Elasticsearch Lucene 數據寫入原理 | ES 核心篇
- 2019 年 10 月 3 日
- 筆記
前言
最近 TL 分享了下 《Elasticsearch基礎整理》https://www.jianshu.com/p/e8226138485d ,蹭著這個機會。寫個小文鞏固下,本文主要講 ES -> Lucene
的底層結構,然後詳細描述新數據寫入 ES 和 Lucene 的流程和原理。這是基礎理論知識,整理了一下,希望能對 Elasticsearch 感興趣的同學有所幫助。
一、Elasticsearch & Lucene 是什麼


什麼是 Elasticsearch ?
Elasticsearch 是一個基於 Apache Lucene(TM) 的開源搜索引擎。
那 Lucene 是什麼?
無論在開源還是專有領域,Lucene 可以被認為是迄今為止最先進、性能最好的、功能最全的搜索引擎庫,並通過簡單的 RESTful API 來隱藏 Lucene 的複雜性,從而讓全文搜索變得簡單。
Elasticsearch 不僅僅是 Lucene 和全文搜索,我們還能這樣去描述它:
- 分散式的實時文件存儲,每個欄位都被索引並可被搜索
- 分散式的實時分析搜索引擎
- 可以擴展到上百台伺服器,處理 PB 級結構化或非結構化數據
二、Elasticsearch & Lucene 的關係


就像很多業務系統是基於 Spring 實現一樣,Elasticsearch 和 Lucene 的關係很簡單:Elasticsearch 是基於 Lucene 實現的。ES 基於底層這些包,然後進行了擴展,提供了更多的更豐富的查詢語句,並且通過 RESTful API 可以更方便地與底層交互。類似 ES 還有 Solr 也是基於 Lucene 實現的。
在應用開發中,用 Elasticsearch 會很簡單。但是如果你直接用 Lucene,會有大量的集成工作。
因此,入門 ES 的同學,稍微了解下 Lucene 即可。如果往高級走,還是需要學習 Lucene 底層的原理。因為倒排索引、打分機制、全文檢索原理、分詞原理等等,這些都是不會過時的技術。
三、新文檔寫入流程
3.1 數據模型
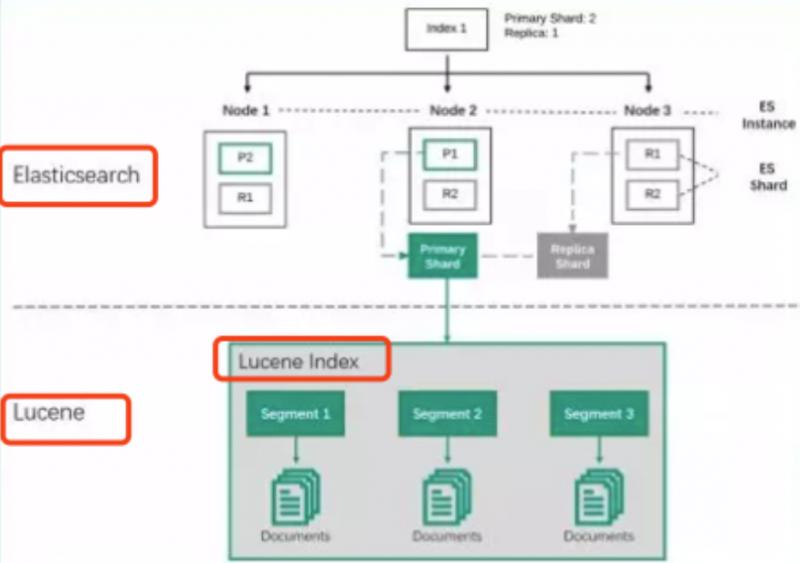

如圖
- 一個 ES Index (索引,比如商品搜索索引、訂單搜索索引)集群下,有多個 Node (節點)組成。每個節點就是 ES 的實例。
- 每個節點上會有多個 shard (分片), P1 P2 是主分片 R1 R2 是副本分片
- 每個分片上對應著就是一個 Lucene Index(底層索引文件)
- Lucene Index 是一個統稱。由多個 Segment (段文件,就是倒排索引)組成。每個段文件存儲著就是 Doc 文檔。
3.2 Lucene Index
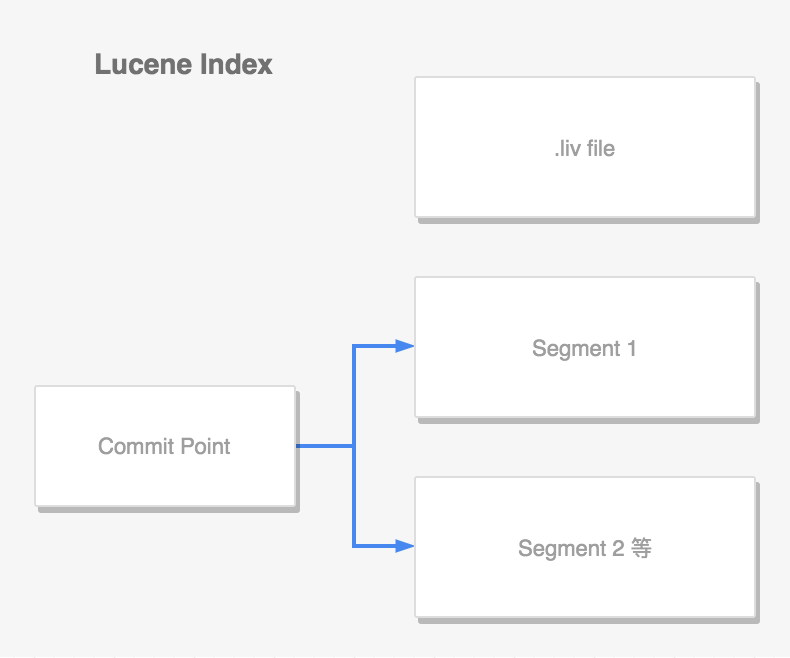

lucene 中,單個倒排索引文件稱為 segment。其中有一個文件,記錄了所有 segments 的資訊,稱為 commit point:
- 文檔 create 新寫入時,會生成新的 segment。同樣會記錄到 commit point 裡面
- 文檔查詢,會查詢所有的 segments
- 當一個段存在文檔被刪除,會維護該資訊在 .liv 文件裡面
3.3 新文檔寫入流程
新文檔創建或者更新時,進行如下流程:
更新不會修改原來的 segment,更新和創建操作都會生成新的一個 segment。數據哪裡來呢?先會存在記憶體的 bugger 中,然後持久化到 segment 。
數據持久化步驟如下:write -> refresh -> flush -> merge
3.3.1 write 過程
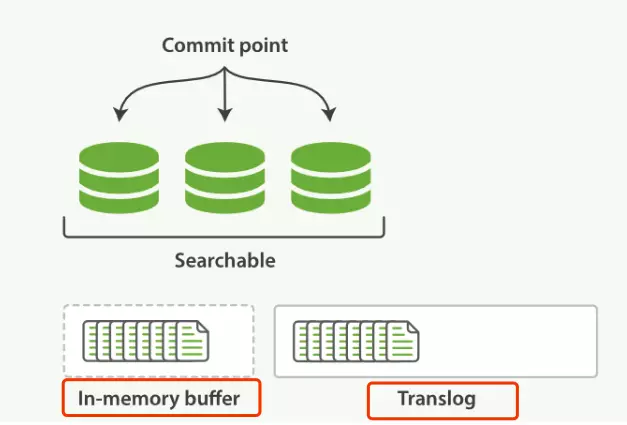

一個新文檔過來,會存儲在 in-memory buffer 記憶體快取區中,順便會記錄 Translog。
這時候數據還沒到 segment ,是搜不到這個新文檔的。數據只有被 refresh 後,才可以被搜索到。那麼 講下 refresh 過程
3.3.2 refresh 過程


refresh 默認 1 秒鐘,執行一次上圖流程。ES 是支援修改這個值的,通過 index.refresh_interval 設置 refresh (沖刷)間隔時間。refresh 流程大致如下:
- in-memory buffer 中的文檔寫入到新的 segment 中,但 segment 是存儲在文件系統的快取中。此時文檔可以被搜索到
- 最後清空 in-memory buffer。注意: Translog 沒有被清空,為了將 segment 數據寫到磁碟
文檔經過 refresh 後, segment 暫時寫到文件系統快取,這樣避免了性能 IO 操作,又可以使文檔搜索到。refresh 默認 1 秒執行一次,性能損耗太大。一般建議稍微延長這個 refresh 時間間隔,比如 5 s。因此,ES 其實就是准實時,達不到真正的實時。
3.3.3 flush 過程
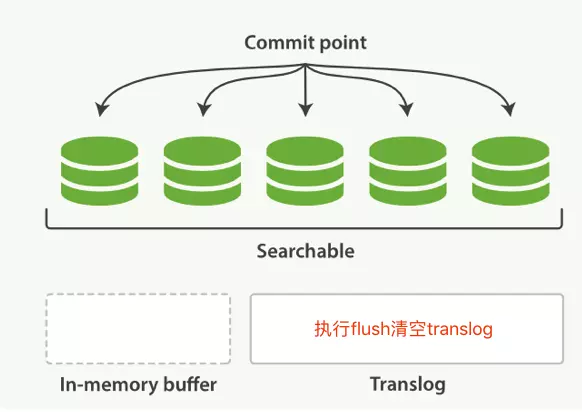

上個過程中 segment 在文件系統快取中,會有意外故障文檔丟失。那麼,為了保證文檔不會丟失,需要將文檔寫入磁碟。那麼文檔從文件快取寫入磁碟的過程就是 flush。寫入次怕後,清空 translog。
translog 作用很大:
- 保證文件快取中的文檔不丟失
- 系統重啟時,從 translog 中恢復
- 新的 segment 收錄到 commit point 中
具體可以看官方文檔:https://www.elastic.co/guide/en/elasticsearch/reference/7.3/indices-flush.html
3.3.4 merge 過程


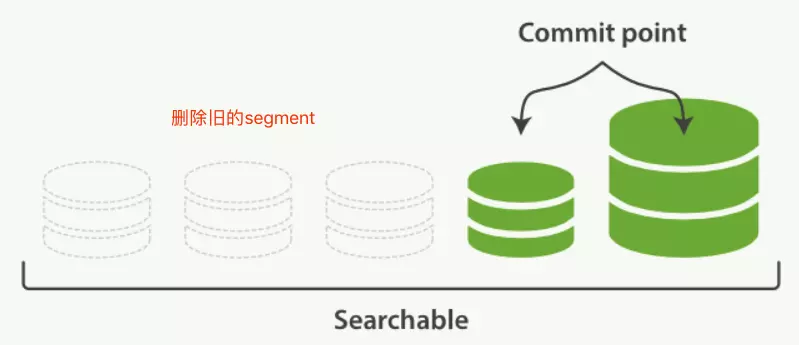

上面幾個步驟,可見 segment 會越來越多,那麼搜索會越來越慢?怎麼處理呢?
通過 merge 過程解決:
- 就是各個小段文件,合併成一個大段文件。段合併過程
- 段合併結束,舊的小段文件會被刪除
- .liv 文件維護的刪除文檔,會通過這個過程進行清除
四、小結
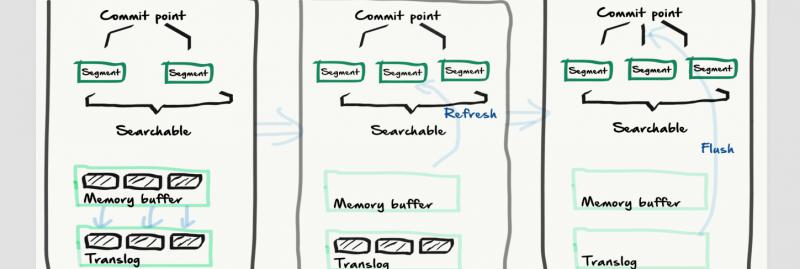

如這個圖,ES 寫入原理不難,記住關鍵點即可。
write -> refresh -> flush
- write:文檔數據到記憶體快取,並存到 translog
- refresh:記憶體快取中的文檔數據,到文件快取中的 segment 。此時可以被搜到
- flush 是快取中的 segment 文檔數據寫入到磁碟
寫入的原理告訴我們,考慮的點很多:性能、數據不丟失等等
(完)
參考資料:
Java微服務資料,加我微w信x:bysocket01 (加的人,一般很帥)

