java架構之路-(Redis專題)Redis的高性能和持久化
- 2019 年 10 月 21 日
- 筆記
上次我們簡單的說了一下我們的redis的安裝和使用,這次我們來說說redis為什麼那麼快和持久化數據
在我們現有的redis中(5.0.*之前的版本),Redis都是單執行緒的,那麼單執行緒的Redis為什麼還會有那麼高的效率呢?因為它所有的數據都在記憶體中,所有的運算都是記憶體級別的運算,而且單執行緒避免了多執行緒的切換中性能損耗的問題,正因為Redis是單執行緒,所以我們要小心使用Redis指令,對於那些耗時的指令(比如keys),我們一定要謹慎使用。
在並發環境中,我們Redis的單執行緒並不是執行緒1請求了,而我們的執行緒2就無法繼續請求了,而他的內部是採用了IO多路復用,redis利用epoli來實現IO多路復用,將連接資訊和事件放在隊列中,依次放到事件分派器,事件分派器將事件分發給我們的事件處理器來執行指令操作。
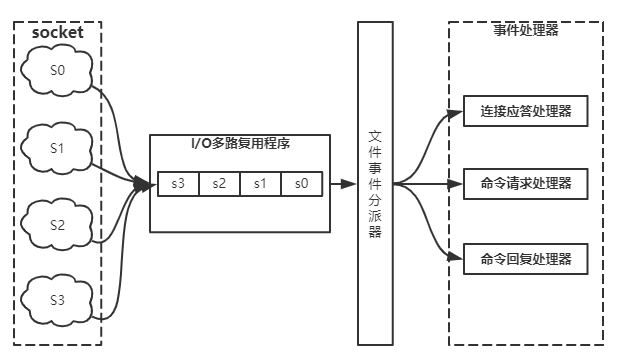
redis默認支援最大連接數是10000,我們通過設置我們的redis.conf來指定我們的最大連接數,# maxclients 10000 => maxclients 100,大致在539行,或者我們輸入/maxclients 可以快速查找到我們需要改的配置,進入我們的客戶端,輸入$ CONFIG GET maxclients,即可查看我們的客戶端最大連接數。
127.0.0.1:6379> CONFIG GET maxclients 1) "maxclients" 2) "100"
高級命令
我們輸入keys *,既可以返回我們的全部鍵的數據,一般不推薦使用,如果數據量過大,會相當消耗性能的。
scan,scan提供了三個參數,第一個是cursor整數值,第二個是key的正則模式。第三個是第一次遍歷的key的數量,並不是符合條件的結果的數量,第一次遍歷時,cursor值為0,然後我們將返回結果中第一個整數作為下一次遍歷的cursor。一直遍歷到cursor值為0時結束。
127.0.0.1:6379> scan 0 match key* count 5 1) "6" 2) 1) "key6" 2) "key4" 3) "key1" 127.0.0.1:6379> scan 6 match key* count 5 1) "0" 2) 1) "key5" 2) "key2" 3) "key3"
Info:查看redis服務運行資訊,分為 9 大塊,每個塊都有非常多的參數,這 9 個塊分別是:
Server 伺服器運行的環境參數
Clients 客戶端相關資訊
Memory 伺服器運行記憶體統計數據
Persistence 持久化資訊
Stats 通用統計數據
Replication 主從複製相關資訊
CPU CPU 使用情況
Cluster 集群資訊
KeySpace 鍵值對統計數量資訊
日誌
redis.conf文件配置logfile來配置我們的log日誌資訊。大概在137行。
logfile "logForRedis.log"
Redis持久化
持久化主要分為三種,RDB,AOF和混合模式(4.0.*以後的模式)。
RDB快照模式
在默認情況下,Redis將記憶體資料庫快照保存為*.rdb的二進位文件。我用的是5.0.5版本,默認是開啟我們的RDB快照模式的,大致在253行,我們看到dbfilename dump.rdb,就是我們要以dump.rdb的文件來存儲,存儲位置在263行的dir ./ 也就是我們的當前路徑(這裡可以設置絕對路徑)。
我們在大概218行可以看到三個save,也就是我們RDB的保存策略
save 900 1 //表示在900秒內,發生了一次變動,我們就生成一次快照,變動只是數據的變動,get並不算變動
save 300 10 //表示在300秒內,發生了十次變動,我們就生成一次快照
save 60 10000 //表示在60秒內,發生了一萬次變動,我們就生成一次快照
三者條件滿足其一就保存一次,他們之間是一個或者的關係,如果三個條件都未滿足,這時宕機可能造成數據的丟失。
我們還可以通過進入redis-cli客戶端以後,我們手動輸入save或者bgsave來生成我們的dump.rdb文件。我們的redis服務端配置是採用bgsave的方式來保存的。我們來看一下save和bgsave的比較。
| 命令 | save | bgsave |
| IO類型 | 同步 | 非同步 |
| 是否阻塞redis其它命令 | 是 | 否(在生成子進程執行調用fork函數時會有超級短暫的阻塞) |
| 時間複雜度 | O(n) | O(n) |
| 優點 | 不會消耗額外記憶體 | 不阻塞客戶端命令 |
| 缺點 | 阻塞客戶端命令 | 需要fork子進程,消耗記憶體 |
AOF命令模式
我們為什麼成為AOF叫做命令模式呢?我們的AOF其實是保存了我們每一個操作的動作,也就是我們每一個Redis指令,我們只需要設置appendonly yes即可,大概在699行。下面的appendfilename是我們需要保存aof的文件名,rdb中提到的dir對應的也是aof文件的保存路徑。這樣的持久化,其實也不是每次都要向磁碟寫入數據的,他有三個選項供我們來修改。
appendfsync always:每次有新命令追加到 AOF 文件時就執行一次 fsync ,非常慢,也非常安全。
appendfsync everysec:每秒 fsync 一次,足夠快(和使用 RDB 持久化差不多),並且在故障時只會丟失 1 秒鐘的數據。
appendfsync no:從不 fsync ,將數據交給作業系統來處理。更快,也更不安全的選擇。
大概在728-730行設置這三種策略,默認的每秒一次,也是推薦使用的,三種策略只能選擇其中一種生效。一組set testkey testvalue命令大概這樣的
| *3 | 表示佔了幾個位置,*3表示佔了三個位置,也就是*** *** *** 樣式的命令 |
| $3 | 表示下面命令佔位的長度 |
| set | 就是我們實際的命令 |
| $7 | 表示下一個命令佔位的長度 |
| testkey | 就是我們實際的命令 |
| $9 | 表示下一個命令佔位的長度 |
| testvalue | 就是我們實際的命令 |
我們假象一下輸入了一百次incr article:xiaocai命令,我們現在要使用AOF來恢復我們的文件,那麼指令incr article:xiaocai就要存儲100次,恢復100次,貌似效率不高啊。這裡就提到了我們的AOF文件重寫。也就是把一些指令重新組合生成新的指令,但保證數據的準確性。我們來看一下,我們先經歷三次set命令,key值是一樣的,我很容易知道,這裡set了三次,但前兩次並沒有什麼卵用,最後一次將我們的值已經覆蓋掉了。
127.0.0.1:6379> set xiaocai 123 OK 127.0.0.1:6379> set xiaocai 456 OK 127.0.0.1:6379> set xiaocai 666 OK 127.0.0.1:6379> BGREWRITEAOF Background append only file rewriting started 127.0.0.1:6379>
這時應該生產三條AOF指令,我們來執行我們的AOF重寫命令$ BGREWRITEAOF,重寫之後,前面的set就不見了,相同鍵的set,只保留最後一次的set。可能造成亂碼(我們5.0.5默認開啟了混合模式,後面會說),但是確實壓縮了,恢復也是可以成功的。我們來看一下我該掉默認配置後的AOF重寫文件。
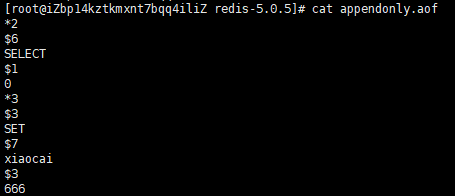
我們可以看到我們前兩條指令被優化去掉了,這也就是我們的AOF重寫。
auto-aof-rewrite-min-size 64mb //表示當我們的aof文件達到64M時,我們就重寫一次,建議使用默認配置就可以,太多了,重寫耗時長,太小了,經常重寫,消耗性能。
auto-aof-rewrite-percentage 100 這個表示。//當我們的配置增加了100%我們就重寫一次
說到這,兩種持久化的方式就都說完了,我們來看一下誰才是王者,誰才是最優質的。
| 命令 | RDB | AOF |
| 啟動優先順序 | 低 | 高 |
| 體積 | 小 | 大 |
| 恢復速度 | 快 | 慢 |
| 數據安全性 | 容易丟失數據 | 根據策略決定 |
注意:當我們同時開啟RDB和AOF時,當我們重啟redis時,Redis會優先去載入AOF文件來恢復我們的數據,相對來說AOF的數據更完整
混合模式
重啟redis時,我們很少使用RDB來恢復記憶體數據,因為會丟失大量的數據。通常我們使用AOF指令來恢復,但AOF的性能相比RDB要慢很多,看到這我們還是覺得並沒有一種完美的解決方案,來持久化我們的數據,這時Redis4.0就引出了我們混合持久化。我們可以通過設置 # aof-use-rdb-preamble yes來開啟我們的混合持久化,這時我們生成的持久化文件內部還是AOF的,但我們重寫的時候,會將這些AOF的指令重寫為二進位文件。這樣我們就綜合了RDB和AOF的優勢,在恢複數據的時候大部分是執行二進位文件的,小部分來執行我們的AOF指令操作,使我們的恢複數據的效率更高,在備份的時候是以AOF來備份的,也保證了數據的安全性。
總結
這次我們主要說了我們的Redis的記憶體高性能,Redis在記憶體來計算的,再就是我們的高級設置keys *(少用或者別用)和我們的scan命令,再就是Redis的持久化,兩種RDB和AOF,RDB持久化可能數據丟失,但是二進位文件恢復的快,AOF持久化幾乎不會丟數據,但是是指令的模式,恢複數據效率低。由於都有缺點我們引入了混合模式,保存用AOF來存,恢復用RDB+AOF來恢復。再就是一個重點是save和bgsave的區別。記住bgsave是後台執行的,需要fork子進程,消耗記憶體,但是不阻塞Redis的其它執行緒。
今天就說這麼多,下次博文我們說說我們的主從模式,哨兵模式和我們的Redis集群。


最進弄了一個公眾號,小菜技術,歡迎大家的加入

