半監督學習(三)——混合模型
- 2019 年 10 月 27 日
- 筆記
Semi-Supervised Learning
半監督學習(三)
方法介紹
Mixture Models & EM
無標籤數據告訴我們所有類的實例混和在一起是如何分布的,如果我們知道每個類中的樣本是如何分布的,我們就能把混合模型分解成獨立的類,這就是mixture models背後的機制。今天,小編就帶你學習半監督學習的混合模型方法。
混合模型 監督學習
首先,我們來學習概率模型的概念,先來看一個例子:
-
Example 1. Gaussian Mixture Model with Two Components
訓練數據來自兩個一維的高斯分布,如下圖展示了真實的分布以及一些訓練樣本,其中只有兩個有標籤數據,分別標記為正負。
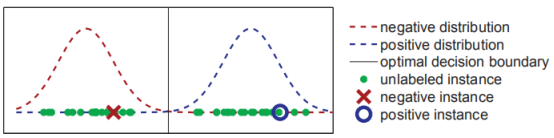
假如我們知道數據來自兩個高斯分布,但是不知道參數(均值,方差,先驗概率等),我們可以利用數據(有標籤和無標籤)對兩個分布的參數進行估計。注意這個例子中,帶標籤的兩個樣本實際上帶有誤導性,因為它們都位於真實分布均值的右側,而無標籤數據可以幫助我們定義兩個高斯分布的均值。參數估計就是選擇能 最大限度提高模型生成此類訓練數據概率 的參數。
更規範化地解釋:要預測樣本x的標籤y,我們希望預測值能最大化條件概率p(y|x),由條件概率的定義,可知對於所有可能的標籤y,
 ,且
,且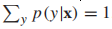 ,如果我們想要最小化分類錯誤率,那麼我們的目標函數就是
,如果我們想要最小化分類錯誤率,那麼我們的目標函數就是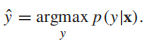 ,當然了,如果不同類型的誤分類導致的損失不同(如,將良性腫瘤錯誤分類為惡性),那麼上述的最小化期望誤差可能不是最佳策略,我們將在下文中討論最小化損失函數的內容。那麼如何計算p(y|x)呢?一種方法就是使用生成模型(採用Bayes規則):
,當然了,如果不同類型的誤分類導致的損失不同(如,將良性腫瘤錯誤分類為惡性),那麼上述的最小化期望誤差可能不是最佳策略,我們將在下文中討論最小化損失函數的內容。那麼如何計算p(y|x)呢?一種方法就是使用生成模型(採用Bayes規則):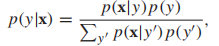 其中,P(x|y):類條件概率;p(y):先驗概率;P(x,y) = p(y)p(x|y) :聯合分布。多元高斯分布常作為連續型隨機變數的生成模型,它的類條件概率的形式如下:
其中,P(x|y):類條件概率;p(y):先驗概率;P(x,y) = p(y)p(x|y) :聯合分布。多元高斯分布常作為連續型隨機變數的生成模型,它的類條件概率的形式如下: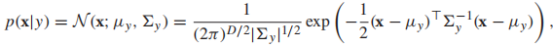
 和
和 分別表示均值向量和協方差矩陣。以一個影像分類任務為例,x是一張圖片的像素向量,每一種類別的影像都用高斯分布建模,那麼整體的生成模型就叫做高斯混合模型(GMM)。
分別表示均值向量和協方差矩陣。以一個影像分類任務為例,x是一張圖片的像素向量,每一種類別的影像都用高斯分布建模,那麼整體的生成模型就叫做高斯混合模型(GMM)。 -
多項式分布也常作為生成模型,他的形式如下:
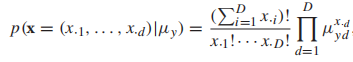
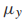 是一個概率向量。以一個文本分類的任務為例,x是一個文檔的詞向量,每一種類型的文檔都用多項式分布來建模,那麼整體的生成模型就叫做多項式混合模型。
是一個概率向量。以一個文本分類的任務為例,x是一個文檔的詞向量,每一種類型的文檔都用多項式分布來建模,那麼整體的生成模型就叫做多項式混合模型。作為另一種生成模型的例子,隱馬爾可夫模型(HMM)通常用來建模序列,序列中的每個實例都是從隱藏狀態生成的,隱藏狀態可以是高斯分布,也可以是多項式分布,而且HMMs 指定狀態之間的轉移概率來生成序列,學習HMMs模型包括估計條件概率分布的參數和轉移概率。
現在,我們知道如何根據p(x|y)和p(y)來做分類,問題仍然是如何從訓練集中學習到這些分布。類條件概率p(x|y)由模型參數決定,比如高斯分布的均值和協方差矩陣,對於p(y),如果由C個類,那麼需要估計C-1個參數:p(y=1),…,p(y=C-1),因為p(y=C)=1- (p(y=1)+…+p(y=C-1))。用θ表示我們要估計的參數集合,一個最常用的準則是最大似然估計
(MLE),給定訓練集D,
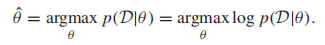
(我們常常使用對數似然,因為log函數是單調的,它與使用原函數有相同的最優解,但是更容易處理)。
在監督學習中,訓練集為
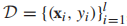
,我們重寫一些對數似然函數
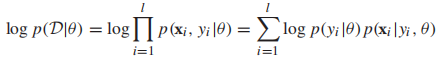
現在我們來定義在監督學習中如何使用MLE(參數估計)建模高斯混合模型(以2分類高斯混合模型為例):
首先定義我們的約束優化問題:
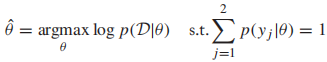
接著我們引入拉格朗日乘子:
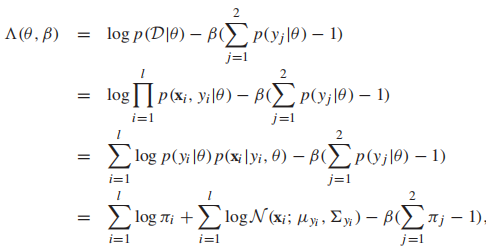
其中,
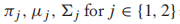 分別是類先驗,高斯分布的均值和協方差矩陣。我們計算所有參數的偏導,然後設每個偏導函數為0,得到MLE的閉式解:
分別是類先驗,高斯分布的均值和協方差矩陣。我們計算所有參數的偏導,然後設每個偏導函數為0,得到MLE的閉式解: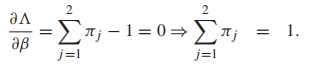
(顯然,β拉格朗日乘數的作用是對類先驗概率執行規範化約束) 以及
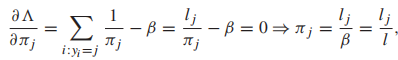
從上面的式子中可以發現β=l,最後我們發現,類先驗概率就是每個類樣本佔總樣本的比例。我們接下來解決類均值的問題,我們仍對均值向量求偏導,通常讓v代表一個向量,A是一個合適大小的方陣,有
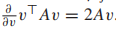 所以我們可以得到
所以我們可以得到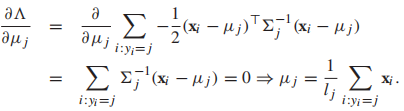 我們發現每個類的均值就是類中樣本的均值。最後,用MLE求協方差矩陣
我們發現每個類的均值就是類中樣本的均值。最後,用MLE求協方差矩陣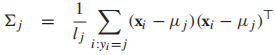 ,也是一個類中樣本的協方差。
,也是一個類中樣本的協方差。
Mixture models for semi-supervised classification
閱讀完第一節,相信你們已經對混合模型及其參數估計有了理解,現在我們進入正題,如何將混合模型運用到半監督學習上去。
因為訓練集中包含有標籤和無標籤數據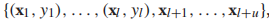
那麼可以將似然函數定義為如下形式:
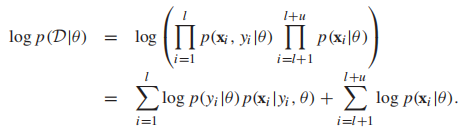
P(x|θ)叫做邊緣概率,
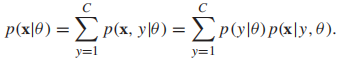
它代表的是我們知道這些未標記樣本的存在,但是不知道它們屬於哪個類。半監督的![]() 需要同時適用標籤數據和無標籤數據。我們把未觀察到的標籤叫做隱變數,不 幸的是,這些隱變數會導致log似然函數非凸而難以優化。但是,很多優化方法可以找到局部最優的θ,最有名的就是EM(expectation maximization)演算法。
需要同時適用標籤數據和無標籤數據。我們把未觀察到的標籤叫做隱變數,不 幸的是,這些隱變數會導致log似然函數非凸而難以優化。但是,很多優化方法可以找到局部最優的θ,最有名的就是EM(expectation maximization)演算法。
OPTIMIZATION WITH THE EM ALGORITHM

![]() 是隱藏標籤的分布,可以認為是根據當前的模型參數為無標籤數據預測的“軟標籤”。可以證明的是,EM每一輪迭代提高了log似然函數,但是EM只能求局部最優解(θ可能不是全局最優)。EM收斂的局部最優解依賴於θ的初始值,常用的初始值是有標籤樣本的MLE。注意,EM演算法需要針對特定的生成模型,以GMM為例。
是隱藏標籤的分布,可以認為是根據當前的模型參數為無標籤數據預測的“軟標籤”。可以證明的是,EM每一輪迭代提高了log似然函數,但是EM只能求局部最優解(θ可能不是全局最優)。EM收斂的局部最優解依賴於θ的初始值,常用的初始值是有標籤樣本的MLE。注意,EM演算法需要針對特定的生成模型,以GMM為例。
-
EM for GMM

其中,E-step相當於給每個樣例計算一個標籤概率向量,M-step更新模型參數,演算法會在log似然函數收斂的時候停止,混合高斯模型的log似然函數是:
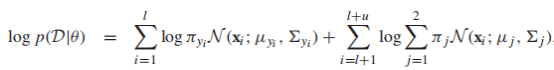
有的同學會發現,EM演算法和我們之前提到過的self-training相似,EM演算法可以看作self-training的特殊形式,其中當前的分類器θ將利用所有有標籤數據給無標籤數據打上標籤,但是每個分類器的權重是
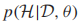 ,然後這些增強的無標籤數據被用來更新分類器。
,然後這些增強的無標籤數據被用來更新分類器。
-
The Assumptions of Mixture Models
混合模型提供了半監督學習的框架,事實上,如果使用正確的生成模型,這種框架的效果是很好的,所以我們有必要在這裡提以下模型假設:
Mixture Model Assumption:數據來自混合模型且模型個數,先驗概率p(y)和條件概率p(x|y)是正確的。
然而,這一假設很難成立,因為有標籤數據很少,很多時候我們都是根據領域知識去選擇生成模型,但是模型一旦選錯了,半監督學習會使模型表現變差,在這種場景下,最好只使用在有標籤數據上進行監督學習。
-
Cluster-than-Label Method
我們已經用EM演算法來給無標籤數據打標籤,其實無監督聚類演算法同樣可以從無標籤數據中定義出類:

第一步,聚類演算法A是無監督的,第二步,我們利用每個聚類中的有標籤數據學習一個分類器,然後使用這個預測器對這個聚類中的無標籤數據進行預測。
舉一個使用層次聚類的Cluster-than-Label實例:
我們首先用層次聚類(距離方程用歐式距離,聚類之間的距離用single linkage決定)
下圖展示了數據的原始分布(兩個類),以及最終的標籤預測結果,在這個例子中,由於兩個有標籤實例恰好是正確的,我們正確分類了所有的數據。
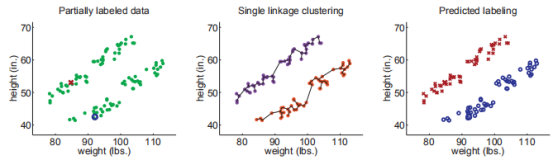
其實使用single linkage方法在這裡非常重要(真實的聚類又細又長),如果使用complete linkage 聚類,聚類結果會偏向球形,結果會像這樣:
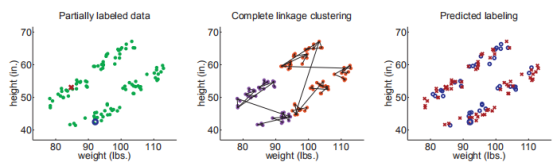
上面的實驗並不是想說明complete linkage 不如 single linkage,而是為了強調假設對半監督學習的重要性。
總結:
這篇文章混合模型和EM演算法在半監督學習上的應用,隨後也介紹了一種非概率的,先聚類後標記的方法,它們背後都隱含這相同的思想:無標籤數據可以幫助定義輸入空間的聚類,下一篇文章中,我們會介紹另一種半監督學習方法 co-training,敬請期待~
希望大家多多支援我的公眾號,掃碼關注,我們一起學習,一起進步~


