xenomai內核解析之訊號signal(一)—Linux訊號機制
版權聲明:本文為本文為部落客原創文章,轉載請註明出處。如有錯誤,歡迎指正。部落格地址://www.cnblogs.com/wsg1100/
1. Linux訊號
涉及硬體底層,本文以X86平台講解。
訊號是事件發生時對進程的通知機制,是作業系統提供的一種軟體中斷。訊號提供了一種非同步處理事件的方法,訊號與硬體中斷的相似之處在於打斷了程式執行的正常流程,例如,中斷用戶鍵入中斷鍵(Ctrl+C),會通過訊號機制停止應用程式。
- 訊號的幾種產生方式:
- 按鍵產生 當用戶按某些按鍵時,引發終端產生的訊號。 ctrl+C產生 SIGINT訊號、ctrl+\產生SIGQUIT訊號、ctrl+z產生SIGTSTP 訊號
- 系統調用產生 進程調用系統調用函數將任意訊號發送給另一個進程或進程組。如:kill() 、raise()、abort()
- 軟體條件產生 當作業系統檢測到某種軟體條件時,使用訊號通知有關進程。如:定時器函數alarm()
- 硬體異常產生 由硬體檢測到某些條件,並通知內核,然後內核為該條件發生時正在運行的進程產生適當的訊號。如:非法操作記憶體(段錯誤)SIGSEGV訊號、除0操作(浮點數除外)SIGFPE 訊號、匯流排錯誤SIGBUS訊號。
- 命令產生 其時都是系統調用的封裝,如:
kill -9 pid。
- 當某個訊號產生時,進程可告訴內核其處理方式:
- 執行系統默認動作。linux下可通過
man 7 signal來查看具體訊號及默認處理動作,大多數訊號的系統默認動作是終止進程。 - 忽略此訊號。SIGKILL和SIGSTOP訊號不能被忽略,它們用於在任何時候中斷或結束某一進程。。
- 捕捉訊號。告訴內核在某種訊號產生時,調用一個用戶處理函數。在處理函數中,執行用戶對該訊號的具體處理。SIGKILL和SIGSTOP訊號不能捕捉。
- 訊號的兩種狀態
- 抵達 遞送並且到達進程。
- 未決 產生和遞達之間的狀態。主要由於阻塞(屏蔽)導致該狀態。
可以使用kill –l命令查看當前系統可使用的訊號.
$ kill -l
1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP
6) SIGABRT 7) SIGBUS 8) SIGFPE 9) SIGKILL 10) SIGUSR1
11) SIGSEGV 12) SIGUSR2 13) SIGPIPE 14) SIGALRM 15) SIGTERM
16) SIGSTKFLT 17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP
21) SIGTTIN 22) SIGTTOU 23) SIGURG 24) SIGXCPU 25) SIGXFSZ
26) SIGVTALRM 27) SIGPROF 28) SIGWINCH 29) SIGIO 30) SIGPWR
31) SIGSYS 34) SIGRTMIN 35) SIGRTMIN+1 36) SIGRTMIN+2 37) SIGRTMIN+3
38) SIGRTMIN+4 39) SIGRTMIN+5 40) SIGRTMIN+6 41) SIGRTMIN+7 42) SIGRTMIN+8
43) SIGRTMIN+9 44) SIGRTMIN+10 45) SIGRTMIN+11 46) SIGRTMIN+12 47) SIGRTMIN+13
48) SIGRTMIN+14 49) SIGRTMIN+15 50) SIGRTMAX-14 51) SIGRTMAX-13 52) SIGRTMAX-12
53) SIGRTMAX-11 54) SIGRTMAX-10 55) SIGRTMAX-9 56) SIGRTMAX-8 57) SIGRTMAX-7
58) SIGRTMAX-6 59) SIGRTMAX-5 60) SIGRTMAX-4 61) SIGRTMAX-3 62) SIGRTMAX-2
63) SIGRTMAX-1 64) SIGRTMAX
每個訊號都有一個唯一的ID,其中1-31號訊號為常規訊號(也叫普通訊號或標準訊號)是不可靠訊號,產生多次只記錄一次;34-64稱之為可靠訊號,支援排隊,與驅動編程等相關。可靠與不可靠在後面的內核分析中會看到。
1.1註冊訊號處理函數
用戶進程對訊號的常見操作:註冊訊號處理函數和發送訊號。如果我們不想讓某個訊號執行默認操作,一種方法就是對特定的訊號註冊相應的訊號處理函數(捕捉),設置訊號處理方式的是signal() 函數。注意:以下內容是基於用戶進程描述的。
typedef void (*sighandler_t)(int);
sighandler_t signal(int signum, sighandler_t handler);
該函數由ANSI定義,由於歷史原因在不同版本的Unix和不同版本的Linux中可能有不同的行為。如果我們在 Linux 下面執行 man signal 的話,會發現 Linux 不建議我們直接用這個方法,而是改用 sigaction。
int sigaction(int signum, const struct sigaction *act,
struct sigaction *oldact);
struct sigaction {
void (*sa_handler)(int);
void (*sa_sigaction)(int, siginfo_t *, void *);
sigset_t sa_mask;/* mask last for extensibility */
int sa_flags;
void (*sa_restorer)(void);
};
sa_restorer:該元素是過時的,不應該使用,POSIX.1標準將不指定該元素。(棄用)
sa_sigaction:當sa_flags被指定為SA_SIGINFO標誌時,使用該訊號處理程式。(很少使用)
① sa_handler:指定訊號捕捉後的處理函數名(即註冊函數)。也可賦值為SIG_IGN表忽略 或 SIG_DFL表執行默認動作。
② sa_mask: 調用訊號處理函數時,所要屏蔽的訊號集合(訊號屏蔽字)。注意:僅在處理函數被調用期間屏蔽生效,是臨時性設置。當註冊了某個訊號捕捉函數,當這個訊號處理函數執行的過程中,如果再有其他訊號,哪怕相同的訊號到來的時候,這個訊號處理函數就會被中斷。如果訊號處理函數中是關於全局變數的處理,執行期間,同一訊號再次到來再次執行,這樣的話,同步、死鎖這些都要想好。sa_mask就是用來設置這個訊號處理期間需要屏蔽哪些訊號。阻塞的常規訊號不支援排隊,產生多次只記錄一次,後32個實時訊號支援排隊。
③ sa_flags:通常設置為0,表使用默認屬性。
所以,sigaction()與signal()的區別在於,sigaction()可以讓你更加細緻地控制訊號處理的行為。而 signal 函數沒有給你機會設置這些。需要注意的是,signal ()不是系統調用,而是 glibc 封裝的一個函數。
/*glibc-2.28\signal\signal.h*/
# define signal __sysv_signal
/*glibc-2.28\sysdeps\posix\sysv_signal.c*/
__sighandler_t
__sysv_signal (int sig, __sighandler_t handler)
{
struct sigaction act, oact;
.....
act.sa_handler = handler;
__sigemptyset (&act.sa_mask);
act.sa_flags = SA_ONESHOT | SA_NOMASK | SA_INTERRUPT;
act.sa_flags &= ~SA_RESTART;
if (__sigaction (sig, &act, &oact) < 0)
return SIG_ERR;
return oact.sa_handler;
}
可以看到signal ()的默認設置,sa_flags 設置為SA_ONESHOT | SA_NOMASK | SA_INTERRUPT並清除了SA_RESTART,SA_ONESHOT 意思是,這裡設置的訊號處理函數,僅僅起作用一次。用完了一次後,就設置回默認行為。這其實並不是我們想看到的。畢竟我們一旦安裝了一個訊號處理函數,肯定希望它一直起作用,直到我顯式地關閉它。SA_NOMASK表示訊號處理函數執行過程中不阻塞任何訊號。
設置了SA_INTERRUPT,清除SA_RESTART,由於訊號的到來是不可預期的,有可能程式正在進行漫長的系統調用,這個時候一個訊號來了,會中斷這個系統調用,去執行訊號處理函數,那執行完了以後呢?系統調用怎麼辦呢?
這時候有兩種處理方法,一種就是 SA_INTERRUPT,也即系統調用被中斷了,就不再重試這個系統調用了,而是直接返回一個 -EINTR 常量,告訴調用方,這個系統調用被訊號中斷,但是怎麼處理你看著辦。另外一種處理方法是 SA_RESTART。這個時候系統調用會被自動重新啟動,不需要調用方自己寫程式碼。
因而,建議使用 sigaction()函數,根據自己的需要訂製參數。
系統調用小節說到過,glibc 中的文件 syscalls.list定義了庫函數調用哪些系統調用,這裡看sigaction。
/*glibc-2.28\sysdeps\unix\syscalls.list*/
sigaction - sigaction i:ipp __sigaction sigaction
__sigaction 會調用 __libc_sigaction,並最終調用的系統調用是rt_sigaction。
int
__sigaction (int sig, const struct sigaction *act, struct sigaction *oact)
{
.....
return __libc_sigaction (sig, act, oact);
}
int
__libc_sigaction (int sig, const struct sigaction *act, struct sigaction *oact)
{
int result;
struct kernel_sigaction kact, koact;
if (act)
{
kact.k_sa_handler = act->sa_handler;
memcpy (&kact.sa_mask, &act->sa_mask, sizeof (sigset_t));
kact.sa_flags = act->sa_flags;
SET_SA_RESTORER (&kact, act);
}
/* XXX The size argument hopefully will have to be changed to the
real size of the user-level sigset_t. */
result = INLINE_SYSCALL_CALL (rt_sigaction, sig,
act ? &kact : NULL,
oact ? &koact : NULL, STUB(act) _NSIG / 8);
if (oact && result >= 0)
{
oact->sa_handler = koact.k_sa_handler;
memcpy (&oact->sa_mask, &koact.sa_mask, sizeof (sigset_t));
oact->sa_flags = koact.sa_flags;
RESET_SA_RESTORER (oact, &koact);
}
return result;
}
在看系統調用前先看一下進程內核管理結構task_struct 裡面關於訊號處理的欄位。
struct task_struct {
....
/* Signal handlers: */
struct signal_struct *signal;
struct sighand_struct *sighand;
sigset_t blocked;
sigset_t real_blocked;
/* Restored if set_restore_sigmask() was used: */
sigset_t saved_sigmask;
struct sigpending pending;
unsigned long sas_ss_sp;
size_t sas_ss_size;
unsigned int sas_ss_flags;
......
}
blocked定義了哪些訊號被阻塞暫不處理,pending表示哪些訊號尚等待處理(未決),sighand表示哪些訊號設置了訊號處理函數。sas_ss_xxx 這三個變數用於表示訊號處理函數默認使用用戶態的函數棧,或開闢新的棧專門用於訊號處理。另外訊號需要區分進程和執行緒,進入 struct signal_struct *signal 可以看到,還有一個 struct sigpending shared_pending。pending是本任務的(執行緒也是一個輕量級任務),shared_pending執行緒組共享的。
回到系統調用,linux內核中為了兼容過去、兼容32位,關於訊號的實現有很多種,由不同的宏控制,這裡只看系統調用 rt_sigaction。
/*kernel\signal.c*/
SYSCALL_DEFINE4(rt_sigaction, int, sig,
const struct sigaction __user *, act,
struct sigaction __user *, oact,
size_t, sigsetsize)
{
struct k_sigaction new_sa, old_sa;
int ret = -EINVAL;
....
if (act) {
if (copy_from_user(&new_sa.sa, act, sizeof(new_sa.sa)))
return -EFAULT;
}
ret = do_sigaction(sig, act ? &new_sa : NULL, oact ? &old_sa : NULL);
if (!ret && oact) {
if (copy_to_user(oact, &old_sa.sa, sizeof(old_sa.sa)))
return -EFAULT;
}
out:
return ret;
}
在rt_sigaction里,將用戶態的struct sigaction拷貝為內核態的struct k_sigaction,然後調用do_sigaction(),
每個進程內核數據結構里,struct task_struct 中有關於訊號處理的幾個成員,其中sighand裡面有個action,是一個k_sigaction的數組,其中記錄著進程的每個訊號的struct k_sigaction。do_sigaction()就是將用戶設置的k_sigaction保存到這個數組中,同時將該訊號原來的k_sigaction保存到oact中,拷貝到用戶空間。
int do_sigaction(int sig, struct k_sigaction *act, struct k_sigaction *oact)
{
struct task_struct *p = current, *t;
struct k_sigaction *k;
sigset_t mask;
if (!valid_signal(sig) || sig < 1 || (act && sig_kernel_only(sig)))
return -EINVAL;
k = &p->sighand->action[sig-1];
spin_lock_irq(&p->sighand->siglock);
if (oact)
*oact = *k;
if (act) {
sigdelsetmask(&act->sa.sa_mask,
sigmask(SIGKILL) | sigmask(SIGSTOP));
*k = *act;
.......
}
spin_unlock_irq(&p->sighand->siglock);
return 0;
}
到此一個訊號處理函數註冊完成了。

1.2 訊號的發送
訊號的產生多種多樣,無論如何產生,都是由內核去處理的,這裡以最簡單的kill系統調用來看訊號的發送過程。
SYSCALL_DEFINE2(kill, pid_t, pid, int, sig)
{
struct siginfo info;
info.si_signo = sig;
info.si_errno = 0;
info.si_code = SI_USER;
info.si_pid = task_tgid_vnr(current);
info.si_uid = from_kuid_munged(current_user_ns(), current_uid());
return kill_something_info(sig, &info, pid);
}
kill->kill_something_info->kill_pid_info->group_send_sig_info->do_send_sig_info
int do_send_sig_info(int sig, struct siginfo *info, struct task_struct *p,
bool group)
{
unsigned long flags;
int ret = -ESRCH;
if (lock_task_sighand(p, &flags)) {
ret = send_signal(sig, info, p, group);
unlock_task_sighand(p, &flags);
}
return ret;
}
同樣使用tkill或者 tgkill 發送訊號給某個執行緒,最終都是調用了 do_send_sig_info函數。
tkill->do_tkill->do_send_specific->do_send_sig_info
tgkill->do_tkill->do_send_specific->do_send_sig_info
do_send_sig_info 會調用 send_signal,進而調用 __send_signal。
static int __send_signal(int sig, struct siginfo *info, struct task_struct *t,
int group, int from_ancestor_ns)
{
struct sigpending *pending;
struct sigqueue *q;
int override_rlimit;
int ret = 0, result;
assert_spin_locked(&t->sighand->siglock);
result = TRACE_SIGNAL_IGNORED;
if (!prepare_signal(sig, t,
from_ancestor_ns || (info == SEND_SIG_FORCED)))
goto ret;
pending = group ? &t->signal->shared_pending : &t->pending;
.....
if (legacy_queue(pending, sig))
goto ret;
......
if (sig < SIGRTMIN)
override_rlimit = (is_si_special(info) || info->si_code >= 0);
else
override_rlimit = 0;
q = __sigqueue_alloc(sig, t, GFP_ATOMIC | __GFP_NOTRACK_FALSE_POSITIVE,
override_rlimit);
if (q) {
list_add_tail(&q->list, &pending->list);
switch ((unsigned long) info) {
case (unsigned long) SEND_SIG_NOINFO:
q->info.si_signo = sig;
q->info.si_errno = 0;
q->info.si_code = SI_USER;
q->info.si_pid = task_tgid_nr_ns(current,
task_active_pid_ns(t));
q->info.si_uid = from_kuid_munged(current_user_ns(), current_uid());
break;
case (unsigned long) SEND_SIG_PRIV:
q->info.si_signo = sig;
q->info.si_errno = 0;
q->info.si_code = SI_KERNEL;
q->info.si_pid = 0;
q->info.si_uid = 0;
break;
default:
copy_siginfo(&q->info, info);
if (from_ancestor_ns)
q->info.si_pid = 0;
break;
}
userns_fixup_signal_uid(&q->info, t);
}
......
out_set:
signalfd_notify(t, sig);
sigaddset(&pending->signal, sig);
complete_signal(sig, t, group);
ret:
trace_signal_generate(sig, info, t, group, result);
return ret;
}
先看是要使用哪個pending,如果是kill發送的,就是要發送給整個進程,應該使用t->signal->shared_pending,這裡面的訊號是整個進程所有執行緒共享的;如果是tkill發送的,也就是發送給某個執行緒,應該使用t->pending,這是執行緒的task_struct獨享的。
struct sigpending 結構如下。
struct sigpending {
struct list_head list;
sigset_t signal;
};
有兩個成員變數,一個sigset_t表示收到了哪些變數,另一個是一個鏈表,也表示接收到的訊號。如果都表示收到了訊號,這兩者有什麼區別呢?接著往下看 __send_signal 裡面的程式碼。接下來,調用legacy_queue。如果滿足條件,那就直接退出。那 legacy_queue 裡面判斷的是什麼條件呢?我們來看它的程式碼。
static inline int legacy_queue(struct sigpending *signals, int sig)
{
return (sig < SIGRTMIN) && sigismember(&signals->signal, sig);
}
#define SIGRTMIN 32
當訊號小於 SIGRTMIN,也即 32 的時候,如果這個訊號已經在集合裡面了就直接退出了。這樣會造成什麼現象呢?就是訊號的丟失。例如,我們發送給進程 100 個SIGUSR1(對應的訊號為 10),那最終能夠被我們的訊號處理函數處理的訊號有多少呢?這就不好說了,比如總共 5 個 SIGUSR1,分別是 A、B、C、D、E。
如果這五個信來得太密。A 來了,但是訊號處理函數還沒來得及處理,B、C、D、E 就都來了。根據上面的邏輯,因為 A 已經將 SIGUSR1 放在 sigset_t 集合中了,因而後面四個都要丟失。 如果是另一種情況,A 來了已經被訊號處理函數處理了,內核在調用訊號處理函數之前,我們會將集合中的標誌位清除,這個時候 B 再來,B 還是會進入集合,還是會被處理,也就不會丟。
這樣訊號能夠處理多少,和訊號處理函數什麼時候被調用,訊號多大頻率被發送,都有關係,而且從後面的分析,我們可以知道,訊號處理函數的調用時間也是不確定的。看小於 32 的訊號如此不靠譜,我們就稱它為不可靠訊號。
對於對於大於32的訊號呢?接著往下看 __send_signal 裡面的程式碼,會調用__sigqueue_alloc分配一個struct sigqueue 對象,然後通過 list_add_tail 掛在 struct sigpending 裡面的鏈表上。這樣,連續發送100個訊號過來,就會在鏈表上掛100項,不會丟,靠譜多了。因此,大於 32 的訊號我們稱為可靠訊號。當然,隊列的長度也是有限制的,執行ulimit -a命令可以查看訊號限制 pending signals (-i) 15348。
$ ulimit -a
core file size (blocks, -c) 0
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 15348
max locked memory (kbytes, -l) 64
max memory size (kbytes, -m) unlimited
open files (-n) 1024
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) 8192
cpu time (seconds, -t) unlimited
max user processes (-u) 15348
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited
當訊號掛到了 task_struct 結構之後,最後調用 complete_signal。這裡面的邏輯也很簡單,就是說,既然這個進程有了一個新的訊號,趕緊找一個執行緒處理一下(在多執行緒的程式中,如果不做特殊的訊號阻塞處理,當發送訊號給進程時,由系統選擇一個執行緒來處理這個訊號)。
static void complete_signal(int sig, struct task_struct *p, int group)
{
struct signal_struct *signal = p->signal;
struct task_struct *t;
/*
* Now find a thread we can wake up to take the signal off the queue.
*
* If the main thread wants the signal, it gets first crack.
* Probably the least surprising to the average bear.
*/
if (wants_signal(sig, p))
t = p;
else {
/*
* Otherwise try to find a suitable thread.
*/
t = signal->curr_target;
while (!wants_signal(sig, t)) {
t = next_thread(t);
if (t == signal->curr_target)
/*
* No thread needs to be woken.
* Any eligible threads will see
* the signal in the queue soon.
*/
return;
}
signal->curr_target = t;
}
......
/*
* The signal is already in the shared-pending queue.
* Tell the chosen thread to wake up and dequeue it.
*/
signal_wake_up(t, sig == SIGKILL);
return;
}
在找到了一個進程或者執行緒的 task_struct 之後,我們要調用 signal_wake_up,來企圖喚醒它,signal_wake_up 會調用 signal_wake_up_state。
void signal_wake_up_state(struct task_struct *t, unsigned int state)
{
set_tsk_thread_flag(t, TIF_SIGPENDING);
if (!wake_up_state(t, state | TASK_INTERRUPTIBLE))
kick_process(t);
}
signal_wake_up_state 裡面主要做了兩件事情。第一,就是給這個執行緒設置TIF_SIGPENDING,這就說明其實訊號的處理和進程的調度是採取這樣一種類似的機制。
當發現一個進程應該被調度的時候,我們並不直接把它趕下來,而是設置一個標識位TIF_NEED_RESCHED,表示等待調度,然後等待系統調用結束或者中斷處理結束,從內核態返回用戶態的時候,調用 schedule 函數進行調度。訊號也是類似的,當訊號來的時候,我們並不直接處理這個訊號,而是設置一個標識位 TIF_SIGPENDING,來表示已經有訊號等待處理。同樣等待系統調用結束,或者中斷處理結束,從內核態返回用戶態的時候,再進行訊號的處理。
signal_wake_up_state 的第二件事情,就是試圖喚醒這個進程或者執行緒。wake_up_state 會調用 try_to_wake_up 方法。這個函數就是將這個進程或者執行緒設置為 TASK_RUNNING,然後放在運行隊列中,這個時候,當隨著時鐘不斷的滴答,遲早會被調用。如果 wake_up_state 返回 0,說明進程或者執行緒已經是 TASK_RUNNING 狀態了,如果它在另外一個 CPU 上運行,則調用 kick_process 發送一個處理器間中斷,強制那個進程或者執行緒重新調度,重新調度完畢後,會返回用戶態運行。這是一個時機會檢查TIF_SIGPENDING 標識位。
1.3 訊號的處理
訊號已經發送到位了,什麼時候真正處理它呢?
就是在從系統調用或者中斷返回的時候,咱們講調度的時候講過,無論是從系統調用返回還是從中斷返回,都會調用 exit_to_usermode_loop,重點關注_TIF_SIGPENDING 標識位。
static void exit_to_usermode_loop(struct pt_regs *regs, u32 cached_flags)
{
while (true) {
/* We have work to do. */
enable_local_irqs();
if (cached_flags & _TIF_NEED_RESCHED)
schedule();
.....
/* deal with pending signal delivery */
if (cached_flags & _TIF_SIGPENDING)
do_signal(regs);/*有訊號掛起*/
if (cached_flags & _TIF_NOTIFY_RESUME) {
clear_thread_flag(TIF_NOTIFY_RESUME);
tracehook_notify_resume(regs);
}
......
if (!(cached_flags & EXIT_TO_USERMODE_LOOP_FLAGS))
break;
}
}
如果在前一個環節中,已經設置了 _TIF_SIGPENDING,我們就調用 do_signal 進行處理。
void do_signal(struct pt_regs *regs)
{
struct ksignal ksig;
if (get_signal(&ksig)) {
/* Whee! Actually deliver the signal. */
handle_signal(&ksig, regs);
return;
}
/* Did we come from a system call? */
if (syscall_get_nr(current, regs) >= 0) {
/* Restart the system call - no handlers present */
switch (syscall_get_error(current, regs)) {
case -ERESTARTNOHAND:
case -ERESTARTSYS:/*一個系統調用因沒有數據阻塞,但然被訊號喚醒,但系統調用還沒完成,會返回該標誌*/
case -ERESTARTNOINTR:
regs->ax = regs->orig_ax;
regs->ip -= 2;
break;
case -ERESTART_RESTARTBLOCK:
regs->ax = get_nr_restart_syscall(regs);
regs->ip -= 2;
break;
}
}
/*
* If there's no signal to deliver, we just put the saved sigmask
* back.
*/
restore_saved_sigmask();
}
do_signal 會調用 handle_signal。按說,訊號處理就是調用用戶提供的訊號處理函數,但是這事兒沒有看起來這麼簡單,因為訊號處理函數是在用戶態的。
要回答這個問題還需要回憶系統調用的過程。這個進程當時在用戶態執行到某一行 Line A,調用了一個系統調用,當 syscall 指令調用的時候,會從這個暫存器裡面拿出函數地址來調用,也就是調用entry_SYSCALL_64。
entry_SYSCALL_64函數先使用swaps切換到內核棧,然後保存當前用戶態的暫存器到內核棧,在內核棧的最高地址端,存放的是結構 pt_regs.這樣,這樣,在內核 pt_regs 裡面就保存了用戶態執行到了 Line A的指針。
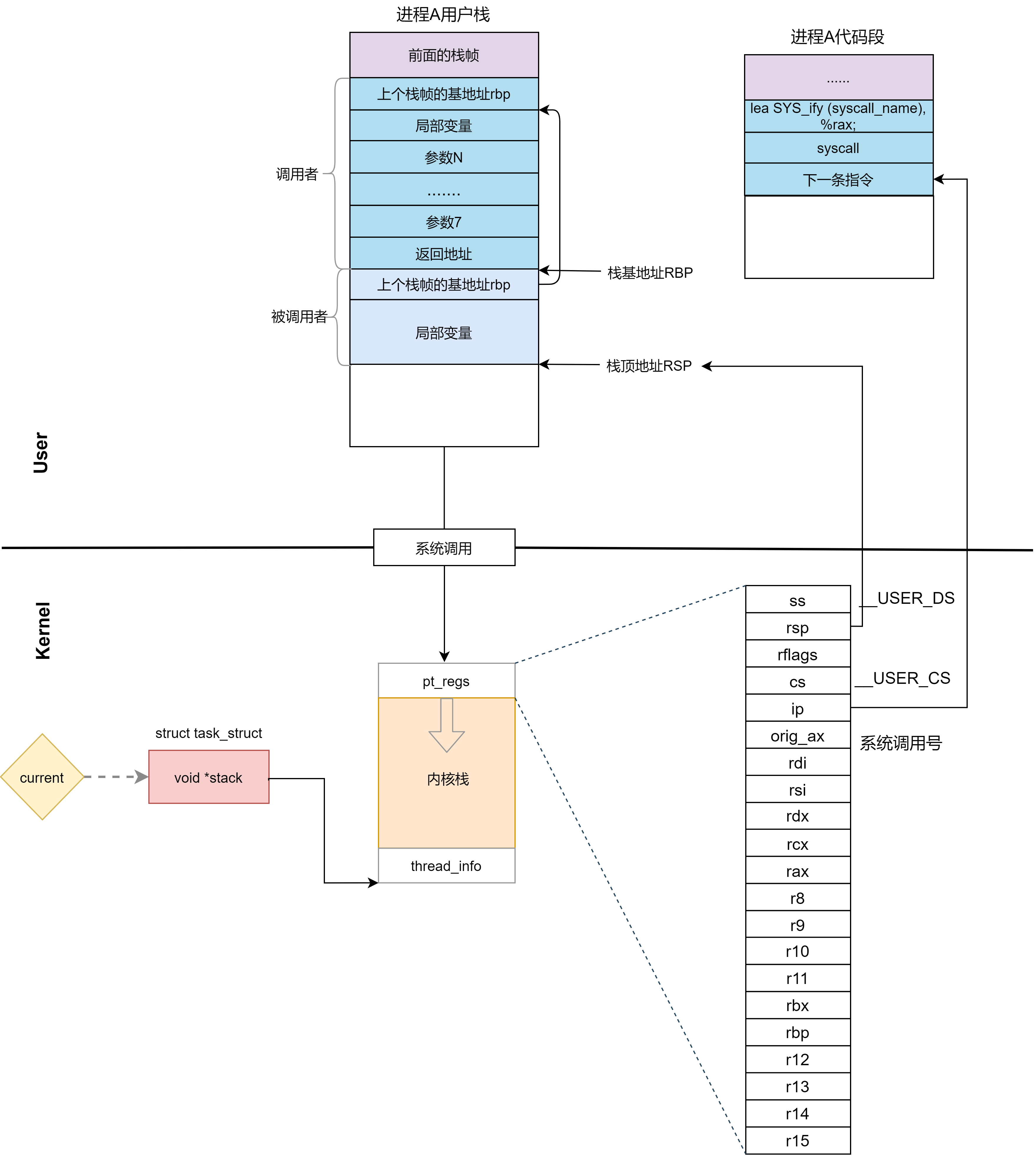
現在我們從系統調用返回用戶態了,按說應該從 pt_regs 拿出 Line A,然後接著 Line A 執行下去,但是為了響應訊號,我們不能回到用戶態的時候返回 Line A 了,而是應該返回訊號處理函數的起始地址。
static void
handle_signal(struct ksignal *ksig, struct pt_regs *regs)
{
bool stepping, failed;
struct fpu *fpu = ¤t->thread.fpu;
....
/* Are we from a system call? */
if (syscall_get_nr(current, regs) >= 0) {
/* If so, check system call restarting.. */
switch (syscall_get_error(current, regs)) {
case -ERESTART_RESTARTBLOCK:
case -ERESTARTNOHAND:
regs->ax = -EINTR;
break;
/*當發現出現錯誤 ERESTARTSYS 的時候,我們就知道這是從一個沒有調用完的系統調用返回的,
設置系統調用錯誤碼 EINTR。*/
case -ERESTARTSYS:
if (!(ksig->ka.sa.sa_flags & SA_RESTART)) {
regs->ax = -EINTR;/*設置系統調用錯誤碼 EINTR。*/
break;
}
/* fall through */
case -ERESTARTNOINTR:
regs->ax = regs->orig_ax;
regs->ip -= 2;
break;
}
}
......
failed = (setup_rt_frame(ksig, regs) < 0);
......
signal_setup_done(failed, ksig, stepping);
}
這個時候,就需要干預和自己來訂製 pt_regs 了。這個時候,要看,是否從系統調用中返回。如果是從系統調用返回的話,還要區分是從系統調用中正常返回,還是在一個非運行狀態的系統調用中,因為會被訊號中斷而返回。
這裡解析一個最複雜的場景。還記得咱們解析進程調度的時候,舉的一個例子,就是從一個 tap 網卡中讀取數據。當時主要關注 schedule 那一行,也即如果當發現沒有數據的時候,就調用 schedule,自己進入等待狀態,然後將 CPU 讓給其他進程。具體的程式碼如下:
static ssize_t tap_do_read(struct tap_queue *q,
struct iov_iter *to,
int noblock, struct sk_buff *skb)
{
......
while (1) {
if (!noblock)
prepare_to_wait(sk_sleep(&q->sk), &wait,
TASK_INTERRUPTIBLE);
/* Read frames from the queue */
skb = skb_array_consume(&q->skb_array);
if (skb)
break;
if (noblock) {
ret = -EAGAIN;
break;
}
if (signal_pending(current)) {
ret = -ERESTARTSYS;
break;
}
/* Nothing to read, let's sleep */
schedule();
}
......
}
這裡我們關注和訊號相關的部分。這其實是一個訊號中斷系統調用的典型邏輯。
首先,我們把當前進程或者執行緒的狀態設置為 TASK_INTERRUPTIBLE,這樣才能是使這個系統調用可以被中斷。
其次,可以被中斷的系統調用往往是比較慢的調用,並且會因為數據不就緒而通過 schedule讓出 CPU 進入等待狀態。在發送訊號的時候,我們除了設置這個進程和執行緒的_TIF_SIGPENDING 標識位之外,還試圖喚醒這個進程或者執行緒,也就是將它從等待狀態中設置為 TASK_RUNNING。
當這個進程或者執行緒再次運行的時候,我們根據進程調度第一定律,從 schedule 函數中返回,然後再次進入 while 循環。由於這個進程或者執行緒是由訊號喚醒的,而不是因為數據來了而喚醒的,因而是讀不到數據的,但是在 signal_pending 函數中,我們檢測到了_TIF_SIGPENDING 標識位,這說明系統調用沒有真的做完,於是返回一個錯誤ERESTARTSYS,然後帶著這個錯誤從系統調用返回。
然後,我們到了 exit_to_usermode_loop->do_signal->handle_signal。在這裡面,當發現出現錯誤ERESTARTSYS 的時候,我們就知道這是從一個沒有調用完的系統調用返回的,設置系統調用錯誤碼 EINTR。
接下來,我們就開始折騰 pt_regs 了,主要通過調用 setup_rt_frame->__setup_rt_frame。
static int __setup_rt_frame(int sig, struct ksignal *ksig,
sigset_t *set, struct pt_regs *regs)
{
struct rt_sigframe __user *frame;
void __user *fp = NULL;
int err = 0;
frame = get_sigframe(&ksig->ka, regs, sizeof(struct rt_sigframe), &fp);
.....
if (ksig->ka.sa.sa_flags & SA_SIGINFO) {
if (copy_siginfo_to_user(&frame->info, &ksig->info))
return -EFAULT;
}
put_user_try {
/* Create the ucontext. */
put_user_ex(frame_uc_flags(regs), &frame->uc.uc_flags);
put_user_ex(0, &frame->uc.uc_link);
save_altstack_ex(&frame->uc.uc_stack, regs->sp);
/* Set up to return from userspace. If provided, use a stub
already in userspace. */
/* x86-64 should always use SA_RESTORER. */
if (ksig->ka.sa.sa_flags & SA_RESTORER) {
put_user_ex(ksig->ka.sa.sa_restorer, &frame->pretcode);
} ....
} put_user_catch(err);
err |= setup_sigcontext(&frame->uc.uc_mcontext, fp, regs, set->sig[0]);
err |= __copy_to_user(&frame->uc.uc_sigmask, set, sizeof(*set));
......
/* Set up registers for signal handler */
regs->di = sig;
/* In case the signal handler was declared without prototypes */
regs->ax = 0;
/* This also works for non SA_SIGINFO handlers because they expect the
next argument after the signal number on the stack. */
regs->si = (unsigned long)&frame->info;
regs->dx = (unsigned long)&frame->uc;
regs->ip = (unsigned long) ksig->ka.sa.sa_handler;
regs->sp = (unsigned long)frame;
regs->cs = __USER_CS;
....
return 0;
}
frame 的類型是 rt_sigframe。frame 的意思是幀。
- 在 get_sigframe 中會得到 pt_regs 的 sp 變數,也就是原來這個程式在用戶態的棧頂指針,然後 get_sigframe 中,我們會將 sp 減去 sizeof(struct rt_sigframe),也就是把這個棧幀塞到了用戶棧裡面。

-
將sa.sa_restorer的地址保存到frame的pretcode中。這個操作比較重要。
-
原來的 pt_regs 不能丟,調用setup_sigcontext將原來的 pt_regs 保存在了 frame 中的 uc_mcontext 裡面。
-
訊號處理期間要屏蔽的訊號set也保存到frame->uc.uc_sigmask。
-
在 __setup_rt_frame 把 regs->sp 設置成等於 frame。這就相當於強行在程式原來的用戶態的棧裡面插入了一個棧幀。
-
並在最後將 regs->ip 設置為用戶定義的訊號處理函數 sa_handler。
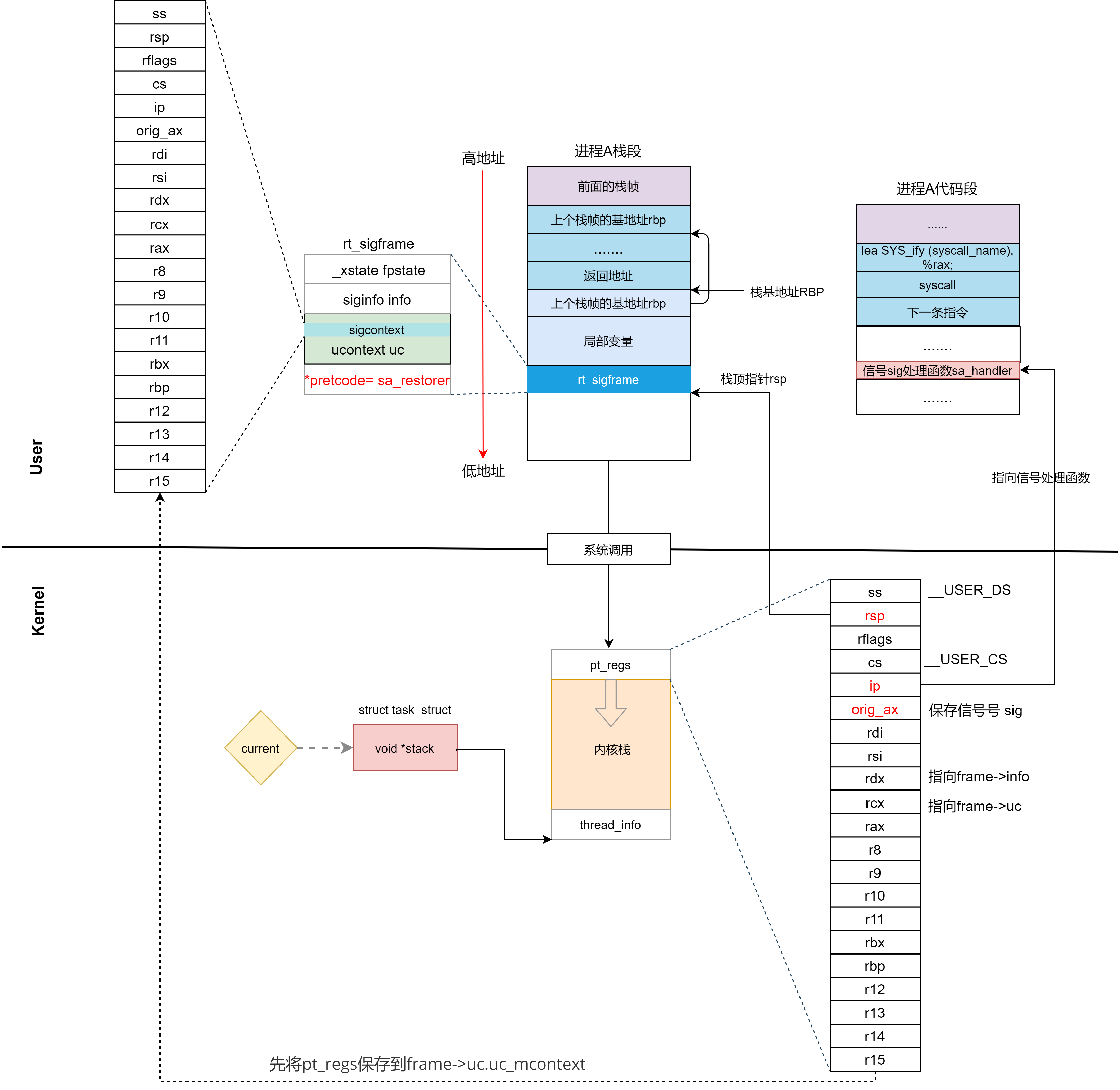

這意味著,本來返回用戶態應該接著原來系統調用的程式碼執行的,現在不了,要執行 sa_handler 了。那執行完了以後呢?按照函數棧的規則,彈出上一個棧幀來,也就是彈出了 frame。按照函數棧的規則。函數棧裡面包含了函數執行完跳回去的地址。
那如果我們假設 sa_handler 成功返回了,怎麼回到程式原來在用戶態運行的地方呢?那就是在 __setup_rt_frame 中,通過 put_user_ex,將 sa_restorer 放到 frame->pretcode 裡面。當 sa_handler 執行完之後,會執行iret指令,彈出返回地址,也就到 sa_restorer 執行。sa_restorer 這是什麼呢?

咱們在 sigaction 介紹的時候就沒有介紹它,在 Glibc 的 __libc_sigaction 函數中也沒有注意到,它被賦值成了 restore_rt。這其實就是 sa_handler 執行完畢之後,馬上要執行的函數。從名字我們就能感覺到,它將恢復原來程式運行的地方。
在 Glibc 中,我們可以找到它的定義,它竟然調用了一個系統調用,系統調用號為__NR_rt_sigreturn。
RESTORE (restore_rt, __NR_rt_sigreturn)
#define RESTORE(name, syscall) RESTORE2 (name, syscall)
# define RESTORE2(name, syscall) \
asm \
( \
/* `nop' for debuggers assuming `call' should not disalign the code. */ \
" nop\n" \
".align 16\n" \
".LSTART_" #name ":\n" \
" .type __" #name ",@function\n" \
"__" #name ":\n" \
" movq $" #syscall ", %rax\n" \
" syscall\n"

在內核裡面找到 __NR_rt_sigreturn 對應的系統調用。
asmlinkage long sys_rt_sigreturn(void)
{
struct pt_regs *regs = current_pt_regs();
struct rt_sigframe __user *frame;
sigset_t set;
unsigned long uc_flags;
frame = (struct rt_sigframe __user *)(regs->sp - sizeof(long));
if (!access_ok(VERIFY_READ, frame, sizeof(*frame)))
goto badframe;
if (__copy_from_user(&set, &frame->uc.uc_sigmask, sizeof(set)))
goto badframe;
if (__get_user(uc_flags, &frame->uc.uc_flags))
goto badframe;
set_current_blocked(&set);
if (restore_sigcontext(regs, &frame->uc.uc_mcontext, uc_flags))
goto badframe;
if (restore_altstack(&frame->uc.uc_stack))
goto badframe;
return regs->ax;
.....
}
在這裡面,把上次填充的那個 rt_sigframe 拿出來,然後 restore_sigcontext 將 pt_regs恢復成為原來用戶態的樣子。從這個系統調用返回的時候,應用A還誤以為從上次的系統調用返回的呢。
至此,整個訊號處理過程才全部結束。
訊號的發送與處理是一個複雜的過程,這裡來總結一下。
- 假設我們有一個進程 A,main 函數裡面調用系統調用進入內核。
- 按照系統調用的原理,會將用戶態棧的資訊保存在 pt_regs 裡面,也即記住原來用戶態是運行到了 line A 的地方。
- 在內核中執行系統調用讀取數據。
- 當發現沒有什麼數據可讀取的時候,只好進入睡眠狀態,並且調用 schedule 讓出 CPU,這是進程調度第一定律。
- 將進程狀態設置為 TASK_INTERRUPTIBLE,可中斷的睡眠狀態,也即如果有訊號來的話,是可以喚醒它的。
- 其他的進程或者 shell 發送一個訊號,有四個函數可以調用 kill,tkill,tgkill,rt_sigqueueinfo
- 四個發送訊號的函數,在內核中最終都是調用 do_send_sig_info
- do_send_sig_info 調用 send_signal 給進程 A 發送一個訊號,其實就是找到進程 A 的task_struct,或者加入訊號集合,為不可靠訊號,或者加入訊號鏈表,為可靠訊號
- do_send_sig_info 調用 signal_wake_up 喚醒進程 A。
- 進程 A 重新進入運行狀態 TASK_RUNNING,根據進程調度第一定律,一定會接著schedule 運行。
- 進程 A 被喚醒後,檢查是否有訊號到來,如果沒有,重新循環到一開始,嘗試再次讀取數據,如果還是沒有數據,再次進入 TASK_INTERRUPTIBLE,即可中斷的睡眠狀態。
- 當發現有訊號到來的時候,就返回當前正在執行的系統調用,並返回一個錯誤表示系統調用被中斷了。
- 系統調用返回的時候,會調用 exit_to_usermode_loop,這是一個處理訊號的時機
- 調用 do_signal 開始處理訊號
- 根據訊號,得到訊號處理函數 sa_handler,然後修改 pt_regs 中的用戶態棧的資訊,讓pt_regs 指向 sa_handler。同時修改用戶態的棧,插入一個棧幀 sa_restorer,裡面保存了原來的指向 line A 的 pt_regs,並且設置讓 sa_handler 運行完畢後,跳到 sa_restorer 運行。
- 返回用戶態,由於 pt_regs 已經設置為 sa_handler,則返回用戶態執行 sa_handler。
- sa_handler 執行完畢後,訊號處理函數就執行完了,接著根據第 15 步對於用戶態棧幀的修改,會跳到 sa_restorer 運行。
- sa_restorer 會調用系統調用 rt_sigreturn 再次進入內核。
- 在內核中,rt_sigreturn 恢復原來的 pt_regs,重新指向 line A。
- 從 rt_sigreturn 返回用戶態,還是調用 exit_to_usermode_loop。
- 這次因為 pt_regs 已經指向 line A 了,於是就到了進程 A 中,接著系統調用之後運行,當然這個系統調用返回的是它被中斷了,沒有執行完的錯誤。
2 linux 多執行緒訊號
上節說了linux訊號指的是linux進程或者整個進程組,其實執行緒和進程在linux內核中都是task,發送訊號可以是kill或tkill,對於在多執行緒的程式中,如果不做特殊的訊號阻塞處理,當發送訊號給進程時,從上面內核程式碼中看到,由系統選擇一個執行緒來處理這個訊號。
每個執行緒由自己的訊號屏蔽字,但是訊號的處理是進程中所有執行緒貢獻的。這意味著單個執行緒可以阻止某些訊號,但是當某個執行緒修改了給定訊號的相關處理行為後,該進程下的所有執行緒都必須共享這個處理方式的改變。換句話說:signal或者sigaction是進程裡面的概念,他們是針對整個進程進行控制的,是所有執行緒共享的,某個執行緒調用了signal或者sigaction更改了給定訊號的處理方式,那麼進程訊號處理方式就改變。
如果一個訊號與硬體故障相關,那麼該訊號一般會發給引起該事件的執行緒中去。
執行緒的訊號操作介面如下。執行緒使用pthread_sigmask來阻止訊號發送。
#include<signal.h>
int pthread_sigmask(int how, const sigset_t *restrict set,
sigset_t *restrict oset);
set參數包含執行緒用於修改訊號屏蔽字的訊號集,oset如果不為NULL,並把oset設置為siget_t結構的地址,來獲取當前的訊號屏蔽字。how:SIG_BLOCK將set加入到執行緒訊號屏蔽字中,SIG_SETMASK用訊號集set替換執行緒當前的訊號屏蔽字;SUG_UNBLOCK,從當前執行緒訊號屏蔽字中移除set中的訊號。
執行緒可通過sigwait等待一個或多個訊號的出現。
#include<signal.h>
int siwait(const sigset_t *restrict set, int *restrich signop)
int sigwaitinfo(const sigset_t *set, siginfo_t *si);
int sigtimedwait (const sigset_t *set, siginfo_t *si,
const struct timespec *timeout);
set參數指定執行緒等待的訊號集,signop指向整數將包含發送訊號的數量。sigwait從set中選擇一個未決訊號(pending),從執行緒的未決訊號集中移除該訊號,並在sig中返回該訊號值。如果set中的所有訊號都不是pending狀態,則sigwait會阻塞調用它的執行緒,直到set中的訊號變為pending。
除了返回資訊方面,sigwaitinfo的行為基本上與sigwait類似。sigwait在sig中返回觸發的訊號值;而sigwaitinfo的返回值就是觸發的訊號值,並且如果info不為NULL,則sigwaitinfo返回時,還會在siginfo_t *info中返回更多該訊號的資訊.
執行緒可通過pthread_kill把訊號發送給執行緒。
#include<signal.h>
int pthread_kill(pthread_t thread,int signo);
可以傳一個0值得signo來檢查一個執行緒是否存在。如果訊號的默認處理動作是終止該進程,那麼把該訊號傳遞給某個執行緒任然會殺死整個進程。
參考:
英特爾® 64 位和 IA-32 架構軟體開發人員手冊第 3 卷 :系統編程指南
極客時間專欄-趣談Linux作業系統
《linux內核源程式碼情景分析》


