經典排序演算法–快速排序
- 2019 年 10 月 28 日
- 筆記
快速排序原理
快速排序是基於“分治法”原理實現,所謂分治法就是不斷的將原數組序列按照一定規律進行拆分,拆分後各自實現排序直到拆分到序列只剩下一個關鍵字為止。快速排序首先選取一個關鍵字為標誌位(關鍵字的選取影響排序效率),然後將序列中小於標誌位的關鍵字移動至標誌位左側,大於標誌位的關鍵字移動至右側。一趟比較完成後,整個序列以選取的標誌位為界,左側均小於標誌位,右側均大於關鍵字。但左右兩側內部並不是有序的(左右兩側關鍵字個數也不一定相同)。進而繼續將左右兩側分別再以這種方式進行排序,直到將序列拆分的剩餘一個關鍵字為止,整個序列即變成有序。
圖解快速排序
下面以[6 ,1 ,2 ,7, 9 ,3 ,4 ,5 ,10 ,8]序列為例用圖解的方式講解快速排序的過程

這裡我們選取標誌位的方式是:序列左邊第一個關鍵字即 6 並放入標誌位變數flag中 ,然後將L(left)指針指向最左邊,將R(right)指針指向最右邊。
然後從右邊指針開始讓R指針指向的關鍵字與標誌位flag比較,如果關鍵字大於或等於flag,則繼續向左移動(右側關鍵字本身就要大於flag),直到找到小於flag的關鍵字,即關鍵字5。R指針停止移動。並開始讓L指針指向的關鍵字與flag比較,如果小於flag則L指針繼續向後移動,直到找到大於flag的關鍵字,即關鍵字7。此時序列如下圖所示 
此時再比較指針L是否小於R,滿足條件,交換兩指針對應的值,即7與5交換。交換後仍滿足L<R指針,繼續從R指針與flag比較,找小於6的關鍵字,即指向關鍵字4,R指針停止移動。並開始讓L指針指向的關鍵字與flag比較,找大於6的關鍵字,即指向關鍵字9。此時序列如下圖所示
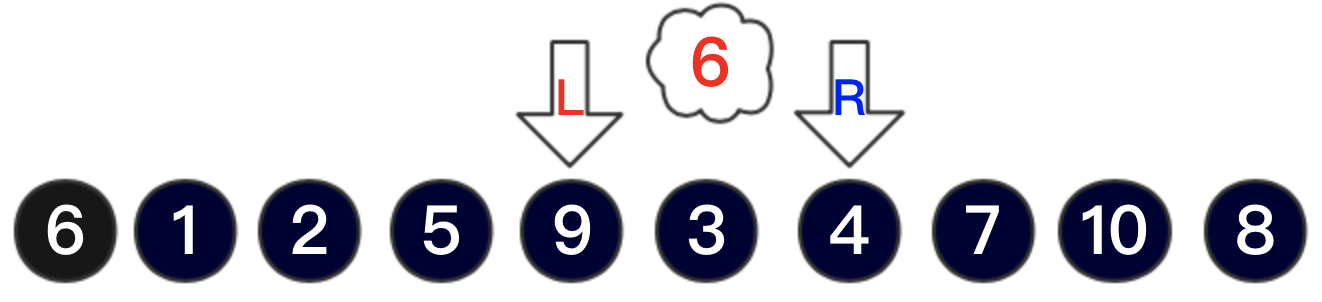
此時仍滿足L<R的條件,所以將9與4交換。繼續按照上述步驟進行,R向前移動並找到小於flag的關鍵字3,R指針停止移動。並開始L指針向後移動,當L指針指向3時,雖然滿足3<6,但此時不再滿足L<R(此時L=R)。然後將L和R同時指向的關鍵字3移動至序列左邊第一個關鍵字中,並將flag放入L和R指向的位置,這一趟比較結束。此時序列如下圖所示

從圖中可以看到,一趟比較後,整個序列以我們選取的標誌位為界,將整個序列分為兩個部分,其中左邊部分關鍵字都小於標誌位,而右側部分均大於標誌位。但左右兩側內部無序。
然後再將左右兩側子序列分別執行上述步驟,直至左右兩側剩餘一個元素無法再拆分時,整個序列即為有序。
程式碼實現
1 public static void quickSort(int[] array ,int left,int right){ 2 int l,r,flag,temp; 3 if(left >= right){ 4 return; 5 } 6 l = left; 7 r = right; 8 flag = array[left]; 9 while (l < r){ 10 //先從右邊找 11 while (array[r] >= flag && l < r){ 12 r --; 13 } 14 //再從左邊找 15 while (array[l] <= flag && l < r){ 16 l ++; 17 } 18 //交換 19 if(l < r){ 20 temp = array[l]; 21 array[l] = array[r]; 22 array[r] = temp; 23 } 24 } 25 //一趟交換完將基準值放入臨界位置 26 array[left] = array[l]; 27 array[l] = flag; 28 //向左遞歸 29 quickSort(array,left,l-1); 30 quickSort(array,l+1,right); 31 }
程式碼分析
1)選取數組左邊第一個關鍵字為標誌位,並暫存至flag中(註:標誌位選取的方式可用不同方式)
2)第一層while循環用於保證一趟比較遍歷完所有關鍵字
3)第二層第一個while循環用於從右側依次向左找小於flag的關鍵字
4)第二層第二個while循環用於從左側依次向右找大於flag的關鍵字
5)第二層的兩個while循環執行後,如果l<r則進行交換
6)一趟比較後,將l和r共同指向的關鍵字放入最左側,即flag的選取位置,並將flag值放入此位置,此時序列便以flag為界,左邊均小於flag,右邊均大於flag
7)然後再用“分治法”分別向左和向右遞歸執行上述步驟,直到無法拆分為止,整個序列即為有序
時間複雜度
快速排序時間複雜度為O(NlogN)
測試演算法執行效率
與前面的排序演算法相同,我們依然生成10萬個隨機數的數組,使用插入排序方法進行排序,看其執行時間。測試程式碼如下
public static void main(String[] args){ int array[] = new int[100000]; for (int i = 0; i < 100000; i++) { array[i] = (int) (Math.random()*1000000); } long begin = System.currentTimeMillis(); quickSort(array,0,array.length-1); System.out.println("總耗時="+(System.currentTimeMillis()-begin)+"毫秒"); }
測試結果

可以看到快速排序對10萬個關鍵字的數組進行排序,只用了50多毫秒,相比我們前面講解的希爾排序又快了許多。
總結
快速排序每趟比較首先選取某個關鍵字作為標誌位,然後使用左右指針遍曆數組關鍵字與flag進行比較,並將右側小於flag的關鍵字與左側大於flag的關鍵字進行交換。然後再使用“分治法”方式對數組拆分,將數組以flag為界拆分為左右兩個子序列,並對兩個子序列遞歸執行上述步驟,直到子序列剩餘1個關鍵字無法拆分為止,此時整個序列即為有序。


