Spring Data R2DBC響應式操作MySQL
- 2020 年 7 月 29 日
- 筆記

1. 前言
在使用R2DBC操作MySQL資料庫 一文中初步介紹了r2dbc-mysql的使用。由於藉助DatabaseClient操作MySQL,過於初級和底層,不利於開發。今天就利用Spring Data R2DBC來演示Spring 數據存儲抽象(Spring Data Repository)風格的R2DBC資料庫操作。
請注意:目前Spring Data R2DBC雖然已經迭代了多個正式版,但是仍然處於初級階段,還不足以運用到生產中。不過未來可期,值得研究學習。
2. Spring Data R2DBC
Spring Data R2DBC提供了基於R2DBC反應式關係資料庫驅動程式的流行的Repository抽象。但是這並不是一個ORM框架,你可以把它看做一個資料庫訪問的抽象層或者R2DBC的客戶端程式。它不提供ORM框架具有的快取、懶載入等諸多特性,但它抽象了資料庫和對象的抽象映射關係,具有輕量級、易用性的特點。
2.1 版本對應關係
胖哥總結了截至目前Spring Data R2DBC和Spring Framework的版本對應關係:
| Spring Data R2DBC | Spring Framework |
|---|---|
| 1.0.0.RELEASE | 5.2.2.RELEASE |
| 1.1.0.RELEASE | 5.2.6.RELEASE |
| 1.1.1.RELEASE | 5.2.7.RELEASE |
| 1.1.2.RELEASE | 5.2.8.RELEASE |
一定要注意版本對應關係,避免不兼容的情況。
3. 基礎依賴
上次我沒有引用R2DBC連接池,這次我將嘗試使用它。主要依賴如下 ,這裡我還集成了Spring Webflux:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-r2dbc</artifactId>
</dependency>
<!-- r2dbc 連接池 -->
<dependency>
<groupId>io.r2dbc</groupId>
<artifactId>r2dbc-pool</artifactId>
</dependency>
<!--r2dbc mysql 庫-->
<dependency>
<groupId>dev.miku</groupId>
<artifactId>r2dbc-mysql</artifactId>
</dependency>
<!--自動配置需要引入的一個嵌入式資料庫類型對象-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jdbc</artifactId>
</dependency>
<!-- 反應式web框架 webflux-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>
這裡我採用的是 Spring Boot 2.3.2.RELEASE。
4. 配置
上次我們採用的是JavaConfig風格的配置,只需要向Spring IoC注入一個ConnectionFactory。這一次我將嘗試在application.yaml中配置R2DBC的必要參數。
spring:
r2dbc:
url: r2dbcs:mysql://127.0.0.1:3306/r2dbc
username: root
password: 123456
以上就是R2DBC的主要配置。特別注意的是spring.r2dbc.url的格式,根據資料庫的不同寫法是不同的,要看驅動的定義,這一點非常重要。連接池這裡使用默認配置即可,不用顯式定義。
5. 編寫業務程式碼
接下來就是編寫業務程式碼了。這裡我還嘗試使用DatabaseClient來執行了DDL語句創建了client_user表,感覺還不錯。
@Autowired
DatabaseClient databaseClient;
@Test
void doDDL() {
List<String> ddl = Collections.unmodifiableList(Arrays.asList("drop table if exists client_user;", "create table client_user(user_id varchar(64) not null primary key,nick_name varchar(32),phone_number varchar(16),gender tinyint default 0) charset = utf8mb4;"));
ddl.forEach(sql -> databaseClient.execute(sql)
.fetch()
.rowsUpdated()
.as(StepVerifier::create)
.expectNextCount(1)
.verifyComplete());
}
5.1 聲明資料庫實體
熟悉Spring Data JPA的同學應該很輕車熟路了。
/**
* the client user type
*
* @author felord.cn
*/
@Data
@Table
public class ClientUser implements Serializable {
private static final long serialVersionUID = -558043294043707772L;
@Id
private String userId;
private String nickName;
private String phoneNumber;
private Integer gender;
}
5.2 聲明CRUD介面
上面實體類中的@Table註解是有說法的,當我們的操作介面繼承的是ReactiveCrudRepository<T, ID> 或者ReactiveSortingRepository<T, ID>時,需要在實體類上使用@Table註解,這也是推薦的用法。
public interface ReactiveClientUserSortingRepository extends ReactiveSortingRepository<ClientUser,String> {
}
當然實體類不使用@Table註解標記時,我們還可以繼承R2dbcRepository<T, ID>介面。然後ReactiveClientUserSortingRepository將提供一些操作資料庫的方法。
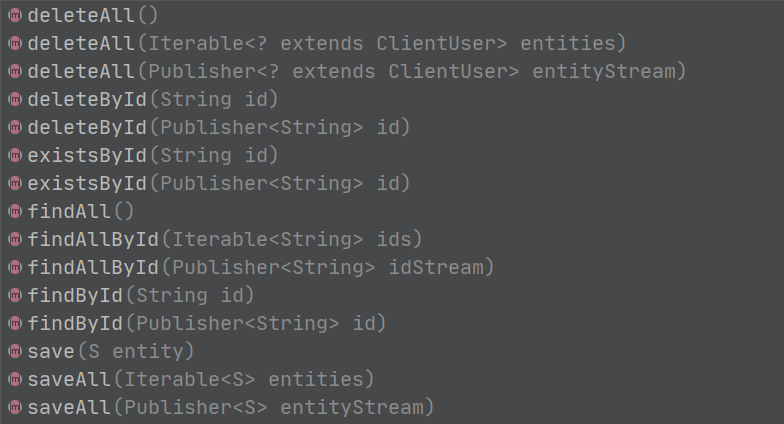
然後Spring Data JPA怎麼寫,這裡也差不多怎麼寫,但是有些功能現在還沒有得到支援,比如上面提到的分頁,還有主鍵策略等。
類似
PagingAndSortingRepository<T,ID>的反應式分頁功能介面目前還沒有實裝,會在未來的版本集成進來。
5.3 實際操作
接下來我們就要通過R2DBC實際操作MySQL資料庫了。按照我們傳統的邏輯寫了如下的新增邏輯:
ClientUser clientUser = new ClientUser();
clientUser.setGender(2);
clientUser.setNickName("r2dbc");
clientUser.setPhoneNumber("9527");
clientUser.setUserId("snowflake");
Mono<ClientUser> save = reactiveClientUserSortingRepository.save(clientUser);
結果資料庫並沒有寫入數據。這時因為r2dbc-mysql不能被直接使用,只能由客戶端去實現並委託給客戶端去操作。
這也是R2DBC的設計原則,R2DBC的目標是最小化SPI平面,目的是消除資料庫之間的差異部分,並使得整個資料庫完全具有反應式和背壓。它主要用作客戶端庫使用的驅動程式SPI,而不打算直接在應用程式程式碼中使用。
所以這裡我們可以藉助於reactor-test測試庫去執行一下,改寫為:
reactiveClientUserSortingRepository.save(clientUser)
.log()
.as(StepVerifier::create)
.expectNextCount(1)
.verifyComplete();
但是依然不能執行成功,提示update table [client_user]. Row with Id [snowflake] does not exist ,也就是說期望執行的是新增但是實際執行的是更新,由於資料庫找不到主鍵為snowflake的記錄就報了錯。這裡為什麼是更新呢?
這時因為實體類在進行新增時會判斷主鍵是否填充,如果沒有填充就認為是新數據,採取真正的新增操作,主鍵需要資料庫來自動填充;如果主鍵存在值則認為是舊數據則調用更新操作。胖哥同Spring Data R2DBC的項目組溝通後並沒有得到友好的解決方案,不過我已經找到了方法,這裡先留個坑。
那麼該如何新增一條數據呢?我們只能藉助於@Query註解來編寫一條SQL寫入了:
@Modifying
@Query("insert into client_user (user_id,nick_name,phone_number,gender) values (:userId,:nickName,:phoneNumber,:gender)")
Mono<Integer> addClientUser(String userId, String nickName, String phoneNumber, Integer gender);
當添加了@Modifying後,返回值可以從Mono<ClientUser>、Mono<Boolean>或者Mono<Integer>任意一種選擇。
reactiveClientUserSortingRepository
.addClientUser("snowflake",
"r2dbc",
"132****155",
0)
.as(StepVerifier::create)
.expectNextCount(1)
.verifyComplete();

這樣就證明寫成功了一條數據。
5.4 搭配Webflux使用
但是實際中該如何應用呢?目前能夠想到的就是結合反應式框架Spring Webflux了,就像Spring Data JPA配合Spring MVC一樣。
我們編寫一個Webflux介面:
@RestController
@RequestMapping("/user")
public class ReactiveClientUserController {
@Autowired
private ReactiveClientUserSortingRepository reactiveClientUserSortingRepository;
/**
* 這裡為了檢驗默認api 就不分層了
*
* @param userId the user id
* @return the mono
*/
@GetMapping("/{userId}")
public Mono<ClientUser> findUserById(@PathVariable String userId) {
return reactiveClientUserSortingRepository.findById(userId);
}
}
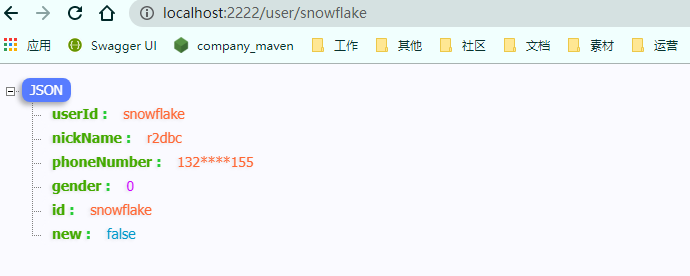
5.5 一些測試數據參考
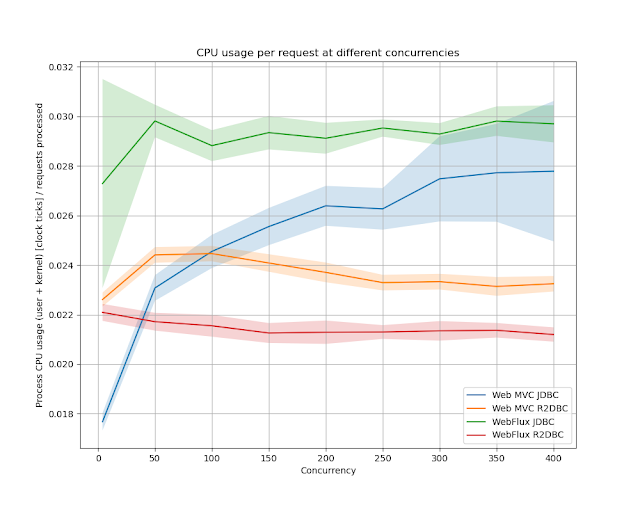
在低並發時,Spring MVC + JDBC表現最佳,但在高並發下,WebFlux + R2DBC使用每個已處理請求的記憶體最少。
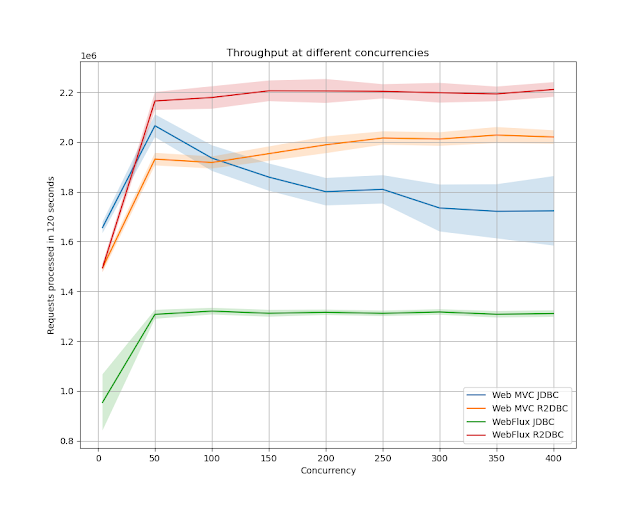
在高並發下,Spring MVC + JDBC的響應時間開始下降。顯然,R2DBC在更高的並發性下提供了更好的響應時間。Spring WebFlux也比使用Spring MVC的類似實現更好。
6. 總結
今天對Spring Data R2DBC進一步演示,相信你能夠從中學到一些東西。由於R2DBC還是比較新,還存在一些需要改進和補充的東西。目前社區非常活躍,發展十分迅速。好了今天的文章就到這裡,原創不易多多關註:碼農小胖哥 如果你覺得本文很有用,請點贊、轉發、再看。
關注公眾號:Felordcn 獲取更多資訊


