【Python3爬蟲】我爬取了七萬條彈幕,看看RNG和SKT打得怎麼樣
- 2019 年 10 月 20 日
- 筆記
一、寫在前面
直播行業已經火熱幾年了,幾個大平台也有了各自獨特的“彈幕文化”,不過現在很多平台直播比賽時的彈幕都基本沒法看的,主要是因為網路上的噴子還是挺多的,尤其是在觀看比賽的時候,很多彈幕不是噴選手就是噴戰隊,如果看了這種彈幕,真是讓比賽減分不少。

但和別的平台比起來,B 站的彈幕會好一些。正好現在是英雄聯盟的世界總決賽時間,也有不少人選擇在 B 站看比賽直播,那麼大家在看直播的時候會發什麼彈幕呢?話不多說,這就用 Python 寫個爬蟲來爬取 B 站直播時的彈幕吧!
二、爬取分析
首先打開 Bilibili,然後找到英雄聯盟比賽的直播間:

我得到的直播間的鏈接為:https://live.bilibili.com/6?broadcast_type=0&visit_id=8abcmywu95s0#/,這個鏈接中的 broadcast_type 和 visit_id 是隨機生成的,不過對我們的爬取也沒影響,只要找到直播間的鏈接就好了。
打開開發者工具,切換到 NetWork,點選上 XHR,在其中能找到一個請求:https://api.live.bilibili.com/ajax/msg。這個請求需要四個參數(roomid,csrf_token,csrf,visit_id),其中 roomid 為直播間的 id,csrf_token 和 csrf 可以從瀏覽器上 copy,visit_id 為空。該請求返回的結果中包含十條彈幕資訊,包括彈幕內容、彈幕發送人昵稱等等。所以要獲得更多彈幕內容,我們只需要一直發送這個請求就 OK 了!
三、爬取實現
通過前面的分析可以發現要爬取 B 站直播彈幕還是很輕鬆的,但是要得到大量彈幕可能就需要考慮使用多執行緒了。對於爬取到的彈幕,還要及時地保存下來,這裡我選擇使用 MongoDB 資料庫來保存彈幕資訊。在爬取直播彈幕的時候,我開了四個執行緒來爬取,開了兩個執行緒來解析和保存數據,執行緒之間使用隊列來處理數據。
這裡建了兩個類 CrawlThread 和 ParseThread,CrawThread 是用於爬取彈幕的執行緒,ParseThread 是用於解析和保存彈幕的執行緒,兩個類都繼承了 threading.Thread,並重寫了 run() 方法。下面是爬取彈幕的程式碼內容:
1 class CrawlThread(threading.Thread): 2 def __init__(self, url: str, name: str, data_queue: Queue): 3 """ 4 initial function 5 :param url: room url 6 :param name: thread name 7 :param data_queue: data queue 8 """ 9 super(CrawlThread, self).__init__() 10 self.room_url = url 11 self.room_id = re.findall(r"/(d+)?", url)[0] 12 self.headers = { 13 "Accept": "application/json, text/plain, */*", 14 "Content-Type": "application/x-www-form-urlencoded", 15 "Origin": "https://live.bilibili.com", 16 "Referer": "", 17 "Sec-Fetch-Mode": "cors", 18 "UserAgent": get_random_ua() 19 } 20 self.name = name 21 self.data_queue = data_queue 22 23 def run(self): 24 """ 25 send request and receive response 26 :return: 27 """ 28 while 1: 29 try: 30 time.sleep(1) 31 msg_url = "https://api.live.bilibili.com/ajax/msg" 32 # set referer 33 self.headers["Referer"] = self.room_url 34 # set data 35 data = { 36 "roomid": self.room_id, 37 "csrf_token": "e7433feb8e629e50c8c316aa52e78cb2", 38 "csrf": "e7433feb8e629e50c8c316aa52e78cb2", 39 "visit_id": "" 40 } 41 res = requests.post(msg_url, headers=self.headers, data=data) 42 self.data_queue.put(res.json()["data"]["room"]) 43 except Exception as e: 44 logging.error(self.name, e)
下面是解析和保存彈幕的程式碼內容,主要是一直查詢隊列,如果隊列中有數據,就取出來進行解析和保存:
1 class ParseThread(threading.Thread): 2 def __init__(self, url: str, name: str, data_queue: Queue): 3 """ 4 initial function 5 :param url: room url 6 :param name: thread name 7 :param data_queue: data queue 8 """ 9 super(ParseThread, self).__init__() 10 self.name = name 11 self.data_queue = data_queue 12 self.room_id = re.findall(r"/(d+)?", url)[0] 13 client = pymongo.MongoClient(host=MONGO_HOST, port=MONGO_PORT) 14 self.col = client[MONGO_DB][MONGO_COL + self.room_id] 15 16 def run(self): 17 """ 18 get data from queue 19 :return: 20 """ 21 while 1: 22 comments = self.data_queue.get() 23 logging.info("Comment count: {}".format(len(comments))) 24 self.parse(comments) 25 26 def parse(self, comments): 27 """ 28 parse comment to get message 29 :return: 30 """ 31 for x in comments: 32 comment = { 33 "text": x["text"], 34 "time": x["timeline"], 35 "username": x["nickname"], 36 "user_id": x["uid"] 37 } 38 # print(comment) 39 self.save_msg(comment) 40 41 def save_msg(self, msg: dict): 42 """ 43 save comment to MongoDB 44 :param msg: comment 45 :return: 46 """ 47 try: 48 self.col.insert_one(msg) 49 except Exception as e: 50 logging.info(msg) 51 logging.error(e)
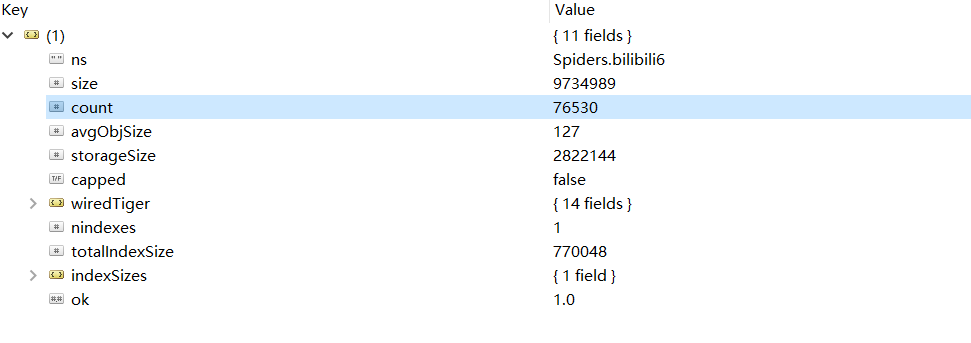
從比賽開始到比賽結束,總共爬取到了76530條彈幕,在 Robot 3T 中截圖如下:
四、生成詞雲
彈幕資訊已經存好了,但是考慮到其中有很多表情等無用內容,所以需要將這些內容給清洗掉。清洗結束之後就能夠進行分詞操作了,這裡我選擇用 jieba 庫來處理,在使用 jieba 的時候,可以設置用戶詞典,因為像選手 ID,英雄名稱這些內容是會被分詞的,但設置用戶詞典之後就不會被分詞了,設置方法如下:
jieba.load_userdict(“userdict.txt”)
userdict.txt 中保存了選手 ID,選手外號,英雄名稱等內容,在設置了用戶詞典後,這些內容在分詞的時候都不會被分開了。在分詞結束之後,需要將那些長度為1的部分清除掉,然後將出現頻次高的內容提取出來,這裡用到了 collecttions 中的 Counter,利用 Counter 可以很方便地統計頻次。這一部分程式碼內容如下:
1 def get_words(txt: str) -> str: 2 """ 3 use jieba to cut words 4 :param txt: input text 5 :return: 6 """ 7 # cut words 8 seg_list = jieba.cut(txt) 9 c = Counter() 10 # count words 11 for x in seg_list: 12 if len(x) > 1 and x != 'rn': 13 c[x] += 1 14 result = "" 15 for (k, v) in c.most_common(300): 16 # print('%s %d' % (k, v)) 17 result += "n" + k 18 return result
在進行完上述操作之後,就可以使用 wordcloud 這個庫來生成詞雲了,生成詞雲時可以設置停止詞和字體,這一部分的程式碼如下:
1 def generate_word_cloud(text): 2 """ 3 generate word cloud 4 :param text: text 5 :return: 6 """ 7 # text cleaning 8 with open("stopwords.txt", "r", encoding='utf-8') as f: 9 stopwords = set(f.read().split("n")) 10 wc = WordCloud( 11 font_path="font.ttf", 12 background_color="white", 13 width=1200, 14 height=800, 15 max_words=100, 16 max_font_size=200, 17 min_font_size=10, 18 stopwords=stopwords, # 設置停用詞 19 ) 20 # generate word cloud 21 wc.generate("".join(text)) 22 # save as an image 23 wc.to_file("rng_vs_skt.png")
最終生成的詞雲圖為:

可以看到很多人都在討論 faker 的,李哥還是李哥啊,李哥的瑞茲也是強的不行,也有不少彈幕在說天使和加里奧的問題,不得不說,小虎小明的發揮是有問題的,此外還有一些說噴子的,看來 B 站的噴子也不少啊。
完整程式碼已上傳到 GitHub!