基於Prometheus和Grafana的監控平台 – 運維告警
- 2019 年 10 月 27 日
- 筆記
通過前面幾篇文章我們搭建好了監控環境並且監控了伺服器、資料庫、應用,運維人員可以實時了解當前被監控對象的運行情況,但是他們不可能時時坐在電腦邊上盯著DashBoard,這就需要一個告警功能,當伺服器或應用指標異常時發送告警,通過郵件或者簡訊的形式告訴運維人員及時處理。
今天我們就來聊聊 基於Prometheus和Grafana的監控平台的異常告警功能。
告警方式
Grafana
新版本的Grafana已經提供了告警配置,直接在dashboard監控panel中設置告警即可,但是我用過後發現其實並不靈活,不支援變數,而且好多下載的圖表無法使用告警,所以我們不選擇使用Grafana告警,而使用Alertmanager。

Alertmanager
相比於Grafana的圖形化介面,Alertmanager需要依靠配置文件實現,配置稍顯繁瑣,但是勝在功能強大靈活。接下來我們就一步一步實現告警通知。
告警類型
Alertmanager告警主要使用以下兩種:
- 郵件接收器 email_config
- Webhook接收器 webhook_config,會用post形式向配置的url地址發送如下格式的參數。
{ "version": "2", "status": "<resolved|firing>", "alerts": [{ "labels": < object > , "annotations": < object > , "startsAt": "<rfc3339>", "endsAt": "<rfc3339>" }] }這次主要使用郵件的方式進行告警。
#### 實現步驟
-
下載
從GitHub上下載最新版本的Alertmanager,將其上傳解壓到伺服器上。
tar -zxvf alertmanager-0.19.0.linux-amd64.tar.gz - 配置Alertmanager
vi alertmanager.yml global: resolve_timeout: 5m smtp_smarthost: 'mail.163.com:25' #郵箱發送埠 smtp_from: '[email protected]' smtp_auth_username: '[email protected]' #郵箱帳號 smtp_auth_password: 'xxxxxx' #郵箱密碼 smtp_require_tls: false route: group_by: ['alertname'] group_wait: 10s # 最初即第一次等待多久時間發送一組警報的通知 group_interval: 10s # 在發送新警報前的等待時間 repeat_interval: 1h # 發送重複警報的周期 對於email配置中,此項不可以設置過低,否則將會由於郵件發送太多頻繁,被smtp伺服器拒絕 receiver: 'email' receivers: - name: 'email' email_configs: - to: '[email protected]'修改完成後可以使用./amtool check-config alertmanager.yml校驗文件是否正確。
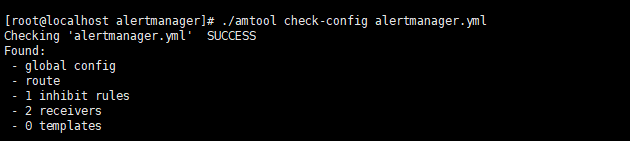
校驗正確啟動alertmanager。`nohup ./alertmanager &`。(第一次啟動可以不使用nohup靜默啟動,方便後面查看日誌) 我們只定義了一個路由,那就意味著所有由Prometheus產生的告警在發送到Alertmanager之後都會通過名為`email`的receiver接收。實際上,對於不同級別的告警,會有不同的處理方式,因此在route中,我們還可以定義更多的子Route。具體配置規則大家可以去百度進一步了解。-
配置Prometheus
在Prometheus安裝目錄下建立rules文件夾,放置所有的告警規則文件。alerting: alertmanagers: - static_configs: - targets: ['192.168.249.131:9093'] rule_files: - rules/*.yml
在rules文件夾下建立告警規則文件service_down.yml,當伺服器下線時發送郵件。
groups: - name: ServiceStatus rules: - alert: ServiceStatusAlert expr: up == 0 for: 2m labels: team: node annotations: summary: "Instance {{ $labels.instance }} has bean down" description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 2 minutes." value: "{{ $value }}"
**配置詳解** alert:告警規則的名稱。
expr:基於PromQL表達式告警觸發條件,用於計算是否有時間序列滿足該條件。
for:評估等待時間,可選參數。用於表示只有當觸發條件持續一段時間後才發送告警。在等待期間新產生告警的狀態為PENDING,等待期後為FIRING。
labels:自定義標籤,允許用戶指定要附加到告警上的一組附加標籤。
annotations:用於指定一組附加資訊,比如用於描述告警詳細資訊的文字等,annotations的內容在告警產生時會一同作為參數發送到Alertmanager。
配置完成後重啟Prometheus,訪問Prometheus查看告警配置。
- 測試
關閉node_exporter,過2分鐘就可以收到告警郵件啦,截圖如下:
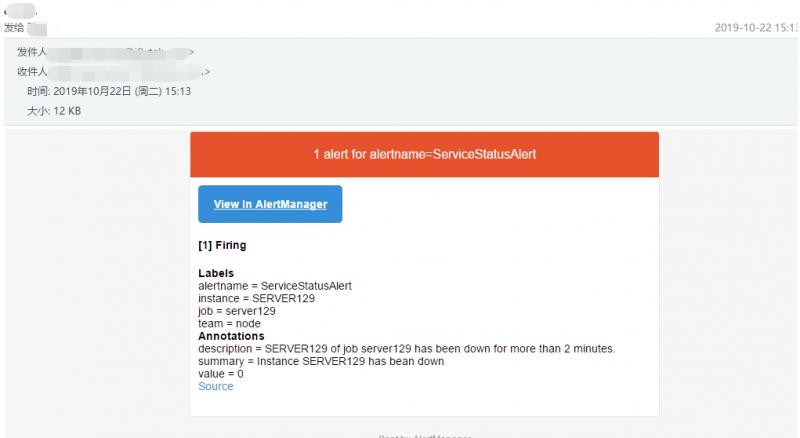
Alertmanager的告警內容支援使用模板配置,可以使用好看的模板進行渲染,感興趣的可以試試!The More
-
CPU使用率(單位為percent)
(avg by (instance) (irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100) -
記憶體已使用(單位為bytes)
node_memory_MemTotal_bytes - node_memory_MemFree_bytes - node_memory_Cached_bytes - node_memory_Buffers_bytes - node_memory_Slab_bytes -
記憶體使用量(單位為bytes/sec)
node_memory_MemTotal_bytes - node_memory_MemFree_bytes - node_memory_Cached_bytes - node_memory_Buffers_bytes - node_memory_Slab_bytes -
記憶體使用率(單位為percent)
((node_memory_MemTotal_bytes - node_memory_MemFree_bytes - node_memory_Cached_bytes - node_memory_Buffers_bytes - node_memory_Slab_bytes)/node_memory_MemTotal_bytes) * 100 -
server1的記憶體使用率(單位為percent)
((node_memory_MemTotal_bytes{instance="server1"} - node_memory_MemAvailable_bytes{instance="server1"})/node_memory_MemTotal_bytes{instance="server1"}) * 100 -
server2的磁碟使用率(單位為percent)
((node_filesystem_size_bytes{fstype=~"xfs|ext4",instance="server2"} - node_filesystem_free_bytes{fstype=~"xfs|ext4",instance="server2"}) / node_filesystem_size_bytes{fstype=~"xfs|ext4",instance="server2"}) * 100 -
uptime時間(單位為seconds)
time() - node_boot_time -
server1的uptime時間(單位為seconds)
time() - node_boot_time_seconds{instance="server1"} -
網路流出量(單位為bytes/sec)
irate(node_network_transmit_bytes_total{device!~"lo|bond[0-9]|cbr[0-9]|veth.*"}[5m]) > 0 -
server1的網路流出量(單位為bytes/sec)
irate(node_network_transmit_bytes_total{instance="server1", device!~"lo|bond[0-9]|cbr[0-9]|veth.*"}[5m]) > 0 -
網路流入量(單位為bytes/sec)
irate(node_network_receive_bytes_total{device!~"lo|bond[0-9]|cbr[0-9]|veth.*"}[5m]) > 0 -
server1的網路流入量(單位為bytes/sec)
irate(node_network_receive_bytes_total{instance="server1", device!~"lo|bond[0-9]|cbr[0-9]|veth.*"}[5m]) > 0 -
磁碟讀取速度(單位為bytes/sec)
irate(node_disk_read_bytes_total{device=~"sd.*"}[5m])
請關注個人公眾號:JAVA日知錄