Spark基礎學習精髓——第一篇
- 2020 年 8 月 17 日
- 筆記
Spark基礎學習精髓
1 Spark與大數據
1.1 大數據基礎
1.1.1 大數據特點
- 存儲空間大
- 數據量大
- 計算量大
1.1.2 大數據開發通用步驟及其對應的技術
大數據採集->大數據預處理->大數據存儲->大數據處理->大數據可視化
(1)大數據採集技術
分散式架構、多種採集技術混合使用
web數據採集:shell編程、爬蟲工具、爬蟲程式開發、HTTP協議、TCP/IP基本原理及Socket程式介面、程式語言、數據格式轉換、分散式存儲的命令和介面(HDFS、HBase等)、分散式應用開發
日誌數據採集:採集工具(Flume、Fluentd等)、接入工具(Kafka).日誌採集程式(Java、Python等)開發、Shell編程、TCP/IP基本原理以及網路編程介面、程式語言、數據格式轉換、分散式存儲系統的命令和介面(HDFS、HBase等)、分散式應用開發。
資料庫數據採集:Shell編程、採集工具(Flume、Fluentd等)、接入工具(Kafka)、資料庫採集程式(Java、Python等)開發、SQL查詢語言及編程介面、關係型數據、庫連接如JDBC等的使用、TCP/IP基本原理以及Socket編程介面、程式語言、數據格式轉換、分散式存儲系統的命令和介面(HDFS、HBase等)、分散式應用開發。
(2)大數據存儲技術
分散式海量文件存儲:HDFS CEPH Moosefs GlusterFS。
NoSQL資料庫:Hbase Cassandra。
NewSQL資料庫:VoltDB、Spanner、TiDB等。
(3)大數據處理技術
Hadoop框架、Spark框架
1.2 認識Spark
Spark是一個統一的大規模數據處理分析引擎。
技術特點:高性能(基於記憶體)、支援多種語言、通用(提供SQL操作、流數據處理、圖數據處理、機器學習演算法庫)、多平台運行、分散式開發更容易
1.3 Spark技術棧
1.4 Scala與Spark關係
Spark框架是用scala開發的。Scala語言特點有如下:
- 面向對象、函數式編程
- 是強類型語言,不支援類型的隱式轉換
- 靜態類型語言
- 在JVM虛擬機上運行,可以利用JAVA資源
- 支援互動式解釋器REPL
1.5 Spark快速學習路線
虛擬機基礎:訂製虛擬機、能安裝centos7
Linux基礎:實現host和guest網路連接、完成基本文件操作、會用vim
Scala編程:能編寫、編譯、打包、調試、運行Scala程式,會用Scala編寫簡單的串列處理程式,能看懂簡單的Spark Scala API介面
Spark基礎:能說出Spark程式運行時架構、能提交Spark程式分散式運行、能解釋Spark相關概念:RDD、Application、Job、DAG、Stage、Task,能說出Spark程式的運行過程和程式碼執行過程
Spark核心編程:能使用IDEA來編寫、編譯、打包、調試、運行Spark程式;能使用RDD、DataFrame/Dataset的基礎API編寫Spark程式
(具體學習資源請參見《Spark大數據編程實用教程》以及《艾叔》網易雲系列,能幫助初學者快速入門,少踩坑)
1.6 使用軟體和版本推薦
VMware workstation15、Centos7.2、jdk-8u162-linux-x64.tar.gz、hadoop-2.7.6.tar.gz、spark-2.3.0-bin-hadoop2.7.tgz、scala-2.11.12、ideaIC-2018.1.4.tar.gz
2 Spark運行環境的搭建
構建一個Spark運行環境,除Spark自身框架外,還要有集群管理器和存儲系統用來存儲輸入和輸出數據。
2.1 Spark程式運行時架構
定義:Spark程式運行後程式的各個組成部分。
三種角色:
- Client(客戶端):負責提交Spark程式,提交的對象可以是集群管理器、也可以沒有提交對象從而在本地運行;
- Driver(驅動程式):負責此次Spark程式運行的管理和狀態監控,從程式開始到程式結束都由Driver全程負責;
- Executor(執行器):負責執行具體任務,Executor可能有多個,所有executor合併共同完成整個任務。Executor中具體任務是Task,每個Task是一個執行緒(每個Task不一定只佔一個CPU,可以佔多個CPU),一個executor中可能有多個Task,一個Task的處理邏輯相同,處理數據不一樣;

Client向集群管理器發出申請,集群管理器接收請求,並為其分配合適的資源。具體選擇哪種管理器,可以在Client提交時通過參數指定。每種資源管理器運行Spark程式時機制可能不一樣,但不管怎樣,Spark程式運行時的架構是不變的。其他細節,如Excutor、Task的分配、資源調度、不同資源管理器上Spak執行機制等。
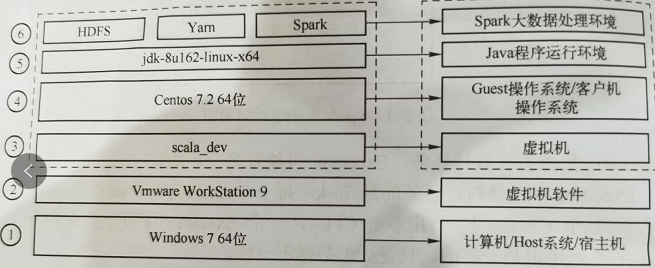
2.2 首先構建最簡Spark大數據運行環境
最簡單的Spark運行環境由HDFS、Yarn、Spark三個部分組成。
部署圖如下:
2.2.1 構建HDFS
1.什麼是hdfs
HDFS(Hadoop Distributed File System Hadoop分散式文件系統),是一個分散式文件系統。Spark處理數據時的數據源和處理結果都存儲在HDFS上。
2.重要特徵
(1)HDFS中的文件在物理上是分塊存儲(block),塊的大小可以通過配置參數( dfs.blocksize)來規定,默認大小在hadoop2.x版本中是128M,老版本中是64M
(2)HDFS文件系統會給客戶端提供一個統一的抽象目錄樹,客戶端通過路徑來訪問文件,形如:hdfs://namenode:port/dir-a/dir-b/dir-c/file.data
(3)目錄結構及文件分塊資訊(元數據)的管理由namenode節點承擔——namenode是HDFS集群主節點,負責維護整個hdfs文件系統的目錄樹,以及每一個路徑(文件)所對應的block塊資訊(block的id,及所在的datanode伺服器)
(4)文件的各個block的存儲管理由datanode節點承擔—- datanode是HDFS集群從節點,每一個block都可以在多個datanode上存儲多個副本(副本數量也可以通過參數設置dfs.replication)
(5)HDFS是設計成適應一次寫入,多次讀出的場景,且不支援文件的修改
3.hdfs命令行
(1)查看幫助 hdfs dfs -help (2)查看當前目錄資訊 hdfs dfs -ls / (3)上傳文件 hdfs dfs -put /本地路徑 /hdfs路徑 (4)剪切文件 hdfs dfs -moveFromLocal a.txt /aa.txt (5)下載文件到本地 hdfs dfs -get /hdfs路徑 /本地路徑 (6)合併下載 hdfs dfs -getmerge /hdfs路徑文件夾 /合併後的文件 (7)創建文件夾 hdfs dfs -mkdir /hello (8)創建多級文件夾 hdfs dfs -mkdir -p /hello/world (9)移動hdfs文件 hdfs dfs -mv /hdfs路徑 /hdfs路徑 (10)複製hdfs文件 hdfs dfs -cp /hdfs路徑 /hdfs路徑 (11)刪除hdfs文件 hdfs dfs -rm /aa.txt (12)刪除hdfs文件夾 hdfs dfs -rm -r /hello (13)查看hdfs中的文件 hdfs dfs -cat /文件 hdfs dfs -tail -f /文件 (14)查看文件夾中有多少個文件 hdfs dfs -count /文件夾 (15)查看hdfs的總空間 hdfs dfs -df / hdfs dfs -df -h / (16)修改副本數 hdfs dfs -setrep 1 /a.txt
4.hdfs工作機制
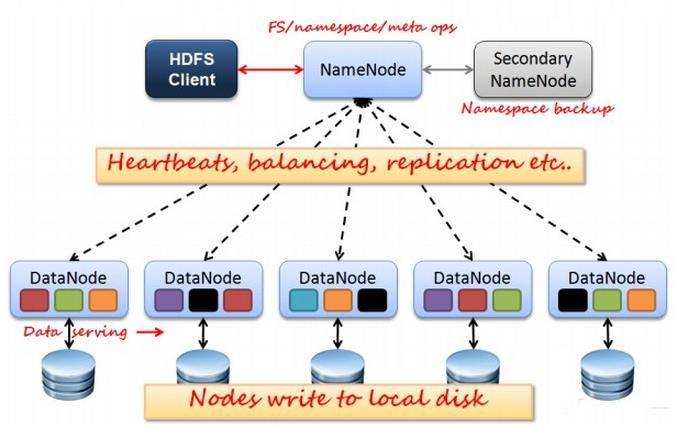
(1)概述
- HDFS集群分為兩大角色:NameNode、DataNode
- NameNode負責管理整個文件系統的元數據
- DataNode 負責管理用戶的文件數據塊
- 文件會按照固定的大小(blocksize)切成若干塊後分散式存儲在若干台datanode上
- 每一個文件塊可以有多個副本,並存放在不同的datanode上
- Datanode會定期向Namenode彙報自身所保存的文件block資訊,而namenode則會負責保持文件的副本數量
- HDFS的內部工作機制對客戶端保持透明,客戶端請求訪問HDFS都是通過向namenode申請來進
(2)HDFS寫工作原理
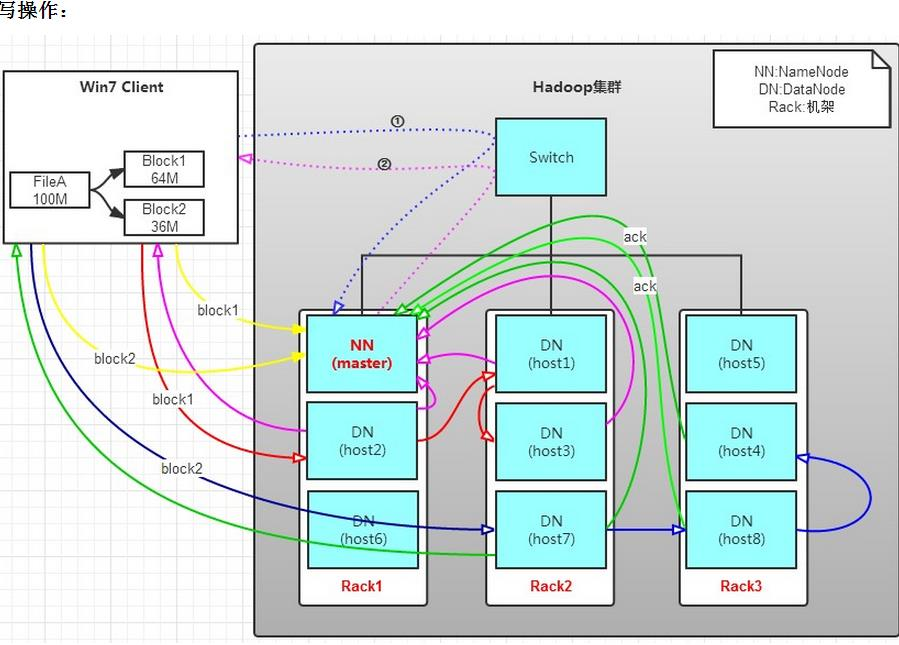
有一個文件FileA,100M大小。Client將FileA寫入到HDFS上。
HDFS按默認配置。
HDFS分布在三個機架上Rack1,Rack2,Rack3。
a. Client將FileA按64M分塊。分成兩塊,block1和Block2;
b. Client向nameNode發送寫數據請求,如圖藍色虛線①——>。
c. NameNode節點,記錄block資訊。並返回可用的DataNode,如粉色虛線②———>。
Block1: host2,host1,host3
Block2: host7,host8,host4
原理:
NameNode具有RackAware機架感知功能,這個可以配置。
若client為DataNode節點,那存儲block時,規則為:副本1,同client的節點上;副本2,不同機架節點上;副本3,同第二個副本機架的另一個節點上;其他副本隨機挑選。
若client不為DataNode節點,那存儲block時,規則為:副本1,隨機選擇一個節點上;副本2,不同副本1,機架上;副本3,同副本2相同的另一個節點上;其他副本隨機挑選。
d. client向DataNode發送block1;發送過程是以流式寫入。
流式寫入過程,//逐個傳輸 host2–>host1–host3>
1>將64M的block1按64k的package劃分;
2>然後將第一個package發送給host2;
3>host2接收完後,將第一個package發送給host1,同時client想host2發送第二個package;
4>host1接收完第一個package後,發送給host3,同時接收host2發來的第二個package。
5>以此類推,如圖紅線實線所示,直到將block1發送完畢。
6>host2,host1,host3向NameNode,host2向Client發送通知,說「消息發送完了」。如圖粉紅顏色實線所示。
7>client收到host2發來的消息後,向namenode發送消息,說我寫完了。這樣就真完成了。如圖×××粗實線
8>發送完block1後,再向host7,host8,host4發送block2,如圖藍色實線所示。
9>發送完block2後,host7,host8,host4向NameNode,host7向Client發送通知,如圖淺綠色實線所示。
10>client向NameNode發送消息,說我寫完了,如圖×××粗實線。。。這樣就完畢了。
分析,通過寫過程,我們可以了解到:
①寫1T文件,我們需要3T的存儲,3T的網路流量貸款。
②在執行讀或寫的過程中,NameNode和DataNode通過HeartBeat進行保存通訊,確定DataNode活著。如果發現DataNode死掉了,就將死掉的DataNode上的數據,放到其他節點去。讀取時,要讀其他節點去。
③掛掉一個節點,沒關係,還有其他節點可以備份;甚至,掛掉某一個機架,也沒關係;其他機架上,也有備份。
(3)HDFS讀工作原理

讀操作就簡單一些了,如圖所示,client要從datanode上,讀取FileA。而FileA由block1和block2組成。
那麼,讀操作流程為:
a. client向namenode發送讀請求。
b. namenode查看Metadata資訊,返回fileA的block的位置。
block1:host2,host1,host3
block2:host7,host8,host4
c. block的位置是有先後順序的,先讀block1,再讀block2。而且block1去host2上讀取;然後block2,去host7上讀取;
上面例子中,client位於機架外,那麼如果client位於機架內某個DataNode上,例如,client是host6。那麼讀取的時候,遵循的規律是:
優選讀取本機架上的數據。
5.HDFS的構建
(1)訂製虛擬機(取名scala_dev)
在VMware 15.x上安裝centos7.x,在第一部分已經介紹過具體的安裝包版本,可以在對應的官網或者中國源下載,也可以聯繫我的郵箱[email protected]。
具體安裝步驟可參見://www.cnblogs.com/gebilaoqin/p/12817510.html
建議安裝圖形化介面,並且配置好網路,使得host和guest能夠相互Ping通。本人使用的是NAT模式,並且給網卡配置固定的IP地址,防止重啟後IP有變化,影響後續的配置和ssh登錄。
NAT配置可參見://blog.csdn.net/sdyb_yueding/article/details/78216135?utm_source=blogxgwz8
關閉防火牆可參見://www.cnblogs.com/yyxq/p/10551274.html
安裝vmtools設置共享文件夾,將windows下載的安裝包通過共享文件夾傳遞到centos中://www.cnblogs.com/Jankin-Wen/p/10157244.html
修改主機名:
a. 在root用戶下:vi /etc/hosts

b. 在root用戶下: vi /etc/hostname
![]()
修改完主機名就可以輸入:reboot 重啟centos
可以ping scaladev看看是否能解析出IP地址
(2)scala_dev無密碼登錄自己
因為搭建的是最簡單的HDFS,NameNode 和 DataNode 都在 scala_dev 上,因此,需要做 scala_dev 無密碼登錄自己,操作如下。:
![]()
解釋:上述命令會 1)自動創建~/.ssh 目錄; 2)在~/.ssh 下自動生成:id_dsa 和 id_dsa.pub 兩個文件,其中,id_dsa 是私鑰,保存在 NameNode 節點,id_dsa.pub 是公鑰,要放置在 DataNode 節點,id_dsa.pub 相當於 NameNode 的身份資訊,一旦在 DataNode 節點登記,就相當於 DataNode 節點已認可 NameNode,這樣, NameNode 就可以無密碼登錄 DataNode 了; 3)-P 後面的 ” 是 2 個單引號,不是雙引號;
將公鑰 id_dsa.pub 加入到 scala_dev 的 authorized_keys 中,實現 scala_dev 對 scala_dev 自身的認證。
![]()
修改 authorized_keys 的許可權
![]()
驗證,如果不需要密碼就可以登錄,則說明操作成功
![]() (填自己的IP地址)查詢系統自帶的java文件,根據不同的系統版本,輸入
(填自己的IP地址)查詢系統自帶的java文件,根據不同的系統版本,輸入rpm -qa | grep jdk或者rpm -qa | grep java
(3)配置JDK
1)查看系統自帶的jdk

2)查詢系統自帶的java文件,根據不同的系統版本,輸入rpm -qa | grep jdk或者rpm -qa | grep java
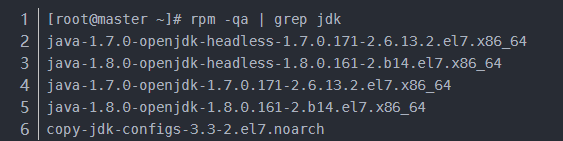
3)刪除noarch文件以外的其他文件,輸入rpm -e --nodeps 需要卸載的安裝文件名

4)查看是否已經刪除完畢

5)解壓jdk
在設置好共享目錄的前提下,共享目錄一般都在/mnt/hgfs/<共享文件名>/, 在windows上把安裝包都放在此目錄下
然後解壓到/home/user/ ,命令為:tar xf /mnt/hgfs/sharefile/jdk-8u162-linux-x64.tar.gz /home/user/
6)配置環境變數
切換到root, 然後vi /etc/profile,輸入以下內容(路徑根據自己實際路徑來,不要照搬)

然後切換的普通用戶:su user
配置完環境變數後都要source /etc/profile
驗證:java -version
(4) 配置HDFS
1)解壓hdfs
tar xf /mnt/hgfs/sharefile/hadoop-2.7.6.tar.gz /home/user/
2)配置環境變數
切換到root然後編輯/etc/profile(路徑根據自己實際路徑來,不要照搬)
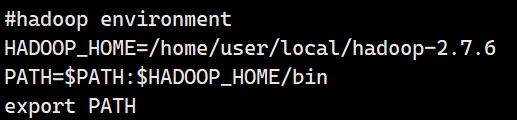
配置完環境變數後都要source /etc/profile
驗證,退回到普通用戶,輸入 hd,看能否用 tab 鍵補全 hdfs,如果可以,說明 profile 設 置成功,如果不行,則要檢查,或者運行 source/etc/profile 再試。
3)設置hostname

此處scaladev不等加下劃線_,否則會出錯,然後重啟;
4)添加hosts資訊

驗證,如果 pingscaladev 能自動解析出 IP,則說明修改成功。
5)修改 hadoop-env.sh (在前面修改了環境變數/etc/profile是不夠的,必須在每台節點上加入java的路徑)

6)修改slaves,它存儲的是所有DataNode的主機名

後續擴展DataNode,只需要在slaves裡面加主機名
7)修改 hdfs-site.xml,先複製模板文件
![]()
編輯模板




8)修改core-site.xml 複製模板


配置了 defaultFS 和 fs.default.name 後,會自動在路徑前面加上 hdfs://scaladev:9001/前綴,這樣,默 認路徑就是 hdfs 上的路徑,之前的 file:///前綴,表示的是本地文件系統。按照目前的配置,/表示 hdfs://scaladev:9001/,表示 HDFS 上的/目錄,而 file:///則表示本地文件系統的/目錄。

9)格式化並啟動 HDFS
a.格式化
![]()
b.啟動HDFS
![]()
c.驗證

2.2.2 構建YARN
1.yarn簡介
Yarn是hadoop的集群管理器,Spark和Mapreduce程式都可以運行在Yarn上。
2.Yarn配置步驟
(1)複製 yarn-site.xml 模板文件

編輯 yarn-site.xml
![]()

(2)複製 mapred-site.xml 模板文件

(3)啟動Yarn

(4)驗證:Yarn上運行MapReduce程式
MapReduce 和 Spark 一樣,也是一個分散式處理框架,MapReduce 程式和 Spark 一樣,可 以提交到 Yarn 上運行,在 Spark 出現之前,MapReduce 是主流的大數據處理平台。Hadoop 中自帶了 MapReduce 的例子程式,如經典的 wordcount(單詞計數)程式,如果 MapReduce 執行成功,說明 Yarn 配置成功,後續,我們將學習如何將 Spark 程式提交到 Yarn 上執行。
提交 MapReduce 程式到 Yarn 上執行的步驟如下:
1)複製文件到HDFS
file:///表示本地文件系統,/表示 HDFS 的根目錄,這是因為在 core-site.xml 中配置了 defaultFS 為 hdfs://scaladev:9001/
![]()
2)驗證
![]()
3)在 HDFS 上準備輸入目錄 input,以及文件 core-site.xml
![]()
4)運行wordcount的例子

5)驗證

(5)Yarn運行Mapreduce程式的過程
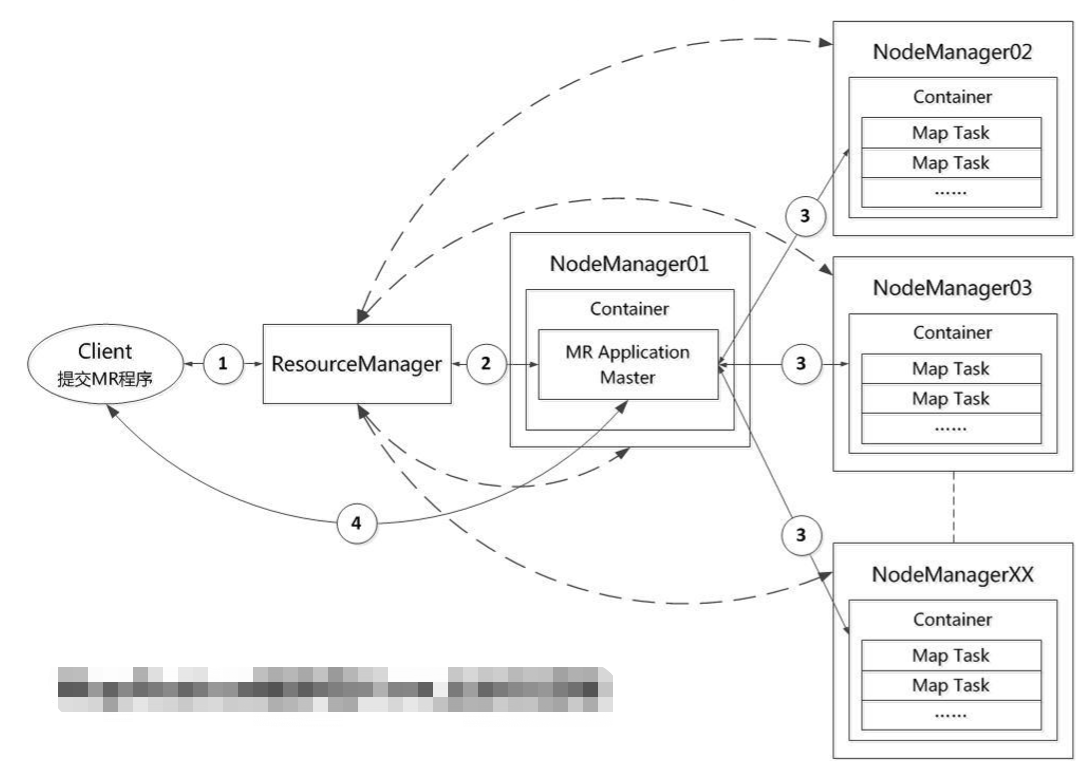
1)當執行下面的命令後, Client 向 ResourceManager 發送運行 wordcount 程式(Application) 的請求;ResourceManager 響應請求,返回 Application ID 和一個 HDFS 地址;Client 將啟動 Application 所需資訊(要運行的 jar 包,資源要求等)上傳到指定的 HDFS 路徑下,並向 ResourceManager 發起啟動 MRApplicationMaster(簡稱 AM)請求; hadoopjarshare/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.6.jarwordcount/input/output
2)ResourceManager 根據當前資源使用情況和調度策略,確定一個可用節點(例如 NodeManager01),向該節點的 NodeManager 發送命令,啟動一個 Container 來運行 AM;
AM 是此次 wordcount 程式運行的管理者,從 wordcount 的啟動到結束都由此 AM 來負責。 AM 啟動後,向 ResourceManager 註冊,計算 Task 數(map 數(Split 數量決定,一個 Split 對 應一個 map)+reduce 數(mapreduce.job.reduces)),以此確定 Container 數(map 數+reduce 數),然後準備好每個任務 Container 請求,發送給 ResourceManager;ResourceManager 響應 請求,為其指定可用的節點 NodeManager02~NodeManagerXX;

3) AM 依次和這些節點的 NodeManager 通訊,在這些節點上啟動 Container,並在 Container 執行 wordcount 中的 Task,wordcount 的 Task 分為 map 和 reduce 兩種,先執行 mapTask,然 後執行 reduceTask(匯總操作),並向 AM 彙報任務狀態;在執行過程中,Client 會和 AM 通 信,查詢 Application 執行情況或者控制任務執行;
4)當某個 Container 上的任務執行完畢,可以退出時,AM 會和 ResourceManager 通訊, 申請釋放此 Container 及其資源。待總的 Application 結束,所有資源都釋放完畢,AM 會向 ResourceManager 申請註銷自己,最後,Client 退出。
(6)Yarn日誌
Yarn的日誌分為兩大類: 1.Yarn架構自身相關日誌,包括ResourceManager和NodeManager 的日誌;2. 在 Yarn 上執行的程式(Application)日誌。
第一類日誌的 ResourceManager 日誌位於 ResoureManager 的$HADOOP_HOME 下的 log 目錄中,日誌文件名是 yarn-user-resourcemanager-scaladev.log。
第一類日誌的 NodeManager 日誌位於每個 NodeManager 的$HADOOP_HOME 下的 log 目 錄中,日誌文件名是 yarn-user-nodemanager-scaladev.log。
第二類日誌位於 ResoureManager 的$HADOOP_HOME 下的 log/userlogs 目錄下,每個 Application 都會根據其 ID 號創建一個目錄,例如:application_1533802263437_0005,在此目錄下,會保存該 Application 所有 Container 的日誌,示例如下,可以看到 wordcount 這個 Application有3個Container,其中尾號為1的container是AM,其它的container用來執行Task, 可能是 MapTask,也可能ReduceTask。每個 container 日誌目錄下又有 3 個文件:stdout、 stderr 和 syslog,其中 stdout 是 Task 執行過程中輸出,例如 printfln 就會輸出到 stdout 中, stderr 會保存報錯資訊,syslog 則會保存系統日誌輸出。
2.2.3 構建Spark集群
(1)下載 Spark 軟體包
Spark 所選擇的版本是 2.3.0,軟體包名:spark-2.3.0-bin-hadoop2.7.tgz,下載地址為: //archive.apache.org/dist/spark/spark-2.3.0/spark-2.3.0-bin-hadoop2.7.tgz
(2)解壓
![]()
(3)配置環境變數

(4)設置JAVA_HOME

2.3 運行Spark程式
本地運行、分散式運行
2.3.1本地運行方式
示例:SparkPi
Spark軟體包中有一個spark-examples_2.11-2.3.0.jar 它是Spark自帶示例的jar包,下面就以其中的SparkPi為例,介紹Spark程式的本地(local)運行方式
運行SparkPi具體命令如下:
在spark目錄下執行:spark-submit –class org.apache.spark.examples.SparkPi –master local examples/jars/spark-examples_2.11-2.3.0.jar 10
SparkPi的程式參數說明如下:
- –class org.apache.spark.examples.SparkPi , 指明此運行程式的Main Class
- –master local ,表示此Spark程式Local運行
- examples/jars/spark-examples_2.11-2.3.0.jar, 為Spark示例的jar包
- 10,表示迭代10次。
如果輸出結果,這說明成功。
程式運行時如果報了一個WARN提示:NativeCodeLoader:62-Unable to load native-hadoop library for your platform
解決辦法是在/etc/profile中添加下面的內容
export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native
切換到普通用戶,運行下面的命令,使得配置生效。
source /etc/profile
2.4 運行Spark程式(分散式)
Spark程式分散式運行要依賴特定的集群管理器,最常用的有Yarn和Standalone。Client和Driver是否在一個進程里,可以分為client和cluster模式。
2.4.1 Spark on Yarn
1.client deploy mode
以DFSReadWriteTest為例,說明Spark on Yarn的client 的deploy mode。
DFSReadWriteTest是Spark-examples_2.11-2.3.0.jar自帶的一個示例,它會讀取本地文件進行單詞計數,然後將本地文件上傳到HDFS,從HDFS讀取該文件,使用Spark進行計數,最後比較兩次計數的結果。
(1)提交Spark程式 到Yarn上 ,以client mode運行
spark-submit –class org.apache.spark.examples.DFSReadWriteTest –master yarn /home/user/spark-2.3.0-bin-hadoop2.7/examples/jars/spark-examples_2.11-2.3.0.jar /etc/profile /output
運行改程式要保證Yarn和HDFS同時啟動。
如果結果正確,會輸出:Success!
運行報錯:初次運行程式時,可能會有以下兩個報錯。
報錯1的報錯資訊如下所示:
Exception in thread “main”java.lang Exception: When unning with master yam’ either HADOOP_CONF DIR or YARN_CONF _DIR must be set in the environment.
報錯原因:沒有設置環境變數:HADOOP_CONF_DIR或YARN_CONF_DR.
解決辦法:在/etc/profile中增加下面的內容。
HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_CONF_DIR
切回到普通用戶,使剛才的配置失效。
報錯2的報錯資訊如下所示。
報錯原因:Container(容器)的記憶體超出了虛擬記憶體限制,Container的虛擬記憶體為2.1GB,但使用了2.3GB.comtainer fpd-+22containeriD-container.15373079299 0002_02 0000l1]is runing ba
mual ncnoy ias CGma uage I64 SMB ofI GB plysical memory uscd 23 GB of 2.1 GB virual meaused Killing container
解決辦法:
改變分配Container最小物理記憶體值,將yarn.scheduler.minimum-allocation-mb設置成2GB,重啟Yarn,每個Container向RM申請的虛擬記憶體為2GB*2.1=4.2GB
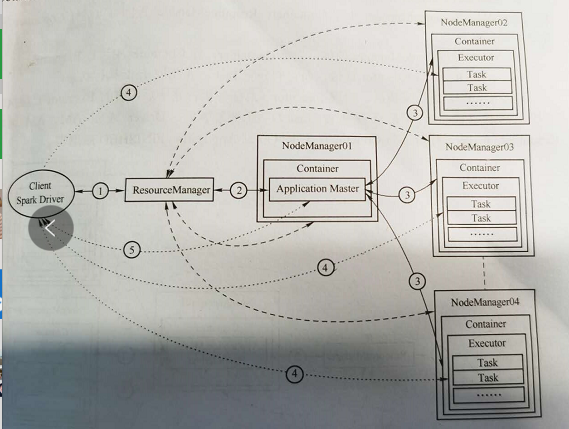
(2)Spark程式在Yarn上的執行過程
1)client模式下,Client和Driver在一個進程內,向Resource Manager發出請求;
2)Resource Manager指定一個節點啟動Container,用來運行AM;AM向resource manager申請container來執行程式,resource manager向AM返回可用節點;
3)AM同可用節點的NodeManager通訊,在每個節點上啟動Container,每個Container中運行 一個Spark的Excutor,Excutor再運行若干Tasks;
4)Driver與Executor通訊,向其分配Task並運行,並檢測其狀態,直到整個任務完成;
5)總任務完成後,Driver清理Executor,通知AM,AM想ResouceManager請求釋放Container,所有資源清理完畢後,AM註銷並退出、client退出。
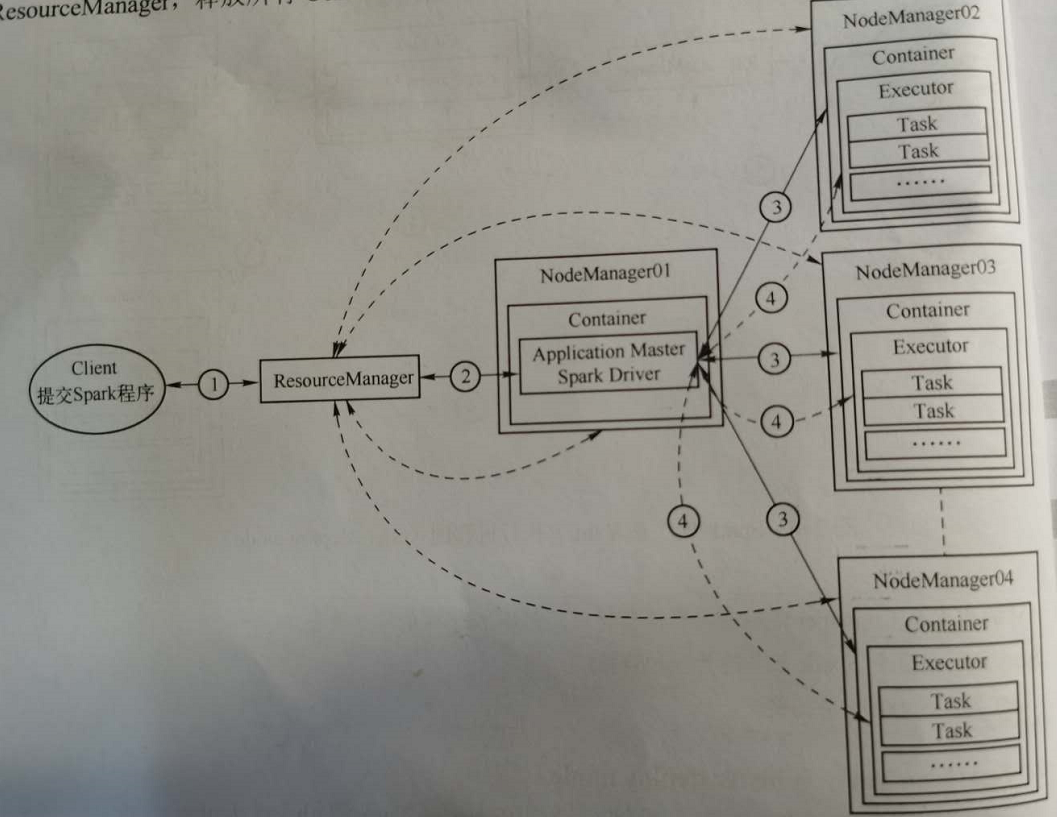
2. Spark on Yarn (cluster deploy mode)
(1)提交DFSReadWriteTest到Yarn運行(cluster deploy mode)
命令:spark-submit –deploy-mode cluster –class org.apache.spark.examples.DFSReadWriteTest –master yarn /home/user/spark-2.3.0-bin-hadoop2.7/examples/jars/spark-example_2.11-2.3.0.jar /etc/profile /outputSpark
(2)Spark程式在Yarn上執行過程
1)Client想ResourceManager提交Application請求;
2)ResourceManager指定一個節點,啟動Container來運行AM和Spark Driver;AM根據任務情況向ResourceManager申請Container;ResourceManager返回可以運行Container NodeManager;
3)AM與這些NodeManager通訊,啟動Container,在Container中執行Executor;
4)Spark Driver與Executor通訊,向它們分配Task,並監控Task執行狀態;
5)所有Task執行完畢後,清理Executor,清理完畢後,Driver通知AM,AM請求Resource Manager,釋放所有Container;Client收到Application FINISHED後退出。
2.4.2 Spark on Standalone
Standalone是Spark自帶的集群管理器,主/從式架構,包括Master和Worker兩種角色,Master管理所有的Worker,Worker負責單個節點的管理。
優點:簡單、方便、快速部署。
缺點:不通用、只支援Spark,功能沒有Yarn強大
1.Spark on Standalone(client deployed mode)
(1)部署Standalone
1)配置slaves文件,改文件保存了整個集群中被管理節點的主機名。先複製模板文件;
cp conf/slaves.template conf/slaves
2)編輯slaves文件
vi conf/slaves
3)將localhost修改為scaladev
scala_dev
4)添加JAVA_HOME
cp conf/spark-env.sh.template conf/spark-env.sh
5)編輯spark-env.sh文件
vi conf/spark-env.sh
6)在最後一行添加下面內容
export JAVA_HOME=/home/user/jdk1.8.0_162
7)啟動Standalone集群
sbin/start-all.sh
8)驗證 jps,查看是否有worker和master
9)查看Standalone的Web監控介面
(2)提交Spark程式到Standalone上,以client deploy mode運行
提交前卻把HDFS已經啟動,HDFS上/output目錄下已經清空。具體命令如下:
spark-submit –class org.apache.spark.examples.DFSReadWriteTest –master spark://scaladev:7077 /home/user/spark-2.3.0-bin-hadoop2.7/examples/jars/spark-examples_2.11-2.3.0.jar /etc/profile /output
其中-master spark:// scaladev:7077 表示連接Standalone集群, scaladev是Master所在的主機名,沒有指定–deploy-mode cluster,則部署模式默認為client
(3)Spark程式在Standalone上的運行過程(client deploy mode)
client部署模式下,Spark程式在Standalone的運行過程如圖所示。

1)Client初始化,內部啟動Client模組和Driver模組,並向Master發送Application請求;
2)Master接收請求,為其分配Worker,並通知Worker啟動Executor;
3)Executor向Driver註冊,Driver向Executor發送Task,Executor執行Task,並回饋執行狀態,Driver再根據Executor的當前情況,繼續發送Task,直到整個Job完成。
2.Spark on Standalone(cluster deploy mode)
(1)提交Spark程式到Standalone,以cluster deploy mode運行
具體命令如下:
spark-submit –class org.apache.spark.examples.DFSReadWriteTest –master spark://scaladev:6066 –deploy-mode cluster /home/user/spark-2.3.0-bin-hadoop2.7/examples/jars/spark-examples_2.11-2.3.0.jar /etc/profile hdfs://scaladev:9001/output
有4點要特別注意:
1)採用cluster deploy mode時,Driver需要一個處理器,後續Executor還需要另外的處理器,如果虛擬機scaladev只有1個處理器,就會出現資源不足的警告,導致程式運行失敗,如下所示:
WARN TaskSchedulerImpl:66 – Initial job has not accepted any resource
解決辦法:增加虛擬機的處理器為2個。
2)命令參數中,–master spark://scaladev:6066 用來指定Master的URL,cluster deploy mode下,Client會向Master提交Rest URL, Spark://scaladev:6066就是Spark的Rest URL;如果還是使用原來的參數–master spark://scaladev:7077,則會報下的錯誤;
WARN RestSubmissionClient:66 -Unable to connect to server spark://7077
3)HDFS的路徑前面要加hdfs://,因為Cluster Mode下,core-site.xml中的defaultFS設置不起作用;
4)Client提交成功後就會退出,而不是等待Application結束後才退出。
(2)Spark程式在Standalone上的運行過程(cluster deploy mode)
cluster deploy mode下,Spark程式在Standalone的運行過程如圖所示。
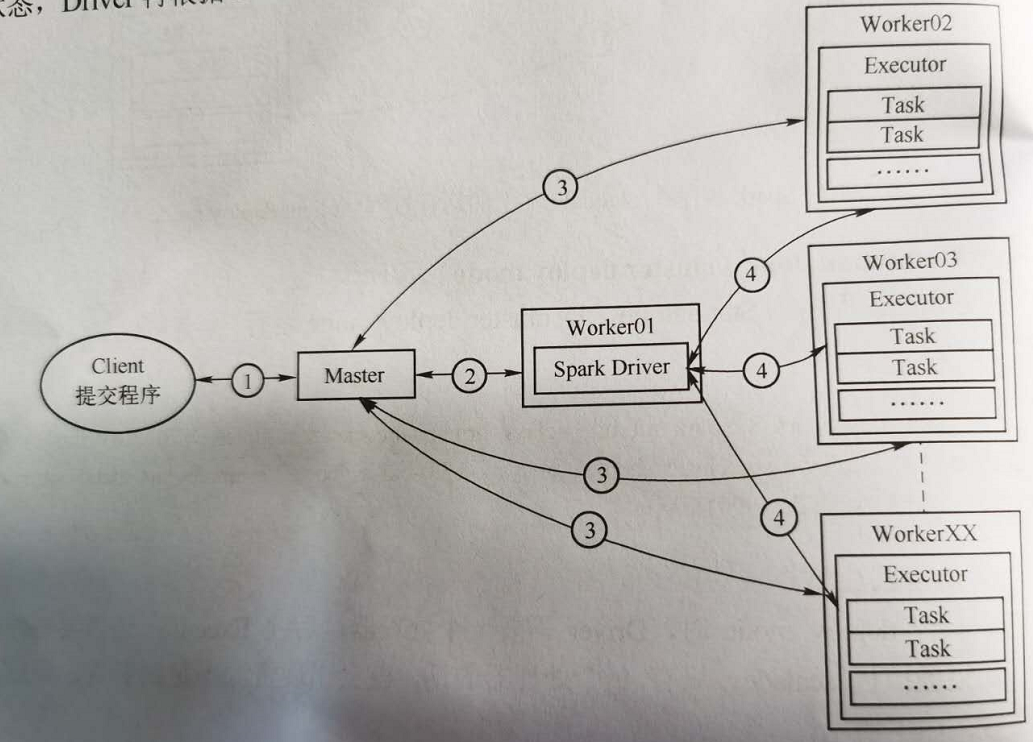
1)Client初始化,內部啟動Client模組,並向Master註冊Driver模組,並等待Driver資訊,待後續Driver模組正常運行,Client退出;
2)Master接收請求,分配一個Worker,並通知這些Worker啟動Executor;
3)Master接受請求,分配Worker,並通知這些Worker啟動Executor;
4)Executor向Driver註冊,Driver向Executor發送Task,Executor執行Task,並回饋執行狀態,Driver再根據Executor的當前情況,繼續發送Task,直到整個Job完成
3. Spark on Standalone日誌
standalone的日誌分為兩類:框架日誌、應用日誌。
框架日誌:指Master和Worker日誌,Master日誌位於Master的Spark目錄下的logs目錄下,文件名:spark-user-org.apache.spark.deploy.master.Master-1-scaladev.out;Worker位於每個Worker節點的Spark目錄下的logs目錄下,文件名為:spark-user-org.apache.spark.deploy.worker.Worker-1-scaladev.out。
應用日誌:指每個Spark程式運行的日誌,因為一個Spark程式可能會啟動多個Executor,每個Executor都會有一個日誌文件,位於Executor所在的Worker節點的Spark目錄的work目錄下,每個Spark運行會分配一個ID,運行時在控制台會列印ID的值,如下所示:
Connected to Spark cluster with app ID app-2018081004758-0001
列出woker目錄下的內容,命令如下。
ls work/
然後就可以看目錄下的內容。


