LSTM和GRU的解析從未如此通俗易懂
- 2019 年 10 月 28 日
- 筆記
▌短時記憶 RNN 會受到短時記憶的影響。如果一條序列足夠長,那它們將很難將資訊從較早的時間步傳送到後面的時間步。 因此,如果你正在嘗試處理一段文本進行預測,RNN 可能從一開始就會遺漏重要資訊。 在反向傳播期間,RNN 會面臨梯度消失的問題。 梯度是用於更新神經網路的權重值,消失的梯度問題是當梯度隨著時間的推移傳播時梯度下降,如果梯度值變得非常小,就不會繼續學習。

梯度更新規則 因此,在遞歸神經網路中,獲得小梯度更新的層會停止學習—— 那些通常是較早的層。 由於這些層不學習,RNN 可以忘記它在較長序列中看到的內容,因此具有短時記憶。
▌作為解決方案的 LSTM 和 GRU LSTM 和 GRU 是解決短時記憶問題的解決方案,它們具有稱為「門」的內部機制,可以調節資訊流。

這些「門」可以知道序列中哪些重要的數據是需要保留,而哪些是要刪除的。 隨後,它可以沿著長鏈序列傳遞相關資訊以進行預測,幾乎所有基於遞歸神經網路的技術成果都是通過這兩個網路實現的。
AI項目體驗地址 https://loveai.tech
LSTM 和 GRU 可以在語音識別、語音合成和文本生成中找到,你甚至可以用它們為影片生成字幕。對 LSTM 和 GRU 擅長處理長序列的原因,到這篇文章結束時你應該會有充分了解。 下面我將通過直觀解釋和插圖進行闡述,並避免儘可能多的數學運算。 本質 讓我們從一個有趣的小實驗開始吧。當你想在網上購買生活用品時,一般都會查看一下此前已購買該商品用戶的評價。 當你瀏覽評論時,你的大腦下意識地只會記住重要的關鍵詞,比如「amazing」和「awsome」這樣的辭彙,而不太會關心「this」、「give」、「all」、「should」等字樣。如果朋友第二天問你用戶評價都說了什麼,那你可能不會一字不漏地記住它,而是會說出但大腦里記得的主要觀點,比如「下次肯定還會來買」,那其他一些無關緊要的內容自然會從記憶中逐漸消失。
而這基本上就像是 LSTM 或 GRU 所做的那樣,它們可以學習只保留相關資訊來進行預測,並忘記不相關的數據。 ▌RNN 述評 為了了解 LSTM 或 GRU 如何實現這一點,讓我們回顧一下遞歸神經網路。 RNN 的工作原理如下;第一個詞被轉換成了機器可讀的向量,然後 RNN 逐個處理向量序列。

逐一處理矢量序列 處理時,RNN 將先前隱藏狀態傳遞給序列的下一步。 而隱藏狀態充當了神經網路記憶,它包含相關網路之前所見過的數據的資訊。

將隱藏狀態傳遞給下一個時間步 讓我們看看 RNN 的一個細胞,了解一下它如何計算隱藏狀態。 首先,將輸入和先前隱藏狀態組合成向量, 該向量包含當前輸入和先前輸入的資訊。 向量經過激活函數 tanh之後,輸出的是新的隱藏狀態或網路記憶。

RNN 細胞
激活函數 Tanh 激活函數 Tanh 用於幫助調節流經網路的值。 tanh 函數將數值始終限制在 -1 和 1 之間。

當向量流經神經網路時,由於有各種數學運算的緣故,它經歷了許多變換。 因此想像讓一個值繼續乘以 3,你可以想到一些值是如何變成天文數字的,這讓其他值看起來微不足道。

沒有 tanh 函數的向量轉換 tanh 函數確保值保持在 -1~1 之間,從而調節了神經網路的輸出。 你可以看到上面的相同值是如何保持在 tanh 函數所允許的邊界之間的。

有 tanh 函數的向量轉換 這是一個 RNN。 它內部的操作很少,但在適當的情形下(如短序列)運作的很好。 RNN 使用的計算資源比它的演化變體 LSTM 和 GRU 要少得多。 ▌LSTM LSTM 的控制流程與 RNN 相似,它們都是在前向傳播的過程中處理流經細胞的數據,不同之處在於 LSTM 中細胞的結構和運算有所變化。

LSTM 的細胞結構和運算 這一系列運算操作使得 LSTM具有能選擇保存資訊或遺忘資訊的功能。咋一看這些運算操作時可能有點複雜,但沒關係下面將帶你一步步了解這些運算操作。
核心概念 LSTM 的核心概念在於細胞狀態以及「門」結構。細胞狀態相當於資訊傳輸的路徑,讓資訊能在序列連中傳遞下去。你可以將其看作網路的「記憶」。理論上講,細胞狀態能夠將序列處理過程中的相關資訊一直傳遞下去。 因此,即使是較早時間步長的資訊也能攜帶到較後時間步長的細胞中來,這克服了短時記憶的影響。資訊的添加和移除我們通過「門」結構來實現,「門」結構在訓練過程中會去學習該保存或遺忘哪些資訊。
Sigmoid 門結構中包含著 sigmoid 激活函數。Sigmoid 激活函數與 tanh 函數類似,不同之處在於 sigmoid 是把值壓縮到 0~1 之間而不是 -1~1 之間。這樣的設置有助於更新或忘記資訊,因為任何數乘以 0 都得 0,這部分資訊就會剔除掉。同樣的,任何數乘以 1 都得到它本身,這部分資訊就會完美地保存下來。這樣網路就能了解哪些數據是需要遺忘,哪些數據是需要保存。

Sigmoid 將值壓縮到 0~1 之間 接下來了解一下門結構的功能。LSTM 有三種類型的門結構:遺忘門、輸入門和輸出門。 遺忘門 遺忘門的功能是決定應丟棄或保留哪些資訊。來自前一個隱藏狀態的資訊和當前輸入的資訊同時傳遞到 sigmoid 函數中去,輸出值介於 0 和 1 之間,越接近 0 意味著越應該丟棄,越接近 1 意味著越應該保留。

遺忘門的運算過程 輸入門 輸入門用於更新細胞狀態。首先將前一層隱藏狀態的資訊和當前輸入的資訊傳遞到 sigmoid 函數中去。將值調整到 0~1 之間來決定要更新哪些資訊。0 表示不重要,1 表示重要。 其次還要將前一層隱藏狀態的資訊和當前輸入的資訊傳遞到 tanh 函數中去,創造一個新的侯選值向量。最後將 sigmoid 的輸出值與 tanh 的輸出值相乘,sigmoid 的輸出值將決定 tanh 的輸出值中哪些資訊是重要且需要保留下來的。

輸入門的運算過程 細胞狀態 下一步,就是計算細胞狀態。首先前一層的細胞狀態與遺忘向量逐點相乘。如果它乘以接近 0 的值,意味著在新的細胞狀態中,這些資訊是需要丟棄掉的。然後再將該值與輸入門的輸出值逐點相加,將神經網路發現的新資訊更新到細胞狀態中去。至此,就得到了更新後的細胞狀態。

細胞狀態的計算 輸出門 輸出門用來確定下一個隱藏狀態的值,隱藏狀態包含了先前輸入的資訊。首先,我們將前一個隱藏狀態和當前輸入傳遞到 sigmoid 函數中,然後將新得到的細胞狀態傳遞給 tanh 函數。 最後將 tanh 的輸出與 sigmoid 的輸出相乘,以確定隱藏狀態應攜帶的資訊。再將隱藏狀態作為當前細胞的輸出,把新的細胞狀態和新的隱藏狀態傳遞到下一個時間步長中去。

輸出門的運算過程 讓我們再梳理一下。遺忘門確定前一個步長中哪些相關的資訊需要被保留;輸入門確定當前輸入中哪些資訊是重要的,需要被添加的;輸出門確定下一個隱藏狀態應該是什麼。
程式碼示例 對於那些懶得看文字的人來說,程式碼也許更好理解,下面給出一個用 python 寫的示例。

python 寫的偽程式碼 1.首先,我們將先前的隱藏狀態和當前的輸入連接起來,這裡將它稱為 combine; 2.其次將 combine 丟到遺忘層中,用於刪除不相關的數據; 3.再用 combine 創建一個候選層,候選層中包含著可能要添加到細胞狀態中的值; 4.combine 同樣要丟到輸入層中,該層決定了候選層中哪些數據需要添加到新的細胞狀態中; 5.接下來細胞狀態再根據遺忘層、候選層、輸入層以及先前細胞狀態的向量來計算; 6.再計算當前細胞的輸出; 7.最後將輸出與新的細胞狀態逐點相乘以得到新的隱藏狀態。 是的,LSTM 網路的控制流程就是幾個張量和一個 for 循環。你還可以使用隱藏狀態進行預測。結合這些機制,LSTM 能夠在序列處理中確定哪些資訊需要記憶,哪些資訊需要遺忘。 ▌GRU 知道了 LSTM 的工作原理之後,來了解一下 GRU。GRU 是新一代的循環神經網路,與 LSTM 非常相似。與 LSTM 相比,GRU 去除掉了細胞狀態,使用隱藏狀態來進行資訊的傳遞。它只包含兩個門:更新門和重置門。
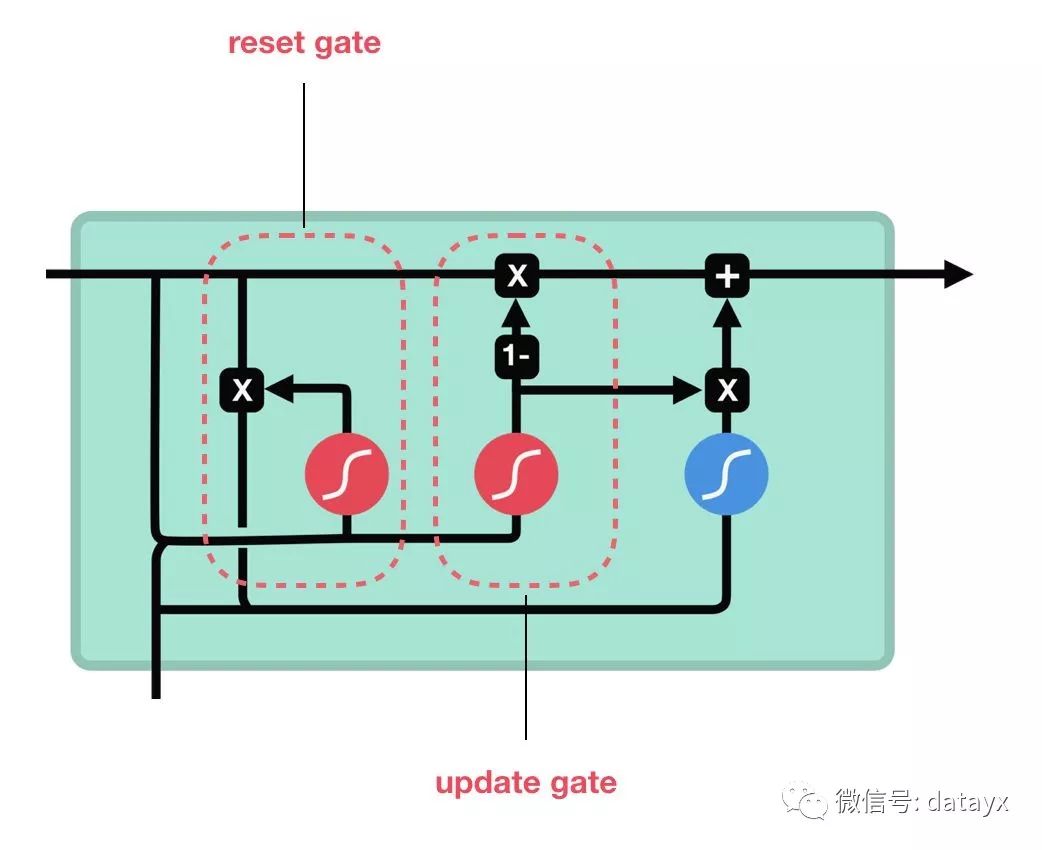
GRU 的細胞結構和門結構
更新門 更新門的作用類似於 LSTM 中的遺忘門和輸入門。它決定了要忘記哪些資訊以及哪些新資訊需要被添加。 重置門 重置門用於決定遺忘先前資訊的程度。 這就是 GRU。GRU 的張量運算較少,因此它比 LSTM 的訓練更快一下。很難去判定這兩者到底誰更好,研究人員通常會兩者都試一下,然後選擇最合適的。 總而言之,RNN 適用於處理序列數據用於預測,但卻受到短時記憶的制約。LSTM 和 GRU 採用門結構來克服短時記憶的影響。門結構可以調節流經序列鏈的資訊流。LSTM 和 GRU 被廣泛地應用到語音識別、語音合成和自然語言處理等。


