java大數據最全課程學習筆記(6)–MapReduce精通(二)–MapReduce框架原理
目前CSDN,部落格園,簡書同步發表中,更多精彩歡迎訪問我的gitee pages
MapReduce精通(二)
MapReduce框架原理
MapReduce工作流程
- 流程示意圖

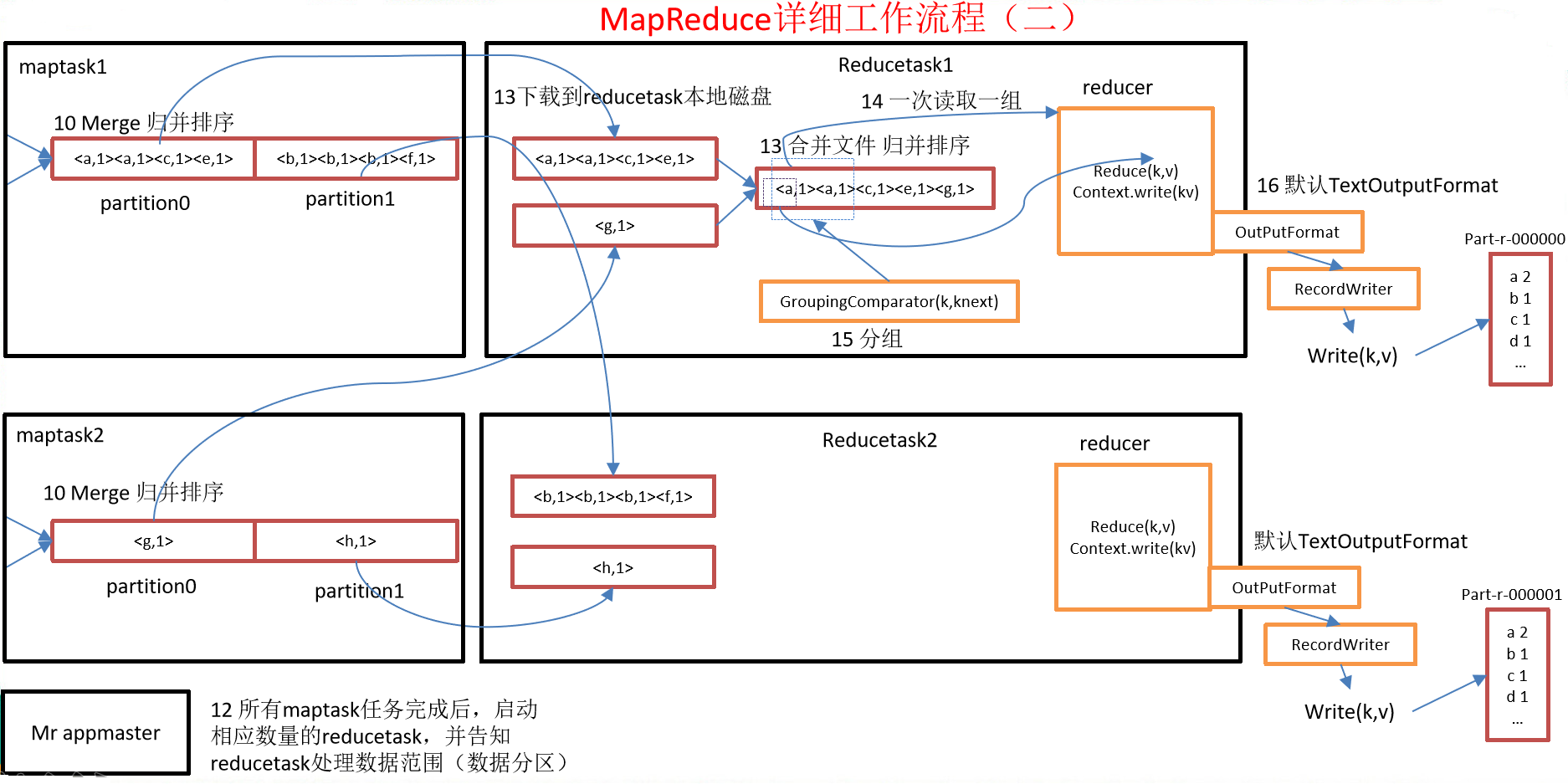
-
流程詳解
上面的流程是整個MapReduce最全工作流程,但是Shuffle過程只是從第7步開始到第16步結束,具體Shuffle過程詳解,如下:
-
MapTask收集我們的map()方法輸出的kv對,放到記憶體緩衝區中
-
從記憶體緩衝區不斷溢出本地磁碟文件,可能會溢出多個文件
-
多個溢出文件會被合併成大的溢出文件
-
在溢出過程及合併的過程中,都要調用Partitioner進行分區和針對key進行排序
-
ReduceTask根據自己的分區號,去各個MapTask機器上取相應的結果分區數據
-
ReduceTask會取到同一個分區的來自不同MapTask的結果文件,ReduceTask會將這些文件再進行合併(歸併排序)
-
合併成大文件後,Shuffle的過程也就結束了,後面進入ReduceTask的邏輯運算過程(從文件中取出一個一個的鍵值對Group,調用用戶自定義的reduce()方法)
注意:
Shuffle中的緩衝區大小會影響到MapReduce程式的執行效率,原則上說,緩衝區越大,磁碟io的次數越少,執行速度就越快。
緩衝區的大小可以通過參數調整,參數:io.sort.mb 默認100M。
-
-
源碼解析流程
context.write(k, NullWritable.get());
output.write(key, value);
collector.collect(key, value,partitioner.getPartition(key, value, partitions));
HashPartitioner();
collect()
close()
collect.flush()
sortAndSpill()
sort() QuickSort
mergeParts();

collector.close();

InputFormat數據輸入
切片與MapTask並行度決定機制
-
問題引出
MapTask的並行度決定Map階段的任務處理並發度,進而影響到整個Job的處理速度。
思考:1G的數據,啟動8個MapTask,提高的並發處理能力。那麼1K的數據,也啟動8個MapTask嗎?MapTask並行任務是否越多越好呢?
-
MapTask並行度決定機制
數據塊:Block是HDFS物理上把數據分成一塊一塊。
數據切片:數據切片只是在邏輯上對輸入進行分片,並不會在磁碟上將其切分成片進行存儲。
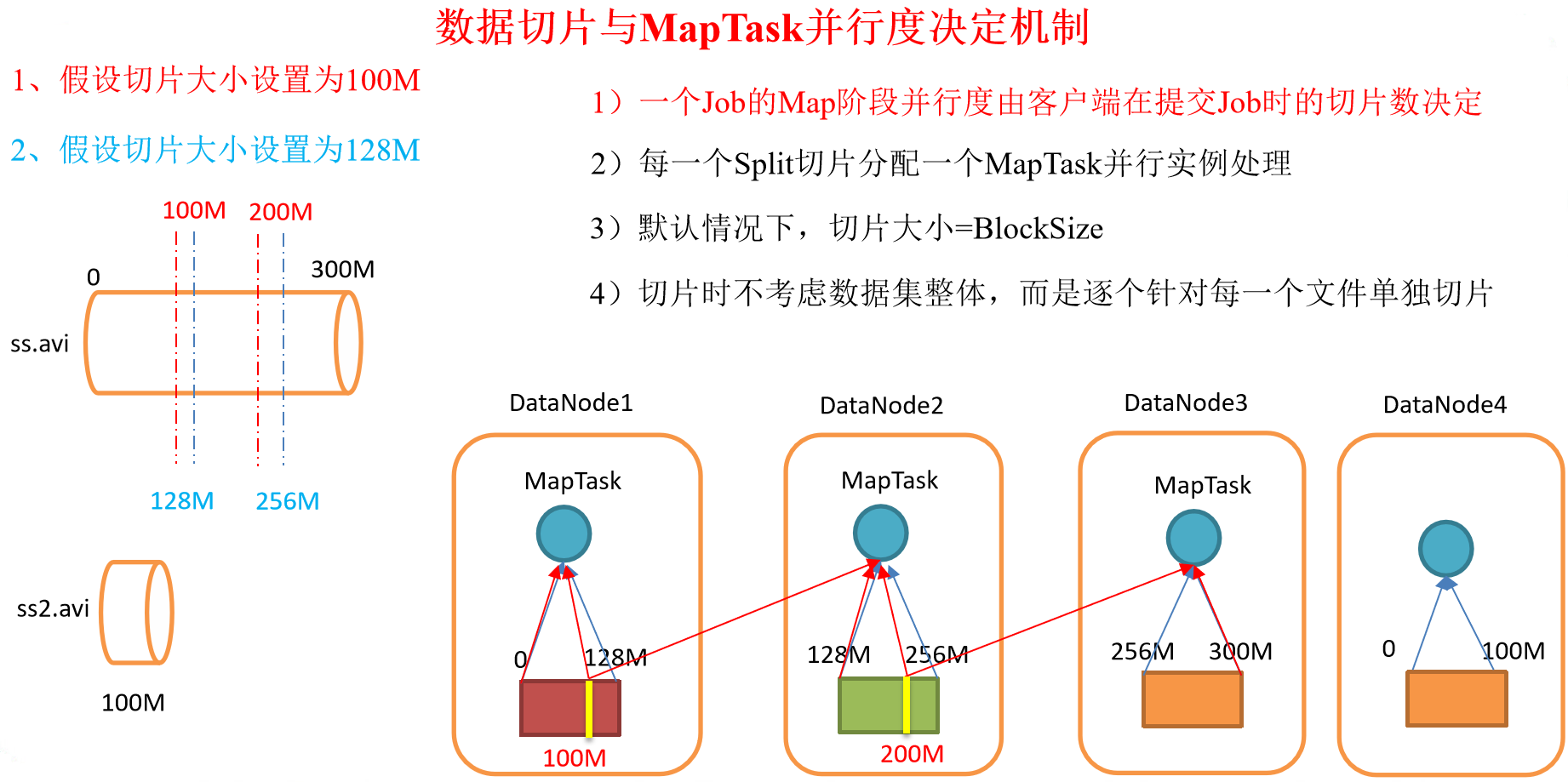

Job提交流程源碼和切片源碼詳解
- Job提交流程源碼詳解
waitForCompletion()
submit();
// 1建立連接
connect();
// 1)創建提交Job的代理
new Cluster(getConfiguration());
// (1)判斷是本地yarn還是遠程
initialize(jobTrackAddr, conf);
// 2 提交job
submitter.submitJobInternal(Job.this, cluster)
// 1)創建給集群提交數據的Stag路徑
Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf);
// 2)獲取jobid ,並創建Job路徑
JobID jobId = submitClient.getNewJobID();
// 3)拷貝jar包到集群
copyAndConfigureFiles(job, submitJobDir);
rUploader.uploadFiles(job, jobSubmitDir);
// 4)計算切片,生成切片規劃文件
writeSplits(job, submitJobDir);
maps = writeNewSplits(job, jobSubmitDir);
input.getSplits(job);
// 5)向Stag路徑寫XML配置文件
writeConf(conf, submitJobFile);
conf.writeXml(out);
// 6)提交Job,返回提交狀態
status = submitClient.submitJob(jobId, submitJobDir.toString(), job.getCredentials());

- FileInputFormat切片源碼解析(input.getSplits(job))
public List<InputSplit> getSplits(JobContext job) throws IOException {
StopWatch sw = new StopWatch().start();
// minSize從mapreduce.input.fileinputformat.split.minsize和1之間對比,取最大值
long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job));
// 讀取mapreduce.input.fileinputformat.split.maxsize,如果沒有設置使用Long.MaxValue作為默認值
long maxSize = getMaxSplitSize(job);
// generate splits
List<InputSplit> splits = new ArrayList<InputSplit>();
// 獲取當前Job輸入目錄中所有文件的狀態(元數據)
List<FileStatus> files = listStatus(job);
// 以文件為單位進行切片
for (FileStatus file: files) {
Path path = file.getPath();
long length = file.getLen();
if (length != 0) {
BlockLocation[] blkLocations;
if (file instanceof LocatedFileStatus) {
blkLocations = ((LocatedFileStatus) file).getBlockLocations();
} else {
FileSystem fs = path.getFileSystem(job.getConfiguration());
blkLocations = fs.getFileBlockLocations(file, 0, length);
}
// 判斷當前文件是否可切,如果可切,切片
if (isSplitable(job, path)) {
long blockSize = file.getBlockSize();
long splitSize = computeSplitSize(blockSize, minSize, maxSize);
// 聲明待切部分數據的餘量
long bytesRemaining = length;
// 如果 待切部分 / 片大小 > 1.1,先切去一片,再判斷
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(makeSplit(path, length-bytesRemaining, splitSize,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
bytesRemaining -= splitSize;
}
// 否則,將剩餘部分整個作為1片。 最後一片有可能超過片大小,但是不超過其1.1倍
if (bytesRemaining != 0) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(makeSplit(path, length-bytesRemaining, bytesRemaining,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
}
} else { // not splitable
// 如果不可切,整個文件作為1片!
splits.add(makeSplit(path, 0, length, blkLocations[0].getHosts(),
blkLocations[0].getCachedHosts()));
}
} else {
//Create empty hosts array for zero length files
// 如果文件是個空文件,創建一個切片對象,這個切片從當前文件的0offset起,向後讀取0個位元組
splits.add(makeSplit(path, 0, length, new String[0]));
}
}
// Save the number of input files for metrics/loadgen
job.getConfiguration().setLong(NUM_INPUT_FILES, files.size());
sw.stop();
if (LOG.isDebugEnabled()) {
LOG.debug("Total # of splits generated by getSplits: " + splits.size()
+ ", TimeTaken: " + sw.now(TimeUnit.MILLISECONDS));
}
return splits;
}

FileInputFormat切片機制

- FileInputFormat切片大小的參數配置

CombineTextInputFormat切片機制
框架默認的TextInputformat切片機制是對任務按文件規劃切片,不管文件多小,都會是一個單獨的切片,都會交給一個MapTask,這樣如果有大量小文件,就會產生大量的MapTask,處理效率極其低下。
-
應用場景:
CombineTextInputFormat用於小文件過多的場景,它可以將多個小文件從邏輯上規划到一個切片中,這樣,多個小文件就可以交給一個MapTask處理。
-
虛擬存儲切片最大值設置
CombineTextInputFormat.setMaxInputSplitSize(job, 4194304);// 4m
虛擬存儲切片最大值設置可以根據實際的小文件大小情況來設置具體的值。 -
切片機制
生成切片過程包括:虛擬存儲過程和切片過程二部分。
-
虛擬存儲過程:
-
將輸入目錄下所有文件按照文件名稱字典順序一次讀入,記錄文件大小,並累加計算所有文件的總長度。
-
根據是否設置setMaxInputSplitSize值,將每個文件劃分成一個一個setMaxInputSplitSize值大小的文件。
-
注意:當剩餘數據大小超過setMaxInputSplitSize值且不大於2倍setMaxInputSplitSize值,此時將文件均分成2個虛擬存儲塊(防止出現太小切片)。
例如setMaxInputSplitSize值為4M,最後文件剩餘的大小為4.02M,如果按照4M邏輯劃分,就會出現0.02M的小的虛擬存儲文件,所以將剩餘的4.02M文件切分成(2.01M和2.01M)兩個文件。
-
-
切片過程:
-
判斷虛擬存儲的文件大小是否大於setMaxInputSplitSize值,大於等於則單獨形成一個切片。
-
如果不大於則跟下一個虛擬存儲文件進行合併,共同形成一個切片。
-
測試舉例:有4個小文件大小分別為1.7M、5.1M、3.4M以及6.8M這四個小文件,則虛擬存儲之後形成6個文件塊,大小分別為:
1.7M,(2.55M、2.55M),3.4M以及(3.4M、3.4M)
最終會形成3個切片,大小分別為:
(1.7+2.55)M,(2.55+3.4)M,(3.4+3.4)M
-
-
CombineTextInputFormat案例實操
-
需求
將輸入的大量小文件合併成一個切片統一處理。
-
輸入數據
準備4個小文件
-
期望
期望一個切片處理4個文件
-
-
實現過程
-
隨便準備四個小文件,運行WordCount案例實操中的程式,觀察切片個數為4
number of splits:4 -
在WordcountDriver中增加如下程式碼,運行程式,並觀察運行的切片個數為1
-
驅動類中添加程式碼如下:
// 如果不設置InputFormat,它默認用的是TextInputFormat.class job.setInputFormatClass(CombineTextInputFormat.class); //虛擬存儲切片最大值設置4m CombineTextInputFormat.setMaxInputSplitSize(job, 4194304); -
運行如果為1個切片
number of splits:1
-
-
FileInputFormat實現類




KeyValueTextInputFormat使用案例
-
需求
統計輸入文件中每一行的第一個單詞相同的行數。
-
輸入數據
banzhang ni hao
xihuan hadoop banzhang
banzhang ni hao
xihuan hadoop banzhang
xihuan hadoop banzhang
banzhang ni hao
xihuan hadoop banzhang
-
期望結果數據
banzhang 2
xihuan 2
-
-
需求分析

-
程式碼實現
-
編寫Mapper類
package com.atguigu.mapreduce.KeyValueTextInputFormat; import java.io.IOException; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; //注意KEYIN和VALUEIN都是Text類型 public class KVTextMapper extends Mapper<Text, Text, Text, LongWritable>{ // 1 設置value LongWritable v = new LongWritable(1); @Override protected void map(Text key, Text value, Context context) throws IOException, InterruptedException { // banzhang ni hao // 2 寫出 context.write(key, v); } } -
編寫Reducer類
package com.atguigu.mapreduce.KeyValueTextInputFormat; import java.io.IOException; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class KVTextReducer extends Reducer<Text, LongWritable, Text, LongWritable>{ LongWritable v = new LongWritable(); @Override protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException { long sum = 0L; // 1 匯總統計 for (LongWritable value : values) { sum += value.get(); } v.set(sum); // 2 輸出 context.write(key, v); } } -
編寫Driver類
package com.atguigu.mapreduce.keyvaleTextInputFormat; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.KeyValueLineRecordReader; import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class KVTextDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Configuration conf = new Configuration(); // 設置切割符 conf.set(KeyValueLineRecordReader.KEY_VALUE_SEPERATOR, " "); // 獲取job對象 Job job = Job.getInstance(conf); // 設置jar包位置,關聯mapper和reducer job.setJarByClass(KVTextDriver.class); job.setMapperClass(KVTextMapper.class); job.setReducerClass(KVTextReducer.class); // 設置map輸出kv類型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(LongWritable.class); // 設置最終輸出kv類型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(LongWritable.class); // 設置輸入輸出數據路徑 FileInputFormat.setInputPaths(job, new Path(args[0])); // 設置輸入格式 job.setInputFormatClass(KeyValueTextInputFormat.class); // 設置輸出數據路徑 FileOutputFormat.setOutputPath(job, new Path(args[1])); // 提交job job.waitForCompletion(true); } }
-

NLineInputFormat使用案例
-
需求
對每個單詞進行個數統計,要求根據每個輸入文件的行數來規定輸出多少個切片。此案例要求每三行放入一個切片中。
-
輸入數據
banzhang ni hao
xihuan hadoop banzhang
banzhang ni hao
xihuan hadoop banzhang
banzhang ni hao
xihuan hadoop banzhang
banzhang ni hao
xihuan hadoop banzhang
banzhang ni hao
xihuan hadoop banzhang banzhang ni hao
xihuan hadoop banzhang
-
期望輸出數據
Number of splits:4
-
-
需求分析

-
程式碼實現
-
編寫Mapper類
package com.atguigu.mapreduce.nline; import java.io.IOException; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; public class NLineMapper extends Mapper<LongWritable, Text, Text, LongWritable>{ private Text k = new Text(); private LongWritable v = new LongWritable(1); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 1 獲取一行 String line = value.toString(); // 2 切割 String[] splited = line.split(" "); // 3 循環寫出 for (int i = 0; i < splited.length; i++) { k.set(splited[i]); context.write(k, v); } } } -
編寫Reducer類
package com.atguigu.mapreduce.nline; import java.io.IOException; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class NLineReducer extends Reducer<Text, LongWritable, Text, LongWritable>{ LongWritable v = new LongWritable(); @Override protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException { long sum = 0L; // 1 匯總 for (LongWritable value : values) { sum += value.get(); } v.set(sum); // 2 輸出 context.write(key, v); } } -
編寫Driver類
package com.atguigu.mapreduce.nline; import java.io.IOException; import java.net.URISyntaxException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.NLineInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class NLineDriver { public static void main(String[] args) throws IOException, URISyntaxException, ClassNotFoundException, InterruptedException { // 輸入輸出路徑需要根據自己電腦上實際的輸入輸出路徑設置 args = new String[] { "e:/input/inputword", "e:/output1" }; // 1 獲取job對象 Configuration configuration = new Configuration(); Job job = Job.getInstance(configuration); // 7設置每個切片InputSplit中劃分三條記錄 NLineInputFormat.setNumLinesPerSplit(job, 3); // 8使用NLineInputFormat處理記錄數 job.setInputFormatClass(NLineInputFormat.class); // 2設置jar包位置,關聯mapper和reducer job.setJarByClass(NLineDriver.class); job.setMapperClass(NLineMapper.class); job.setReducerClass(NLineReducer.class); // 3設置map輸出kv類型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(LongWritable.class); // 4設置最終輸出kv類型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(LongWritable.class); // 5設置輸入輸出數據路徑 FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); // 6提交job job.waitForCompletion(true); } }
-

自定義InputFormat

自定義InputFormat案例實操
無論HDFS還是MapReduce,在處理小文件時效率都非常低,但又難免面臨處理大量小文件的場景,此時,就需要有相應解決方案。可以自定義InputFormat實現小文件的合併。
-
需求
將多個小文件合併成一個SequenceFile文件(SequenceFile文件是Hadoop用來存儲二進位形式的key-value對的文件格式),SequenceFile裡面存儲著多個文件,存儲的形式為文件路徑+名稱為key,文件內容為value。
-
輸入數據



-
期望輸出文件格式(合併後的文件)
part-r-00000
-
需求分析

-
程式碼實現
-
自定義InputFromat
package com.atguigu.mapreduce.inputformat; import java.io.IOException; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.BytesWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.mapreduce.InputSplit; import org.apache.hadoop.mapreduce.JobContext; import org.apache.hadoop.mapreduce.RecordReader; import org.apache.hadoop.mapreduce.TaskAttemptContext; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; // 定義類繼承FileInputFormat public class WholeFileInputformat extends FileInputFormat<Text, BytesWritable>{ @Override protected boolean isSplitable(JobContext context, Path filename) { return false; } @Override public RecordReader<Text, BytesWritable> createRecordReader(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException { WholeRecordReader recordReader = new WholeRecordReader(); recordReader.initialize(split, context); return recordReader; } } -
自定義RecordReader類
package com.atguigu.mapreduce.inputformat; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FSDataInputStream; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.BytesWritable; import org.apache.hadoop.io.IOUtils; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.mapreduce.InputSplit; import org.apache.hadoop.mapreduce.RecordReader; import org.apache.hadoop.mapreduce.TaskAttemptContext; import org.apache.hadoop.mapreduce.lib.input.FileSplit; public class WholeRecordReader extends RecordReader<Text, BytesWritable>{ private Configuration configuration; private FileSplit split; private boolean isProgress= true; private BytesWritable value = new BytesWritable(); private Text k = new Text(); @Override public void initialize(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException { this.split = (FileSplit)split; configuration = context.getConfiguration(); } @Override public boolean nextKeyValue() throws IOException, InterruptedException { if (isProgress) { // 1 定義快取區 byte[] contents = new byte[(int)split.getLength()]; FileSystem fs = null; FSDataInputStream fis = null; try { // 2 獲取文件系統 Path path = split.getPath(); fs = path.getFileSystem(configuration); // 3 讀取數據 fis = fs.open(path); // 4 讀取文件內容 IOUtils.readFully(fis, contents, 0, contents.length); // 5 輸出文件內容 value.set(contents, 0, contents.length); // 6 獲取文件路徑及名稱 String name = split.getPath().toString(); // 7 設置輸出的key值 k.set(name); } catch (Exception e) { }finally { IOUtils.closeStream(fis); } isProgress = false; return true; } return false; } @Override public Text getCurrentKey() throws IOException, InterruptedException { return k; } @Override public BytesWritable getCurrentValue() throws IOException, InterruptedException { return value; } @Override public float getProgress() throws IOException, InterruptedException { return 0; } @Override public void close() throws IOException { } } -
編寫SequenceFileMapper類處理流程
package com.atguigu.mapreduce.inputformat; import java.io.IOException; import org.apache.hadoop.io.BytesWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.lib.input.FileSplit; public class SequenceFileMapper extends Mapper<Text, BytesWritable, Text, BytesWritable>{ @Override protected void map(Text key, BytesWritable value,Context context) throws IOException, InterruptedException { context.write(key, value); } } -
編寫SequenceFileReducer類處理流程
package com.atguigu.mapreduce.inputformat; import java.io.IOException; import org.apache.hadoop.io.BytesWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class SequenceFileReducer extends Reducer<Text, BytesWritable, Text, BytesWritable> { @Override protected void reduce(Text key, Iterable<BytesWritable> values, Context context) throws IOException,InterruptedException { context.write(key, values.iterator().next()); } } -
編寫SequenceFileDriver類處理流程
package com.atguigu.mapreduce.inputformat; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.BytesWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat; public class SequenceFileDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { // 輸入輸出路徑需要根據自己電腦上實際的輸入輸出路徑設置 args = new String[] { "e:/input/inputinputformat", "e:/output1" }; // 1 獲取job對象 Configuration conf = new Configuration(); Job job = Job.getInstance(conf); // 2 設置jar包存儲位置、關聯自定義的mapper和reducer job.setJarByClass(SequenceFileDriver.class); job.setMapperClass(SequenceFileMapper.class); job.setReducerClass(SequenceFileReducer.class); //7 設置輸入的inputFormat job.setInputFormatClass(WholeFileInputformat.class); //8 設置輸出的outputFormat job.setOutputFormatClass(SequenceFileOutputFormat.class); // 3 設置map輸出端的kv類型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(BytesWritable.class); // 4 設置最終輸出端的kv類型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(BytesWritable.class); // 5 設置輸入輸出路徑 FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); // 6 提交job boolean result = job.waitForCompletion(true); System.exit(result ? 0 : 1); } }
-
-




MapTask工作機制
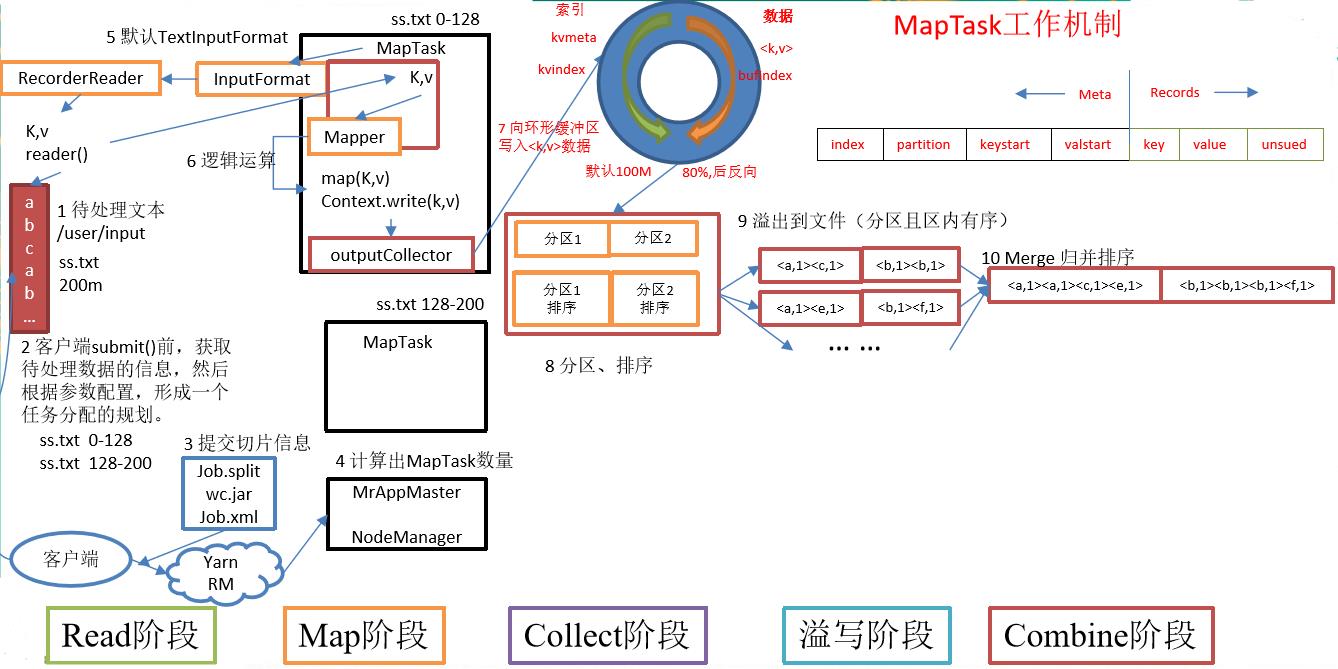
-
Read階段:MapTask通過用戶編寫的RecordReader,從輸入InputSplit中解析出一個個key/value。
-
Map階段:該節點主要是將解析出的key/value交給用戶編寫map()函數處理,併產生一系列新的key/value。
-
Collect收集階段:在用戶編寫map()函數中,當數據處理完成後,一般會調用OutputCollector.collect()輸出結果。在該函數內部,它會將生成的key/value分區(調用Partitioner),並寫入一個環形記憶體緩衝區中。
-
Spill階段:即「溢寫」,當環形緩衝區滿後,MapReduce會將數據寫到本地磁碟上,生成一個臨時文件。需要注意的是,將數據寫入本地磁碟之前,先要對數據進行一次本地排序,並在必要時對數據進行合併、壓縮等操作。
溢寫階段詳情:
- 利用快速排序演算法對快取區內的數據進行排序,排序方式是,先按照分區編號Partition進行排序,然後按照key進行排序。這樣,經過排序後,數據以分區為單位聚集在一起,且同一分區內所有數據按照key有序。
- 按照分區編號由小到大依次將每個分區中的數據寫入任務工作目錄下的臨時文件output/spillN.out(N表示當前溢寫次數)中。如果用戶設置了Combiner,則寫入文件之前,對每個分區中的數據進行一次聚集操作。
- 將分區數據的元資訊寫到記憶體索引數據結構SpillRecord中,其中每個分區的元資訊包括在臨時文件中的偏移量、壓縮前數據大小和壓縮後數據大小。如果當前記憶體索引大小超過1MB,則將記憶體索引寫到文件output/spillN.out.index中。
-
Combine階段:當所有數據處理完成後,MapTask對所有臨時文件進行一次合併,以確保最終只會生成一個數據文件。
當所有數據處理完後,MapTask會將所有臨時文件合併成一個大文件,並保存到文件output/file.out中,同時生成相應的索引文件output/file.out.index。
在進行文件合併過程中,MapTask以分區為單位進行合併。對於某個分區,它將採用多輪遞歸合併的方式。每輪合併io.sort.factor(默認10)個文件,並將產生的文件重新加入待合併列表中,對文件排序後,重複以上過程,直到最終得到一個大文件。
讓每個MapTask最終只生成一個數據文件,可避免同時打開大量文件和同時讀取大量小文件產生的隨機讀取帶來的開銷。
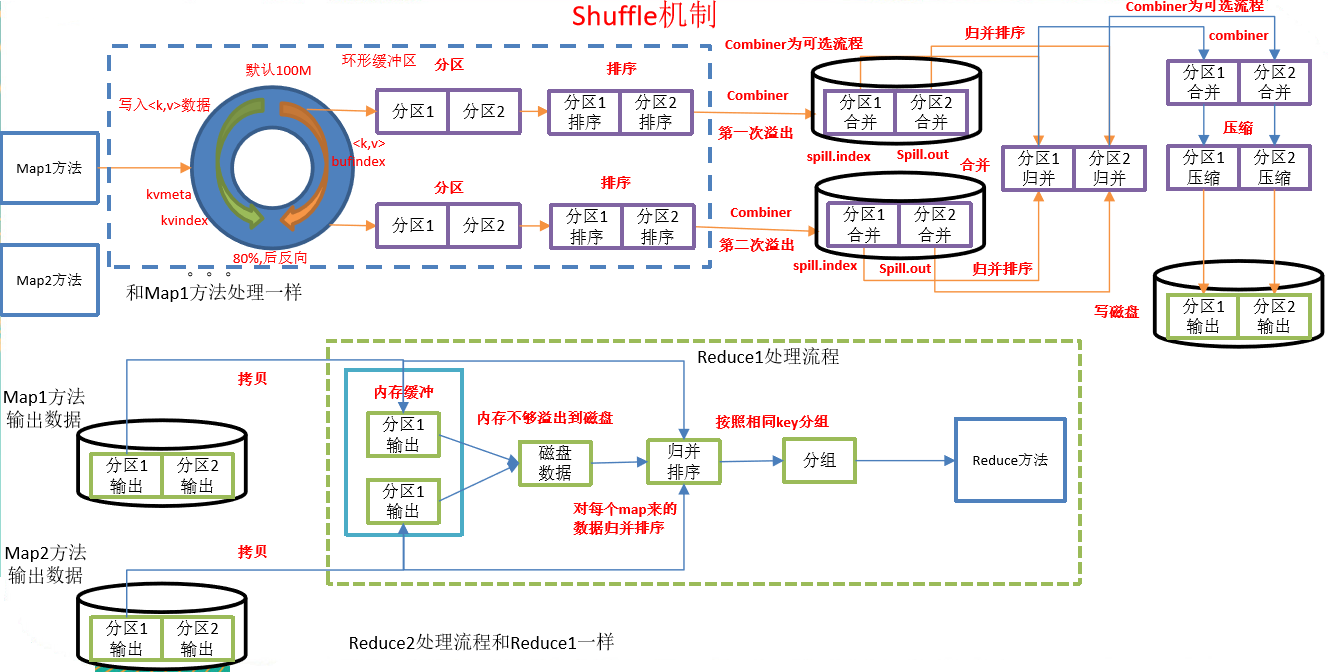
Shuffle機制
Shuffle機制
Mapreduce確保每個Reducer的輸入都是按key排序的。系統執行排序的過程(即將Mapper輸出作為輸入傳給Reducer)稱為Shuffle,如圖所示。
Partition分區



Partition分區案例實操
-
需求
將統計結果按照手機歸屬地不同省份輸出到不同文件中(分區)
-
輸入數據
1 13736230513 192.196.100.1 www.atguigu.com 2481 24681 200
2 13846544121 192.196.100.2 264 0 200
3 13956435636 192.196.100.3 132 1512 200
4 13966251146 192.168.100.1 240 0 404
5 18271575951 192.168.100.2 www.atguigu.com 1527 2106 200
6 84188413 192.168.100.3 www.atguigu.com 4116 1432 200
7 13590439668 192.168.100.4 1116 954 200
8 15910133277 192.168.100.5 www.hao123.com 3156 2936 200
9 13729199489 192.168.100.6 240 0 200
10 13630577991 192.168.100.7 www.shouhu.com 6960 690 200
11 15043685818 192.168.100.8 www.baidu.com 3659 3538 200
12 15959002129 192.168.100.9 www.atguigu.com 1938 180 500
13 13560439638 192.168.100.10 918 4938 200
14 13470253144 192.168.100.11 180 180 200
15 13682846555 192.168.100.12 www.qq.com 1938 2910 200
16 13992314666 192.168.100.13 www.gaga.com 3008 3720 200
17 13509468723 192.168.100.14 www.qinghua.com 7335 110349 40418 18390173782 192.168.100.15 www.sogou.com 9531 2412 200
19 13975057813 192.168.100.16 www.baidu.com 11058 48243 200
20 13768778790 192.168.100.17 120 120 200
21 13568436656 192.168.100.18 www.alibaba.com 2481 24681 200
22 13568436656 192.168.100.19 1116 954 200
-
期望輸出數據
手機號136、137、138、139開頭都分別放到一個獨立的4個文件中,其他開頭的放到一個文件中。
-
-
需求分析

-
在上一章節中的Hadoop序列化之序列化案例實操的基礎上,增加一個分區類
package com.atguigu.mapreduce.flowsum; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Partitioner; public class ProvincePartitioner extends Partitioner<Text, FlowBean> { @Override public int getPartition(Text key, FlowBean value, int numPartitions) { // 1 獲取電話號碼的前三位 String preNum = key.toString().substring(0, 3); int partition = 4; // 2 判斷是哪個省 if ("136".equals(preNum)) { partition = 0; }else if ("137".equals(preNum)) { partition = 1; }else if ("138".equals(preNum)) { partition = 2; }else if ("139".equals(preNum)) { partition = 3; } return partition; } } -
在驅動函數中增加自定義數據分區設置和ReduceTask設置
package com.atguigu.mapreduce.flowsum; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class FlowsumDriver { public static void main(String[] args) throws IllegalArgumentException, IOException, ClassNotFoundException, InterruptedException { // 輸入輸出路徑需要根據自己電腦上實際的輸入輸出路徑設置 args = new String[]{"e:/output1","e:/output2"}; // 1 獲取配置資訊,或者job對象實例 Configuration configuration = new Configuration(); Job job = Job.getInstance(configuration); // 6 指定本程式的jar包所在的本地路徑 job.setJarByClass(FlowsumDriver.class); // 2 指定本業務job要使用的mapper/Reducer業務類 job.setMapperClass(FlowCountMapper.class); job.setReducerClass(FlowCountReducer.class); // 3 指定mapper輸出數據的kv類型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(FlowBean.class); // 4 指定最終輸出的數據的kv類型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(FlowBean.class); // 8 指定自定義數據分區 job.setPartitionerClass(ProvincePartitioner.class); // 9 同時指定相應數量的reduce task job.setNumReduceTasks(5); // 5 指定job的輸入原始文件所在目錄 FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); // 7 將job中配置的相關參數,以及job所用的java類所在的jar包, 提交給yarn去運行 boolean result = job.waitForCompletion(true); System.exit(result ? 0 : 1); } }
WritableComparable排序
- 排序概述


- 排序的分類

-
自定義排序WritableComparable
bean對象實現WritableComparable介面重寫compareTo方法,就可以實現排序
@Override public int compareTo(FlowBean o) { // 倒序排列,從大到小 return this.sumFlow > o.getSumFlow() ? -1 : 1; }
WritableComparable排序案例實操(全排序)
-
需求
根據上一章節Hadoop序列化之序列化案例實操產生的結果再次對總流量進行排序。
-
輸入數據
原始數據

第一次處理後的數據
-
期望輸出數據
13509468723 7335 110349 117684
13736230513 2481 24681 27162
13956435636 132 1512 1644
13846544121 264 0 264
。。。 。。。
-
-
需求分析

-
程式碼實現
-
FlowBean對象在在需求1基礎上增加了比較功能
package com.at編寫Mapper類guigu.mapreduce.sort; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; import org.apache.hadoop.io.WritableComparable; public class FlowBean implements WritableComparable<FlowBean> { private long upFlow; private long downFlow; private long sumFlow; // 反序列化時,需要反射調用空參構造函數,所以必須有 public FlowBean() { super(); } public FlowBean(long upFlow, long downFlow) { super(); this.upFlow = upFlow; this.downFlow = downFlow; this.sumFlow = upFlow + downFlow; } public void set(long upFlow, long downFlow) { this.upFlow = upFlow; this.downFlow = downFlow; this.sumFlow = upFlow + downFlow; } public long getSumFlow() { return sumFlow; } public void setSumFlow(long sumFlow) { this.sumFlow = sumFlow; } public long getUpFlow() { return upFlow; } public void setUpFlow(long upFlow) { this.upFlow = upFlow; } public long getDownFlow() { return downFlow; } public void setDownFlow(long downFlow) { this.downFlow = downFlow; } /** * 序列化方法 * @param out * @throws IOException */ @Override public void write(DataOutput out) throws IOException { out.writeLong(upFlow); out.writeLong(downFlow); out.writeLong(sumFlow); } /** * 反序列化方法 注意反序列化的順序和序列化的順序完全一致 * @param in * @throws IOException */ @Override public void readFields(DataInput in) throws IOException { upFlow = in.readLong(); downFlow = in.readLong(); sumFlow = in.readLong(); } @Override public String toString() { return upFlow + "\t" + downFlow + "\t" + sumFlow; } @Override public int compareTo(FlowBean o) { // 倒序排列,從大到小 return this.sumFlow > o.getSumFlow() ? -1 : 1; } } -
編寫Mapper類
package com.atguigu.mapreduce.sort; import java.io.IOException; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; public class FlowCountSortMapper extends Mapper<LongWritable, Text, FlowBean, Text>{ FlowBean bean = new FlowBean(); Text v = new Text(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 1 獲取一行 String line = value.toString(); // 2 截取 String[] fields = line.split("\t"); // 3 封裝對象 String phoneNbr = fields[0]; long upFlow = Long.parseLong(fields[1]); long downFlow = Long.parseLong(fields[2]); bean.set(upFlow, downFlow); v.set(phoneNbr); // 4 輸出 context.write(bean, v); } } -
編寫Reducer類
package com.atguigu.mapreduce.sort; import java.io.IOException; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class FlowCountSortReducer extends Reducer<FlowBean, Text, Text, FlowBean>{ @Override protected void reduce(FlowBean key, Iterable<Text> values, Context context) throws IOException, InterruptedException { // 循環輸出,避免總流量相同情況 for (Text text : values) { context.write(text, key); } } } -
編寫Driver類
package com.atguigu.mapreduce.sort; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class FlowCountSortDriver { public static void main(String[] args) throws ClassNotFoundException, IOException, InterruptedException { // 輸入輸出路徑需要根據自己電腦上實際的輸入輸出路徑設置 args = new String[]{"e:/output1","e:/output2"}; // 1 獲取配置資訊,或者job對象實例 Configuration configuration = new Configuration(); Job job = Job.getInstance(configuration); // 6 指定本程式的jar包所在的本地路徑 job.setJarByClass(FlowCountSortDriver.class); // 2 指定本業務job要使用的mapper/Reducer業務類 job.setMapperClass(FlowCountSortMapper.class); job.setReducerClass(FlowCountSortReducer.class); // 3 指定mapper輸出數據的kv類型 job.setMapOutputKeyClass(FlowBean.class); job.setMapOutputValueClass(Text.class); // 4 指定最終輸出的數據的kv類型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(FlowBean.class); // 5 指定job的輸入原始文件所在目錄 FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); // 7 將job中配置的相關參數,以及job所用的java類所在的jar包, 提交給yarn去運行 boolean result = job.waitForCompletion(true); System.exit(result ? 0 : 1); } }
-



WritableComparable排序案例實操(區內排序)
-
需求
要求每個省份手機號輸出的文件中按照總流量內部排序。
-
需求分析
基於前一個需求,增加自定義分區類,分區按照省份手機號設置。

-
案例實操
-
增加自定義分區類
package com.atguigu.mapreduce.sort; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Partitioner; public class ProvincePartitioner extends Partitioner<FlowBean, Text> { @Override public int getPartition(FlowBean key, Text value, int numPartitions) { // 1 獲取手機號碼前三位 String preNum = value.toString().substring(0, 3); int partition = 4; // 2 根據手機號歸屬地設置分區 if ("136".equals(preNum)) { partition = 0; }else if ("137".equals(preNum)) { partition = 1; }else if ("138".equals(preNum)) { partition = 2; }else if ("139".equals(preNum)) { partition = 3; } return partition; } } -
在驅動類中添加分區類
// 載入自定義分區類 job.setPartitionerClass(FlowSortPartitioner.class); // 設置Reducetask個數 job.setNumReduceTasks(5);
-

Combiner合併

(6)自定義Combiner實現步驟
-
自定義一個Combiner繼承Reducer,重寫Reduce方法
public class WordcountCombiner extends Reducer<Text, IntWritable, Text,IntWritable>{ @Override protected void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException { // 1 匯總操作 int count = 0; for(IntWritable v :values){ count += v.get(); } // 2 寫出 context.write(key, new IntWritable(count)); } } -
在Job驅動類中設置:
job.setCombinerClass(WordcountCombiner.class);
Combiner合併案例實操
-
需求
統計過程中對每一個MapTask的輸出進行局部匯總,以減小網路傳輸量即採用Combiner功能。
-
數據輸入
banzhang ni hao
xihuan hadoop banzhang
banzhang ni hao
xihuan hadoop banzhang
-
期望輸出數據
期望:Combine輸入數據多,輸出時經過合併,輸出數據降低。
-
-
需求分析

-
案例實操-方案一
-
增加一個WordcountCombiner類繼承Reducer
package com.atguigu.mr.combiner; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class WordcountCombiner extends Reducer<Text, IntWritable, Text, IntWritable>{ IntWritable v = new IntWritable(); @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { // 1 匯總 int sum = 0; for(IntWritable value :values){ sum += value.get(); } v.set(sum); // 2 寫出 context.write(key, v); } } -
在WordcountDriver驅動類中指定Combiner
// 指定需要使用combiner,以及用哪個類作為combiner的邏輯 job.setCombinerClass(WordcountCombiner.class);
-
-
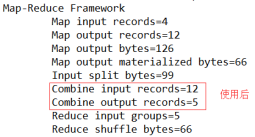
案例實操-方案二
將WordcountReducer作為Combiner在WordcountDriver驅動類中指定
- 使用後

GroupingComparator分組(輔助排序)
對Reduce階段的數據根據某一個或幾個欄位進行分組。
GroupingComparator分組案例實操
-
需求
有如下訂單數據
訂單id 商品id 成交金額 0000001 Pdt_01 222.8 Pdt_06 25.8 0000002 Pdt_03 522.8 Pdt_04 122.4 Pdt_05 722.4 0000003 Pdt_07 232.8 Pdt_02 33.8 現在需要求出每一個訂單中最貴的商品。
-
輸入數據
輸入數據
0000001 Pdt_01 222.80000002 Pdt_06 722.4
0000001 Pdt_05 25.8
0000003 Pdt_01 232.8
0000003 Pdt_01 33.8
0000002 Pdt_03 522.8
0000002 Pdt_04 122.4
-
期望輸出數據
1 222.8
2 722.4
3 232.8
-
-
需求分析
-
利用「訂單id和成交金額」作為key,可以將Map階段讀取到的所有訂單數據按照id分區,按照金額排序,發送到Reduce。
-
在Reduce端利用groupingComparator將訂單id相同的kv聚合成組,然後取第一個即是最大值,如圖所示。

-
-
程式碼實現
-
定義訂單資訊OrderBean類
package com.atguigu.mapreduce.order; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; import org.apache.hadoop.io.WritableComparable; public class OrderBean implements WritableComparable<OrderBean> { private int order_id; // 訂單id號 private double price; // 價格 public OrderBean() { super(); } public OrderBean(int order_id, double price) { super(); this.order_id = order_id; this.price = price; } @Override public void write(DataOutput out) throws IOException { out.writeInt(order_id); out.writeDouble(price); } @Override public void readFields(DataInput in) throws IOException { order_id = in.readInt(); price = in.readDouble(); } @Override public String toString() { return order_id + "\t" + price; } public int getOrder_id() { return order_id; } public void setOrder_id(int order_id) { this.order_id = order_id; } public double getPrice() { return price; } public void setPrice(double price) { this.price = price; } // 二次排序 @Override public int compareTo(OrderBean o) { int result; if (order_id > o.getOrder_id()) { result = 1; } else if (order_id < o.getOrder_id()) { result = -1; } else { // 價格倒序排序 result = price > o.getPrice() ? -1 : 1; } return result; } } -
編寫OrderSortMapper類
package com.atguigu.mapreduce.order; import java.io.IOException; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; public class OrderMapper extends Mapper<LongWritable, Text, OrderBean, NullWritable> { OrderBean k = new OrderBean(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 1 獲取一行 String line = value.toString(); // 2 截取 String[] fields = line.split("\t"); // 3 封裝對象 k.setOrder_id(Integer.parseInt(fields[0])); k.setPrice(Double.parseDouble(fields[2])); // 4 寫出 context.write(k, NullWritable.get()); } } -
編寫OrderSortGroupingComparator類
package com.atguigu.mapreduce.order; import org.apache.hadoop.io.WritableComparable; import org.apache.hadoop.io.WritableComparator; public class OrderGroupingComparator extends WritableComparator { protected OrderGroupingComparator() { super(OrderBean.class, true); } @Override public int compare(WritableComparable a, WritableComparable b) { OrderBean aBean = (OrderBean) a; OrderBean bBean = (OrderBean) b; int result; if (aBean.getOrder_id() > bBean.getOrder_id()) { result = 1; } else if (aBean.getOrder_id() < bBean.getOrder_id()) { result = -1; } else { result = 0; } return result; } } -
編寫OrderSortReducer類
package com.atguigu.mapreduce.order; import java.io.IOException; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.mapreduce.Reducer; public class OrderReducer extends Reducer<OrderBean, NullWritable, OrderBean, NullWritable> { @Override protected void reduce(OrderBean key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException { context.write(key, NullWritable.get()); } } -
編寫OrderSortDriver類
package com.atguigu.mapreduce.order; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class OrderDriver { public static void main(String[] args) throws Exception, IOException { // 輸入輸出路徑需要根據自己電腦上實際的輸入輸出路徑設置 args = new String[]{"e:/input/inputorder" , "e:/output1"}; // 1 獲取配置資訊 Configuration conf = new Configuration(); Job job = Job.getInstance(conf); // 2 設置jar包載入路徑 job.setJarByClass(OrderDriver.class); // 3 載入map/reduce類 job.setMapperClass(OrderMapper.class); job.setReducerClass(OrderReducer.class); // 4 設置map輸出數據key和value類型 job.setMapOutputKeyClass(OrderBean.class); job.setMapOutputValueClass(NullWritable.class); // 5 設置最終輸出數據的key和value類型 job.setOutputKeyClass(OrderBean.class); job.setOutputValueClass(NullWritable.class); // 6 設置輸入數據和輸出數據路徑 FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); // 8 設置reduce端的分組 job.setGroupingComparatorClass(OrderGroupingComparator.class); // 7 提交 boolean result = job.waitForCompletion(true); System.exit(result ? 0 : 1); } }
-

ReduceTask工作機制
-
ReduceTask工作機制
ReduceTask工作機制,如圖所示
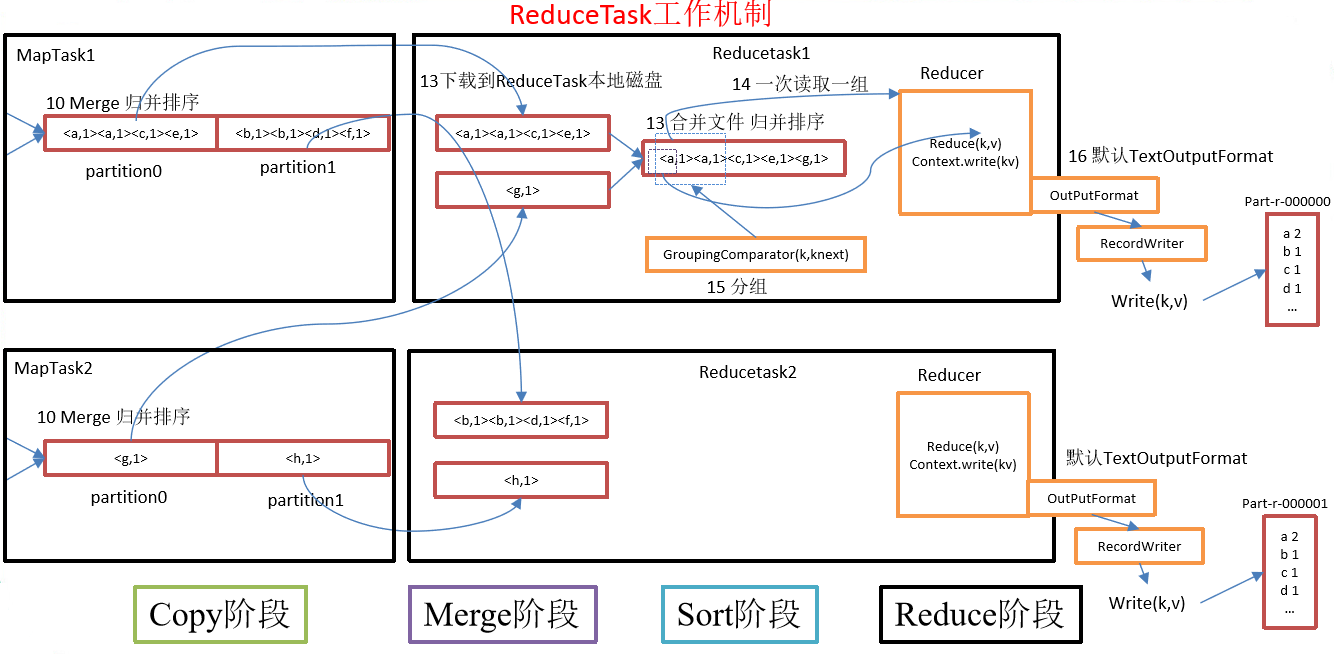
- Copy階段:ReduceTask從各個MapTask上遠程拷貝一片數據,並針對某一片數據,如果其大小超過一定閾值,則寫到磁碟上,否則直接放到記憶體中。
- Merge階段:在遠程拷貝數據的同時,ReduceTask啟動了兩個後台執行緒對記憶體和磁碟上的文件進行合併,以防止記憶體使用過多或磁碟上文件過多。
- Sort階段:按照MapReduce語義,用戶編寫reduce()函數輸入數據是按key進行聚集的一組數據。為了將key相同的數據聚在一起,Hadoop採用了基於排序的策略。由於各個MapTask已經實現對自己的處理結果進行了局部排序,因此,ReduceTask只需對所有數據進行一次歸併排序即可。
- Reduce階段:reduce()函數將計算結果寫到HDFS上。
-
設置ReduceTask並行度(個數)
ReduceTask的並行度同樣影響整個job的執行並發度和執行效率,但與MapTask的並發數由切片數決定不同,Reducetask數量的決定是可以直接手動設置:
//默認值是1,手動設置為4 job.setNumReduceTasks(4); -
注意事項

-
實驗:測試ReduceTask多少合適。
-
實驗環境:1個Master節點,16個Slave節點:CPU:8GHZ,記憶體: 2G
-
實驗結論:
改變ReduceTask (數據量為1GB)
Map task =16 Reduce task 1 5 10 15 16 20 25 30 45 60 總時間 892 146 110 92 88 100 128 101 145 104
-


OutputFormat數據輸出
OutputFormat介面實現類

自定義OutputFormat

自定義OutputFormat案例實操
-
需求
過濾輸入的log日誌,包含atguigu的網站輸出到e:/atguigu.log,不包含atguigu的網站輸出到e:/other.log。
-
輸入數據
-
期望輸出數據
atguigu.log
other.log
-
-
需求分析

-
案例實操
-
自定義一個OutputFormat類
package com.atguigu.mapreduce.outputformat; import java.io.IOException; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.RecordWriter; import org.apache.hadoop.mapreduce.TaskAttemptContext; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class FilterOutputFormat extends FileOutputFormat<Text, NullWritable>{ @Override public RecordWriter<Text, NullWritable> getRecordWriter(TaskAttemptContext job) throws IOException,InterruptedException { // 創建一個RecordWriter return new FilterRecordWriter(job); } } -
編寫RecordWriter類
package com.atguigu.mapreduce.outputformat; import java.io.IOException; import org.apache.hadoop.fs.FSDataOutputStream; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.RecordWriter; import org.apache.hadoop.mapreduce.TaskAttemptContext; public class FilterRecordWriter extends RecordWriter<Text, NullWritable> { FSDataOutputStream atguiguOut = null; FSDataOutputStream otherOut = null; public FilterRecordWriter(TaskAttemptContext job) { // 1 獲取文件系統 FileSystem fs; try { fs = FileSystem.get(job.getConfiguration()); // 2 創建輸出文件路徑 Path atguiguPath = new Path("e:/atguigu.log"); Path otherPath = new Path("e:/other.log"); // 3 創建輸出流 atguiguOut = fs.create(atguiguPath); otherOut = fs.create(otherPath); } catch (IOException e) { e.printStackTrace(); } } @Override public void write(Text key, NullWritable value) throws IOException, InterruptedException { // 判斷是否包含「atguigu」輸出到不同文件 if (key.toString().contains("atguigu")) { atguiguOut.write(key.toString().getBytes()); } else { otherOut.write(key.toString().getBytes()); } } @Override public void close(TaskAttemptContext context) throws IOException, InterruptedException { // 關閉資源 if (atguiguOut != null) { atguiguOut.close(); } if (otherOut != null) { otherOut.close(); } } } -
編寫FilterMapper類
package com.atguigu.mapreduce.outputformat; import java.io.IOException; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; public class FilterMapper extends Mapper<LongWritable, Text, Text, NullWritable>{ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 寫出 context.write(value, NullWritable.get()); } } -
編寫FilterReducer類
package com.atguigu.mapreduce.outputformat; import java.io.IOException; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class FilterReducer extends Reducer<Text, NullWritable, Text, NullWritable> { Text k = new Text(); @Override protected void reduce(Text key, Iterable<NullWritable> values, Context context) throws IOException,InterruptedException { String line = key.toString(); line = line + "\r\n"; k.set(line); context.write(k, NullWritable.get()); } } -
編寫FilterDriver類
package com.atguigu.mapreduce.outputformat; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class FilterDriver { public static void main(String[] args) throws Exception { // 輸入輸出路徑需要根據自己電腦上實際的輸入輸出路徑設置 args = new String[] { "e:/input/inputoutputformat", "e:/output2" }; Configuration conf = new Configuration(); Job job = Job.getInstance(conf); job.setJarByClass(FilterDriver.class); job.setMapperClass(FilterMapper.class); job.setReducerClass(FilterReducer.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(NullWritable.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(NullWritable.class); // 要將自定義的輸出格式組件設置到job中 job.setOutputFormatClass(FilterOutputFormat.class); FileInputFormat.setInputPaths(job, new Path(args[0])); // 雖然我們自定義了outputformat,但是因為我們的outputformat繼承自fileoutputformat // 而fileoutputformat要輸出一個_SUCCESS文件,所以,在這還得指定一個輸出目錄 FileOutputFormat.setOutputPath(job, new Path(args[1])); boolean result = job.waitForCompletion(true); System.exit(result ? 0 : 1); } }
-

Join多種應用
Reduce Join工作原理及缺點

Reduce Join案例實操
-
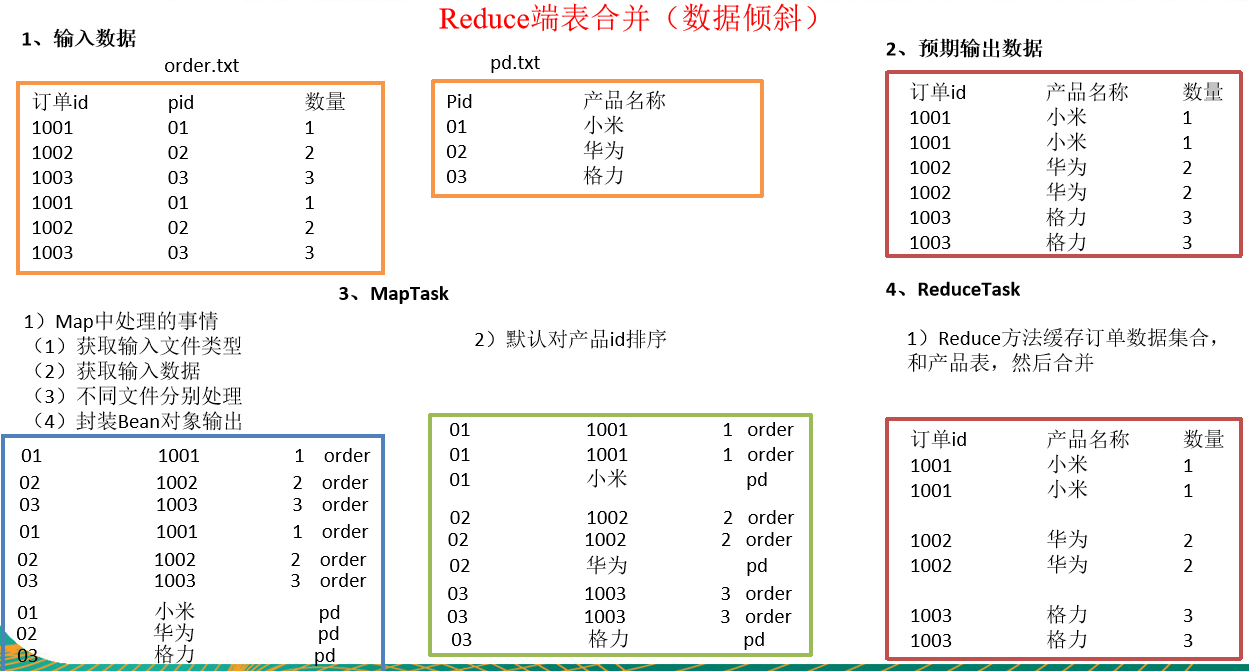
需求
order.txt
id pid amount 1001 01 1 1002 02 2 1003 03 3 1004 01 4 1005 02 5 1006 03 6 pd.txt
pid pname 01 小米 02 華為 03 格力 將商品資訊表中數據根據商品pid合併到訂單數據表中。
最終數據形式
id pname amount 1001 小米 1 1004 小米 4 1002 華為 2 1005 華為 5 1003 格力 3 1006 格力 6 -
需求分析
通過將關聯條件作為Map輸出的key,將兩表滿足Join條件的數據並攜帶數據所來源的文件資訊,發往同一個ReduceTask,在Reduce中進行數據的串聯,如圖所示
-
程式碼實現
-
創建商品和訂合併後的Bean類
package com.atguigu.mapreduce.table; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; import org.apache.hadoop.io.Writable; public class TableBean implements Writable { private String order_id; // 訂單id private String p_id; // 產品id private int amount; // 產品數量 private String pname; // 產品名稱 private String flag; // 表的標記 public TableBean() { super(); } public TableBean(String order_id, String p_id, int amount, String pname, String flag) { super(); this.order_id = order_id; this.p_id = p_id; this.amount = amount; this.pname = pname; this.flag = flag; } public String getFlag() { return flag; } public void setFlag(String flag) { this.flag = flag; } public String getOrder_id() { return order_id; } public void setOrder_id(String order_id) { this.order_id = order_id; } public String getP_id() { return p_id; } public void setP_id(String p_id) { this.p_id = p_id; } public int getAmount() { return amount; } public void setAmount(int amount) { this.amount = amount; } public String getPname() { return pname; } public void setPname(String pname) { this.pname = pname; } @Override public void write(DataOutput out) throws IOException { out.writeUTF(order_id); out.writeUTF(p_id); out.writeInt(amount); out.writeUTF(pname); out.writeUTF(flag); } @Override public void readFields(DataInput in) throws IOException { this.order_id = in.readUTF(); this.p_id = in.readUTF(); this.amount = in.readInt(); this.pname = in.readUTF(); this.flag = in.readUTF(); } @Override public String toString() { return order_id + "\t" + pname + "\t" + amount + "\t" ; } } -
編寫TableMapper類
package com.atguigu.mapreduce.table; import java.io.IOException; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.lib.input.FileSplit; public class TableMapper extends Mapper<LongWritable, Text, Text, TableBean>{ String name; TableBean bean = new TableBean(); Text k = new Text(); @Override protected void setup(Context context) throws IOException, InterruptedException { // 1 獲取輸入文件切片 FileSplit split = (FileSplit) context.getInputSplit(); // 2 獲取輸入文件名稱 name = split.getPath().getName(); } @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 1 獲取輸入數據 String line = value.toString(); // 2 不同文件分別處理 if (name.startsWith("order")) {// 訂單表處理 // 2.1 切割 String[] fields = line.split("\t"); // 2.2 封裝bean對象 bean.setOrder_id(fields[0]); bean.setP_id(fields[1]); bean.setAmount(Integer.parseInt(fields[2])); bean.setPname(""); bean.setFlag("other"); k.set(fields[1]); }else {// 產品表處理 // 2.3 切割 String[] fields = line.split("\t"); // 2.4 封裝bean對象 bean.setP_id(fields[0]); bean.setPname(fields[1]); bean.setFlag("pd"); bean.setAmount(0); bean.setOrder_id(""); k.set(fields[0]); } // 3 寫出 context.write(k, bean); } } -
編寫TableReducer類
package com.atguigu.mapreduce.table; import java.io.IOException; import java.util.ArrayList; import org.apache.commons.beanutils.BeanUtils; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class TableReducer extends Reducer<Text, TableBean, TableBean, NullWritable> { @Override protected void reduce(Text key, Iterable<TableBean> values, Context context) throws IOException, InterruptedException { // 1準備存儲訂單的集合 ArrayList<TableBean> orderBeans = new ArrayList<>(); // 2 準備bean對象 TableBean pdBean = new TableBean(); for (TableBean bean : values) { if ("order".equals(bean.getFlag())) {// 訂單表 // 拷貝傳遞過來的每條訂單數據到集合中 TableBean orderBean = new TableBean(); try { BeanUtils.copyProperties(orderBean, bean); } catch (Exception e) { e.printStackTrace(); } orderBeans.add(orderBean); } else {// 產品表 try { // 拷貝傳遞過來的產品表到記憶體中 BeanUtils.copyProperties(pdBean, bean); } catch (Exception e) { e.printStackTrace(); } } } // 3 表的拼接 for(TableBean bean:orderBeans){ bean.setPname (pdBean.getPname()); // 4 數據寫出去 context.write(bean, NullWritable.get()); } } } -
編寫TableDriver類
package com.atguigu.mapreduce.table; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class TableDriver { public static void main(String[] args) throws Exception { // 0 根據自己電腦路徑重新配置 args = new String[]{"e:/input/inputtable","e:/output1"}; // 1 獲取配置資訊,或者job對象實例 Configuration configuration = new Configuration(); Job job = Job.getInstance(configuration); // 2 指定本程式的jar包所在的本地路徑 job.setJarByClass(TableDriver.class); // 3 指定本業務job要使用的Mapper/Reducer業務類 job.setMapperClass(TableMapper.class); job.setReducerClass(TableReducer.class); // 4 指定Mapper輸出數據的kv類型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(TableBean.class); // 5 指定最終輸出的數據的kv類型 job.setOutputKeyClass(TableBean.class); job.setOutputValueClass(NullWritable.class); // 6 指定job的輸入原始文件所在目錄 FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); // 7 將job中配置的相關參數,以及job所用的java類所在的jar包, 提交給yarn去運行 boolean result = job.waitForCompletion(true); System.exit(result ? 0 : 1); } }
-
-
測試
運行程式查看結果
1001 小米 1
1001 小米 1
1002 華為 2
1002 華為 2
1003 格力 3
1003 格力 3
-
總結
缺點:這種方式中,合併的操作是在Reduce階段完成,Reduce端的處理壓力太大,Map節點的運算負載則很低,資源利用率不高,且在Reduce階段極易產生數據傾斜。
解決方案:Map端實現數據合併

Map Join
-
使用場景
Map Join適用於一張表十分小、一張表很大的場景。
-
優點
思考:在Reduce端處理過多的表,非常容易產生數據傾斜。怎麼辦?
在Map端快取多張表,提前處理業務邏輯,這樣增加Map端業務,減少Reduce端數據的壓力,儘可能的減少數據傾斜。
-
具體辦法:採用DistributedCache
-
在Mapper的setup階段,將文件讀取到快取集合中。
-
在驅動函數中載入快取。
// 快取普通文件到Task運行節點。 job.addCacheFile(new URI("file://e:/cache/pd.txt"));
-
Map Join案例實操
-
需求
order.txt
id pid amount 1001 01 1 1002 02 2 1003 03 3 1004 01 4 1005 02 5 1006 03 6 pd.txt
pid pname 01 小米 02 華為 03 格力 將商品資訊表中數據根據商品pid合併到訂單數據表中。
id pname amount 1001 小米 1 1004 小米 4 1002 華為 2 1005 華為 5 1003 格力 3 1006 格力 6 -
需求分析
MapJoin適用於關聯表中有小表的情形;

-
實現程式碼
-
先在驅動模組中添加快取文件
package test; import java.net.URI; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class DistributedCacheDriver { public static void main(String[] args) throws Exception { // 0 根據自己電腦路徑重新配置 args = new String[]{"e:/input/inputtable2", "e:/output1"}; // 1 獲取job資訊 Configuration configuration = new Configuration(); Job job = Job.getInstance(configuration); // 2 設置載入jar包路徑 job.setJarByClass(DistributedCacheDriver.class); // 3 關聯map job.setMapperClass(DistributedCacheMapper.class); // 4 設置最終輸出數據類型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(NullWritable.class); // 5 設置輸入輸出路徑 FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); // 6 載入快取數據 job.addCacheFile(new URI("file:///e:/input/inputcache/pd.txt")); // 7 Map端Join的邏輯不需要Reduce階段,設置reduceTask數量為0 job.setNumReduceTasks(0); // 8 提交 boolean result = job.waitForCompletion(true); System.exit(result ? 0 : 1); } } -
讀取快取的文件數據
package test; import java.io.BufferedReader; import java.io.FileInputStream; import java.io.IOException; import java.io.InputStreamReader; import java.util.HashMap; import java.util.Map; import org.apache.commons.lang.StringUtils; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; public class DistributedCacheMapper extends Mapper<LongWritable, Text, Text, NullWritable>{ Map<String, String> pdMap = new HashMap<>(); @Override protected void setup(Mapper<LongWritable, Text, Text, NullWritable>.Context context) throws IOException,InterruptedException { // 1 獲取快取的文件 BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream("pd.txt"),"UTF-8")); String line; while(StringUtils.isNotEmpty(line = reader.readLine())){ // 2 切割 String[] fields = line.split("\t"); // 3 快取數據到集合 pdMap.put(fields[0], fields[1]); } // 4 關流 reader.close(); } Text k = new Text(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 1 獲取一行 String line = value.toString(); // 2 截取 String[] fields = line.split("\t"); // 3 獲取產品id String pId = fields[1]; // 4 獲取商品名稱 String pdName = pdMap.get(pId); // 5 拼接 k.set(line + "\t"+ pdName); // 6 寫出 context.write(k, NullWritable.get()); } }
-

計數器應用

數據清洗(ETL)
在運行核心業務MapReduce程式之前,往往要先對數據進行清洗,清理掉不符合用戶要求的數據。清理的過程往往只需要運行Mapper程式,不需要運行Reduce程式。
數據清洗案例實操-簡單解析版
-
需求
去除日誌中欄位長度小於等於11的日誌。
-
輸入數據
- 內容太多,就不在此粘貼了,大家可自行創建測試數據

-
期望輸出數據
每行欄位長度都大於11。
-
-
需求分析
需要在Map階段對輸入的數據根據規則進行過濾清洗。
-
實現程式碼
-
編寫LogMapper類
package com.atguigu.mapreduce.weblog; import java.io.IOException; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; public class LogMapper extends Mapper<LongWritable, Text, Text, NullWritable>{ Text k = new Text(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 1 獲取1行數據 String line = value.toString(); // 2 解析日誌 boolean result = parseLog(line,context); // 3 日誌不合法退出 if (!result) { return; } // 4 設置key k.set(line); // 5 寫出數據 context.write(k, NullWritable.get()); } // 2 解析日誌 private boolean parseLog(String line, Context context) { // 1 截取 String[] fields = line.split(" "); // 2 日誌長度大於11的為合法 if (fields.length > 11) { // 系統計數器 context.getCounter("map", "true").increment(1); return true; }else { context.getCounter("map", "false").increment(1); return false; } } } -
編寫LogDriver類
package com.atguigu.mapreduce.weblog; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class LogDriver { public static void main(String[] args) throws Exception { // 輸入輸出路徑需要根據自己電腦上實際的輸入輸出路徑設置 args = new String[] { "e:/input/inputlog", "e:/output1" }; // 1 獲取job資訊 Configuration conf = new Configuration(); Job job = Job.getInstance(conf); // 2 載入jar包 job.setJarByClass(LogDriver.class); // 3 關聯map job.setMapperClass(LogMapper.class); // 4 設置最終輸出類型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(NullWritable.class); // 設置reducetask個數為0 job.setNumReduceTasks(0); // 5 設置輸入和輸出路徑 FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); // 6 提交 job.waitForCompletion(true); } }
-

數據清洗案例實操-複雜解析版
-
需求
對Web訪問日誌中的各欄位識別切分,去除日誌中不合法的記錄。根據清洗規則,輸出過濾後的數據。
-
實現程式碼
-
定義一個bean,用來記錄日誌數據中的各數據欄位
package com.atguigu.mapreduce.log; public class LogBean { private String remote_addr;// 記錄客戶端的ip地址 private String remote_user;// 記錄客戶端用戶名稱,忽略屬性"-" private String time_local;// 記錄訪問時間與時區 private String request;// 記錄請求的url與http協議 private String status;// 記錄請求狀態;成功是200 private String body_bytes_sent;// 記錄發送給客戶端文件主體內容大小 private String http_referer;// 用來記錄從那個頁面鏈接訪問過來的 private String http_user_agent;// 記錄客戶瀏覽器的相關資訊 private boolean valid = true;// 判斷數據是否合法 public String getRemote_addr() { return remote_addr; } public void setRemote_addr(String remote_addr) { this.remote_addr = remote_addr; } public String getRemote_user() { return remote_user; } public void setRemote_user(String remote_user) { this.remote_user = remote_user; } public String getTime_local() { return time_local; } public void setTime_local(String time_local) { this.time_local = time_local; } public String getRequest() { return request; } public void setRequest(String request) { this.request = request; } public String getStatus() { return status; } public void setStatus(String status) { this.status = status; } public String getBody_bytes_sent() { return body_bytes_sent; } public void setBody_bytes_sent(String body_bytes_sent) { this.body_bytes_sent = body_bytes_sent; } public String getHttp_referer() { return http_referer; } public void setHttp_referer(String http_referer) { this.http_referer = http_referer; } public String getHttp_user_agent() { return http_user_agent; } public void setHttp_user_agent(String http_user_agent) { this.http_user_agent = http_user_agent; } public boolean isValid() { return valid; } public void setValid(boolean valid) { this.valid = valid; } @Override public String toString() { StringBuilder sb = new StringBuilder(); sb.append(this.valid); sb.append("\001").append(this.remote_addr); sb.append("\001").append(this.remote_user); sb.append("\001").append(this.time_local); sb.append("\001").append(this.request); sb.append("\001").append(this.status); sb.append("\001").append(this.body_bytes_sent); sb.append("\001").append(this.http_referer); sb.append("\001").append(this.http_user_agent); return sb.toString(); } } -
編寫LogMapper類
package com.atguigu.mapreduce.log; import java.io.IOException; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; public class LogMapper extends Mapper<LongWritable, Text, Text, NullWritable>{ Text k = new Text(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 1 獲取1行 String line = value.toString(); // 2 解析日誌是否合法 LogBean bean = pressLog(line); if (!bean.isValid()) { return; } k.set(bean.toString()); // 3 輸出 context.write(k, NullWritable.get()); } // 解析日誌 private LogBean pressLog(String line) { LogBean logBean = new LogBean(); // 1 截取 String[] fields = line.split(" "); if (fields.length > 11) { // 2封裝數據 logBean.setRemote_addr(fields[0]); logBean.setRemote_user(fields[1]); logBean.setTime_local(fields[3].substring(1)); logBean.setRequest(fields[6]); logBean.setStatus(fields[8]); logBean.setBody_bytes_sent(fields[9]); logBean.setHttp_referer(fields[10]); if (fields.length > 12) { logBean.setHttp_user_agent(fields[11] + " "+ fields[12]); }else { logBean.setHttp_user_agent(fields[11]); } // 大於400,HTTP錯誤 if (Integer.parseInt(logBean.getStatus()) >= 400) { logBean.setValid(false); } }else { logBean.setValid(false); } return logBean; } } -
編寫LogDriver類
package com.atguigu.mapreduce.log; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class LogDriver { public static void main(String[] args) throws Exception { // 1 獲取job資訊 Configuration conf = new Configuration(); Job job = Job.getInstance(conf); // 2 載入jar包 job.setJarByClass(LogDriver.class); // 3 關聯map job.setMapperClass(LogMapper.class); // 4 設置最終輸出類型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(NullWritable.class); // 5 設置輸入和輸出路徑 FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); // 6 提交 job.waitForCompletion(true); } }
-
MapReduce開發總結(重點)
在編寫MapReduce程式時,需要考慮的幾個方面:





由於篇幅過長,[Hadoop數據壓縮]等以後的內容,請看下回分解!

