Java進階專題(十一) 想理解JVM看了這篇文章,就知道了!(中)
前言
上次講解了JVM記憶體相關知識,今天繼續JVM專題。
JVM垃圾回收演算法
什麼是垃圾回收
程式的運行必然需要申請記憶體資源,無效的對象資源如果不及時處理就會一直佔有記憶體資源,最終將導致記憶體溢出,所以對記憶體資源的管理是非常重要了。
什麼樣的對象需要回收
引用計數法
引用計數是歷史最悠久的一種演算法,最早George E. Collins在1960的時候首次提出,50年後的今天,該演算法依然被很多程式語言使用。
原理
假設有一個對象A,任何一個對象對A的引用,那麼對象A的引用計數器+1,當引用失效時,對象A的引用計數器
就-1,如果對象A的計數器的值為0,就說明對象A沒有引用了,可以被回收。
優缺點
優點:
實時性較高,無需等到記憶體不夠的時候,才開始回收,運行時根據對象的計數器是否為0,就可以直接回收。
在垃圾回收過程中,應用無需掛起。如果申請記憶體時,記憶體不足,則立刻報outofmember 錯誤。
區域性,更新對象的計數器時,只是影響到該對象,不會掃描全部對象。
缺點:
每次對象被引用時,都需要去更新計數器,有一點時間開銷。
浪費CPU資源,即使記憶體夠用,仍然在運行時進行計數器的統計。
無法解決循環引用問題。(最大的缺點)
class TestA{
public TestB b;
}
class TestB{
public TestA a;
}
//雖然a和b都為null,但是由於a和b存在循環引用,這樣a和b永遠都不會被回收。
public class Main{
public static void main(String[] args){
A a = new A();
B b = new B();
a.b=b;
b.a=a;
a = null; //釋放資源
b = null; //釋放資源
}
}
可達性分析演算法
通過一系列稱為「GC Roots」的根對象作為起始節點集,從這些節點開始,根據引用關係向下搜索,搜索過程所走過的路徑稱為「引用鏈」(Reference Chain),如果某個對象到GC Roots間沒有任何引用鏈相連,就說明從GC Roots到這個對象不可達時,則證明此對象是不可能再被使用的,就是可以回收的對象。
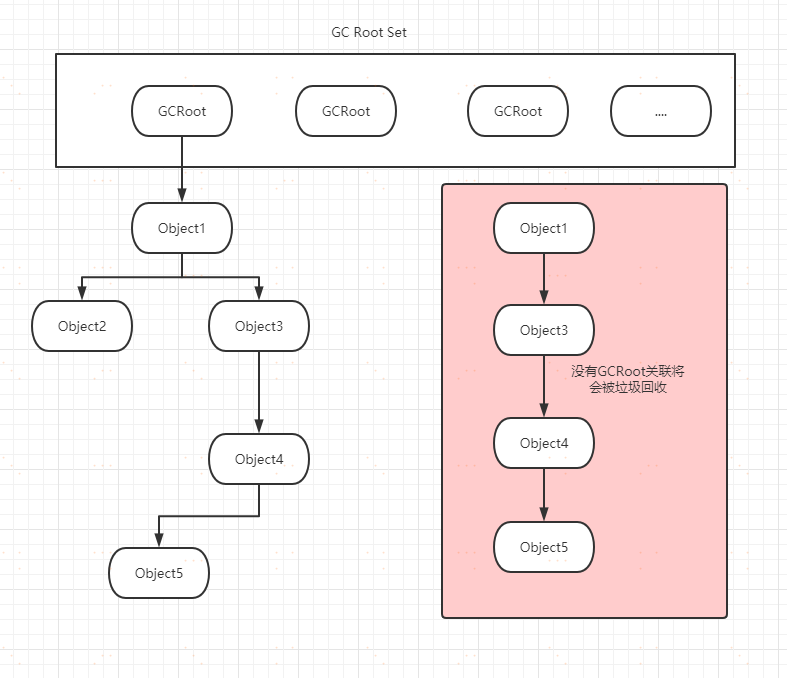
在JVM虛擬機中,可作為GC Roots的對象包括以下幾種:
- 在虛擬機棧(棧幀中的本地變數表)中引用的對象,譬如各個執行緒被調用的方法堆棧中使用到的參數、局部變數、臨時變數等。
- 在方法區中類靜態屬性引用的對象,譬如Java類的引用類型靜態變數。
- 在方法區中常量引用的對象,譬如字元串常量池(String T able)里的引用。
- 在本地方法棧中JNI(即通常所說的Native方法)引用的對象。
- Java虛擬機內部的引用,如基本數據類型對應的Class對象,一些常駐的異常對象(比如NullPointExcepiton、OutOfMemoryError)等,還有系統類載入器。
- 所有被同步鎖(synchronized關鍵字)持有的對象。反映Java虛擬機內部情況的JMXBean、JVMTI中註冊的回調、本地程式碼快取等。
對象的引用
在java中,對象的引用分為:強引用(Strongly Re-ference)、軟引用(Soft Reference)、弱引用(Weak Reference)和虛引用(Phantom Reference)4種。
- 強引用
在程式程式碼之中普遍存在的引用賦值,即類似「Object obj=new Object()」這種引用關係。
無論任何情況下,只要強引用關係還存在,垃圾收集器就永遠不會回收掉被引用的對象。 - 軟引用
用來描述一些還有用,但非必須的對象。
只被軟引用關聯著的對象,在系統將要發生記憶體溢出異常前,會把這些對象列進回收範圍之中進行第二次回收,如果這次回收還沒有足夠的記憶體,才會拋出記憶體溢出異常。 - 弱引用
用來描述那些非必須對象,但是它的強度比軟引用更弱一些,被弱引用關聯的對象只能存活到下一次垃圾收集發生為止。
當垃圾收集器開始工作,無論當前記憶體是否足夠,都會回收掉只被弱引用關聯的對象。 - 虛引用
最弱的一種引用關係,一個對象是否有虛引用的存在,完全不會對其生存時間構成影響,也無法通過虛引用來取得一個對象實例。
為一個對象設置虛引用關聯的唯一目的只是為了能在這個對象被收集器回收時收到一個系統通知。
如何回收垃圾
自動化的管理記憶體資源,垃圾回收機制必須要有一套演算法來進行計算,哪些是有效的對象,哪些是無效的對象,對於無效的對象就要進行回收處理。
常見的垃圾回收演算法有:標記清除法、標記壓縮法、複製演算法、分代演算法等。
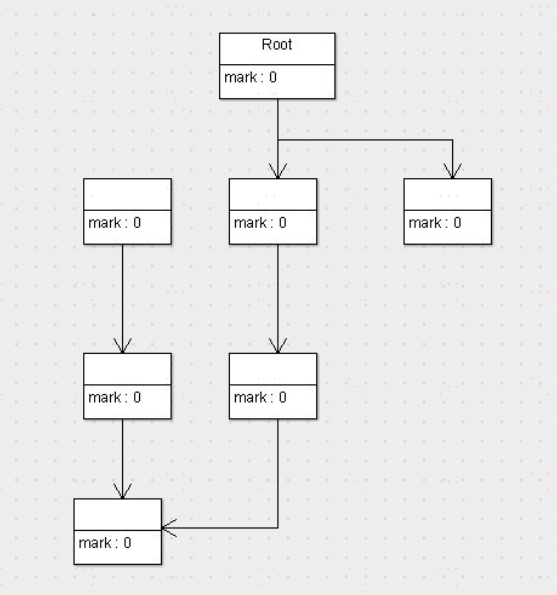
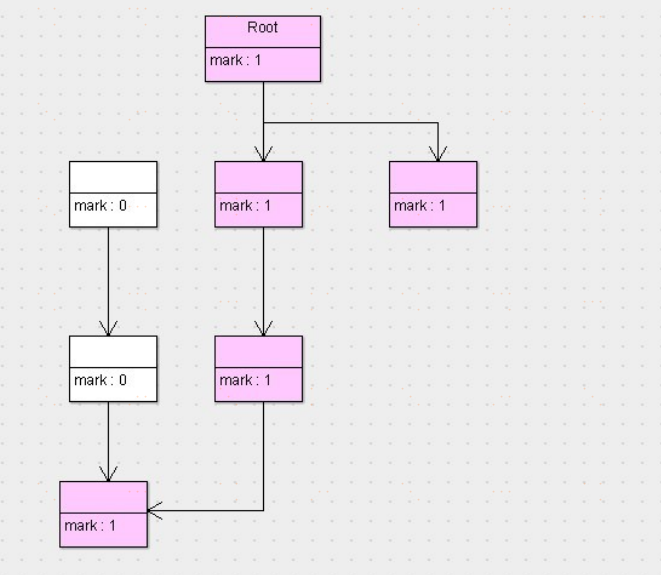
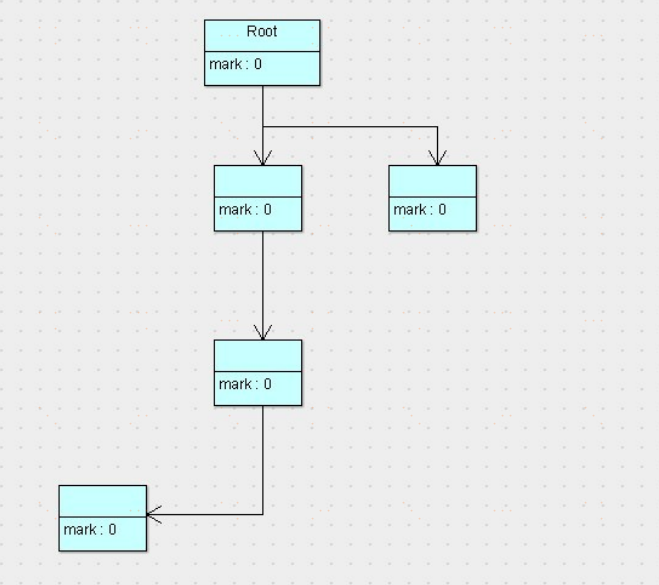
標記清除演算法
標記清除演算法,是將垃圾回收分為2個階段,分別是標記和清除。
標記:從根節點開始標記引用的對象。
清除:未被標記引用的對象就是垃圾對象,可以被清理。
標記清除法可以說是最基礎的收集演算法,因為後續的收集演算法大多都是以標記-清除演算法為基礎,對其缺點進行改進而得到的。
標記前
標記後
回收後
優缺點
可以看到,標記清除演算法解決了引用計數演算法中的循環引用的問題,沒有從root節點引用的對象都會被回收。
同樣,標記清除演算法也是有缺點的:
效率較低,標記和清除兩個動作都需要遍歷所有的對象,並且在GC時,需要停止應用程式,對於交互性要求比較高的應用而言這個體驗是非常差的。
通過標記清除演算法清理出來的記憶體,碎片化較為嚴重,因為被回收的對象可能存在於記憶體的各個角落,所以清理出來的記憶體是不連貫的。
標記壓縮演算法
標記壓縮演算法是在標記清除演算法的基礎之上,做了優化改進的演算法。和標記清除演算法一樣,也是從根節點開始,對對象的引用進行標記,在清理階段,並不是簡單的清理未標記的對象,而是將存活的對象壓縮到記憶體的一端,然後清理邊界以外的垃圾,從而解決了碎片化的問題。
原理

優缺點
優缺點同標記清除演算法,解決了標記清除演算法的碎片化的問題,同時,標記壓縮演算法多了一步,對象移動記憶體位置的步驟,其效率也有有一定的影響。
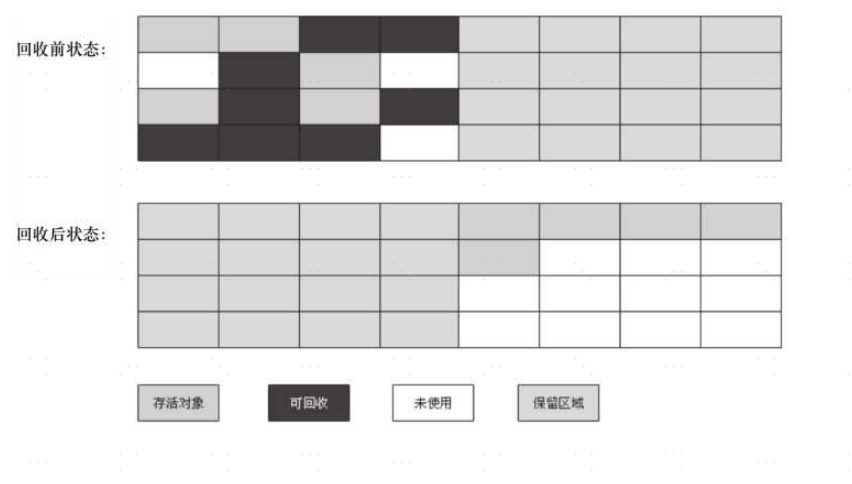
複製演算法
複製演算法的核心就是,將原有的記憶體空間一分為二,每次只用其中的一塊,在垃圾回收時,將正在使用的對象複製
到另一個記憶體空間中,然後將該記憶體空間清空,交換兩個記憶體的角色,完成垃圾的回收。
如果記憶體中的垃圾對象較多,需要複製的對象就較少,這種情況下適合使用該方式並且效率比較高,反之,則不適合。
原理
優缺點
優點:
在垃圾對象多的情況下,效率較高
清理後,記憶體無碎片
缺點:
在垃圾對象少的情況下,不適用,如:老年代記憶體
分配的2塊記憶體空間,在同一個時刻,只能使用一半,記憶體使用率較低
分代演算法
在堆記憶體中,有些對象短暫存活有些則是長久存活,所以需要將堆記憶體進行分代,將短暫存活的對象放到一起,進行高頻率的回收,長久存活的對象集中放到一起,進行低頻率的回收,這樣才能夠更加合理的利系統資源。分代演算法其實就是這樣的,根據回收對象的特點進行選擇,在jvm中,年輕代適合使用複製演算法,老年代適合使用標記清除或標記壓縮演算法。
垃圾回收的相關概念:
部分收集(Partial GC)
新生代收集(Minor GC/Young GC):指目標只是新生代的垃圾收集。
老年代收集(Major GC/Old GC):指目標只是老年代的垃圾收集。
混合收集(Mixed GC):指目標是收集整個新生代以及部分老年代的垃圾收集。
整堆收集(Full GC)
垃圾收集器
前面我們講了垃圾回收的演算法,還需要有具體的實現,在jvm中,實現了多種垃圾收集器,包括:串列垃圾收集
器、並行垃圾收集器、CMS(並發)垃圾收集器、G1垃圾收集器和JDK11中的ZGC(超牛逼)接下來,我們一個個的了解學習。
串列垃圾收集器
串列垃圾收集器,是指使用單執行緒進行垃圾回收,垃圾回收時,只有一個執行緒在工作,並且java應用中的所有執行緒都要暫停,等待垃圾回收的完成。這種現象稱之為STW(Stop-The-World)。
對於交互性較強的應用而言,這種垃圾收集器是不能夠接受的。一般在Javaweb應用中是不會採用該收集器的。
並行垃圾收集器
並行垃圾收集器在串列垃圾收集器的基礎之上做了改進,將單執行緒改為了多執行緒進行垃圾回收,這樣可以縮短垃圾回收的時間。(這裡是指,並行能力較強的機器)
當然了,並行垃圾收集器在收集的過程中也會暫停應用程式,這個和串列垃圾回收器是一樣的,只是並行執行,速度更快些,暫停的時間更短一些。
ParNew垃圾收集器
ParNew垃圾收集器是工作在年輕代上的,只是將串列的垃圾收集器改為了並行。
通過-XX:+UseParNewGC參數設置年輕代使用ParNew回收器,老年代使用的依然是串列收集器。
測試
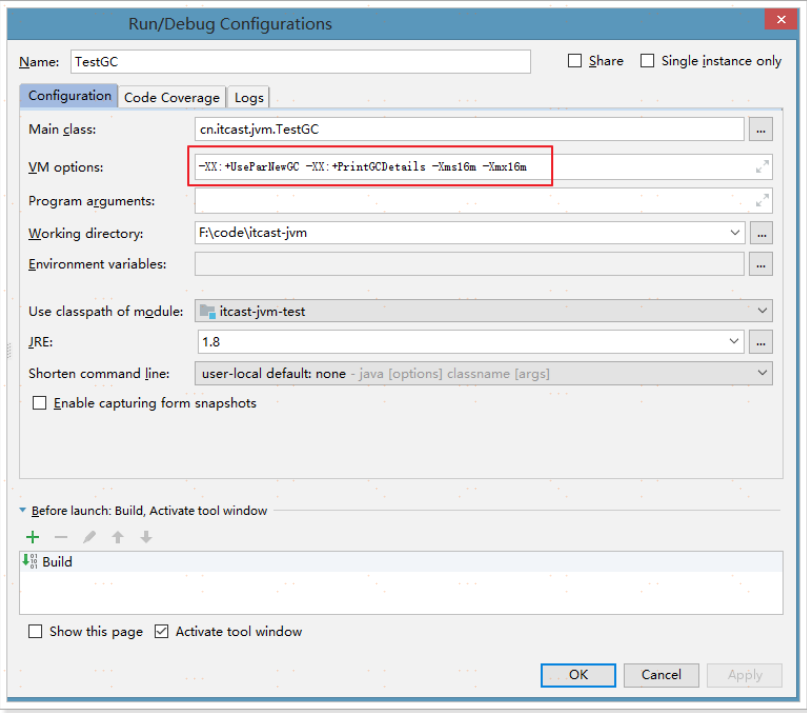
#參數
-XX:+UseParNewGC -XX:+PrintGCDetails -Xms16m -Xmx16m
#列印出的資訊
[GC (Allocation Failure) [ParNew: 4416K->512K(4928K), 0.0032106 secs] 4416K->1988K(15872K), 0.0032697 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
由以上資訊可以看出, ParNew: 使用的是ParNew收集器。其他資訊和串列收集器一致。
ParallelGC垃圾收集器
ParallelGC收集器工作機制和ParNewGC收集器一樣,只是在此基礎之上,新增了兩個和系統吞吐量相關的參數,使得其使用起來更加的靈活和高效。
相關參數如下:
-XX:+UseParallelGC
年輕代使用ParallelGC垃圾回收器,老年代使用串列回收器。
-XX:+UseParallelOldGC
年輕代使用ParallelGC垃圾回收器,老年代使用ParallelOldGC垃圾回收器。
-XX:MaxGCPauseMillis
設置最大的垃圾收集時的停頓時間,單位為毫秒
需要注意的時,ParallelGC為了達到設置的停頓時間,可能會調整堆大小或其他的參數,如果堆的大小
設置的較小,就會導致GC工作變得很頻繁,反而可能會影響到性能。
該參數使用需謹慎。
-XX:GCTimeRatio
設置垃圾回收時間占程式運行時間的百分比,公式為1/(1+n)。
它的值為0~100之間的數字,默認值為99,也就是垃圾回收時間不能超過1%
-XX:UseAdaptiveSizePolicy
自適應GC模式,垃圾回收器將自動調整年輕代、老年代等參數,達到吞吐量、堆大小、停頓時間之間的
平衡。
一般用於,手動調整參數比較困難的場景,讓收集器自動進行調整。
測試:
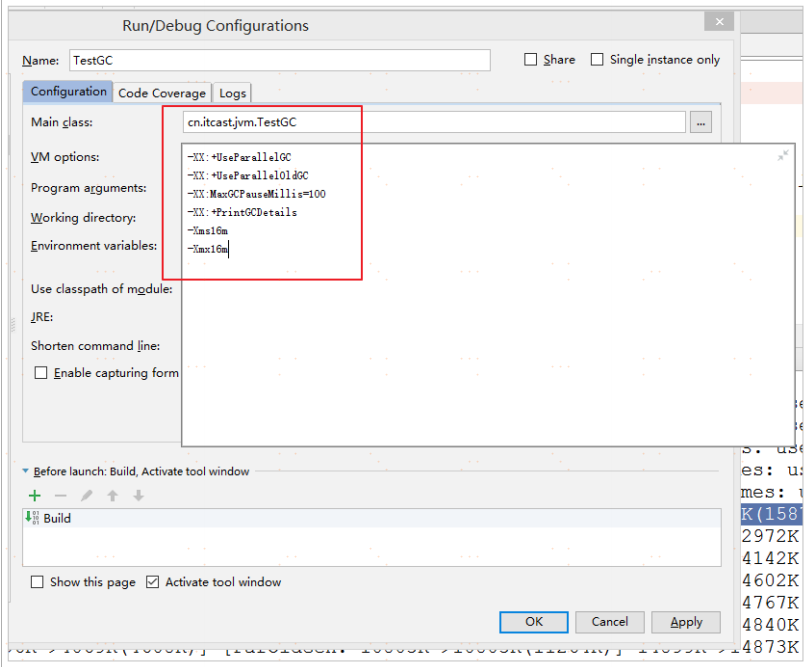
#參數
-XX:+UseParallelGC -XX:+UseParallelOldGC -XX:MaxGCPauseMillis=100 -XX:+PrintGCDetails -Xms16m -Xmx16m
#列印的資訊
[GC (Allocation Failure) [PSYoungGen: 4096K->480K(4608K)] 4096K->1840K(15872K),
0.0034307 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[Full GC (Ergonomics) [PSYoungGen: 505K->0K(4608K)] [ParOldGen: 10332K->10751K(11264K)]
10837K->10751K(15872K), [Metaspace: 3491K->3491K(1056768K)], 0.0793622 secs] [Times:
user=0.13 sys=0.00, real=0.08 secs]
有以上資訊可以看出,年輕代和老年代都使用了ParallelGC垃圾回收器。
CMS垃圾收集器
CMS全稱Concurrent Mark Sweep,是一款並發的、使用標記-清除演算法的垃圾回收器,該回收器是針對老年代垃圾回收的,通過參數-XX:+UseConcMarkSweepGC進行設置
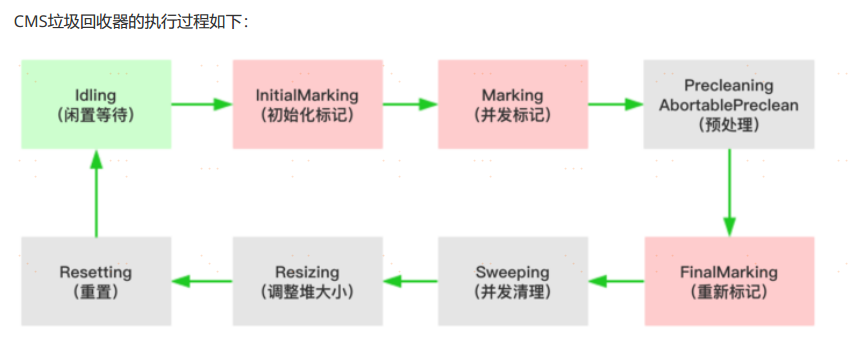
- 初始化標記(CMS-initial-mark) ,標記root,會導致stw;
- 並發標記(CMS-concurrent-mark),與用戶執行緒同時運行;
- 預清理(CMS-concurrent-preclean),與用戶執行緒同時運行;
- 重新標記(CMS-remark) ,會導致stw;
- 並發清除(CMS-concurrent-sweep),與用戶執行緒同時運行;
- 調整堆大小,設置CMS在清理之後進行記憶體壓縮,目的是清理記憶體中的碎片;
- 並發重置狀態等待下次CMS的觸發(CMS-concurrent-reset),與用戶執行緒同時運行;
測試
#設置啟動參數
-XX:+UseConcMarkSweepGC -XX:+PrintGCDetails -Xms16m -Xmx16m
#運行日誌
[GC (Allocation Failure) [ParNew: 4926K->512K(4928K), 0.0041843 secs] 9424K->6736K(15872K), 0.0042168 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
#第一步,初始標記
[GC (CMS Initial Mark) [1 CMS-initial-mark: 6224K(10944K)] 6824K(15872K), 0.0004209
secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
#第二步,並發標記
[CMS-concurrent-mark-start]
[CMS-concurrent-mark: 0.002/0.002 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
#第三步,預處理
[CMS-concurrent-preclean-start]
[CMS-concurrent-preclean: 0.000/0.000 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
#第四步,重新標記
[GC (CMS Final Remark) [YG occupancy: 1657 K (4928 K)][Rescan (parallel) , 0.0005811
secs][weak refs processing, 0.0000136 secs][class unloading, 0.0003671 secs][scrub
symbol table, 0.0006813 secs][scrub string table, 0.0001216 secs][1 CMS-remark:
6224K(10944K)] 7881K(15872K), 0.0018324 secs] [Times: user=0.00 sys=0.00, real=0.00
secs]
#第五步,並發清理
[CMS-concurrent-sweep-start]
[CMS-concurrent-sweep: 0.004/0.004 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
#第六步,重置
[CMS-concurrent-reset-start]
[CMS-concurrent-reset: 0.000/0.000 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
由以上日誌資訊,可以看出CMS執行的過程。
G1垃圾收集器
G1垃圾收集器是在jdk1.7中正式使用的全新的垃圾收集器,oracle官方計劃在jdk9中將G1變成默認的垃圾收集器,
以替代CMS。
G1的設計原則就是簡化JVM性能調優,開發人員只需要簡單的三步即可完成調優:
- 第一步,開啟G1垃圾收集器
- 第二步,設置堆的最大記憶體
- 第三步,設置最大的停頓時間。
G1中提供了三種模式垃圾回收模式,Young GC、Mixed GC 和Full GC,在不同的條件下被觸發。
原理
G1垃圾收集器相對比其他收集器而言,最大的區別在於它取消了年輕代、老年代的物理劃分,取而代之的是將堆劃分為若干個區域(Region),這些區域中包含了有邏輯上的年輕代、老年代區域。
這樣做的好處就是,我們再也不用單獨的空間對每個代進行設置了,不用擔心每個代記憶體是否足夠。
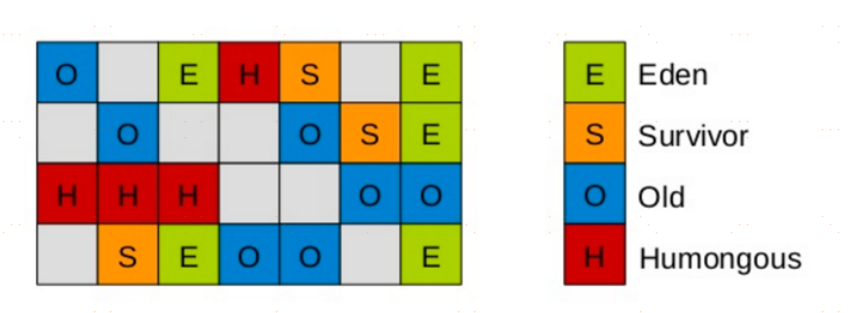
在G1劃分的區域中,年輕代的垃圾收集依然採用暫停所有應用執行緒的方式,將存活對象拷貝到老年代或者Survivor空間,G1收集器通過將對象從一個區域複製到另外一個區域,完成了清理工作。
這就意味著,在正常的處理過程中,G1完成了堆的壓縮(至少是部分堆的壓縮),這樣也就不會有cms記憶體碎片問題的存在了。
在G1中,有一種特殊的區域,叫Humongous區域。
- 如果一個對象佔用的空間超過了分區容量50%以上,G1收集器就認為這是一個巨型對象。
- 這些巨型對象,默認直接會被分配在老年代,但是如果它是一個短期存在的巨型對象,就會對垃圾收集器造成負面影響。
- 為了解決這個問題,G1劃分了一個Humongous區,它用來專門存放巨型對象。如果一個H區裝不下一個巨型對象,那麼G1會尋找連續的H分區來存儲。為了能找到連續的H區,有時候不得不啟動Full GC。
Young GC
Young GC主要是對Eden區進行GC,它在Eden空間耗盡時會被觸發。
Eden空間的數據移動到Survivor空間中,如果Survivor空間不夠,Eden空間的部分數據會直接晉陞到年老代空間。
Survivor區的數據移動到新的Survivor區中,也有部分數據晉陞到老年代空間中。最終Eden空間的數據為空,GC停止工作,應用執行緒繼續執行。
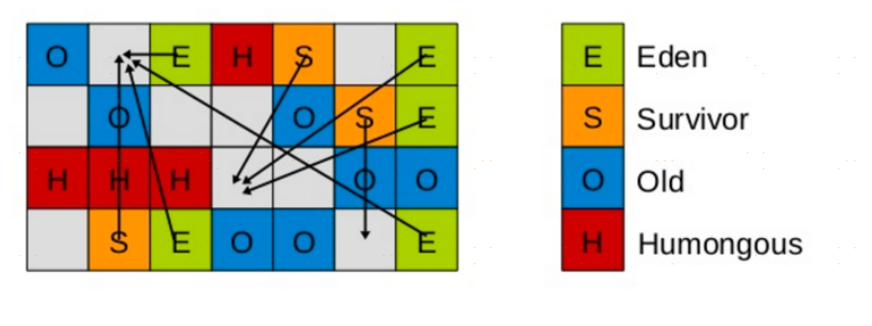
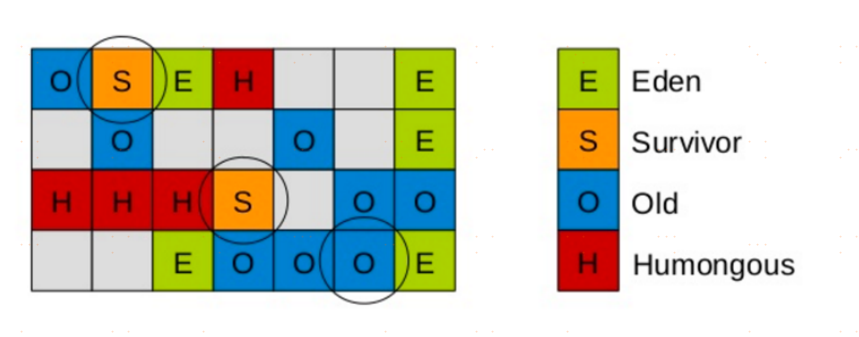
Remembered Set(已記憶集合)
在GC年輕代的對象時,我們如何找到年輕代中對象的根對象呢?
根對象可能是在年輕代中,也可以在老年代中,那麼老年代中的所有對象都是根么?
如果全量掃描老年代,那麼這樣掃描下來會耗費大量的時間。
於是,G1引進了RSet的概念。它的全稱是Remembered Set,其作用是跟蹤指向某個堆內的對象引用。

每個Region初始化時,會初始化一個RSet,該集合用來記錄並跟蹤其它Region指向該Region中對象的引用,每個Region默認按照512Kb劃分成多個Card,所以RSet需要記錄的東西應該是xx Region的xx Card。
Mixed GC
當越來越多的對象晉陞到老年代old region時,為了避免堆記憶體被耗盡,虛擬機會觸發一個混合的垃圾收集器,即Mixed GC,該演算法並不是一個Old GC,除了回收整個Young Region,還會回收一部分的Old Region,這裡需要注意:是一部分老年代,而不是全部老年代,可以選擇哪些old region進行收集,從而可以對垃圾回收的耗時時間進行控制。也要注意的是Mixed GC 並不是Full GC。
MixedGC什麼時候觸發? 由參數-XX:InitiatingHeapOccupancyPercent=n 決定。默認:45%,該參數的意思是:當老年代大小占整個堆大小百分比達到該閥值時觸發。
它的GC步驟分2步:
- 全局並發標記(global concurrent marking)
- 拷貝存活對象(evacuation)
全局並發標記
全局並發標記,執行過程分為五個步驟:
初始標記(initial mark,STW)
標記從根節點直接可達的對象,這個階段會執行一次年輕代GC,會產生全局停頓。
根區域掃描(root region scan)
G1 GC 在初始標記的存活區掃描對老年代的引用,並標記被引用的對象。
該階段與應用程式(非STW)同時運行,並且只有完成該階段後,才能開始下一次STW 年輕代垃圾回收。
並發標記(Concurrent Marking)
G1 GC 在整個堆中查找可訪問的(存活的)對象。該階段與應用程式同時運行,可以被STW 年輕代垃圾回收中斷。
重新標記(Remark,STW)
該階段是STW 回收,因為程式在運行,針對上一次的標記進行修正。
清除垃圾(Cleanup,STW)
清點和重置標記狀態,該階段會STW,這個階段並不會實際上去做垃圾的收集,等待evacuation階段來回收。
拷貝存活對象
Evacuation階段是全暫停的。該階段把一部分Region里的活對象拷貝到另一部分Region中,從而實現垃圾的回收清理。
G1收集器相關參數
- -XX:+UseG1GC
使用G1 垃圾收集器 - -XX:MaxGCPauseMillis
設置期望達到的最大GC停頓時間指標(會儘力實現,但不保證達到),默認值是200 毫秒。 - -XX:G1HeapRegionSize=n
設置的G1 區域的大小。值是2 的冪,範圍是1 MB 到32 MB 之間。目標是根據最小的Java 堆大小劃分出約2048 個區域。默認是堆記憶體的1/2000。 - -XX:ParallelGCThreads=n
設置STW 工作執行緒數的值。將n 的值設置為邏輯處理器的數量。n 的值與邏輯處理器的數量相同,最多為8。 - -XX:ConcGCThreads=n
設置並行標記的執行緒數。將n 設置為並行垃圾回收執行緒數(ParallelGCThreads) 的1/4 左右。 - -XX:InitiatingHeapOccupancyPercent=n
設置觸發Mixed GC 的Java 堆佔用率閾值。默認佔用率是整個Java 堆的45%
測試
-XX:+UseG1GC -XX:MaxGCPauseMillis=100 -XX:+PrintGCDetails -Xmx256m
#日誌
[GC pause (G1 Evacuation Pause) (young), 0.0044882 secs]
[Parallel Time: 3.7 ms, GC Workers: 3]
[GC Worker Start (ms): Min: 14763.7, Avg: 14763.8, Max: 14763.8, Diff: 0.1]
#掃描根節點
[Ext Root Scanning (ms): Min: 0.2, Avg: 0.3, Max: 0.3, Diff: 0.1, Sum: 0.8]
#更新RS區域所消耗的時間
[Update RS (ms): Min: 1.8, Avg: 1.9, Max: 1.9, Diff: 0.2, Sum: 5.6]
[Processed Buffers: Min: 1, Avg: 1.7, Max: 3, Diff: 2, Sum: 5]
[Scan RS (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[Code Root Scanning (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
#對象拷貝
[Object Copy (ms): Min: 1.1, Avg: 1.2, Max: 1.3, Diff: 0.2, Sum: 3.6]
[Termination (ms): Min: 0.0, Avg: 0.1, Max: 0.2, Diff: 0.2, Sum: 0.2]
[Termination Attempts: Min: 1, Avg: 1.0, Max: 1, Diff: 0, Sum: 3]
[GC Worker Other (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[GC Worker Total (ms): Min: 3.4, Avg: 3.4, Max: 3.5, Diff: 0.1, Sum: 10.3]
[GC Worker End (ms): Min: 14767.2, Avg: 14767.2, Max: 14767.3, Diff: 0.1]
[Code Root Fixup: 0.0 ms]
[Code Root Purge: 0.0 ms]
[Clear CT: 0.0 ms] #清空CardTable
[Other: 0.7 ms]
[Choose CSet: 0.0 ms] #選取CSet
[Ref Proc: 0.5 ms] #弱引用、軟引用的處理耗時
[Ref Enq: 0.0 ms] #弱引用、軟引用的入隊耗時
[Redirty Cards: 0.0 ms]
[Humongous Register: 0.0 ms] #大對象區域註冊耗時
[Humongous Reclaim: 0.0 ms] #大對象區域回收耗時
[Free CSet: 0.0 ms]
[Eden: 7168.0K(7168.0K)->0.0B(13.0M) Survivors: 2048.0K->2048.0K Heap:
55.5M(192.0M)->48.5M(192.0M)] #年輕代的大小統計
[Times: user=0.00 sys=0.00, real=0.00 secs]
對於G1垃圾收集器優化建議
- 年輕代大小
避免使用-Xmn 選項或-XX:NewRatio 等其他相關選項顯式設置年輕代大小。固定年輕代的大小會覆蓋暫停時間目標。 - 暫停時間目標不要太過嚴苛
G1 GC 的吞吐量目標是90% 的應用程式時間和10%的垃圾回收時間。評估G1 GC 的吞吐量時,暫停時間目標不要太嚴苛。目標太過嚴苛表示您願意承受更多的垃圾回收開銷,而這會直接影響到吞吐量。
ZGC
ZGC是一款在JDK 11中新加入的具有實驗性質的低延遲垃圾收集器,是由Oracle公司研發的。ZGC的目標是希望在儘可能對吞吐量影響不太大的前提下,實現在任意堆記憶體大小下都可以把垃圾收集的停頓時間限制在10毫秒以內的低延遲。
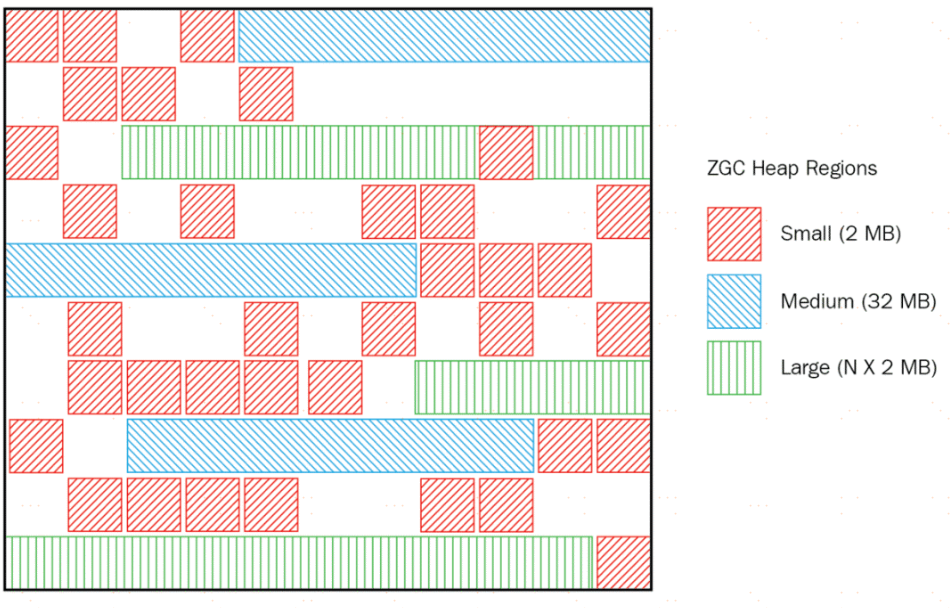
記憶體布局
ZGC的記憶體布局與G1一樣,也採用基於Region的堆記憶體布局,但不同的是,ZGC的Page(ZGC中稱之為頁面,道理和Region一樣)具有動態性——動態創建和銷毀,以及動態的區域容量大小。在x64硬體平台下,ZGC的Pag可以具有大、中、小三類容量:
-
小型頁面(Small Page):容量固定為2MB,用於放置小於256KB的小對象。
-
中型頁面(Medium Page):容量固定為32MB,用於放置大於等於256KB但小於4MB的對象。
-
大型頁面(Large Page):容量不固定,可以動態變化,但必須為2MB的整數倍,用於放置4MB或以上的大對象。
每個大頁面中只會存放一個大對象,這也預示著雖然名字叫作「大型Page」,但它的實際容量完全有可能小於中型Page,最小容量可低至4MB。
大型Page在ZGC的實現中是不會被重分配(重分配是ZGC的一種處理動作)的,因為複製一個大對象的代價非常高昂。
性能表現
在性能方面,儘管目前還處於實驗狀態,還沒有完成所有特性,穩定性打磨和性能調優也仍在進行,但即使是這種狀態下的ZGC,其性能表現已經相當亮眼,從官方給出的測試結果來看,用「令人震驚的、革命性的ZGC」來形容都不為過。
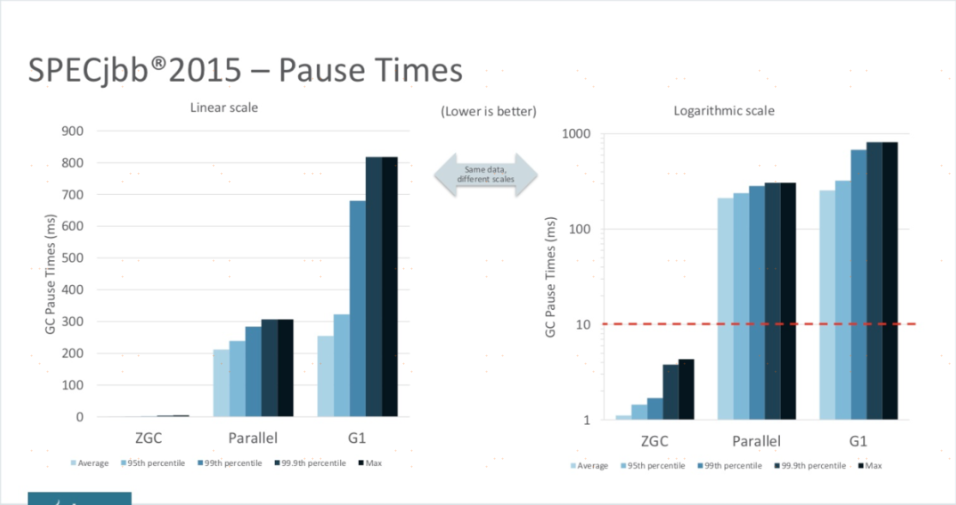
ZGC與Parallel Scavenge、G1三款收集器通過SPECjbb 2015(java伺服器業務測試工具)的測試結果。在ZGC的「弱項」吞吐量方面,以低延遲為首要目標的ZGC已經達到了以高吞吐量為目標Parallel Scavenge的99%,直接超越了G1。如果將吞吐量測試設定為面向SLA(Service Level Agreements)應用的「Critical Throughput」 (要求最大延遲不超過某個設置值(10毫秒到100毫秒)下測得的吞吐量)的話,ZGC的表現甚至還反超ParallelScavenge收集器。
ZGC的強項停頓時間測試上,它就毫不留情地與Parallel Scavenge、G1拉開了兩個數量級的差距。不論是平均停頓,還是95%停頓、99%停頓、99.9%停頓,抑或是最大停頓時間,ZGC均能毫不費勁地控制在十毫秒之內,以至於把它和另外兩款停頓數百近千毫秒的收集器放到一起對比,就幾乎顯示不了ZGC的柱狀條(圖a),必須把結果的縱坐標從線性尺度調整成對數尺度(圖b,縱坐標軸的尺度是對數增長的)才能觀察到ZGC的測試結果。
使用
在jdk11下,只能在linux 64位的平台上使用ZGC,如果想要在Windows下使用ZGC就需要升級jdk到14了。
cd /usr/local/src/
#上傳jdk-11.0.7_linux-x64_bin.tar.gz
tar -xvf jdk-11.0.7_linux-x64_bin.tar.gz
#如果本身已經安裝openjdk的話,先刪除
java –version
rpm -qa | grep java
rpm -e --nodeps java-xxxx-openjdk-xxxx.x86_64
vim /etc/profile
#寫入如下內容
#set java environment
JAVA_HOME=/usr/local/src/jdk-11.0.7
CLASSPATH=.:$JAVA_HOME/lib.tools.jar
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME CLASSPATH PATH
#生效
source /etc/profile
#執行命令
java -XX:+UnlockExperimentalVMOptions -XX:+UseZGC -Xmx256m -Xlog:gc*=info TestGC
#參數說明
-XX:+UnlockExperimentalVMOptions 解鎖實驗參數
-XX:+UseZGC 啟用ZGC垃圾收集器
-Xmx256m 設置最大記憶體
-Xlog:gc*=info 設置列印gc日誌資訊
#設置並行的執行緒數,一般默認即可
-XX:ConcGCThreads
#執行日誌
[1.141s][info][gc,start ] GC(2) Garbage Collection (Warmup)
[1.141s][info][gc,phases ] GC(2) Pause Mark Start 0.190ms
[1.143s][info][gc,phases ] GC(2) Concurrent Mark 1.837ms
[1.143s][info][gc,phases ] GC(2) Pause Mark End 0.136ms
[1.144s][info][gc,phases ] GC(2) Concurrent Process Non-Strong References 0.308ms
[1.144s][info][gc,phases ] GC(2) Concurrent Reset Relocation Set 0.001ms
[1.144s][info][gc,phases ] GC(2) Concurrent Destroy Detached Pages 0.000ms
[1.145s][info][gc,phases ] GC(2) Concurrent Select Relocation Set 1.219ms
[1.145s][info][gc,phases ] GC(2) Concurrent Prepare Relocation Set 0.009ms
[1.145s][info][gc,phases ] GC(2) Pause Relocate Start 0.230ms
[1.146s][info][gc,phases ] GC(2) Concurrent Relocate 0.853ms
[1.146s][info][gc,load ] GC(2) Load: 0.00/0.02/0.05
[1.146s][info][gc,mmu ] GC(2) MMU: 2ms/78.1%, 5ms/88.9%, 10ms/93.4%, 20ms/96.7%,
50ms/98.7%, 100ms/99.0%
[1.146s][info][gc,marking ] GC(2) Mark: 1 stripe(s), 1 proactive flush(es), 1
terminate flush(es), 0 completion(s), 0 continuation(s)
[1.146s][info][gc,reloc ] GC(2) Relocation: Successful, 1M relocated
[1.146s][info][gc,nmethod ] GC(2) NMethods: 59 registered, 0 unregistered
[1.146s][info][gc,metaspace] GC(2) Metaspace: 4M used, 4M capacity, 5M committed, 8M
reserved
[1.146s][info][gc,ref ] GC(2) Soft: 131 encountered, 0 discovered, 0 enqueued
[1.146s][info][gc,ref ] GC(2) Weak: 222 encountered, 215 discovered, 0 enqueued
[1.146s][info][gc,ref ] GC(2) Final: 0 encountered, 0 discovered, 0 enqueued
[1.146s][info][gc,ref ] GC(2) Phantom: 1 encountered, 1 discovered, 0 enqueued
[1.146s][info][gc,heap ] GC(2) Mark Start Mark End
Relocate Start Relocate End High Low
[1.146s][info][gc,heap ] GC(2) Capacity: 114M (45%) 114M (45%)
114M (45%) 114M (45%) 114M (45%) 114M (45%)
[1.146s][info][gc,heap ] GC(2) Reserve: 36M (14%) 36M (14%)
36M (14%) 36M (14%) 36M (14%) 36M (14%)
[1.146s][info][gc,heap ] GC(2) Free: 142M (55%) 142M (55%)
184M (72%) 184M (72%) 184M (72%) 142M (55%)
[1.146s][info][gc,heap ] GC(2) Used: 78M (30%) 78M (30%)
36M (14%) 36M (14%) 78M (30%) 36M (14%)
[1.146s][info][gc,heap ] GC(2) Live: - 1M (1%)
1M (1%) 1M (1%) - -[1.146s][info][gc,heap ] GC(2) Allocated: - 0M (0%)
0M (0%) 4M (2%) - -[1.146s][info][gc,heap ] GC(2) Garbage: - 76M (30%)
34M (14%) 34M (14%) - -[1.146s][info][gc,heap ] GC(2) Reclaimed: - -
42M (16%) 42M (16%) - -[1.146s][info][gc ] GC(2) Garbage Collection (Warmup) 78M(30%)->36M(14%)
染色指針技術
ZGC為了實現目標,新增了染色指針技術。
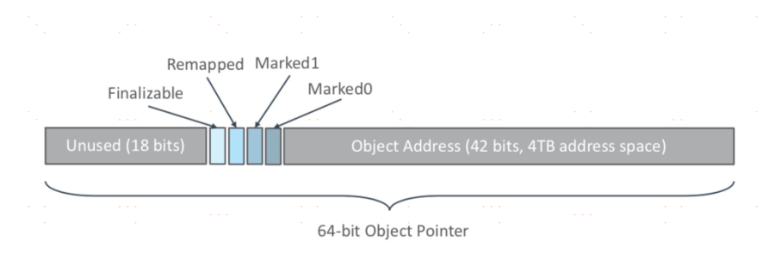
染色指針是一種直接將少量額外的資訊存儲在指針上的技術,在64位系統中,理論可以訪問的記憶體高達16EB(2的64次冪)位元組。實際上,64位的Linux則分別支援47位(128TB)的進程虛擬地址空間和46位(64TB)的物理地址空間,64位的Windows系統甚至只支援44位(16TB)的物理地址空間。
Linux下64位指針的高18位不能用來定址,但剩餘的46位指針所能支援的64TB記憶體在今天仍然能夠充分滿足大型伺服器的需要。
ZGC的染色指針技術使用上了這剩下的46位指針寬度,將其高4位提取出來存儲四個標誌資訊。通過這些標誌位,虛擬機可以直接從指針中看到其引用對象的三色標記狀態、是否進入了重分配集(即被移動過)、是否只能通過finalize()方法才能被訪問到。
由於這些標誌位進一步壓縮了原本就只有46位的地址空間,也直接導致ZGC能夠管理的記憶體不可以超過4TB(2的42次冪)。
染色指針的好處
- 染色指針可以使得一旦某個Region的存活對象被移走之後,這個Region立即就能夠被釋放和重用掉,而不必等待整個堆中所有指向該Region的引用都被修正後才能清理。
- 染色指針可以大幅減少在垃圾收集過程中記憶體屏障的使用數量。
一般寫屏障的目的通常是為了記錄對象引用的變動情況,如果將這些資訊直接維護在指針中,顯然就可以省去一些專門的記錄操作。
ZGC都並未使用任何寫屏障,只使用了讀屏障。
染色指針可以作為一種可擴展的存儲結構用來記錄更多與對象標記、重定位過程相關的數據,以便日後進一步提高性能。
工作過程
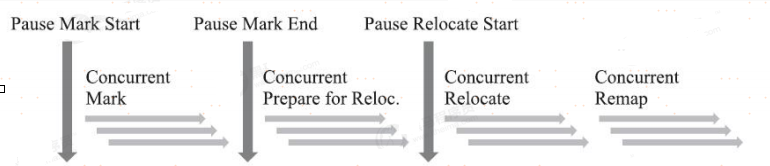
ZGC的運作過程大致可劃分為四個大的階段,這四個階段都是可以並發執行的。僅在Mark Start、Initial Mark 階段中會存在短暫的STW。
-
並發標記(Concurrent Mark)
與G1一樣,並發標記是遍歷對象圖做可達性分析的階段,前後也要經過初始標記、最終標記的短暫停頓。ZGC的標記是在指針上而不是在對象上進行的,標記階段會更新染色指針中的Marked 0、Marked 1標誌位。
-
並發預備重分配(Concurrent Prepare for Relocate)
這個階段需要根據特定的查詢條件統計得出本次收集過程要清理哪些Region,將這些Region組成重分配集(Relocation Set)。
ZGC每次回收都會掃描所有的Region,用範圍更大的掃描成本換取省去G1中記憶集的維護成本。
ZGC的重分配集只是決定了裡面的存活對象會被重新複製到其他的Region中,裡面的Region會被釋放。 -
並發重分配(Concurrent Relocate)
重分配是ZGC執行過程中的核心階段,這個過程要把重分配集中的存活對象複製到新的Region上,並為重分配集中的每個Region維護一個轉發表(Forward T able),記錄從舊對象到新對象的轉向關係。
由於使用了染色指針的支援,ZGC收集器能僅從引用上就明確得知一個對象是否處於重分配集之中,如果用戶執行緒此時並發訪問了位於重分配集中的對象,這次訪問將會被預置的記憶體屏障所截獲,然後立即根據Region上的轉發表記錄將訪問轉發到新複製的對象上,並同時修正更新該引用的值,使其直接指向新對象,ZGC將這種行為稱為指針的「自愈」(Self-Healing)能力。 -
並發重映射(Concurrent Remap)
重映射所做的就是修正整個堆中指向重分配集中舊對象的所有引用。
並發重映射並不是一個必須要「迫切」去完成的任務,但是當所有指針都被修正之後,原來記錄新舊對象關係的轉發表就可以釋放掉了。


