深度學習模型建立的整體流程和框架
深度學習模型建立的整體流程和框架
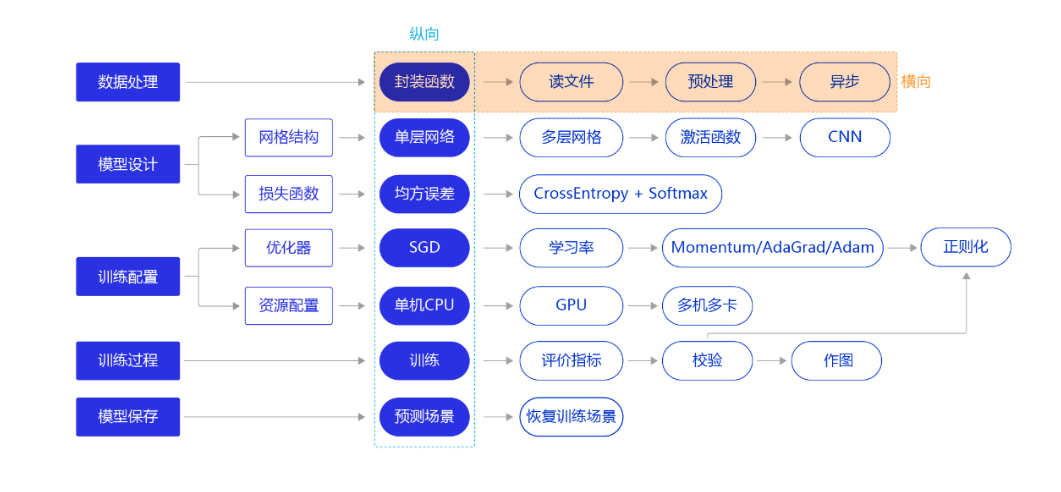
框架圖如下,縱向是建立模型的主要流程,是一個簡化且宏觀的概念,橫向是針對具體模組的延展。
數據處理
數據處理一般涉及到一下五個環節:
- 讀入數據
- 劃分數據集
- 生成批次數據
- 訓練樣本集亂序
- 校驗數據有效性
模型設計
網路結構
網路結構指的就是通常所說的神經網路演算法中的網路框架,如全連接神經網路,卷積神經網路以及循環神經網路等,不同的網路結構通常有各自最優的處理場景,所以在處理具體問題時選擇合適的網路結構是十分重要的。
損失函數
損失函數是模型優化的目標,用於在眾多的參數取值中,識別出最優的參數。損失函數的計算在訓練過程的程式碼中,每一輪模型訓練的過程都相同,分如下三步:
- 先根據輸入特徵數據正向計算預測輸出
- 再根據預測值和真實值計算損失(誤差)
- 最後根據損失反向傳播梯度並更新參數
損失函數也有很多種,如均方差,交叉熵等,不同的深度學習任務需要有各自適宜的損失函數,具體可以參考該部落格機器學習-損失函數
訓練配置
優化演算法
優化演算法用來確定參數更新的方式以及快慢,常用的優化演算法有如下四個:
- 隨機梯度下降(SGD):隨機梯度下降演算法,每次訓練少量數據,抽樣偏差導致參數收斂過程中震蕩。
- 動量(Momentum):引入物理「動量」的概念,累積速度,減少震蕩,使參數更新的方向更穩定。
- AdaGrad: 根據不同參數距離最優解的遠近,動態調整學習率。學習率逐漸下降,依據各參數變化大小調整學習率。
- Adam: 由於動量和自適應學習率兩個優化思路是正交的,因此可以將兩個思路結合起來,這就是當前廣泛應用的演算法。
下面是不同學習率優化演算法的示意圖:
設置學習率
學習率代表參數更新幅度的大小,即步長。當學習率最優時,模型的有效容量最大,最終能達到的效果最好。學習率和深度學習任務類型有關,合適的學習率往往需要大量的實驗和調參經驗。探索學習率最優值時需要注意如下兩點:
- 學習率不是越小越好。學習率越小,損失函數的變化速度越慢,意味著我們需要花費更長的時間進行收斂,如 圖2 左圖所示。
- 學習率不是越大越好。只根據總樣本集中的一個批次計算梯度,抽樣誤差會導致計算出的梯度不是全局最優的方向,且存在波動。在接近最優解時,過大的學習率會導致參數在最優解附近震蕩,損失難以收斂,
深度學習其他知識點
模型優化
從上述流程圖可以看出,深度學習模型的可以從數據處理、網路結構、損失函數、優化器和資源配置等五個方面進行模型的整體優化,選擇最合適的就是最好的。
卷積神經網路尺寸的計算
卷積神經網路(CNN)張量(影像)的尺寸和參數計算(深度學習)
參考資料:


