(例如Google或Facebook每天為他們的用戶收集萬億比特的數據)。這些類型的數據存儲不需要固定的模式,無需多餘操作就可以橫向擴展
能幹嘛
易擴展
- NoSQL資料庫種類繁多,但是一個共同的特點都是去掉關係資料庫的關係型特徵。數據之間無關係,這樣就非常容易擴展。也無形之間,在架構的層面上帶來了可擴展的能力
大數據量高性能
- NoSQL資料庫都具有非常高的讀寫性能,尤其在大數據量下,同樣表現優秀,這得益於它的無關係性,資料庫的結構簡單
- 一般MySQL使用Query Cache,每次表的更新Cache就失效,是一種大粒度的Cache,
在針對web2.0的交互頻繁的應用,Cache性能不高。而NoSQL的Cache是記錄級的,
是一種細粒度的Cache,所以NoSQL在這個層面上來說就要性能高很多
多樣靈活的數據模型
- NoSQL無需事先為要存儲的數據建立欄位,隨時可以存儲自定義的數據格式。而在關係資料庫里,
增刪欄位是一件非常麻煩的事情。如果是非常大數據量的表,增加欄位簡直就是一個噩夢
傳統RDBMS VS NOSQL
-
RDBMS vs NoSQL
-
RDBMS NoSQL 高度組織化結構化數據 代表著不僅僅是SQL 結構化查詢語言(SQL) 沒有聲明性查詢語言 數據和關係都存儲在單獨的表中 沒有預定義的模式 數據操縱語言,數據定義語言 鍵 – 值對存儲,列存儲,文檔存儲,圖形資料庫 嚴格的一致性 最終一致性,而非ACID屬性 基礎事務 非結構化和不可預知的數據 CAP定理 高性能,高可用性和可伸縮性
去哪裡下
- Redis
- Memcache
- Mongdb
怎麼玩
- KV
- Cache
- Persistence
- ……
3V+3高
大數據時代的3V
- 海量Volume
- 多樣Variety
- 實時Velocity
互聯網需求的3高
- 高並發
- 高可擴
- 高性能
當下的NoSQL經典應用
當下的應用是sql和nosql一起使用
阿里巴巴中文站商品資訊如何存放
- 和我們相關的,多數據源多數據類型的存儲問題
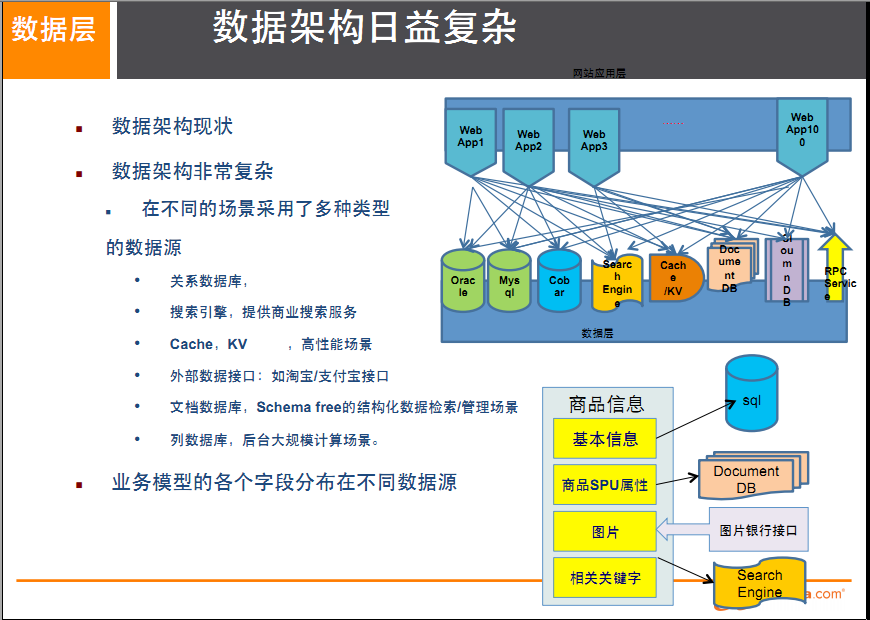

1.商品基本資訊
- 名稱、價格,出廠日期,生產廠商等
- 關係型資料庫:mysql/oracle目前淘寶在去O化(也即拿掉Oracle),注意,淘寶內部用的Mysql是裡面的大牛自己改造過的
- 為什麼去IOE:2008年,王堅加盟阿里巴巴成為集團首席架構師,即現在的首席技術官。這位前微軟亞洲研究院常務副院長被馬雲定位為:將幫助阿里巴巴集團建立世界級的技術團隊,並負責集團技術架構以及基礎技術平台搭建。
在加入阿里後,帶著技術基因和學者風範的王堅就在阿里巴巴集團提出了被稱為「去IOE」(在IT建設過程中,去除IBM小型機、Oracle資料庫及EMC存儲設備)的想法,並開始把雲計算的本質,植入阿里IT基因。
王堅這樣概括「去IOE」運動和阿里雲之間的關係:「去IOE」徹底改變了阿里集團IT架構的基礎,是阿里擁抱雲計算,產出計算服務的基礎。「去IOE」的本質是分布化,讓隨處可以買到的Commodity PC架構成為可能,使雲計算能夠落地的首要條件。
- 為什麼去IOE:2008年,王堅加盟阿里巴巴成為集團首席架構師,即現在的首席技術官。這位前微軟亞洲研究院常務副院長被馬雲定位為:將幫助阿里巴巴集團建立世界級的技術團隊,並負責集團技術架構以及基礎技術平台搭建。
2.商品描述、詳情、評價資訊(多文字類)
- 多文字資訊描述類,IO讀寫性能變差
- 文檔資料庫MongDB中
3.商品的圖片
- 商品圖片展示類
- 分散式的文件系統中
- 淘寶自己的TFS
- Google的GFS
- Hadoop的HDFS
4.商品的關鍵字
- 搜索引擎,淘寶內用
- ISearch
5.商品的波段性的熱點高頻資訊
- 記憶體資料庫
- Tair、Redis、Memcache
6.商品的交易、價格計算、積分累計
- 外部系統,外部第3方支付介面
- 支付寶
7.總結大型互聯網應用(大數據、高並發、多樣數據類型)的難點和解決方案
- 難點
- 數據類型多樣性
- 數據源多樣性和變化重構
- 數據源改造而數據服務平台不需要大面積重構
- 解決辦法
- EAI和統一數據平台服務
- 阿里、淘寶:UDSL
- 是什麼

- 什麼樣
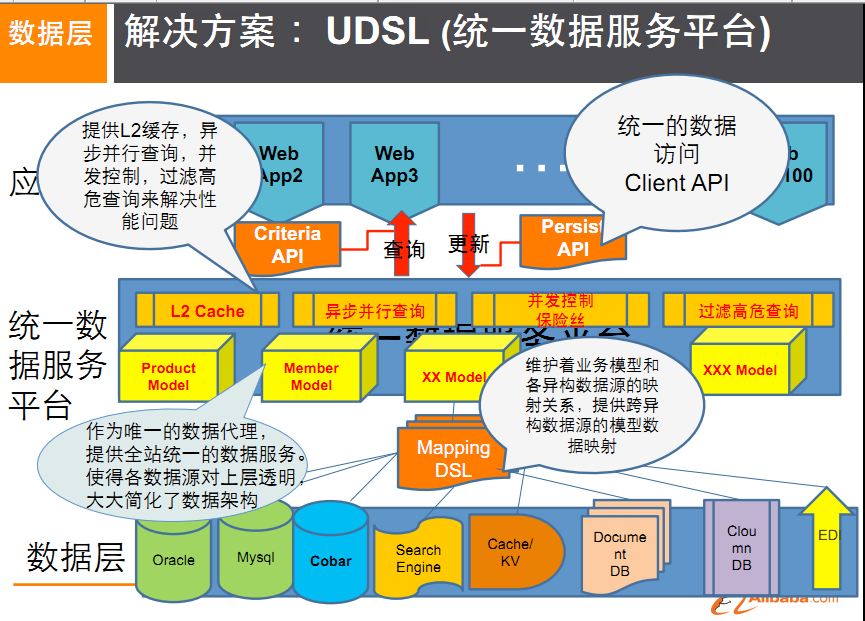
- 映射
- API
- 熱點快取
- ……
- 是什麼


NoSQL數據模型簡介
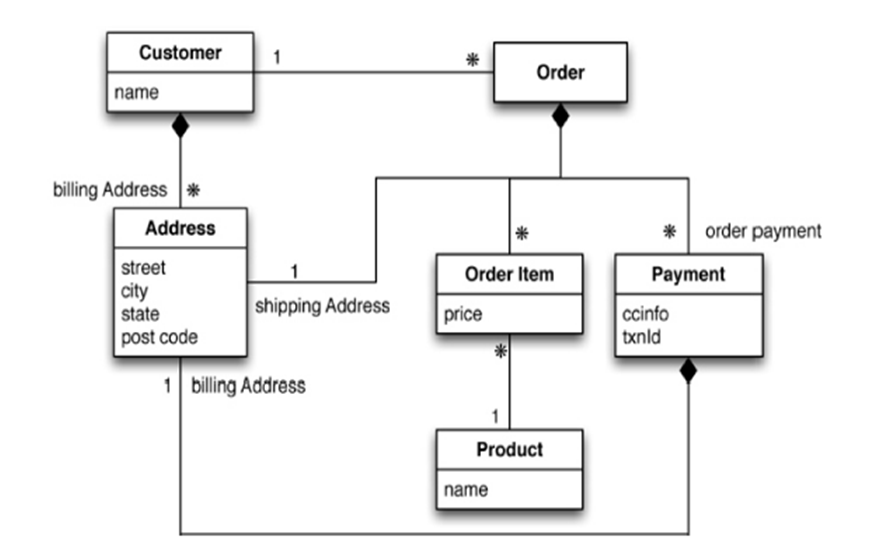
以一個電商客戶、訂單、訂購、地址模型來對比下關係型資料庫和非關係型資料庫
傳統的關係型資料庫你如何設計?
- ER圖(1:1/1:N/N:N,主外鍵等常見)

NoSQL你如何設計
-
什麼是BSON:BSON()是一種類json的一種二進位形式的存儲格式,簡稱Binary JSON,它和JSON一樣,支援內嵌的文檔對象和數組對象
-
BSON數據模型
-
{ "customer":{ "id":1136, "name":"Z3", "billingAddress":[{"city":"beijing"}], "orders":[ { "id":17, "customerId":1136, "orderItems":[{"productId":27,"price":77.5,"productName":"thinking in java"}], "shippingAddress":[{"city":"beijing"}] "orderPayment":[{"ccinfo":"111-222-333","txnid":"asdfadcd334","billingAddress":{"city":"beijing"}}], } ] } }
-
兩者對比,問題和難點
- 為什麼上述的情況可以用聚合模型來處理
- 高並發的操作是不太建議有關聯查詢的,互聯網公司用冗餘數據來避免關聯查詢
- 分散式事務是支援不了太多的並發的
- 啟發學生,想想關係模型資料庫你如何查?如果按照我們新設計的BSon,是不是查詢起來很可愛
聚合模型
- KV鍵值對
- BSON
- 列族
- 顧名思義,是按列存儲數據的。最大的特點是方便存儲結構化和半結構化數據,方便做數據壓縮,對針對某一列或者某幾列的查詢有非常大的IO優勢
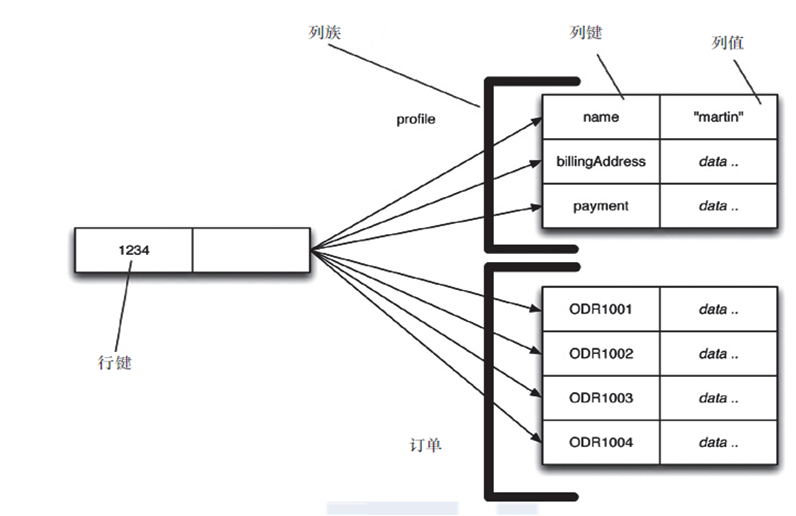
- 顧名思義,是按列存儲數據的。最大的特點是方便存儲結構化和半結構化數據,方便做數據壓縮,對針對某一列或者某幾列的查詢有非常大的IO優勢
- 圖形
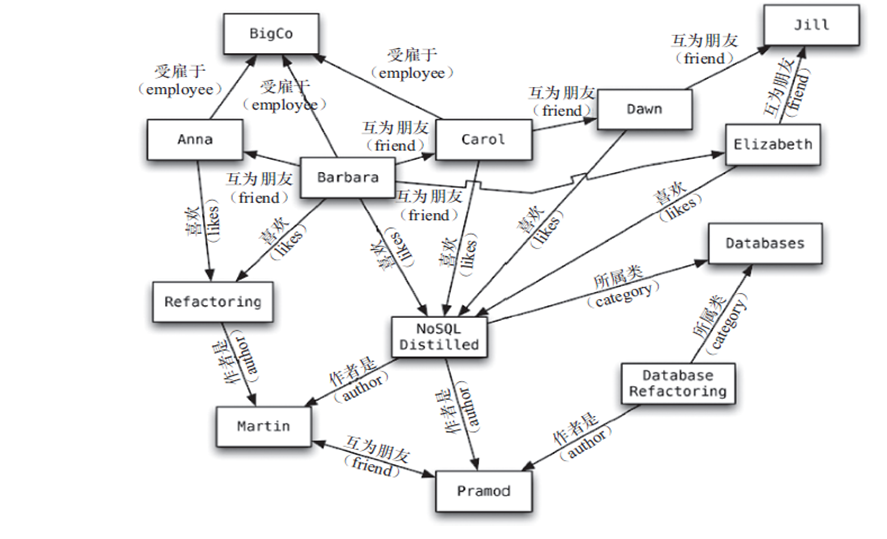


NoSQL資料庫的四大分類
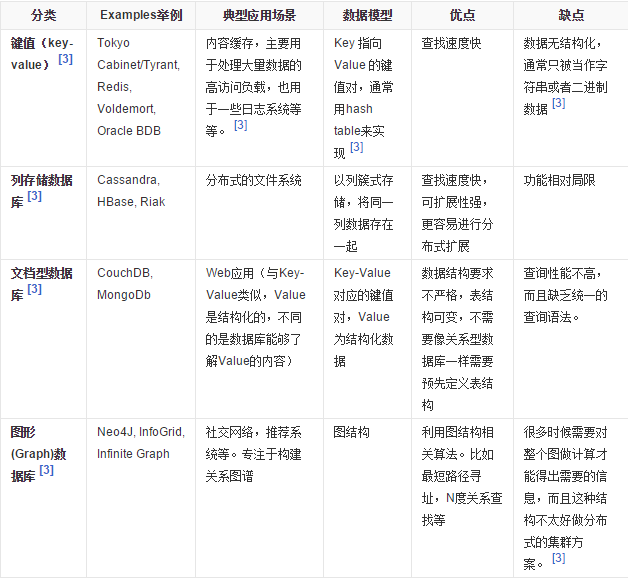
KV鍵值:典型介紹
- 新浪:BerkeleyDB+redis
- 美團:redis+tair
- 阿里、百度:memcache+redis
文檔型資料庫(bson格式比較多):典型介紹
- CouchDB
- MongoDB
- MongoDB 是一個基於分散式文件存儲的資料庫。由 C++ 語言編寫。旨在為 WEB 應用提供可擴展的高性能數據存儲解決方案
- MongoDB 是一個介於關係資料庫和非關係資料庫之間的產品,是非關係資料庫當中功能最豐富,最像關係資料庫的
列存儲資料庫
- Cassandra、HBase
- 分散式文件系統
圖關係資料庫
- 它不是放圖形的,放的是關係比如:朋友圈社交網路、廣告推薦系統,社交網路,推薦系統等。專註於構建關係圖譜
- Neo4j,InfoGrid
四者對比
在分散式資料庫中CAP原理CAP+BASE
傳統的ACID分別是什麼
- A (Atomicity) 原子性
原子性很容易理解,也就是說事務里的所有操作要麼全部做完,要麼都不做,事務成功的條件是事務里的所有操作都成功,只要有一個操作失敗,整個事務就失敗,需要回滾。比如銀行轉賬,從A賬戶轉100元至B賬戶,分為兩個步驟:1)從A賬戶取100元;2)存入100元至B賬戶。這兩步要麼一起完成,要麼一起不完成,如果只完成第一步,第二步失敗,錢會莫名其妙少了100元。 - C (Consistency) 一致性
一致性也比較容易理解,也就是說資料庫要一直處於一致的狀態,事務的運行不會改變資料庫原本的一致性約束。 - I (Isolation) 獨立性
所謂的獨立性是指並發的事務之間不會互相影響,如果一個事務要訪問的數據正在被另外一個事務修改,只要另外一個事務未提交,它所訪問的數據就不受未提交事務的影響。比如現有有個交易是從A賬戶轉100元至B賬戶,在這個交易還未完成的情況下,如果此時B查詢自己的賬戶,是看不到新增加的100元的 - D (Durability) 持久性
持久性是指一旦事務提交後,它所做的修改將會永久的保存在資料庫上,即使出現宕機也不會丟失。
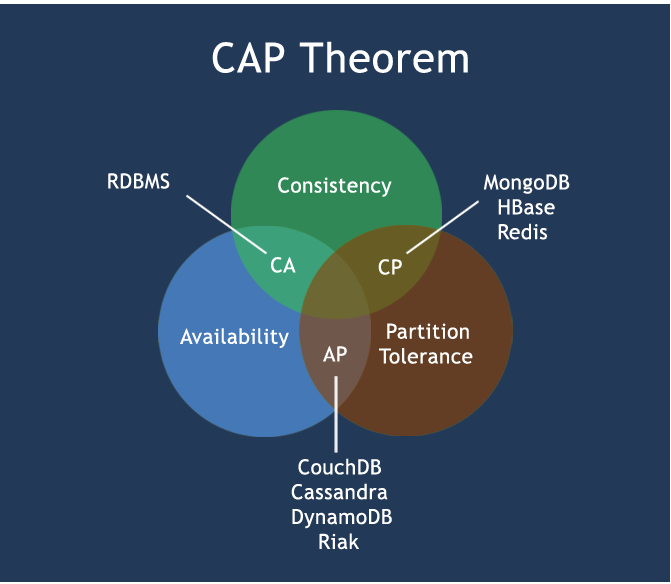
CAP
- C:Consistency(強一致性)
- A:Availability(可用性)
- P:Partition tolerance(分區容錯性)
CAP的三選二
-
CAP理論就是說在分散式存儲系統中,最多只能實現上面的兩點。而由於當前的網路硬體肯定會出現延遲丟包等問題,所以分區容忍性是我們必須需要實現的。所以我們只能在一致性和可用性之間進行權衡,沒有NoSQL系統能同時保證這三點
-
C:強一致性 、A:高可用性 、P:分散式容忍性
-
CA 傳統Oracle資料庫
-
AP 大多數網站架構的選擇
-
CP Redis、Mongodb
-
注意:分散式架構的時候必須做出取捨。一致性和可用性之間取一個平衡。多餘大多數web應用,其實並不需要強一致性。因此犧牲C換取P,這是目前分散式資料庫產品的方向
-
經典CAP圖
- CAP理論的核心是:一個分散式系統不可能同時很好的滿足一致性,可用性和分區容錯性這三個需求,
最多只能同時較好的滿足兩個。因此,根據 CAP 原理將 NoSQL 資料庫分成了滿足 CA 原則、滿足 CP 原則和滿足 AP 原則三 大類: - CA – 單點集群,滿足一致性,可用性的系統,通常在可擴展性上不太強大
- CP – 滿足一致性,分區容忍必的系統,通常性能不是特別高
- AP – 滿足可用性,分區容忍性的系統,通常可能對一致性要求低一些

BASE
-
BASE就是為了解決關係資料庫強一致性引起的問題而引起的可用性降低而提出的解決方案。
-
BASE其實是下面三個術語的縮寫:
- 基本可用(Basically Available)
- 軟狀態(Soft state)
- 最終一致(Eventually consistent)
-
它的思想是通過讓系統放鬆對某一時刻數據一致性的要求來換取系統整體伸縮性和性能上改觀。為什麼這麼說呢,緣由就在於大型系統往往由於地域分布和極高性能的要求,不可能採用分散式事務來完成這些指標,要想獲得這些指標,我們必須採用另外一種方式來完成,這裡BASE就是解決這個問題的辦法
分散式+集群簡介
-
分散式系統(distributed system
- 由多台電腦和通訊的軟體組件通過電腦網路連接(本地網路或廣域網)組成。分散式系統是建立在網路之上的軟體系統。正是因為軟體的特性,所以分散式系統具有高度的內聚性和透明性。因此,網路和分散式系統之間的區別更多的在於高層軟體(特別是作業系統),而不是硬體。分散式系統可以應用在在不同的平台上如:Pc、工作站、區域網和廣域網上等。
-
簡單來講:
-
分散式:不同的多台伺服器上面部署不同的服務模組(工程),他們之間通過Rpc/Rmi之間通訊和調用,對外提供服務和組內協作
-
集群:不同的多台伺服器上面部署相同的服務模組,通過分散式調度軟體進行統一的調度,對外提供服務和訪問
-
Redis入門介紹
入門概述
是什麼
-
Redis:REmote DIctionary Server(遠程字典伺服器)
-
是完全開源免費的,用C語言編寫的,遵守BSD協議,是一個高性能的(key/value)分散式記憶體資料庫,基於記憶體運行,並支援持久化的NoSQL資料庫,是當前最熱門的NoSql資料庫之一,也被人們稱為數據結構伺服器
-
Redis 與其他 key – value 快取產品(memcache)有以下三個特點
- Redis支援數據的持久化,可以將記憶體中的數據保持在磁碟中,重啟的時候可以再次載入進行使用
- Redis不僅僅支援簡單的key-value類型的數據,同時還提供list,set,zset,hash等數據結構的存儲
- Redis支援數據的備份,即master-slave模式的數據備份
能幹嘛
- 記憶體存儲和持久化:redis支援非同步將記憶體中的數據寫到硬碟上,同時不影響繼續服務
- 取最新N個數據的操作,如:可以將最新的10條評論的ID放在Redis的List集合裡面
- 模擬類似於HttpSession這種需要設定過期時間的功能
- 發布、訂閱消息系統
- 定時器、計數器
去哪下
怎麼玩
- 數據類型、基本操作和配置
- 持久化和複製,RDB/AOF
- 事務的控制
- 複製
- ……
Redis的安裝
下載redis到/opt目錄
- 第三方軟體習慣放置於/opt目錄下
執行make、make install命令
-
注意gcc版本
-
詳細操作參考:升級gcc
Redis啟動
- 進入默認安裝目錄 /usr/local/bin
- redis-server redis.conf(自定義的conf文件)
- redis-cli -p 6379
Redis啟動後雜項基礎知識講解
單進程
- 單進程模型來處理客戶端的請求。對讀寫等事件的響應是通過對epoll函數的包裝來做到的。Redis的實際處理速度完全依靠主進程的執行效率
- Epoll是Linux內核為處理大批量文件描述符而作了改進的epoll,是Linux下多路復用IO介面select/poll的增強版本,它能顯著提高程式在大量並發連接中只有少量活躍的情況下的系統CPU利用率
默認16個資料庫,類似數組下表從零開始,初始默認使用零號庫
- 設置資料庫的數量,默認資料庫為0,可以使用SELECT
命令在連接上指定資料庫id
databases 16
Select命令切換資料庫
-
select 0
Dbsize查看當前資料庫的key的數量
keys列出庫中所有的key
- keys *
- keys k? 類似模糊查找
FlushDb:清空當前庫
FlushALL:通殺所有庫
統一密碼管理,16個庫都是同樣密碼,要麼都OK要麼一個也連接不上
Redis索引都是從零開始
為什麼默認埠是6379
Redis數據類型
Redis的五大數據類型
String(字元串)
- string是redis最基本的類型,你可以理解成與Memcached一模一樣的類型,一個key對應一個value
- string類型是二進位安全的。意思是redis的string可以包含任何數據。比如jpg圖片或者序列化的對象
- string類型是Redis最基本的數據類型,一個redis中字元串value最多可以是512M
Hash(哈希,類似java里的Map)
- Redis hash 是一個鍵值對集合
- Redis hash是一個string類型的field和value的映射表,hash特別適合用於存儲對象
- 類似Java裡面的Map<String,Object>
List(列表)
- Redis 列表是簡單的字元串列表,按照插入順序排序,你可以添加一個元素到列表的頭部(左邊)或尾部
- 它的底層實際是個鏈表
Set(集合)
- Redis的Set是string類型的無序無重複集合。它是通過HashTable實現實現的
- 注意:new HashSet 底層相當於new HashMap(詳情查看JDK源碼)
Zset(sorted set :有序集合)
- Redis zset 和 set 一樣也是string類型元素的集合,且不允許重複的成員,不同的是每個元素都會關聯一個double類型的分數
- redis正是通過分數來為集合中的成員進行從小到大的排序。zset的成員是唯一的,但分數(score)卻可以重複。
哪裡去獲得redis常見數據類型操作命令
redis命令參考大全




Redis鍵(key)
常用
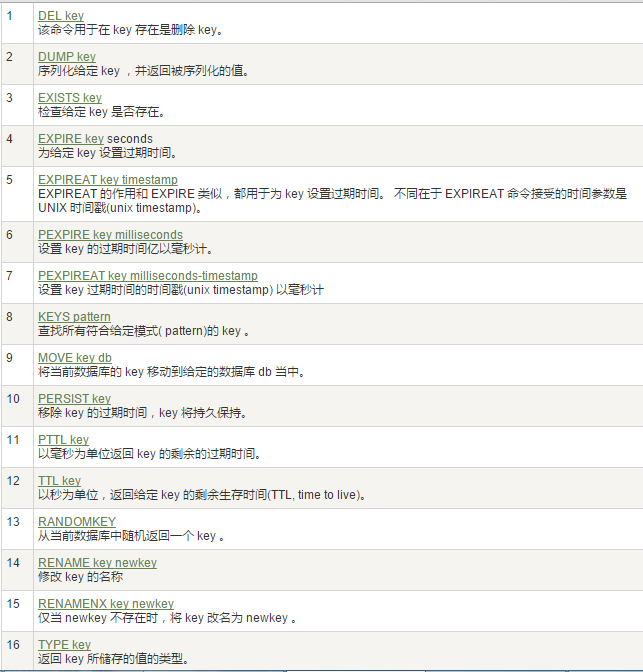
案例
- keys *
- exists key的名字,判斷某個key是否存在
- move key db —>當前庫就沒有了,被移除了
- expire key 秒鐘:為給定的key設置過期時間
- ttl key 查看還有多少秒過期,-1表示永不過期,-2表示已過期
- type key 查看你的key是什麼類型
Redis字元串(String)
常用
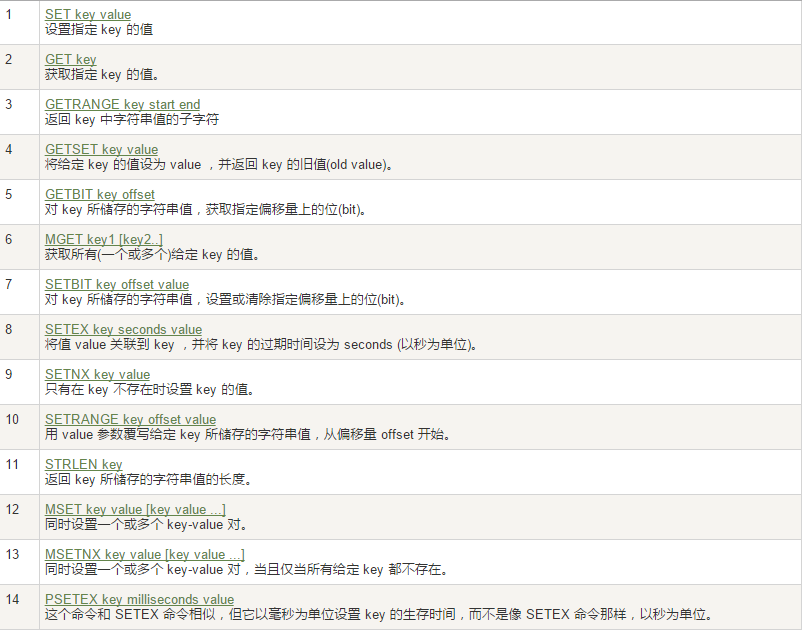

單值單Value
案例
set/get/del/append/strlen
Incr/decr/incrby/decrby,一定要是數字才能進行加減
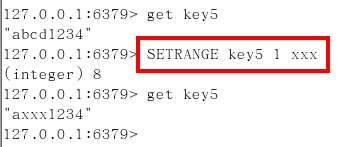
getrange/setrange
- getrange:獲取指定區間範圍內的值,類似between……and的關係

- setrange設置指定區間範圍內的值,格式是setrange key值 具體值


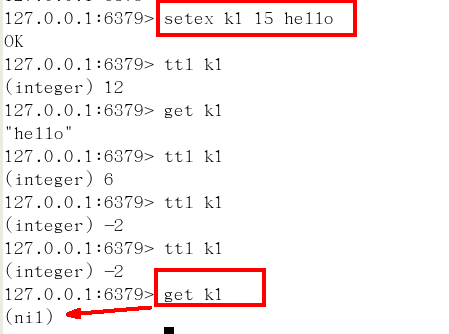
setex(set with expire)鍵秒值/setnx(set if not exist)
- setex:設置帶過期時間的key,動態設置
- setex 鍵 秒值 真實值
- setnx:只有在 key 不存在時設置 key 的值

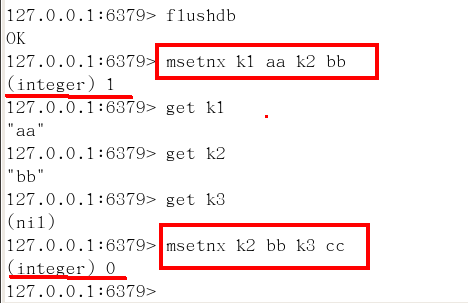
mset/mget/msetnx
- mset:同時設置一個或多個 key-value 對

- mget:獲取所有(一個或多個)給定 key 的值

- msetnx:同時設置一個或多個 key-value 對,當且僅當所有給定 key 都不存在



getset(先get再set)
- getset:將給定 key 的值設為 value ,並返回 key 的舊值(old value),簡單一句話,先get然後立即set


Redis列表(List)
常用
單值多Value
案例
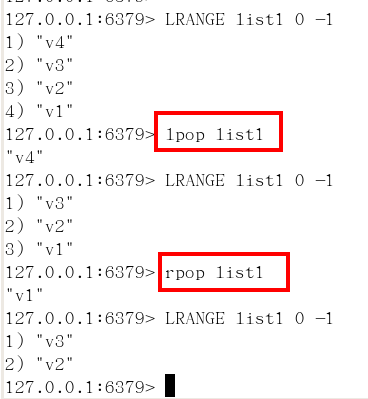
lpush(列表頭部)/rpush(尾部)/lrange
lpop/rpop
lindex,按照索引下標獲得元素(從上到下)
llen
lrem key 刪N個value
- 從left往right刪除2個值等於v1的元素,返回的值為實際刪除的數量
- LREM list3 0 值,表示刪除全部給定的值。零個就是全部值
ltrim key 開始index 結束index,截取指定範圍的值後再賦值給key
rpoplpush 源列表 目的列表
lset key index value
linsert key before/after 值1 值2
性能總結
-
它是一個字元串鏈表,left、right都可以插入添加;如果鍵不存在,創建新的鏈表;如果鍵已存在,新增內容;如果值全移除,對應的鍵也就消失了。
-
鏈表的操作無論是頭和尾效率都極高,但假如是對中間元素進行操作,效率就很慘淡了。
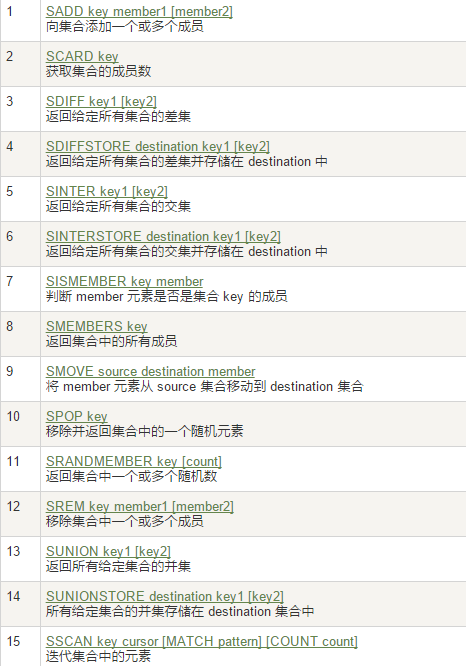
Redis集合(Set)
常用
單值多Value
案例
sadd/smembers/sismember

scard,獲取集合裡面的元素個數

srem key value 刪除集合中元素
srandmember key 某個整數(隨機出幾個數)
spop key 隨機出棧
smove key1 key2 在key1里某個值 作用是將key1里的某個值賦給key2
數學集合類
- 差集:sdiff 在第一個set裡面而不在後面任何一個set裡面的項
- 交集:sinter
- 並集:sunion
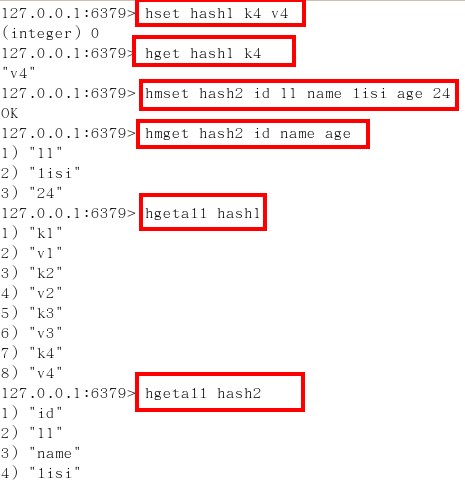
Redis哈希(Hash)
常用
KV模式不變,但V是一個鍵值對
案例
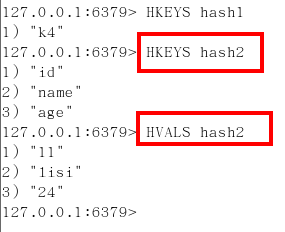
hset/hget/hmset/hmget/hgetall/hdel(*)
hlen
hexists key 在key裡面的某個值的key
hkeys/hvals
hincrby/hincrbyfloat
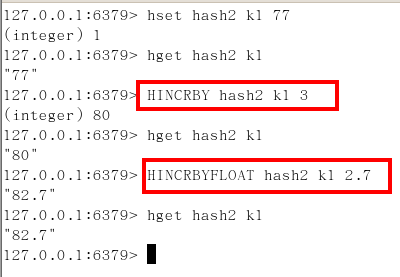
hsetnx
- 不存在賦值,存在了無效
Redis有序集合Zset(sorted set)
常用
區別set
-
在set基礎上,加一個score值,之前set是k1 v1 v2 v3,現在zset是k1 score1 v1 score2 v2
案例
zadd/zrange
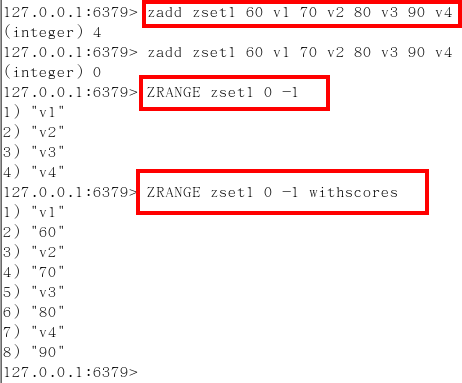
zrangebyscore key 開始score 結束score
- withscores
- ( 不包含
- Limit 作用是返回限制 limit 開始下標步 多少步
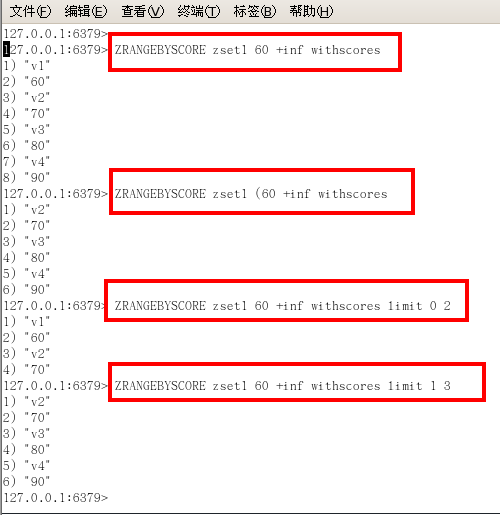

zrem key 某score下對應的value值,作用是刪除元素
- 刪除元素,格式是zrem zset的key 項的值,項的值可以是多個,zrem key score某個對應值,可以是多個值
zcard/zcount key score區間/zrank key values值,作用是獲得下標值/zscore key 對應值,獲得分數
- zcard :獲取集合中元素個數
- zcount :獲取分數區間內元素個數,zcount key 開始分數區間 結束分數區間
- zrank: 獲取value在zset中的下標位置
- zscore:按照值獲得對應的分數
zrevrank key values值,作用是逆序獲得下標值
zrevrange
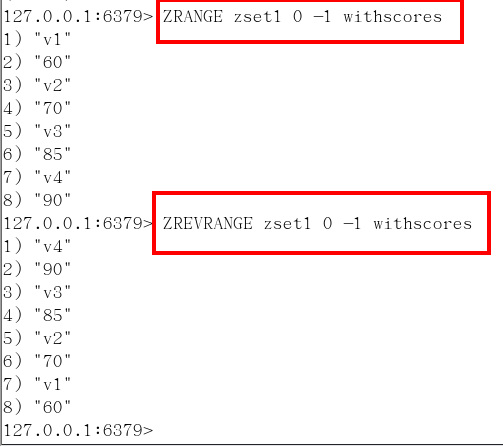
zrevrangebyscore key 結束score 開始score
- zrevrangebyscore zset1 90 60 withscores 分數是反著來的
解析配置文件redis.conf
Units單位
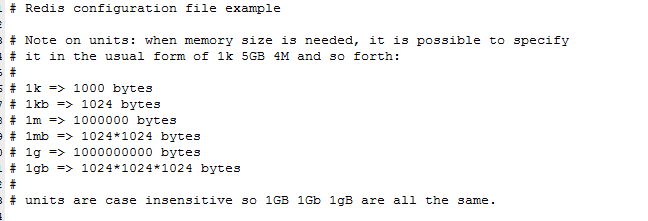
- 配置大小單位,開頭定義了一些基本的度量單位,只支援bytes,不支援bit
- 對大小寫不敏感

INCLUDES包含
- 可以通過includes包含,redis.conf可以作為總閘,包含其他
GENERAL通用
Daemonize 守護執行緒方式啟動
Pidfile
Port
Tcp-backlog
- 設置tcp的backlog,backlog其實是一個連接隊列,backlog隊列總和=未完成三次握手隊列 + 已經完成三次握手隊列。
- 在高並發環境下你需要一個高backlog值來避免慢客戶端連接問題。注意Linux內核會將這個值減小到/proc/sys/net/core/somaxconn的值,所以需要確認增大somaxconn和tcp_max_syn_backlog兩個值
來達到想要的效果
Timeout
Bind
Tcp-keepalive
- 單位為秒,如果設置為0,則不會進行Keepalive檢測,建議設置成60
Loglevel
- debug (development/testing)
- verbose
- notice (production probably)
- warning
Logfile
Syslog-enabled
Syslog-ident
Syslog-facility
Databases
SNAPSHOTTING快照(*)
Save
-
格式: save 秒鐘 寫操作的次數
-
RDB是整個記憶體的壓縮過的Snapshot,RDB的數據結構,可以配置複合的快照觸發條件,
-
默認是1分鐘內改了1萬次,或5分鐘內改了10次,或15分鐘內改了1次
-
save 900 1
-
save 300 5
-
save 60 10000
-
-
禁用
- 如果想禁用RDB持久化的策略,只要不設置任何save指令,或者給save傳入一個空字元串參數也可以
- save 「 」
Stop-writes-on-bgsave-error
-
如果保存出錯 停止寫操作的意思
-
如果配置成no,表示你不在乎數據不一致或者有其他的手段發現和控制
rdbcompression
- rdbcompression:對於存儲到磁碟中的快照,可以設置是否進行壓縮存儲。如果是的話,redis會採用
LZF演算法進行壓縮。如果你不想消耗CPU來進行壓縮的話,可以設置為關閉此功能
rdbchecksum
- rdbchecksum:在存儲快照後,還可以讓redis使用CRC64演算法來進行數據校驗,但是這樣做會增加大約
10%的性能消耗,如果希望獲取到最大的性能提升,可以關閉此功能
dbfilename
dir
- 獲取目錄:config get dir
REPLICATION複製
SECURITY安全
- 訪問密碼的查看、設置和取消
LIMITS限制
- Maxclients
- 設置redis同時可以與多少個客戶端進行連接。默認情況下為10000個客戶端。當你無法設置進程文件句柄限制時,redis會設置為當前的文件句柄限制值減去32,因為redis會為自身內部處理邏輯留一些句柄出來。如果達到了此限制,redis則會拒絕新的連接請求,並且向這些連接請求方發出「max number of clients reached」以作回應。
- Maxmemory
- 設置redis可以使用的記憶體量。一旦到達記憶體使用上限,redis將會試圖移除內部數據,移除規則可以通過maxmemory-policy來指定。如果redis無法根據移除規則來移除記憶體中的數據,或者設置了「不允許移除」,
那麼redis則會針對那些需要申請記憶體的指令返回錯誤資訊,比如SET、LPUSH等。 - 但是對於無記憶體申請的指令,仍然會正常響應,比如GET等。如果你的redis是主redis(說明你的redis有從redis),那麼在設置記憶體使用上限時,需要在系統中留出一些記憶體空間給同步隊列快取,只有在你設置的是「不移除」的情況下,才不用考慮這個因素
- 設置redis可以使用的記憶體量。一旦到達記憶體使用上限,redis將會試圖移除內部數據,移除規則可以通過maxmemory-policy來指定。如果redis無法根據移除規則來移除記憶體中的數據,或者設置了「不允許移除」,
- Maxmemory-policy
- LRU演算法:leastest recently use 最近最少使用
- Volatile-lru:使用LRU演算法移除key,只對設置了過期時間的鍵
- Allkeys-lru :使用LRU演算法移除key
- Volatile-random :在過期集合中移除隨機的key,只對設置了過期時間的鍵
- Allkeys-random :移除隨機的key
- Volatile-ttl :移除那些TTL值最小的key,即那些最近要過期的key
- Noeviction :不進行移除,針對寫操作,只是返回錯誤資訊
- Maxmemory-samples
- 設置樣本數量,LRU演算法和最小TTL演算法都並非是精確的演算法,而是估算值,所以你可以設置樣本的大小,redis默認會檢查這麼多個key並選擇其中LRU的那個
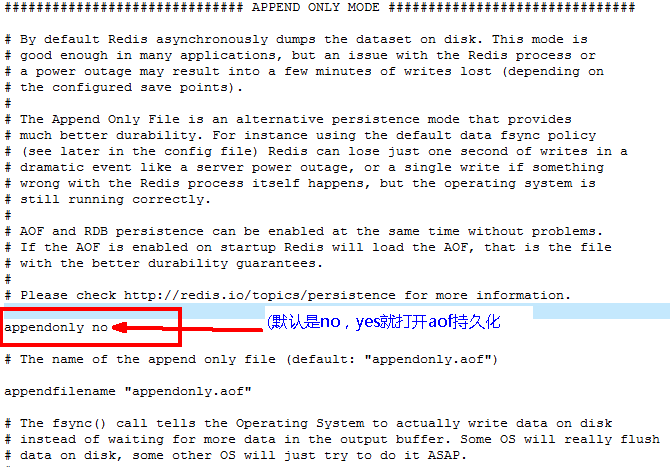
APPEND ONLY MODE追加(*)
appendonly
appendfilename
Appendfsync
-
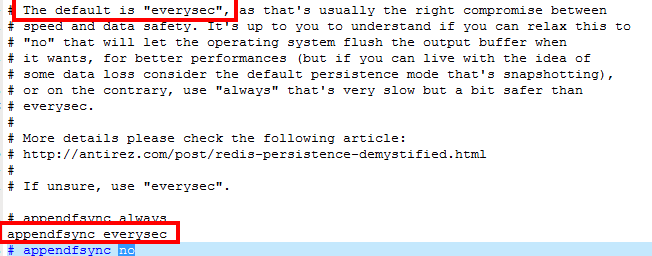
-
三種策略
- Always:同步持久化 每次發生數據變更會被立即記錄到磁碟 性能較差但數據完整性比較好
- Everysec:出廠默認推薦,非同步操作,每秒記錄 如果一秒內宕機,有數據丟失
- No

No-appendfsync-on-rewrite:重寫時是否可以運用Appendfsync,用默認no即可,保證數據安全性
Auto-aof-rewrite-min-size:設置重寫的基準值
Auto-aof-rewrite-percentage:設置重寫的基準值
常見配置redis.conf介紹(*)
參數說明
- redis.conf 配置項說明如下:
- Redis默認不是以守護進程的方式運行,可以通過該配置項修改,使用yes啟用守護進程
daemonize no - 當Redis以守護進程方式運行時,Redis默認會把pid寫入/var/run/redis.pid文件,可以通過pidfile指定
pidfile /var/run/redis.pid - 指定Redis監聽埠,默認埠為6379,作者在自己的一篇博文中解釋了為什麼選用6379作為默認埠,因為6379在手機按鍵上MERZ對應的號碼,而MERZ取自義大利歌女Alessia Merz的名字
port 6379 - 綁定的主機地址
bind 127.0.0.1 - 當 客戶端閑置多長時間後關閉連接,如果指定為0,表示關閉該功能
timeout 300 - 指定日誌記錄級別,Redis總共支援四個級別:debug、verbose、notice、warning,默認為verbose
loglevel verbose - 日誌記錄方式,默認為標準輸出,如果配置Redis為守護進程方式運行,而這裡又配置為日誌記錄方式為標準輸出,則日誌將會發送給/dev/null
logfile stdout - 設置資料庫的數量,默認資料庫為0,可以使用SELECT
命令在連接上指定資料庫id
databases 16 - 指定在多長時間內,有多少次更新操作,就將數據同步到數據文件,可以多個條件配合
save
Redis默認配置文件中提供了三個條件:
save 900 1
save 300 10
save 60 10000
分別表示900秒(15分鐘)內有1個更改,300秒(5分鐘)內有10個更改以及60秒內有10000個更改。 - 指定存儲至本地資料庫時是否壓縮數據,默認為yes,Redis採用LZF壓縮,如果為了節省CPU時間,可以關閉該選項,但會導致資料庫文件變的巨大
rdbcompression yes - 指定本地資料庫文件名,默認值為dump.rdb
dbfilename dump.rdb - 指定本地資料庫存放目錄
dir ./ - 設置當本機為slav服務時,設置master服務的IP地址及埠,在Redis啟動時,它會自動從master進行數據同步
slaveof - 當master服務設置了密碼保護時,slav服務連接master的密碼
masterauth - 設置Redis連接密碼,如果配置了連接密碼,客戶端在連接Redis時需要通過AUTH
命令提供密碼,默認關閉
requirepass foobared - 設置同一時間最大客戶端連接數,默認無限制,Redis可以同時打開的客戶端連接數為Redis進程可以打開的最大文件描述符數,如果設置 maxclients 0,表示不作限制。當客戶端連接數到達限制時,Redis會關閉新的連接並向客戶端返回max number of clients reached錯誤資訊
maxclients 128 - 指定Redis最大記憶體限制,Redis在啟動時會把數據載入到記憶體中,達到最大記憶體後,Redis會先嘗試清除已到期或即將到期的Key,當此方法處理 後,仍然到達最大記憶體設置,將無法再進行寫入操作,但仍然可以進行讀取操作。Redis新的vm機制,會把Key存放記憶體,Value會存放在swap區
maxmemory - 指定是否在每次更新操作後進行日誌記錄,Redis在默認情況下是非同步的把數據寫入磁碟,如果不開啟,可能會在斷電時導致一段時間內的數據丟失。因為 redis本身同步數據文件是按上面save條件來同步的,所以有的數據會在一段時間內只存在於記憶體中。默認為no
appendonly no - 指定更新日誌文件名,默認為appendonly.aof
appendfilename appendonly.aof - 指定更新日誌條件,共有3個可選值:
no:表示等作業系統進行數據快取同步到磁碟(快)
always:表示每次更新操作後手動調用fsync()將數據寫到磁碟(慢,安全)
everysec:表示每秒同步一次(折衷,默認值)
appendfsync everysec - 指定是否啟用虛擬記憶體機制,默認值為no,簡單的介紹一下,VM機制將數據分頁存放,由Redis將訪問量較少的頁即冷數據swap到磁碟上,訪問多的頁面由磁碟自動換出到記憶體中(在後面的文章我會仔細分析Redis的VM機制)
vm-enabled no - 虛擬記憶體文件路徑,默認值為/tmp/redis.swap,不可多個Redis實例共享
vm-swap-file /tmp/redis.swap - 將所有大於vm-max-memory的數據存入虛擬記憶體,無論vm-max-memory設置多小,所有索引數據都是記憶體存儲的(Redis的索引數據 就是keys),也就是說,當vm-max-memory設置為0的時候,其實是所有value都存在於磁碟。默認值為0
vm-max-memory 0 - Redis swap文件分成了很多的page,一個對象可以保存在多個page上面,但一個page上不能被多個對象共享,vm-page-size是要根據存儲的 數據大小來設定的,作者建議如果存儲很多小對象,page大小最好設置為32或者64bytes;如果存儲很大大對象,則可以使用更大的page,如果不 確定,就使用默認值
vm-page-size 32 - 設置swap文件中的page數量,由於頁表(一種表示頁面空閑或使用的bitmap)是在放在記憶體中的,,在磁碟上每8個pages將消耗1byte的記憶體。
vm-pages 134217728 - 設置訪問swap文件的執行緒數,最好不要超過機器的核數,如果設置為0,那麼所有對swap文件的操作都是串列的,可能會造成比較長時間的延遲。默認值為4
vm-max-threads 4 - 設置在向客戶端應答時,是否把較小的包合併為一個包發送,默認為開啟
glueoutputbuf yes - 指定在超過一定的數量或者最大的元素超過某一臨界值時,採用一種特殊的哈希演算法
hash-max-zipmap-entries 64
hash-max-zipmap-value 512 - 指定是否激活重置哈希,默認為開啟(後面在介紹Redis的哈希演算法時具體介紹)
activerehashing yes - 指定包含其它的配置文件,可以在同一主機上多個Redis實例之間使用同一份配置文件,而同時各個實例又擁有自己的特定配置文件
include /path/to/local.conf
- Redis默認不是以守護進程的方式運行,可以通過該配置項修改,使用yes啟用守護進程
Redis持久化(*)
總體介紹
官網
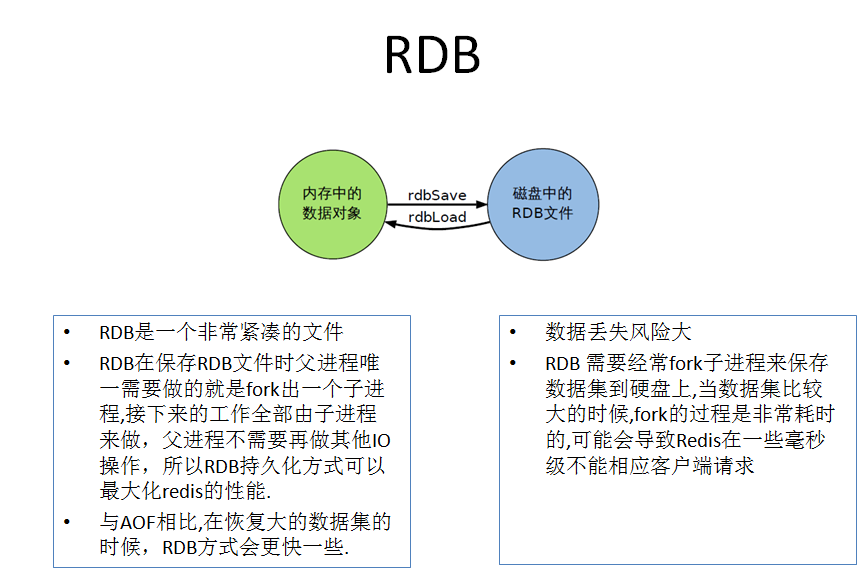
RDB(Redis DataBase)
是什麼
- 在指定的時間間隔內將記憶體中的數據集快照寫入磁碟,也就是行話講的Snapshot快照,它恢復時是將快照文件直接讀到記憶體里
- Redis會單獨創建(fork)一個子進程來進行持久化,會先將數據寫入到一個臨時文件中,待持久化過程都結束了,再用這個臨時文件替換上次持久化好的文件。整個過程中,主進程是不進行任何IO操作的,這就確保了極高的性能如果需要進行大規模數據的恢復,且對於數據恢復的完整性不是非常敏感,那RDB方式要比AOF方式更加的高效。RDB的缺點是最後一次持久化後的數據可能丟失
Fork
- Fork的作用是複製一個與當前進程一樣的進程,新進程的多有數據(變數、環境變數、程式計數器等)數值都和原進程一致,但是是一個全新的進程,並作為原進程的子進程
Rdb 保存的是dump.rdb文件
- save 命令 迅速備份 快速生成rdb文件
配置文件的位置(參照解析配置文件的快照)
如何觸發RDB快照
配置文件默認的快照配置
- 默認是1分鐘內改了1萬次,或5分鐘內改了10次,或15分鐘內改了1次
- save 900 1
- save 300 5
- save 60 10000
命令save或者是bgsave
- 都可以迅速 立刻生成dump.rdb文件
- Save:save時只管保存,其它不管,全部阻塞
- BGSAVE:Redis會在後台非同步進行快照操作,快照同時還可以響應客戶端請求。可以通過lastsave
命令獲取最後一次成功執行快照的時間
執行flushall命令,也會產生dump.rdb文件,但裡面是空的,無意義
如何恢復
- 將備份文件 (dump.rdb) 移動到 redis 安裝目錄並啟動服務即可
- CONFIG GET dir獲取目錄
優勢
適合大規模的數據恢復
對數據完整性和一致性要求不高
劣勢
在一定間隔時間做一次備份,所以如果redis意外down掉的話,就會丟失最後一次快照後的所有修改
Fork的時候,記憶體中的數據被克隆了一份,大致2倍的膨脹性需要考慮
如何停止
動態所有停止RDB保存規則的方法:redis-cli config set save “”
小總結
AOF(Append Only File)
官網
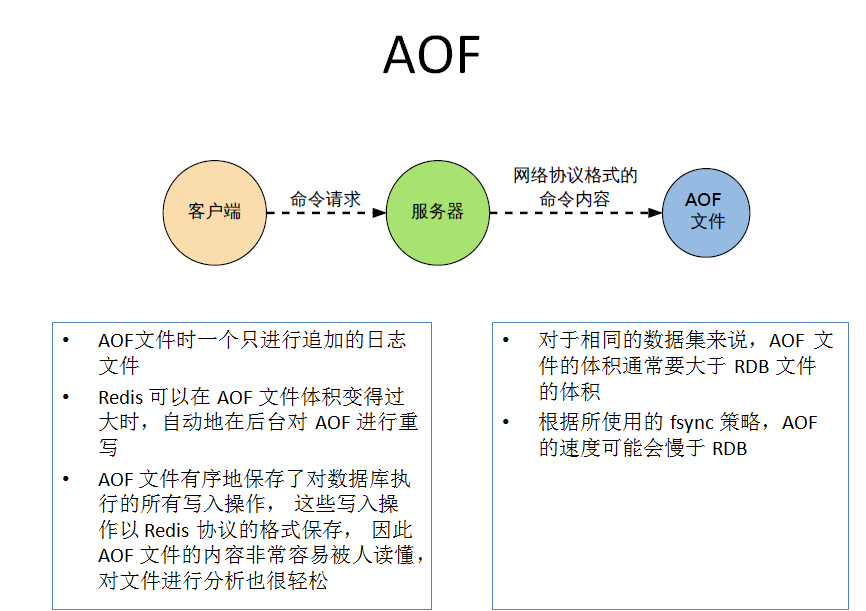
是什麼
- 以日誌的形式來記錄每個寫操作,將Redis執行過的所有寫指令記錄下來(讀操作不記錄),只許追加文件但不可以改寫文件,redis啟動之初會讀取該文件重新構建數據,換言之,redis重啟的話就根據日誌文件的內容將寫指令從前到後執行一次以完成數據的恢復工作
AOF保存的是appendonly.aof文件
配置位置
-
-
見解析配置文件—APPEND ONLY MODE追加

AOF啟動/修復/恢復
正常恢復
- 啟動:設置Yes,修改默認的appendonly no,改為yes
- 將有數據的aof文件複製一份保存到對應目錄(config get dir)
- 恢復:重啟redis然後重新載入
異常恢復
-
啟動:設置Yes,修改默認的appendonly no,改為yes
-
備份被寫壞的AOF文件
-
修復:Redis-check-aof –fix aof文件 進行修復
-
恢復:重啟redis然後重新載入
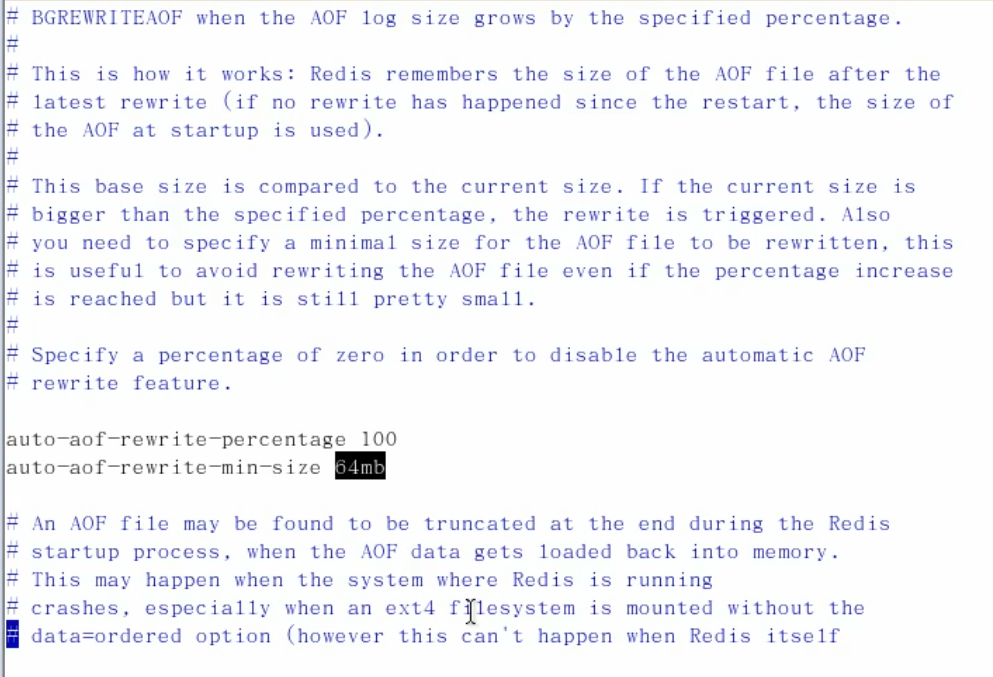
Rewrite
是什麼
-
-
AOF採用文件追加方式,文件會越來越大為避免出現此種情況,新增了重寫機制,當AOF文件的大小超過所設定的閾值時,Redis就會啟動AOF文件的內容壓縮,只保留可以恢複數據的最小指令集.可以使用命令bgrewriteaof

重寫原理
- AOF文件持續增長而過大時,會fork出一條新進程來將文件重寫(也是先寫臨時文件最後再rename),遍歷新進程的記憶體中數據,每條記錄有一條的Set語句。重寫aof文件的操作,並沒有讀取舊的aof文件,而是將整個記憶體中的資料庫內容用命令的方式重寫了一個新的aof文件,這點和快照有點類似
觸發機制
- Redis會記錄上次重寫時的AOF大小,默認配置是當AOF文件大小是上次rewrite後大小的一倍且文件大於64M時觸發
優勢
- 每修改同步:appendfsync always 同步持久化 每次發生數據變更會被立即記錄到磁碟 性能較差但數據完整性比較好
- 每秒同步:appendfsync everysec 非同步操作,每秒記錄 如果一秒內宕機,有數據丟失
- 不同步:appendfsync no 從不同步
劣勢
- 相同數據集的數據而言aof文件要遠大於rdb文件,恢復速度慢於rdb
- Aof運行效率要慢於rdb,每秒同步策略效率較好,不同步效率和rdb相同
小總結
總結(Which one)
官網建議

比較:
-
RDB持久化方式能夠在指定的時間間隔能對你的數據進行快照存儲
-
AOF持久化方式記錄每次對伺服器寫的操作,當伺服器重啟的時候會重新執行這些命令來恢復原始的數據,AOF命令以redis協議追加保存每次寫的操作到文件末尾,Redis還能對AOF文件進行後台重寫,使得AOF文件的體積不至於過大
-
只做快取:如果你只希望你的數據在伺服器運行的時候存在,你也可以不使用任何持久化方式.
同時開啟兩種持久化方式
- 在這種情況下,當redis重啟的時候會優先載入AOF文件來恢復原始的數據,因為在通常情況下AOF文件保存的數據集要比RDB文件保存的數據集要完整
- RDB的數據不實時,同時使用兩者時伺服器重啟也只會找AOF文件。那要不要只使用AOF呢?作者建議不要,因為RDB更適合用於備份資料庫(AOF在不斷變化不好備份),快速重啟,而且不會有AOF可能潛在的bug,留著作為一個萬一的手段。
性能建議
- 因為RDB文件只用作後備用途,建議只在Slave上持久化RDB文件,而且只要15分鐘備份一次就夠了,只保留save 900 1這條規則。
- 如果Enalbe AOF,好處是在最惡劣情況下也只會丟失不超過兩秒數據,啟動腳本較簡單只load自己的AOF文件就可以了。代價一是帶來了持續的IO,二是AOF rewrite的最後將rewrite過程中產生的新數據寫到新文件造成的阻塞幾乎是不可避免的。只要硬碟許可,應該盡量減少AOF rewrite的頻率,AOF重寫的基礎大小默認值64M太小了,可以設到5G以上。默認超過原大小100%大小時重寫可以改到適當的數值。
- 如果不Enable AOF ,僅靠Master-Slave Replication 實現高可用性也可以。能省掉一大筆IO也減少了rewrite時帶來的系統波動。代價是如果Master/Slave同時倒掉,會丟失十幾分鐘的數據,啟動腳本也要比較兩個Master/Slave中的RDB文件,載入較新的那個。新浪微博就選用了這種架構
Redis的事務
是什麼
官網
概述
- 可以一次執行多個命令,本質是一組命令的集合。一個事務中的所有命令都會序列化,按順序地串列化執行而不會被其它命令插入,不許加塞
能幹嘛
-
一個隊列中,一次性、順序性、排他性的執行一系列命令
怎麼玩

常用命令

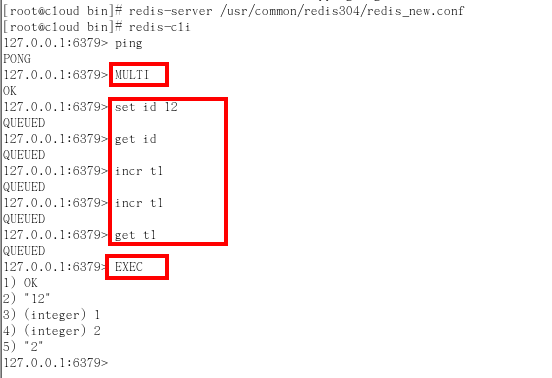
Case1:正常執行
Case2:放棄事務
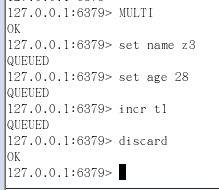
Case3:全體連坐

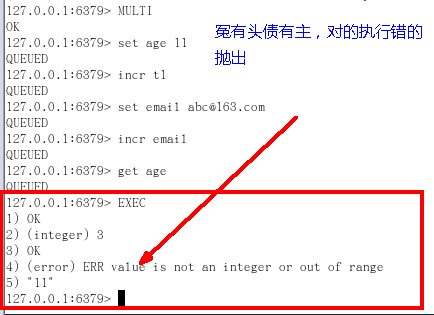
Case4:冤頭債主
-
即使錯了,但是加入進隊列了queued ,而不是像case3在運行時直接報錯並沒有加入隊列
-

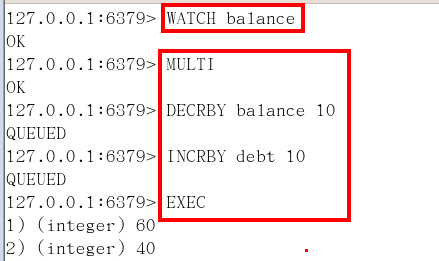
Case5:watch監控
悲觀鎖/樂觀鎖/CAS(Check And Set)
- 悲觀鎖
- 悲觀鎖(Pessimistic Lock), 顧名思義,就是很悲觀,每次去拿數據的時候都認為別人會修改,所以每次在拿數據的時候都會上鎖,這樣別人想拿這個數據就會block直到它拿到鎖。傳統的關係型資料庫裡邊就用到了很多這種鎖機制,比如行鎖,表鎖等,讀鎖,寫鎖等,都是在做操作之前先上鎖
- 樂觀鎖
- 樂觀鎖(Optimistic Lock), 顧名思義,就是很樂觀,每次去拿數據的時候都認為別人不會修改,所以不會上鎖,但是在更新的時候會判斷一下在此期間別人有沒有去更新這個數據,可以使用版本號等機制。樂觀鎖適用於多讀的應用類型,這樣可以提高吞吐量
- 樂觀鎖策略:提交版本必須大於記錄當前版本才能執行更新
- CAS
初始化信用卡可用餘額和欠額

無加塞篡改,先監控再開啟multi,保證兩筆金額變動在同一個事務內
有加塞篡改
- 監控了key,如果key被修改了,後面一個事務的執行失效


unwatch
-
取消監控
-
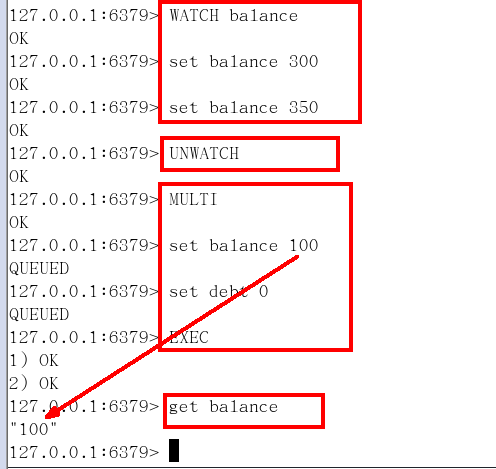

一旦執行了exec之前加的監控鎖都會被取消掉了
小結
-
Watch指令,類似樂觀鎖,事務提交時,如果Key的值已被別的客戶端改變,比如某個list已被別的客戶端push/pop過了,整個事務隊列都不會被執行
-
通過WATCH命令在事務執行之前監控了多個Keys,倘若在WATCH之後有任何Key的值發生了變化,EXEC命令執行的事務都將被放棄,同時返回Nullmulti-bulk應答以通知調用者事務執行失敗
3階段
開啟
- 以MULTI開始一個事務
入隊
- 將多個命令入隊到事務中,接到這些命令並不會立即執行,而是放到等待執行的事務隊列裡面
執行
- 執行:由EXEC命令觸發事務
3特性
-
單獨的隔離操作:事務中的所有命令都會序列化、按順序地執行。事務在執行的過程中,不會被其他客戶端發送來的命令請求所打斷
-
沒有隔離級別的概念:隊列中的命令沒有提交之前都不會實際的被執行,因為事務提交前任何指令都不會被實際執行,也就不存在」事務內的查詢要看到事務里的更新,在事務外查詢不能看到」這個讓人萬分頭痛的問題
-
不保證原子性:redis同一個事務中如果有一條命令執行失敗,其後的命令仍然會被執行,沒有回滾—部分支援事務
Redis的發布和訂閱
是什麼
概述
- 進程間的一種消息通訊模式:發送者(pub)發送消息,訂閱者(sub)接收消息
訂閱/發布消息圖
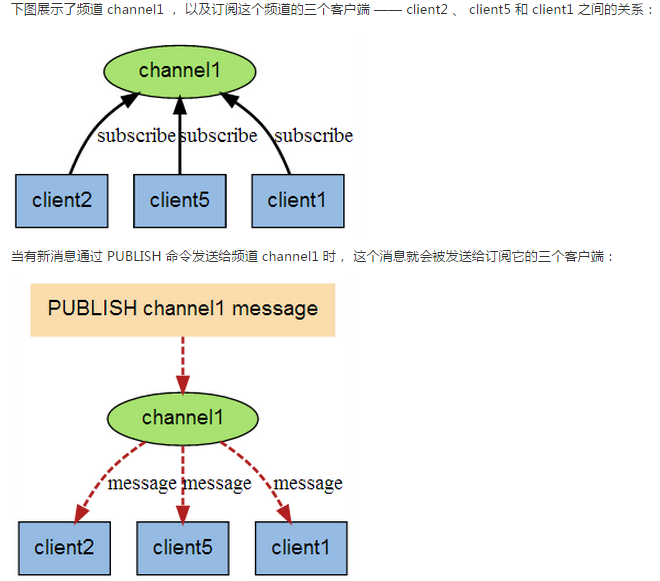
命令

案例
先訂閱後發布後才能收到消息
操作
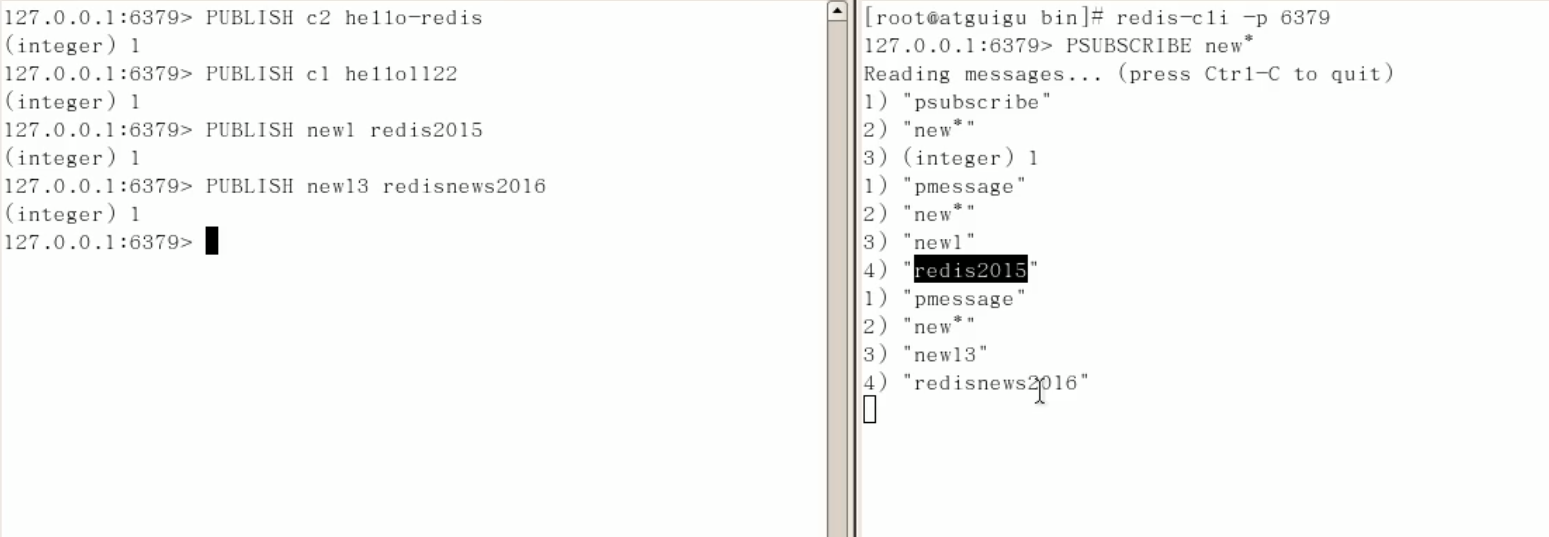
1.1.可以一次性訂閱多個,SUBSCRIBE c1 c2 c3
1.2 消息發布,PUBLISH c2 hello-redis
2.1 訂閱多個,通配符, PSUBSCRIBE new
2.2 收取消息, PUBLISH new1 redis2015
Redis的複製(Master/Slave)
是什麼
官網
- redis主從複製
- 行話:也就是我們所說的主從複製,主機數據更新後根據配置和策略,自動同步到備機的master/slaver機制,Master以寫為主,Slave以讀為主
能幹嘛
讀寫分離
容災恢復
怎麼玩
1.配從(庫)不配主(庫)
2.從庫配置:slaveof 主庫IP 主庫埠
- 每次與master斷開之後,都需要重新連接,除非你配置進redis.conf文件
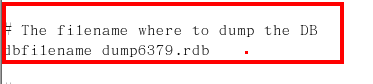
- Info replication
3.修改配置文件細節操作
3.1 拷貝多個redis.conf文件
3.2 開啟daemonize yes
3.3 Pid文件名字
3.4 指定埠
3.5 Log文件名字

3.6 Dump.rdb名字
4.常用3招
一主二仆
-
Init
-
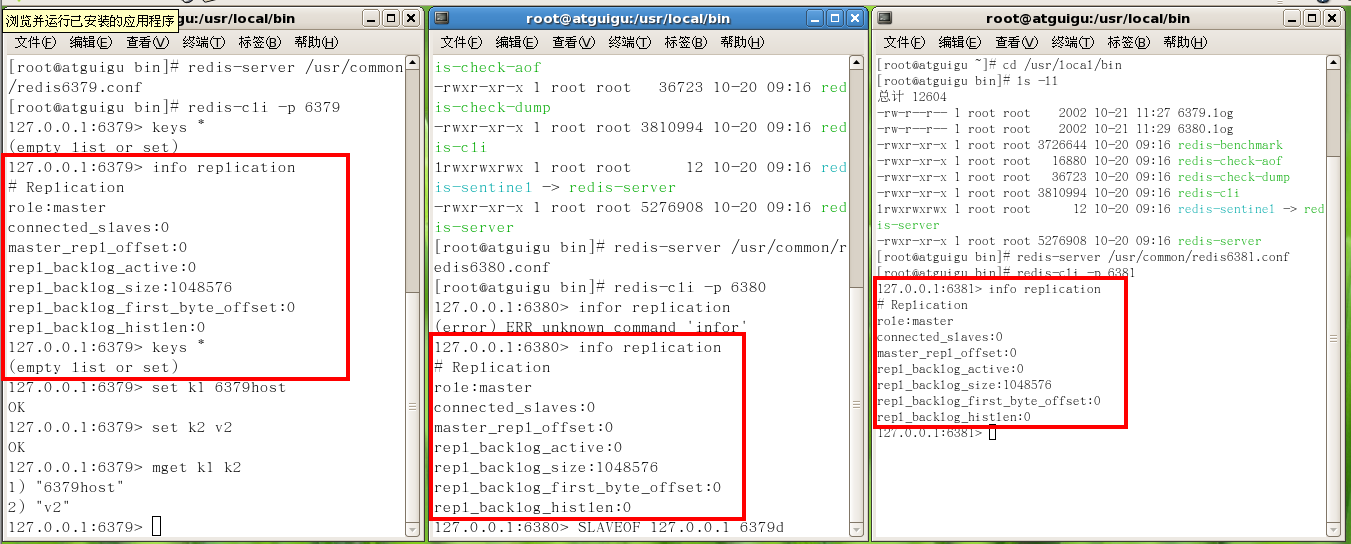
info replication 查看資訊
-
-
-
一個Master兩個Slave
-
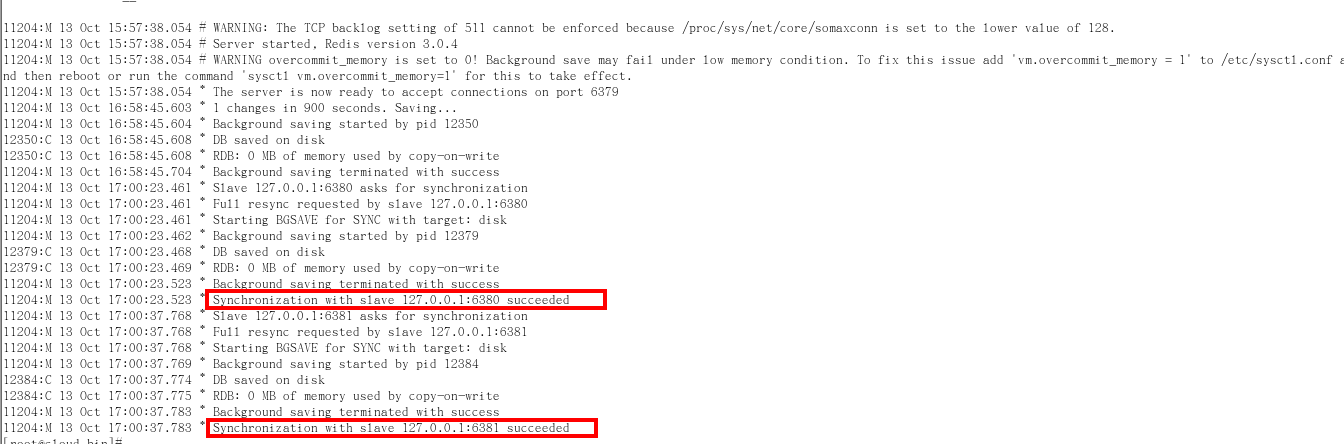
日誌查看
- 主機日誌
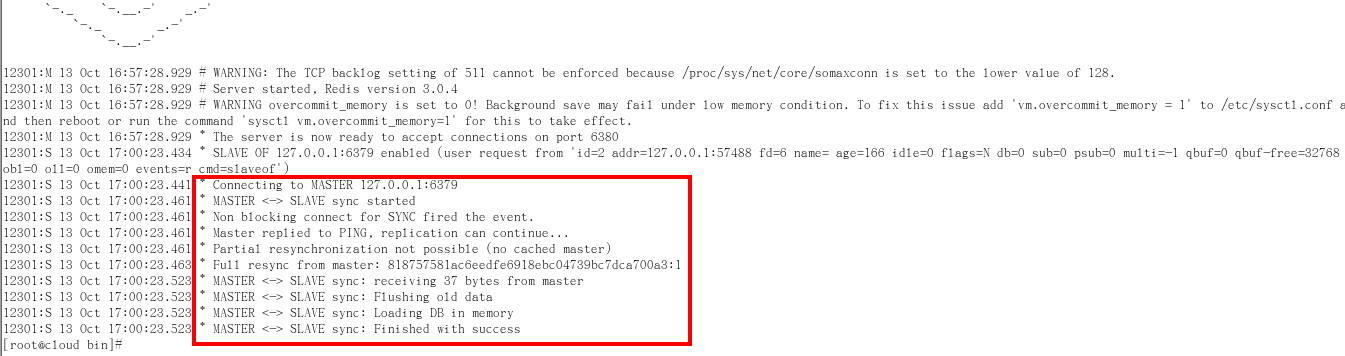
- 從機日誌
- info replication
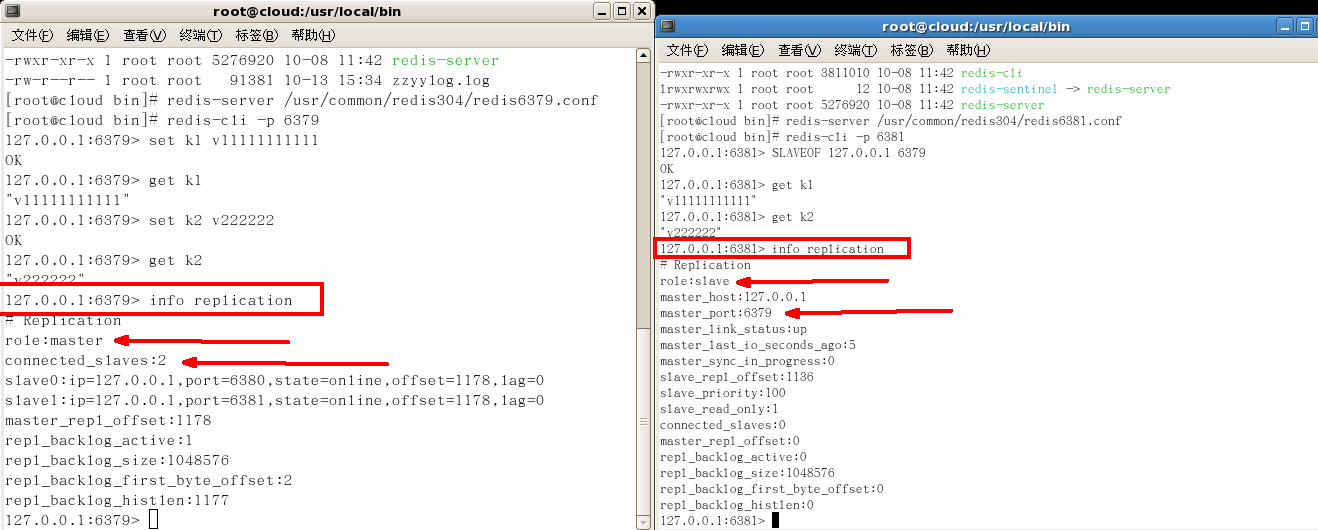
- 主機日誌
-
主從問題演示
-
1.切入點問題?slave1、slave2是從頭開始複製還是從切入點開始複製?比如從k4進來,那之前的123是否也可以複製
答:切入點複製,不需要從頭複製
-
2.從機是否可以寫?set可否?
答:從機只讀,不可set
-
3.主機shutdown後情況如何?從機是上位還是原地待命
答:原地待命,不上位
-
4.主機又回來了後,主機新增記錄,從機還能否順利複製
答:可以順利複製
-
5.其中一台從機down後情況如何?依照原有它能跟上大部隊嗎?
答:恢復後,會取消之前的主從設置,變為master。 重新slaveof即可
-

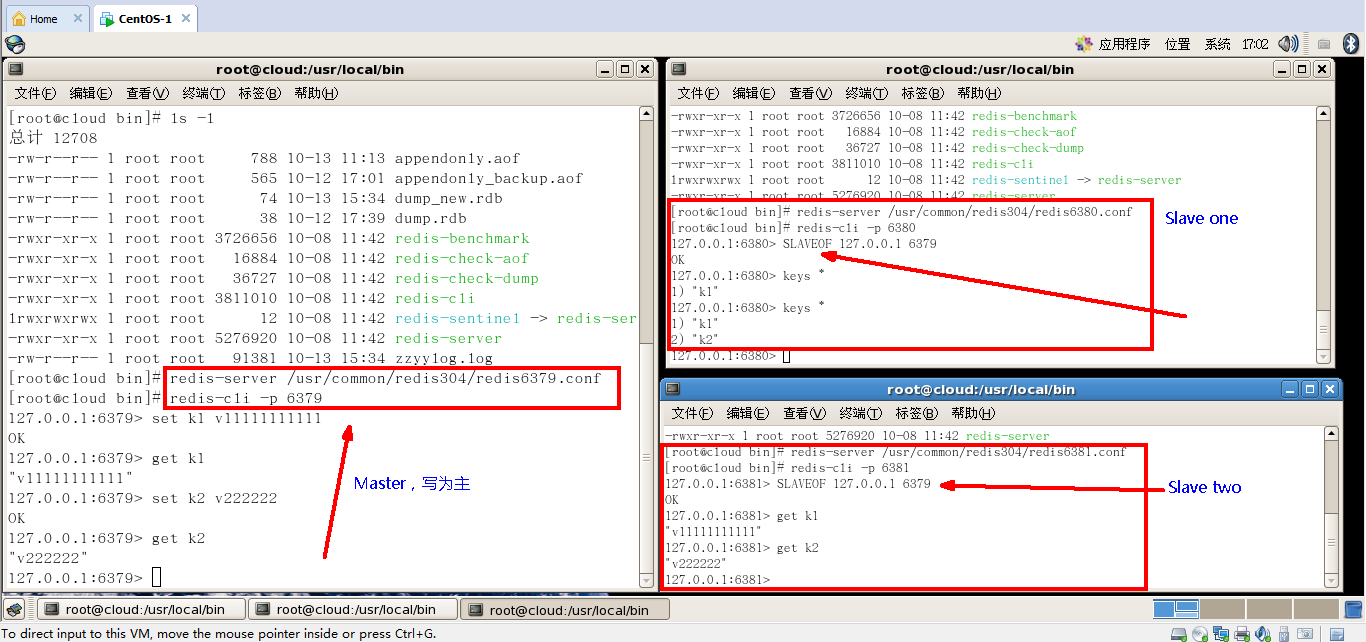



薪火相傳
-
上一個Slave可以是下一個slave的Master,Slave同樣可以接收其他slaves的連接和同步請求,那麼該slave作為了鏈條中下一個的master,可以有效減輕master的寫壓力(去中心化)
-
中途變更轉向:會清除之前的數據,重新建立拷貝最新的
-
Slaveof 新主庫IP 新主庫埠
反客為主
- SLAVEOF no one
- 使當前資料庫停止與其他資料庫的同步,轉成主資料庫
複製原理
複製流程
- Slave啟動成功連接到master後會發送一個sync命令
- Master接到命令啟動後台的存檔進程,同時收集所有接收到的用於修改數據集命令,在後台進程執行完畢之後,master將傳送整個數據文件到slave,以完成一次完全同步
- 全量複製:而slave服務在接收到資料庫文件數據後,將其存檔並載入到記憶體中
- 增量複製:Master繼續將新的所有收集到的修改命令依次傳給slave,完成同步
- 但是只要是重新連接master,一次完全同步(全量複製)將被自動執行
哨兵模式(Sentinel)
是什麼
-
反客為主的自動版,能夠後台監控主機是否故障,如果故障了根據投票數自動將從庫轉換為主庫
使用步驟
1.調整結構,6379帶著80、81
2.新建sentinel.conf文件,名字絕不能錯
3.配置哨兵,填寫內容
- sentinel monitor 被監控資料庫名字(自己起名字) 127.0.0.1 6379 1
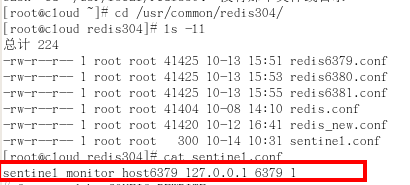
- 上面最後一個數字1,表示主機掛掉後salve投票看讓誰接替成為主機,得票數多少後成為主機

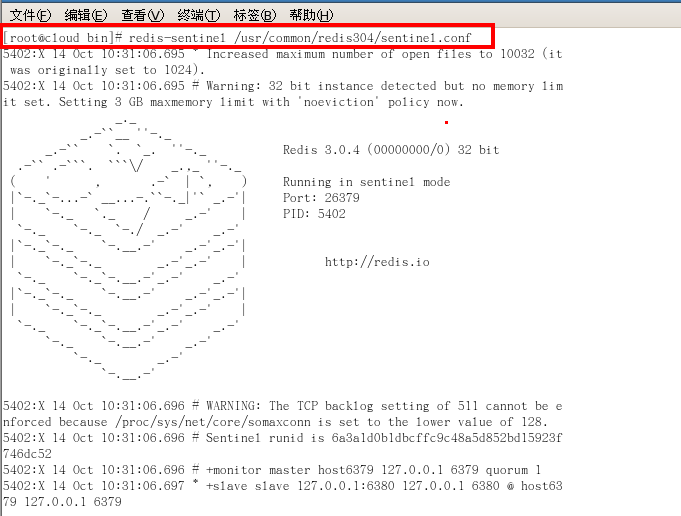
4.啟動哨兵
-
Redis-sentinel /opt/redis-6.0.6/sentinel.conf
-

5.正常主從演示
6.原有的master掛了
7.投票新選
- 哨兵監控到原有的主節點失效,自動投票選舉新主節點
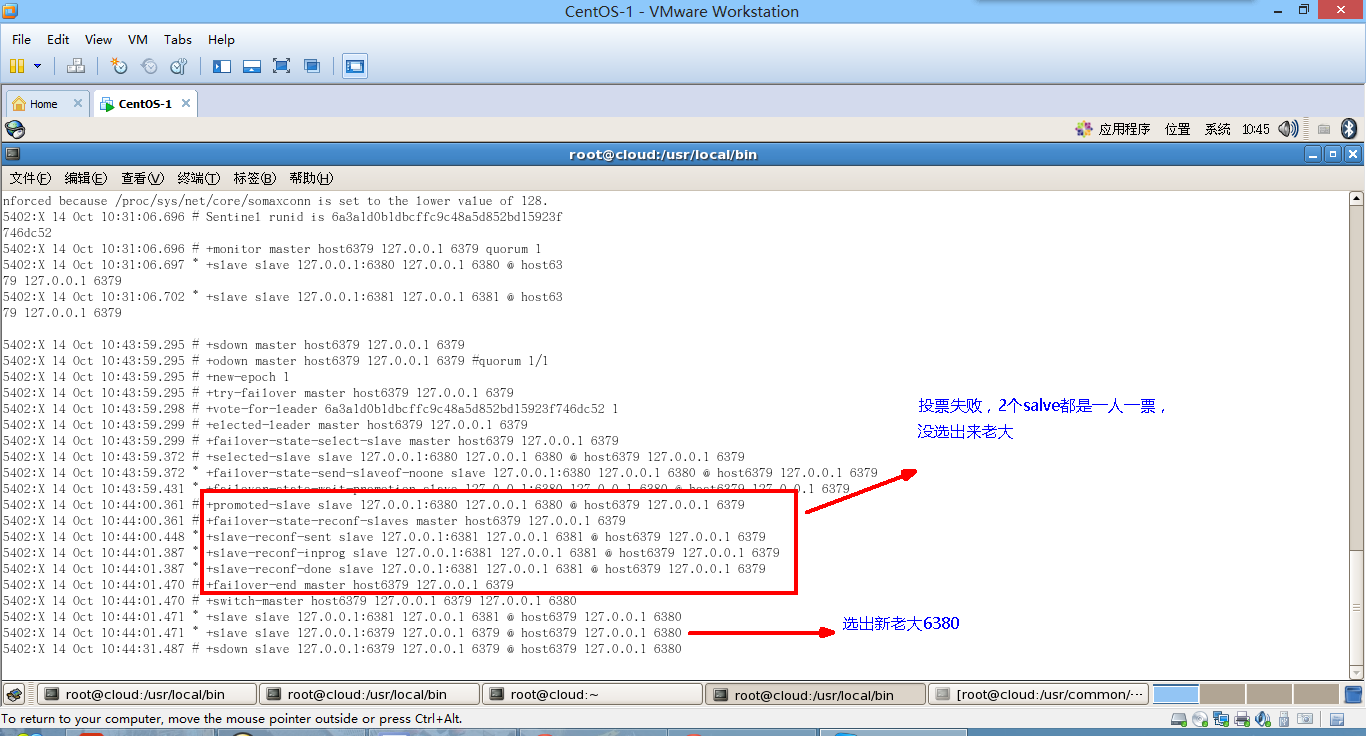

8.重新主從繼續開工,info replication查看
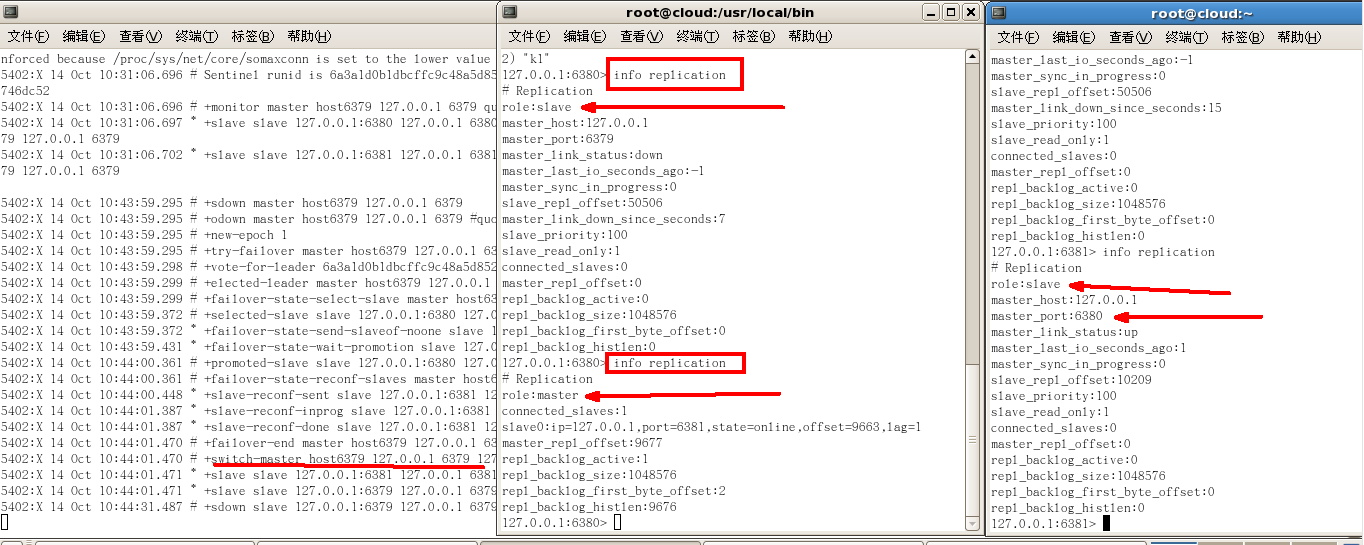
9.問題:如果之前的master重啟回來,會不會雙master衝突?
- 不會
- 保持新選舉的master,原先宕機的master,會變成新master的子節點
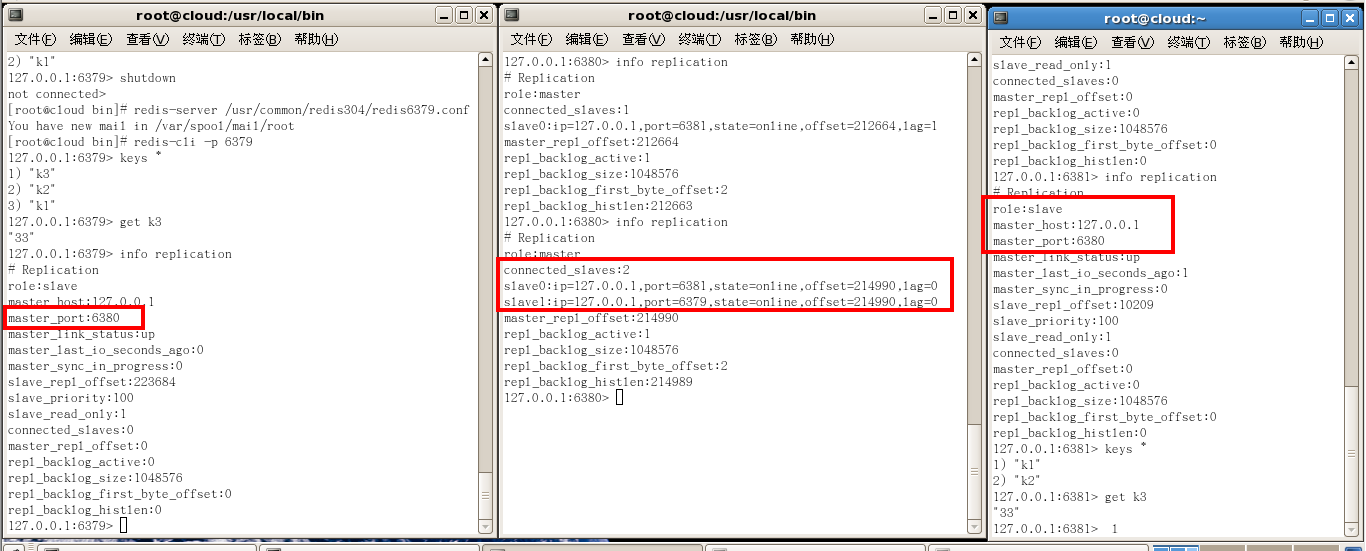

一組sentinel能同時監控多個Master
複製的缺點
複製延時
- 由於所有的寫操作都是先在Master上操作,然後同步更新到Slave上,所以從Master同步到Slave機器有一定的延遲,當系統很繁忙的時候,延遲問題會更加嚴重,Slave機器數量的增加也會使這個問題更加嚴重
Redis的Java客戶端Jedis
Jedis官網
基礎用法
高級用法
Jedis常用API
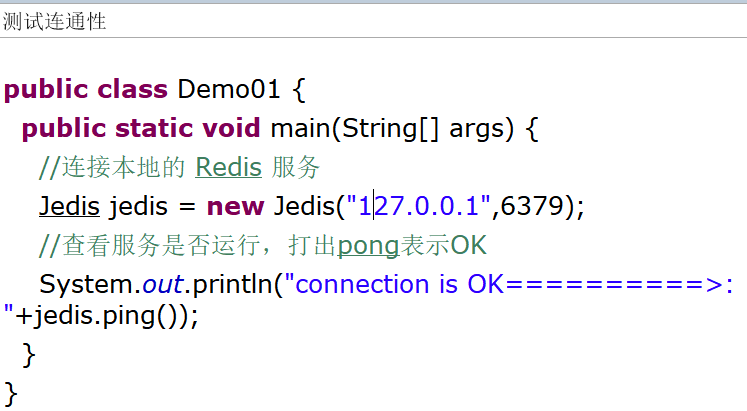
測試連通性
5+1
一個key
五大數據類型

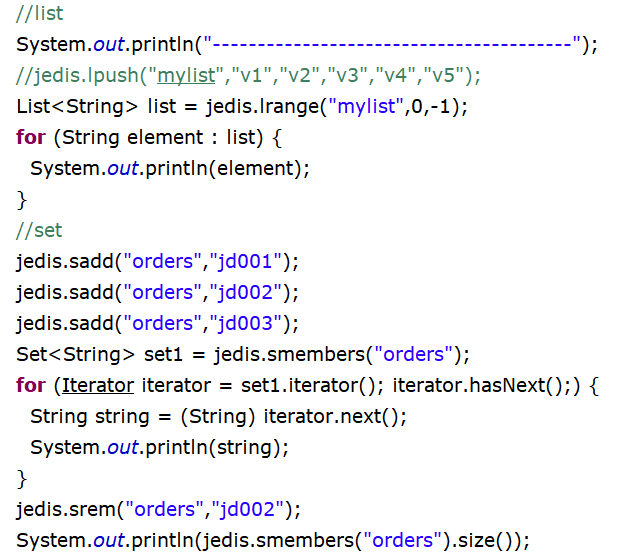

事務提交
日常

加鎖
-
通俗點講,watch命令就是標記一個鍵,如果標記了一個鍵, 在提交事務前如果該鍵被別人修改過,那事務就會失敗,這種情況通常可以在程式中重新再嘗試一次
- 首先標記了鍵balance,然後檢查餘額是否足夠,不足就取消標記,並不做扣減; 足夠的話,就啟動事務進行更新操作
- 如果在此期間鍵balance被其它人修改, 那在提交事務(執行exec)時就會報錯, 程式中通常可以捕獲這類錯誤再重新執行一次,直到成功
-


主從複製
-
6379,6380啟動,先各自先獨立
-
主寫
-
從讀
-


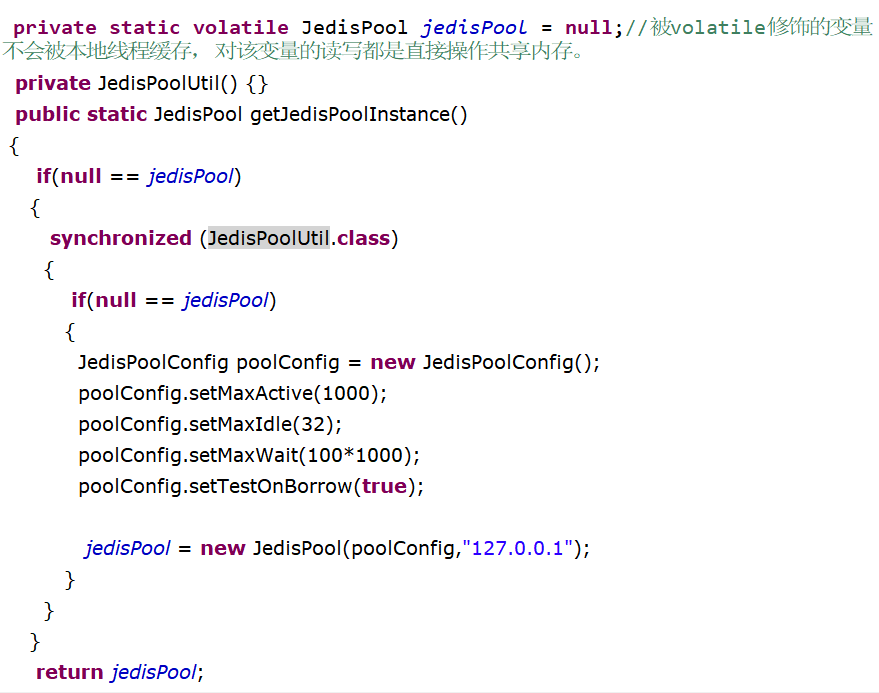
JedisPool
獲取Jedis實例需要從JedisPool中獲取
用完Jedis實例需要返還給JedisPool
如果Jedis在使用過程中出錯,則也需要還給JedisPool
案例
JedisPoolUtil
JedisPool.getResource()

配置總結all
JedisPool的配置參數大部分是由JedisPoolConfig的對應項來賦值的。
-
maxActive:控制一個pool可分配多少個jedis實例,通過pool.getResource()來獲取;如果賦值為-1,則表示不限制;如果pool已經分配了maxActive個jedis實例,則此時pool的狀態為exhausted
-
maxIdle:控制一個pool最多有多少個狀態為idle(空閑)的jedis實例
-
whenExhaustedAction:表示當pool中的jedis實例都被allocated完時,pool要採取的操作;
默認有三種:
- WHEN_EXHAUSTED_FAIL:表示無jedis實例時,直接拋出NoSuchElementException
- WHEN_EXHAUSTED_BLOC:則表示阻塞住,或者達到maxWait時拋出JedisConnectionException;
- WHEN_EXHAUSTED_GROW:則表示新建一個jedis實例,也就說設置的maxActive無用;
-
maxWait:表示當borrow一個jedis實例時,最大的等待時間,如果超過等待時間,則直接拋JedisConnectionException;
-
testOnBorrow:獲得一個jedis實例的時候是否檢查連接可用性(ping());如果為true,則得到的jedis實例均是可用的;
-
testOnReturn:return 一個jedis實例給pool時,是否檢查連接可用性(ping())
-
testWhileIdle:如果為true,表示有一個idle object evitor執行緒對idle object進行掃描,如果validate失敗,此object會被從pool中drop掉;這一項只有在timeBetweenEvictionRunsMillis大於0時才有意義;
-
timeBetweenEvictionRunsMillis:表示idle object evitor兩次掃描之間要sleep的毫秒數;
-
numTestsPerEvictionRun:表示idle object evitor每次掃描的最多的對象數;
-
minEvictableIdleTimeMillis:表示一個對象至少停留在idle狀態的最短時間,然後才能被idle object evitor掃描並驅逐;這一項只有在timeBetweenEvictionRunsMillis大於0時才有意義;
-
softMinEvictableIdleTimeMillis:在minEvictableIdleTimeMillis基礎上,加入了至少minIdle個對象已經在pool裡面了。如果為-1,evicted不會根據idle time驅逐任何對象。如果minEvictableIdleTimeMillis>0,則此項設置無意義,且只有在timeBetweenEvictionRunsMillis大於0時才有意義;
-
lifo:borrowObject返回對象時,是採用DEFAULT_LIFO(last in first out,即類似cache的最頻繁使用隊列),如果為False,則表示FIFO隊列;
-
其中JedisPoolConfig對一些參數的默認設置如下:
testWhileIdle=true
minEvictableIdleTimeMills=60000
timeBetweenEvictionRunsMillis=30000
numTestsPerEvictionRun=-1
Redis集群(簡略)
是什麼
- Redis集群實現了對Redis的水平擴容,即啟動N個redis節點,將整個資料庫分布存儲在這N個節點中,每個節點存儲總數據的1/N
- Redis集群通過分區(partition)來提供一定程度的可用性(availability):即使集群中有一部分節點失效或者無法進行通訊,集群也可以繼續處理命令請求
集群配置
redis cluster配置修改
- cluster-enabled yes 打開集群模式
- cluster-config-file node-6379.conf 設定節點配置文件名
- cluster-node-timeout 15000 設定節點失聯時間,超過該時間(毫秒),集群自動進行主從切換
整合redis實例
- cd /opt/redis-6.0.6/src
- ./redis-trib.rb create –replicas 1 xxx:6379 xxx:6380 xxx:6381
集群分配規則
- 一個集群至少要有三個節點
- 選項 –replicas 1 表示我們希望為集群中的每個主節點創建一個從節點
- 分配原則盡量保證每個主資料庫運行在不同的IP地址,每個從庫和主庫不再一個IP地址上
什麼是slots
-
一個Redis集群包含16384個插槽(hash slot),資料庫中每個鍵都屬於這16384個插槽的其中一個,集群使用公式CRC16(key) % 16384 來計算鍵key屬於哪個槽,其中CRC16(key)用於計算鍵key的CRC16校驗和
-
集群中的每個節點負責處理一部分插槽,舉個例子,如果一個集群可以有主節點,其中:
- 節點A負責處理0至5500號插槽
- 節點B負責處理5501號至11000號插槽
- 節點C負責處理11001號至16383號插槽
集群常用指令
- 集群模式下啟動客戶端: redis-cli -c -p 6379
- 查看集群資訊 :cluster nodes
- 計算鍵key應該被放置在哪個槽上: CLUSTER KEYSLOT
- 返回槽slot目前包含的鍵值對數量:CLUSTER COUNTKEYSINSLOT
- 返回count個slot槽中的鍵:CLUSTER GETKEYSINSLOT


