JDK8 String類知識總結
一、概述
java的String類可以說是日常實用的最多的類,但是大多數時候都只是簡單的拼接或者調用API,今天決定深入點了解一下String類。
要第一時間了解一個類,沒有什麼比官方的javaDoc文檔更直觀的了:
String類表示字元串。Java程式中的所有字元串文本(如「abc」)都作為此類的實例實現。
字元串是常量;它們的值在創建後不能更改。字元串緩衝區支援可變字元串。因為字元串對象是不可變的,所以可以共享它們。
類字元串包括用於檢查序列的單個字元、比較字元串、搜索字元串、提取子字元串以及創建字元串副本的方法,其中所有字元都轉換為大寫或小寫。大小寫映射基於Character類指定的Unicode標準版本。
Java語言提供了對字元串連接運算符(+)以及將其他對象轉換為字元串的特殊支援。字元串連接是通過
StringBuilder(或StringBuffer)類及其append方法實現的。字元串轉換是通過toString方法實現的,由Object定義並由Java中的所有類繼承。有關字元串連接和轉換的更多資訊,請參閱Gosling、Joy和Steele,Java語言規範。除非另有說明,否則向此類中的構造函數或方法傳遞null參數將導致引發
NullPointerException。
字元串表示UTF-16格式的字元串,其中補充字元由代理項對表示(有關詳細資訊,請參閱Character類中的Unicode字元表示部分)。索引值引用字元程式碼單位,因此補充字元在字元串中使用兩個位置。除了處理Unicode程式碼單元(即字元值)的方法外,String類還提供了處理Unicode程式碼點(即字元)的方法。
根據文檔,對於String類,我們關注三個問題:
- String對象的不可變性(為什麼是不可變的,這麼設計的必要性)
- String對象的創建方式(兩種創建方式,字元串常量池)
- String對象的拼接(StringBuffer,StringBuilder,加號拼接的本質)
一、String對象的不可變性
1.String為什麼是不可變的
文檔中提到:
字元串是常量;它們的值在創建後不能更改。
對於這段話我們結合源碼來看;
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final char value[];
/** Cache the hash code for the string */
private int hash; // Default to 0
}
我們可以看到,String類字元其實就是char數組對象的二次封裝,存儲變數value[]是被final修飾的,所以一個String對象創建以後是無法被改變值的,這點跟包裝類是一樣的。
我們常見的寫法:
String s = "AAA";
s = "BBB";
實際上創建了兩個String對象,我們使用 = 只是把s指從AAA的記憶體地址指向了BBB的記憶體地址。
我們再看看熟悉的substring()方法:
public String substring(int beginIndex, int endIndex) {
... ...
return ((beginIndex == 0) && (endIndex == value.length)) ? this
: new String(value, beginIndex, subLen);
}
可以看出,在最後也是返回了一個新的String對象,同理,toLowerCase(),trim()等返回字元串的方法也都是在最後返回了一個新對象。
2.String不可變的必要性
String之所以被設計為不可變的,目的是為了效率和安全性:
- 效率:
- String不可變是字元串常量池實現的必要條件,通過常量池可以避免了過多的創建String對象,節省堆空間。
- String的包含了自身的HashCode,不可變保證了對象HashCode的唯一性,避免了反覆計算。
- 安全性:
- String被許多Java類用來當參數,如果字元串可變,那麼會引起各種嚴重錯誤和安全漏洞。
- 再者String作為核心類,很多的內部方法的實現都是本地調用的,即調用作業系統本地API,其和作業系統交流頻繁,假如這個類被繼承重寫的話,難免會是作業系統造成巨大的隱患。
- 最後字元串的不可變性使得同一字元串實例被多個執行緒共享,所以保障了多執行緒的安全性。而且類載入器要用到字元串,不可變性提供了安全性,以便正確的類被載入。
二、字元串常量池
1.作用
文檔中有提到:
因為字元串對象是不可變的,所以可以共享它們
字元串常量池是一塊用於記錄字元串常量的特殊區域(具體可以參考我在關於jvm記憶體結構的文章),JDK8之前字元串常量池在方法區的運行時常量池中,JDK8之後分離到了堆中。「共享」操作就依賴於字元串常量池。
我們知道String是一個對象,而value[]是一個不可變值,所以當我們日常中使用String的時候就會頻繁的創建新的String對象。JVM為了提高性能減少記憶體開銷,在通過類似String S = 「aaa」這樣的操作的時候,JVM會先檢查常量池是否是存在相同的字元串,如果已存在就直接返回字元串實例地址,否則就會先實例一個String對象放到池中,再返回地址。
舉個例子:
String s1 = "aaa";
String s2 = "aaa";
System.out.print(s1 == s2); // true
我們知道「==」比較對象的時候比較的是記憶體地址是否相等,當s1創建的時候,一個「aaa」String對象被創建並放入池中,s1指向的是該對象地址;當第二個s2賦值的時候,JVM從常量池中找到了值為「aaa」的字元串對象,於是跳過了創建過程,直接將s1指向的對象地址也賦給了s2.
2.入池方法intern()
這裡要提一下String對象的手動入池方法 intern()。
這個方法的注釋是這樣的:
最初為空的字元串池由String類私有維護。
調用intern方法時,如果池已經包含等於
equal()方法確定的此String對象的字元串,則返回池中的字元串。否則,將此String對象添加到池中,並返回對此String對象的引用。
舉個例子說明作用:
String s1 = "aabb";
String s2 = new String("aabb");
System.out.println(s1 == s2); //false
System.out.println(s1 == s2.intern()); //true
最開始s1創建了「aabb」對象A,並且加入了字元串常量池,接著s2創建了新的”aabb”對象B,這個對象在堆中並且獨立於常量池,此時s1指向常量池中的A,s2指向常量池外的B,所以==返回是false。
我們使用intern()方法手動入池,字元串常量池中已經有了值等於「aabb」的對象A,於是直接返回了對象A的地址,此時s1和s2指向的都是記憶體中的對象A,所以==返回了true。
三、String對象的創建方式
從上文我們知道String對象的創建和字元串常量池是密切相關的,而創建一個新String對象有兩種方式:
- 使用字面值形式創建。類似
String s = "aaa" - 使用new關鍵字創建。類似
String s = new String("aaa")
1.使用字面值形式創建
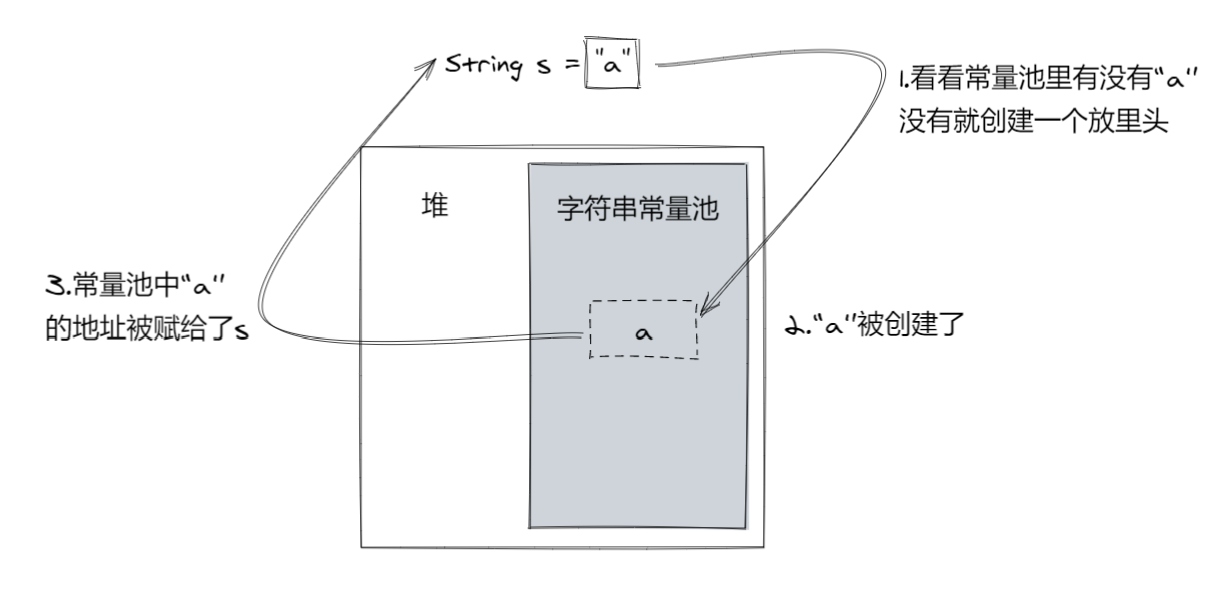
當使用字面值創建String對象的時候,會根據該字元串是否已存在於字元串常量池裡來決定是否創建新的String對象。
當我們使用類似String s = "a"這樣的程式碼創建字元串常量的時候,JVM會先檢查「a」這個字元串是否在常量池中:
-
如果存在,就直接將此String對象地址賦給引用s(引用s是個成員變數,它在虛擬機棧中);
-
如果不存在,就會先在堆中創建一個String對象,然後將對象移入字元串常量池,最後將地址賦給s。
2.使用new關鍵字創建
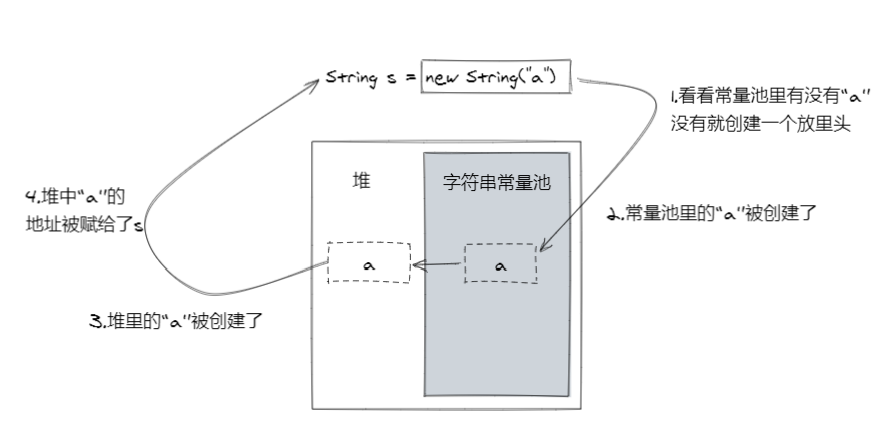
當使用String關鍵字創建String對象的時候,無論字元串常量池中是否有同值對象,都會創建一個新實例。
看看new調用的的構造函數的注釋:
初始化新創建的字元串對象,使其表示與參數相同的字元序列;換句話說,新創建的字元串是參數字元串的副本。除非需要original的顯式副本,否則沒有必要使用此構造函數,因為字元串是不可變的。
當我們使用new關鍵字創建String對象時,和字面值形式創建一樣,JVM會檢查字元串常量池是否存在同值對象:
- 如果存在,則就在堆中創建一個對象,然後返回該堆中對象的地址;
- 否則就先在字元串常量池中創建一個String對象,然後再在堆中創建一個一模一樣的對象,然後返回堆中對象的地址。
也就是說,使用字面值創建後產生的對象只會有一個,但是用new創建對象後產生的對象可能會有兩個(只有堆中一個,或者堆中一個和常量池中一個)。
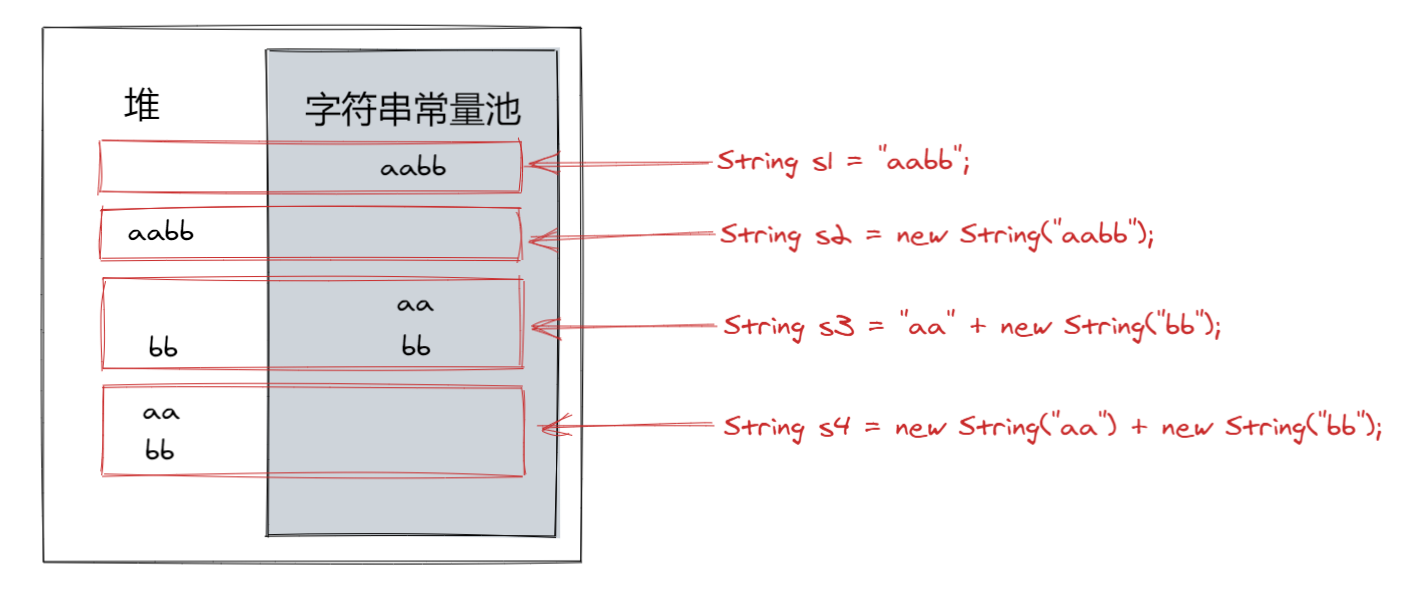
我們舉個例子:
String s1 = "aabb";
String s2 = new String("aabb");
String s3 = "aa" + new String("bb");
String s4 = new String("aa") + new String("bb");
System.out.println(s1 == s2); //false
System.out.println(s1 == s3); //false
System.out.println(s1 == s4); //false
System.out.println(s2 == s3); //false
System.out.println(s2 == s4); //false
System.out.println(s3 == s4); //false
我們可以看到,四個String對象是都是相互獨立的。
實際上,執行完以後對象在記憶體中的情況是這樣的:
3.小結
- 使用new或者字面值形式創建String時都會根據常量池是否存在同值對象而決定是否在常量池中創建對象
- 使用字面值創建的String,引用直接指向常量池中的對象
- 使用new創建的String,還會在堆中常量池外再創建一個對象,引用指向常量池外的對象
四、String的拼接
我們知道,String經常會用拼接操作,而這依賴於StringBuilder類。實際上,字元串類不止有String,還有StringBuilder和StringBuffer。
簡單的來說,StringBuilder和StringBuffer與String的主要區別在於後兩者是可變的字元序列,每次改變都是針對對象本身,而不是像String那樣直接創建新的對象,然後再改變引用。
1.StringBuilder
我們先看看它的javaDoc是怎麼介紹的:
可變的字元序列。
此類提供與StringBuffer兼容的API,但不保證同步。
此類設計為在單執行緒正在使用StringBuilder的地方來代替StringBuffer。在可能的情況下,建議優先使用此類而不是StringBuffer,因為在大多數實現中它會更快。
StringBuilder上的主要操作是
append()和insert()方法,它們會被重載以接受任何類型的數據。每個有效地將給定的基準轉換為字元串,然後將該字元串的字元追加或插入到字元串生成器中。 append方法始終將這些字元添加到生成器的末尾。 insert方法在指定點添加字元。例如:
如果z指向當前內容為「 start」的字元串生成器對象,則方法調用z.append(「 le」)會使字元串生成器包含「 startle」,而z.insert(4,「 le」)將更改字元串生成器以包含「 starlet」。
通常,如果sb引用StringBuilder的實例,則sb.append(x)與sb.insert(sb.length(),x)具有相同的效果。每個字元串生成器都有能力。只要字元串構建器中包含的字元序列的長度不超過容量,就不必分配新的內部緩衝區。如果內部緩衝區溢出,則會自動變大。
StringBuilder實例不能安全地用於多個執行緒。如果需要這樣的同步,則建議使用StringBuffer。除非另有說明,否則將null參數傳遞給此類中的構造函數或方法將導致引發NullPointerException。
我們知道這個類的主要作用在於能夠動態的擴展(append())和改變字元串對象(insert())的值。
我們對比一下String和StringBuilder:
//String
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence{}
//StringBuilder
public final class StringBuilder extends AbstractStringBuilder
implements java.io.Serializable, CharSequence{}
不難看出,兩者的區別在於String實現了Comparable介面而StringBulier繼承了抽象類AbstractStringBuilder。後者的擴展性就來自於AbstractStringBuilder。
AbstractStringBuilder中和String一樣採用一個char數組來保存字元串值,但是這個char數組是未經final修飾,是可變的。
char數組有一個初始大小,跟集合容器類似,當append的字元串長度超過當前char數組容量時,則對char數組進行動態擴展,即重新申請一段更大的記憶體空間,然後將當前char數組拷貝到新的位置;反之就會適當縮容。
一般是新數組長度默認為:(舊數組長度+新增字元長度) * 2 + 2。(不太準確,想要了解更多的同學可以參考AbstractStringBuilder類源碼中的newCapacity()方法)
2.加號拼接與append方法拼接
我們平時一般都直接對String使用加號拼接,實際上這仍然還是依賴於StringBuilder的append()方法。
舉個例子:
String s = "";
for(int i = 0; i < 10; i++) {
s += "a";
}
這寫法實際上編譯以後會變成類似這樣:
String s = "";
for (int i = 0; i < 10; i++) {
s = (new StringBuilder(String.valueOf(s))).append("a").toString();
}
我們可以看見每一次循環都會生成一個新的StringBuilder對象,這樣無疑是很低效的,也是為什麼網上很多文章會說循環中拼接字元串不要使用String而是StringBuilder的原因。因為如果我們自己寫就可以寫成這樣:
StringBuilder s = new StringBuilder();
for (int i = 0; i < 10; i++) {
s.append("a");
}
明顯比編譯器轉換後的寫法要高效。
理解了加號拼接的原理,我們也就知道了為什麼字元串對象使用加號憑藉==返回的是false:
String s1 = "abcd";
String s2 = "ab";
String s3 = "cd";
String s4 = s1 + s2;
String s5 = "ab" + s3;
System.out.println(s1 == s4); //false
System.out.println(s1 == s5); //false
分析一下上面的過程,無論 s1 + s2還是 "ab" + s3實際上都調用了StringBuilder在字元串常量池外創建了一個新的對象,所以==判斷返回了false。
值得一提的是,如果我們遇到了「常量+字面值」的組合,是可以看成單純的字面值:
String s1 = "abcd";
final String s3 = "cd";
String s5 = "ab" + s3;
System.out.println(s1 == s5); //true
總結一下就是:
- 對於「常量+字面值」的組合,可以等價於純字面值創建對象
- 對於包含字元串對象引用的寫法,由於會調用StringBuilder類的toString方法生成新對象,所以等價於new的方式創建對象
3.StringBuffer
同樣看看它的javaDoc,與StringBuilder基本相同的內容我們跳過:
執行緒安全的可變字元序列。StringBuffer類似於字元串,但是可以修改。
對於**。字元串緩衝區可安全用於多個執行緒。這些方法在必要時進行同步,以使任何特定實例上的所有操作都表現為好像以某種串列順序發生,該順序與所涉及的每個單獨執行緒進行的方法調用的順序一致。
… …
請注意,雖然StringBuffer被設計為可以安全地從多個執行緒中並發使用,但是如果將構造函數或append或insert操作傳遞給在執行緒之間共享的源序列,則調用程式碼必須確保該操作具有一致且不變的視圖操作期間源序列的長度。這可以通過調用方在操作調用期間保持鎖定,使用不可變的源序列或不跨執行緒共享源序列來滿足。
… …
從JDK 5版本開始,該類已經添加了一個等效類StringBuilder,該類旨在供單執行緒使用。通常應優先使用StringBuilder類,因為它支援所有相同的操作,但它更快,因為它不執行同步,因此它比所有此類都優先使用。
可以知道,StringBuilder是與JDK5之後添加的StringBuffer是「等效類」,兩個類功能基本一致,唯一的區別在於StringBuffer是執行緒安全的。
我們查看源碼,可以看到StringBuffer實現執行緒安全的方式是為成員方法添加synchronized關鍵字進行修飾,比如append():
public synchronized StringBuffer append(Object obj) {
toStringCache = null;
super.append(String.valueOf(obj));
return this;
}
事實上,StringBuffer幾乎所有的方法都加了synchronized。這也就不難理解為什麼一般情況下StringBuffer效率不如StringBuilder了,因為StringBuffer的所有方法都加了鎖。


