Java源碼解析|HashMap的前世今生
- 2019 年 10 月 19 日
- 筆記
HashMap的前世今生
Java8在Java7的基礎上,做了一些改進和優化。
底層數據結構和實現方法上,HashMap幾乎重寫了一套
所有的集合都新增了函數式的方法,比如說forEach,也新增了很多好用的函數。
前世——Java 1.7
底層數據結構
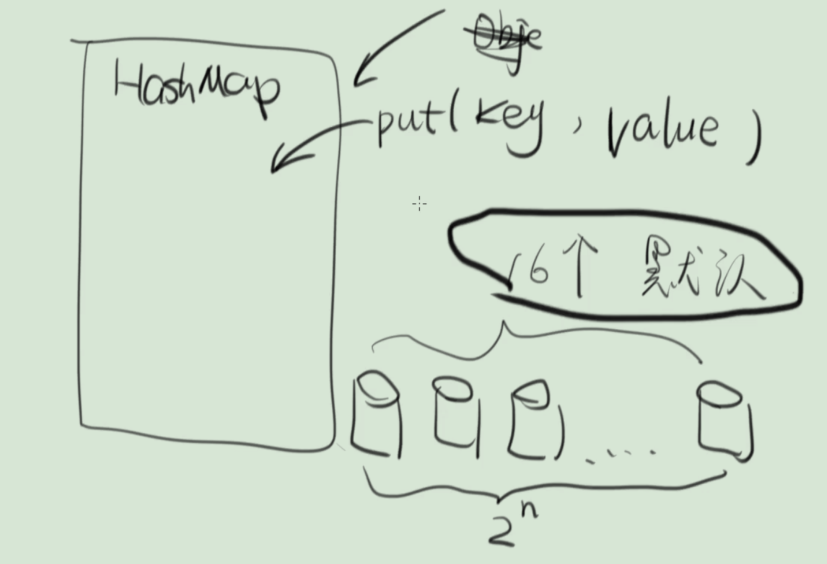
數組 + 鏈表
在Java1.7中HashMap使用數組+鏈表來作為存儲結構
數組就類似一個個桶構成的容器,鏈表用來解決衝突,當出現衝突時,就找到當前數據應該存儲的桶的位置(數組下標),在當前桶中插入新鏈表結點。
如下圖所示:
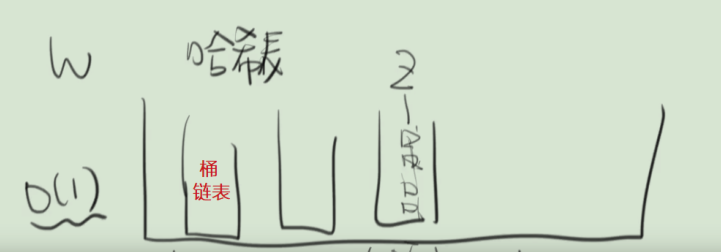
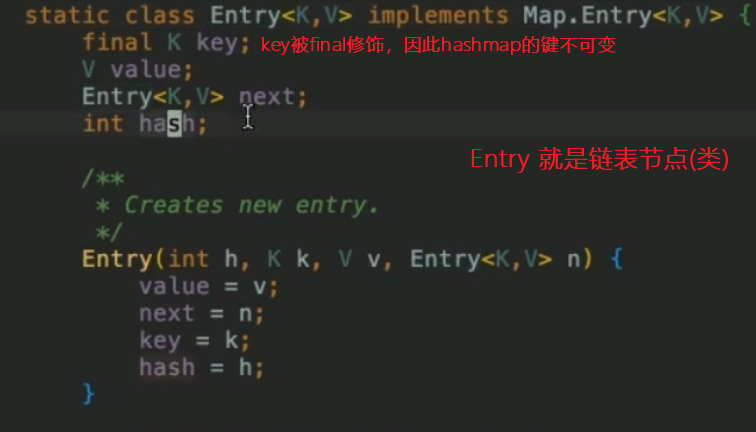
鏈表結點中存放(key,value)鍵值對
擴容與初始化
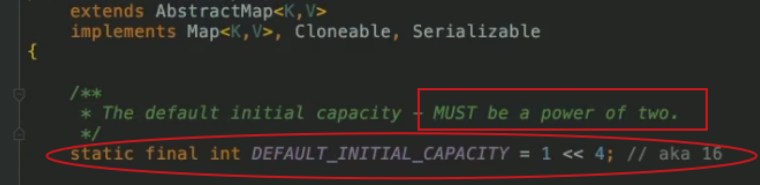
初始化:初始時,HashMap的數組大小(桶個數)默認為16,且數組大小必須是2的冪次方
看下圖源碼注釋所示
resize方法擴容
什麼時候擴容?
桶里鏈表結點元素超過threshole變數= 16 * 擴容因子0.75 = 12個時開始擴容

限定擴容最大值為Integer的大小
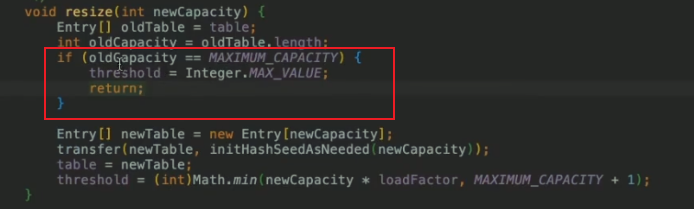
-
擴容一倍:
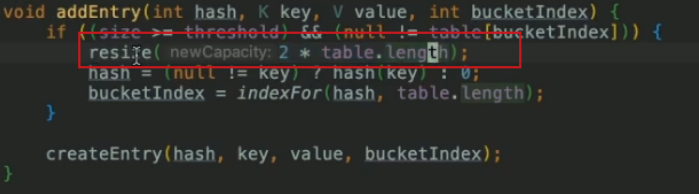
-
怎麼擴容:開闢新的數組(桶),使用transfer方法將舊數組數據拷貝到新數組中,部分元素重寫計算hash值(rehash)
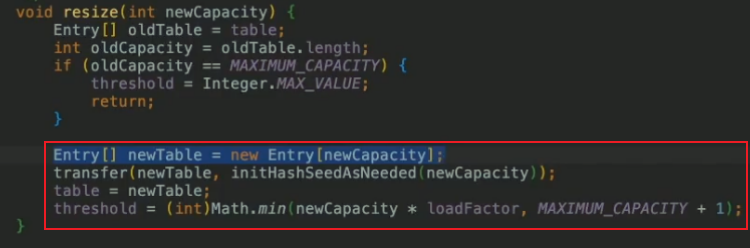
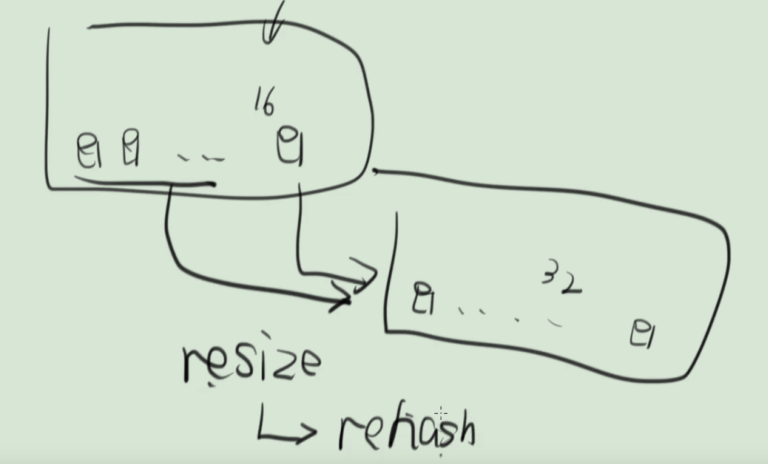
-
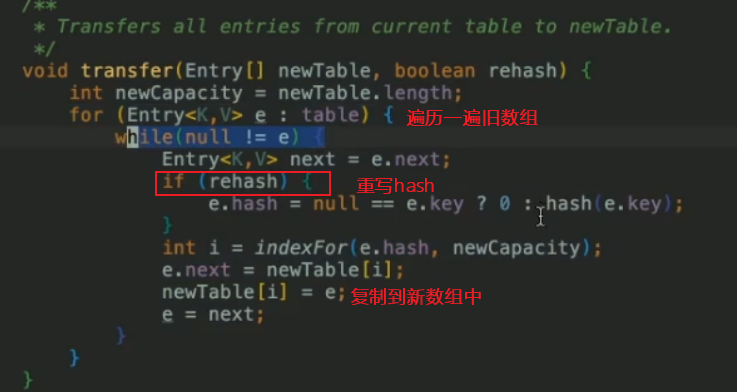
transfer函數,把舊錶的桶搬到新的桶
遍歷每一個桶的鏈表,重新rehash,indexFor拿到新表的下標,放到新表
hash演算法
- 為什麼數組的大小必須為2的冪呢
我們在求key的hash值在數組的下標的方法中發現 數組設置為2的冪,是為了在求模轉成位運算時,恰好可以得到數組下標

舉個栗子:比如,假設 數組長度為2的5次方,也就是32個長度,我們拿key的hash值(32位)與數組長度作&與運算,就能得到一個在數組長度範圍內的下標,這個下標就是當前key應該在表table的位置了。
看下圖演示吧:
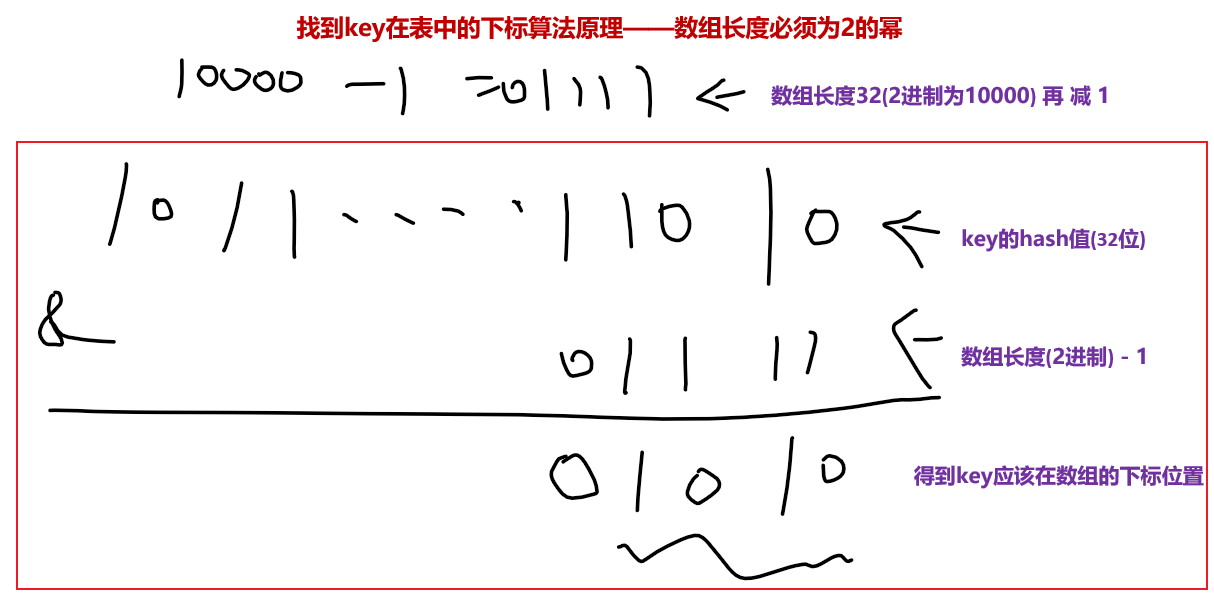
所以數組大小必須規定為2的冪的原因就是為了hash演算法將來計算key在數組中的index下標。
由key得到hashcode的演算法,在1.7中比較複雜,就不過多陳述了。
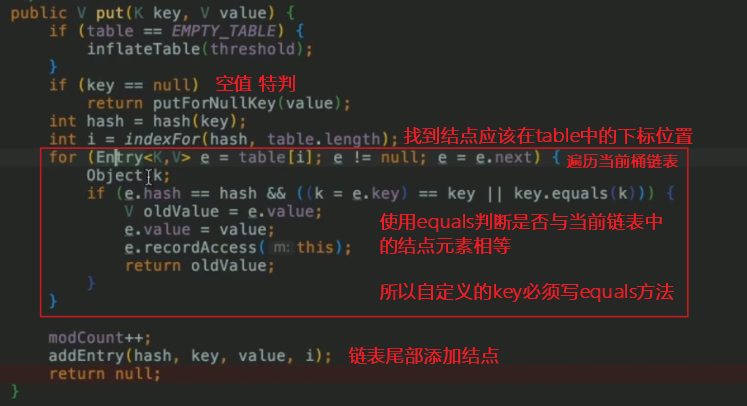
put方法
- 需要使用equals方法比較key,所以自定義的類需要重載equals方法
- 因此也推薦使用String這種已經重寫equals方法的類作為鍵key。

遺留問題:安全、死鎖
1.hashmap1.7執行緒不安全
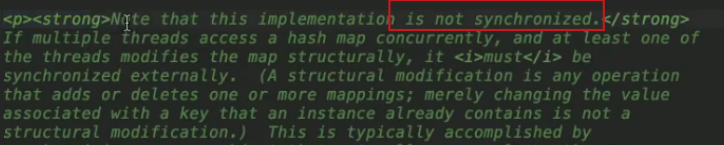
並發下並發下,擴容時,需要使用transfer函數拷貝鏈表數據,有坑,容易出現死循環鏈表,死鎖
2.hash碰撞的安全問題
Java1.7中的hash演算法會出現碰撞,可以通過惡意請求引發DOS
如下,hash值相同
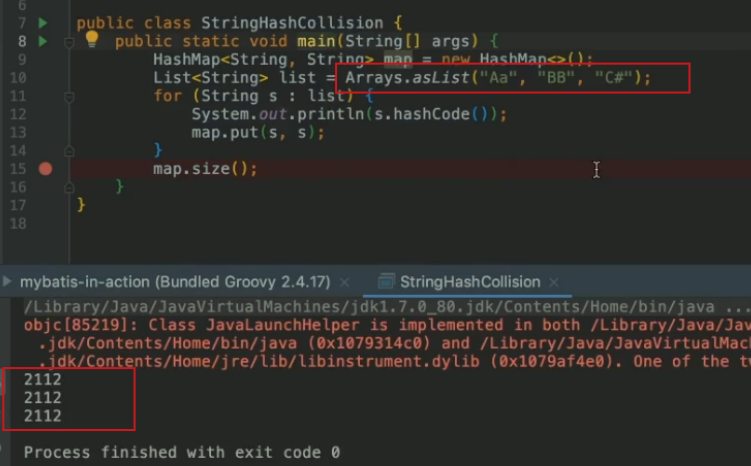
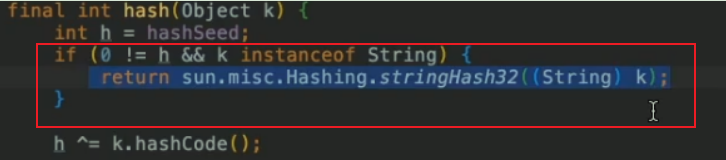
解決方法:換一種hash計算方法

今生——Java 1.8
底層數據結構
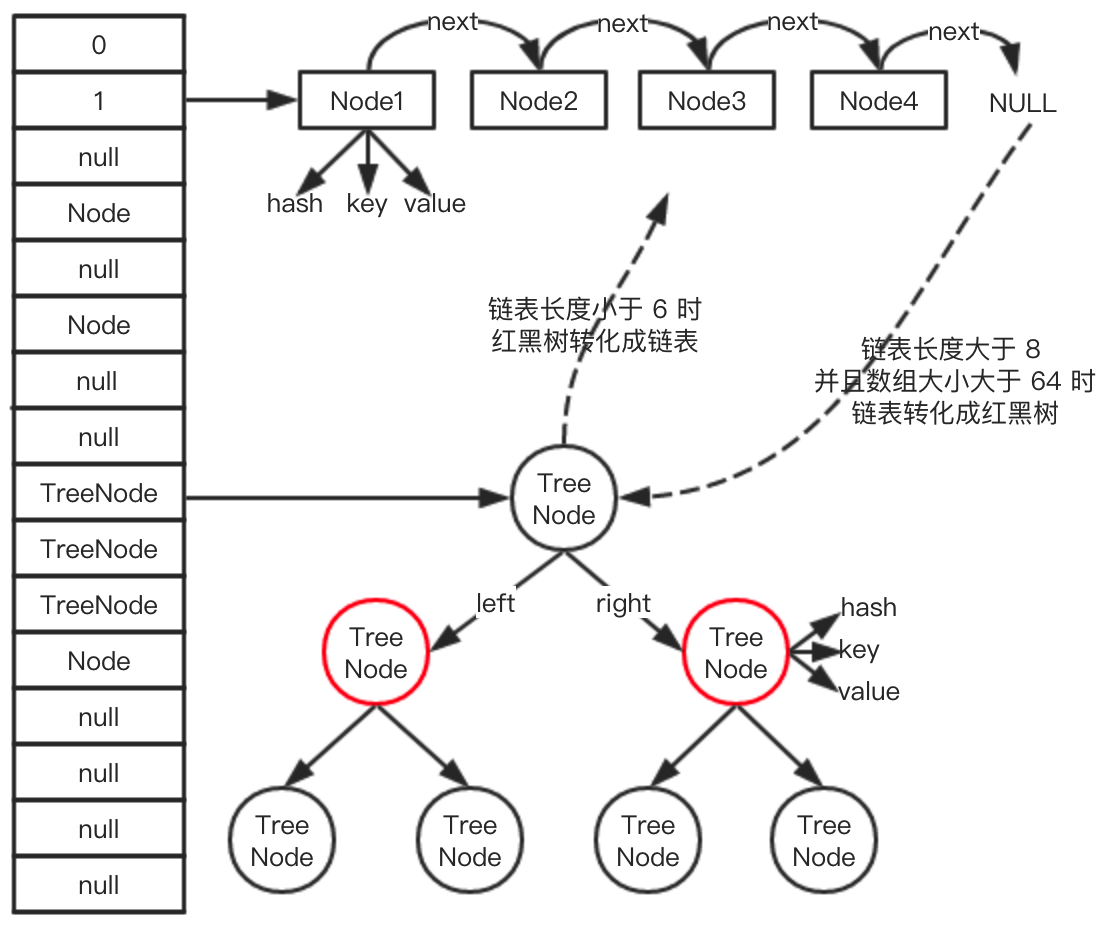
- HashMap底層的數據結構是:數組+鏈表+紅黑樹。
- 當鏈表的長度大於等於8時,鏈表會轉化成紅黑樹;
- 當紅黑樹的大小小於等於6時,紅黑樹會轉化成鏈表;
整體的數據結構如下:
擴容與初始化
常見屬性:
//初始容量為 16 static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; //最大容量 static final int MAXIMUM_CAPACITY = 1 << 30; //負載因子默認值 static final float DEFAULT_LOAD_FACTOR = 0.75f; //桶上的鏈表長度大於等於8時,鏈錶轉化成紅黑樹 static final int TREEIFY_THRESHOLD = 8; //桶上的紅黑樹大小小於等於6時,紅黑樹轉化成鏈表 static final int UNTREEIFY_THRESHOLD = 6; //當數組容量大於 64 時,鏈表才會轉化成紅黑樹 static final int MIN_TREEIFY_CAPACITY = 64; //記錄迭代過程中 HashMap 結構是否發生變化,如果有變化,迭代時會 fail-fast transient int modCount; //HashMap 的實際大小,可能不準(因為當你拿到這個值的時候,可能又發生了變化) transient int size; //存放數據的數組 transient Node<K,V>[] table; // 擴容的門檻,有兩種情況 // 如果初始化時,給定數組大小的話,通過 tableSizeFor 方法計算,數組大小永遠接近於 2 的冪次方,比如你給定初始化大小 19,實際上初始化大小為 32,為 2 的 5 次方。 // 如果是通過 resize 方法進行擴容,大小 = 數組容量 * 0.75 int threshold; //鏈表的節點 static class Node<K,V> implements Map.Entry<K,V> { //紅黑樹的節點 static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V>- 可以看到初始容量為16,最大容量為2的30次方
- 當數組容量大於 64 時,並且鏈表結點數>=8時,鏈表才會轉化成紅黑樹
而轉化成紅黑樹的概率是非常小的(千萬分之一),原因是一個合適的hash計算不會很少出現多次碰撞
在考慮設計鏈表結點數>=8這個值的時候,我們參考了泊松分布概率函數,由泊松分布中得出結論,鏈表各個長度的命中概率為:
* 0: 0.60653066 * 1: 0.30326533 * 2: 0.07581633 * 3: 0.01263606 * 4: 0.00157952 * 5: 0.00015795 * 6: 0.00001316 * 7: 0.00000094 * 8: 0.00000006意思是,當鏈表的長度是8的時候,出現的概率是0.00000006,不到千萬分之一,所以說正常情況下,鏈表的長度不可能到達8,而一旦到達8時,肯定是hash 演算法出了問題,所以在這種情況下,為了讓HashMap仍然有較高的查詢性能,所以讓鏈錶轉化成紅黑樹,我們正常寫程式碼,使用HashMap時,幾乎不會碰到鏈錶轉化成紅黑樹的情況。
- 擴容
擴容有兩種情況:
-
如果初始化時,給定數組大小的話,通過 tableSizeFor 方法計算,數組的容量大小會近似一下,數組大小永遠是 2 的冪次方,比如你給定初始化大小 19,實際上初始化大小為 32,也就是 2 的 5 次方。
-
如果是通過 resize 方法進行擴容,當大小 > 數組容量 * 0.75進行resize
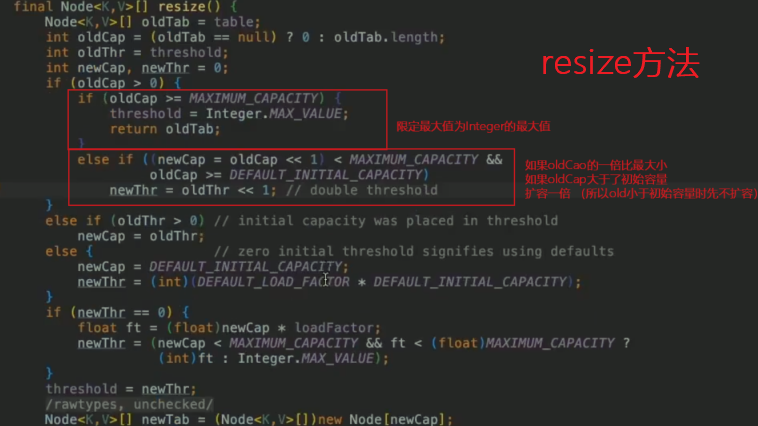
- 擴容後拷貝原來的table,像java1.7的transfer函數,java1.8中保持順序複製,執行緒仍然不安全
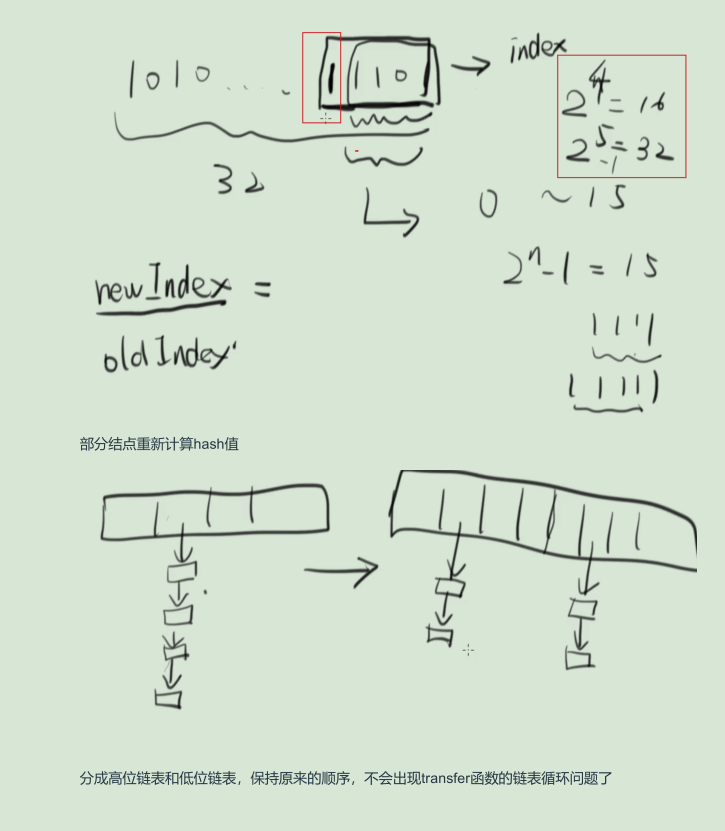
-
擴容時的高低位鏈表 不太懂。
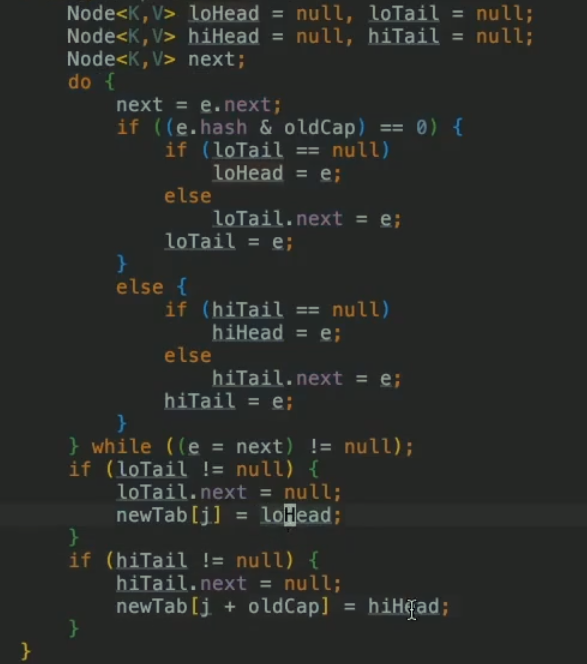
-
resize效率低,需要拷貝,所以初始化時最好指定一定的容量,避免頻繁擴容帶來的性能問題。
put插入方法
- HashMap新增結點步驟如下:

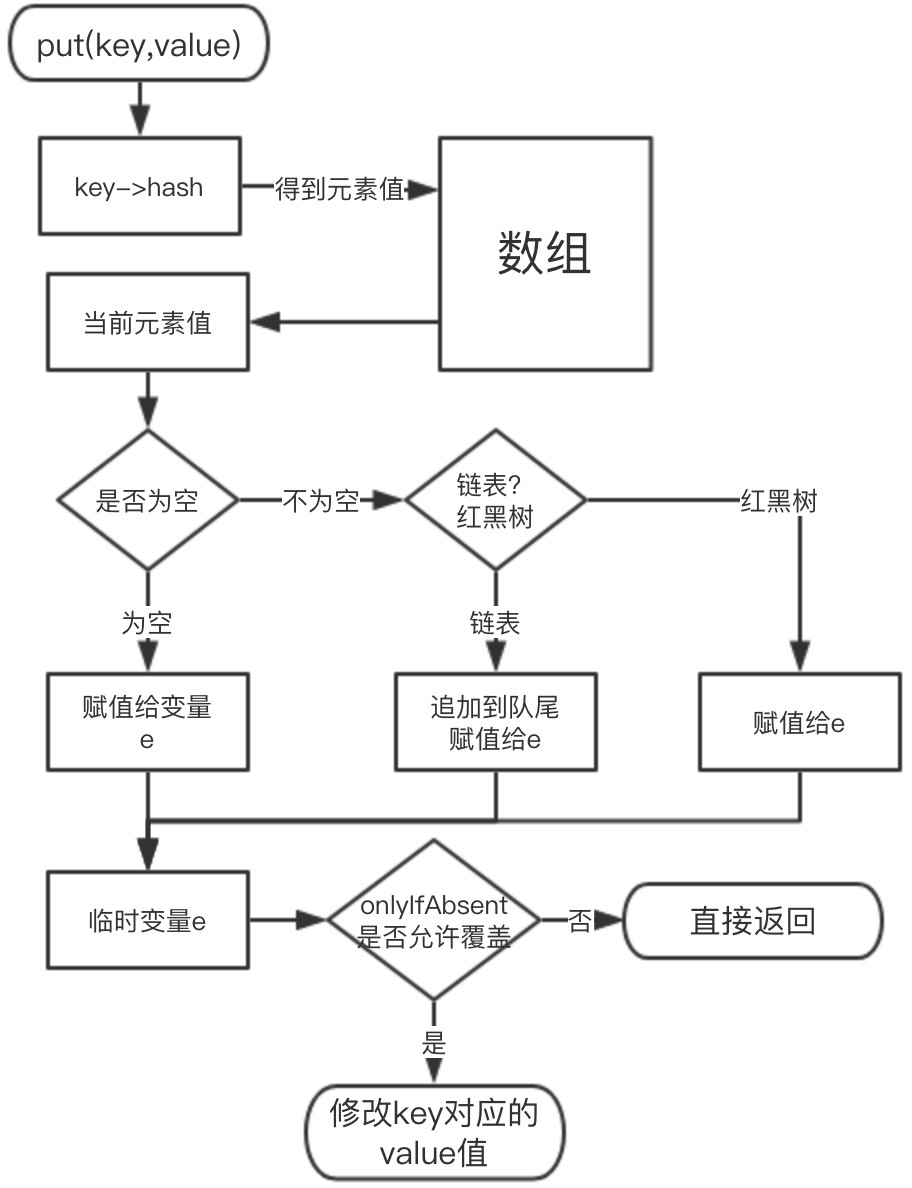
- put的部分程式碼如下
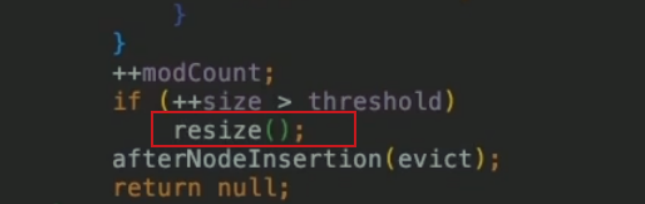
// 入參 hash:通過 hash 演算法計算出來的值。 // 入參 onlyIfAbsent:false 表示即使 key 已經存在了,仍然會用新值覆蓋原來的值,默認為 false final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { // n 表示數組的長度,i 為數組索引下標,p 為 i 下標位置的 Node 值 Node<K,V>[] tab; Node<K,V> p; int n, i; //如果數組為空,使用 resize 方法初始化 if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; // 如果當前索引位置是空的,直接生成新的節點在當前索引位置上 if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null); // 如果當前索引位置有值的處理方法,即我們常說的如何解決 hash 衝突 else { // e 當前節點的臨時變數 Node<K,V> e; K k; // 如果 key 的 hash 和值都相等,直接把當前下標位置的 Node 值賦值給臨時變數 if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; // 如果是紅黑樹,使用紅黑樹的方式新增 else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); // 是個鏈表,把新節點放到鏈表的尾端 else { // 自旋 for (int binCount = 0; ; ++binCount) { // e = p.next 表示從頭開始,遍歷鏈表 // p.next == null 表明 p 是鏈表的尾節點 if ((e = p.next) == null) { // 把新節點放到鏈表的尾部 p.next = newNode(hash, key, value, null); // 當鏈表的長度大於等於 8 時,鏈錶轉紅黑樹 if (binCount >= TREEIFY_THRESHOLD - 1) treeifyBin(tab, hash);//樹化 break; } // 鏈表遍歷過程中,發現有元素和新增的元素相等,結束循環 if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; //更改循環的當前元素,使 p 在遍歷過程中,一直往後移動。 p = e; } } // 說明新節點的新增位置已經找到了 if (e != null) { V oldValue = e.value; // 當 onlyIfAbsent 為 false 時,才會覆蓋值 if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); // 返回老值 return oldValue; } } // 記錄 HashMap 的數據結構發生了變化 ++modCount; //如果 HashMap 的實際大小大於擴容的門檻,開始擴容 if (++size > threshold) resize(); afterNodeInsertion(evict); return null; }如果數組有了key,但不想覆蓋 value,可以選擇putlfAbsent方法,這個方法有個內置變數onlylfAbsent,內置是true,就不會覆蓋,我們平時使用的put方法,內置onlylfAbsent為false,是允許覆蓋的。
- 鏈表新增結點:把新結點添加到鏈表尾部就行了。
- 紅黑樹新增結點步驟如下

//入參 h:key 的hash值 final TreeNode<K,V> putTreeVal(HashMap<K,V> map, Node<K,V>[] tab, int h, K k, V v) { Class<?> kc = null; boolean searched = false; //找到根節點 TreeNode<K,V> root = (parent != null) ? root() : this; //自旋 for (TreeNode<K,V> p = root;;) { int dir, ph; K pk; // p hash 值大於 h,說明 p 在 h 的右邊 if ((ph = p.hash) > h) dir = -1; // p hash 值小於 h,說明 p 在 h 的左邊 else if (ph < h) dir = 1; //要放進去key在當前樹中已經存在了(equals來判斷) else if ((pk = p.key) == k || (k != null && k.equals(pk))) return p; //自己實現的Comparable的話,不能用hashcode比較了,需要用compareTo else if ((kc == null && //得到key的Class類型,如果key沒有實現Comparable就是null (kc = comparableClassFor(k)) == null) || //當前節點pk和入參k不等 (dir = compareComparables(kc, k, pk)) == 0) { if (!searched) { TreeNode<K,V> q, ch; searched = true; if (((ch = p.left) != null && (q = ch.find(h, k, kc)) != null) || ((ch = p.right) != null && (q = ch.find(h, k, kc)) != null)) return q; } dir = tieBreakOrder(k, pk); } TreeNode<K,V> xp = p; //找到和當前hashcode值相近的節點(當前節點的左右子節點其中一個為空即可) if ((p = (dir <= 0) ? p.left : p.right) == null) { Node<K,V> xpn = xp.next; //生成新的節點 TreeNode<K,V> x = map.newTreeNode(h, k, v, xpn); //把新節點放在當前子節點為空的位置上 if (dir <= 0) xp.left = x; else xp.right = x; //當前節點和新節點建立父子,前後關係 xp.next = x; x.parent = x.prev = xp; if (xpn != null) ((TreeNode<K,V>)xpn).prev = x; //balanceInsertion 對紅黑樹進行著色或旋轉,以達到更多的查找效率,著色或旋轉的幾種場景如下 //著色:新節點總是為紅色;如果新節點的父親是黑色,則不需要重新著色;如果父親是紅色,那麼必須通過重新著色或者旋轉的方法,再次達到紅黑樹的5個約束條件 //旋轉: 父親是紅色,叔叔是黑色時,進行旋轉 //如果當前節點是父親的右節點,則進行左旋 //如果當前節點是父親的左節點,則進行右旋 //moveRootToFront 方法是把算出來的root放到根節點上 moveRootToFront(tab, balanceInsertion(root, x)); return null; } } }- 有關紅黑樹還需要補充知識點(占坑)
get查找方法
鏈表查詢的時間複雜度是O(n),紅黑樹的查詢複雜度是O(log(n)。在鏈表數據不多的時候,使用鏈表進行遍歷也比較快,只有當鏈表數據比較多的時候,才會轉化成紅黑樹,但紅黑樹需要的佔用空間是鏈表的2倍,考慮到轉化時間和空間損耗,所以我們需要定義出轉化的邊界值,鏈表結點>=8時才進行樹化。
-
HashMap查找步驟:

- 鏈表查找 key是自定義類時需要重寫equals方法(來比較鏈表結點值是否相等)
// 採用自旋方式從鏈表中查找 key,e 初始為為鏈表的頭節點 do { // 如果當前節點 hash 等於 key 的 hash,並且 equals 相等,當前節點就是我們要找的節點 // 當 hash 衝突時,同一個 hash 值上是一個鏈表的時候,我們是通過 equals 方法來比較 key 是否相等的 if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) return e; // 否則,把當前節點的下一個節點拿出來繼續尋找 } while ((e = e.next) != null);- 紅黑樹查找 key是自定義類時需要重寫compator方法(來判斷紅黑樹往左子結點走還是往右走)

hash演算法精簡
使用異或計算hash,拿高16位異或低16位
static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); } key 在數組中的位置公式:tab[(n - 1) & hash]- h^(h>>>16),這麼做的好處是使大多數場景下,算出來的hash值比較分散。
hash 值算出來之後,要計算當前key在數組中的索引下標位置時,可以採用對數組長度取模,但是取模操作對於處理器的計算是比較慢的,數學上有個公式,當b是2的冪次方時,a%b=a&(b-1),所以此處索引位置的計算公式我們可以更換為:(n-1)&hash。

因為樹有可能退化到鏈表狀態,所以紅黑樹是一個二叉平衡樹,通過自旋來調整高度
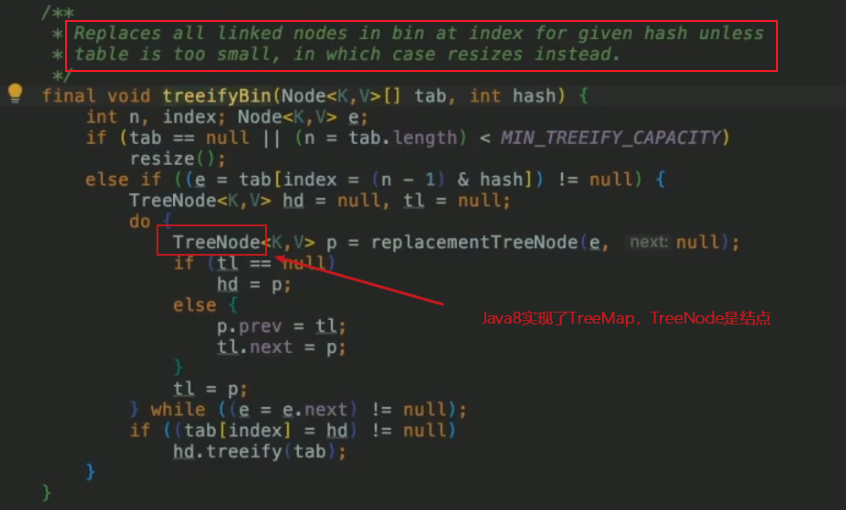
新增方法
- getOrDefault方法:如果 key 對應的值不存在,返回期望的默認值 defaultValue
public V getOrDefault(Object key, V defaultValue) { Node<K,V> e; return (e = getNode(hash(key), key)) == null ? defaultValue : e.value; }- putlfAbsent(K key,V value):如果map中存在key了,那麼value就不會覆蓋,如果不存在key,新增成功。
- compute 方法:允許我們把 key和value的值進行計算後,再put到map中,為防止key值不存在造成未知錯誤,
- computelfPresent方法:表示只有在key存在的時候,才執行計算
public void compute(){ HashMap<Integer,Integer> map = Maps.newHashMap(); map.put(10,10); log.info("compute 之前值為:{}",map.get(10)); map.compute(10,(key,value) -> key * value); log.info("compute 之後值為:{}",map.get(10)); // 還原測試值 map.put(10,10); // 如果為 11 的 key 不存在的話,需要注意 value 為空的情況,下面這行程式碼就會報空指針 // map.compute(11,(key,value) -> key * value); // 為了防止 key 不存在時導致的未知異常,我們一般有兩種辦法 // 1:自己判斷空指針 map.compute(11,(key,value) -> null == value ? null : key * value); // 2:computeIfPresent 方法裡面判斷 map.computeIfPresent(11,(key,value) -> key * value); log.info("computeIfPresent 之後值為:{}",map.get(11)); } 結果是: compute 之前值為:10 compute 之後值為:100 computeIfPresent 之後值為:null(這個結果中,可以看出,使用 computeIfPresent 避免了空指針)從前世到今生的奈何橋——default
- Java8在集合類上新增了很多方法,為什麼Java7中這些介面的的實現者不需要強制實現這些方法呢?
主要是因為這些新增的方法被default 關鍵字修飾了,default一旦修飾介面上的方法,我們需要在介面的方法中寫默認實現,並且子類無需強制實現這些方法,所以Java7介面的實現者無需感知。
總結:HashMap的三生三世
Java8在Java7的基礎上,做了一些改進和優化,通過default關鍵字來連接兩代。HashMap幾乎重寫了一套,所有的集合都新增了函數式的方法,比如說forEach,也新增了很多好用的函數。
