打破國外壟斷,開發中國人自己的程式語言(1):先弄一個可以解析表達式的計算器玩玩
筆記 JAVA , 原創 , 程式語言 , 編譯器
閱讀本系列文章將是「最殘酷的頭腦風暴,大家做好準備了嗎 」
本文是《打破國外壟斷,開發中國人自己的程式語言 》系列文章的第1篇。本系列文章的主要目的是教大家學會如何從零開始設計一種程式語言(marvel語言),並使用marvel語言開發一些真實的項目,如移動App、Web應用等。marvel語言可以通過下面3種方式運行:
1. 解釋執行
2. 編譯成Java Bytecode,利用JVM執行
3. 編譯成二進位文件,本地執行(基於LLVM)
本系列文章實現的marvel語言並不像很多《自己動手》系列一樣,做一個玩具。marvel語言是一個工業級的程式語言,與kotlin、Java等語言是同一個級別,設計之初是為了試驗程式語言的新特性。我們團隊開發的超平台開發系統UnityMarvel內嵌的Ori語言的部分特性也是來源於Marvel。關於UnityMarvel的細節後面會專門寫文章介紹。這裡先討論編譯器的問題。
1. 如果系統軟體受到制約,有沒有可能突出重圍呢?
我們知道,現在中美貿易戰如火如荼,可能以後使用國外很多軟體,尤其是系統軟體,都會有一些問題。這就需要我們在一些關鍵領域有自己可以控制的技術和軟體,例如,作業系統、程式語言、資料庫、科學計算軟體等。其實這些種類的軟體中,大多都屬於基礎軟體,只有作業系統和程式語言(以及相關的IDE)可以稱為是系統軟體。
這裡先說說基礎軟體和系統軟體的區別。基礎軟體是指很多軟體都依賴的軟體,例如,流行的程式庫(如tensorflow、pytorch等)、資料庫(如MySQL、Oracle等)。但大多數基礎軟體的一個共同特點是只服務於特定領域,例如,你不可能用MySQL開發一款遊戲,也不可能用tensorflow開發移動App。而在基礎軟體中有一小類,它們是通用的,幾乎適合於各個領域,我們將這類軟體稱為系統軟體。它們是整個IT領域的基礎架構。沒有它們,整個IT領域將不復存在。例如,目前,只有作業系統和編譯器符合這兩個特徵。大家可以想想,沒有了關係型資料庫,還有其他類型的資料庫可以使用,沒有了tensorflow,IT領域也不會停止運轉。但沒有了Windows、macOS、Linux、C語言、Java語言這些技術,世界將會怎樣,將會重新退回到工業文明時代。 所以系統軟體是基礎軟體的一個子集,而且必不可少。如果將基礎軟體和其他軟體比作星球,那麼系統軟體就是星核。
在系統軟體中,編譯器是最容易突破的。因為編譯器(程式語言)的生態相比作業系統來說,更容易建立。這是因為目前有很多虛擬機可以選擇,例如,最常用的是JVM,當然,還有微軟的.net core等技術。 如果我們的程式語言可以基於JVM,那麼就意味著可以利用Java語言的所有生態,如果我們的程式語言可以用更容易的方式調用其他語言(如C++、Go等),在某種程度上,也就可以直接使用這些程式語言的生態。當然,還有更先進的超生態技術(UnityMarvel的Ori語言正是基於超生態技術的),總之,作為一種新的程式語言,利用其他的生態是最廉價的方式,當然,在語言發展的過程中,也可以逐漸建立自己的生態(相當於騎驢找馬),這也是一種策略。所以如果想突破,編譯器(程式語言)是最容易的一個。當然,如果擁有自己可以控制的程式語言,可以為後期的作業系統提供支援,例如,利用超生態技術,在建立新作業系統之前,就為該作業系統提前建立生態(這一點以後專門撰文闡述)。
2. 開發程式語言需要哪些知識
現在進入到最關鍵的部分了,開發一種程式語言到底需要哪些知識呢?其實需要的知識還是蠻多的。最基礎的要求是必須至少會一種程式語言。如C、C++、Java、C#、Go、Python等。當然,推薦會3種以上的程式語言,因為我們是在設計程式語言,不是在設計普通的軟體。在設計程式語言時,需要進行橫向比較,也就是需要參考其他的程式語言,因為任何新技術都不可能100%完全憑空產生,這些新技術都會或多或少地留下其他同類技術的影子,程式語言也不例外。例如,UnityMarvel內嵌的Ori語言就是參考了數十種程式語言,以及加入了自己的新技術而最終形成的。
除了要了解大量的程式語言外,還有很多與業務有關的知識需要掌握。主要的知識結構(不僅僅這些,後面用到了再詳細講)如下:
(1)了解大量的程式語言(推薦3種以上)
(2)編譯原理的基礎知識
(3)演算法能力
(4)編譯器前端生成器
(5)學習能力
(6)想像力
儘管開發程式語言並不會像大學學的編譯原理一樣從0開始構造一個編譯器,但編譯原理的基礎知識還是要掌握的,不了解編譯原理的同學,趕緊上B站、西瓜影片、YouTube去補課,後期我也會結合marvel語言做相關的影片課程,大家可以關注哦!
演算法就不必說了,編譯器裡面充斥著各種演算法,編譯器的演算法密度幾乎超過了絕大多數應用。任何形式的演算法都可能涉及到,最基礎的數據結構必須掌握,其他的演算法,能學多少就學多少,多多益善。這個沒有固定的教程,也是需要不斷在實踐中學習。
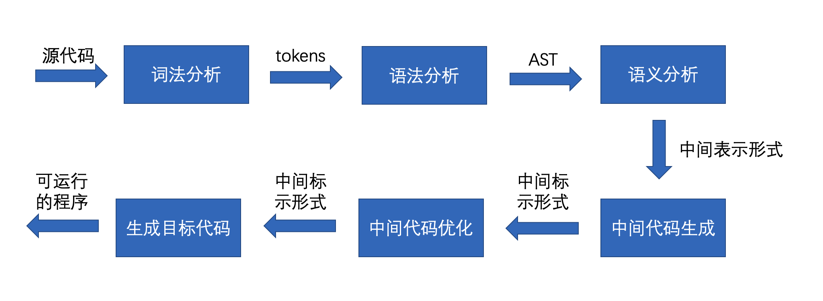
開發編譯器的基本步驟如下圖所示。
首先說明一點,並不是所有的編譯器都嚴格按照這些步驟進行,有可能會將多個步驟合成一個步驟(例如,語法分析和語義分析合成一步,最後輸出AST),也有可能將一步分成多個步驟,或者再增加一些與業務相關的步驟。
對於工業級編譯器來說,並不會從0開始實現詞法和語法分析器,並不是這東西有多難,而是如果完全手工編寫程式碼,要添加或修改一個新語法,那簡直就是一場噩夢,因為要修改非常多的地方,而且一旦出錯,非常不好找原因(因為程式碼過於複雜)。由於詞法分析和語法分析有規律可循,所以出現了很多通過文法生成詞法分析器和語法分析器的工具,由於詞法分析與語法分析是編譯器前端的重要組成部分,所以這類工具通常稱為「編譯器前端生成器」。比較著名的包括lex、yacc、javacc、antlr等。其中lex是專門用來生成詞法分析器的,yacc用來生成語法分析器的,javacc可以同時生成詞法和語法分析器、antlr也同樣可以生成詞法分析器和語法分析器。不過lex和yacc只支援C語言,javacc只支援Java語言。而antlr支援多種程式語言,例如Java、C++、JavaScript、Go、C#、Swift等。本系列文章也使用了antlr的最新版本antlr4來實現編譯器的前端(詞法分析器和語法分析器)。
這幾種工具都是依賴於文法生成詞法分析器和語法分析器的,例如,在antlr4中,如果要識別加減乘除四則運算,只需要編寫下面的文法即可。
expr: expr op=(' * ' |' / ' ) expr | expr op=(' + ' |' - ' ) expr
文法是不是很簡單呢?但如果要編寫完善的程式碼,可能需要上百行才能實現(我們團隊實現的Ori語言,利用antlr4生成的詞法和語法分析器,總共6萬行Go語言程式碼,我們自己編寫了大概4萬行Go程式碼,整個編譯器有超過10萬行程式碼,3/5是自動生成的,2/5是自己編寫的)。而且文法還標識了優先順序,antlr4規定,寫在前面的文法的優先順序高於寫在後面的文法的優先順序。我們知道,對於四則運算來說,是先乘除,後加減,所以expr op=(‘*’|’/’) expr 應該在expr op=(‘+’|’-‘) expr 前面,倒過來是不行了。如果要加更複雜的運算,例如,平方、開方、冪等,只需要修改這個文法即可,是不是很簡單呢?
前面說的前4點是硬知識,也有很多教程可以學習,但最後兩點:學習能力和想像力,就要完全靠自己的天賦了。因為前面4點能讓你做出一個看著還不錯的編譯器,但最後兩點能決定你做的編譯器有多強大。
實現一個程式語言,所涉及到的知識要比實現編譯器難度更大。因為如果實現編譯器,並且是已經存在的程式語言,由於語法已經確定,所以只需要實現出來即可。但程式語言不同,一切需要重新設計,尤其是在涉及到新語法時,非常困難,需要了解的知識相當多,所以需要擁有快速學習能力,可以在短時間內學會並掌握任何知識和技術。另外,想像力更重要,因為設計一款新的程式語言,有些東西可能不僅僅局限於IT領域,也不僅僅局限於自己所從事的技術領域,例如。在Ori語言中,擁有一些創新的語法,需要同時適應類似JavaScript的單執行緒模式和Java的多執行緒模式。因此,擁有多維度的想像力才是最終取得勝利的關鍵。
3. 自己設計的程式語言會流行嗎
我經常在網上看到很多同學在問,為什麼中國沒有自己流行的程式語言(儘管有易語言,但由於是中文編程,所以註定不會全球流行,中國也並不算流行)呢?BAT等大廠為何不開發一個呢? 然後有人回答,開發程式語言容易,關鍵是生態,還有人回答,BAT是因為沒有必要,因為程式語言沒有和KPI掛鉤,也有些人回答,開發一款程式語言,火起來很難。 其實這些都可能是原因,但主要原因其實就是需求沒有與行動掛鉤,或者說,現在的程式語言已經足夠滿足需求了,沒有必要再開發一款新的程式語言,而且這些大廠的盈利壓力都很大,當然,還有技術積累的問題。
其實程式語言有很多種,有一種就是像Java、C#、C++一樣的通用程式語言,這類語言什麼都能做,是一種圖靈完備的程式語言。還有另外一種程式語言,如SQL、VBA、ABAP(SAP的內嵌語言),這類屬於領域程式語言,他們也可能是圖靈完備的,也可能不是圖靈完備的。通常使用這類程式語言完成某些特定的工作,如SQL操作資料庫,VBA操作Office、ABAP操作SAP數據等。其實在中國有很多公司內部已經提供了類似的領域語言,只是非常專業,功能單一,絕大多數人不清楚而已。
至於自己開發出來的程式語言是否會流行,其實你們想太多了。程式語言是為了解決實際問題而存在的,不是為了流行而存在的。就像衣服,最初的用途是為了保暖,而不是時尚,當大多數人都使用自己生產的衣服保暖,那他就是流行款了!所以讓程式語言解決實際問題才是優先要考慮,至於以後是否會流行,自己說了不算!
像我們團隊開發的UM系統,其實原來壓根就沒打算自己開發程式語言,想直接使用JavaScript,不過後來發現,JavaScript太動態了,使用JavaScript根本沒有辦法做一款完美的IDE,而且功能有限,並且混亂。還有就是JS是動態語言,如果將其轉換為靜態語言,會以犧牲性能為代價,而且無法有效融合單執行緒和多執行緒的特性,並且還無法與UM IDE融為一體,所以沒辦法,才開發一款自己的程式語言Ori,並且融合了數十種程式語言的優秀特性,而且加入了更先進的特性(如內嵌SQL、虛擬組件、虛擬資料庫、支援跨平台的語法、客戶端服務端一體化、柔性熱更新等),當然,這些特性需要與UM IDE配合才能使用。
4. 開發程式語言,從這裡起航:配置Antlr4環境
如果一上來就開發程式語言,估計大家就開始暈了,所以我們先從最簡單的開始,就是先來編寫一個可以解析加減乘除表達式的編譯器。我們使用了antlr4來生成詞法分析器和語法分析器,所以先要配置一下antlr4的開發環境。
由於antlr4使用Java開發,所以不管用什麼程式語言設計編譯器,JDK必須安裝,並且還需要一款強大的Java IDE,這裡推薦Intellij IDEA。我們只使用Intellij IDEA的最基礎功能,所以CE(社區版)版足夠了,這個版本是免費的。
在安裝完Intellij IDEA CE後,到下面的頁面下載antlr4工具相關的庫。
進入頁面,找到下面的部分,點擊第1個鏈接下載即可。
下載完antlr4的工具包後,找到其中的Java運行時庫,並用Intellij IDEA CE創建一個Java工程,然後直接將Antlr4 Java運行時庫複製到工程的lib目錄中(沒有lib目錄可以建立一個),如下圖所示。
然後在lib目錄的右鍵菜單中點擊「Mark Directory as」>「Sources Root」菜單項,將lib編程源程式碼目錄,這樣Intellij IDEA CE就會搜索lib目錄中的所有庫。當然,可以直接在模組中引用antlr4的庫,不過將antlr4 運行時庫與工程放到一起,這樣如果將工程複製到其他機器上,就不會由於antlr4的運行庫沒有複製而導致無法運行了。
然後需要安裝Intellij IDEA CE的Antlr插件。進入插件安裝頁面,如果沒有安裝antlr插件,選擇Marketplace標籤頁,輸入antlr搜索插件,通常第一個就是。點擊右側的install按鈕即可安裝。如果已經安裝,Antlr插件會出現在Installed頁面中,如下圖所示。
安裝完Antlr插件後,新創建一個文件,將文件擴展名設置為g4,就會看到文件前面的圖標變成了紅色,裡面有一個A字母,這就是Antlr4的標識,如下圖所示。
5. Antlr4的Hello World
現在我們開始進入激動人心的時刻了,用Antlr4親手做我們的第一個編譯器:解析四則運算表達式的計算器。不過在完成這個編譯器之前,一定要了解一下Antlr4。
下面先給出一個可以識別以hello開頭的片語的識別程式的文法。首先創建一個名為Hello.g4的文件,並輸入下面的程式碼:
grammar Hello;
r : ' hello ' ID ;
ID : [a -z]+ ;
WS : [ \t\r\n] + -> skip ;
大家先不需要管這些程式碼是什麼意思,只需要照貓畫虎輸入即可。
然後在Hello.g4右鍵菜單點擊「Configure ANTLR」菜單項,會彈出如下圖的對話框,設置第一個文本輸入框,指定生成目錄,這裡指定與Hello.g4相同的目錄。Hello.g4生成的文件都會放在這個目錄中。
然後點擊Hello.g4右鍵菜單的「Generate ANTLR Recognizer」菜單項,會自動生成一堆文件,如下圖所示。注意:Java文件都隱藏了擴展名。
Hello.java和MyHelloVisitor.java是後來創建的,其他文件都是自動生成的。其中HelloLexer.java是詞法分析器、HelloParser.java是語法分析器,其他文件後面再說。
大家可以打開這兩個文件,看到每一個文件的內容都有上百行,這要是人工編寫,會累死人,而使用Antlr4,只需要4行文法就搞定。如果要添加或修改原來的語法,只需要修改Hello.g4文件,然後再重新生成一遍即可。
現在有一個問題,怎麼用Hello.g4生成的一堆文件呢?或者換種問法,生成的這些文件有什麼用呢?
Hello.g4生成的這些文件的主要目的就是進行詞法分析和語法分析,那麼如何用呢?使用有如下兩種方式:
1. 用grun工具測試
2. 用Java程式碼調用詞法分析器和語法分析器,編寫完整的編譯器
現在先來說說grun工具。其實並沒有grun這個東西,grun是一個別名,真實的工具在是antlr-4.8-complete.jar中的 org.antlr.v4.gui.TestRig類,在macOS或Linux下,可以使用alias命令起一個別名,官方叫grun,所以這裡就沿用了官方的叫法。如果在windows下,可以創建一個grun.cmd文件。
起別名的完整命令如下:
alias grun=’java -classpath .:/System/Volumes/Data/sdk/compilers/antlr4-4.8/antlr-4.8-complete.jar org.antlr.v4.gui.TestRig’
現在就可以使用grun測試我們的程式了。
首先要說明一點,grun測試的是.class文件,不是.java文件,所以在測試之前,要在終端中切換到.class文件所在的目錄。Intellij IDEA CE默認的.class目錄是out/production目錄,如下圖所示。在一開始,前面生成的.java文件並沒有編譯,讀者可以隨便找個Java程式運行下,這時Intellij IDEA CE會編譯所有還沒有編譯的.java文件,我們會發現,剛才生成的所有.java文件都生成了同名的.class文件。
讀者可以直接在作業系統的終端進入.class所在的目錄,或者通過Intellij IDEA CE下方的Terminal也可以輸入命令行,如下圖所示。
現在來做我們的第一個測試:
首先輸入下面的命令(先不需要管命令是什麼意思):
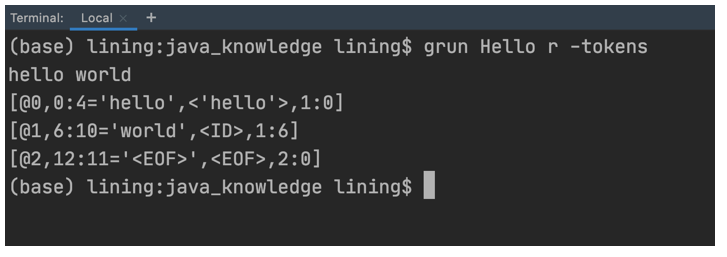
grun Hello r -tokens
然後輸入下面的內容:
hello world
如果讀者在macOS或Linux下,按Ctrl+D,如果在Windows下,按Ctrl+Z輸入結束符號,會輸出如下圖的內容:
現在來解釋一下grun Hello r -tokens是什麼意思。Hello表示Hello.g4中grammar後面的部分,也就是Hello。r是文法產生式等號左側的符號(非終結符),也就是r : ‘hello’ ID ;中的r。 -tokens表示列出所有的tokens。
那麼什麼是token呢? 其實token是詞法分析器的輸出,同時,token將作為語法分析器的輸入,而AST(抽象語法樹)則是語法分析器的輸出。
token就是程式語言中不可再分的單元,相當於程式語言的原子。看下面的程式:
這是一個非常簡單的條件語句,那麼在這兩行程式碼中,有多少個token呢?根據token不可分割的原則,包含如下的token:
上面用逗號(,)分隔的符號都是token,例如,if是關鍵字,將作為一個整體對待,在解析程式碼時,肯定不會將if拆開,10是一個整數,也將作為一個整體對待,肯定不會將其拆成1和0。
那麼Hello的輸出結果意味著什麼呢?我們輸入了hello world,根據語法規則。任何字元串都需要以hello開頭,所以hello將作為一個token(相當於前麵條件語句的if關鍵字,這裡hello是一個關鍵字)。而後面可以是任意字元串,但與hello之間至少要有一個空格。所以hello world符合Hello的語法規則,hello abc也同樣符合,而helloabc就不符合了,因為hello和abc之間沒有任何分隔符,根據最長匹配原則,Antlr4會選擇最長的字元串進行匹配,所以匹配的是helloabc,而不是hello。
現在我們的實驗也做完了,可能很多讀者還是一頭霧水,不過不要緊,我們再詳細講一下Antlr4到底是怎麼分析的。
Antlr4採用了自頂向下遞歸的分析方式。自頂向下就是先將整個程式語言源文件看成一個整體,這就是入口點,也就是Hello.g4中的r。這個入口點起任何名字都可以,只要不和其他的文法標識重名即可。然後從這個入口點開始,就可以用遞歸的方式寫文法了。文法用於從上到下推導,左側是文法標識,右側是文法的產生式。例如,要識別下面一組字元串:
hello world
hello abc
hello Bill
hello 李寧
很明顯,這4行文本都是以hello開頭,後面跟著任意的字元串,中間用空格分隔。所以我們的文法應該是以hello開頭,後面跟一個標識,用ID表示。文法如下:
在Antlr4中,每一個文法都要用分號(;)結尾,如果是固定的字元串,如關鍵字,用單引號括起來。如’hello’。
ID表示任意的標識符,也是終結符。所謂終結符,是指不能再繼續往下推導的符號(相當於樹的葉子節點)。在Antlr4中,終結符標識用由首字母大寫的字元串表示,如ID。而非終結符(可以繼續往下推導)用首字母小寫的字元串表示,如r。
現在是自頂向下分析的第1步,第2步是處理ID。文法如下:
ID的產生式不包含任何的非終結符,也就是再也無法繼續推導了。[a-z]是一種簡寫,也就是a到z共26個小寫字母中的任何一個,後面的加號(+)表示至少要有一個小寫字母。
到現在為止,自頂向下分析的過程已經完成了,分為兩步,第一步將整個字元串看做一個整體,並且將其分解為hello和後面的任意字元串。第二部來處理這個任意字元串。這裡規定,這個任意字元串只能由小寫字母組成。
不過現在還有一個問題,Antlr4怎麼知道hello和world之間需要有空格或其他空白符分隔呢?其實這就涉及到Hello.g4的最後一行程式碼了:WS : [ \t\r\n]+ -> skip ; 這行程式碼設置了一個skip通道(通道會在後面的文章中詳細講解),用於忽略指定的字元,這些被忽略的字元,將作為token的分隔符,這裡面指定了4個分隔符:空格、製表符(\t)、回車符(\r)、換行符(\n)。也就是說,下面的形式也是可以的:
ok,現在Hello.g4的語法規則已經講的差不多了,裡面涉及到了一些概念,在後面的文章中會詳細講解。現在來總結一下:
Antlr4的文法文件是以g4作為擴展名,第一行程式碼必須以grammar開頭,後面跟著語法名,如Hello,該名字必須與g4文件名一致。每一行程式碼都必須用分號(;)分隔。然後就是若干文法產生式了。例如,Ori語言的最頂端文法是這樣的。
grammar Ori;
program : sourceElements ? EOF
sourceElement : statement
statement
:
importStatement
| sqlStatement
| dollarMemberStatement
| classDeclarationStatement
| interfaceDeclarationStatement
| functionDeclarationStatement
| variableStatement
| ifStatement
| iterationStatement
| continueStatement
| breakStatement
| returnStatement
| withStatement
| switchStatement
| throwStatement
| tryStatement
| blockStatement
| expressionStatement
| commentStatement
;
program是Ori語言的入口點,然後Ori語言將整個語言分成若干源程式碼元素(sourceElements?),後面的問號表示可選,也就是說,Ori語言的源程式碼文件可以是空文件。EOF是文件結束符。這裡講每一個源程式碼元素對應一條statement(語句),這裡之所以不直接使用statement,而是使用sourceElement,是因為以後可能會進行擴展,這時只需要修改sourceElement即可(目前sourceElement等於statement),而一條語句包括多種,如ImportStatement、sqlStatement(內嵌SQL)、classDeclarationStatement(類聲明)等。然後就繼續往下分,如sqlStatement還會包含sqlInsert、sqlUpdate等。以此類推,直到不可再分為止。這就是自頂向下分析的基本方法,其實這就是分治法的一種表現,儘管程式語言看著很複雜,一個大型系統可能會有上百萬甚至更多行程式碼,但如果將程式語言從頂向下分析,涉及到的語句種類也不過幾十種而已。Ori語言的文法文件也就1000多行,包括詞法文件部分,也就2000行出頭。用2000行程式碼,就可以完全描述一種圖靈完備的程式語言,真是perfect。而這2000行程式碼,生成的Go語言程式碼超過了60000行。
現在再回到grun工具上來。其實grun的功能很強大,除了可以作為測試工具外,還可以顯示Antlr4生成的AST,看一下自頂向下分析的流程。
首先準備一個hello.txt文件,並輸入hello world。然後在終端輸入下面的命令(讀者要將hello.txt文件的路徑改成自己機器上的路徑):
grun Hello r -gui < /MyStudio/java/java_knowledge/antlr/test/hello.txt
然後就會彈出如下圖的窗口,右側顯示了AST的樹狀結構。Antlr4製作編譯器的過程就是先根據源程式碼生成AST,然後對AST進行遍歷(根據語言的特性,會遍歷1到n遍),遍歷完後,就會生成中間程式碼、以及最終的二進位文件。所以AST起到了承前啟後的作用。
6. 如何用程式進行詞法和語法分析
儘管已經了解了Antlr4的基本使用方法,但到現在為止,還沒有用Java編寫過一行程式碼呢?現在我就來演示如何用Java調用上一節生成的詞法分析器和語法分析器。
下面先給出實現程式碼:
首先創建一個MyHelloVisitor.java文件,並輸入下面的程式碼:
import org.antlr.v4.runtime.tree.AbstractParseTreeVisitor;
public class MyHelloVisitor extends AbstractParseTreeVisitor<String> implements HelloVisitor<String> {
@Override public String visitR(HelloParser.RContext ctx) {
System.out.println(ctx.getText());
System.out.println(ctx.ID().getText());
return visitChildren(ctx);
}
}
然後再創建一個Hello.java文件,並輸入下面的程式碼:
import org.antlr.v4.runtime.CharStream;
import org.antlr.v4.runtime.CharStreams;
import org.antlr.v4.runtime.CommonTokenStream;
import org.antlr.v4.runtime.tree.ParseTree;
public class Hello {
public static void main(String[] args) throws Exception {
// 讀取源程式碼文件,這裡選擇直接從字元串讀取
CharStream input = CharStreams.fromString("hello world");
// 創建詞法分析器對象
HelloLexer lexer = new HelloLexer(input);
// 獲取詞法分析器輸出的tokens
CommonTokenStream tokens = new CommonTokenStream(lexer);
// 創建語法分析器對象,並將詞法分析器輸出的tokens作為語法分析器的輸入
HelloParser parser = new HelloParser(tokens);
// 開始分析程式,這也是生成AST的過程
ParseTree tree = parser.r(); // 文法的入口點r會轉換為一個方法,調用該方法,就會自頂向下遞歸分析源程式碼
// 創建Visitor對象
MyHelloVisitor hello = new MyHelloVisitor();
// 開始遍歷AST
hello.visit(tree);
}
}
現在運行Hello.java,如果在Run窗口輸出如下圖的內容,說明運行成功了。
現在來解釋一下前面的程式碼。這裡先要知道Antlr4是如何遍歷AST的。Antlr4有如下兩種方式遍歷AST:
(1)listener
(2)visitor
第一種方式更靈活,但不容易使用。visitor不靈活,但容易使用。本例使用了第2種方式來遍歷AST,但本系列文章的大多數程式碼主要使用listener來遍歷AST。listener方式會在後面的文章中詳細介紹,這裡主要介紹visitor。其實這兩種遍歷AST的方式的原理類似,都是遇到了一個節點,就會調用相應的回調方法,然後將必要的資訊作為參數傳入回調方法,用戶可以在回調方法中完成程式碼生成、數據處理、中間程式碼優化等工作。那麼這些回調方法放在哪裡呢?這就要說到前面創建的MyHelloVisitor類。該類實現了HelloVisitor介面,該介面是根據Hello.g4文件自動生成的,程式碼如下:
import org.antlr.v4.runtime.tree.ParseTreeVisitor;
public interface HelloVisitor<T> extends ParseTreeVisitor<T> {
T visitR(HelloParser.RContext ctx);
}
我們可以看到,該介面中只有一個方法,就是visitR,該方法是遍歷到r節點調用的回調方法。
如果文法文件很大時,會生成相當多的回調方法,例如,Ori語言的文法就生成了數百個回調方法,這些回調方法並不一定都用到,在這種情況下,並不需要實現所有的回調方法,所以Antlr4在生成回調介面文件的同時,還生成了一個默認實現類,如本例的HelloBaseVisitor,默認實現類已經默認實現了所有的回調方法,我們的Visitor類只需要從該類繼承,就只需要實現必要的回調方法即可。
import org.antlr.v4.runtime.tree.AbstractParseTreeVisitor;
public class HelloBaseVisitor<T> extends AbstractParseTreeVisitor<T> implements HelloVisitor<T> {
@Override public T visitR(HelloParser.RContext ctx) { return visitChildren(ctx); }
}
本例的MyHelloVisitor類繼承了HelloBaseVisitor類,並覆蓋了visitR方法,輸出了r節點的文本和ID的文本。
對於Hello類來說,就是最終的調用程式碼了。通常一個用Antlr4實現的編譯器,需要經過如下幾步:
(1)讀取源程式碼文件(或直接從字元串獲取源程式碼)
(2)創建詞法分析器(輸入是單個字元、輸出是tokens)
(3)創建語法分析器(輸入是tokens、輸出是AST)
(4)開始遍歷AST
這4步已經在Hello類中做了詳細的注釋,大家可以自行查看。
7. 弄一個可以解析表達式的計算器
前面已經給出了一個完整的Antlr4案例,不過這個案例太簡單了,沒什麼實際的用途,本節會利用Antlr4實現一個有實際價值的計算器程式。該程式可以解析過個表達式,表達式包含加減乘除運算,每一個表達式佔一行,用分號(;)結尾。
先給出文法:Calc.g4
grammar Calc;
// 下面是語法
prog: stat+ ;
stat: expr ';' # printExpr
| ID '=' expr ';' # assign
| NEWLINE # blank
;
expr: expr op =('*'|'/') expr # MulDiv
| expr op=('+'|'-') expr # AddSub
| INT # int
| ID # id
| '(' expr ')' # parens
;
// 下面是詞法
MUL : '*' ;
DIV : '/' ;
ADD : '+' ;
SUB : '-' ;
ID : [a -zA-Z]+ ; // 匹配標識符
INT : [0-9]+ ; // 匹配整數
WS : [ \t]+ -> skip ; // 忽略空白符
NEWLINE:'\r'? '\n' ; // 空行
現在生成Calc.g4 的相關文件。先看一下生成的CalcVisitor.java文件,程式碼如下:
import org.antlr.v4.runtime.tree.ParseTreeVisitor;
public interface CalcVisitor<T> extends ParseTreeVisitor<T> {
T visitProg(CalcParser.ProgContext ctx);
T visitPrintExpr(CalcParser.PrintExprContext ctx);
T visitAssign(CalcParser.AssignContext ctx);
T visitBlank(CalcParser.BlankContext ctx);
T visitParens(CalcParser.ParensContext ctx);
T visitMulDiv(CalcParser.MulDivContext ctx);
T visitAddSub(CalcParser.AddSubContext ctx);
T visitId(CalcParser.IdContext ctx);
T visitInt(CalcParser.IntContext ctx);
}
CalcVisitor有9個回調方法,從文法上看,有多少個文法,就應該有多少個回調方法。在Calc.g4中,除了第一個文法(prog:stat+;)外,其他的文法都起了別名,如printExpr,assign等。所以這些文法對應的回調方法都是以別名作為後綴的,然後前面加上visit。其實這9個方法,分別經過了AST的9個非葉子節點後(如果有的話),被分別調用。
例如,現在測試這個表達式(將表達式放置expr.calc文件中):1+3 * 4 – 12 /5;
grun Calc prog -gui < /MyStudio/java/java_knowledge/antlr/Calc/expr.calc
執行上面的命令,會顯示如下圖的AST。
要計算上述表達式,就需要遍歷這棵AST。例如,當遍歷到prog節點時,就會調用visitProg方法,通過該方法的參數可以獲取prog節點的直接子節點的資訊(就是左右兩個stat節點)。當遇到減法表達式時,就會調用visitAddSub方法,以此類推。
現在看一下EvalVisitor類的實現。該類的實現原理是當直接計算兩個值時,如3 * 5、4 – 1,就分別由visitMulDivhe visitAddSub方法計算,並通過返回值返回計算結果。如果遇到變數(Calc支援變數),需要首先將變數放到一個Map中,然後在獲取該變數時,會從Map讀取。Map相當於一個符號表。
import java.util.HashMap;
import java.util.Map;
public class EvalVisitor extends CalcBaseVisitor<Integer> {
/** "memory" for our calculator; variable/value pairs go here */
Map <String, Integer> memory = new HashMap<String, Integer>();
boolean error = false ;
/** ID '=' expr NEWLINE */
// 初始化變數的操作(賦值操作)
@Override
public Integer visitAssign(CalcParser.AssignContext ctx) {
String id = ctx.ID().getText(); // id is left-hand side of '='
int value = visit(ctx.expr()); // compute value of expression on right
memory.put(id, value); // store it in our memory
return value;
}
/** expr NEWLINE */
// 輸出表達式的計算結果
@Override
public Integer visitPrintExpr(CalcParser.PrintExprContext ctx) {
Integer value = visit(ctx.expr()); // evaluate the expr child
System.out.println(value); // print the result
return 0; // return dummy value
}
/** INT */
// 將字元串形式的整數轉換為整數類型
@Override
public Integer visitInt(CalcParser.IntContext ctx) {
return Integer.valueOf(ctx.INT().getText());
}
/** ID */
@Override
public Integer visitId(CalcParser.IdContext ctx) {
String id = ctx.ID().getText();
// 從Map中獲取變數的值
if ( memory.containsKey(id) ) {
return memory.get(id);
} else {
// 引用了不存在的變數,輸出錯誤資訊
System.err.println(String.format("變數<%s> 不存在!",id));
error = true ;
}
return 0;
}
/** expr op=('*'|'/') expr */
// 計算乘法和除法
@Override
public Integer visitMulDiv(CalcParser.MulDivContext ctx) {
int left = visit(ctx.expr(0)); // get value of left subexpression
int right = visit(ctx.expr(1)); // get value of right subexpression
if ( ctx.op.getType() == CalcParser.MUL ) return left * right;
return left / right; // must be DIV
}
// 計算加法和減法
/** expr op=('+'|'-') expr */
@Override
public Integer visitAddSub(CalcParser.AddSubContext ctx) {
int left = visit(ctx.expr(0)); // get value of left subexpression
int right = visit(ctx.expr(1)); // get value of right subexpression
if ( ctx.op.getType() == CalcParser.ADD ) return left + right;
return left - right; // must be SUB
}
/** '(' expr ')' */
// 處理括弧表達式
@Override
public Integer visitParens(CalcParser.ParensContext ctx) {
return visit(ctx.expr()); // return child expr's value
}
}
最後看一下主程式(MarvelCalc)的源程式碼。
import org.antlr.v4.runtime.ANTLRInputStream;
import org.antlr.v4.runtime.CharStream;
import org.antlr.v4.runtime.CharStreams;
import org.antlr.v4.runtime.CommonTokenStream;
import org.antlr.v4.runtime.tree.ParseTree;
import java.io.FileInputStream;
import java.io.InputStream;
public class MarvelCalc {
public static void main(String[] args) throws Exception {
// 從文件讀取源程式碼
String inputFile = null ;
if ( args.length>0 ) {
inputFile = args[0];
} else {
System.out.println( "語法格式:MarvelCalc inputfile");
return ;
}
InputStream is = System.in;
if ( inputFile!=null ) is = new FileInputStream(inputFile);
CharStream input = CharStreams.fromStream(is);
CalcLexer lexer = new CalcLexer(input);
CommonTokenStream tokens = new CommonTokenStream(lexer);
CalcParser parser = new CalcParser(tokens);
ParseTree tree = parser.prog(); // 分析源程式碼
EvalVisitor eval = new EvalVisitor();
eval.visit(tree);
}
}
在expr.calc文件中輸入下面的內容:
1+3 * 4 - 12 /6;
x = 40;
y = 13;
x * y + 20 - 42/6;
z = 12;
x + 5 * z - y;
並使用下面的命令行執行計算器程式,或在IDE中將expr.calc作為參數允許MarvelCalc。
java MarvelCalc expr.calc
會得到下面的結果:
我們可以看到,在expr.calc文件中,有3個可以計算的表達式,其中最後兩個表達式使用了變數,而輸出結果就是這3個表達式的計算結果。從Calc.g4中也可以看出。語句一共有如下3種:
(1) 輸出表達式(包括運算、id和常量)
(2)賦值表達式(創建變數)
(3)空行
從EvalVisitor類的實現可以看出,只有輸出表達式才會輸出結果,其他的表達式只是在內部計算,生成內部結果,如向Map中存儲變數和值。
OK,到現在為止,我們已經創建了一個非常實用的計算器程式,不過這個程式仍然很簡單,在後面的文章中,將會不斷利用新學到的知識完成更複雜的編譯器程式,直到可以實現Marvel語言為止。
下載本文完整源程式碼,請關注微信公眾號「極客起源 」,更多精彩內容期待您的光臨!