Java多執行緒_快取對齊
1.什麼是快取對齊
當前的電腦中,數據存儲在磁碟上,可以斷電保存,但是讀取效率較低。不斷電的情況下,數據可以在記憶體中存儲,相對硬碟效率差不多是磁碟的一萬倍左右。但是運算時,速度最快的是直接快取在CPU中的數據。CPU有三級快取分別是L1,L2,L3三級,CPU訪問速度大概是記憶體的100倍。
1.1CPU結構
對於一台電腦,其主板可以支援多少個CPU插槽,稱為CPU個數。對於一顆多核CPU,單片CPU上集成的處理核心稱為CPU核數。對於每個核心,可以給每個核設置兩組暫存器,兩組pc。
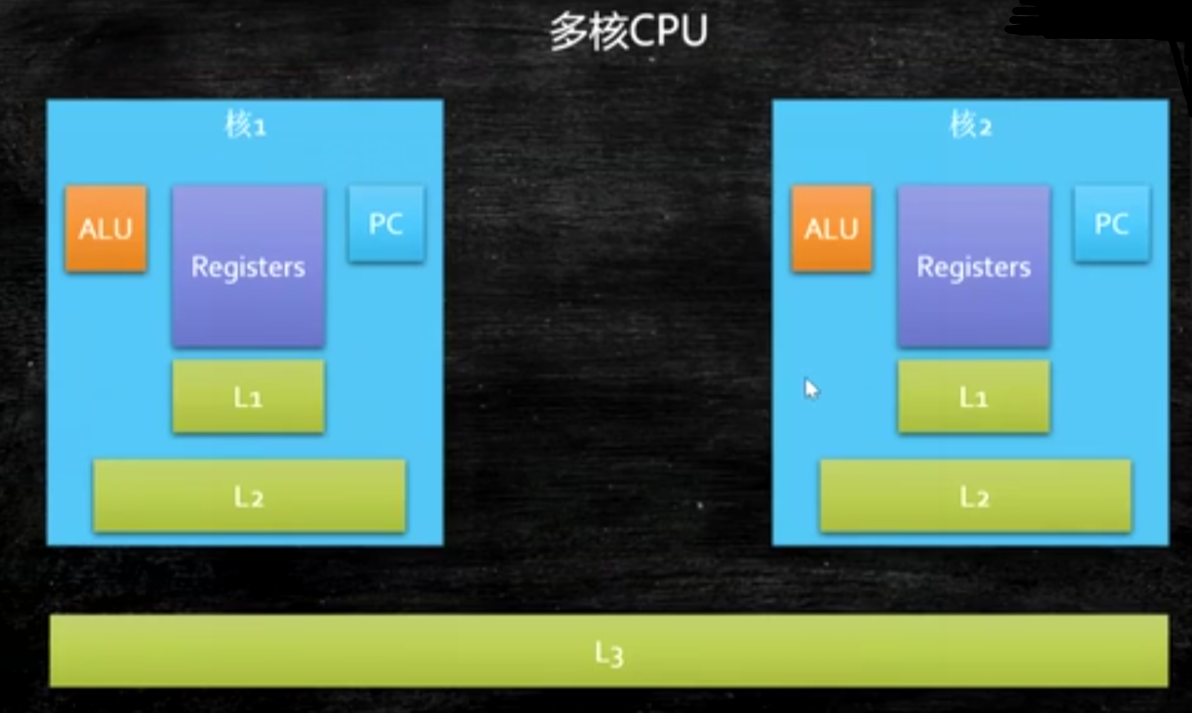
CPU結構如上圖所示(圖片來自網路),對於一塊CPU,可以有多個處理核心。每個核心內有自己的L1,L2快取,多個核心共用同一個L3快取。但一個電腦如果有多個CPU插槽,各個CPU有自己的L3。對於一個CPU核心來說,每個核心都有ALU,邏輯運算單元。負責對指令進行計算。Register 暫存器,記錄執行緒執行對應的數據。PC:指令暫存器,記錄執行緒執行到了哪個位置。裡面存的是指令行數。通俗講,就是記錄執行緒執行到了哪一行指令(程式碼在進入CPU運行前,會被編譯成指令)了。
執行緒在執行的時候,將當前執行緒對應的數據放入暫存器,將執行行數放到指令暫存器,然後執行過一個時間片後,如果執行緒沒有執行完,將數據和指令保存,然後其他執行緒進入執行。一個ALU對應多個PC|registers的時候(所謂的四核八執行緒)。一般來說,同一個CPU核在同一個時間點,只能執行同一個執行緒,但是,如果一個核裡面有兩組暫存器,兩個pc。那麼就可以同時執行兩組執行緒,在切換執行緒的時候,沒必要再去等待暫存器的數據保存和數據載入。直接切換到下一組暫存器就可以。這就是超執行緒。
1.2快取對齊

CPU到記憶體之間有很多層的記憶體,如圖所示,CPU需要經過L1,L2,L3及主記憶體才能讀到數據。從主記憶體讀取數據時的過程如下:
當我左側的CPU讀取x的值的時候,首先會去L1快取中去找x的值,如果沒有,那麼取L2,L3依次去找。最後從主記憶體讀入的時候,首先將記憶體數據讀入L3,然後L2最後L1,然後再進行運算。但是讀取的時候,並不是只讀一個X的值,而是按塊去讀取(跟電腦的匯流排寬度有關,一次讀取一塊的數據,效率更高)。CPU讀取X後,很可能會用到相鄰的數據,所以在讀X的時候,會把同一塊中的Y數據也讀進來。這樣在用Y的時候,直接從L1中取數據就可以了。
讀取的塊就叫做快取行,cache line 。快取行越大,局部性空間效率越高,但讀取時間慢。快取行越小,局部性空間效率越低,但讀取時間快。目前多取一個平衡的值,64位元組。
然後,如果你的X和y在同一塊快取行中,且兩個欄位都用volatile修飾了,那麼將來兩個執行緒再修改的時候,就需要將x和y發生修改的消息高速另外一個執行緒,讓它重新載入對應快取,然而另外一個執行緒並沒有使用該快取行中對應的內容,只是因為快取行讀取的時候跟變數相鄰,這就會產生效率問題。
解決起來也簡單,我們將數據中的兩個volatile之間插入一些無用的記憶體,將第二個值擠出當前快取行,那麼執行的時候,就不會出現相應問題了。提高程式碼效率。
2.快取對齊在java中實現
在java中,jdk一些涉及到多執行緒的類,有時候會看到類似於public volatile long p1,p2,p3,p4,p5,p6,p7;這樣的程式碼,有的就是做的快取行對齊。
我們設計一個實驗去驗證快取行對齊的導致的性能問題,及相關的解決後的效率問題。具體程式碼見第三小節。這裡的思路是,首先,我們寫一個類T,這個類裡面有一個用volatile修飾的long屬性的值,這個值佔用8個位元組。然後聲明一個靜態數組,包含兩個元素,分別T的兩個對象。然後開啟兩個執行緒,讓兩個執行緒分別給數組的第一個值和第二個值賦值,執行一百萬次,看執行的耗時。
這個時候,程式碼執行的時候如1.2的圖中所示,假設數組中第一個值為X,第二個值為Y。左側框內為第一個執行緒,執行修改X值的操作,右側框內為第二個執行緒,修改Y的值。因為兩個值在同一個快取行中,所以在X值在讀取的時候,同時將X值和Y值一起讀入快取。第二個執行緒只修改Y的值,但是同樣將XY全部讀入快取。執行緒1中X值發生修改後,第二個執行緒中的X值需要進行更新。而執行緒2修改Y的值後也需要同樣的操作,但是這個更新不是必要的,而且會影響執行的效率。
解決方法是:我們給第T的long值之前加入8個long值,這樣Y值就會被擠到其他快取行,這樣彼此修改的時候就不會產生干擾,提高程式碼執行效率。
下面是具體驗證的程式碼,其中在沒有加入父類的時候,是相互干擾時的執行耗時。第二個是加入父類後,不再干擾時的耗時,執行後可以看出,第二套程式碼在執行的時候,程式碼要優於第一套程式碼的執行。
3.快取對齊的程式碼實現
1 public class T01_CacheLinePadding { 2 private static class T{ 3 public volatile long x = 0L; 4 } 5 public static T[] orr = new T[2]; 6 static { 7 orr[0]= new T(); 8 orr[1]= new T(); 9 } 10 public static void main(String[] args) throws Exception { 11 Thread t1 = new Thread(()->{ 12 for (long i = 0; i < 1000_000L; i++) { 13 orr[0].x = i; 14 } 15 }); 16 Thread t2 = new Thread(()->{ 17 for (long i = 0; i < 1000_000L; i++) { 18 orr[1].x = i; 19 } 20 }); 21 final long start = System.nanoTime(); 22 t1.start(); 23 t2.start(); 24 t1.join(); 25 t2.join(); 26 System.out.println((System.nanoTime()-start)/100_000); 27 } 28 }
1 package msb; 2 /** 3 * 快取行對齊問題程式碼 4 * @author L Ys 5 * 6 */ 7 public class T02_CacheLinePadding { 8 private static class Padding{ 9 public volatile long p1,p2,p3,p4,p5,p6,p7; 10 } 11 private static class T extends Padding{ 12 public volatile long x = 0L; 13 } 14 public static T[] orr = new T[2]; 15 static { 16 orr[0]= new T(); 17 orr[1]= new T(); 18 } 19 public static void main(String[] args) throws Exception { 20 Thread t1 = new Thread(()->{ 21 for (long i = 0; i < 1000_000L; i++) { 22 orr[0].x = i; 23 } 24 }); 25 Thread t2 = new Thread(()->{ 26 for (long i = 0; i < 1000_000L; i++) { 27 orr[1].x = i; 28 } 29 }); 30 final long start = System.nanoTime(); 31 t1.start(); 32 t2.start(); 33 t1.join(); 34 t2.join(); 35 System.out.println((System.nanoTime()-start)/100_000); 36 } 37 }


