記錄一次jvm記憶體泄露的問題
- 2019 年 10 月 16 日
- 筆記
前些天,運維告訴我剛上線的java服務佔用CPU過高。
以下是發現解決問題的具體流程。
1:通過#top命令查看,我的java服務確實把CPU幾乎佔滿了,如圖
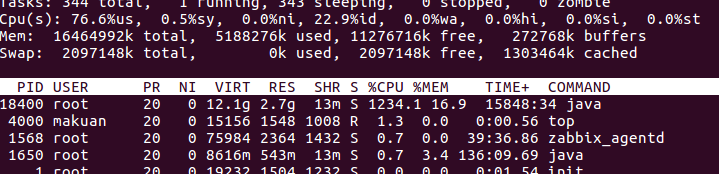
可看到18400這個進程CPU佔用達到了1200%,這確實不太正常,那麼我們接下來分析到底哪些執行緒佔用了CPU
2:通過#top -Hp 18400這條命令我們可以看到這個進程中執行緒的情況,部分截圖如下。
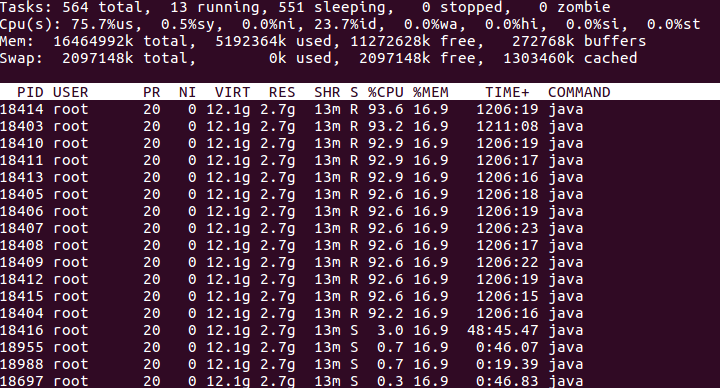
通過截圖可以看到,前面的執行緒佔用的CPU是比較高的,那我們就具體分析這些執行緒
3:我們通過#jstack 18400>18400.txt命令將這個java進程的執行緒棧給抓出來,可以多抓幾次做個對比。
我們以18414這個執行緒為例,將它轉成16進位,linux可以用終端通過命令#printf “%x” 18414將執行緒id轉為16進位為47ee,那麼我們接下來在文件里找47ee這個執行緒在幹什麼,部分截圖如下
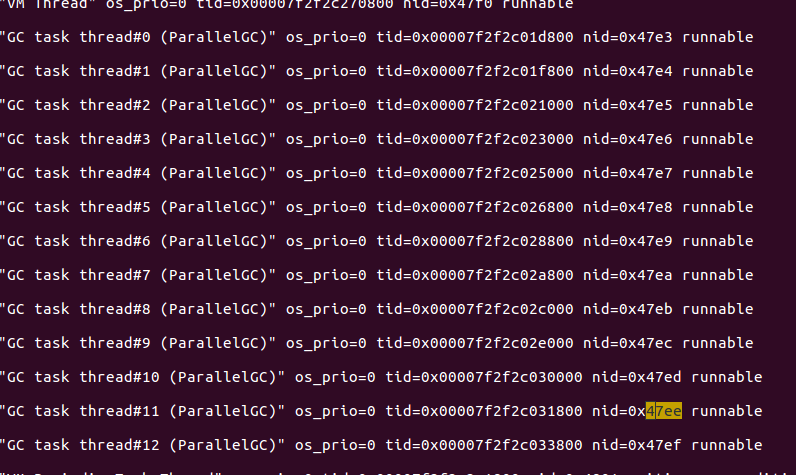
我們可以看到47ee是個垃圾回收執行緒;我們對其他佔用CPU高的執行緒做相同的操作,發現都是GC執行緒。說明這個java服務一直在GC,這很不正常。那麼我們接下來分析GC情況。
4:我們通過命令#jstat -gcutil 18400 1000 100來查看接下開的GC情況,部分截圖如下
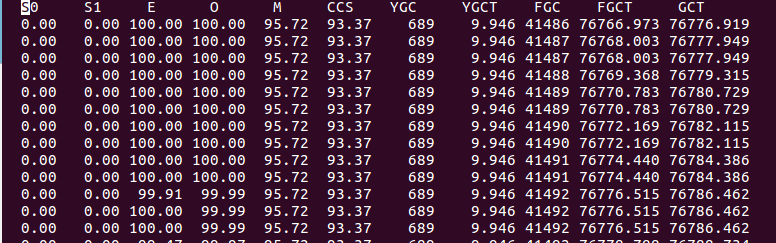
是不是很直觀,通過YGC這一列發現younggc次數沒有增加,但是通過FGC這一列看到fullgc的次數一直在增加,可怕的是老年代並沒有回收(通過O這列看出來)。
這時候你是不是想起來了一個名詞:記憶體泄露。沒錯,接下來我們就需要分析哪裡出現了記憶體泄露。
5:我們可以通過#jmap -dump:live,format=b,file=18400.dump 18400將這個進程當前的堆給dump下來。注意,這個文件可以看成是堆的快照,所以當前堆有多大,dump下來差不多也有多大。我dump下來的差不多2G。
有了這個文件,我們需要分析,你可以用命令jhat分析,當然我們常用的是功能比較強大的圖形化工具,如JDK自帶的visualvm,也可以用第三方的JProfiler(我用的是這個),如果你用Eclipse,也可以安裝MAT插件。這些工具都能分析堆dump文件。
需要注意的是,由於dump文件可能比較大,所以所需分析工具的記憶體也比較大,最好在性能比較好的機器上進行分析。
下面是我的JProfiler分析的部分截圖
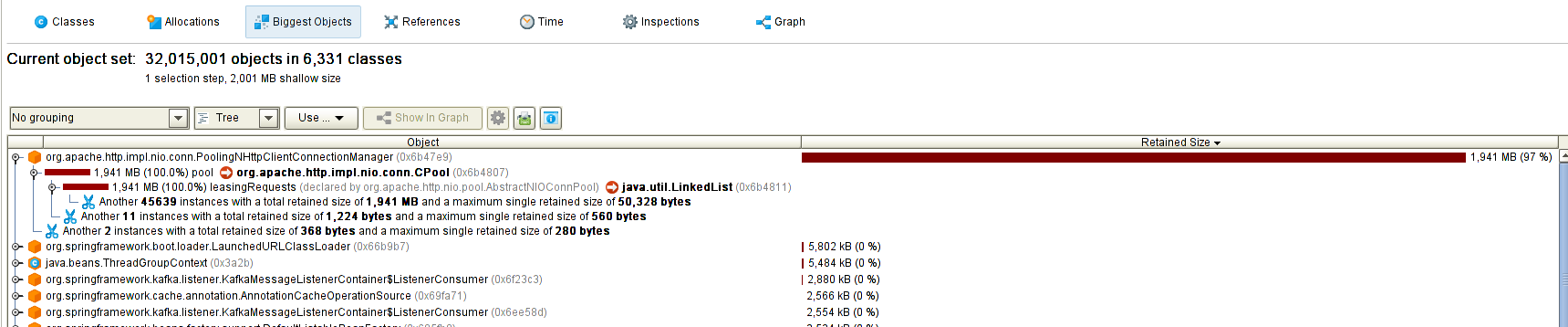
是不是很直觀,有個對象佔了97%的記憶體。那麼接下來需要分析這個對象在哪產生,在哪被引用。我這裡很明顯是這個LinkedList佔用了全部空間,那麼就去分析這個LinkedList裡面都存了些什麼,這些有可能需要結合你的程式碼,我就不細說了。
我分析出來的是ElasticSearch的客戶端工具JestClient的非同步請求隊列太長了,整個List裡面的節點都是非同步請求資訊,大概生成了10多萬個。消費不及時又無法被回收,所以產生了記憶體泄露。(注意,使用執行緒池也有可能會出現這個情況)
6:分析出了原因,那麼接下來就解決問題。因為我當時急著上線,不知道JestClient的非同步隊列長度怎麼配,就暫時把非同步改成了同步,暫時解決了這個問題。上線後查看CPU,垃圾回收等情況確實恢復了正常。
總的來說,上面的6步是一個完整的分析解決jvm虛擬機記憶體泄露的流程,當然可能有不完善的地方,但大體思路是沒錯的。
通過這篇文章,我們可以總結出以下幾點:
1:如何分析Java服務佔用CPU過高的問題
2:使用Java各種隊列的時候一定要關注隊列的長度,預防記憶體泄露。
3:最好熟悉一下jvm的記憶體模型


